
RabbitMQ एक संदेश ब्रोकर है जो एरलैंग भाषा में लिखा गया है, जो आपको कई नोड्स के लिए पूर्ण डेटा प्रतिकृति के साथ एक विफलता क्लस्टर को व्यवस्थित करने की अनुमति देता है, जहां प्रत्येक नोड रीड एंड रिक्वेस्ट को हैंडल कर सकता है। उत्पादन में कई कुबेरनेट समूहों के साथ, हम बड़ी संख्या में रैबिटमक्यू इंस्टॉलेशन का समर्थन करते हैं और डाउनटाइम के बिना एक क्लस्टर से दूसरे में डेटा स्थानांतरित करने की आवश्यकता के साथ सामना किया जाता है।
यह ऑपरेशन कम से कम दो मामलों में हमारे लिए आवश्यक था:
- RabbitMQ क्लस्टर से डेटा स्थानांतरित करना जो कुबेरनेट्स में एक नए क्लस्टर में नहीं है जो पहले से ही "ट्यूनर्ड आउट" है (जो कि K8 पॉड्स में कार्य कर रहा है)।
- एक नाम स्थान से दूसरे नाम के कुबेरनेट्स के भीतर RabbitMQ का प्रवासन (उदाहरण के लिए, यदि पथ नामस्थानों द्वारा सीमांकित किए जाते हैं, तो बुनियादी ढांचे को एक पथ से दूसरे स्थान पर स्थानांतरित करने के लिए)।
इस लेख में प्रस्तावित नुस्खा स्थितियों पर केंद्रित है (लेकिन उन तक सीमित नहीं है), जिसमें एक पुराना रैबिटएमक्यू क्लस्टर है (उदाहरण के लिए, 3 नोड्स का), जो कि K8 में या कुछ पुराने सर्वरों पर स्थित है। कुबेरनेट्स में होस्ट किया गया एक एप्लिकेशन इसके साथ काम करता है (पहले से ही या भविष्य में):

... और हम इसे कुबेरनेट्स में एक नए उत्पादन में स्थानांतरित करने की चुनौती का सामना कर रहे हैं।
सबसे पहले, प्रवास के लिए एक सामान्य दृष्टिकोण का वर्णन किया जाएगा, और उसके बाद, इसके कार्यान्वयन पर तकनीकी विवरण।
प्रवासन एल्गोरिथ्म
किसी भी कार्रवाई से पहले पहला, प्रारंभिक, कदम यह सत्यापित करना है कि उच्च उपलब्धता (
HA ) मोड पुराने RabbitMQ इंस्टॉलेशन में सक्षम है। कारण स्पष्ट है - हम कोई डेटा खोना नहीं चाहते हैं। इस जाँच को अंजाम देने के लिए, आप RabbitMQ के व्यवस्थापक पैनल पर जा सकते हैं और व्यवस्थापक → नीतियाँ टैब में यह सुनिश्चित कर सकते हैं कि मान
ha-mode: all :

अगला कदम कुबेरनेट्स पॉड्स में एक नया रैबिटमक्यू क्लस्टर उठाना है (हमारे मामले में, उदाहरण के लिए, 3 नोड्स से मिलकर, लेकिन उनकी संख्या भिन्न हो सकती है)।
उसके बाद, हम पुराने और नए RabbitMQ समूहों को मिलाते हैं, जो एकल क्लस्टर (6 नोड्स) प्राप्त करते हैं:
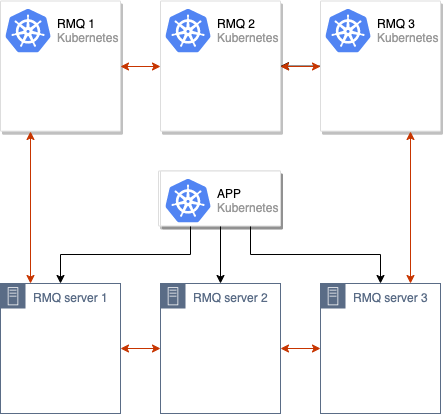
पुराने और नए RabbitMQ समूहों के बीच डेटा को सिंक्रनाइज़ करने की प्रक्रिया शुरू की गई है। सभी डेटा क्लस्टर में सभी नोड्स के बीच सिंक्रनाइज़ होने के बाद, हम नए क्लस्टर का उपयोग करने के लिए एप्लिकेशन को स्विच कर सकते हैं:
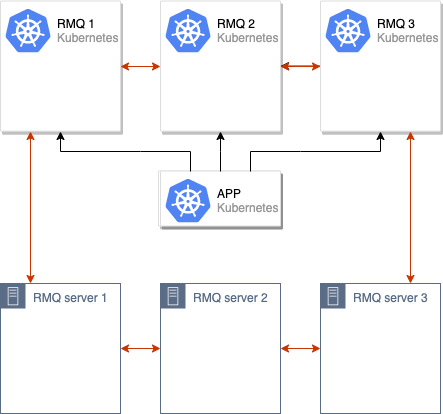
इन ऑपरेशनों के बाद, यह रैबिटएमक्यू क्लस्टर से पुराने नोड्स को हटाने के लिए पर्याप्त है, और इस कदम को पूरा किया जा सकता है:

हमने अपने उत्पादन में इस योजना का बार-बार उपयोग किया है। हालांकि, उनकी अपनी सुविधा के लिए, हमने इसे एक विशेष प्रणाली के ढांचे के भीतर लागू किया, जो कुबेरनेट क्लस्टर्स के सेट पर विशिष्ट आरएमक्यू कॉन्फ़िगरेशन वितरित करता है
(जो उत्सुक हैं: हम एडऑन-ऑपरेटर के बारे में बात कर रहे हैं, जिसके बारे में हम हाल ही में जानते हैं ) । नीचे व्यक्तिगत निर्देश प्रस्तुत किए गए हैं कि कोई भी कार्रवाई में प्रस्तावित समाधान का प्रयास करने के लिए अपने प्रतिष्ठानों पर आवेदन कर सकता है।
हम अभ्यास में प्रयास करते हैं
आवश्यकताओं
विवरण बहुत सरल हैं:
- कुबेरनेट्स क्लस्टर (मिनिक्यूब भी उपयुक्त है);
- RabbitMQ क्लस्टर (नंगे धातु पर तैनात किया जा सकता है, और आधिकारिक हेलन चार्ट से कुबेरनेट्स में एक नियमित क्लस्टर के रूप में बनाया गया है)।
नीचे वर्णित उदाहरण के लिए, मैंने आरएमक्यू को कुबेरनेट्स में तैनात किया और इसे
rmq-old नाम दिया।
स्टैंड की तैयारी
1. हेल्म चार्ट डाउनलोड करें और इसे थोड़ा संपादित करें:
helm fetch --untar stable/rabbitmq-ha
सुविधा के लिए, हम एक पासवर्ड सेट करते हैं,
ErlangCookie और
ha-all पॉलिसी सेट करते हैं ताकि डिफ़ॉल्ट रूप से आरएमक्यू क्लस्टर के सभी नोड्स के बीच कतारें सिंक्रनाइज़ हो जाएं:
rabbitmqPassword: guest rabbitmqErlangCookie: mae9joopaol7aiVu3eechei2waiGa2we definitions: policies: |- { "name": "ha-all", "pattern": ".*", "vhost": "/", "definition": { "ha-mode": "all", "ha-sync-mode": "automatic", "ha-sync-batch-size": 81920 } }
2. चार्ट सेट करें:
helm install . --name rmq-old --namespace rmq-old
3. RabbitMQ व्यवस्थापक पैनल पर जाएं, एक नई कतार बनाएं और कुछ संदेश जोड़ें। इनकी आवश्यकता होगी ताकि प्रवास के बाद हम यह सुनिश्चित कर सकें कि सभी डेटा सहेज लिए गए हैं और हमने कुछ भी नहीं खोया है:

परीक्षण बेंच तैयार है: हमारे पास "पुराना" रैबिटएमक्यू है जिसके डेटा को स्थानांतरित करने की आवश्यकता है।
RabbitMQ क्लस्टर प्रवासन
1. सबसे पहले, उपयोगकर्ता के लिए
एक ही ErlangCookie और पासवर्ड के साथ एक
अलग नामस्थान में नए RabbitMQ को तैनात करें। ऐसा करने के लिए, हम ऊपर वर्णित ऑपरेशन करते हैं, अंतिम आरएमक्यू इंस्टॉलेशन कमांड को निम्नलिखित में बदलते हैं:
helm install . --name rmq-new --namespace rmq-new
2. अब आपको नए क्लस्टर को पुराने के साथ मर्ज करने की आवश्यकता है। ऐसा करने के लिए,
नए RabbitMQ के प्रत्येक पॉड पर जाएं और कमांड निष्पादित करें:
export OLD_RMQ=rabbit@rmq-old-rabbitmq-ha-0.rmq-old-rabbitmq-ha-discovery.rmq-old.svc.cluster.local && \ rabbitmqctl stop_app && \ rabbitmqctl join_cluster $OLD_RMQ && \ rabbitmqctl start_app
OLD_RMQ चर
OLD_RMQ पुराने RMQ क्लस्टर के नोड्स में से एक का पता
OLD_RMQ ।
ये आदेश
नए RMQ क्लस्टर के वर्तमान नोड को रोक देंगे, इसे पुराने क्लस्टर में संलग्न करेंगे, और इसे पुनः आरंभ करेंगे।
3. 6 नोड्स का RMQ क्लस्टर तैयार है:

जब तक संदेश सभी नोड्स के बीच समन्वयित न हो जाए, आपको इंतजार करना चाहिए। यह अनुमान लगाना आसान है कि संदेशों का सिंक्रनाइज़ेशन समय उस लोहे की क्षमता पर निर्भर करता है जिस पर क्लस्टर तैनात किया गया है, और संदेशों की संख्या पर। वर्णित परिदृश्य में उनमें से केवल 10 हैं, इसलिए डेटा को तुरंत सिंक्रनाइज़ किया गया था, लेकिन पर्याप्त संख्या में संदेशों के साथ, सिंक्रनाइज़ेशन में घंटों लग सकते हैं।
तो, सिंक्रनाइज़ेशन स्थिति:

यहां,
+5 मतलब है कि संदेश
पहले से
ही 5 नोड्स पर हैं (
Node क्षेत्र में निर्दिष्ट के अलावा)। इस प्रकार, सिंक्रनाइज़ेशन सफल रहा।
4. यह एप्लिकेशन में नए क्लस्टर में RMQ पते को स्विच करने के लिए ही रहता है (यहां विशिष्ट क्रियाएं आपके द्वारा उपयोग किए जा रहे प्रौद्योगिकी स्टैक और अन्य एप्लिकेशन विशिष्टताओं पर निर्भर करती हैं), जिसके बाद आप पुराने को अलविदा कह सकते हैं।
अंतिम ऑपरेशन के लिए (यानी, एप्लिकेशन को नए क्लस्टर में बदलने के
बाद ), हम
पुराने क्लस्टर के प्रत्येक नोड पर जाते हैं और कमांड निष्पादित करते हैं:
rabbitmqctl stop_app rabbitmqctl reset
पुराने नोड्स के बारे में क्लस्टर "भूल गया": आप पुराने आरएमक्यू को हटा सकते हैं, जो इस कदम को पूरा करेगा।
नोट : यदि आप प्रमाण पत्र के साथ आरएमक्यू का उपयोग करते हैं, तो मूल रूप से कुछ भी नहीं बदलता है - आगे बढ़ने की प्रक्रिया बिल्कुल उसी तरह की जाएगी।निष्कर्ष
वर्णित योजना लगभग सभी मामलों के लिए उपयुक्त है जब हमें RabbitMQ को स्थानांतरित करने की आवश्यकता होती है या सिर्फ एक नए क्लस्टर में स्थानांतरित होता है।
हमारे मामले में, कठिनाइयां केवल एक बार हुईं जब आरएमक्यू को कई जगहों से एक्सेस किया गया था, और हमारे पास आरएमक्यू एड्रेस को हर जगह एक नए में बदलने का अवसर नहीं था। फिर हमने समान लेबल वाले समान नामस्थान में एक नया RMQ लॉन्च किया, ताकि यह मौजूदा सेवाओं और इनग्रेड्स के अंतर्गत आए, और जब हमने पॉड शुरू किया, तो हमने अपने हाथों से लेबलों को हेरफेर किया, उन्हें शुरुआत में ही डिलीट कर दिया, ताकि वे खाली आरएमक्यू पर न गिरें, और संदेश सिंक्रनाइज़ेशन के बाद उन्हें वापस जोड़ना।
हमने एक ही रणनीति का उपयोग किया जब एक संशोधित कॉन्फ़िगरेशन के साथ एक नए संस्करण में रैबिटएमक्यू को अपडेट किया गया - सब कुछ घड़ी की तरह काम किया।
पुनश्च
इस सामग्री की तार्किक निरंतरता के रूप में, हम MongoDB (आयरन सर्वर से कुबेरनेट्स में प्रवास) और MySQL (कुबर्नेट्स के अंदर इस DBMS को "तैयार करने" के विकल्पों में से एक) के बारे में लेख तैयार कर रहे हैं। आने वाले महीनों में उन्हें प्रकाशित किया जाएगा।
पी पी एस
हमारे ब्लॉग में भी पढ़ें: