हाल ही में, एबीबीवाई मान्यता समूह में, हम विभिन्न कार्यों में तंत्रिका नेटवर्क का उपयोग कर रहे हैं। बहुत अच्छी तरह से वे खुद को मुख्य रूप से जटिल प्रकार के लेखन के लिए साबित कर चुके हैं। पिछले पोस्टों में, हमने जापानी, चीनी और कोरियाई लिपियों को पहचानने के लिए तंत्रिका नेटवर्क का उपयोग करने के तरीके के बारे में बात की।
 जापानी और चीनी पात्रों की मान्यता के बारे में पोस्ट करें कोरियाई चरित्र मान्यता पोस्ट
जापानी और चीनी पात्रों की मान्यता के बारे में पोस्ट करें कोरियाई चरित्र मान्यता पोस्टदोनों मामलों में, हमने एकल चिह्न के लिए वर्गीकरण पद्धति को पूरी तरह से बदलने के लिए तंत्रिका नेटवर्क का उपयोग किया। सभी दृष्टिकोणों में कई अलग-अलग नेटवर्क शामिल थे, और कुछ कार्यों में उन छवियों पर पर्याप्त रूप से काम करने की आवश्यकता शामिल थी जो प्रतीक नहीं हैं। इन स्थितियों में मॉडल को किसी तरह संकेत देना चाहिए कि हम एक प्रतीक नहीं हैं। आज हम सिर्फ इस बारे में बात करेंगे कि यह सिद्धांत में क्यों आवश्यक हो सकता है, और उन तरीकों के बारे में जो वांछित प्रभाव को प्राप्त करने के लिए उपयोग किए जा सकते हैं।
प्रेरणा
क्या समस्या है? छवियों पर काम क्यों करें जो अलग-अलग वर्ण नहीं हैं? ऐसा लगता है कि आप एक स्ट्रिंग के टुकड़े को वर्णों में विभाजित कर सकते हैं, उन सभी को वर्गीकृत कर सकते हैं और इस से परिणाम एकत्र कर सकते हैं, जैसे, उदाहरण के लिए, नीचे दी गई तस्वीर में।
हां, विशेष रूप से इस मामले में, यह वास्तव में किया जा सकता है। लेकिन, अफसोस, वास्तविक दुनिया बहुत अधिक जटिल है, और व्यवहार में, पहचानते समय, आपको ज्यामितीय विकृतियों, धब्बा, कॉफी के दाग और अन्य कठिनाइयों से निपटना पड़ता है।
नतीजतन, आपको अक्सर ऐसे टुकड़ों के साथ काम करना पड़ता है:
मुझे लगता है कि यह सभी के लिए स्पष्ट है कि समस्या क्या है। एक टुकड़े की ऐसी छवि के अनुसार, व्यक्तिगत रूप से पहचानने के लिए इसे स्पष्ट रूप से अलग-अलग प्रतीकों में विभाजित करना इतना सरल नहीं है। हमें इस बारे में परिकल्पना का एक सेट सामने रखना होगा कि पात्रों के बीच की सीमाएँ कहाँ हैं, और पात्र स्वयं कहाँ हैं। इसके लिए, हम तथाकथित रैखिक विभाजन ग्राफ (GLD) का उपयोग करते हैं। ऊपर की तस्वीर में, यह ग्राफ सबसे नीचे दिखाया गया है: हरे रंग के खंड निर्मित जीएलडी के आर्क्स हैं, यानी, जहां व्यक्तिगत प्रतीकों के बारे में परिकल्पनाएं हैं।
इस प्रकार, कुछ छवियां जिनके लिए व्यक्तिगत चरित्र पहचान मॉड्यूल लॉन्च किया गया है, वास्तव में, व्यक्तिगत वर्ण नहीं, बल्कि विभाजन त्रुटियां हैं। और इसी मॉड्यूल को संकेत देना चाहिए कि इसके सामने, सबसे अधिक संभावना है, एक प्रतीक नहीं है, सभी मान्यता विकल्पों के लिए कम आत्मविश्वास लौटाता है। और अगर ऐसा नहीं होता है, तो अंत में, प्रतीकों द्वारा इस टुकड़े को खंडित करने का गलत विकल्प चुना जा सकता है, जो रैखिक विभाजन त्रुटियों की संख्या में काफी वृद्धि करेगा।
विभाजन त्रुटियों के अलावा, मॉडल को पृष्ठ से प्राथमिकता वाले कचरे के लिए भी प्रतिरोधी होना चाहिए। उदाहरण के लिए, इस तरह की छवियों को किसी एकल वर्ण को पहचानने के लिए भी भेजा जा सकता है:
यदि आप केवल ऐसी छवियों को अलग-अलग वर्णों में वर्गीकृत करते हैं, तो वर्गीकरण परिणाम पहचान परिणामों में गिर जाएंगे। इसके अलावा, वास्तव में, ये छवियां केवल बिनाराइजेशन एल्गोरिदम की कलाकृतियां हैं, अंतिम परिणाम में उनके अनुरूप कुछ भी नहीं होना चाहिए। तो उनके लिए भी, आपको वर्गीकरण में कम आत्मविश्वास लौटाने में सक्षम होना चाहिए।
सभी समान छवियां: विभाजन त्रुटियां, एक प्राथमिकता कचरा, आदि। इसके बाद हम नकारात्मक उदाहरण कहलाएंगे। वास्तविक प्रतीकों की छवियों को सकारात्मक उदाहरण कहा जाएगा।
तंत्रिका नेटवर्क दृष्टिकोण की समस्या
अब याद करते हैं कि एक सामान्य तंत्रिका नेटवर्क व्यक्तिगत वर्णों को पहचानने के लिए कैसे काम करता है। आमतौर पर यह कुछ प्रकार की दृढ़ और पूरी तरह से जुड़ी हुई परतें होती हैं, जिनकी मदद से इनपुट छवि से प्रत्येक विशेष वर्ग से संबंधित संभावनाओं की वेक्टर बनती है।
इसके अलावा, वर्गों की संख्या वर्णमाला के आकार के साथ मेल खाती है। तंत्रिका नेटवर्क के प्रशिक्षण के दौरान, वास्तविक प्रतीकों की छवियों को परोसा जाता है और सही प्रतीक वर्ग के लिए एक उच्च संभावना वापस करने के लिए सिखाया जाता है।
और क्या होगा यदि एक तंत्रिका नेटवर्क को विभाजन त्रुटियों और एक प्राथमिक कचरा के साथ खिलाया जाता है? वास्तव में, विशुद्ध रूप से सैद्धांतिक रूप से, कुछ भी हो सकता है, क्योंकि नेटवर्क ने ऐसी छवियों को सीखने की प्रक्रिया में बिल्कुल नहीं देखा। कुछ छवियों के लिए, यह भाग्यशाली हो सकता है, और नेटवर्क सभी वर्गों के लिए कम संभावना लौटाएगा। लेकिन कुछ मामलों में, नेटवर्क एक निश्चित प्रतीक के परिचित रूपरेखा के लिए प्रवेश द्वार पर कचरे के बीच खोजना शुरू कर सकता है, उदाहरण के लिए, प्रतीक "ए" और इसे 0.99 की संभावना के साथ पहचानें।
व्यवहार में, जब हमने काम किया, उदाहरण के लिए, जापानी और चीनी लेखन के लिए एक तंत्रिका नेटवर्क मॉडल पर, नेटवर्क के आउटपुट से क्रूड प्रायिकता के उपयोग ने भारी संख्या में विभाजन त्रुटियों को प्रकट किया। और, इस तथ्य के बावजूद कि प्रतीकात्मक मॉडल ने छवियों के आधार पर बहुत अच्छा काम किया, इसे पूर्ण मान्यता एल्गोरिदम में एकीकृत करना संभव नहीं था।
कोई यह पूछ सकता है: आखिर तंत्रिका नेटवर्क के साथ ऐसी समस्या क्यों उत्पन्न होती है? विशेषता क्लासिफायर ने उसी तरह से काम क्यों नहीं किया, क्योंकि उन्होंने छवियों के आधार पर भी अध्ययन किया, जिसका अर्थ है कि सीखने की प्रक्रिया में कोई नकारात्मक उदाहरण नहीं थे?
मौलिक अंतर, मेरी राय में, यह है कि प्रतीक चित्रों से बिल्कुल कैसे अलग हैं। सामान्य क्लासिफायर के मामले में, एक व्यक्ति खुद को बताता है कि उन्हें कैसे निकालना है, अपने डिवाइस के कुछ ज्ञान द्वारा निर्देशित। एक तंत्रिका नेटवर्क के मामले में, फीचर निष्कर्षण भी मॉडल का एक प्रशिक्षित हिस्सा है: उन्हें कॉन्फ़िगर किया गया है ताकि विभिन्न वर्गों के पात्रों को अलग करना सबसे अच्छा हो। और व्यवहार में, यह पता चलता है कि किसी व्यक्ति द्वारा वर्णित विशेषताएं छवियों के प्रति अधिक प्रतिरोधी हैं जो प्रतीक नहीं हैं: वे वास्तविक प्रतीकों की छवियों के समान होने की संभावना कम हैं, जिसका अर्थ है कि कम आत्मविश्वास मूल्य उन्हें वापस किया जा सकता है।
सेंटर लॉस के साथ मॉडल स्थिरता को बढ़ाना
क्योंकि हमारे संदेह के अनुसार, समस्या यह थी कि तंत्रिका नेटवर्क कैसे संकेतों का चयन करता है, हमने इस विशेष भाग को बेहतर बनाने की कोशिश करने का फैसला किया, अर्थात्, कुछ "अच्छे" संकेतों को उजागर करना सीखना। गहरी शिक्षा में, इस विषय के लिए एक अलग खंड समर्पित है, और इसे "प्रतिनिधित्व सीखना" कहा जाता है। हमने इस क्षेत्र में विभिन्न सफल दृष्टिकोणों को आजमाने का फैसला किया। अधिकांश समाधान चेहरे की पहचान की समस्याओं में अभ्यावेदन के प्रशिक्षण के लिए प्रस्तावित किए गए थे।
लेख में वर्णित दृष्टिकोण "डी
फेस फेस रिकग्निशन के लिए एक भेदभावपूर्ण विशेषता सीखना दृष्टिकोण " काफी अच्छा लग रहा था। लेखकों का मुख्य विचार: नुकसान फ़ंक्शन के लिए एक अतिरिक्त शब्द जोड़ना, जो एक ही वर्ग के तत्वों के बीच सुविधा स्थान में यूक्लिडियन दूरी को कम करेगा।
सामान्य हानि फ़ंक्शन में इस शब्द के वजन के विभिन्न मूल्यों के लिए, कोई व्यक्ति विशेषता स्थानों में विभिन्न चित्र प्राप्त कर सकता है:
यह आंकड़ा एक दो-आयामी विशेषता स्थान में एक परीक्षण नमूने के तत्वों के वितरण को दर्शाता है। हस्तलिखित संख्याओं को वर्गीकृत करने की समस्या को माना जाता है (नमूना MNIST)।
एक महत्वपूर्ण गुण जो लेखकों द्वारा कहा गया था: प्रशिक्षण सेट में नहीं थे लोगों के लिए प्राप्त विशेषताओं की सामान्यीकरण क्षमता में वृद्धि। कुछ लोगों के चेहरे अभी भी पास में थे, और अलग-अलग लोगों के चेहरे दूर थे।
हमने यह जांचने का निर्णय लिया कि क्या चरित्र चयन के लिए समान संपत्ति संरक्षित है। उसी समय, उन्हें निम्नलिखित तर्क द्वारा निर्देशित किया गया था: यदि सुविधा स्थान में एक ही वर्ग के सभी तत्वों को एक बिंदु के पास कॉम्पैक्ट रूप से समूहीकृत किया जाता है, तो नकारात्मक उदाहरणों के लिए संकेत उसी बिंदु के पास स्थित होने की संभावना कम होगी। इसलिए, फ़िल्टरिंग के लिए मुख्य मानदंड के रूप में, हमने यूक्लिडियन दूरी का उपयोग एक विशेष वर्ग के सांख्यिकीय केंद्र के लिए किया।
परिकल्पना का परीक्षण करने के लिए, हमने निम्नलिखित प्रयोग किया: हमने मॉडल को जापानी वर्णों के एक छोटे उपसमूह को अक्षर अक्षर (तथाकथित काना) से पहचानने के लिए प्रशिक्षित किया। प्रशिक्षण नमूने के अलावा, हमने नकारात्मक उदाहरणों के 3 कृत्रिम आधारों की भी जांच की:
- जोड़े - यूरोपीय पात्रों के जोड़े का एक सेट
- कट्स - जापानी लाइनों के टुकड़े अंतराल में कटते हैं, वर्ण नहीं
- काना नहीं - जापानी वर्णमाला के अन्य वर्ण जो संबंधित उपसमुच्चय से संबंधित नहीं हैं
हम क्रॉस एंट्रॉपी लॉस फ़ंक्शन के साथ क्लासिक दृष्टिकोण की तुलना करना चाहते थे और नकारात्मक उदाहरणों को फ़िल्टर करने की उनकी क्षमता में सेंटर लॉस के साथ दृष्टिकोण। नकारात्मक उदाहरणों के लिए फ़िल्टरिंग मानदंड अलग थे। क्रॉस एंट्रॉपी लॉस के मामले में, हमने अंतिम परत से नेटवर्क प्रतिक्रिया का उपयोग किया, और सेंटर लॉस के मामले में, हमने यूक्लिडियन दूरी का उपयोग विशेषता अंतरिक्ष में कक्षा के सांख्यिकीय केंद्र के लिए किया। दोनों ही मामलों में, हमने इसी आँकड़ों की दहलीज को चुना, जिस पर परीक्षण नमूने से 3% से अधिक सकारात्मक उदाहरणों को समाप्त नहीं किया गया है और इस सीमा पर समाप्त होने वाले प्रत्येक डेटाबेस से नकारात्मक उदाहरणों के अनुपात को देखा गया है।
जैसा कि आप देख सकते हैं, सेंटर लॉस एप्रोच वास्तव में नकारात्मक उदाहरणों को छानने का बेहतर काम करता है। इसके अलावा, दोनों मामलों में, हमारे पास सीखने की प्रक्रिया में नकारात्मक उदाहरणों की छवियां नहीं थीं। यह वास्तव में बहुत अच्छा है, क्योंकि सामान्य मामले में, ओसीआर समस्या में सभी नकारात्मक उदाहरणों का प्रतिनिधि आधार प्राप्त करना आसान काम नहीं है।
हमने जापानी पात्रों (दो-स्तरीय मॉडल के दूसरे स्तर पर) को पहचानने की समस्या के लिए इस दृष्टिकोण को लागू किया, और परिणाम ने हमें प्रसन्न किया: रैखिक विभाजन त्रुटियों की संख्या में काफी कमी आई। यद्यपि गलतियाँ बनी रहीं, उन्हें पहले से ही विशिष्ट प्रकारों के द्वारा वर्गीकृत किया जा सकता है: क्या यह संख्याओं या चित्रलिपि के जोड़ों के साथ एक अटक पंक्चर प्रतीक है। इन त्रुटियों के लिए, पहले से ही नकारात्मक उदाहरणों के कुछ सिंथेटिक आधार बनाना और सीखने की प्रक्रिया में इसका उपयोग करना संभव था। यह कैसे किया जा सकता है, इसके बारे में और आगे चर्चा की जाएगी।
प्रशिक्षण में नकारात्मक उदाहरणों के आधार का उपयोग करना
यदि आपके पास नकारात्मक उदाहरणों के कुछ संग्रह हैं, तो यह सीखने की प्रक्रिया में इसका उपयोग न करना मूर्खता है। लेकिन आइए इस बारे में सोचें कि यह कैसे किया जा सकता है।
सबसे पहले, सबसे सरल योजना पर विचार करें: हम सभी नकारात्मक उदाहरणों को एक अलग वर्ग में वर्गीकृत करते हैं और इस वर्ग के अनुरूप आउटपुट परत में एक और न्यूरॉन जोड़ते हैं। अब आउटपुट पर हमारे पास
N + 1 वर्ग के लिए प्रायिकता वितरण है। और हम इसे सामान्य क्रॉस-एंट्रॉपी लॉस सिखाते हैं।
मानदंड जो कि उदाहरण नकारात्मक है, को संबंधित नए नेटवर्क प्रतिक्रिया का मूल्य माना जा सकता है। लेकिन कभी-कभी बहुत उच्च गुणवत्ता वाले वास्तविक पात्रों को नकारात्मक उदाहरणों के रूप में वर्गीकृत नहीं किया जा सकता है। क्या सकारात्मक और नकारात्मक उदाहरणों के बीच संक्रमण को सहज बनाना संभव है?
वास्तव में, आप आउटपुट की कुल संख्या में वृद्धि नहीं करने की कोशिश कर सकते हैं, लेकिन बस मॉडल बनाते हैं, जब सीखते हैं, तो इनपुट पर नकारात्मक उदाहरण लागू करते समय सभी वर्गों के लिए कम प्रतिक्रियाएं देते हैं। ऐसा करने के लिए, हम मॉडल में
एन + 1 आउटपुट को स्पष्ट रूप से नहीं जोड़ सकते हैं, लेकिन अन्य सभी वर्गों के लिए प्रतिक्रियाओं से
-max को
एन + 1 तत्व में जोड़ सकते हैं। फिर, इनपुट में नकारात्मक उदाहरण लागू करते समय, नेटवर्क जितना संभव हो उतना करने की कोशिश करेगा, जिसका अर्थ है कि अधिकतम प्रतिक्रिया जितना संभव हो उतना कम करने की कोशिश करेगी।
वास्तव में इस तरह की एक योजना हमने दूसरे स्तर पर केंद्र हानि दृष्टिकोण के साथ मिलकर जापानी के लिए दो-स्तरीय मॉडल के पहले स्तर पर लागू की थी। इस प्रकार, कुछ नकारात्मक उदाहरणों को पहले स्तर पर फ़िल्टर किया गया था, और कुछ को दूसरे स्तर पर। संयोजन में, हम पहले से ही एक समाधान प्राप्त करने में कामयाब रहे हैं जो सामान्य मान्यता एल्गोरिथ्म में एम्बेडेड होने के लिए तैयार है।
सामान्य तौर पर, कोई यह भी पूछ सकता है: सेंटर लॉस के दृष्टिकोण में नकारात्मक उदाहरणों के आधार का उपयोग कैसे करें? यह पता चला है कि किसी भी तरह हमें उन नकारात्मक उदाहरणों को बंद करने की आवश्यकता है जो विशेषता अंतरिक्ष में कक्षाओं के सांख्यिकीय केंद्रों के करीब स्थित हैं। इस तर्क को नुकसान फ़ंक्शन में कैसे डाला जाए?
चलो
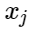
- नकारात्मक उदाहरणों के संकेत, और
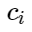
- कक्षाओं के केंद्र। फिर हम नुकसान के कार्य के लिए निम्नलिखित जोड़ पर विचार कर सकते हैं:
यहां
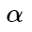
- केंद्र और नकारात्मक उदाहरणों के बीच एक निश्चित स्वीकार्य अंतर, जिसके अंदर नकारात्मक उदाहरणों पर जुर्माना लगाया जाता है।
ऊपर वर्णित योगात्मक के साथ सेंटर लॉस का संयोजन, हमने सफलतापूर्वक लागू किया है, उदाहरण के लिए, कोरियाई वर्णों को पहचानने के कार्य में कुछ व्यक्तिगत क्लासिफायर के लिए।
निष्कर्ष
सामान्य तौर पर, ऊपर वर्णित तथाकथित "नकारात्मक उदाहरण" को फ़िल्टर करने के सभी दृष्टिकोण किसी भी वर्गीकरण की समस्याओं में लागू किए जा सकते हैं जब आपके पास प्रतिनिधियों के अच्छे आधार के बिना बाकी के सापेक्ष कुछ अत्यधिक असंतुलित वर्ग होते हैं, जिसे फिर भी किसी भी तरह से दोबारा शामिल करने की आवश्यकता होती है। । OCR केवल कुछ विशेष कार्य है जिसमें यह समस्या सबसे तीव्र है।
स्वाभाविक रूप से, ये सभी समस्याएं केवल व्यक्तिगत पात्रों को पहचानने के लिए मुख्य मॉडल के रूप में तंत्रिका नेटवर्क का उपयोग करते समय उत्पन्न होती हैं। जब एक अलग मॉडल के रूप में एंड-टू-एंड लाइन मान्यता का उपयोग किया जाता है, तो ऐसी समस्या उत्पन्न नहीं होती है।
OCR न्यू टेक्नोलॉजीज ग्रुप