हाल ही में, GraphQL अधिक से अधिक लोकप्रियता प्राप्त कर रहा है, और इसके साथ सूचना सुरक्षा विशेषज्ञों की दिलचस्पी बढ़ रही है। प्रौद्योगिकी का उपयोग कंपनियों द्वारा किया जाता है जैसे: फेसबुक, ट्विटर, पेपाल, जीथब और अन्य, जिसका अर्थ है कि यह पता लगाने का समय है कि इस तरह के एपीआई का परीक्षण कैसे किया जाए। इस लेख में, हम इस क्वेरी भाषा के सिद्धांतों और ग्राफ़िकल के साथ अनुप्रयोगों के प्रवेश के परीक्षण के निर्देशों के बारे में बात करेंगे।
आपको ग्राफ़कॉल को जानने की आवश्यकता क्यों है? यह क्वेरी भाषा सक्रिय रूप से विकसित हो रही है और अधिक से अधिक कंपनियां इसके लिए व्यावहारिक उपयोग कर रही हैं। बग बाउंटी कार्यक्रमों के ढांचे के भीतर, इस भाषा की लोकप्रियता भी बढ़ रही है, दिलचस्प उदाहरण
यहां और
यहां देखे जा सकते
हैं ।
ट्रेनिंगएक परीक्षण साइट जहां आपको इस लेख में अधिकांश उदाहरण मिलेंगे।
अनुप्रयोगों के साथ
एक सूची जिसे आप अध्ययन करने के लिए भी उपयोग कर सकते हैं।
विभिन्न APIs के साथ बातचीत करने के लिए, ग्राफ़िकल आईडीई का उपयोग करना बेहतर है:
हम अंतिम आईडीई की सिफारिश करते हैं: अनिद्रा का एक सुविधाजनक और सरल इंटरफ़ेस है, कई सेटिंग्स और अनुरोध फ़ील्ड के स्वत: पूर्ण होने हैं।
ग्राफकॉक के साथ अनुप्रयोगों के सुरक्षा विश्लेषण के सामान्य तरीकों पर सीधे आगे बढ़ने से पहले, हम बुनियादी अवधारणाओं को याद करते हैं।
GraphQL क्या है?
GraphQL एक एपीआई क्वेरी भाषा है जिसे REST के लिए अधिक कुशल, शक्तिशाली और लचीला विकल्प प्रदान करने के लिए डिज़ाइन किया गया है। यह डिक्लेरेटिव डेटा सैंपलिंग पर आधारित है, यानी क्लाइंट एपीआई से डेटा की सही-सही जानकारी ले सकता है। मल्टीपल एपीआई एंडपॉइंट्स (आरईएसटी) के बजाय, ग्राफक्लाइन एक एंडपॉइंट प्रदान करता है जो क्लाइंट को अनुरोधित डेटा प्रदान करता है।
REST और ग्राफकलाइन के बीच मुख्य अंतर
आमतौर पर REST API में आपको अलग-अलग एंडपॉइंट से जानकारी प्राप्त करने की आवश्यकता होती है। GraphQL में, समान डेटा प्राप्त करने के लिए, आपको उस डेटा को इंगित करने के लिए एक क्वेरी बनाने की आवश्यकता होती है जिसे आप प्राप्त करना चाहते हैं।
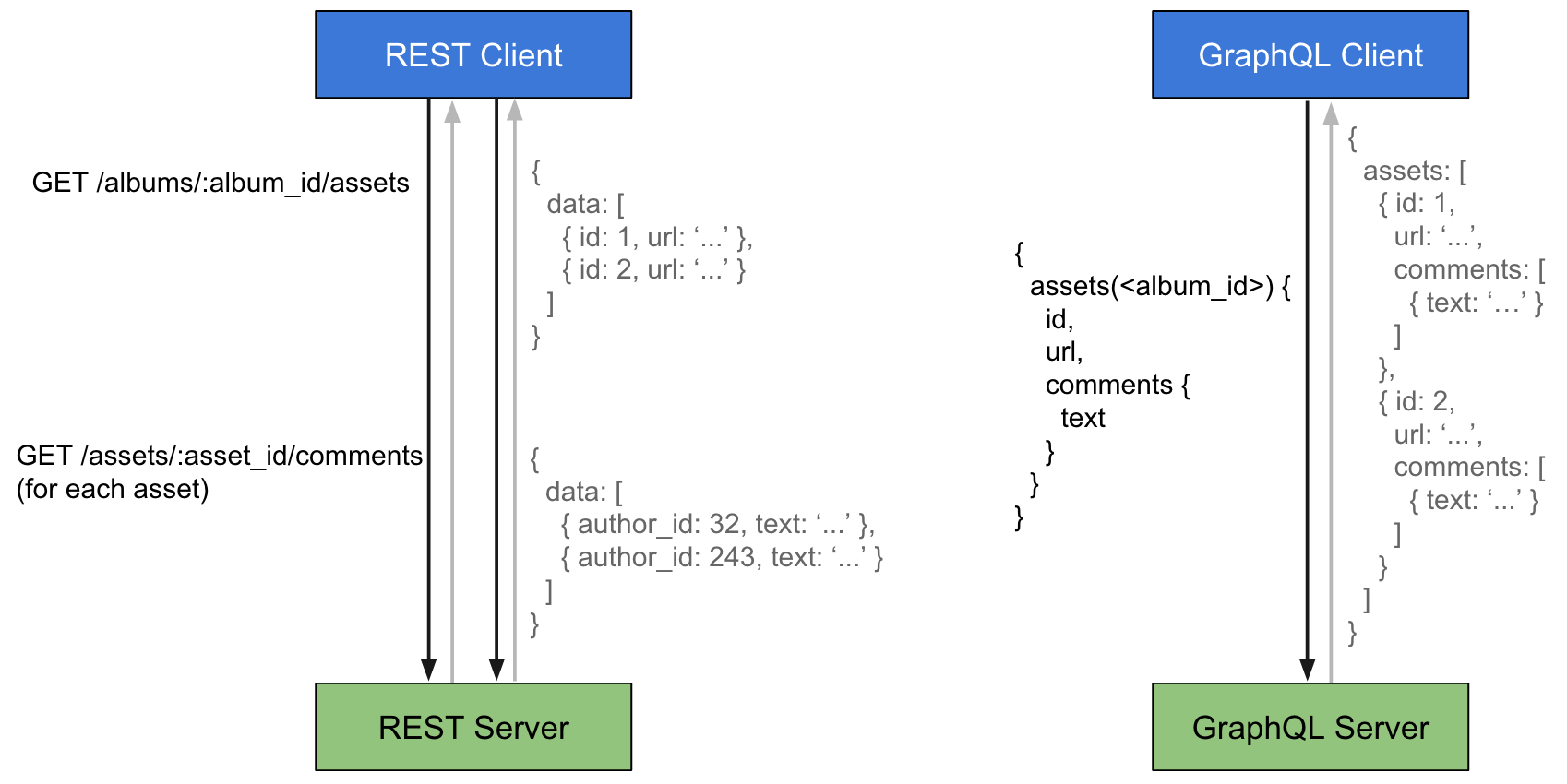
REST API वह जानकारी प्रदान करता है जो डेवलपर API में डाल देगा, अर्थात, यदि आपको API के सुझाव से अधिक या कम जानकारी प्राप्त करने की आवश्यकता है, तो अतिरिक्त क्रियाओं की आवश्यकता होगी। फिर से, ग्राफकलाइन अनुरोधित जानकारी प्रदान करता है।
एक उपयोगी जोड़ यह है कि ग्राफकॉल में एक स्कीमा है जो बताता है कि क्लाइंट को कैसे और क्या डेटा प्राप्त हो सकते हैं।
क्वेरी के प्रकार
GraphQL में 3 मुख्य प्रकार के प्रश्न हैं:
सवालस्कीमा में डेटा को पुनः प्राप्त / पढ़ने के लिए क्वेरी क्वेरी का उपयोग किया जाता है।
ऐसे अनुरोध का एक उदाहरण:
query { allPersons { name } }
अनुरोध में, हम संकेत देते हैं कि हम सभी उपयोगकर्ताओं के नाम प्राप्त करना चाहते हैं। नाम के अतिरिक्त, हम अन्य फ़ील्ड्स निर्दिष्ट कर सकते हैं:
आयु ,
आईडी ,
पोस्ट आदि। यह पता लगाने के लिए कि हमें कौन से फ़ील्ड मिल सकते हैं, आपको Ctrl + Space दबाने की आवश्यकता है। इस उदाहरण में, हम उस पैरामीटर को पास करते हैं जिसके साथ आवेदन पहले दो रिकॉर्ड लौटाएगा:
query { allPersons(first: 2) { name } }
परिवर्तनयदि डेटा पढ़ने के लिए क्वेरी प्रकार की आवश्यकता होती है, तो ग्राफक्यूएल में डेटा को लिखने, हटाने और संशोधित करने के लिए म्यूटेशन प्रकार की आवश्यकता होती है।
ऐसे अनुरोध का एक उदाहरण:
mutation { createPerson(name:"Bob", age: 37) { id name age } }
इस अनुरोध में, हम बॉब और उम्र 37 के साथ एक उपयोगकर्ता बनाते हैं (इन मापदंडों को तर्क के रूप में पारित किया जाता है), अटैचमेंट में (घुंघराले ब्रैकेट) हम संकेत देते हैं कि उपयोगकर्ता बनाने के बाद हम सर्वर से क्या डेटा प्राप्त करना चाहते हैं। यह समझने के लिए आवश्यक है कि अनुरोध सफल था, साथ ही डेटा प्राप्त करने के लिए कि सर्वर स्वतंत्र रूप से उत्पन्न करता है, जैसे कि
आईडी ।
अंशदानGraphQL में एक अन्य प्रकार की क्वेरी सदस्यता है। सिस्टम में होने वाले किसी भी परिवर्तन के उपयोगकर्ताओं को सूचित करना आवश्यक है। यह इस तरह से काम करता है: क्लाइंट किसी घटना के लिए सदस्यता लेता है, जिसके बाद सर्वर (आमतौर पर वेबस्केट के माध्यम से) के साथ एक कनेक्शन स्थापित होता है, और जब यह घटना होती है, तो सर्वर क्लाइंट को स्थापित कनेक्शन के बारे में एक अधिसूचना भेजता है।
एक उदाहरण:
subscription { newPerson { name age id } }
जब एक नया व्यक्ति बनाया जाता है, तो सर्वर क्लाइंट को जानकारी भेजेगा। स्कीमा में सदस्यता प्रश्नों की उपस्थिति क्वेरी और म्यूटेशन की तुलना में कम सामान्य है।
यह ध्यान देने योग्य है कि क्वेरी, म्यूटेशन और सदस्यता के लिए सभी क्षमताओं को एक विशिष्ट एपीआई के डेवलपर द्वारा बनाया और कॉन्फ़िगर किया गया है।
ऐच्छिक
व्यवहार में, डेवलपर्स अक्सर स्पष्टता के लिए प्रश्नों में उपनाम और ऑपरेशननाम का उपयोग करते हैं।
उपनामक्वेरीज़ के लिए ग्राफ़िक उपनाम सुविधा प्रदान करता है, जिससे यह समझना आसान हो जाता है कि ग्राहक क्या अनुरोध कर रहा है।
मान लें कि हमारे पास फ़ॉर्म की एक क्वेरी है:
{ Person(id: 123) { age } }
जो
आईडी 123 के साथ उपयोगकर्ता नाम प्रदर्शित करेगा। इस उपयोगकर्ता नाम को Vasya होने दें।
ताकि अगली बार जब आपको यह पता न चले कि यह अनुरोध क्या प्रदर्शित करेगा, तो आप इसे इस तरह कर सकते हैं:
{ Vasya: Person(id: 123) { age } }
OperationNameउपनाम के अलावा, ग्राफकॉन ऑपरेशननेम का उपयोग करता है:
query gettingAllPersons { allPersons { name age } }
ऑपरेशननाम को यह समझाने की जरूरत है कि अनुरोध क्या करता है।
Pentest
हम मूल बातें पता लगाने के बाद, हम सीधे पंचक पर जाते हैं। कैसे समझें कि कोई एप्लिकेशन ग्राफकॉल का उपयोग करता है? यहाँ एक उदाहरण क्वेरी है जिसमें एक ग्राफक्यूएल क्वेरी है:
POST /simple/v1/cjp70ml3o9tpa0184rtqs8tmu/ HTTP/1.1 Host: api.graph.cool User-Agent: Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:65.0) Gecko/20100101 Firefox/65.0 Accept: */* Accept-Language: ru-RU,ru;q=0.8,en-US;q=0.5,en;q=0.3 Accept-Encoding: gzip, deflate Referer: https://api.graph.cool/simple/v1/cjp70ml3o9tpa0184rtqs8tmu/ content-type: application/json Origin: https://api.graph.cool Content-Length: 139 Connection: close {"operationName":null,"variables":{},"query":"{\n __schema {\n mutationType {\n fields {\n name\n }\n }\n }\n}\n"}
कुछ पैरामीटर जिसके द्वारा आप समझ सकते हैं कि यह ग्राफकॉल है, और कुछ और नहीं:
- अनुरोध निकाय में शब्द हैं: __schema, फ़ील्ड्स, ऑपरेशननाम, म्यूटेशन, आदि;
- अनुरोध निकाय में कई वर्ण "\ n" हैं। जैसा कि अभ्यास से पता चलता है, उन्हें अनुरोध पढ़ने के लिए इसे और अधिक सुविधाजनक बनाने के लिए हटाया जा सकता है;
- अक्सर सर्वर को अनुरोध भेजने का तरीका: agraphql
महान, पाया और पहचाना गया। लेकिन
उद्धरण चिह्न कहाँ डालें, यह कैसे पता करें कि हमें किसके साथ काम करने की आवश्यकता है? आत्मनिरीक्षण करने के लिए आ जाएगा।
आत्मनिरीक्षण
ग्राफकॉल एक आत्मनिरीक्षण योजना प्रदान करता है, अर्थात डेटा का वर्णन करने वाली एक योजना जो हम प्राप्त कर सकते हैं। इसके लिए धन्यवाद, हम यह पता लगा सकते हैं कि क्या अनुरोध मौजूद हैं, क्या तर्क दिए जा सकते हैं / उन्हें पारित किया जाना चाहिए, और बहुत कुछ। ध्यान दें कि कुछ मामलों में, डेवलपर्स जानबूझकर अपने आवेदन के आत्मनिरीक्षण की संभावना को अनुमति नहीं देते हैं। हालांकि, विशाल बहुमत अभी भी इस संभावना को छोड़ देता है।
प्रश्नों के मूल उदाहरणों पर विचार करें।
उदाहरण 1. सभी प्रकार के अनुरोध प्राप्त करना query { __schema { types { name fields { name } } } }
हम एक क्वेरी क्वेरी बनाते हैं, यह इंगित करते हैं कि हम __schema पर डेटा प्राप्त करना चाहते हैं, और इसमें प्रकार, उनके नाम और क्षेत्र। GraphQL में, सेवा चर नाम हैं: __schema, __typename, __type।
उत्तर में हम योजना में मौजूद सभी प्रकार के अनुरोधों, उनके नामों और क्षेत्रों को प्राप्त करेंगे।
उदाहरण 2. विशिष्ट प्रकार के अनुरोध के लिए फ़ील्ड प्राप्त करना (क्वेरी, म्यूटेशन, विवरण) query { __schema { queryType { fields { name args { name } } } } }
इस अनुरोध का उत्तर सभी संभावित अनुरोध होंगे जिन्हें हम योजना के लिए डेटा (क्वेरी के प्रकार), और उनके लिए संभव / आवश्यक तर्क प्राप्त करने के लिए निष्पादित कर सकते हैं। कुछ प्रश्नों के लिए, तर्क निर्दिष्ट करना आवश्यक है। यदि आप एक आवश्यक तर्क निर्दिष्ट किए बिना इस तरह के अनुरोध को निष्पादित करते हैं, तो सर्वर को एक त्रुटि संदेश प्रदर्शित करना चाहिए जिसे आपको इसे निर्दिष्ट करना होगा। क्वेरी टाइप के बजाय, हम क्रमशः उत्परिवर्तन और सब्सक्रिप्शन टाइप कर सकते हैं, क्रमशः उत्परिवर्तन और सदस्यता के लिए सभी संभव अनुरोध प्राप्त करने के लिए।
उदाहरण 3. एक विशेष प्रकार के अनुरोध के बारे में जानकारी प्राप्त करना query { __type(name: "Person") { fields { name } } }
इस क्वेरी के लिए धन्यवाद, हम व्यक्ति के लिए सभी फ़ील्ड प्राप्त करते हैं। एक तर्क के रूप में, व्यक्ति के बजाय, हम किसी अन्य अनुरोध नाम को पारित कर सकते हैं।
अब जब हम परीक्षण के तहत आवेदन की सामान्य संरचना का पता लगा सकते हैं, तो निर्धारित करें कि हम क्या देख रहे हैं।
जानकारी का खुलासाअधिकतर, ग्राफ़िकल का उपयोग करने वाले एक एप्लिकेशन में कई फ़ील्ड और प्रकार के प्रश्न होते हैं, और, जैसा कि बहुत से लोग जानते हैं, जितना अधिक जटिल और बड़ा अनुप्रयोग है, उतना ही मुश्किल यह है कि इसकी सुरक्षा को कॉन्फ़िगर और मॉनिटर करना। यही कारण है कि सावधान आत्मनिरीक्षण के साथ आप कुछ दिलचस्प पा सकते हैं, उदाहरण के लिए: उपयोगकर्ताओं के पूर्ण नाम, उनके फोन नंबर और अन्य महत्वपूर्ण डेटा। इसलिए, यदि आप ऐसा कुछ खोजना चाहते हैं, तो हम अनुशंसा करते हैं कि आप आवेदन के सभी संभावित क्षेत्रों और तर्कों की जांच करें। इसलिए, किसी एक एप्लिकेशन में पेंटेस्ट के हिस्से के रूप में, उपयोगकर्ता डेटा पाया गया: नाम, फोन नंबर, जन्म तिथि, कुछ डेटा डेटा, आदि।
एक उदाहरण:
query { User(id: 1) { name birth phone email password } }
आईडी मानों के माध्यम से जाने पर, हम अन्य उपयोगकर्ताओं के बारे में जानकारी प्राप्त कर सकते हैं (और शायद नहीं, अगर सब कुछ सही तरीके से कॉन्फ़िगर किया गया है)।
इंजेक्शनकहने की जरूरत नहीं है, लगभग हर जगह जहां बड़ी मात्रा में डेटा के साथ काम होता है, डेटाबेस हैं? और जहाँ एक डेटाबेस है - वहाँ SQL- इंजेक्शन, NoSQL-इंजेक्शन और अन्य प्रकार के इंजेक्शन हो सकते हैं।
एक उदाहरण:
mutation { createPerson(name:"Vasya'--+") { name } }
यहाँ क्वेरी तर्क में एक प्राथमिक SQL इंजेक्शन है।
प्राधिकरण बाईपासमान लें कि हम उपयोगकर्ता बना सकते हैं:
mutation { createPerson(username:"Vasya", password: "Qwerty1") { } }
यह मानते हुए कि सर्वर पर हैंडलर में एक निश्चित पैरामीटर .Admin है, हम फॉर्म का अनुरोध भेज सकते हैं:
mutation { createPerson(username:"Vasya", password: "Qwerty1", isAdmin: True) { } }
और उपयोगकर्ता वास्या को प्रशासक बनाते हैं।
DoS
घोषित सुविधा के अलावा, ग्राफकॉल की अपनी सुरक्षा खामियां हैं।
एक उदाहरण पर विचार करें:
query { Person { posts { author { posts { author { posts { author ... } } } } } } }
जैसा कि आप देख सकते हैं, हमने एक लूप्ड सबक्वेरी बनाई। इस तरह के निवेश की एक बड़ी संख्या के साथ, उदाहरण के लिए, 50 हजार, हम एक अनुरोध भेज सकते हैं जो सर्वर द्वारा बहुत लंबे समय तक संसाधित किया जाएगा या इसे पूरी तरह से "ड्रॉप" करेगा। मान्य अनुरोधों को संसाधित करने के बजाय, सर्वर डमी अनुरोध के विशाल नेस्टिंग को अनपैक करने में व्यस्त होगा।
बड़े घोंसले के शिकार के अलावा, प्रश्न स्वयं "भारी" हो सकते हैं - यह तब होता है जब किसी क्वेरी में बहुत सारे फ़ील्ड और आंतरिक अनुलग्नक होते हैं। इस तरह के अनुरोध से सर्वर पर प्रोसेसिंग में भी मुश्किलें आ सकती हैं।
निष्कर्ष
इसलिए, हमने ग्राफकॉल के साथ अनुप्रयोगों के प्रवेश परीक्षण के मूल सिद्धांतों की जांच की। हमें उम्मीद है कि आपने अपने लिए कुछ नया और उपयोगी सीखा होगा। यदि आप इस विषय में रुचि रखते हैं, और आप इसका गहराई से अध्ययन करना चाहते हैं, तो हम निम्नलिखित संसाधनों की सलाह देते हैं:
और मत भूलना: अभ्यास परिपूर्ण बनाता है। सौभाग्य है