
छवि स्रोत: www.nikonsmallworld.com
एंटी-प्लाजिरिज़्म एक विशेष खोज इंजन है, जो पहले से ही पहले से ही लिखा गया था । और किसी भी खोज इंजन, जो भी कह सकता है, जल्दी से काम करने के लिए, अपने स्वयं के सूचकांक की आवश्यकता होती है, जो खोज क्षेत्र की सभी विशेषताओं को ध्यान में रखता है। हेबर पर अपने पहले लेख में , मैं हमारे खोज सूचकांक के वर्तमान कार्यान्वयन, इसके विकास के इतिहास और एक या किसी अन्य समाधान को चुनने के कारणों के बारे में बात करूंगा। प्रभावी .NET एल्गोरिदम एक मिथक नहीं है, लेकिन एक कठिन और उत्पादक वास्तविकता है। हम हैशिंग, बिटवाइज़ कम्प्रेशन और मल्टी-लेवल प्राथमिकता वाले कैश की दुनिया में उतरेंगे। यदि आपको O (1) से अधिक तेज़ी से खोज की आवश्यकता हो तो क्या होगा?
अगर किसी और को नहीं पता कि इस तस्वीर में दाद कहां है, तो स्वागत है ...
दाद, सूचकांक और उनके लिए क्यों दिखते हैं
एक शिंगल आकार में कुछ शब्दों का एक टुकड़ा है। दाद एक दूसरे को ओवरलैप करते हैं, इसलिए नाम (अंग्रेजी, दाद - तराजू, टाइलिंग)। उनका विशिष्ट आकार एक खुला रहस्य है - 4 शब्द। या 5? खैर, यह निर्भर करता है। हालांकि, यहां तक कि यह मूल्य बहुत कम देता है और स्टॉप शब्दों की संरचना पर निर्भर करता है, शब्दों को सामान्य करने के लिए एल्गोरिथ्म और अन्य विवरण जो इस लेख के ढांचे में महत्वपूर्ण नहीं हैं। अंत में, हम इस शिंगल के आधार पर 64-बिट हैश की गणना करते हैं, जिसे हम भविष्य में शिंगल कहेंगे।
दस्तावेज़ के पाठ के अनुसार, आप कई दाद बना सकते हैं, जिनमें से संख्या दस्तावेज़ में शब्दों की संख्या के बराबर है:
पाठ: स्ट्रिंग → दाद: uint64 []
यदि कई दाद दो दस्तावेजों में मेल खाते हैं, तो हम मानते हैं कि दस्तावेज प्रतिच्छेद करते हैं। जितने अधिक शिंगल मिलते हैं, उतने ही समान पाठ इस जोड़ी के दस्तावेजों में होते हैं। सूचकांक उन दस्तावेज़ों की खोज करता है जिनमें सबसे अधिक संख्या में चौराहों के साथ दस्तावेज़ की जाँच की जा रही है।

चित्र स्रोत: विकिपीडिया
दाद सूचकांक आपको दो मुख्य कार्य करने की अनुमति देता है:
अपने पहचानकर्ताओं के साथ दस्तावेजों के दानों को अनुक्रमित करें:
index.Add (docId, दाद)
अतिव्यापी दस्तावेजों के लिए पहचानकर्ताओं की एक सूचीबद्ध सूची खोजें और प्रदर्शित करें:
index.Search (दाद) → (docId, स्कोर) []
रैंकिंग एल्गोरिथ्म, मेरा मानना है कि सामान्य रूप से एक अलग लेख के योग्य है, इसलिए हम इसके बारे में यहां नहीं लिखेंगे।
दाद का सूचकांक सुप्रसिद्ध पूर्ण-पाठ समकक्षों से अलग है, जैसे स्फिंक्स, इलास्टिक या बड़ा: Google, यैंडेक्स, आदि ... एक तरफ, इसे किसी भी एनएलपी और जीवन के अन्य खुशियों की आवश्यकता नहीं है। सभी पाठ प्रसंस्करण को बाहर निकाल दिया जाता है और इस प्रक्रिया को प्रभावित नहीं करता है, साथ ही पाठ में दाद का क्रम भी होता है। दूसरी ओर, खोज क्वेरी एक शब्द या कई शब्दों का एक वाक्यांश नहीं है, बल्कि कई सौ हजार हैश तक है , जो कुल मिलाकर अलग-अलग हैं, और अलग-अलग नहीं।
हाइपोथेटिक रूप से, आप शिंगल्स इंडेक्स के प्रतिस्थापन के रूप में पूर्ण-पाठ इंडेक्स का उपयोग कर सकते हैं, लेकिन अंतर बहुत महान हैं। कुछ प्रसिद्ध कुंजी-मूल्य-भंडारण का उपयोग करने का सबसे आसान तरीका, यह नीचे उल्लेख किया जाएगा। हम अपनी बाइक के कार्यान्वयन को देख रहे हैं, जिसे कहा जाता है - शिंगलइंडेक्स।
हम क्यों परेशान करते हैं? लेकिन क्यों।
- वॉल्यूम :
- बहुत सारे दस्तावेज हैं। अब हमारे पास लगभग 650 मिलियन हैं, और इस साल जाहिर तौर पर उनमें से अधिक होंगे;
- अनोखे दाद की संख्या छलांग और सीमा से बढ़ रही है और पहले से ही सैकड़ों अरबों तक पहुंच रही है। हम एक खरब का इंतजार कर रहे हैं।
- गति :
- ग्रीष्मकालीन सत्र के दौरान, दिन के दौरान, एंटी-प्लाजिरिज्म प्रणाली के माध्यम से 300 हजार से अधिक दस्तावेजों की जांच की जाती है । यह लोकप्रिय खोज इंजन के मानकों से थोड़ा सा है, लेकिन यह स्वर में रहता है;
- अद्वितीयता के लिए दस्तावेजों के सफल सत्यापन के लिए, अनुक्रमित दस्तावेजों की संख्या की जाँच की जा रही दस्तावेजों से अधिक परिमाण के आदेश होने चाहिए। औसत पर हमारे सूचकांक का वर्तमान संस्करण प्रति सेकंड 4000 से अधिक मध्यम दस्तावेजों की गति से भर सकता है।
और यह सब एक मशीन पर है! हां, हम दोहरा सकते हैं , हम धीरे-धीरे एक क्लस्टर पर डायनेमिक शार्किंग के करीब पहुंच रहे हैं, लेकिन 2005 से लेकर आज तक, सावधानी से देखभाल के साथ एक मशीन पर सूचकांक उपरोक्त सभी कठिनाइयों का सामना करने में सक्षम है।
अजीब अनुभव
हालाँकि, अब हम इतने अनुभवी हैं। यह पसंद है या नहीं, लेकिन हम भी बड़े हो गए हैं और विकास के दौरान विभिन्न चीजों की कोशिश की है, जो अब के बारे में याद करने के लिए मजेदार हैं।
चित्र स्रोत: विकिपीडिया
सबसे पहले, एक अनुभवहीन पाठक एक SQL डेटाबेस का उपयोग करना चाहेगा। आप केवल वे ही नहीं हैं जो ऐसा सोचते हैं, SQL कार्यान्वयन ने कई वर्षों तक हमें बहुत छोटे संग्रह को लागू करने के लिए अच्छी तरह से सेवा की है। फिर भी, ध्यान तुरंत लाखों दस्तावेजों पर था, इसलिए मुझे आगे जाना पड़ा।
जैसा कि आप जानते हैं, कोई भी साइकिल पसंद नहीं करता है, और LevelDB अभी तक सार्वजनिक नहीं थी, इसलिए 2010 में हमारी नज़र बर्कलेबीडी पर पड़ी। सब कुछ शांत है - उपयुक्त बीटी और हैश एक्सेस विधियों और एक लंबे इतिहास के साथ एक निरंतर अंतर्निहित कुंजी-मूल्य-आधार। उसके साथ सब कुछ अद्भुत था, लेकिन:
- हैश कार्यान्वयन के मामले में, जब यह 2GB की मात्रा तक पहुंच गया, तो यह बस गिर गया। हां, हम अभी भी 32-बिट मोड में काम कर रहे थे;
- B + ट्री कार्यान्वयन ने काफी काम किया, लेकिन कुछ गिगाबाइट्स से अधिक की मात्रा के साथ, खोज की गति में काफी गिरावट आई।
हमें यह स्वीकार करना होगा कि हमें इसे अपने कार्य में समायोजित करने का कोई तरीका कभी नहीं मिला। शायद समस्या नेट-बाइंडिंग में है, जिसे अभी भी समाप्त होना था। मुख्य रूप से भरने से पहले BDB कार्यान्वयन अंततः मध्यवर्ती सूचकांक के रूप में SQL के लिए एक प्रतिस्थापन के रूप में उपयोग किया गया था।
समय बीतता गया। 2014 में, उन्होंने LMDB और LevelDB की कोशिश की, लेकिन इसे लागू नहीं किया। हमारे एंटी- प्लाजिरिज्म रिसर्च डिपार्टमेंट के लोगों ने RocksDB को अपने सूचकांक के रूप में इस्तेमाल किया। पहली नज़र में, यह एक खोज थी। लेकिन धीमी गति से पुनःपूर्ति और औसत दर्जे की खोज की गति ने भी छोटे स्तर पर सब कुछ शून्य कर दिया।
हमने अपने स्वयं के कस्टम इंडेक्स को विकसित करते हुए उपरोक्त सभी किया। नतीजतन, वह हमारी समस्याओं को हल करने में इतना अच्छा हो गया कि हमने पिछले "प्लग" को छोड़ दिया और इसे सुधारने पर ध्यान केंद्रित किया, जिसे अब हम हर जगह उत्पादन में उपयोग करते हैं।
सूचकांक परतों
अंत में, अब हमारे पास क्या है? वास्तव में, दाद के सूचकांक में कई परतें (सरणियां) होती हैं, जिसमें निरंतर लंबाई के तत्व होते हैं - 0 से 128 बिट्स तक - जो न केवल परत पर निर्भर करता है और जरूरी नहीं कि यह आठ से अधिक हो।
प्रत्येक परत एक भूमिका निभाती है। कुछ खोज को तेज करते हैं, कुछ को बचाते हैं, और कुछ का कभी उपयोग नहीं किया जाता है, लेकिन वास्तव में जरूरत है। हम खोज में उनकी कुल दक्षता बढ़ाने के लिए उनका वर्णन करने का प्रयास करेंगे।

चित्र स्रोत: विकिपीडिया
1. सूचकांक सरणी
व्यापकता के नुकसान के बिना, अब हम इस बात पर विचार करेंगे कि एक एकल दस्ता दस्तावेज को सौंपा जाए,
(docId → शिंगल)
हम जोड़ी के तत्वों को स्वैप करेंगे (उल्टा, क्योंकि सूचकांक वास्तव में "उलटा" है!)।
(शिंगल → docId)
दाद के मूल्यों द्वारा क्रमबद्ध करें और एक परत बनाएं। क्योंकि दाद के आकार और दस्तावेज़ के पहचानकर्ता स्थिर हैं, अब कोई भी जो द्विआधारी खोज को समझता है वह फ़ाइल के ओ (लॉगन) रीडिंग से परे एक जोड़ी पा सकता है। क्या खूब, एक बहुत का नर्क। लेकिन यह सिर्फ O (n) से बेहतर है।
यदि दस्तावेज़ में कई दाद हैं, तो दस्तावेज़ से कई ऐसे जोड़े होंगे। यदि एक ही शिंगल के साथ कई दस्तावेज़ हैं, तो यह भी बहुत नहीं बदलेगा - एक ही शिंगल के साथ एक पंक्ति में कई जोड़े होंगे। इन दोनों मामलों में, खोज तुलनीय समय के लिए जाएगा।
2. समूहों की सरणी
हम किसी भी सुविधाजनक तरीके से समूहों में पिछले चरण से सूचकांक के तत्वों को ध्यान से विभाजित करते हैं। उदाहरण के लिए, ताकि वे क्लस्टर सेक्टर में फिट हो जाएं , आवंटन इकाई ब्लॉक (पढ़ें, 4096 बाइट्स), बिट्स और अन्य चाल की संख्या को ध्यान में रखते हुए, एक प्रभावी शब्दकोश बनाएंगे। हमें ऐसे समूहों के पदों की एक सरल सारणी मिलती है:
group_map (हैश (शिंगल)) -> group_position।
एक शिंगल की खोज करते समय, अब हम पहले इस शब्दकोश में समूह की स्थिति की खोज करेंगे, और फिर समूह को अनलोड करें और सीधे मेमोरी में खोजें। पूरे ऑपरेशन में दो रीड की आवश्यकता होती है।
समूह के पदों का शब्दकोश सूचकांक की तुलना में परिमाण की कम जगह के कई आदेश लेता है, इसे अक्सर केवल मेमोरी में अनलोड किया जा सकता है। इस प्रकार, दो रीडिंग नहीं होंगे, लेकिन एक। कुल, O (1) ।
3. ब्लूम फ़िल्टर
साक्षात्कार में, उम्मीदवार अक्सर O (n ^ 2) या O (2 ^ n) के साथ अद्वितीय समाधान जारी करके समस्याओं का समाधान करते हैं। लेकिन हम बेवकूफाना बातें नहीं करते हैं। क्या दुनिया में O (0) है, यह सवाल है? एक परिणाम के लिए बहुत आशा के बिना प्रयास करते हैं ...
आइए विषय क्षेत्र की ओर रुख करें। यदि छात्र अच्छी तरह से काम कर रहा है और उसने स्वयं काम लिखा है, या बस पाठ नहीं है, लेकिन बकवास है, तो उसके दाद का एक महत्वपूर्ण हिस्सा अद्वितीय होगा और सूचकांक में नहीं मिलेगा। ब्लूम फिल्टर के रूप में इस तरह के एक डेटा संरचना दुनिया में अच्छी तरह से जाना जाता है। खोज करने से पहले, उस पर दाद की जाँच करें। यदि सूचकांक में कोई शिंगल नहीं है, तो आप आगे नहीं देख सकते हैं, अन्यथा आगे बढ़ें।
ब्लूम फ़िल्टर अपने आप में काफी सरल है, लेकिन यह हमारे संस्करणों के साथ हैश वेक्टर का उपयोग करने के लिए कोई मतलब नहीं है। यह ब्लूम फ़िल्टर से एक: +1 पढ़ने के लिए उपयोग करने के लिए पर्याप्त है। यह बाद के चरणों से -1 या -2 रीडिंग देता है, मामले में शिंगल अद्वितीय है, और फ़िल्टर में कोई गलत सकारात्मक नहीं था। अपने हाथ देखो!
ब्लूम फ़िल्टर त्रुटि की संभावना निर्माण के दौरान निर्धारित की जाती है; एक अज्ञात दाद की संभावना छात्र की ईमानदारी से निर्धारित होती है। सरल गणना निम्नलिखित निर्भरता के लिए आ सकती है:
- यदि हम लोगों की ईमानदारी पर भरोसा करते हैं (यानी, वास्तव में दस्तावेज़ मूल है), तो खोज की गति कम हो जाएगी;
- यदि दस्तावेज़ स्पष्ट रूप से सिले है, तो खोज की गति बढ़ जाएगी, लेकिन हमें स्मृति की बहुत आवश्यकता है।
छात्रों में विश्वास के साथ, हमारे पास "विश्वास, लेकिन सत्यापित" का सिद्धांत है, और अभ्यास से पता चलता है कि ब्लूम फ़िल्टर से अभी भी लाभ है।
यह देखते हुए कि यह डेटा संरचना इंडेक्स से भी छोटा है और इसे कैश किया जा सकता है, सबसे अच्छी स्थिति में यह आपको बिना किसी डिस्क एक्सेस के शिंगल को छोड़ने की अनुमति देता है।
4. भारी पूंछ
ऐसे दाद हैं जो लगभग हर जगह पाए जाते हैं। कुल संख्या में उनका हिस्सा डरावना है, लेकिन पहले चरण में सूचकांक का निर्माण करते समय, दूसरे में, दसियों के समूह और सैकड़ों एमबी आकार में प्राप्त किया जा सकता है। हम उन्हें अलग से याद रखेंगे और हम उन्हें खोज क्वेरी से तुरंत हटा देंगे।
जब यह तुच्छ कदम पहली बार 2011 में इस्तेमाल किया गया था, तो सूचकांक का आकार आधा हो गया था, और खोज स्वयं तेज हो गई थी।
5. अन्य पूंछ
फिर भी, एक शिंगल में कई दस्तावेज हो सकते हैं। और यह सामान्य है। दसियों, सैकड़ों, हजारों ... उन्हें मुख्य सूचकांक के अंदर रखना लाभहीन हो जाता है, वे या तो एक समूह में फिट नहीं हो सकते हैं, जहां से समूह के पदों के शब्दकोश का आयतन फुलाया जाता है। अधिक कुशल भंडारण के साथ उन्हें एक अलग क्रम में रखें। आंकड़ों के अनुसार, इस तरह का निर्णय उचित से अधिक है। इसके अलावा, विभिन्न बिटवाइज़ पैकेज डिस्क एक्सेस की संख्या को कम कर सकते हैं और सूचकांक की मात्रा को कम कर सकते हैं।
नतीजतन, रखरखाव में आसानी के लिए, हम इन सभी परतों को एक बड़ी फ़ाइल - चंक में प्रिंट करते हैं। इसमें दस ऐसी परतें हैं। लेकिन खोज में भाग का उपयोग नहीं किया जाता है, भाग बहुत छोटा है और हमेशा मेमोरी में संग्रहीत किया जाता है, भाग को सक्रिय रूप से आवश्यक / संभव के रूप में कैश किया जाता है।
लड़ाई में, अक्सर एक दाद के लिए खोज एक या दो यादृच्छिक फ़ाइल रीडिंग के लिए नीचे आती है। सबसे खराब स्थिति में, आपको तीन करना होगा। सभी परतें निरंतर लंबाई के तत्वों के प्रभावी ढंग से (कभी-कभी बिटवाइज़) पैक्ड सरणियाँ होती हैं। ऐसा सामान्यीकरण है। भंडारण के दौरान कुल मात्रा की कीमत और बेहतर कैश करने की क्षमता की तुलना में अनपैकिंग का समय नगण्य है।
निर्माण करते समय, परतों के आकार को मुख्य रूप से अग्रिम रूप से गणना की जाती है, क्रमिक रूप से लिखा जाता है, इसलिए यह प्रक्रिया काफी तेज है।
आप वहां कैसे पहुंचे, कहां नहीं पता
2010 , . , . , .

चित्र स्रोत: विकिपीडिया
प्रारंभ में, हमारे सूचकांक में दो भाग शामिल थे - एक निरंतर, जो ऊपर वर्णित है, और एक अस्थायी एक है, जिसकी भूमिका में SQL, या BDB, या इसका अपना अपडेट लॉग था। कभी-कभी, उदाहरण के लिए, महीने में एक बार (और कभी-कभी वर्ष), अस्थायी एक को छांटा जाता है, फ़िल्टर किया जाता है और मुख्य के साथ विलय किया जाता है। परिणाम एक एकजुट था, और दो पुराने को हटा दिया गया था। यदि अस्थायी रैम में फिट नहीं हो सकता है, तो प्रक्रिया बाहरी छंटाई से गुजरती है।
यह प्रक्रिया बल्कि परेशानी थी, यह अर्ध-मैनुअल मोड में शुरू हुई और वास्तव में स्क्रैच से पूरी इंडेक्स फाइल को फिर से लिखना आवश्यक था। लाखों दस्तावेजों के एक जोड़े के लिए सैकड़ों गीगाबाइट्स को फिर से लिखना - अच्छी तरह से, इतना आनंद, मैं आपको बताता हूं ...
अतीत की यादें ...SSD. , 31 SSD wcf- . , . , .
ताकि SSD विशेष रूप से तनावपूर्ण न हो, और सूचकांक को अधिक बार अद्यतन किया जाता है, 2012 में हमने कई टुकड़ों की एक श्रृंखला को शामिल किया, निम्नलिखित योजना के अनुसार चंक:

यहाँ सूचकांक में एक ही प्रकार की श्रृंखला होती है, पहले को छोड़कर। पहला, ऐडऑन, रैम में एक सूचकांक के साथ केवल एक परिशिष्ट था। बाद में विखंडन आकार में वृद्धि हुई (और उम्र) बहुत अंतिम (शून्य, मुख्य, मूल, ...) तक।
साइकिल चालकों को नोट ...कभी-कभी आपको कोड लिखने के नुकसान में नहीं होना चाहिए और यहां तक कि सोचना भी नहीं चाहिए, लेकिन बस इसे और अधिक अच्छी तरह से Google करें। संकेतन तक, आरेख 1996 के लेख
"लॉग-संरचित मर्ज-ट्री" के समान है ।
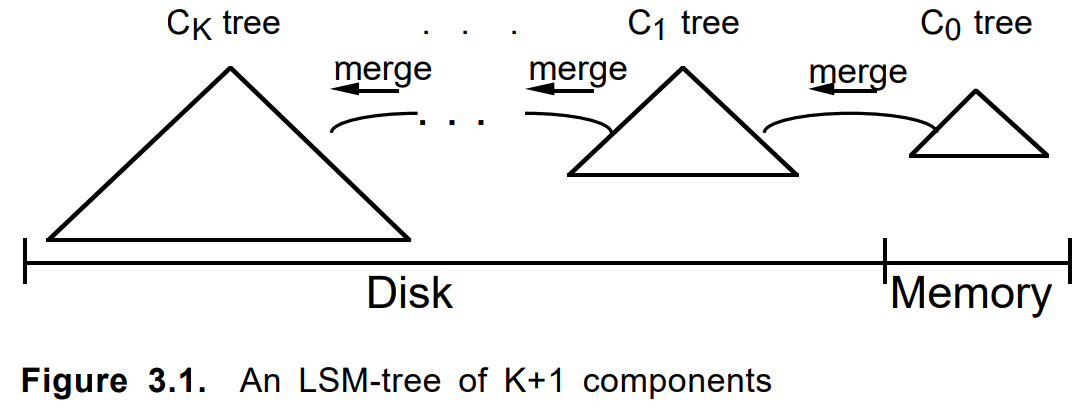
दस्तावेज़ जोड़ते समय, इसे पहले एक ऐडऑन में बदल दिया गया था। जब यह पूर्ण या अन्य मानदंडों से भरा था, तो उस पर एक स्थायी हिस्सा बनाया गया था। यदि आवश्यक हो, पड़ोसी कई हिस्सा एक नए में विलीन हो जाता है, और मूल हटा दिए गए थे। किसी दस्तावेज़ को अपडेट करना या उसे हटाना उसी तरह से काम करता है।
मर्ज मानदंड, श्रृंखला लंबाई, बायपास एल्गोरिदम, हटाए गए आइटम और अपडेट के लिए लेखांकन, अन्य मापदंडों को ट्यून किया गया था। दृष्टिकोण स्वयं कई समान कार्यों में शामिल था और एक स्वच्छ .net पर एक अलग आंतरिक एलएसएम ढांचे के रूप में आकार लिया। उसी समय के आसपास, LevelDB लोकप्रिय हो गया।
एलएसएम-वृक्ष के बारे में छोटी टिप्पणीएलएसएम-ट्री एक अच्छा रोचक एल्गोरिदम है, जिसमें अच्छा औचित्य है। लेकिन, IMHO, ट्री के अर्थ का कुछ धुंधला था। मूल
लेख में, यह शाखाओं को स्थानांतरित करने की क्षमता वाले पेड़ों की एक श्रृंखला के बारे में था। आधुनिक कार्यान्वयन में, यह हमेशा ऐसा नहीं होता है। इसलिए हमारे ढांचे को अंततः लस्माचिन का नाम दिया गया, यानी चूजों की श्रृंखला।
हमारे मामले में एलएसएम एल्गोरिथ्म में बहुत उपयुक्त विशेषताएं हैं:
- तत्काल डालें / हटाएं / अपडेट करें,
- अद्यतन करने के दौरान SSDs पर कम लोड,
- सरलीकृत विखंडू प्रारूप,
- केवल पुराने / नए विखंडू पर चयनात्मक खोज,
- तुच्छ बैकअप
- आत्मा और क्या चाहती है।
- ...
सामान्य तौर पर, आत्म-विकास के लिए साइकिल का आविष्कार करना कभी-कभी उपयोगी होता है।
मैक्रो, माइक्रो, नैनो ऑप्टिमाइज़ेशन
और अंत में, हम तकनीकी युक्तियों को साझा करेंगे कि कैसे हम एंटीप्लाजिज्म में इस तरह के काम करते हैं। नेट (और न केवल उस पर)।
अग्रिम में ध्यान दें कि अक्सर सब कुछ आपके विशिष्ट हार्डवेयर, डेटा या उपयोग मोड पर निर्भर करता है। एक स्थान पर मुड़ने के बाद, हम सीपीयू कैश से बाहर निकलते हैं, दूसरे में - हम एसएटीए इंटरफ़ेस के बैंडविड्थ में भागते हैं, तीसरे में - हम जीसी में लटकना शुरू करते हैं। और कहीं न कहीं एक विशिष्ट प्रणाली कॉल के कार्यान्वयन की अक्षमता है।

चित्र स्रोत: विकिपीडिया
फ़ाइल के साथ काम करें
फ़ाइल तक पहुंच की समस्या हमारे साथ अद्वितीय नहीं है। एक टेराबाइट एक्सैबाइट बड़ी फाइल है, जिसकी मात्रा रैम की मात्रा से कई गुना बड़ी है। कार्य कुछ छोटे यादृच्छिक मूल्यों के चारों ओर बिखरे हुए लाखों को पढ़ना है। और इसे जल्दी, कुशलतापूर्वक और सस्ते में करने के लिए। हमें निचोड़, बेंचमार्क और बहुत कुछ सोचना होगा।
चलो एक साधारण से शुरू करते हैं। जरूरत पड़ी बाइट को पढ़ने के लिए:
- खुली फाइल (नई फाइलस्ट्रीम);
- वांछित स्थिति में जाएं (स्थिति या शोध, कोई अंतर नहीं);
- वांछित बाइट सरणी पढ़ें (पढ़ें);
- फ़ाइल बंद करें (डिस्पोज़ करें)।
और यह बुरा है, क्योंकि यह लंबा और नीरस है। परीक्षण के माध्यम से, त्रुटि और रेक पर दोहराए जाने के बाद, हमने क्रियाओं के निम्नलिखित एल्गोरिदम की पहचान की:
सिंगल ओपन, मल्टीपल रीड
यदि यह क्रम माथे में, डिस्क के हर अनुरोध के लिए किया जाता है, तो हम जल्दी से झुकेंगे। इनमें से प्रत्येक आइटम ओएस कर्नेल के अनुरोध में जाता है, जो महंगा है।
जाहिर है, आपको फ़ाइल को एक बार खोलना चाहिए और क्रमिक रूप से हमारे सभी लाखों मूल्यों को पढ़ना चाहिए, जो हम करते हैं
कुछ भी अतिरिक्त नहीं
फ़ाइल का आकार प्राप्त करना, इसमें वर्तमान स्थिति भी काफी कठिन संचालन है। भले ही फाइल नहीं बदली।
किसी भी प्रश्न जैसे कि फ़ाइल का आकार या उसमें वर्तमान स्थिति प्राप्त करने से बचना चाहिए।
FileStreamPool
अगला। काश, FileStream अनिवार्य रूप से सिंगल-थ्रेडेड है। यदि आप किसी फ़ाइल को समानांतर में पढ़ना चाहते हैं, तो आपको नई फ़ाइल स्ट्रीम बनाना / बंद करना होगा।
जब तक आप aiosync जैसा कुछ बनाते हैं, तब तक आपको अपनी बाइक का आविष्कार करना होगा।
मेरी सलाह है कि प्रति फ़ाइल फ़ाइल धाराओं का एक पूल बनाएं। यह फ़ाइल खोलने / बंद करने में समय बर्बाद करने से बचाएगा। और यदि आप इसे थ्रेडपूल के साथ जोड़ते हैं और इस बात को ध्यान में रखते हैं कि एसएसडी अपने मेगाआईओएस को मजबूत मल्टीथ्रेडिंग के साथ जारी करता है ... ठीक है, आप मुझे समझते हैं।
आवंटन इकाई
अगला। स्टोरेज डिवाइस (HDD, SSD, Optane) और फाइल सिस्टम ब्लॉक स्तर (क्लस्टर, सेक्टर, एलोकेशन यूनिट) पर फाइलों के साथ काम करता है। वे मेल नहीं खा सकते हैं, लेकिन अब यह लगभग हमेशा 4096 बाइट्स है। एक एसएसडी में दो ऐसे ब्लॉक की सीमा पर एक या दो बाइट पढ़ना ब्लॉक के अंदर की तुलना में लगभग डेढ़ गुना धीमा है।
आपको अपना डेटा व्यवस्थित करना चाहिए ताकि घटाए गए तत्व क्लस्टर सेक्टर ब्लॉक की सीमाओं के भीतर हों।
कोई बफर नहीं।
अगला। डिफ़ॉल्ट रूप से FileStream 4096 बाइट बफर का उपयोग करता है। और बुरी खबर यह है कि आप इसे बंद नहीं कर सकते। हालांकि, यदि आप बफर के आकार से अधिक डेटा पढ़ रहे हैं, तो बाद वाले को अनदेखा किया जाएगा।
यादृच्छिक पढ़ने के लिए, आपको बफर को 1 बाइट पर सेट करना चाहिए (यह कम काम नहीं करेगा) और फिर विचार करें कि इसका उपयोग नहीं किया गया है।
बफर का उपयोग करें।
यादृच्छिक रीडिंग के अलावा, क्रमिक वाले भी हैं। यहां बफर पहले से ही उपयोगी हो सकता है यदि आप एक ही बार में सब कुछ नहीं पढ़ना चाहते हैं। मैं आपको इस लेख से शुरू करने की सलाह देता हूं। सेट करने के लिए बफर का आकार इस बात पर निर्भर करता है कि फाइल HDD पर है या SSD पर। पहले मामले में, 1MB इष्टतम होगा, दूसरे में, मानक 4kB पर्याप्त होगा। यदि पढ़ा जाने वाला डेटा क्षेत्र का आकार इन मूल्यों के साथ तुलनीय है, तो बफर को लंघन करते हुए, एक बार में इसे घटा देना बेहतर है, जैसा कि यादृच्छिक पढ़ने के मामले में है। बड़े बफ़र्स गति में लाभ नहीं लाएंगे, लेकिन जीसी पर हिट करना शुरू कर देंगे।
जब फ़ाइल के बड़े टुकड़ों को क्रमिक रूप से पढ़ा जाता है, तो आपको बफर को HDD के लिए 1MB और SSD के लिए 4kB पर सेट करना चाहिए। खैर, यह निर्भर करता है।
MMF बनाम फाइलस्ट्रीम
2011 में, MemoryMappedFile पर एक टिप आई, क्योंकि यह तंत्र .Net Framework v4.0 के बाद से लागू किया गया है। सबसे पहले, उन्होंने इसका उपयोग ब्लूम फ़िल्टर को कैशिंग करते समय किया, जो 4GB सीमा के कारण 32-बिट मोड में पहले से ही असुविधाजनक था। लेकिन 64 बिट्स की दुनिया में जाने पर, मैं और अधिक चाहता था। पहले परीक्षण प्रभावशाली थे। फ्री कैशिंग, फ्रीक स्पीड, सुविधाजनक स्ट्रक्चर रीडिंग इंटरफ़ेस। लेकिन समस्याएं थीं:
- सबसे पहले, अजीब तरह से पर्याप्त, गति। यदि डेटा पहले से ही कैश है, तो सब कुछ ठीक है। लेकिन यदि नहीं, तो फ़ाइल से एक बाइट को पढ़ने के साथ डेटा की एक बड़ी मात्रा के "लिफ्ट" के साथ एक नियमित रीडिंग के साथ होगा।
- दूसरी बात, अजीब तरह से पर्याप्त, स्मृति। गर्म होने पर, साझा की गई मेमोरी बढ़ती है, वर्किंगसेट - नहीं, जो तार्किक है। लेकिन फिर पड़ोसी प्रक्रियाएं बहुत अच्छा व्यवहार नहीं करने लगती हैं। वे स्वैप में जा सकते हैं, या गलती से ओओएम से गिर सकते हैं। RAM, alas में MMF द्वारा अधिग्रहित मात्रा को नियंत्रित नहीं किया जा सकता है। और मामले में कैश से लाभ जब पठनीय फ़ाइल स्मृति से बड़े परिमाण के आदेशों का एक जोड़ा है व्यर्थ हो जाता है।
दूसरी समस्या अभी भी लड़ी जा सकती है। यह गायब हो जाता है अगर सूचकांक docker में या एक समर्पित आभासी मशीन पर काम करता है। लेकिन गति की समस्या घातक थी।
नतीजतन, MMF को पूरी तरह से थोड़ा अधिक छोड़ दिया गया था। एंटी-प्लैरियरिज़्म में कैशिंग एक स्पष्ट रूप में किया जाना शुरू हो गया, यदि संभव हो तो स्मृति को ध्यान में रखते हुए दिए गए प्राथमिकताओं और सीमाओं पर सबसे अधिक बार उपयोग की जाने वाली परतें।

चित्र स्रोत: विकिपीडिया
बिट्स / बाइट्स
बाइट्स नहीं दुनिया एक है। कभी-कभी आपको बिट स्तर तक नीचे जाने की आवश्यकता होती है।
उदाहरण के लिए: मान लीजिए कि आपके पास एक ट्रिलियन आंशिक रूप से ऑर्डर किए गए नंबर हैं, जो अक्सर बचाने और पढ़ने के लिए उत्सुक हैं। इस सब के साथ कैसे काम करें?
- सरल द्विआधारी। - तेज लेकिन धीमी। आकार मायने रखता है। कोल्ड रीडिंग मुख्य रूप से फाइल के आकार पर निर्भर करती है।
- VarInt की एक और भिन्नता? - तेज लेकिन धीमी। संगति मायने रखती है। वॉल्यूम डेटा पर निर्भर होने लगता है, जिसके लिए पोजिशनिंग के लिए अतिरिक्त मेमोरी की आवश्यकता होती है।
- बिट पैकिंग? - तेज लेकिन धीमी। आपको अपने हाथों को अधिक सावधानी से नियंत्रित करना होगा।
कोई आदर्श समाधान नहीं है, लेकिन विशिष्ट मामले में, केवल 32 बिट्स से स्टोर करने के लिए 32 बिट्स से सीमा को संकुचित करना 12% अधिक (जीबी के दसियों!) की तुलना में VarInt (केवल पड़ोसी के अंतर को सहेजना), और वह कई बार है! मूल विकल्प।
एक और उदाहरण। आपके पास फ़ाइल में कुछ संख्याओं के लिए एक लिंक है। लिंक 64-बिट, प्रति टेराबाइट फ़ाइल। सब ठीक लगता है। कभी-कभी सरणी में कई संख्याएं होती हैं, कभी-कभी कुछ। अक्सर थोड़ा। बहुत बार। फिर बस लिंक में ही पूरे एरे को स्टोर करके रखें। लाभ। ध्यान से पैक करें लेकिन मत भूलना।
संरचना, असुरक्षित, बैचिंग, माइक्रो-ऑप्स
अच्छी तरह से और अन्य microoptimization। मैं यहाँ केला के बारे में नहीं लिखूंगा "क्या यह एक लूप में सरणी की लंबाई को बचाने के लायक है" या "जो तेज़ है, फॉरआर्क है"।
दो सरल नियम हैं, और हम उनका पालन करेंगे: 1. "बेंचमार्क सब कुछ", 2. "अधिक बेंचमार्क।"
संरचना । हर जगह उपयोग किया जाता है। जीसी जहाज मत करो। और, जैसा कि यह आज फैशनेबल है, हमारे पास अपना मेगा-फास्ट वैल्यूलिस्ट भी है।
असुरक्षित । मैपिट (और अनमैप) संरचनाओं का उपयोग करने पर बाइट्स की एक सरणी के लिए अनुमति देता है। इस प्रकार, हमें क्रमांकन के अलग-अलग साधनों की आवश्यकता नहीं है। सच है, ढेर को पिन करने और डीफ़्रैग्मेन्ट करने के सवाल हैं, लेकिन अभी तक यह नहीं दिखाया गया है। खैर, यह निर्भर करता है।
बैचने की क्रिया । कई तत्वों के साथ काम पैक / समूह / ब्लॉक के माध्यम से होना चाहिए। फ़ाइल पढ़ें / लिखें, कार्यों के बीच स्थानांतरण। एक अलग मुद्दा इन पैक्स का आकार है। आमतौर पर एक इष्टतम होता है, और इसका आकार अक्सर 1kB से 8MB (CPU कैश आकार, क्लस्टर आकार, पृष्ठ आकार, किसी और चीज़ का आकार) की सीमा में होता है। IEnumerable <बाइट> या IEnumerable <बाइट [1024]> फ़ंक्शन के माध्यम से पंप करने की कोशिश करें और अंतर महसूस करें।
पूलिंग । हर बार जब आप "नया" लिखते हैं, तो एक बिल्ली का बच्चा कहीं मर जाता है। एक बार नए बाइट [ 85000 ] - और ट्रैक्टर ने एक टन गीज़ की सवारी की। यदि स्टैकलॉक का उपयोग करना संभव नहीं है, तो किसी भी ऑब्जेक्ट का एक पूल बनाएं और इसे फिर से उपयोग करें।
आवक । कैसे एक के बजाय दो कार्यों को बनाने के लिए सब कुछ दस बार तेज कर सकते हैं? बस। फ़ंक्शन (विधि) के शरीर का आकार जितना छोटा होगा, उतनी ही अधिक इनलाइन होगी। दुर्भाग्य से, डॉटनेट दुनिया में अभी भी आंशिक इनलाइनिंग करने का कोई तरीका नहीं है, इसलिए यदि आपके पास एक गर्म कार्य है कि 99% मामलों में पहले कुछ लाइनों को संसाधित करने के बाद सामने आता है, और शेष सौ लाइनें शेष 1% को संसाधित करने के लिए जाती हैं, तो इसे सुरक्षित रूप से विभाजित करें दो (या तीन), भारी पूंछ को एक अलग फ़ंक्शन में ले जाना।
और क्या?
स्पैन <टी> , मेमोरी <टी> - होनहार। कोड सरल और शायद थोड़ा तेज होगा। हम .Net Core v3.0 और Std v2.1 के रिलीज़ होने की प्रतीक्षा कर रहे हैं, क्योंकि उन्हें स्विच करना है हमारा कर्नेल .Net Std v2.0 पर, जो आमतौर पर स्पैन का समर्थन नहीं करता है।
Async / इंतजार - अब तक विवादास्पद। सबसे सरल यादृच्छिक रीड बेंचमार्क ने दिखाया कि सीपीयू की खपत वास्तव में गिर रही है, लेकिन रीड की गति भी कम हो रही है। जरूर देखे हम अभी तक इंडेक्स के अंदर इसका उपयोग नहीं कर रहे हैं
निष्कर्ष
मुझे उम्मीद है कि मेरी निश्चिंतता आपको कुछ फैसलों की सुंदरता को समझने से खुशी मिलेगी। हम वास्तव में अपने सूचकांक को पसंद करते हैं। यह कुशल, सुंदर कोड है, शानदार काम करता है। सिस्टम के मूल में एक अत्यधिक विशिष्ट समाधान, इसके काम का महत्वपूर्ण स्थान, सामान्य से बेहतर है। हमारा संस्करण नियंत्रण प्रणाली कोड ++ कोड में कोडांतरक आवेषण को याद करता है। अब चार प्लस हैं - केवल शुद्ध सी #, केवल। नेट। इस पर हम सबसे जटिल खोज एल्गोरिदम लिखते हैं और इसे बिल्कुल भी पछतावा नहीं करते हैं। .नेट कोर के आगमन के साथ, डॉकर को संक्रमण, एक उज्ज्वल DevOps भविष्य का रास्ता आसान और स्पष्ट हो गया है। अहेड समाधान की प्रभावशीलता और सुंदरता को कम किए बिना गतिशील तेजकरण और प्रतिकृति की समस्या का समाधान है।
अंत तक पढ़ने वाले सभी को धन्यवाद। सभी विसंगतियों और अन्य विसंगतियों के लिए, कृपया टिप्पणियां लिखें। मुझे टिप्पणियों में किसी भी उचित सलाह और खंडन की खुशी होगी।