1999 से, हमारा बैंक बैक ऑफिस की सेवा के लिए प्रोग्रेस ओपनएडज प्लेटफॉर्म पर एकीकृत BISKVIT बैंकिंग प्रणाली का उपयोग कर रहा है, जिसका वित्तीय क्षेत्र सहित पूरी दुनिया में व्यापक रूप से उपयोग किया जाता है। इस DBMS का प्रदर्शन आपको एक डेटाबेस (DB) में प्रति सेकंड एक लाख या उससे अधिक रिकॉर्ड पढ़ने की अनुमति देता है। हमारी प्रगति OpenEdge व्यक्तियों के बारे में 1.5 मिलियन जमा करता है और सक्रिय उत्पादों (कार ऋण और बंधक) के लिए लगभग 22.2 मिलियन अनुबंध करता है, और नियामक (CB) और SWIFT के साथ सभी बस्तियों के लिए भी जिम्मेदार है।

प्रगति OpenEdge का उपयोग करते हुए, हमें इस तथ्य से सामना करना पड़ता है कि हमें Oracle DBMS के साथ दोस्त बनाने की आवश्यकता है। प्रारंभ में, यह बंडल हमारे इन्फ्रास्ट्रक्चर का "अड़चन" था - जब तक हमने Pro2 CDC को स्थापित और कॉन्फ़िगर नहीं किया - एक प्रगति उत्पाद जो आपको प्रोग्रेस DBMSs से Oracle डीबीएमएस को सीधे ऑनलाइन डेटा भेजने की अनुमति देता है। इस पोस्ट में, हम विस्तार से बताएंगे, सभी नुकसान के साथ, ओपनएडज और ओरेकल के साथ प्रभावी रूप से दोस्त कैसे बनाएं।
यह कैसा था: फाइल शेयरिंग के माध्यम से क्यूसीडी में डेटा अपलोड करना
सबसे पहले, हमारे बुनियादी ढांचे के बारे में कुछ तथ्य। डेटाबेस के सक्रिय उपयोगकर्ताओं की संख्या लगभग 15 हजार है। प्रतिकृति और स्टैंडबाय सहित सभी उत्पादक डेटाबेस की मात्रा 600 टीबी है, सबसे बड़ा डेटाबेस 16.5 टीबी है। इसी समय, डेटाबेस को लगातार दोहराया जाता है: अकेले पिछले वर्ष में, लगभग 120 टीबी उत्पादक डेटा जोड़ा गया है। सिस्टम x86 प्लेटफॉर्म पर 150 फ्रंट-एंड सर्वर प्रदान करता है। डेटाबेस 21 IBM प्लेटफ़ॉर्म सर्वर पर होस्ट किए गए हैं।
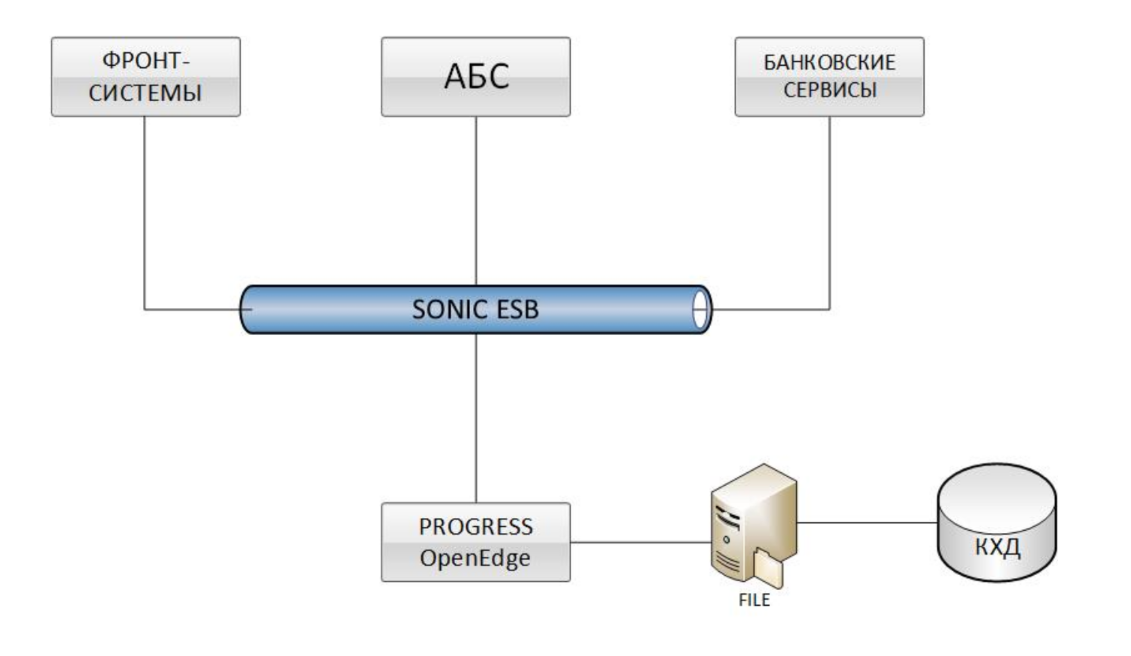
फ्रंट-सिस्टम, विभिन्न ABS और बैंकिंग सेवाएं सोनिक ESB बस के माध्यम से OpenEdge Progress (IBS BISQUIT) के साथ एकीकृत हैं। डेटा को फ़ाइल विनिमय के माध्यम से QCD में अपलोड किया जाता है। इस तरह के एक समाधान, समय में एक निश्चित बिंदु तक, तुरंत दो बड़ी समस्याएं थीं - कॉर्पोरेट डेटा वेयरहाउस (क्यूसीडी) पर जानकारी अपलोड करने का कम प्रदर्शन और अन्य प्रणालियों के साथ डेटा (सामंजस्य) में सामंजस्य स्थापित करने में लंबा समय लगता है।
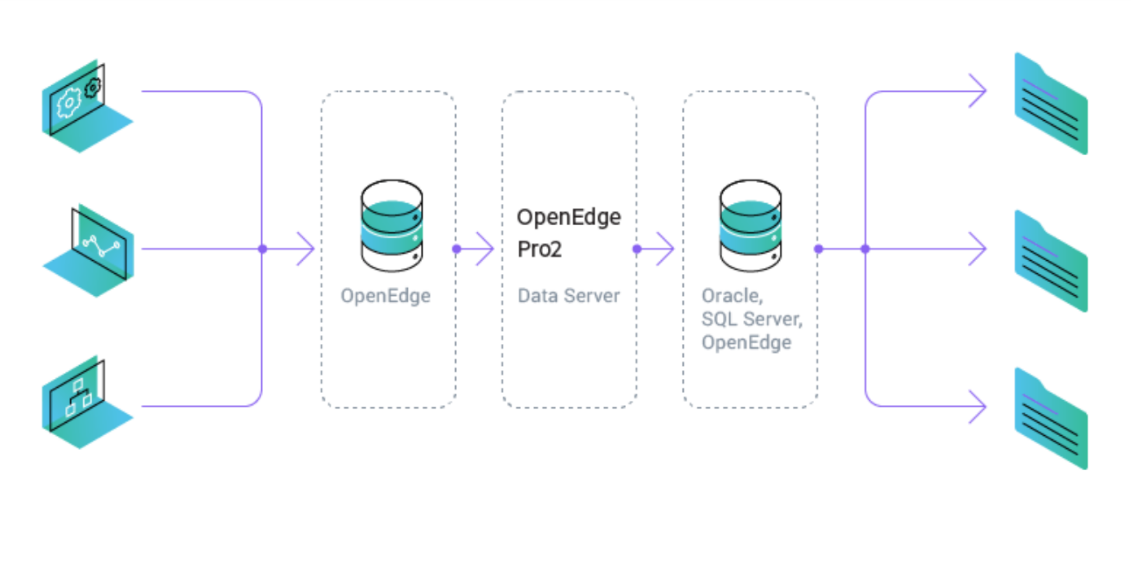
इसलिए, हमने एक ऐसे उपकरण की तलाश शुरू की जो इन प्रक्रियाओं को तेज कर सके। दोनों समस्याओं का समाधान नई प्रगति OpenEdge उत्पाद - Pro2 CDC (डेटा कैप्चर बदलें) था। तो चलिए शुरू करते हैं।
प्रगति OpenEdge और Pro2Oracle स्थापित करें
किसी व्यवस्थापक के Windows कंप्यूटर पर Pro2 Oracle चलाने के लिए, बस Progress OpenEdge Developer Kit Classroom Edition स्थापित करें, जिसे मुफ्त में
डाउनलोड किया जा सकता है। OpenEdge डिफ़ॉल्ट स्थापना निर्देशिकाएं:
DLC: C: \ Progress \ OpenEdge
WRK: C: \ OpenEdge \ WRKETL प्रक्रियाओं के लिए प्रगति OpenEdge संस्करण 11.7+ लाइसेंस की आवश्यकता होती है - अर्थात् Oracle और 4GL विकास प्रणाली के लिए OE DataServer। ये लाइसेंस Pro2 के साथ शामिल हैं। दूरस्थ Oracle डेटाबेस के साथ Oracle के लिए DataServer के पूर्ण संचालन के लिए, पूर्ण Oracle क्लाइंट स्थापित है।
ओरेकल सर्वर पर, आपको ओरेकल डेटाबेस 12+ के संस्करण को स्थापित करने, खाली डेटाबेस बनाने और उपयोगकर्ता को जोड़ने की आवश्यकता है (चलो इसे
ccc कॉल करें)।
Pro2Oracle स्थापित करने के लिए,
Progress Software डाउनलोड केंद्र से नवीनतम वितरण पैकेज डाउनलोड करें। संग्रह को
C: \ Pro2 निर्देशिका में अनपैक करें (समान वितरण किट का उपयोग Pro2 को Unix पर कॉन्फ़िगर करने के लिए किया जाता है और समान कॉन्फ़िगरेशन सिद्धांत लागू होते हैं)।
सीडीसी प्रतिकृति डेटाबेस बनाना
सीडी 2 ( प्रतिकृति
) प्रतिकृति डेटाबेस का उपयोग प्रो 2 द्वारा कॉन्फ़िगरेशन जानकारी को संग्रहीत करने के लिए किया जाता है, जिसमें प्रतिकृति मानचित्र, प्रतिकृति डेटाबेस के नाम और उनकी तालिकाएं शामिल हैं। इसमें एक प्रतिकृति कतार भी शामिल है जिसमें इस तथ्य के बारे में नोट्स होते हैं कि स्रोत डेटाबेस में तालिका पंक्ति बदल गई है। प्रतिकृति कतार से डेटा का उपयोग ईटीएल प्रक्रियाओं द्वारा उन पंक्तियों की पहचान करने के लिए किया जाता है जिन्हें स्रोत डेटाबेस से ओरेकल में कॉपी करने की आवश्यकता होती है।
एक अलग सीडीसी डेटाबेस बनाएँ।
डेटाबेस बनाने की प्रक्रिया- डेटाबेस सर्वर पर, सीडीसी डेटाबेस के लिए एक निर्देशिका बनाएं - उदाहरण के लिए, / डेटाबेस / सीडीसी / सर्वर पर।
- सीडीसी आधार के लिए एक डमी बनाएं: $ डीएलसी / खाली सीडीसी की घोषणा करें
- बड़ी फ़ाइल समर्थन सक्षम करें: proutil cdc -C EnableLargeFiles
- हम cdc डेटाबेस को शुरू करने के लिए स्क्रिप्ट तैयार करते हैं। प्रारंभ पैरामीटर प्रतिकृति डेटाबेस के प्रारंभ पैरामीटर के समान होना चाहिए।
- हम cdc डेटाबेस शुरू करते हैं।
- हम cdc डेटाबेस से कनेक्ट करते हैं और cdc.df फ़ाइल से Pro2 आरेख को लोड करते हैं, जो कि Pro2 पैकेज के साथ शामिल है।
- Cdc डेटाबेस में, निम्नलिखित उपयोगकर्ता बनाएँ:
pro2adm - Pro2 व्यवस्थापक पैनल से कनेक्ट करने के लिए;
pro2etl - ईटीएल प्रक्रियाओं को जोड़ने के लिए (प्रतिकृति);
pro2cdc - सीडीसी प्रक्रियाओं (सीडीसीबैच) को जोड़ने के लिए; OpenEdge Change Data Capture सक्रिय करना
अब चलो सीडीसी तंत्र को स्वयं चालू करें, जिसके माध्यम से डेटा को एक अतिरिक्त तकनीकी क्षेत्र में दोहराया जाएगा। प्रत्येक प्रगति OpenEdge स्रोत डेटाबेस में, आपको अलग-अलग संग्रहण क्षेत्रों को जोड़ने की आवश्यकता होती है, जिस पर स्रोत डेटा को डुप्लिकेट किया जाएगा, और
proutil कमांड का उपयोग करके स्वयं तंत्र को सक्रिय करें।
बिसक्विट डेटाबेस के लिए उदाहरण प्रक्रिया- Cdcadd.st फ़ाइल को C: \ Pro2 \ db निर्देशिका से bisquit स्रोत डेटाबेस निर्देशिका में कॉपी करें।
- हम cdcadd.st में वर्णित है कि रेप्लसीडीसीआरए और रेप्लसीडीसीआरए_आईडीएक्स क्षेत्रों के लिए सीमा विस्तार करते हैं । आप नए संग्रहण क्षेत्रों को ऑनलाइन जोड़ सकते हैं: प्रॉस्ट्रक्ट ऐडऑनलाइन बिस्किट cdcadd.st
- OpenEdge CDC सक्रिय करें:
proutil bisquit -C enablecdc क्षेत्र "ReplCDCArea" indexarea "ReplCDCArea__X"
- निम्नलिखित उपयोगकर्ताओं को रनिंग प्रक्रियाओं की पहचान करने के लिए स्रोत डेटाबेस में बनाया जाना चाहिए:
एक। Pro2adm - Pro2 व्यवस्थापक पैनल से कनेक्ट करने के लिए।
ख। pro2etl - ईटीएल प्रक्रियाओं (ReplBatch) को जोड़ने के लिए।
सी। pro2cdc - सीडीसी प्रक्रियाओं (सीडीसीबैच) को जोड़ने के लिए।
Oracle के लिए DataServer के लिए स्कीमा होल्डर बनाना
इसके बाद, हमें सर्वर पर डेटाबेस स्कीमा होल्डर बनाने की जरूरत है, जहां प्रोग्रेस DBMS से Oracle DBMS का डेटा दोहराया जाएगा। डेटासेवर स्कीमा होल्डर उपयोगकर्ताओं या एप्लिकेशन डेटा के बिना एक खाली प्रगति OpenEdge डेटाबेस है, जिसमें स्रोत तालिकाओं और बाहरी, Oracle तालिकाओं के बीच पत्राचार का मानचित्र है।
Pro2 के लिए Oracle के लिए प्रगति OpenEdge DataServer के लिए स्कीमा धारक डेटाबेस ETL प्रक्रिया सर्वर पर स्थित होना चाहिए; यह प्रत्येक शाखा के लिए अलग से बनाया गया है।
स्कीमा होल्डर कैसे बनाये- Pro2 वितरण को / pro2 निर्देशिका में अनपैक करें
- बनाएँ और / pro2 / dbsh निर्देशिका पर जाएँ
- Procopy $ DLC / खाली bisquitsh कमांड का उपयोग करके स्कीमा होल्डर डेटाबेस बनाएँ
- हम bisquitsh को आवश्यक एन्कोडिंग में परिवर्तित करते हैं - उदाहरण के लिए, UTF-8 में यदि Oracle डेटाबेस UTF-8 में एन्कोडेड हैं: proutil bisquitsh -C convchar Convert UTF-8
- खाली बिस्क्विंश डेटाबेस बनाने के बाद, हम इसे सिंगल-यूजर मोड में जोड़ते हैं : प्रो बिस्क्वितेश
- डेटा शब्दकोश पर जाएँ: उपकरण -> डेटा शब्दकोश -> डेटासेवर -> डेटा उपयोगिताएँ -> डेटा सर्वर बनाएँ
- स्कीम होल्डर लॉन्च करें
- Oracle डेटास्वर ब्रोकर कॉन्फ़िगर करें:
एक। व्यवस्थापक शुरू करें।
प्रदासव -स्टार्ट
ख। Oracle DataServer ब्रोकर की शुरुआत
oraman -name orabroker1 -start
व्यवस्थापक पैनल और प्रतिकृति योजना को कॉन्फ़िगर करें
Pro2 प्रशासनिक पैनल का उपयोग करते हुए, Pro2 सेटिंग्स को कॉन्फ़िगर किया जाता है, जिसमें प्रतिकृति योजना स्थापित करना और ETL प्रक्रिया कार्यक्रम (प्रोसेसर लाइब्रेरी), प्राथमिक सिंक्रोनाइज़ेशन प्रोग्राम (बल्क-कॉपी प्रोसेसर), प्रतिकृति ट्रिगर, और OpenEdge CDP नीतियाँ बनाना शामिल हैं। ईटीएल और सीडीसी प्रक्रियाओं की निगरानी और प्रबंधन के लिए प्राथमिक उपकरण भी हैं। सबसे पहले, हम पैरामीटर फ़ाइलों को कॉन्फ़िगर करते हैं।
पैरामीटर फाइलें कैसे सेट करें- निर्देशिका C: \ Pro2 \ bprepl \ Scripts पर जाएं
- संपादन के लिए replProc.pf फ़ाइल खोलें
- Cdc प्रतिकृति डेटाबेस से कनेक्ट करने के लिए पैरामीटर जोड़ें:
# प्रतिकृति डेटाबेस
-db cdc -ld उत्तर -H <मुख्य डेटाबेस का होस्ट नाम> -S <cdc डेटाबेस ब्रोकर का पोर्ट>
-U pro2admin -P <पासवर्ड>
- प्रतिकृति करने के लिए पैरामीटर फ़ाइलों के रूप में स्रोत डेटाबेस और स्कीमा होल्डर से जुड़ने के लिए पैरामीटर जोड़ें । पैरामीटर फ़ाइल का नाम कनेक्ट होने के लिए स्रोत डेटाबेस के नाम से मेल खाना चाहिए।
# सभी प्रतिकृति स्रोत BISQUIT से कनेक्ट करें
-pf bprepl \ script \ bisquit.pf
- स्कीमा धारक को replProc.pf में जोड़ने के लिए पैरामीटर जोड़ें।
# टारगेट प्रो डीबी स्कीमा होल्डर
-db बिस्क्वितेश-बल्ड बिस्किट्स
-H <ईटीएल प्रक्रियाओं का मेजबान नाम>
-S <बिस्कुट ब्रोकर पोर्ट>
-db bisquitsql
-बड़े बिस्किटक्कल
-dt ORACLE
-S 5162 -H <Oracle ब्रोकर होस्टनाम>
-डाटस सर्विस orabroker1
- ReplProc.pf पैरामीटर फ़ाइल सहेजें
- इसके बाद, आपको C: \ Pro2 \ bprepl \ Scripts: bisquit.pf निर्देशिका में प्रत्येक जुड़े स्रोत डेटाबेस के लिए पैरामीटर फ़ाइलों को संपादित करने के लिए बनाना और खोलना होगा। प्रत्येक pf- फ़ाइल में संबंधित डेटाबेस से कनेक्ट करने के लिए पैरामीटर हैं, उदाहरण के लिए:
-db bisquit -ld bisquit -H <hostname> -S <ब्रोकर पोर्ट>
-U pro2admin -P <पासवर्ड>
विंडोज शॉर्टकट को कॉन्फ़िगर करने के लिए,
C: \ Pro2 \ bprepl \ Scripts निर्देशिका पर जाएं और "Pro2 - व्यवस्थापन" शॉर्टकट संपादित करें। ऐसा करने के लिए, शॉर्टकट के गुणों को खोलें और लाइन में इंस्टॉलेशन डायरेक्टरी Pro2 इंगित करें। इसी तरह के ऑपरेशन को "Pro2 - Editor" और "RunBulkLoader" लेबल के लिए किया जाना चाहिए।
Pro2 प्रशासन कॉन्फ़िगर करना: प्राथमिक कॉन्फ़िगरेशन डाउनलोड करना
हम कंसोल को लॉन्च करते हैं।
"DB मानचित्र" पर जाएं।

Pro2 - प्रशासन में डेटाबेस को लिंक करने के लिए,
DB Map टैब पर जाएं। हम स्रोत डेटाबेस -
स्कीमा होल्डर - ओरेकल की मैपिंग जोड़ते हैं।
 मैपिंग
मैपिंग टैब पर जाएं।
स्रोत डेटाबेस सूची में, पहले जुड़ा स्रोत डेटाबेस डिफ़ॉल्ट रूप से चुना जाता है। सूची के दाईं ओर
सभी डेटाबेस कनेक्टेड होने चाहिए - चयनित डेटाबेस जुड़े हुए हैं। बिसक्विट से प्रगति तालिकाओं की एक सूची बाईं ओर नीचे दिखाई देनी चाहिए। दाईं ओर Oracle डेटाबेस से तालिकाओं की एक सूची है।
Oracle में SQL स्कीमा और डेटाबेस बनाना
प्रतिकृति मानचित्र बनाने के लिए, आपको पहले ओरेकल में
SQL स्कीमा उत्पन्न करना होगा। Pro2 प्रशासन में, मेनू आइटम
टूल्स -> जनरेट कोड -> लक्ष्य स्कीमा को निष्पादित करें, फिर
डेटाबेस संवाद बॉक्स में एक या अधिक स्रोत डेटाबेस का
चयन करें और उन्हें दाईं ओर स्थानांतरित करें।

ठीक क्लिक करें और SQL स्कीमा को बचाने के लिए निर्देशिका का चयन करें।
अगला, हम आधार बनाते हैं। यह किया जा सकता है, उदाहरण के लिए,
ओरेकल SQL डेवलपर के माध्यम से। ऐसा करने के लिए, ओरेकल डेटाबेस से कनेक्ट करें और तालिकाओं को जोड़ने के लिए योजना को लोड करें। Oracle तालिकाओं की संरचना को बदलने के बाद, आपको स्कीमा होल्डर में SQL स्कीमा को अपडेट करना होगा।

डाउनलोड सफलतापूर्वक पूरा होने के बाद, bisquitsh डेटाबेस से बाहर निकलें और Pro2 व्यवस्थापक पैनल खोलें। ओरेकल डेटाबेस से टेबल दाईं ओर मैपिंग टैब पर दिखाई देनी चाहिए।
मैपिंग टेबल
Pro2 व्यवस्थापक पैनल में प्रतिकृति मानचित्र बनाने के लिए, मैपिंग टैब पर जाएं, स्रोत डेटाबेस का चयन करें। हम मैप टेबल्स पर क्लिक करते हैं, बाईं ओर चुनिंदा परिवर्तन तालिकाओं का चयन करें जिन्हें ओरेकल को दोहराया जाना चाहिए, उन्हें दाईं ओर स्थानांतरित करें और चयन की पुष्टि करें। चयनित तालिकाओं के लिए एक मानचित्र स्वचालित रूप से बनाया जाएगा। अन्य स्रोत डेटाबेस के लिए प्रतिकृति मैप बनाने के लिए ऑपरेशन को दोहराएं।
प्रो 2 प्रतिकृति प्रोसेसर लाइब्रेरी और बल्क-कॉपी प्रोसेसर कार्यक्रमों की पीढ़ी
प्रोसेसर लाइब्रेरी को विशेष प्रतिकृति प्रक्रियाओं (ETL) के लिए डिज़ाइन किया गया है जो Pro2 प्रतिकृति कतार को संसाधित करता है और Oracle डेटाबेस में परिवर्तनों को आगे बढ़ाता है। पीढ़ी के बाद, प्रतिकृति प्रोसेसर लाइब्रेरी प्रोग्राम स्वचालित रूप से
bprepl / repl_proc निर्देशिका (पैरामीटर PROC_DIRCORY) में सहेजे जाते हैं। प्रतिकृति प्रोसेसर लाइब्रेरी उत्पन्न करने के लिए,
टूल्स -> जनरेट कोड -> प्रोसेसर लाइब्रेरी पर जाएं। जनरेशन पूरी होने के बाद, प्रोग्राम
bprepl / repl_proc डायरेक्टरी में दिखाई देंगे।
थोक प्रोसेसर प्रोग्राम्स का उपयोग सोर्स प्रोग्रेस डेटाबेस को लक्ष्य ऑरेकल डेटाबेस के साथ प्रोग्रेस एबीएल (4 जीएल) प्रोग्रामिंग लैंग्वेज पर आधारित करने के लिए किया जाता है। उन्हें उत्पन्न करने के लिए, मेनू आइटम
टूल -> जनरेट कोड -> बल्क-कॉपी प्रोसेसर पर जाएं । डेटाबेस का चयन करें संवाद बॉक्स में, स्रोत डेटाबेस का चयन करें, इसे विंडो के दाईं ओर स्थानांतरित करें और
ठीक पर क्लिक करें। पीढ़ी पूरी होने के बाद, प्रोग्राम
bprepl \ repl_mproc निर्देशिका में दिखाई देंगे।
Pro2 में प्रतिकृति प्रक्रियाओं को कॉन्फ़िगर करना
अलग प्रतिकृति थ्रेड द्वारा सेवित सेट में तालिकाओं को विभाजित करना ओरेकल प्रो 2 के प्रदर्शन और दक्षता में सुधार कर सकता है। डिफ़ॉल्ट रूप से, नए प्रतिकृति तालिकाओं के लिए प्रतिकृति नक्शे में बनाए गए सभी कनेक्शन स्ट्रीम नंबर 1 से बंधे होते हैं। यह अनुशंसा की जाती है कि तालिकाओं को अलग-अलग प्रवाह में विभाजित किया जाए।
प्रतिकृति प्रवाह की स्थिति के बारे में जानकारी प्रतिकृति स्थिति अनुभाग में मॉनिटर टैब में Pro2 प्रशासन स्क्रीन पर प्रदर्शित होती है। पैरामीटर मानों का विस्तृत विवरण Pro2 प्रलेखन (डायरेक्टरी C: \ Pro2 \ डॉक्स) में पाया जा सकता है।
सीडीसी नीतियों को बनाएँ और सक्रिय करें
नीतियां OpenEdge CDC तंत्र के नियमों का एक समूह हैं, जिसके अनुसार तालिकाओं में परिवर्तन ट्रैक किए जाते हैं। लेखन के समय, Pro2 केवल स्तर 0 के साथ CDC नीतियों का समर्थन करता है, अर्थात, केवल
रिकॉर्ड परिवर्तन के तथ्य को ट्रैक किया जाता है।
प्रशासनिक पैनल पर सीडीसी नीति बनाने के लिए, मैपिंग टैब पर जाएं, स्रोत डेटाबेस का चयन करें और जोड़ें / निकालें नीतियां बटन पर क्लिक करें। खुलने वाली चुनें विंडो में, बाईं ओर का चयन करें और दाईं तालिका में स्थानांतरित करें जिसके लिए आपको सीडीसी नीति बनाने या हटाने की आवश्यकता है।
सक्रिय करने के लिए, मैपिंग टैब को फिर से खोलें, स्रोत डेटाबेस चुनें और
(इन) सक्रिय करें बटन पर क्लिक करें। तालिका के दाईं ओर का चयन करें और स्थानांतरित करें जिनकी नीतियों को आपको सक्रिय करने की आवश्यकता है, ठीक पर क्लिक करें। उसके बाद उन्हें हरे रंग में चिह्नित किया जाता है।
(इन) सक्रिय नीतियों का उपयोग करके, आप सीडीसी नीतियों को भी निष्क्रिय कर सकते हैं। सभी ऑपरेशन ऑनलाइन किए जाते हैं।

सीडीसी नीति को सक्रिय करने के बाद, बदले हुए अभिलेखों के बारे में नोट मूल डेटाबेस के अनुसार
"रेप्लिकासीआरए" भंडारण क्षेत्र में सहेजे जाते हैं। इन नोटों को एक विशेष
सीडीसीबैच प्रक्रिया द्वारा संसाधित किया जाएगा, जो उनके आधार पर
सीडीसी (उत्तर) डेटाबेस में प्रो 2 प्रतिकृति कतार में नोट बनाएंगे।
इस प्रकार, हमारे पास प्रतिकृति के लिए दो कतारें हैं। पहला चरण सीडीसीबैच है: मूल डेटाबेस से, डेटा पहले मध्यवर्ती सीडीसी डेटाबेस में जाता है। दूसरा चरण है जब डेटा सीडीसी डेटाबेस से ओरेकल में डाला जाता है। यह वर्तमान वास्तुकला और स्वयं उत्पाद की एक विशेषता है - अब तक, डेवलपर्स प्रत्यक्ष प्रतिकृति स्थापित करने में सक्षम नहीं हुए हैं।
प्राथमिक सिंक
सीडीसी तंत्र को चालू करने और प्रो 2 प्रतिकृति सर्वर स्थापित करने के बाद, हमें प्राथमिक सिंक्रनाइज़ेशन शुरू करने की आवश्यकता है। प्राथमिक सिंक्रनाइज़ेशन प्रारंभ कमांड:
/pro2/bprepl/Script/replLoad.sh बिस्क्विट टेबल-नामप्रारंभिक सिंक्रनाइज़ेशन पूरा होने के बाद, प्रतिकृति प्रक्रियाएं शुरू की जा सकती हैं।
प्रतिकृति प्रक्रियाओं को प्रारंभ करें
प्रतिकृति प्रक्रियाओं को शुरू करने के लिए, आपको
replbatch.sh स्क्रिप्ट को चलाने की आवश्यकता है। शुरू करने से पहले, सुनिश्चित करें कि सभी थ्रेड्स के लिए रीप्लेबेक स्क्रिप्ट हैं - रिप्लेबैच 1, रेपबैच 2, आदि यदि सब कुछ जगह में है, तो कमांड लाइन खोलें (उदाहरण के लिए,
proenv) ,
/ bprepl / script निर्देशिका पर जाएं और स्क्रिप्ट शुरू करें। प्रशासनिक पैनल में, हम यह सत्यापित करते हैं कि संबंधित प्रक्रिया को RUNNING का दर्जा मिला है।

परिणाम
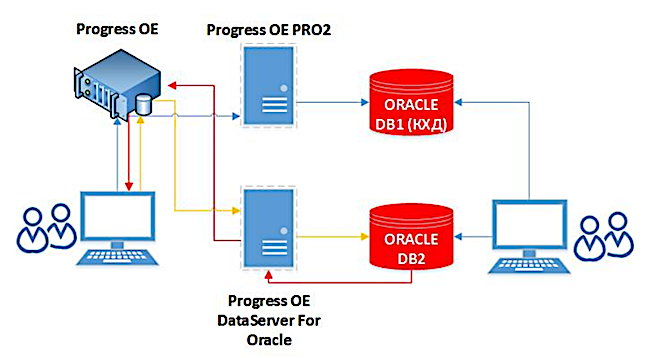
कार्यान्वयन के बाद, हमने कॉर्पोरेट डेटा वेयरहाउस में सूचना के अपलोड को बहुत तेज कर दिया है। डेटा खुद ओरेकल के पास जाता है। विभिन्न प्रणालियों से डेटा एकत्र करने के लिए कुछ लंबे समय तक चलने वाले प्रश्नों पर समय बिताने की आवश्यकता नहीं है। इसके अलावा, इस समाधान में, प्रतिकृति प्रक्रिया डेटा को संपीड़ित कर सकती है, जिसका गति पर भी सकारात्मक प्रभाव पड़ता है। अब, अन्य प्रणालियों के साथ BISKVIT प्रणाली के दैनिक सामंजस्य में 2-2.5 घंटे के बजाय 15-20 मिनट लगते हैं, और पूर्ण सामंजस्य - दो दिनों के बजाय कई घंटे।