नमस्कार।
क्या आप जानते हैं कि विज्ञापन प्लेटफ़ॉर्म अक्सर उनके द्वारा होस्ट किए जाने वाले विज्ञापनों की संख्या बढ़ाने के लिए प्रतियोगियों की सामग्री की प्रतिलिपि बनाते हैं? वे इसे इस तरह से करते हैं: वे विक्रेताओं को बुलाते हैं और उन्हें अपने मंच पर बसने की पेशकश करते हैं। और कभी-कभी वे पूरी तरह से उपयोगकर्ता की अनुमति के बिना विज्ञापनों की नकल करते हैं। एविटो एक लोकप्रिय स्थल है, और हम अक्सर ऐसी अनुचित प्रतिस्पर्धा का सामना करते हैं। हम इस घटना से कैसे लड़ रहे हैं, इसके बारे में पढ़ें, कट के नीचे पढ़ें।

समस्या
Avito से अन्य प्लेटफार्मों पर सामग्री की प्रतिलिपि बनाना कई श्रेणियों की वस्तुओं और सेवाओं में मौजूद है। यह लेख केवल कारों पर केंद्रित होगा। पिछली पोस्ट में, मैंने बात की थी कि हमने कारों पर स्वचालित संख्या को कैसे छिपाया।

लेकिन यह निकला (अन्य प्लेटफार्मों के खोज परिणामों को देखते हुए) कि हमने इस सुविधा को तीन घोषणा स्थलों पर तुरंत लॉन्च किया।

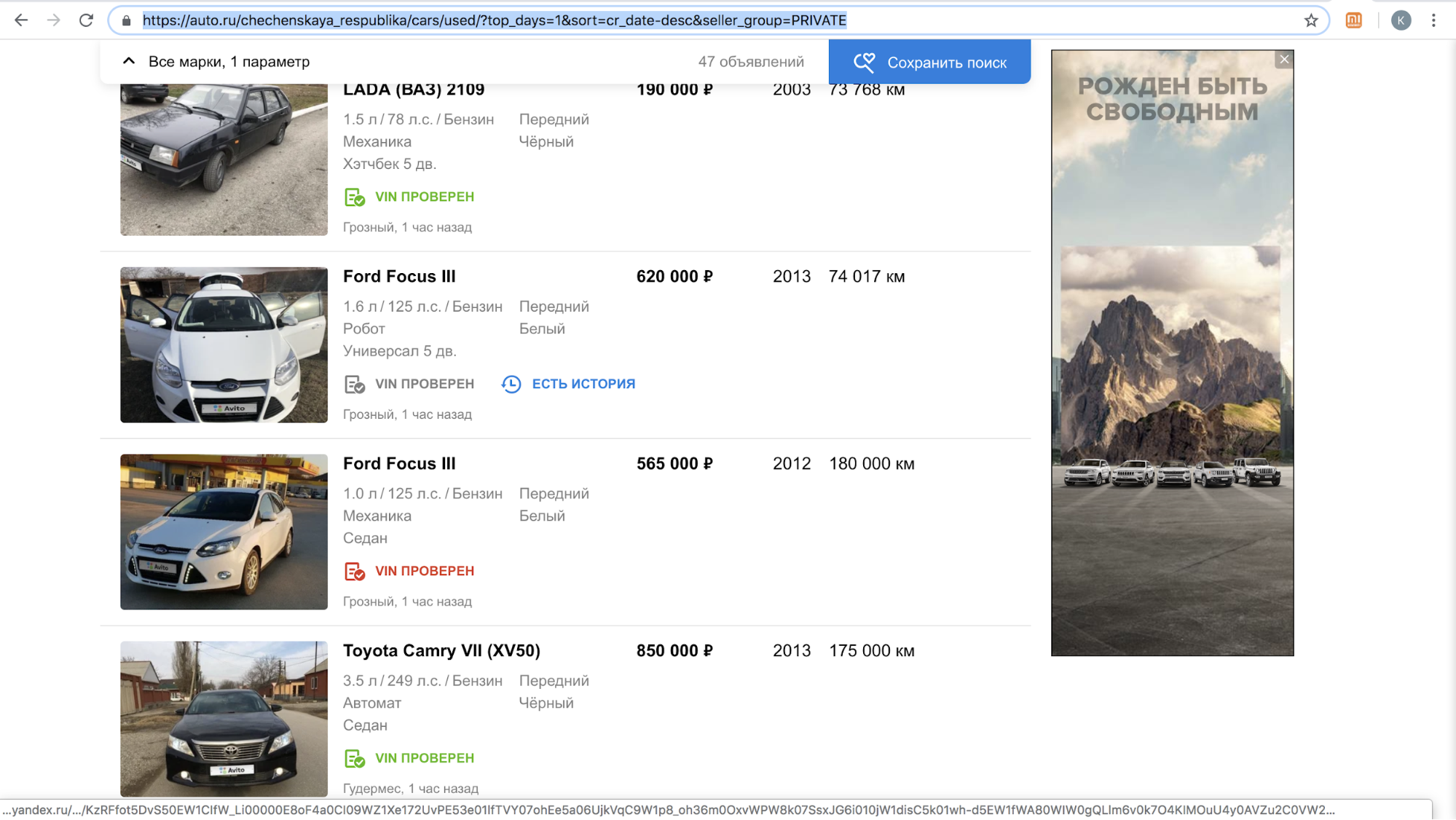
इन साइटों में से एक, सुविधा को लॉन्च करने के बाद, हमारे उपयोगकर्ताओं को उनके प्लेटफ़ॉर्म पर घोषणा को कॉपी करने के ऑफ़र के साथ अस्थायी रूप से निलंबित कर दिया गया: उनकी साइट पर Avito लोगो के साथ बहुत अधिक सामग्री थी, अकेले नवंबर 2018 में - 70,000 से अधिक विज्ञापन। उदाहरण के लिए, चेचन गणराज्य में प्रति दिन उनका खोज परिणाम कैसा दिखता है।
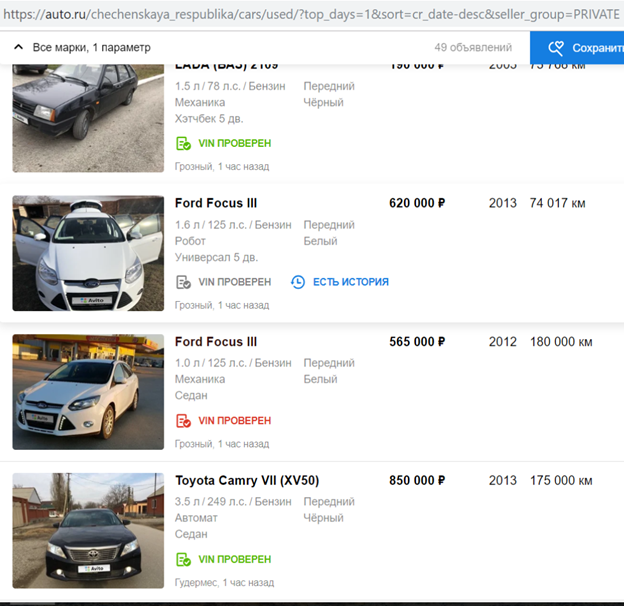
लाइसेंस प्लेटों को छिपाने के लिए उनके एल्गोरिथ्म को पूरा करने के बाद, ताकि यह स्वचालित रूप से पता लगा सके और एविटो लोगो को बंद कर दे, उन्होंने प्रक्रिया को फिर से शुरू किया।

हमारे दृष्टिकोण से, प्रतियोगियों की सामग्री की नकल करना, व्यावसायिक उद्देश्यों के लिए इसका उपयोग करना अनैतिक और अस्वीकार्य है। हमें अपने उपयोगकर्ताओं से शिकायतें प्राप्त होती हैं, जो हमारे समर्थन में इससे नाखुश हैं। और यहाँ कहानियों में से एक में एक प्रतिक्रिया का एक उदाहरण है।
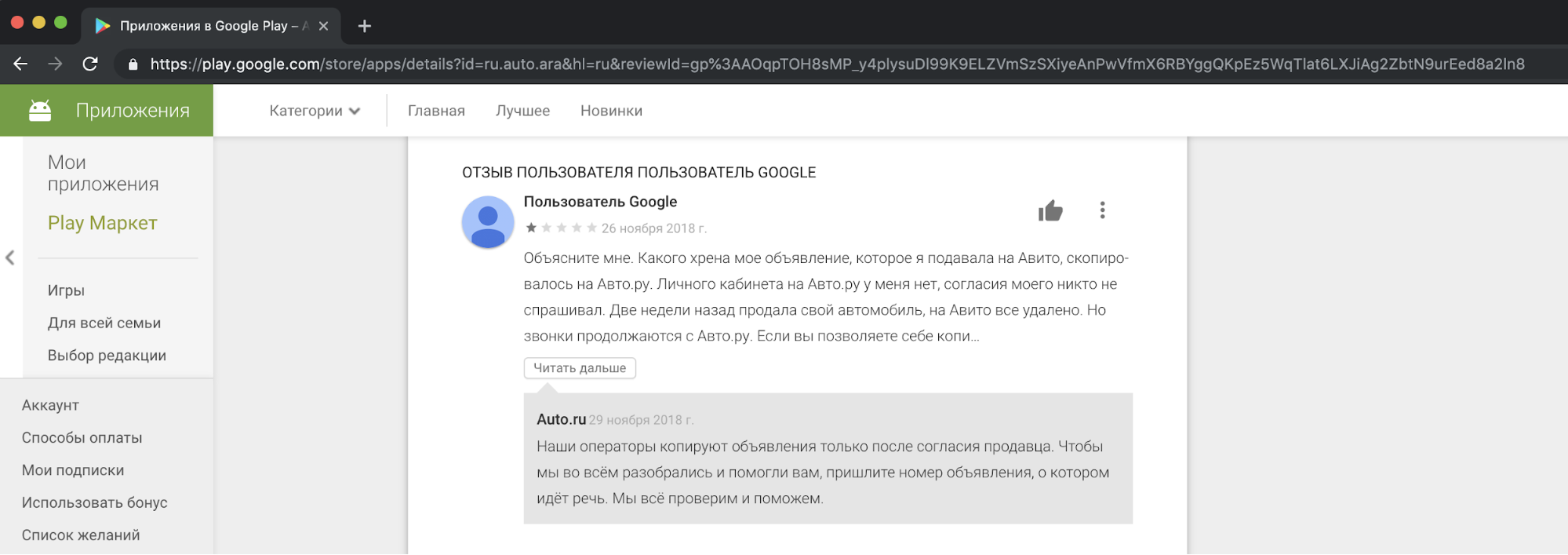
मुझे कहना होगा कि विज्ञापनों को कॉपी करने के लिए लोगों की सहमति के लिए अनुरोध ऐसे कार्यों को उचित नहीं ठहराता है। यह "ऑन एडवरटाइजिंग" और "ऑन पर्सनल डेटा", एविटो नियमों, ट्रेडमार्क अधिकारों और विज्ञापनों के डेटाबेस के कानूनों का उल्लंघन है।
हम एक प्रतियोगी के साथ शांति से सहमत नहीं हो सकते थे, लेकिन हम इस स्थिति को छोड़ना नहीं चाहते थे।
समस्या को हल करने के तरीके
पहला तरीका कानूनी है। इसी तरह की मिसालें पहले से ही दूसरे देशों में हैं। उदाहरण के लिए, जाने-माने अमेरिकी क्लासिफायर क्रैग्सलिस्ट ने साइटों से बड़ी मात्रा में धन की नकल की है।
प्रतिलिपि समस्या को हल करने का दूसरा तरीका छवि में एक बड़ा वॉटरमार्क जोड़ना है ताकि इसे क्रॉप न किया जा सके।
तीसरी विधि तकनीकी है। हम अपनी सामग्री की प्रतिलिपि बनाने की प्रक्रिया को जटिल बना सकते हैं। यह मानना तर्कसंगत है कि कुछ मॉडल प्रतियोगियों से एविटो लोगो को छिपाने में लगे हुए हैं। यह भी ज्ञात है कि कई मॉडल "हमलों" से ग्रस्त हैं जो उन्हें सही तरीके से काम करने से रोकते हैं। यह लेख सिर्फ उनके बारे में होगा।
प्रतिकूल आक्रमण

आदर्श रूप से, नेटवर्क के लिए प्रतिकूल उदाहरण शोर की तरह दिखता है जो मानव आंख से अप्रभेद्य है, लेकिन क्लासिफायरियर के लिए यह उस कक्षा के लिए एक पर्याप्त संकेत जोड़ता है जो चित्र में नहीं है। नतीजतन, एक तस्वीर, उदाहरण के लिए, एक पांडा के साथ, गिब्बन के रूप में उच्च आत्मविश्वास के साथ वर्गीकृत किया जाता है। न केवल चित्र वर्गीकरण नेटवर्क के लिए, बल्कि विभाजन, पहचान के लिए भी प्रतिकूल शोर पैदा करना संभव है। एक दिलचस्प उदाहरण कीन लैब्स का एक हालिया काम है: उन्होंने टेवेला ऑटोपायलट को फुटपाथ पर डॉट्स के साथ और बारिश के डिटेक्टर को सिर्फ ऐसे प्रतिकूल शोर को प्रदर्शित करके धोखा दिया। अन्य डोमेन के लिए भी हमले हैं, उदाहरण के लिए, ध्वनि: अमेज़ॅन एलेक्सा पर प्रसिद्ध हमले और अन्य आवाज सहायकों में मानव कान (अमेजन पर कुछ खरीदने के लिए पेश किए जाने वाले पटाखे) से अविभाज्य टीम खेलने में शामिल थे।
चित्रों का विश्लेषण करने वाले मॉडल के लिए प्रतिकूल शोर पैदा करना मॉडल के प्रशिक्षण के लिए आवश्यक ढाल के गैर-मानक उपयोग के कारण संभव है। आमतौर पर, त्रुटियों के पीछे प्रसार की विधि में, उद्देश्य फ़ंक्शन की गणना की गई ढाल का उपयोग करके, केवल नेटवर्क परतों के वजन को बदल दिया जाता है ताकि यह प्रशिक्षण डाटासेट पर कम गलत न हो। नेटवर्क परतों के लिए के रूप में, आप इनपुट छवि से उद्देश्य समारोह की ढाल की गणना कर सकते हैं और इसे बदल सकते हैं। एक ढाल का उपयोग करके इनपुट छवि को बदलना विभिन्न प्रसिद्ध एल्गोरिदम के लिए उपयोग किया गया था। डीपड्रीम याद है?

अगर हम इनपुट इमेज से ऑब्जेक्टिव फंक्शन के ग्रेडिएंट की गणना करते हैं और इस ग्रैडिएंट को जोड़ते हैं, तो इमेजनेट से प्रचलित क्लास के बारे में अधिक जानकारी इमेज में दिखाई देती है: कुत्तों के अधिक चेहरे दिखाई देते हैं, जिसके कारण लॉस फंक्शन की वैल्यू कम हो जाती है और मॉडल "डॉग" क्लास में ज्यादा कॉन्फिडेंट हो जाता है। उदाहरण में कुत्ता क्यों है? बस 1000 कक्षाओं से इमेजनेट में - कुत्तों के 120 वर्ग । शैली संशोधन में एक समान दृष्टिकोण का उपयोग शैली स्थानांतरण एल्गोरिथ्म में किया गया था, जिसे मुख्य रूप से प्रिज्मा एप्लिकेशन के कारण जाना जाता है।
एक प्रतिकूल उदाहरण बनाने के लिए, आप इनपुट छवि को बदलने के पुनरावृत्ति विधि का भी उपयोग कर सकते हैं।
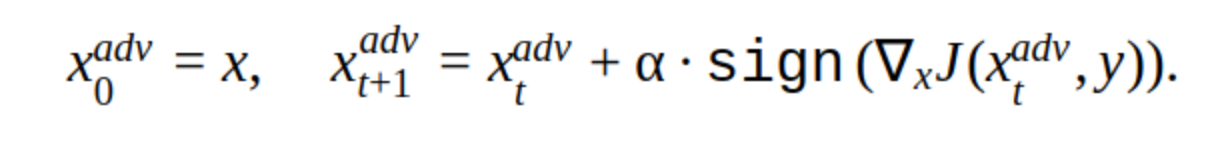
इस पद्धति में कई संशोधन हैं, लेकिन मुख्य विचार सरल है: मूल छवि क्रमिक रूप से क्लासिफायर फ़ंक्शन जे के नुकसान की प्रवणता की दिशा में स्थानांतरित होती है (क्योंकि केवल संकेत का उपयोग किया जाता है) चरण α के साथ। 'y' वह वर्ग है जिसे सही उत्तर में नेटवर्क के विश्वास को कम करने के लिए छवि में दर्शाया गया है। ऐसे हमले को गैर लक्षित कहा जाता है। आप पुनरावृत्तियों का इष्टतम चरण और संख्या चुन सकते हैं ताकि इनपुट छवि में परिवर्तन किसी व्यक्ति के लिए सामान्य से अप्रभेद्य हो। लेकिन समय की लागत के दृष्टिकोण से, ऐसा हमला हमें शोभा नहीं देता। ठेस में एक तस्वीर के लिए 5-10 पुनरावृत्तियों एक लंबे समय है।
पुनरावृत्ति विधियों का एक विकल्प FGSM विधि है।

यह एक एकल शॉट विधि है, अर्थात इसका उपयोग करने के लिए, आपको एक बार इनपुट छवि के लिए नुकसान फ़ंक्शन के ग्रेडिएंट की गणना करने की आवश्यकता है, और प्रतिकूल शोर को चित्र में जोड़ने के लिए तैयार है। यह विधि स्पष्ट रूप से अधिक उत्पादक है। इसका उपयोग उत्पादन में किया जा सकता है।
प्रतिकूल उदाहरण बनाना
हमने अपने स्वयं के मॉडल को हैक करके शुरू करने का फैसला किया।
यह वह तस्वीर है जो हमारे मॉडल के लिए लाइसेंस प्लेट खोजने की संभावना को कम करती है।

यह स्पष्ट है कि इस पद्धति में एक खामी है: चित्र में जो परिवर्तन होता है वह आंख को दिखाई देता है। साथ ही यह विधि गैर लक्षित है, लेकिन इसे निर्देशित हमले करने के लिए बदला जा सकता है। फिर मॉडल दूसरी जगह लाइसेंस प्लेट के लिए जगह की भविष्यवाणी करेगा। यह T-FGSM विधि है।
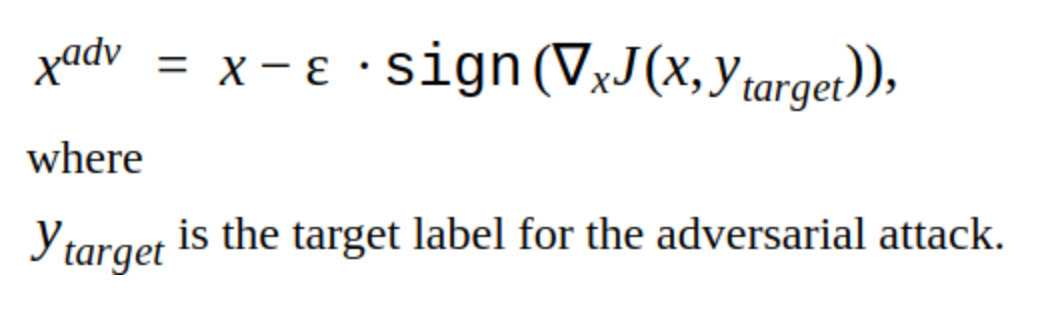
इस पद्धति के साथ हमारे मॉडल को तोड़ने के लिए, आपको इनपुट छवि को थोड़ा अधिक ध्यान से बदलने की आवश्यकता है।

यह कहना अभी तक संभव नहीं है कि परिणाम आदर्श हैं, लेकिन कम से कम तरीकों की दक्षता को सत्यापित किया गया है। हमने Foolbox, CleverHans, और ART-IBM नेटवर्क को हैक करने के लिए तैयार पुस्तकालयों की भी कोशिश की, लेकिन उनकी मदद से हमारे नेटवर्क का पता लगाना संभव नहीं था। वहाँ दिए गए तरीके वर्गीकरण नेटवर्क के लिए बेहतर हैं। यह नेटवर्क हैकिंग में एक सामान्य प्रवृत्ति है: ऑब्जेक्ट डिटेक्शन के लिए किसी हमले को और अधिक कठिन बनाना विशेष रूप से जटिल मॉडल की बात आती है, उदाहरण के लिए, मास्क आरसीएनएन।
हमला परीक्षण
अब तक वर्णित सब कुछ हमारे आंतरिक प्रयोगों से परे नहीं था, लेकिन यह पता लगाना आवश्यक था कि अन्य विज्ञापन प्लेटफार्मों के डिटेक्टरों पर हमलों का परीक्षण कैसे किया जाए।
यह पता चला है कि प्लेटफार्मों में से एक के लिए आवेदन करते समय, लाइसेंस प्लेट का स्वचालित रूप से पता लगाया जाता है, इसलिए आप कई बार तस्वीरें अपलोड कर सकते हैं और जांच सकते हैं कि नए एल्गोरिदम के साथ डिटेक्शन एल्गोरिदम कैसे काम करता है।
यह महान है! लेकिन ...
हमारे मॉडल पर काम करने वाले किसी भी हमले ने किसी अन्य प्लेटफॉर्म पर परीक्षण करते समय काम नहीं किया। ऐसा क्यों हुआ? यह मॉडल में अंतर और कैसे खराब प्रतिकूल हमलों के परिणामस्वरूप विभिन्न नेटवर्क आर्किटेक्चर का सामान्यीकरण है। हमलों के प्रजनन की जटिलता के कारण, उन्हें दो समूहों में विभाजित किया गया है: सफेद बॉक्स और ब्लैक बॉक्स।

उन हमलों को जो हमने अपने मॉडल पर किए थे - यह एक सफेद बॉक्स था। हमें जरूरत है कि एक काले रंग की पेटी है, जिसमें प्रवेश पर अतिरिक्त प्रतिबंध हैं: कोई एपीआई नहीं है, आप सभी कर सकते हैं मैन्युअल रूप से फ़ोटो अपलोड करें और हमलों की जांच करें। यदि कोई एपीआई था, तो आप एक विकल्प मॉडल बना सकते हैं।

ब्लैक बॉक्स मॉडल के इनपुट छवियों और उत्तरों का एक डेटासेट बनाने के लिए विचार है, जिस पर आप विभिन्न आर्किटेक्चर के कई मॉडलों को प्रशिक्षित कर सकते हैं, ताकि ब्लैक बॉक्स मॉडल को अनुमानित कर सकें। फिर आप इन मॉडलों पर एक सफेद बॉक्स हमला कर सकते हैं और वे एक ब्लैक बॉक्स पर काम करने की अधिक संभावना रखते हैं। हमारे मामले में, यह बहुत सारे मैनुअल काम का मतलब है, इसलिए यह विकल्प हमें पसंद नहीं आया।
गतिरोध को तोड़ना
ब्लैक बॉक्स हमलों के विषय पर दिलचस्प कामों की तलाश में, एक लेख पाया गया शेपशाइटर: तेज आर-सीएनएन ऑब्जेक्ट डिटेक्टर पर मजबूत शारीरिक सलाहकार हमला
लेख के लेखकों ने स्टॉप साइन की पृष्ठभूमि के लिए सही वर्ग के अलावा छवियों को जोड़कर स्व-ड्राइविंग मशीनों के नेटवर्क के ऑब्जेक्ट डिटेक्शन पर हमले किए।


इस तरह का हमला मानव आंख को स्पष्ट रूप से दिखाई देता है, हालांकि, यह ऑब्जेक्ट डिटेक्शन नेटवर्क के काम को सफलतापूर्वक तोड़ता है, जो कि हमें चाहिए। इसलिए, हमने कार्य क्षमता के लिए हमले के वांछित अदर्शन को नजरअंदाज करने का फैसला किया।
हम यह जांचना चाहते थे कि पता लगाने वाला मॉडल कितना मुकर गया था, क्या यह कार के बारे में जानकारी का उपयोग करता है, या क्या यह केवल एविटो प्लेट की जरूरत है?
ऐसा करने के लिए, निम्न छवि बनाई गई:

हमने इसे एक मशीन के रूप में एक ब्लैक बॉक्स मॉडल वाले विज्ञापन प्लेटफ़ॉर्म पर अपलोड किया। हम प्राप्त किया:

इसका मतलब यह है कि आप केवल एविटो प्लेट को बदल सकते हैं, इनपुट छवि में बाकी जानकारी ब्लैक बॉक्स मॉडल का पता लगाने के लिए आवश्यक नहीं है।
कई प्रयासों के बाद, FGSM विधि द्वारा प्राप्त एविटो प्लेट के प्रतिकूल शोर को जोड़ने का विचार उत्पन्न हुआ, जिसने हमारे स्वयं के मॉडल को तोड़ दिया, लेकिन एक बड़े गुणांक के साथ। यह इस तरह निकला:

कार से, ऐसा दिखता है:

हमने ब्लैक बॉक्स मॉडल के साथ प्लेटफ़ॉर्म पर एक तस्वीर अपलोड की। परिणाम सफल रहा।

इस विधि को कई अन्य तस्वीरों पर लागू करते हुए, हमें पता चला कि यह अक्सर काम नहीं करता है। फिर, कई प्रयासों के बाद, हमने इस मुद्दे के अन्य सबसे ध्यान देने योग्य हिस्से - सीमा पर ध्यान केंद्रित करने का फैसला किया। यह ज्ञात है कि नेटवर्क की प्रारंभिक दृढ़ परतों में लाइनों, कोण जैसी सरल वस्तुओं पर सक्रियता होती है। सीमा रेखा को "तोड़" कर, हम नेटवर्क को सही ढंग से संख्या के क्षेत्र का पता लगाने से रोक सकते हैं। यह किया जा सकता है, उदाहरण के लिए, कमरे की पूरी सीमा पर एक यादृच्छिक आकार के सफेद वर्गों के रूप में शोर जोड़कर।

इस तरह की तस्वीर को एक ब्लैक बॉक्स मॉडल के साथ एक प्लेटफॉर्म पर अपलोड करने से, हमें एक सफल प्रतिकूल उदाहरण मिला।

अन्य चित्रों के एक सेट पर इस दृष्टिकोण की कोशिश करने के बाद, हमें पता चला कि ब्लैक बॉक्स मॉडल अब एविटो प्लेट का पता नहीं लगा सकता है (सेट को मैन्युअल रूप से इकट्ठा किया गया था, सौ से भी कम तस्वीरें हैं, और यह निश्चित रूप से प्रतिनिधि नहीं है, लेकिन इसे बनाने में बहुत समय लगता है)। एक दिलचस्प अवलोकन: हमला केवल तभी सफल होता है जब एविटो अक्षरों में शोर और एक फ्रेम में यादृच्छिक सफेद वर्गों को मिलाकर, इन विधियों का अलग से उपयोग करने से सफल परिणाम नहीं मिलता है।
नतीजतन, हमने इस एल्गोरिथ्म को ठेस में रोल आउट किया, और यहां जो बताया गया है :)
कई विज्ञापन मिले


कुछ फ्रेशर:
हमने विज्ञापन प्लेटफ़ॉर्म में भी प्रवेश किया:
कुल मिलाकर
नतीजतन, हम एक प्रतिकूल हमला करने में कामयाब रहे, जो हमारे कार्यान्वयन में छवि प्रसंस्करण समय को नहीं बढ़ाता है। हमले को बनाने में हमने जो समय बिताया वह नए साल से दो हफ्ते पहले का है। यदि इस समय के दौरान ऐसा करना संभव नहीं था, तो उन्होंने वॉटरमार्क रखा होगा। अब प्रतिकूल लाइसेंस प्लेट अक्षम हो गई है, क्योंकि अब एक प्रतियोगी उपयोगकर्ताओं को कॉल करता है, उन्हें विज्ञापन को स्वयं फोटो अपलोड करने या इंटरनेट से स्टॉक वाले कार की तस्वीरों को बदलने की पेशकश करता है।