
मशीन लर्निंग सॉफ्टवेयर कोड अक्सर जटिल होता है और भ्रामक होता है। इसमें बग्स का पता लगाना और उन्हें खत्म करना एक संसाधन-गहन कार्य है। यहां तक कि सबसे सरल
प्रत्यक्ष-कनेक्टेड न्यूरल नेटवर्क को नेटवर्क आर्किटेक्चर, वेट के आरंभीकरण और नेटवर्क अनुकूलन के लिए एक गंभीर दृष्टिकोण की आवश्यकता होती है। एक छोटी सी गलती अप्रिय समस्याओं को जन्म दे सकती है।
यह लेख आपके तंत्रिका नेटवर्क के डीबगिंग एल्गोरिदम के बारे में है।
स्किलबॉक्स सलाह देता है: स्क्रैच से एक हाथ पर पाठ्यक्रम अजगर डेवलपर ।
हम आपको याद दिलाते हैं: "हैबर" के सभी पाठकों के लिए - "हैबर" प्रोमो कोड का उपयोग करके किसी भी स्किलबॉक्स कोर्स के लिए पंजीकरण करते समय 10,000 रूबल की छूट।
एल्गोरिथ्म में पाँच चरण होते हैं:
- सरल शुरुआत;
- नुकसान की पुष्टि;
- मध्यवर्ती परिणामों और यौगिकों का सत्यापन;
- मापदंडों के निदान;
- काम पर नियंत्रण।
यदि आपको बाकी चीजों की तुलना में कुछ अधिक दिलचस्प लगता है, तो आप सीधे इन वर्गों में जा सकते हैं।
आसान शुरुआत
जटिल वास्तुकला, नियमितीकरण और सीखने की गति नियोजक के साथ एक तंत्रिका नेटवर्क एक नियमित नेटवर्क की तुलना में पहली फिल्म के लिए कठिन है। हम यहां थोड़े पेचीदा हैं, क्योंकि आइटम का स्वयं डिबगिंग से अप्रत्यक्ष संबंध है, लेकिन फिर भी यह एक महत्वपूर्ण सिफारिश है।
एक सरल शुरुआत एक सरलीकृत मॉडल बनाना और उसे एक डेटा सेट (बिंदु) पर प्रशिक्षित करना है।
पहले हम एक सरलीकृत मॉडल बनाते हैंएक त्वरित शुरुआत के लिए, एक छिपी हुई परत के साथ एक छोटा नेटवर्क बनाएं और जांचें कि सब कुछ सही ढंग से काम करता है। फिर हम धीरे-धीरे मॉडल को जटिल करते हैं, इसकी संरचना के हर नए पहलू (अतिरिक्त परत, पैरामीटर, आदि) की जांच करते हैं, और आगे बढ़ते हैं।
हम मॉडल को एक एकल डेटा सेट (बिंदु) पर प्रशिक्षित करते हैंअपने प्रोजेक्ट के स्वास्थ्य के त्वरित परीक्षण के रूप में, आप सिस्टम सही ढंग से काम कर रहे हैं या नहीं, इसकी पुष्टि के लिए आप प्रशिक्षण के लिए एक या दो डेटा बिंदुओं का उपयोग कर सकते हैं। तंत्रिका नेटवर्क को प्रशिक्षण और सत्यापन की 100% सटीकता दिखानी चाहिए। यदि यह मामला नहीं है, तो या तो मॉडल बहुत छोटा है या आपके पास पहले से ही एक बग है।
यहां तक कि अगर सब ठीक है, तो आगे बढ़ने से पहले एक या अधिक युगों के पारित होने के लिए मॉडल तैयार करें।
हानि का अनुमान
नुकसान का आकलन मॉडल प्रदर्शन को परिष्कृत करने का मुख्य तरीका है। आपको यह सुनिश्चित करने की आवश्यकता है कि नुकसान कार्य से मेल खाता है, और नुकसान कार्यों का मूल्यांकन सही पैमाने पर किया जाता है। यदि आप एक से अधिक प्रकार के नुकसान का उपयोग करते हैं, तो सुनिश्चित करें कि वे सभी एक ही क्रम के हैं और सही ढंग से स्केल किए गए हैं।
प्रारंभिक नुकसानों के लिए चौकस रहना महत्वपूर्ण है। यह जाँचें कि यदि एक यादृच्छिक अनुमान के साथ मॉडल शुरू हुआ, तो वास्तविक परिणाम कितना करीब है।
आंद्रेई करपाती का
काम निम्नलिखित सुझाव देता है : “सुनिश्चित करें कि जब आप बहुत कम मापदंडों के साथ काम करना शुरू करते हैं तो आपको अपेक्षित परिणाम मिलता है। डेटा हानि को तुरंत जांचना बेहतर है (नियमितीकरण की डिग्री के साथ शून्य पर)। उदाहरण के लिए, सॉफ्टमैक्स क्लासिफायर के साथ CIFAR-10 के लिए, हम प्रारंभिक नुकसान 2.302 होने की उम्मीद करते हैं, क्योंकि प्रत्येक वर्ग के लिए अपेक्षित प्रसार संभावना 0.1 है (क्योंकि 10 वर्ग हैं), और सॉफ्टमैक्स का नुकसान सही वर्ग के नकारात्मक लघुगणकीय संभावना है - ln (0.1) = 2.302। "
एक बाइनरी उदाहरण के लिए, एक समान गणना बस प्रत्येक वर्ग के लिए की जाती है। यहां, उदाहरण के लिए, डेटा हैं: 20% 0 और 80% 1। अपेक्षित प्रारंभिक नुकसान -0.2ln (0.5) –0.8ln (0.5) = 0.693147 तक होगा। यदि परिणाम 1 से अधिक है, तो यह संकेत दे सकता है कि तंत्रिका नेटवर्क का वजन ठीक से संतुलित नहीं है या डेटा सामान्य नहीं है।
मध्यवर्ती परिणाम और कनेक्शन की जाँच करना
तंत्रिका नेटवर्क को डिबग करने के लिए, नेटवर्क के भीतर प्रक्रियाओं की गतिशीलता और व्यक्तिगत मध्यवर्ती परतों की भूमिका को समझना आवश्यक है, क्योंकि वे जुड़े हुए हैं। यहां कुछ सामान्य गलतियां हैं जिनका आप सामना कर सकते हैं:
- ग्रेडिएंट अपडेट के लिए गलत भाव
- वजन अद्यतन लागू नहीं होते हैं;
- गायब हो रहा है या ग्रेडिएंट में विस्फोट हो रहा है।
यदि ग्रेडिएंट वैल्यू शून्य है, तो इसका मतलब है कि ऑप्टिमाइज़र में सीखने की गति बहुत धीमी है, या कि आपने ग्रेडिएंट को अपडेट करने के लिए गलत अभिव्यक्ति का सामना किया।
इसके अलावा, सक्रियण फ़ंक्शंस, वज़न और प्रत्येक परतों के अपडेट के मूल्यों की निगरानी करना आवश्यक है। उदाहरण के लिए, पैरामीटर अपडेट (वेट और ऑफ़सेट) का मान
1-e3 होना चाहिए ।
"डाइंग रेएलयू" या
" डिसैपियरिंग
ग्रैडिएंट प्रॉब्लम" नामक एक घटना है जब रेउल न्यूरॉन्स अपने वजन के लिए बड़े नकारात्मक पूर्वाग्रह मूल्य का अध्ययन करने के बाद शून्य का उत्पादन करेंगे। ये न्यूरॉन्स किसी भी डेटा जगह में फिर से सक्रिय नहीं होते हैं।
आप एक संख्यात्मक दृष्टिकोण का उपयोग करके ढाल का अनुमान लगाकर इन त्रुटियों का पता लगाने के लिए ढाल परीक्षण का उपयोग कर सकते हैं। यदि यह परिकलित ढ़ाल के करीब है, तो वापस प्रचार को सही तरीके से लागू किया गया था। एक ग्रेडिएंट चेक बनाने के लिए, इन शानदार CS231 संसाधनों को
यहाँ और
यहाँ , साथ ही इस विषय पर एंड्रयू नगा के ट्यूटोरियल की जाँच करें।
फैज़ान शेख एक तंत्रिका नेटवर्क की कल्पना के लिए तीन मुख्य तरीके बताते हैं:
- प्रारंभिक - सरल तरीके जो हमें प्रशिक्षित मॉडल की सामान्य संरचना दिखाते हैं। वे तंत्रिका नेटवर्क के व्यक्तिगत परतों के रूपों या फ़िल्टर के आउटपुट और प्रत्येक परत में पैरामीटर शामिल करते हैं।
- सक्रियता के आधार पर। उनमें, हम अपने कार्यों को समझने के लिए व्यक्तिगत न्यूरॉन्स या न्यूरॉन्स के समूहों की सक्रियता को परिभाषित करते हैं।
- धीरे-धीरे आधारित है। ये तरीके मॉडल को प्रशिक्षित करते समय और पीछे से आने वाले ग्रेडिएंट्स में हेरफेर करते हैं (जिसमें मॉडल मैप्स और क्लास एक्टिवेशन मैप्स भी शामिल हैं)।
व्यक्तिगत परतों की सक्रियता और कनेक्शन की कल्पना करने के लिए कई उपयोगी उपकरण हैं, उदाहरण के लिए,
कॉनएक्स और
टेन्सरबोर्ड ।
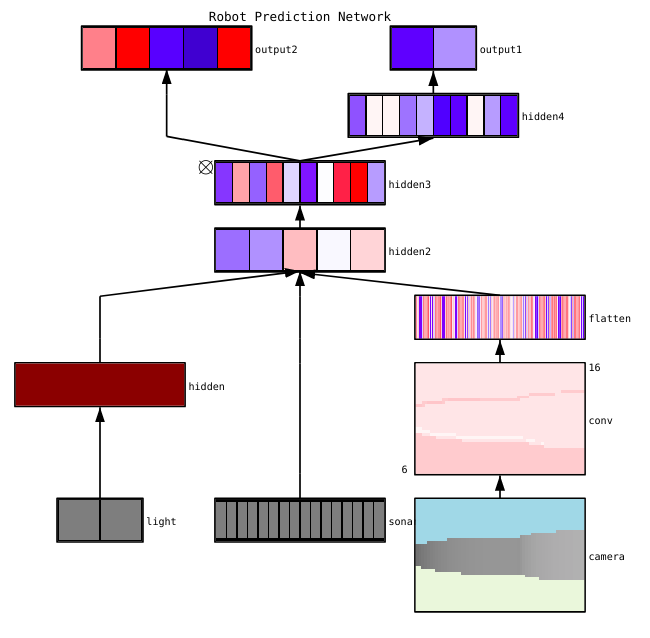
पैरामीटर डायग्नोस्टिक्स
तंत्रिका नेटवर्क में बहुत सारे पैरामीटर हैं जो एक दूसरे के साथ बातचीत करते हैं, जो अनुकूलन को जटिल करता है। दरअसल, यह खंड विशेषज्ञों द्वारा सक्रिय शोध का विषय है, इसलिए नीचे दिए गए प्रस्तावों को केवल सलाह माना जाना चाहिए, शुरुआती बिंदु जिनसे आप निर्माण कर सकते हैं।
पैकेट का आकार (बैच आकार) - यदि आप चाहते हैं कि पैकेट का आकार बड़ा हो तो त्रुटि ग्रेडिएंट का सटीक अनुमान लगा सकते हैं, लेकिन इतना छोटा कि स्टोचस्टिक ग्रेडिएंट डिसेंट (SGD) आपके नेटवर्क को सुव्यवस्थित कर सके। संकुल का छोटा आकार सीखने की प्रक्रिया में और भविष्य में कठिनाइयों का अनुकूलन करने के लिए शोर के कारण तेजी से अभिसरण का कारण बनेगा। यह
यहां और अधिक विस्तार से वर्णित
है ।
सीखने की गति - बहुत धीमी गति से अभिसरण या स्थानीय चढ़ाव में फंस जाने का जोखिम होगा। उसी समय, एक उच्च सीखने की गति अनुकूलन में एक विसंगति का कारण बनेगी, क्योंकि आप गहरी के माध्यम से "कूद" का जोखिम उठाते हैं, लेकिन उसी समय नुकसान फ़ंक्शन का संकीर्ण भाग। तंत्रिका नेटवर्क के प्रशिक्षण के दौरान इसे कम करने के लिए गति योजना का उपयोग करने का प्रयास करें।
इस मुद्दे पर CS231n
का एक बड़ा वर्ग है ।
धीरे-धीरे कतरन - अधिकतम मूल्य या सीमा मानदंड पर वापस प्रसार के दौरान मापदंडों के ग्रेडिएंट को ट्रिम करना। किसी भी विस्फोट के साथ समस्याओं को हल करने के लिए उपयोगी है जो आप तीसरे पैराग्राफ में सामना कर सकते हैं।
बैच सामान्यीकरण - प्रत्येक परत के इनपुट डेटा को सामान्य करने के लिए उपयोग किया जाता है, जो आंतरिक सहसंयोजक पारी की समस्या को हल करने की अनुमति देता है। यदि आप ड्रॉपआउट और बैच नोर्मा का एक साथ उपयोग करते हैं,
तो इस लेख को देखें ।
स्टोकेस्टिक ग्रेडिएंट डिसेंट (SGD) -
SGD की कई किस्में हैं जो गति, अनुकूली सीखने की गति और नेस्टरोव की विधि का उपयोग करती हैं। इसी समय, प्रशिक्षण दक्षता और सामान्यीकरण (
यहां विवरण ) के संदर्भ में दोनों में से किसी का भी स्पष्ट लाभ नहीं है।
नियमितीकरण - सामान्यीकृत मॉडल के निर्माण के लिए महत्वपूर्ण है, क्योंकि यह मॉडल की जटिलता या चरम पैरामीटर मूल्यों के लिए एक दंड जोड़ता है। यह मॉडल के विचलन को कम करने का एक तरीका है जो बिना इसके विस्थापन को बढ़ाए। अधिक
जानकारी यहाँ ।
अपने आप को सब कुछ का मूल्यांकन करने के लिए, आपको नियमितीकरण को अक्षम करना होगा और डेटा हानि की प्रवणता को स्वयं जांचना होगा।
ड्रॉपआउट भीड़ को रोकने के लिए अपने नेटवर्क को सुव्यवस्थित करने का एक और तरीका है। प्रशिक्षण के दौरान, न्यूरॉन की गतिविधि को एक निश्चित संभाव्यता पी (हाइपरपरमीटर) के साथ बनाए रखने या विपरीत स्थिति में शून्य पर सेट करने से ही नुकसान होता है। नतीजतन, नेटवर्क को प्रत्येक प्रशिक्षण पार्टी के लिए मापदंडों का एक अलग उपसमूह का उपयोग करना चाहिए, जो कुछ मापदंडों में परिवर्तन को कम करता है जो प्रमुख हो जाते हैं।
महत्वपूर्ण: यदि आप ड्रॉपआउट और बैच सामान्यीकरण दोनों का उपयोग करते हैं, तो इन ऑपरेशनों के आदेश या उनके संयुक्त उपयोग के साथ भी सावधान रहें। यह सब अभी भी सक्रिय रूप से चर्चा और पूरक है। इस विषय
पर स्टाकेवरफ्लो और
आरएक्सिव पर दो महत्वपूर्ण चर्चाएँ हैं।
काम पर नियंत्रण
यह वर्कफ़्लो और प्रयोगों का दस्तावेजीकरण करने के बारे में है। यदि आप कुछ भी दस्तावेज नहीं करते हैं, तो आप भूल सकते हैं, उदाहरण के लिए, किस प्रकार की प्रशिक्षण गति या वर्ग भार का उपयोग किया जाता है। नियंत्रण के लिए धन्यवाद, आप पिछले प्रयोगों को आसानी से देख और पुन: उत्पन्न कर सकते हैं। इससे डुप्लिकेट प्रयोगों की संख्या कम हो जाती है।
सच है, बड़ी मात्रा में काम करने की स्थिति में मैनुअल प्रलेखन चुनौतीपूर्ण हो सकता है। यहां कॉमेट.एमएल जैसे उपकरण आपको अपने मॉडल (हाइपरपरमेटर्स, मॉडल प्रदर्शन संकेतक और पर्यावरणीय जानकारी) के बारे में महत्वपूर्ण जानकारी सहित डेटा सेट, कोड परिवर्तन, प्रयोग इतिहास और उत्पादन मॉडल को स्वचालित रूप से लॉग इन करने में मदद करते हैं।
एक तंत्रिका नेटवर्क छोटे परिवर्तनों के प्रति बहुत संवेदनशील हो सकता है, और इससे मॉडल के प्रदर्शन में कमी आएगी। ट्रैकिंग और दस्तावेजीकरण का काम आपके पर्यावरण और मॉडलिंग को मानकीकृत करने के लिए पहला कदम है।
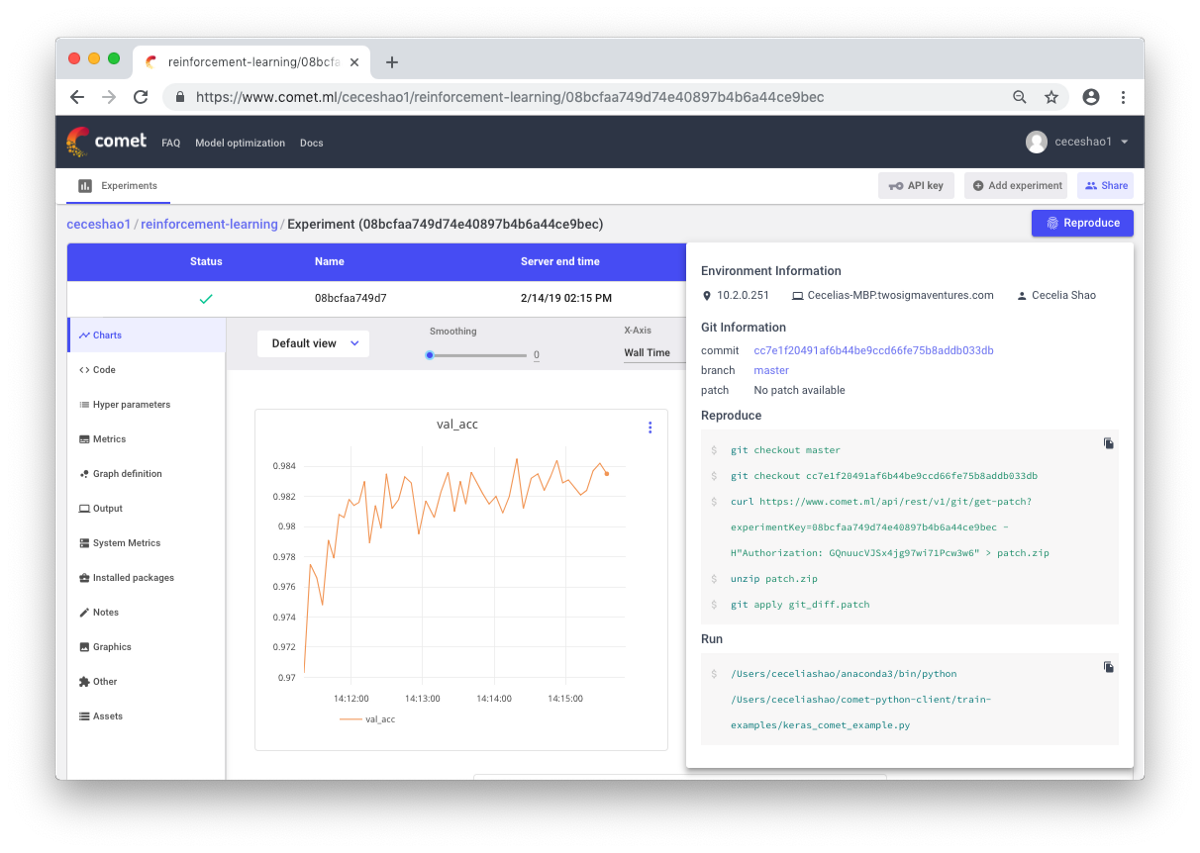
मुझे उम्मीद है कि यह पोस्ट शुरुआती बिंदु बन सकती है जहां से आप अपने तंत्रिका नेटवर्क को डीबग करना शुरू कर देंगे।
स्किलबॉक्स अनुशंसा करता है: