नमस्कार, हेब्र!
हम आपको याद दिलाते हैं कि
काफ्का पर पुस्तक के बाद हमने
काफ्का स्ट्रीम एपीआई पुस्तकालय पर एक समान रूप से दिलचस्प काम जारी किया।

अब तक, समुदाय केवल इस शक्तिशाली उपकरण की सीमाओं को समझ रहा है। इसलिए, हाल ही में एक लेख प्रकाशित हुआ है, जिसके अनुवाद के साथ हम आपका परिचय कराना चाहते हैं। अपने स्वयं के अनुभव पर, लेखक बताता है कि काफ्का धाराओं से वितरित डेटा वेयरहाउस कैसे बनाया जाए। अच्छा पढ़ लो!
अपाचे
काफ्का स्ट्रीम्स लाइब्रेरी का उपयोग अपाचे काफ्का के शीर्ष पर वितरित स्ट्रीमिंग प्रसंस्करण के लिए उद्यम में किया जाता है। इस ढांचे के कम से कम पहलुओं में से एक यह है कि यह आपको स्ट्रीमिंग प्रसंस्करण के आधार पर एक स्थानीय राज्य को स्टोर करने की अनुमति देता है।
इस लेख में, मैं आपको बताता हूँ कि कैसे हमारी कंपनी ने क्लाउड अनुप्रयोगों की सुरक्षा के लिए उत्पाद विकसित करने के इस अवसर का सफलतापूर्वक उपयोग किया है। काफ्का धाराओं का उपयोग करते हुए, हमने साझा-सेवा माइक्रोसर्विसेज का निर्माण किया, जिनमें से प्रत्येक सिस्टम में वस्तुओं की स्थिति के बारे में विश्वसनीय जानकारी के दोष-सहिष्णु और अत्यधिक सुलभ स्रोत के रूप में कार्य करता है। हमारे लिए, यह विश्वसनीयता और समर्थन में आसानी के मामले में एक कदम आगे है।
यदि आप एक वैकल्पिक दृष्टिकोण में रुचि रखते हैं जो आपको अपनी वस्तुओं की औपचारिक स्थिति का समर्थन करने के लिए एक एकल केंद्रीय डेटाबेस का उपयोग करने की अनुमति देता है - पढ़ें, यह दिलचस्प होगा ...
हमने सोचा कि यह साझा राज्य के साथ काम करने के लिए हमारे दृष्टिकोण को बदलने का समय हैहमें एजेंट रिपोर्टों के आधार पर विभिन्न वस्तुओं की स्थिति बनाए रखने की आवश्यकता थी (उदाहरण के लिए: क्या साइट पर हमला किया गया था)? काफ्का धाराओं पर स्विच करने से पहले, हम अक्सर अपने राज्य का प्रबंधन करने के लिए एक एकल केंद्रीय डेटाबेस (+ सेवा एपीआई) पर भरोसा करते थे। इस दृष्टिकोण की अपनी कमियां हैं:
डेटा-गहन स्थितियों में, स्थिरता और सिंक्रनाइज़ेशन के लिए समर्थन एक वास्तविक चुनौती में बदल जाता है। डेटाबेस एक अड़चन बन सकता है, या यह
एक दौड़ की स्थिति में हो सकता है और अप्रत्याशितता से पीड़ित हो सकता है।
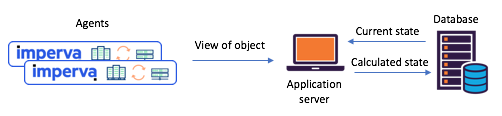 चित्र 1: संक्रमण से पहले एक विशिष्ट विभाजन-स्थिति का सामना करना पड़ा
चित्र 1: संक्रमण से पहले एक विशिष्ट विभाजन-स्थिति का सामना करना पड़ा
काफ्का और काफ्का धाराएँ: एजेंट एपीआई के माध्यम से अपनी प्रस्तुतियाँ संवाद करते हैं, अद्यतन स्थिति की गणना एक केंद्रीय डेटाबेस के माध्यम से की जाती हैकाफ्का धाराओं को पूरा करें - अब साझा राज्य माइक्रोसर्विसेज बनाना आसान हैलगभग एक साल पहले, हमने ऐसी समस्याओं से निपटने के लिए हमारे साझा राज्य परिदृश्यों की गहन समीक्षा करने का निर्णय लिया। तुरंत ही हमने काफ्का धाराओं की कोशिश करने का फैसला किया - हम जानते हैं कि यह कितना स्केलेबल, अत्यधिक सुलभ और दोष सहिष्णु है, इसकी स्ट्रीमिंग कार्यक्षमता कितनी समृद्ध है (स्टेटफुल सहित परिवर्तन)। बस हमें क्या चाहिए, यह उल्लेख करने के लिए नहीं कि काफ्का में संदेश प्रणाली कितनी परिपक्व और विश्वसनीय थी।
हमारे द्वारा बनाए गए प्रत्येक राज्य-संरक्षण वाले माइक्रोसर्विसेज को काफी सरल टोपोलॉजी के साथ काफ्का धाराओं के उदाहरण के आधार पर बनाया गया था। इसमें 1) एक स्रोत 2) एक प्रोसेसर है जिसमें कुंजी और मान 3 के स्थायी भंडारण के साथ 3) नाली:
 चित्र 2: स्टेटफुल माइक्रोसर्विसेज के लिए हमारे स्ट्रीमिंग इंस्टेंस की डिफ़ॉल्ट टोपोलॉजी। कृपया ध्यान दें कि एक भंडार भी है जिसमें नियोजन मेटाडेटा है।
चित्र 2: स्टेटफुल माइक्रोसर्विसेज के लिए हमारे स्ट्रीमिंग इंस्टेंस की डिफ़ॉल्ट टोपोलॉजी। कृपया ध्यान दें कि एक भंडार भी है जिसमें नियोजन मेटाडेटा है।इस नए दृष्टिकोण के साथ, एजेंट मूल विषय को दिए गए संदेशों की रचना करते हैं, और उपभोक्ता कहते हैं, एक मेल अधिसूचना सेवा - स्टॉक (आउटपुट विषय) के माध्यम से गणना की गई साझा स्थिति को स्वीकार करें।
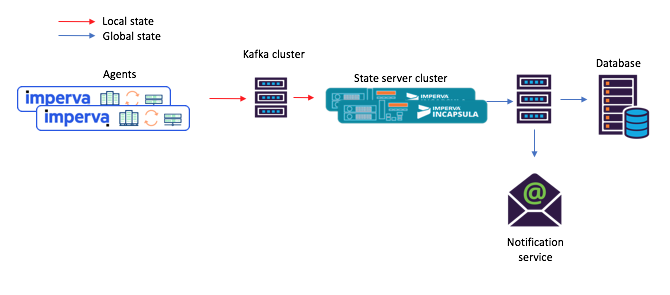 चित्र 3: साझा माइक्रोसर्विसेज के साथ एक परिदृश्य के लिए एक कार्य प्रवाह का एक नया उदाहरण: 1) एजेंट मूल काफ्का विषय में पहुंचने वाले संदेश को उत्पन्न करता है; 2) एक साझा राज्य (कफ़्का धाराओं का उपयोग करके) के साथ एक माइक्रो-सर्विस इसे संसाधित करता है और अंतिम कफका विषय पर गणना की गई स्थिति को लिखता है; जिसके बाद 3) उपभोक्ता नए राज्य को स्वीकार करते हैंअरे, कुंजी और मूल्यों का यह अंतर्निहित भंडार वास्तव में बहुत उपयोगी है!
चित्र 3: साझा माइक्रोसर्विसेज के साथ एक परिदृश्य के लिए एक कार्य प्रवाह का एक नया उदाहरण: 1) एजेंट मूल काफ्का विषय में पहुंचने वाले संदेश को उत्पन्न करता है; 2) एक साझा राज्य (कफ़्का धाराओं का उपयोग करके) के साथ एक माइक्रो-सर्विस इसे संसाधित करता है और अंतिम कफका विषय पर गणना की गई स्थिति को लिखता है; जिसके बाद 3) उपभोक्ता नए राज्य को स्वीकार करते हैंअरे, कुंजी और मूल्यों का यह अंतर्निहित भंडार वास्तव में बहुत उपयोगी है!जैसा कि ऊपर उल्लेख किया गया है, हमारे साझा-राज्य टोपोलॉजी में कुंजियों और मूल्यों का भंडार है। हमें इसके उपयोग के लिए कई विकल्प मिले, और उनमें से दो का वर्णन नीचे किया गया है।
विकल्प # 1: गणना के लिए कीस्टोर और वैल्यू स्टोर का उपयोग करनाकुंजियों और मूल्यों के हमारे पहले भंडार में सहायक डेटा था जो हमें गणना के लिए आवश्यक था। उदाहरण के लिए, कुछ मामलों में, साझा राज्य "बहुमत वोट" सिद्धांत के आधार पर निर्धारित किया गया था। रिपॉजिटरी में एक निश्चित वस्तु की स्थिति पर सभी नवीनतम एजेंट रिपोर्ट रखना संभव था। फिर, एक एजेंट से एक नई रिपोर्ट प्राप्त करना, हम इसे बचा सकते हैं, रिपॉजिटरी से उसी ऑब्जेक्ट की स्थिति के बारे में अन्य सभी एजेंटों से रिपोर्ट निकाल सकते हैं और गणना दोहरा सकते हैं।
नीचे चित्रा 4 दिखाता है कि हमने प्रोसेसर के प्रसंस्करण विधि के लिए कुंजी और मूल्य स्टोर तक पहुंच कैसे खोली, ताकि हम तब नए संदेश को संसाधित कर सकें।
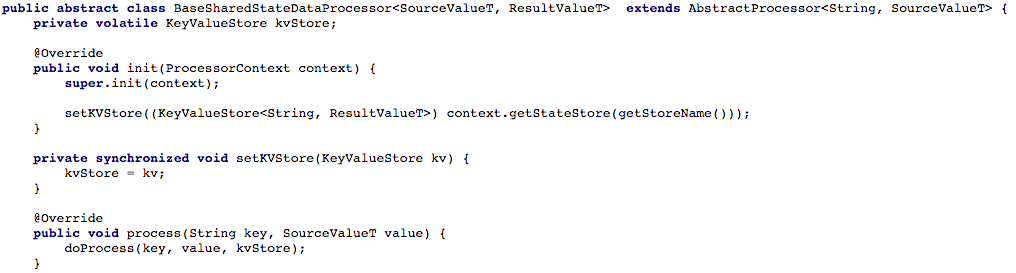 चित्रा 4: हम प्रोसेसर के प्रसंस्करण विधि के लिए कुंजी और मूल्यों के भंडारण के लिए उपयोग खोलते हैं (उसके बाद, प्रत्येक स्क्रिप्ट में एक साझा स्थिति के साथ काम करते हुए, आपको
चित्रा 4: हम प्रोसेसर के प्रसंस्करण विधि के लिए कुंजी और मूल्यों के भंडारण के लिए उपयोग खोलते हैं (उसके बाद, प्रत्येक स्क्रिप्ट में एक साझा स्थिति के साथ काम करते हुए, आपको doProcess पद्धति को लागू करना होगा)विकल्प # 2: कफका धाराओं के शीर्ष पर एक CRUD एपीआई बनानाहमारे कार्यों के मूल प्रवाह को समायोजित करने के बाद, हमने अपने साझा-सेवा माइक्रोसर्विसेज के लिए एक RESTful CRUD API लिखने की कोशिश शुरू की। हम कुछ या सभी वस्तुओं की स्थिति को पुनः प्राप्त करने में सक्षम होना चाहते थे, साथ ही वस्तु की स्थिति को सेट या हटाना (यह सर्वर साइड के समर्थन से उपयोगी है)।
सभी प्राप्त स्टेट एपीआई का समर्थन करने के लिए, जब भी हमें प्रसंस्करण के दौरान राज्य को पुनर्गणना की आवश्यकता होती है, तो हम इसे लंबे समय तक कुंजियों और मूल्यों के अंतर्निहित भंडार में डालते हैं। इस मामले में, काफ्का धाराओं के एकल उदाहरण का उपयोग करके इस तरह के एपीआई को लागू करना काफी सरल हो जाता है, जैसा कि नीचे दी गई सूची में दिखाया गया है:
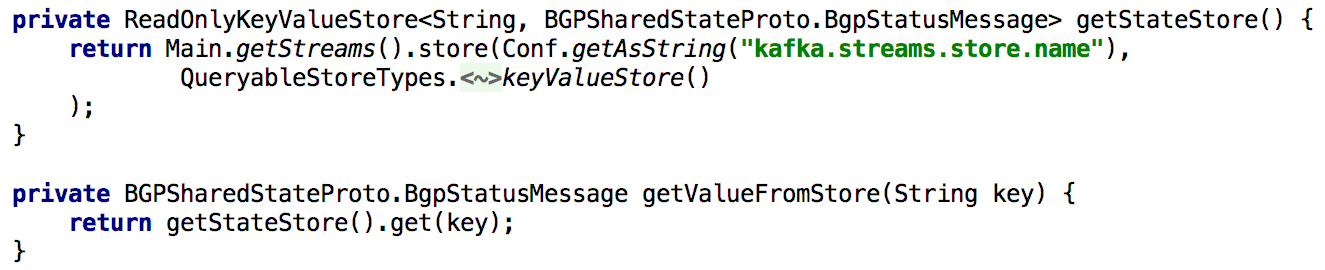 चित्र 5: किसी वस्तु का पूर्वगामी स्थिति प्राप्त करने के लिए कुंजियों और मूल्यों के अंतर्निहित भंडारण का उपयोग करना
चित्र 5: किसी वस्तु का पूर्वगामी स्थिति प्राप्त करने के लिए कुंजियों और मूल्यों के अंतर्निहित भंडारण का उपयोग करनाएपीआई के माध्यम से किसी वस्तु की स्थिति को अद्यतन करना भी लागू करना आसान है। सिद्धांत रूप में, इसके लिए आपको केवल एक निर्माता कफका बनाने की आवश्यकता है, और इसकी मदद से एक रिकॉर्ड बनाते हैं जिसमें एक नया राज्य बनाया जाता है। यह सुनिश्चित करता है कि एपीआई के माध्यम से उत्पन्न सभी संदेशों को उसी तरह से संसाधित किया जाएगा जैसे कि अन्य उत्पादकों (जैसे एजेंटों) से प्राप्त किया जाता है।
 चित्र 6: आप निर्माता कफका का उपयोग करके किसी वस्तु की स्थिति निर्धारित कर सकते हैंएक मामूली जटिलता: काफ्का के कई विभाजन हैं।
चित्र 6: आप निर्माता कफका का उपयोग करके किसी वस्तु की स्थिति निर्धारित कर सकते हैंएक मामूली जटिलता: काफ्का के कई विभाजन हैं।इसके बाद, हम प्रत्येक परिदृश्य के लिए एक साझा-सेवा माइक्रोसेस्टर क्लस्टर प्रदान करके प्रसंस्करण भार वितरित करना और उपलब्धता में सुधार करना चाहते थे। सेटअप हमें यथासंभव सरल दिया गया था: हमने सभी इंस्टेंसेस को कॉन्फ़िगर करने के बाद ताकि वे एक ही एप्लिकेशन आईडी (और एक ही बूट सर्वर के साथ) के साथ काम करें, लगभग सब कुछ स्वचालित रूप से किया गया था। हम यह भी निर्धारित करते हैं कि प्रत्येक स्रोत विषय में कई विभाजन शामिल होंगे, ताकि प्रत्येक उदाहरण को ऐसे विभाजनों का सबसेट सौंपा जा सके।
मैं यह भी उल्लेख करता हूं कि राज्य की दुकान की एक बैकअप प्रति बनाना सामान्य है, इसलिए, उदाहरण के लिए, विफलता के बाद वसूली के मामले में, इस प्रति को किसी अन्य उदाहरण पर स्थानांतरित करें। काफ्का धाराओं में प्रत्येक राज्य के स्टोर के लिए, एक प्रतिकृति विषय को एक परिवर्तन लॉग (जिसमें स्थानीय अपडेट ट्रैक किए जाते हैं) के साथ बनाया जाता है। इस प्रकार, काफ्का लगातार राज्य की दुकान को सुरक्षित करता है। इसलिए, एक या दूसरे काफ्का धाराओं के उदाहरण की विफलता की स्थिति में, राज्य स्टोर को जल्दी से दूसरे उदाहरण में बहाल किया जा सकता है, जहां संबंधित विभाजन जाएंगे। हमारे परीक्षणों से पता चला कि यह सेकंड में किया जा सकता है, भले ही भंडार में लाखों रिकॉर्ड हों।
एक साझा-सेवा माइक्रोसर्विस से माइक्रोसर्विस के एक क्लस्टर में जाना, गेट स्टेट एपीआई को लागू करने के लिए कम तुच्छ हो जाता है। नई स्थिति में, प्रत्येक माइक्रोसिस्ट के राज्य भंडार में समग्र चित्र का केवल एक हिस्सा होता है (वे ऑब्जेक्ट जिनकी कुंजी एक विशेष विभाजन में मैप की गई थी)। हमें यह निर्धारित करना था कि हमें जिस वस्तु की आवश्यकता है वह किस स्थिति में निहित है, और हमने इसे प्रवाह मेटाडेटा के आधार पर किया, जैसा कि नीचे दिखाया गया है:
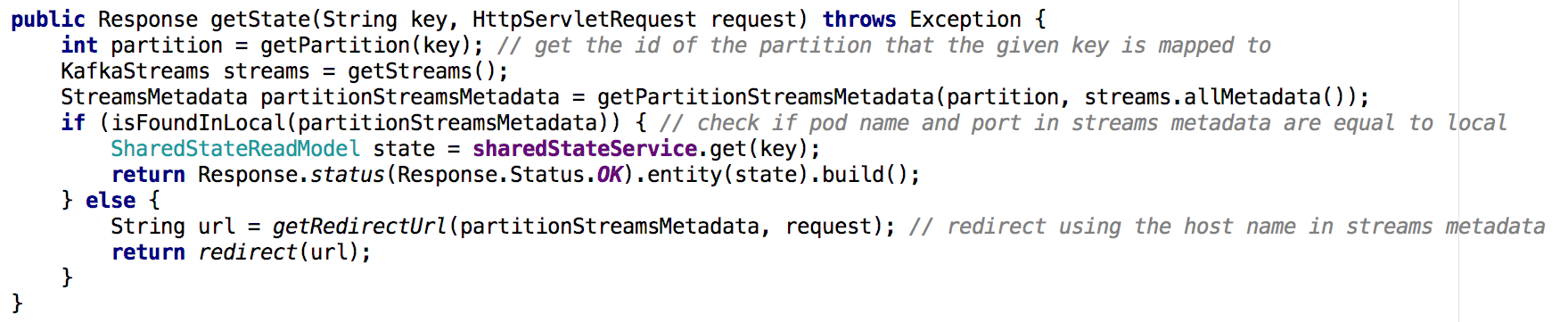 चित्र 7: प्रवाह मेटाडेटा का उपयोग करके हम निर्धारित करते हैं कि वांछित वस्तु की स्थिति का अनुरोध किस उदाहरण से किया गया है; GET ALL API के साथ एक समान दृष्टिकोण का उपयोग किया गया थामुख्य खोज
चित्र 7: प्रवाह मेटाडेटा का उपयोग करके हम निर्धारित करते हैं कि वांछित वस्तु की स्थिति का अनुरोध किस उदाहरण से किया गया है; GET ALL API के साथ एक समान दृष्टिकोण का उपयोग किया गया थामुख्य खोजकफ़्का धाराओं में राज्य के स्टोर, वितरित डेटाबेस के रूप में कार्य कर सकते हैं,
- लगातार काफ्का में दोहराया गया
- ऐसी प्रणाली के शीर्ष पर आसानी से CRUD एपीआई बनाया जाता है
- कई विभाजनों को संसाधित करना थोड़ा अधिक जटिल है
- सहायक डेटा संग्रहीत करने के लिए स्ट्रीम टोपोलॉजी में एक या एक से अधिक राज्य भंडार जोड़ना भी संभव है। इस विकल्प का उपयोग इसके लिए किया जा सकता है:
- स्ट्रीमिंग प्रसंस्करण में गणना के लिए आवश्यक डेटा का दीर्घकालिक भंडारण
- अगली बार स्ट्रीम इंस्टेंस को प्रारंभ करने पर डेटा का दीर्घकालिक संग्रहण उपयोगी हो सकता है
- बहुत अधिक ...
इन और अन्य लाभों के लिए धन्यवाद, काफ्का स्ट्रीम हमारी जैसी वितरित प्रणाली में वैश्विक स्थिति का समर्थन करने के लिए महान है। काफ्का स्ट्रीम उत्पादन में बहुत विश्वसनीय साबित हुई (इसकी तैनाती के क्षण से, हमने व्यावहारिक रूप से संदेश नहीं खोए), और हमें यकीन है कि यह अपनी क्षमताओं तक सीमित नहीं है!