नमस्कार, हेब्र! मैं आपके लिए मैटिक लुबज के लेख " लैंड कवर क्लासिफिकेशन विद ई-लर्न: पार्ट 1 " का अनुवाद प्रस्तुत करता हूं।
भाग २
भाग 3
प्रस्तावना
लगभग छह महीने पहले, GitHub पर ई- लर्निग रिपॉजिटरी के लिए पहला कमिट किया गया था। आज, eo-learn एक अद्भुत ओपन सोर्स लाइब्रेरी के रूप में विकसित हुआ है, जो किसी ऐसे व्यक्ति द्वारा उपयोग के लिए तैयार है जो ईओ (अर्थ ऑब्जर्वेशन - आदि) ट्रांस में रुचि रखता है। डेटा। मशीन सीखने के उपयोग के लिए आवश्यक उपकरण बनाने के चरण से साइनर्जिस टीम में हर कोई संक्रमण के क्षण का इंतजार कर रहा था । eo-learn का उपयोग करके आपको भूमि कवर के वर्गीकरण के बारे में लेखों की एक श्रृंखला शुरू करने का समय है
eo-learn लर्निंग एक खुला स्रोत पायथन पुस्तकालय है जो पृथ्वी अवलोकन / रिमोट सेंसिंग को पाइथन मशीन लर्निंग लाइब्रेरी के पारिस्थितिकी तंत्र से जोड़ने वाले पुल के रूप में कार्य करता है। हमने पहले से ही अपने ब्लॉग पर एक अलग पोस्ट लिखी है, जिसे हम अनुशंसा करते हैं कि आप खुद को परिचित करें। लाइब्रेरी में उपग्रहों के डेटा को स्टोर करने और हेरफेर करने के लिए, numpy और shapely पुस्तकालयों से numpy का उपयोग किया जाता है। फिलहाल, यह GitHub रिपॉजिटरी में उपलब्ध है , और प्रलेखन ReadTheDocs के उपयुक्त लिंक पर उपलब्ध है।

प्रहरी -2 उपग्रह छवि और सर्दियों में स्लोवेनिया के एक छोटे से क्षेत्र का NDVI मुखौटा
eo-learn की क्षमताओं का प्रदर्शन करने के eo-learn , हमने 2017 के आंकड़ों का उपयोग करते हुए स्लोवेनिया गणराज्य (उस देश जहां हम रहते हैं) के क्षेत्र के कवर को वर्गीकृत करने के लिए अपने बहु-अस्थायी कन्वेयर का उपयोग करने का निर्णय लिया। चूंकि पूरी प्रक्रिया एक लेख के लिए बहुत जटिल हो सकती है, इसलिए हमने इसे तीन भागों में विभाजित करने का निर्णय लिया। इसके लिए धन्यवाद, कदमों को छोड़ने और तुरंत मशीन सीखने की आवश्यकता नहीं है - पहले हमें उस डेटा को समझना होगा जिसे हम काम करते हैं। प्रत्येक लेख ज्यूपिटर नोटबुक उदाहरण के साथ होगा। इसके अलावा, रुचि रखने वालों के लिए, हमने सभी चरणों को कवर करते हुए एक पूर्ण उदाहरण तैयार किया है।
- पहले लेख में, हम आपको रुचि के क्षेत्र (इसके बाद - AOI, ब्याज का क्षेत्र) का चयन / विभाजन के लिए प्रक्रिया के माध्यम से मार्गदर्शन करेंगे, और आवश्यक जानकारी प्राप्त करेंगे, जैसे कि उपग्रह सेंसर और क्लाउड मास्क से डेटा। हम एक उदाहरण भी दिखाते हैं कि वेक्टर डेटा से किसी क्षेत्र के वास्तविक कवरेज पर डेटा का रास्टर मास्क कैसे बनाया जाए। विश्वसनीय परिणाम प्राप्त करने के लिए ये सभी आवश्यक कदम हैं।
- दूसरे भाग में, हम मशीन सीखने की प्रक्रिया के लिए डेटा की तैयारी में सिर को डुबोते हैं। इस प्रक्रिया में पिक्सल्स के प्रशिक्षण के सत्यापन के लिए यादृच्छिक नमूने लेना, क्लाउड छवियों को हटाना, "छेद" आदि में अस्थायी डेटा को प्रक्षेपित करना शामिल है।
- तीसरे भाग में हम क्लासिफायर के प्रशिक्षण और सत्यापन पर विचार करेंगे, साथ ही, निश्चित रूप से, सुंदर ग्राफिक्स!

प्रहरी -2 उपग्रह छवि और गर्मियों में स्लोवेनिया में एक छोटे से क्षेत्र का NDVI मुखौटा
ब्याज का क्षेत्र? चुनें!
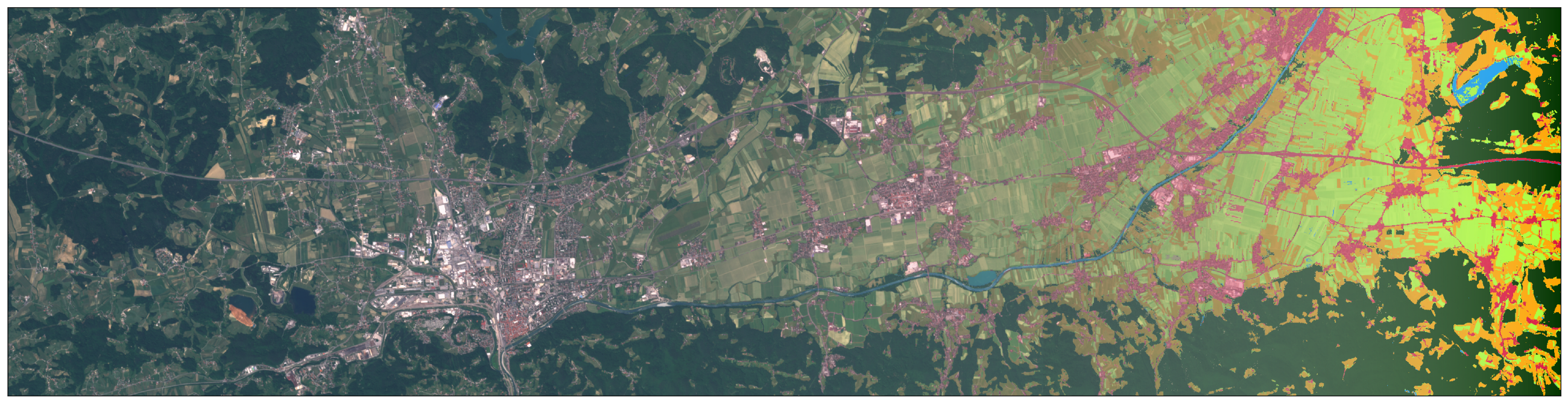
eo-learn लाइब्रेरी आपको एओआई को छोटे टुकड़ों में विभाजित करने की अनुमति देता है जिन्हें सीमित कंप्यूटिंग संसाधनों की शर्तों में संसाधित किया जा सकता है। इस उदाहरण में, स्लोवेनियाई सीमा प्राकृतिक पृथ्वी से ली गई थी, हालांकि, आप किसी भी आकार के क्षेत्र का चयन कर सकते हैं। हमने सीमा पर एक बफर भी जोड़ा, जिसके बाद AOI का आयाम लगभग 250x170 किमी था। geopandas और shapely पुस्तकालयों के जादू का उपयोग करके, हमने एओआई को तोड़ने के लिए एक उपकरण बनाया। इस मामले में, हमने 10 मी के रिज़ॉल्यूशन में 1000x1000 पिक्सल के ~ 300 टुकड़े प्राप्त किए, जिसके परिणामस्वरूप हमने उसी आकार के 25x17 वर्गों में क्षेत्र को विभाजित किया। टुकड़ों में विभाजित करने के बारे में निर्णय उपलब्ध कंप्यूटिंग शक्ति के आधार पर किया जाता है। इस कदम के परिणामस्वरूप, हमें एओआई को कवर करने वाले वर्गों की एक सूची मिलती है।

AOI (स्लोवेनिया का क्षेत्र) 10 मी के रिज़ॉल्यूशन में लगभग 1000x1000 पिक्सल के आकार के साथ छोटे वर्गों में विभाजित है।
प्रहरी उपग्रहों से डेटा प्राप्त करना
वर्गों को निर्धारित करने के बाद, eo-learn आपको सेंटिनल उपग्रहों से डेटा को स्वचालित रूप से डाउनलोड करने की अनुमति देता है। इस उदाहरण में, हमें सभी प्रहरी -2 एल 1 सी चित्र मिलते हैं जो 2017 में लिए गए थे। यह ध्यान देने योग्य है कि प्रहरी -2 एल 2 ए उत्पादों, साथ ही अतिरिक्त डेटा स्रोत (लैंडसैट -8, प्रहरी -1) को इसी तरह से पाइपलाइन में जोड़ा जा सकता है। यह भी ध्यान देने योग्य है कि एल 2 ए उत्पादों के उपयोग से वर्गीकरण परिणामों में सुधार हो सकता है, लेकिन हमने समाधान की बहुमुखी प्रतिभा के लिए एल 1 सी का उपयोग करने का निर्णय लिया। यह sentinelhub-py का उपयोग करके किया गया था, एक पुस्तकालय जो सेंटिनल-हब सेवाओं पर एक आवरण की तरह काम करता है। अनुसंधान संस्थानों और स्टार्ट-अप के लिए इन सेवाओं का उपयोग करना नि: शुल्क है, लेकिन अन्य मामलों में यह सदस्यता के लिए आवश्यक है।

अलग-अलग दिनों में एक टुकड़े की रंगीन छवियां। कुछ छवियां बादल हैं, जिसका अर्थ है कि क्लाउड डिटेक्टर की आवश्यकता है।
प्रहरी डेटा के अलावा, eo-learn आपको पारदर्शी रूप से क्लाउड और क्लाउड प्रायिकता डेटा का उपयोग करने के लिए s2cloudless लाइब्रेरी के लिए धन्यवाद s2cloudless है। यह पुस्तकालय पिक्सेल द्वारा स्वचालित रूप से बादलों का पता लगाने के लिए उपकरण प्रदान करता है। विवरण यहाँ पढ़ा जा सकता है ।
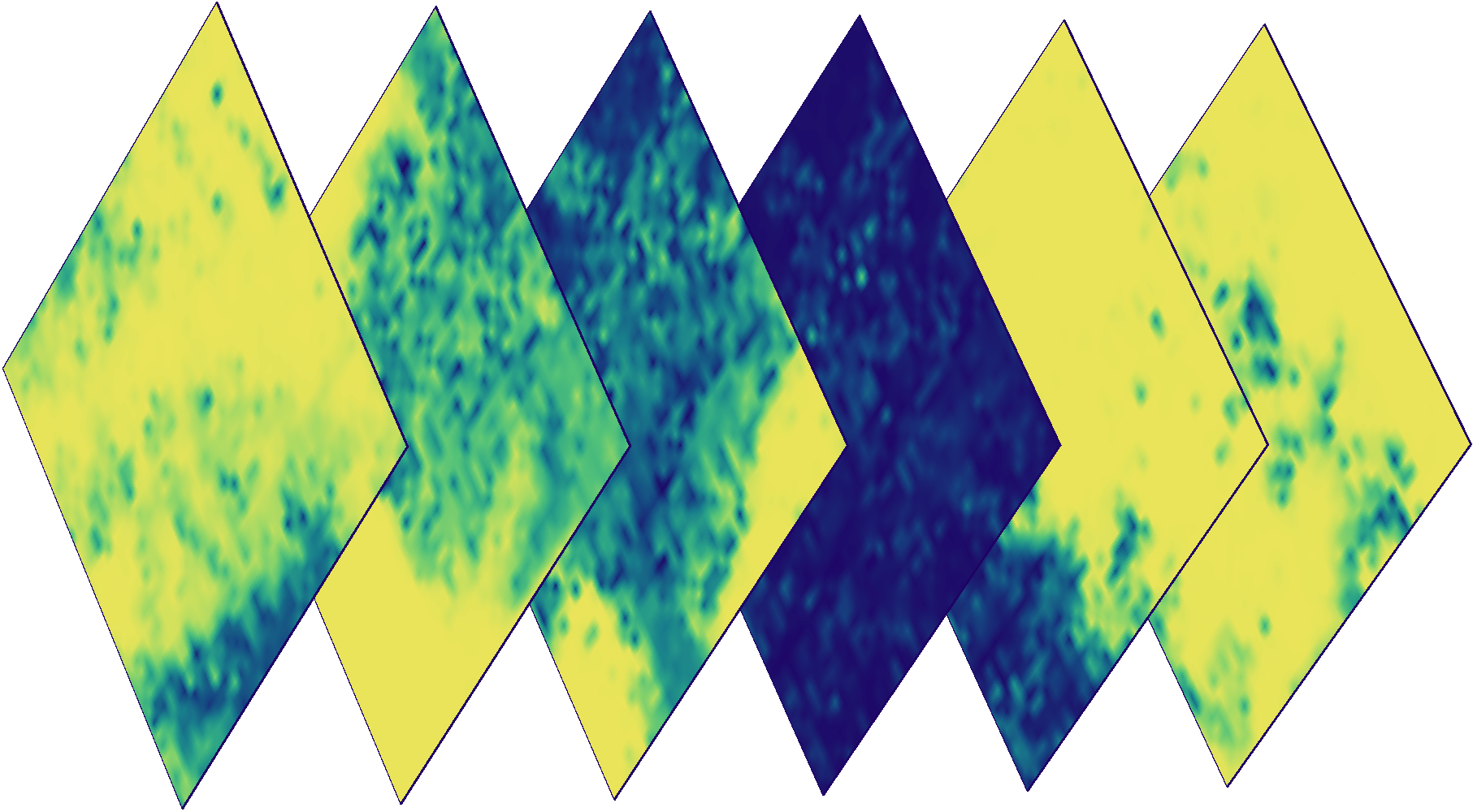
ऊपर की छवियों के लिए क्लाउड मास्क। रंग एक विशिष्ट पिक्सेल (नीला - कम संभावना, पीला - उच्च) के बादल की संभावना को इंगित करता है।
रियल डेटा जोड़ना
एक शिक्षक के साथ पढ़ाने के लिए वास्तविक डेटा या सत्य के साथ एक कार्ड की आवश्यकता होती है । अंतिम शब्द को शाब्दिक रूप से नहीं लिया जाना चाहिए, क्योंकि वास्तव में, डेटा केवल सतह पर एक अनुमान है। दुर्भाग्य से, क्लासिफायर का व्यवहार दृढ़ता से इस कार्ड की गुणवत्ता पर निर्भर करता है ( हालांकि, मशीन सीखने के अधिकांश अन्य कार्यों के लिए )। लेबल किए गए मानचित्र सबसे अधिक बार आकार डेटा में वेक्टर डेटा के रूप में उपलब्ध हैं (उदाहरण के लिए, राज्य या समुदाय द्वारा प्रदान किए गए)। eo-learn में रैस्टर मास्क के रूप में वेक्टर डेटा को रेखांकन के लिए उपकरण शामिल हैं।

एक वर्ग के उदाहरण का उपयोग करके डेटा को मुखौटे में रेखांकन करने की प्रक्रिया। एक वेक्टर फ़ाइल में बहुभुज को बाईं छवि पर दिखाया गया है, प्रत्येक लेबल के लिए रेखापुंज मास्क मध्य में दिखाए जाते हैं - काले और सफेद रंग क्रमशः एक विशिष्ट विशेषता की उपस्थिति और अनुपस्थिति का संकेत देते हैं। सही छवि एक संयुक्त रेखापुंज मुखौटा दिखाती है जिसमें विभिन्न रंग अलग-अलग लेबल इंगित करते हैं।
यह सब एक साथ रखना
ये सभी कार्य बिल्डिंग ब्लॉकों की तरह व्यवहार करते हैं जिन्हें प्रत्येक वर्ग के लिए किए गए कार्यों के सुविधाजनक अनुक्रम में जोड़ा जा सकता है। संभावित रूप से बहुत बड़ी संख्या में ऐसे टुकड़े होने के कारण, पाइपलाइन स्वचालन बिल्कुल आवश्यक है
वास्तविक डेटा को जानना इस तरह के कार्यों के साथ काम करने का पहला चरण है। सेंटिनल -2 के डेटा के साथ जोड़े गए क्लाउड मास्क का उपयोग करके, आप सभी पिक्सेल की गुणवत्ता टिप्पणियों की संख्या, साथ ही किसी विशेष क्षेत्र में बादलों की औसत संभावना निर्धारित कर सकते हैं। इसके लिए धन्यवाद, आप मौजूदा डेटा को बेहतर ढंग से समझ सकते हैं, और आगे की समस्याओं को डीबग करते समय इसका उपयोग कर सकते हैं।

रंग छवि (बाएं), 2017 (केंद्र) के लिए गुणवत्ता माप की संख्या का मुखौटा, और एओआई से यादृच्छिक टुकड़े के लिए 2017 (दाएं) के लिए औसत क्लाउड कवर संभावना।
बादलों को नजरअंदाज करते हुए किसी को औसत एनडीवीआई में दिलचस्पी हो सकती है। क्लाउड मास्क का उपयोग करके, आप बिना डेटा के पिक्सेल को अनदेखा करते हुए, किसी भी सुविधा के औसत मूल्य की गणना कर सकते हैं। इस प्रकार, मास्क के लिए धन्यवाद, हम अपने डेटा में लगभग किसी भी सुविधा के लिए शोर से छवियों को साफ कर सकते हैं।
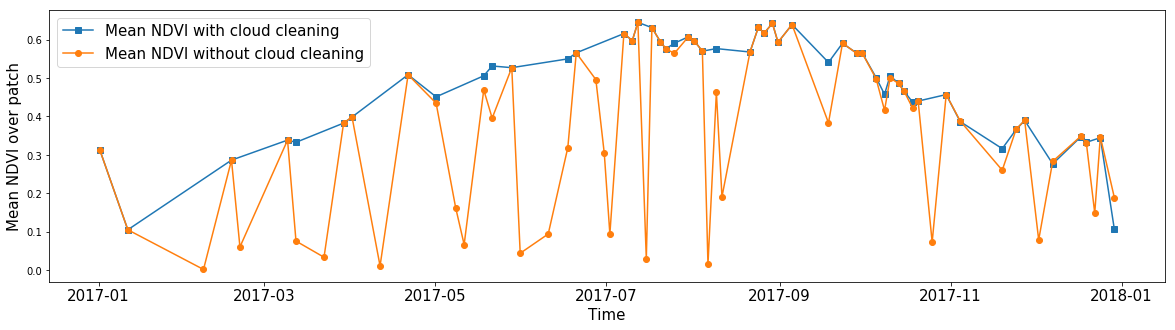
पूरे साल में एक यादृच्छिक AOI टुकड़े में सभी पिक्सेल का औसत NDVI। नीली रेखा बादलों के अंदर के मूल्यों की अनदेखी करते हुए प्राप्त गणना परिणाम दिखाती है। जब सभी पिक्सेल को ध्यान में रखा जाता है, तो नारंगी रेखा औसत मान दिखाती है।
"लेकिन स्केलिंग के बारे में क्या?"
जब हम एक टुकड़े के उदाहरण का उपयोग करके अपने कन्वेयर को स्थापित करते हैं, तो जो कुछ भी किया जाता है वह स्वचालित रूप से सभी टुकड़ों के लिए एक समान प्रक्रिया शुरू करना है (समानांतर में, यदि संसाधन अनुमति देते हैं), जबकि आप एक कप कॉफी के साथ आराम करते हैं और सोचते हैं कि बॉस कितना सुखद होगा। आपके काम के परिणाम। पाइपलाइन की समाप्ति के बाद, आप उस डेटा को निर्यात कर सकते हैं जिसे आप किसी एक छवि में जियोटीफ़ प्रारूप में रुचि रखते हैं। स्क्रिप्ट gdal_merge.py छवियों को प्राप्त करता है और उन्हें जोड़ता है, जिसके परिणामस्वरूप एक चित्र पूरे देश को कवर करता है।
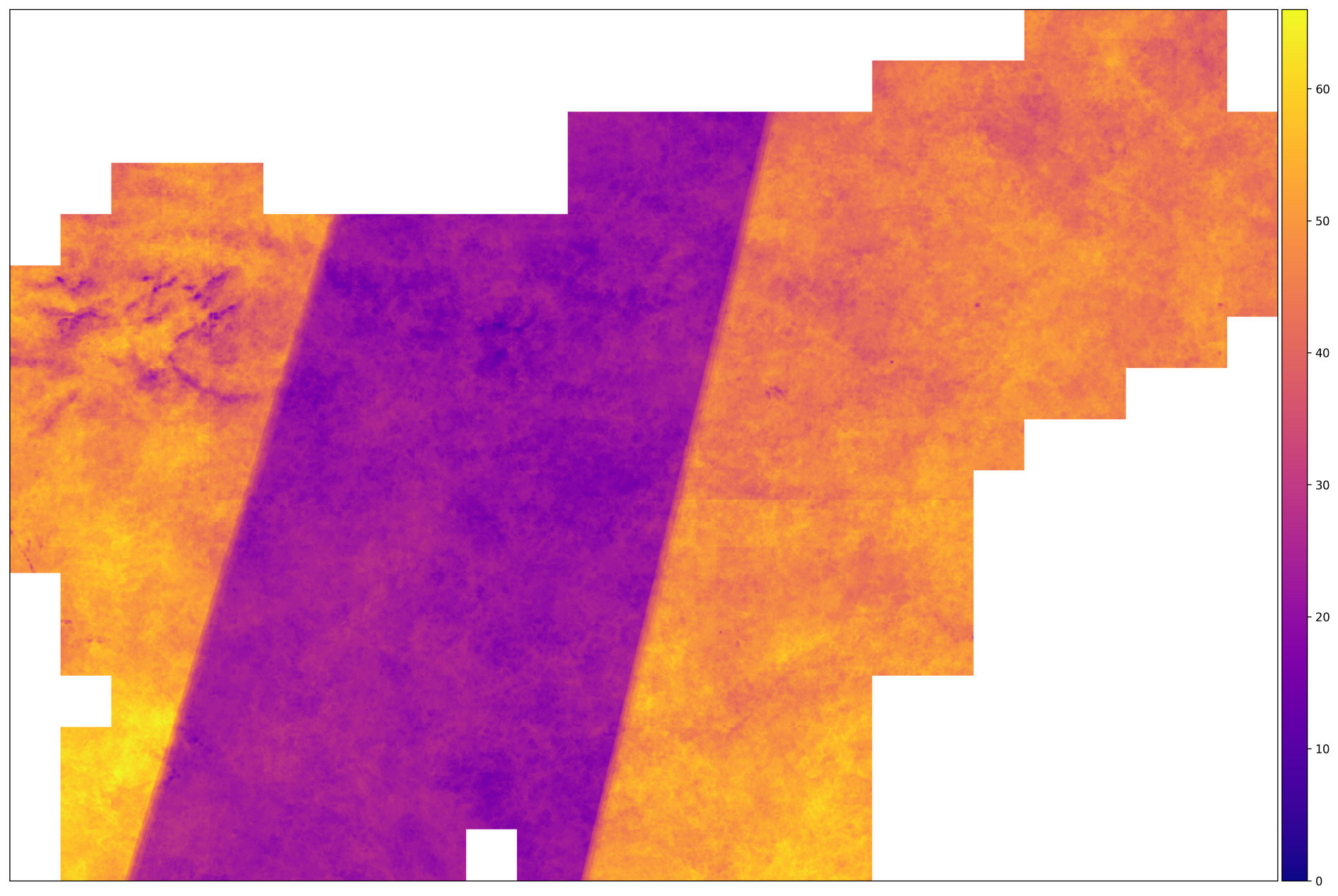
2017 में एओआई के लिए सही शॉट्स की संख्या। बड़ी संख्या में छवियों वाले क्षेत्र उस क्षेत्र पर स्थित हैं जहां प्रहरी -2 ए और प्रहरी -2 बी उपग्रहों के प्रक्षेपवक्र हैं। बीच में ऐसा नहीं होता है।
ऊपर की छवि से, हम यह निष्कर्ष निकाल सकते हैं कि इनपुट डेटा विषम है - कुछ टुकड़ों के लिए, छवियों की संख्या दूसरों की तुलना में दो गुना अधिक है। इसका मतलब है कि हमें डेटा को सामान्य करने के लिए उपाय करने की आवश्यकता है - जैसे कि समय अक्ष के साथ प्रक्षेप।
निर्दिष्ट पाइपलाइन के निष्पादन में एक टुकड़े के लिए लगभग 140 सेकंड का समय लगता है, जो कुल AOI में प्रक्रिया शुरू करने पर ~ 12 घंटे देता है। इस समय का अधिकांश उपग्रह डेटा डाउनलोड कर रहा है। वर्णित कॉन्फ़िगरेशन के साथ औसत असम्पीडित टुकड़ा लगभग 3 जीबी लेता है, जो कुल एओआई के लिए ~ 1 टीबी स्थान देता है।
ज्यूपिटर नोटबुक में उदाहरण
eo-learn कोड के एक आसान परिचय के लिए, हमने इस पोस्ट में चर्चा किए गए विषयों को कवर करने के लिए एक उदाहरण तैयार किया है। उदाहरण को ज्यूपिटर नोटपैड के रूप में डिज़ाइन किया गया है, और आप इसे eo-learn पैकेज के उदाहरण निर्देशिका में पा सकते हैं।