
हमारी परियोजनाओं में हम माइक्रोसैस सर्विस का उपयोग करते हैं। यदि प्रदर्शन में अड़चनें आती हैं, तो लॉग्स की निगरानी और विश्लेषण पर बहुत समय खर्च किया जाता है। जब एक लॉग फ़ाइल में व्यक्तिगत संचालन के समय को लॉग करते हैं, तो आमतौर पर यह समझना मुश्किल होता है कि इन ऑपरेशनों के आह्वान का क्या कारण है, कार्यों के अनुक्रम को ट्रैक करने के लिए या अलग-अलग सेवाओं में एक ऑपरेशन के समय ऑफसेट के सापेक्ष।
मैनुअल श्रम को कम करने के लिए, हमने ट्रेसिंग टूल में से एक का उपयोग करने का निर्णय लिया। ट्रेसिंग का उपयोग कैसे और किसके लिए संभव है इसके बारे में और हमने इसे कैसे किया, और हम इस लेख पर चर्चा करेंगे।
ट्रेस के साथ क्या समस्याएं हल हो सकती हैं
- सभी भाग लेने वाली सेवाओं के बीच एक एकल सेवा के भीतर और संपूर्ण निष्पादन ट्री में प्रदर्शन अड़चनें खोजें। उदाहरण के लिए:
- सेवाओं के बीच कई कम लगातार कॉल, उदाहरण के लिए, जियोकोडिंग या एक डेटाबेस के लिए।
- उदाहरण के लिए, इनपुट इनपुट की प्रतीक्षा में, नेटवर्क पर डेटा स्थानांतरित करना या डिस्क से पढ़ना।
- लंबे डेटा पार्सिंग।
- लंबे संचालन की आवश्यकता सी.पी.यू.
- कोड के टुकड़े जिन्हें अंतिम परिणाम प्राप्त करने की आवश्यकता नहीं है और उन्हें हटा दिया जा सकता है या देरी से चलाया जा सकता है।
- स्पष्ट रूप से समझें कि ऑपरेशन किस क्रम में कहा जाता है और क्या होता है।
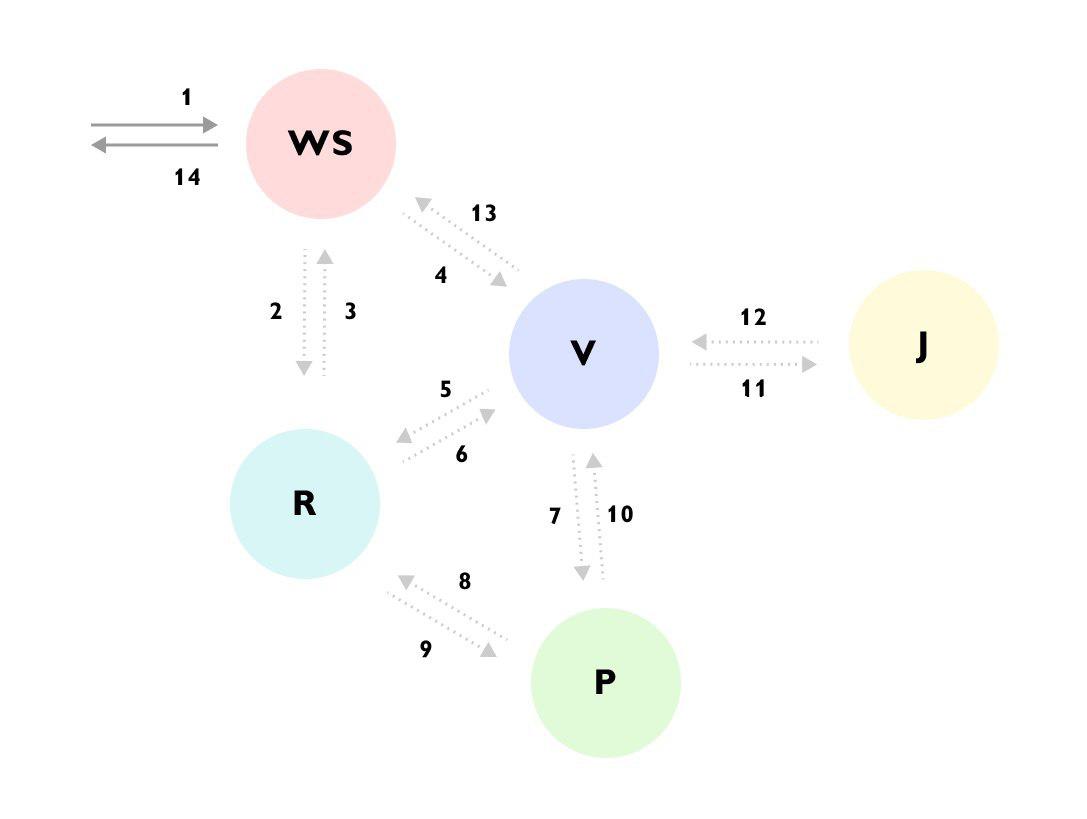
यह देखा जा सकता है कि, उदाहरण के लिए, अनुरोध WS सेवा में आया -> WS सेवा ने R सेवा के माध्यम से डेटा को पूरक किया -> फिर V सेवा में अनुरोध भेजा -> V सेवा ने R सेवा से बहुत अधिक डेटा लोड किया -> P सेवा में गया -> P सेवा फिर से बंद हो गई सेवा R -> सेवा V ने परिणाम को नजरअंदाज कर दिया और सेवा J -> पर गया और केवल तब ही WS सेवा को उत्तर दिया, जबकि पृष्ठभूमि में कुछ और गणना करना जारी रखा।
पूरी प्रक्रिया के लिए इस तरह के ट्रेस या विस्तृत दस्तावेज के बिना, यह समझना बहुत मुश्किल है कि पहली बार आप कोड को क्या देख रहे हैं, और कोड विभिन्न सेवाओं में बिखरा हुआ है और डिब्बे और इंटरफेस के एक गुच्छा के पीछे छिपा हुआ है।
- बाद में लंबित विश्लेषण के लिए निष्पादन पेड़ के बारे में जानकारी का संग्रह। निष्पादन के प्रत्येक चरण में, आप इस चरण में उपलब्ध ट्रेस में जानकारी जोड़ सकते हैं और फिर यह पता लगा सकते हैं कि इनपुट किस तरह के परिदृश्य को जन्म देता है। उदाहरण के लिए:
- उपयोगकर्ता आईडी
- अधिकार
- चयनित विधि का प्रकार
- लॉग या निष्पादन त्रुटि
- मैट्रिक्स के सबसेट में निशान को मोड़ें और मैट्रिक्स के रूप में आगे का विश्लेषण करें।
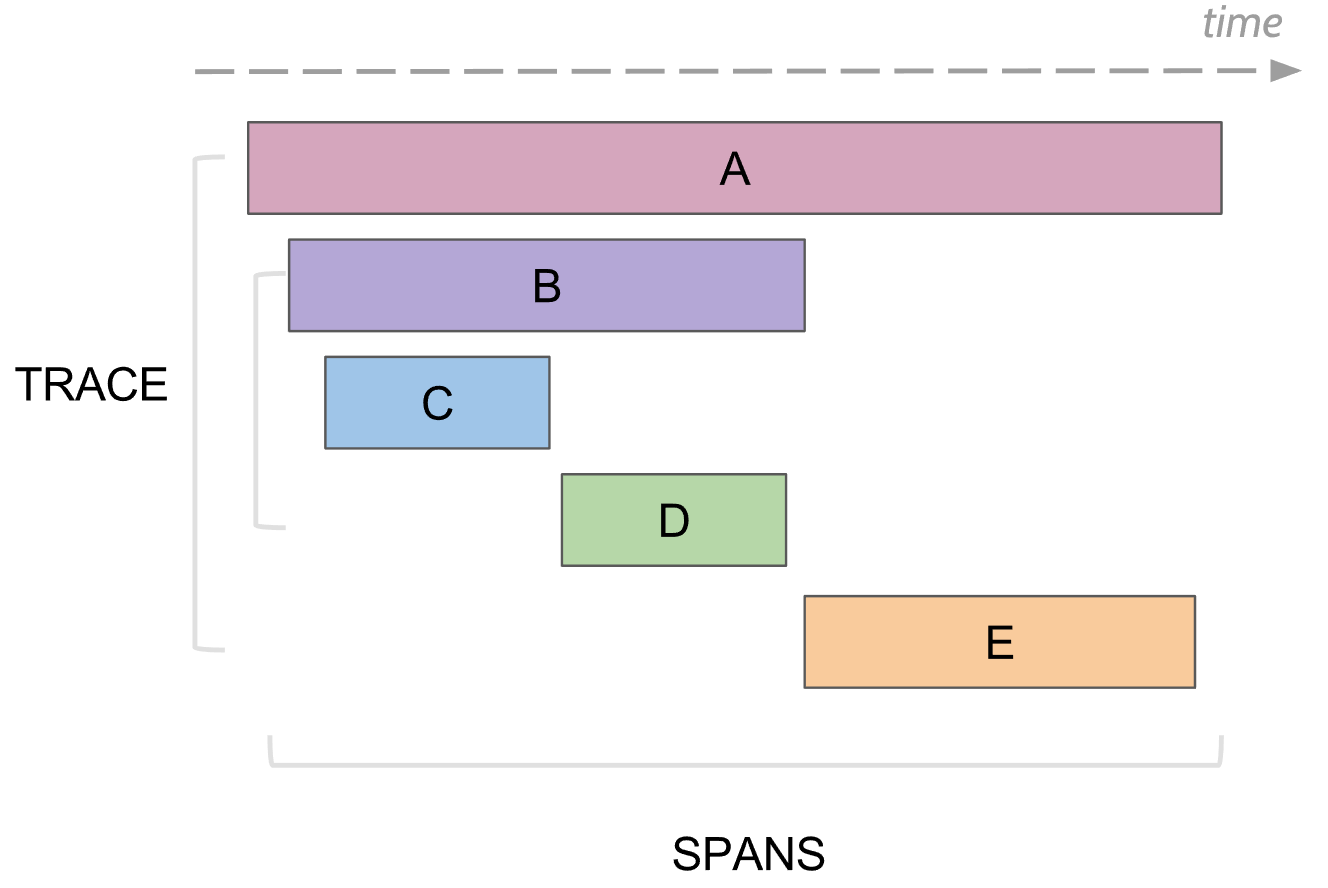
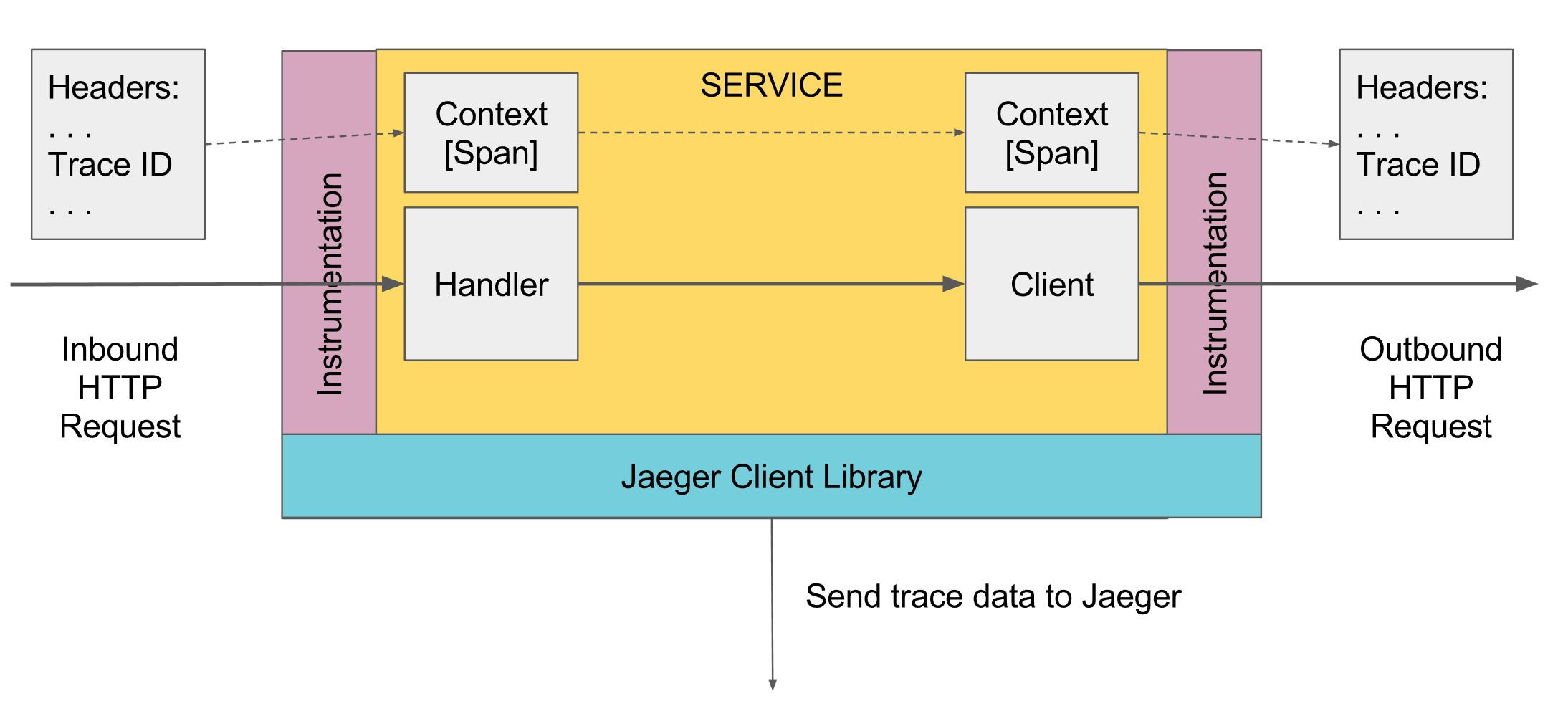
लॉगिंग क्या ट्रेस कर सकती है। स्पैन
ट्रेसिंग में, स्पैन की अवधारणा है, यह कंसोल में एक लॉग का एनालॉग है। अवधि है:
- नाम, आमतौर पर विधि का नाम जिसे निष्पादित किया गया था
- सेवा का नाम जिसमें स्पैन उत्पन्न हुआ था
- खुद की यूनिक आई.डी.
- कुंजी / मूल्य के रूप में कुछ मेटा जानकारी, जो इसे गिरवी रखी गई थी। उदाहरण के लिए, विधि पैरामीटर या विधि एक त्रुटि के साथ समाप्त हुई या नहीं
- इस अवधि का आरंभ और अंत समय
- जनक स्पंद आई.डी.
प्रत्येक स्पान को बाद में देखने के लिए डेटाबेस में सहेजने के लिए स्पान कलेक्टर को भेजा जाता है जैसे ही उसने अपना निष्पादन पूरा किया है। भविष्य में, आप मूल आईडी द्वारा कनेक्ट करके सभी स्पैन का एक पेड़ बना सकते हैं। विश्लेषण में, आप पा सकते हैं, उदाहरण के लिए, सभी किसी न किसी सेवा में कुछ समय से अधिक समय लगाते हैं। इसके अलावा, एक विशेष स्पैन में जाकर, इस स्पैन के ऊपर और नीचे पूरे पेड़ को देखें।
Opentracing, Jagger और हमने इसे अपनी परियोजनाओं के लिए कैसे लागू किया
एक सामान्य
Opentracing मानक है जो बताता है कि किसी भी भाषा में किसी विशिष्ट कार्यान्वयन के लिए कैसे और क्या इकट्ठा किया जाना चाहिए। उदाहरण के लिए, जावा में, सामान्य ओपेंटरिंग एपीआई के माध्यम से निशान के साथ सभी काम किए जाते हैं, और इसके तहत, उदाहरण के लिए, जेगर या एक खाली डिफ़ॉल्ट कार्यान्वयन जो कुछ भी नहीं छिपाया जा सकता है।
हम
Jaeger का उपयोग Opentracing के कार्यान्वयन के रूप में करते हैं। इसमें कई घटक होते हैं:
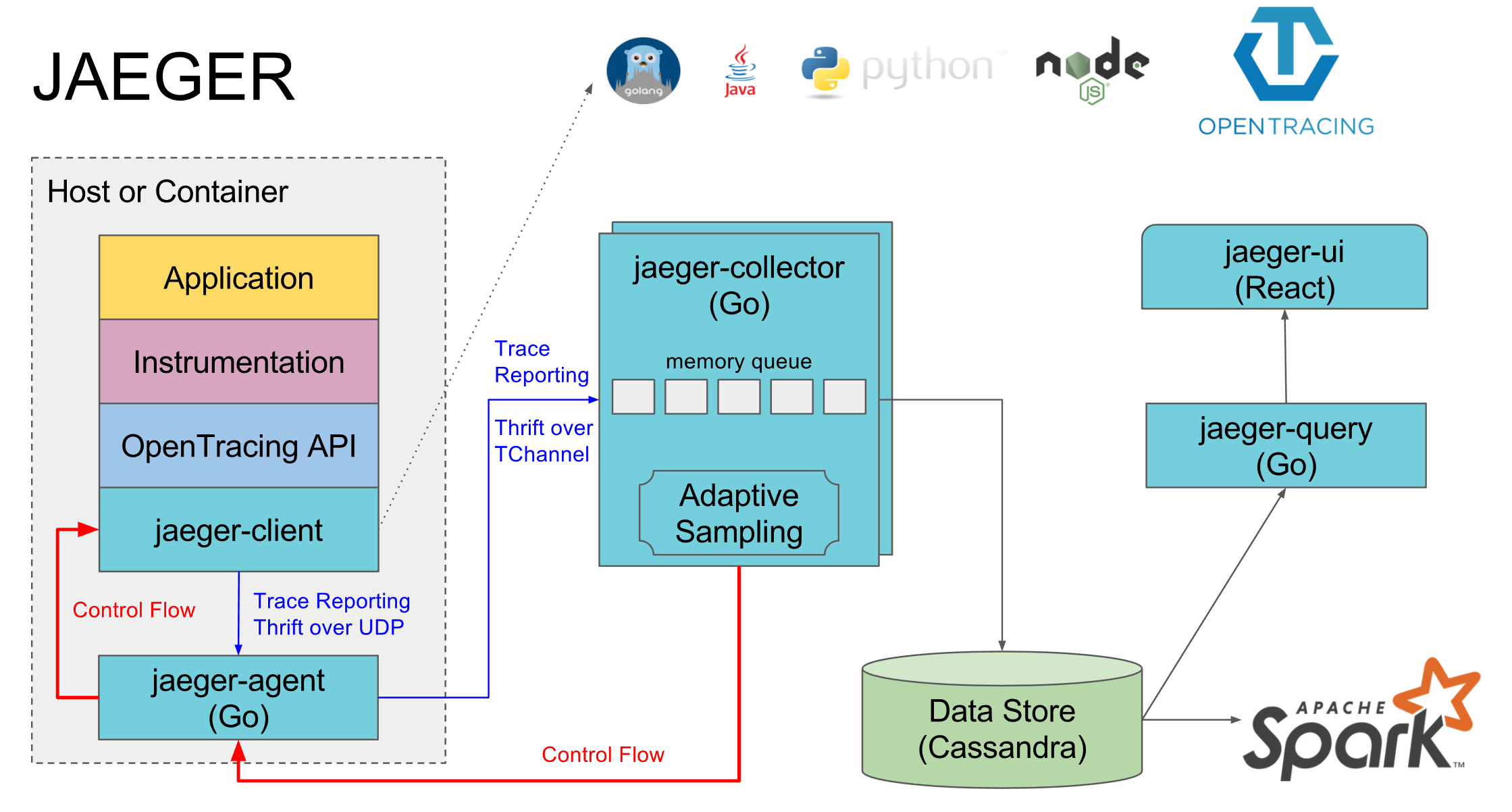
- जैगर-एजेंट एक स्थानीय एजेंट है जो आमतौर पर प्रत्येक मशीन पर खड़ा होता है और सेवाओं को स्थानीय डिफ़ॉल्ट पोर्ट पर लॉग इन किया जाता है। यदि कोई एजेंट नहीं है, तो इस मशीन पर सभी सेवाओं के निशान आमतौर पर बंद हो जाते हैं
- जैगर-कलेक्टर - सभी एजेंट इसके लिए एकत्रित निशान भेजते हैं, और वह उन्हें चयनित डेटाबेस में डालता है
- डेटाबेस उनका पसंदीदा कैसेंड्रा है, लेकिन हम इलास्टिक्स खोज का उपयोग करते हैं, कुछ अन्य डेटाबेस के लिए कार्यान्वयन हैं और एक कार्यान्वयन स्मृति में जो डिस्क को कुछ भी नहीं बचाता है
- जैगर-क्वेरी एक ऐसी सेवा है जो डेटाबेस में जाती है और विश्लेषण के लिए पहले से ही एकत्रित निशान देती है
- Jaeger-ui निशान खोजने और देखने के लिए एक वेब इंटरफ़ेस है, यह jaeger-query के लिए जाता है
एक अलग घटक विशिष्ट भाषाओं के लिए opentracing jaeger का कार्यान्वयन है, जिसके माध्यम से स्पैन jaeger- एजेंट को भेजे जाते हैं।
जावा में जैगर को जोड़ने से io.opentracing.Tracer इंटरफ़ेस का अनुकरण करने के लिए नीचे आता है, जिसके बाद इसके माध्यम से सभी निशान असली एजेंट के लिए उड़ जाएंगे।
आप
opentracing-spring-cloud-starter और Jaeger
opentracing-spring-jaeger-cloud-starter से एक कार्यान्वयन भी जोड़ सकते हैं जो इन घटकों से गुजरने वाली हर चीज के लिए स्वचालित रूप से ट्रेसिंग कॉन्फ़िगर करता है, उदाहरण के लिए, नियंत्रकों के लिए http अनुरोध, jdbc के माध्यम से डेटाबेस अनुरोध आदि
जावा में ट्रेसिंग लॉगिंग
कहीं बहुत उच्चतम स्तर पर, पहला स्पैन बनाया जाना चाहिए, यह स्वचालित रूप से किया जा सकता है, उदाहरण के लिए, वसंत नियंत्रक द्वारा जब एक अनुरोध प्राप्त होता है, या मैन्युअल रूप से यदि कोई नहीं है। आगे यह स्कोप के माध्यम से नीचे प्रसारित किया जाता है। यदि नीचे दी गई कोई विधि स्पैन को जोड़ना चाहती है, तो यह स्कोप से वर्तमान एक्टिवस्पैन लेता है, एक नया स्पैन बनाता है और कहता है कि उसके माता-पिता ने एक्टिवस्पैन प्राप्त किया है, और नए स्पैन को सक्रिय बनाता है। जब बाहरी सेवाओं को कॉल किया जाता है, तो वर्तमान सक्रिय अवधि उन्हें स्थानांतरित कर दी जाती है, और वे सेवाएं इस अवधि के संदर्भ में नए स्पैन बनाती हैं।
सभी कार्य ट्रेसर उदाहरण के माध्यम से जाते हैं, आप इसे डीआई तंत्र, या ग्लोबलट्रैसर.गेट () के माध्यम से वैश्विक चर के रूप में प्राप्त कर सकते हैं यदि डीआई तंत्र काम नहीं करता है। डिफ़ॉल्ट रूप से, यदि अनुरेखक को प्रारंभ नहीं किया गया था, तो NoopTracer वापस आ जाएगा जो कुछ भी नहीं करता है।
इसके अलावा, स्कोपमैनगर के माध्यम से ट्रैसर से वर्तमान स्कोप प्राप्त किया जाता है, नए स्कोप के बंधन के साथ एक नया स्कोप मौजूदा एक से बनाया जाता है, और फिर निर्मित स्कोप को बंद कर दिया जाता है, जो बनाए गए स्पैन को बंद कर देता है और पिछले स्कोप को सक्रिय स्थिति में लौटा देता है। स्कोप एक स्ट्रीम से जुड़ा हुआ है, इसलिए जब बहु-थ्रेडेड प्रोग्रामिंग, आपको इस स्पैन के संदर्भ में किसी अन्य स्ट्रीम के स्कोप के आगे सक्रियण के लिए सक्रिय स्पान को किसी अन्य स्ट्रीम में स्थानांतरित करना नहीं भूलना चाहिए।
io.opentracing.Tracer tracer = ...;
मल्टी-थ्रेडेड प्रोग्रामिंग के लिए, एक TracedExecutorService और इसी तरह के रैपर भी होते हैं जो एसिंक्रोनस रूप से कार्य शुरू करते समय धारा में वर्तमान अवधि को स्वचालित रूप से अग्रेषित करते हैं:
private ExecutorService executor = new TracedExecutorService( Executors.newFixedThreadPool(10), GlobalTracer.get() );
बाहरी http अनुरोधों के लिए,
TracingHttpClient है HttpClient httpClient = new TracingHttpClientBuilder().build();
हम जिन समस्याओं का सामना कर रहे हैं
- बीन्स और डीआई हमेशा काम नहीं करते हैं यदि किसी सेवा या घटक में ट्रेसर का उपयोग नहीं किया जाता है, तो Autowired Tracer काम नहीं कर सकता है और आपको GlobalTracer.get () का उपयोग करना होगा।
- यदि यह एक घटक या सेवा नहीं है, या यदि एक विधि कॉल एक ही वर्ग के पड़ोसी विधि से आती है, तो एनोटेशन काम नहीं करता है। आपको सावधान रहने की जरूरत है, जांच करें कि क्या काम करता है, और यदि ट्रेस काम नहीं करता है, तो ट्रेस के मैनुअल निर्माण का उपयोग करें। आप जावा एनोटेशन के लिए एक अतिरिक्त संकलक भी पेंच कर सकते हैं, फिर उन्हें हर जगह काम करना चाहिए।
- पुराने वसंत और वसंत के जूते में, ओपेंट्रिंग स्प्रिंग क्लाउड का ऑटो-कॉन्फ़िगरेशन डीआई में बग के कारण काम नहीं करता है, तो यदि आप स्वचालित रूप से काम करने के लिए वसंत घटकों में निशान चाहते हैं, तो आप इसे github.com/opentent-contrib/java-spring-jaeger/blob/ के साथ समानता से कर सकते हैं। मास्टर / opentracing-spring-jaeger-starter / src / main / java / io / opentracing / contrib / java / वसंत / jaeger / स्टार्टर / JaegerAutoConigiguration.java
- संसाधनों के साथ प्रयास करें ग्रूवी में काम नहीं करता है, आपको अंततः प्रयास का उपयोग करना चाहिए।
- प्रत्येक सेवा के पास अपना स्वयं का स्प्रिंग होना चाहिए। नामकरण जिसके तहत निशान को लॉग किया जाएगा। बिक्री और परीक्षण के लिए एक अलग नाम क्या है, ताकि उनके साथ एक साथ हस्तक्षेप न करें।
- यदि आप GlobalTracer और tomcat का उपयोग करते हैं, तो इस tomcat में चलने वाली सभी सेवाओं में एक GlobalTracer है, इसलिए इन सभी का एक ही सेवा नाम होगा।
- एक विधि में निशान जोड़ते समय, आपको यह सुनिश्चित करने की आवश्यकता होती है कि इसे कई बार लूप में नहीं कहा जाता है। सभी कॉल के लिए एक सामान्य ट्रेस जोड़ना आवश्यक है, जो काम के कुल समय की गारंटी देता है। अन्यथा, अतिरिक्त भार पैदा किया जाएगा।
- एक बार jaeger-ui में उन्होंने बड़ी संख्या में निशानों के लिए बहुत बड़े अनुरोध किए और चूंकि उन्होंने एक उत्तर की प्रतीक्षा नहीं की, इसलिए उन्होंने इसे फिर से किया। परिणामस्वरूप, jaeger-query ने बहुत सी मेमोरी खानी शुरू कर दी और लोचदार को धीमा कर दिया। मदद jaeger- क्वेरी को पुनरारंभ करें
नमूना, भंडारण और देखने के निशान
नमूने के तीन प्रकार के
नमूने हैं :
- कास्ट जो भेजता है और सभी निशान बचाता है।
- संभावित जो कुछ दिए गए संभावना के साथ निशान को छानता है।
- रैटलिमिटिंग जो प्रति सेकंड निशानों की संख्या को सीमित करता है। आप इन विकल्पों को क्लाइंट पर, jaeger- एजेंट पर या कलेक्टर में कॉन्फ़िगर कर सकते हैं। अब हमारे पास मूल्यांकनकर्ताओं के ढेर में const 1 है, क्योंकि बहुत अधिक अनुरोध नहीं हैं, लेकिन उन्हें एक लंबा समय लगता है। भविष्य में, यदि यह सिस्टम पर अत्यधिक भार डाल देगा, तो आप इसे सीमित कर सकते हैं।
यदि आप कैसेंड्रा का उपयोग करते हैं तो डिफ़ॉल्ट रूप से यह केवल दो दिनों में निशान संग्रहीत करता है। हम
elasticsearch का उपयोग करते हैं और निशान पूरे समय के लिए संग्रहीत किए जाते हैं और हटाए नहीं जाते हैं। प्रत्येक दिन के लिए एक अलग सूचकांक बनाया जाता है, उदाहरण के लिए, jaeger-service-2019-03-04। भविष्य में, आपको पुराने निशान की स्वचालित सफाई को कॉन्फ़िगर करने की आवश्यकता है।
आपके लिए आवश्यक पाठ्यक्रम देखने के लिए:
- ऐसी सेवा चुनें, जिसके द्वारा आप निशान को फ़िल्टर करना चाहते हैं, उदाहरण के लिए टमाटर पर चलने वाली सेवा के लिए tomcat7-default और जिसका नाम नहीं हो सकता है।
- अगला, ऑपरेशन का चयन करें, समय अंतराल और न्यूनतम ऑपरेशन समय, उदाहरण के लिए 10 सेकंड से, केवल लंबे रन लेने के लिए।
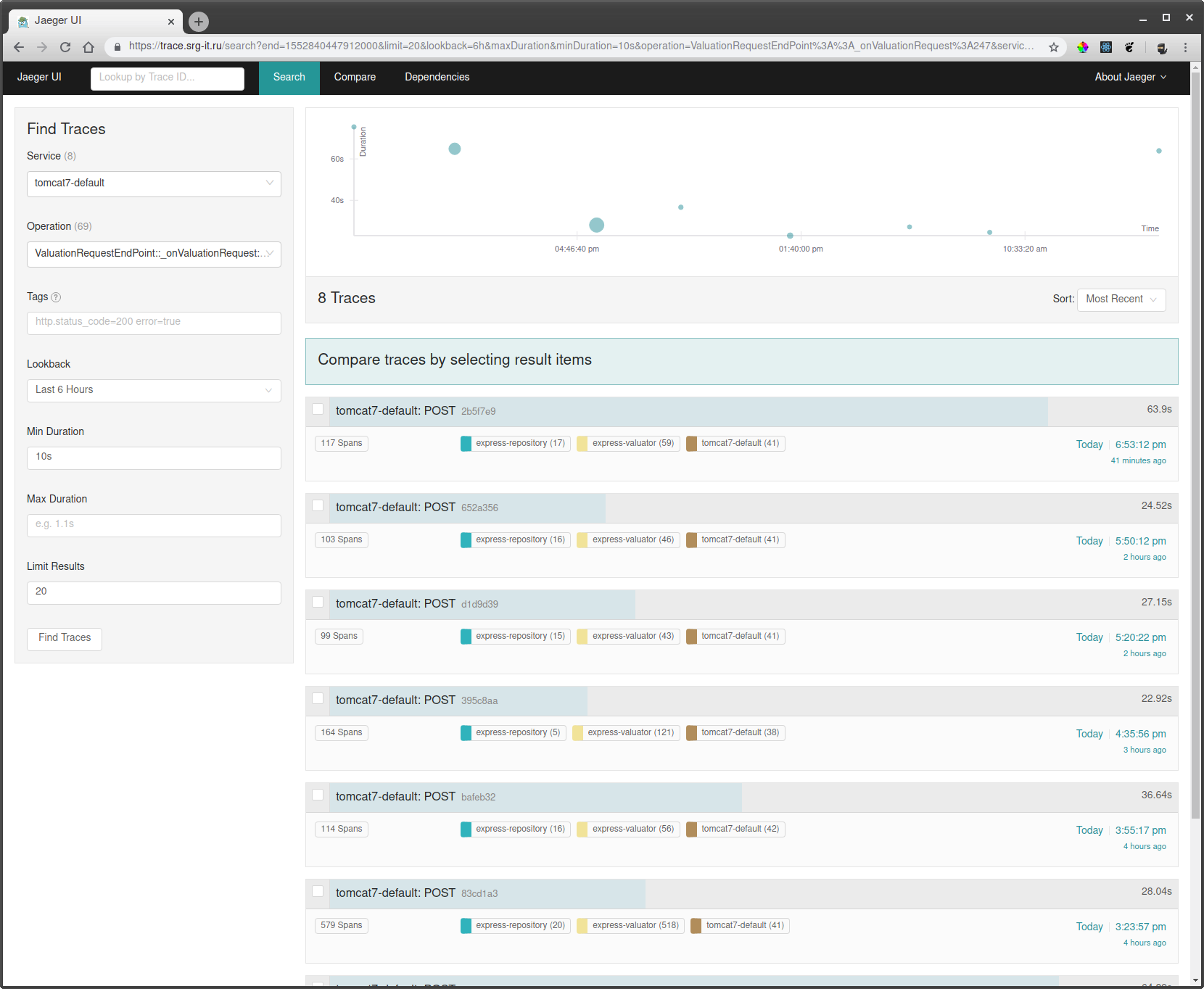
- पटरियों में से एक पर जाएं और देखें कि वहां क्या धीमा था।

साथ ही, यदि अनुरोध की कुछ आईडी ज्ञात है, तो आप इस आईडी द्वारा टैग खोज के माध्यम से एक ट्रेस पा सकते हैं, यदि यह आईडी ट्रेस के समय में लॉग इन है।
प्रलेखन
सामग्री
वीडियो