लेख का शीर्षक अजीब और अच्छे कारण के लिए लग सकता है - यह सुंदर रूप से ठीक है क्योंकि यह मेरे द्वारा नहीं लिखा गया है, लेकिन LSTM तंत्रिका नेटवर्क (या बल्कि, "या" से पहले इसका हिस्सा)।
(LSTM नेटवर्क से समझी गई LSTM योजना)
और आज हम यह पता लगाएंगे कि आप हैबर के लेखों के शीर्षक कैसे बना सकते हैं (और, सिद्धांत रूप में, पाठ को उसी न्यूरो-आर्किटेक्चर द्वारा उत्पन्न किया जा सकता है)। सभी कोड Google से नोटबुक में ऑनलाइन चलाने के लिए उपलब्ध है। डेटा, हमेशा की तरह, जीथब पर खुला है।
और यहां आप Google से (निशुल्क और बिना एसएमएस के) GPU पर पहले से ही प्रशिक्षित मॉडल चला सकते हैं और वास्तव में हेडर उत्पन्न कर सकते हैं।
मुख्य लिंक
इस लेख में तंत्रिका नेटवर्क (विशेष रूप से LSTM) का सिद्धांत और विवरण आधारित है
डेटा विवरण
कुल मिलाकर, लगभग 40k लेख शीर्षक एकत्र किए गए: प्रत्येक शीर्षक को दो विशेष पात्रों <START_CHAR> और <END_CHAR> के साथ शुरुआत और अंत में, साथ ही <PADDING_CHAR> <END_CHAR> शीर्षक के अधिकतम आकार के साथ पूरक किया गया था।
एकत्रित आंकड़ों का एक उदाहरण:
Google IT . Now it's official
LSTM सिद्धांत
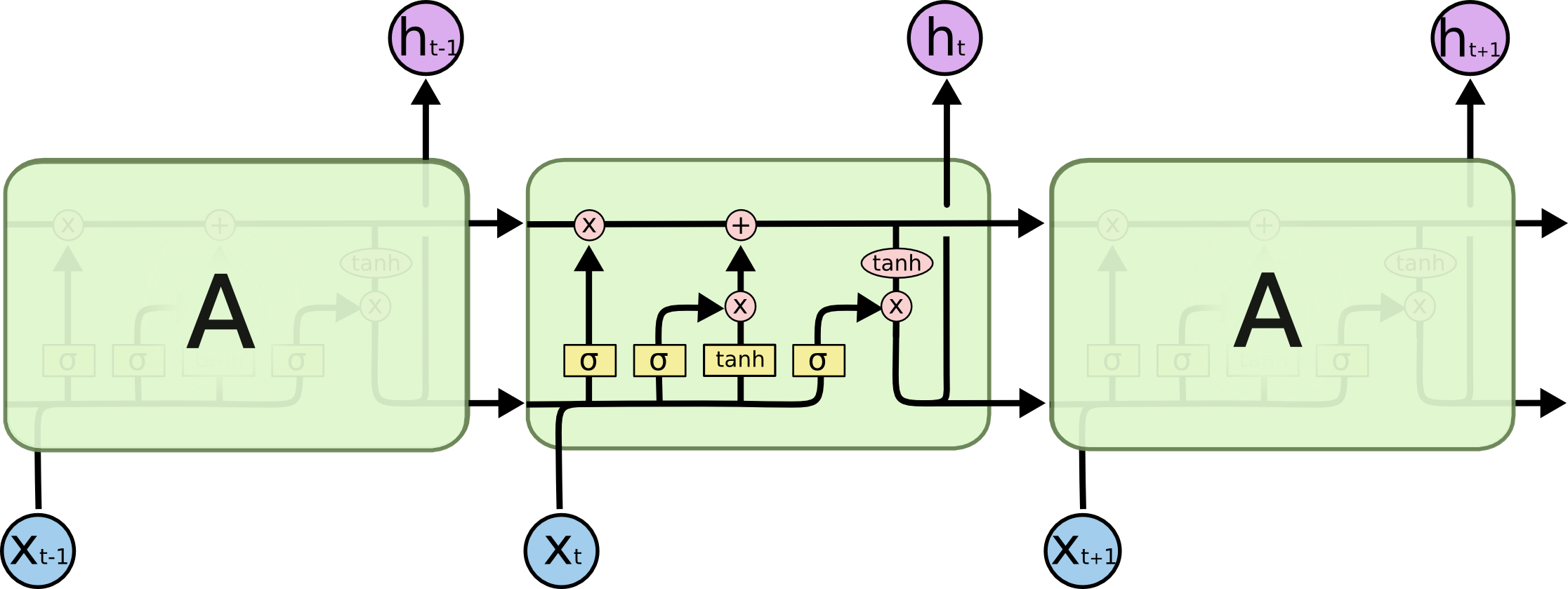
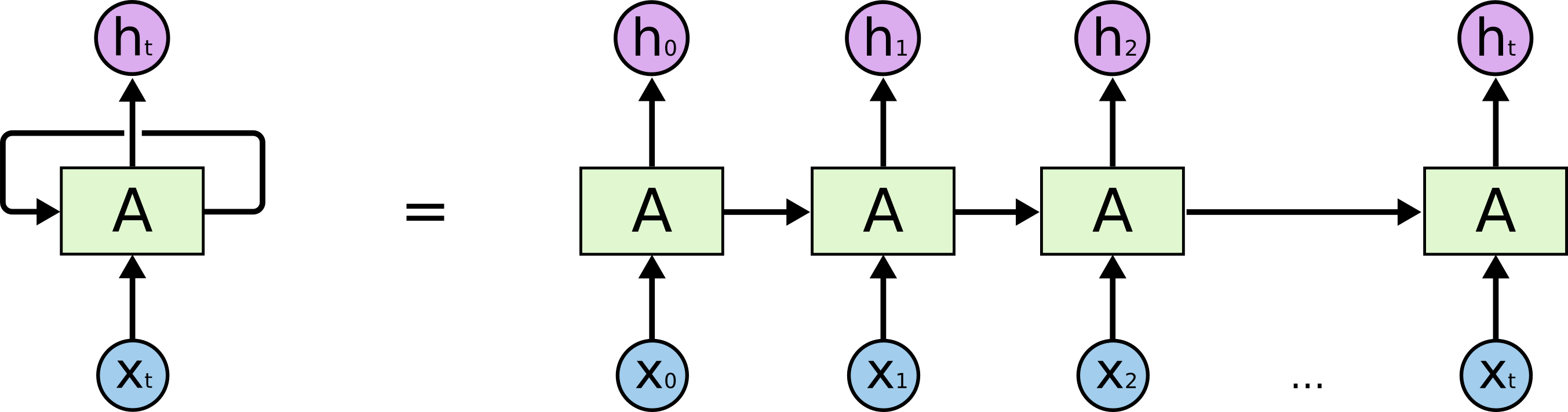
आइए हम जिस वास्तविक कार्य को हल कर रहे हैं, उसके साथ शुरू करें: हम N वर्णों में (N + 1) th लाइन की भविष्यवाणी करना चाहते हैं, LSTM मॉडल के दृष्टिकोण से, यह नीचे दी गई तस्वीर की तरह दिखता है: X नीचे - इनपुट डेटा; h ऊपर ऊपर सप्ताहांत हैं; उनके बीच नेटवर्क की आंतरिक स्थिति है। थोड़ा और विस्तार में - एक प्रतिक्रिया लूप के साथ बाईं ओर छवि, दाईं ओर एक विस्तृत श्रृंखला के बराबर।
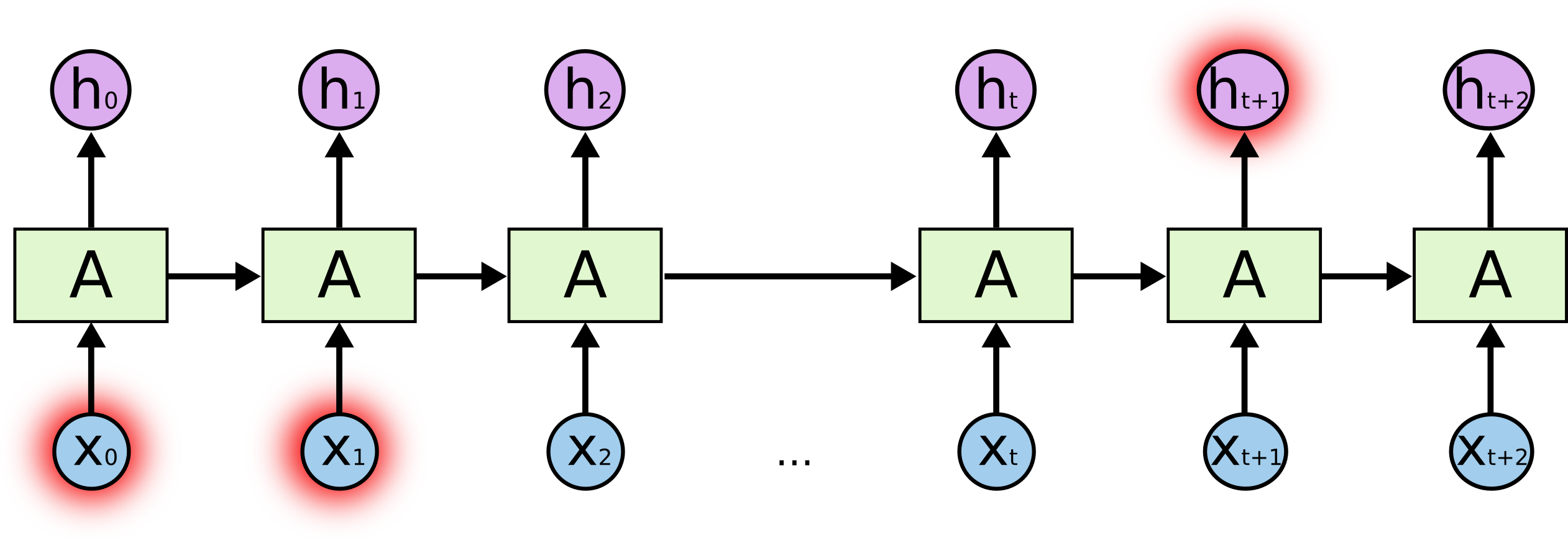
नमक क्या है? अंत में एक हाइलाइट किए गए चरित्र की भविष्यवाणी करने में, शुरुआत में हाइलाइट किए गए किरदार एक महत्वपूर्ण भूमिका निभा सकते हैं - इसलिए दीर्घकालिक निर्भरता शब्द। यह स्पष्ट है कि अक्सर उनके बगल में खड़े पात्र महत्वपूर्ण भूमिका निभाते हैं - इस तरह की निर्भरता को शॉर्ट-टर्म डिपेंडेंसी कहा जाता है।
LSTM सेल इंटर्नल्स:
पूरे सेल में चार मूल तत्व होते हैं।
- भूलने के द्वार - एक तत्व यह तय करता है कि यह स्मृति से बाहर निकल जाएगा
- आने वाले गेट - यह "उम्मीदवार मूल्यों" का एक सेट बनाता है जिसे हम मेमोरी लिखने और अपडेट करने के लिए उपयोग कर सकते हैं
- मेमोरी - एक तत्व यह तय करता है कि वास्तव में और हम कैसे बचाते हैं
- आउटपुट एलिमेंट - मॉडल के आउटपुट को परिभाषित करता है
लीजेंड:

भूलने का द्वार
यदि हम एक शब्द के अंत की भविष्यवाणी करने की कोशिश कर रहे हैं - वर्तमान संज्ञा के लिंग को जानना महत्वपूर्ण है, अगर हमने एक नई संज्ञा देखी - यह पिछले अर्थ को भूल जाने के लायक है:

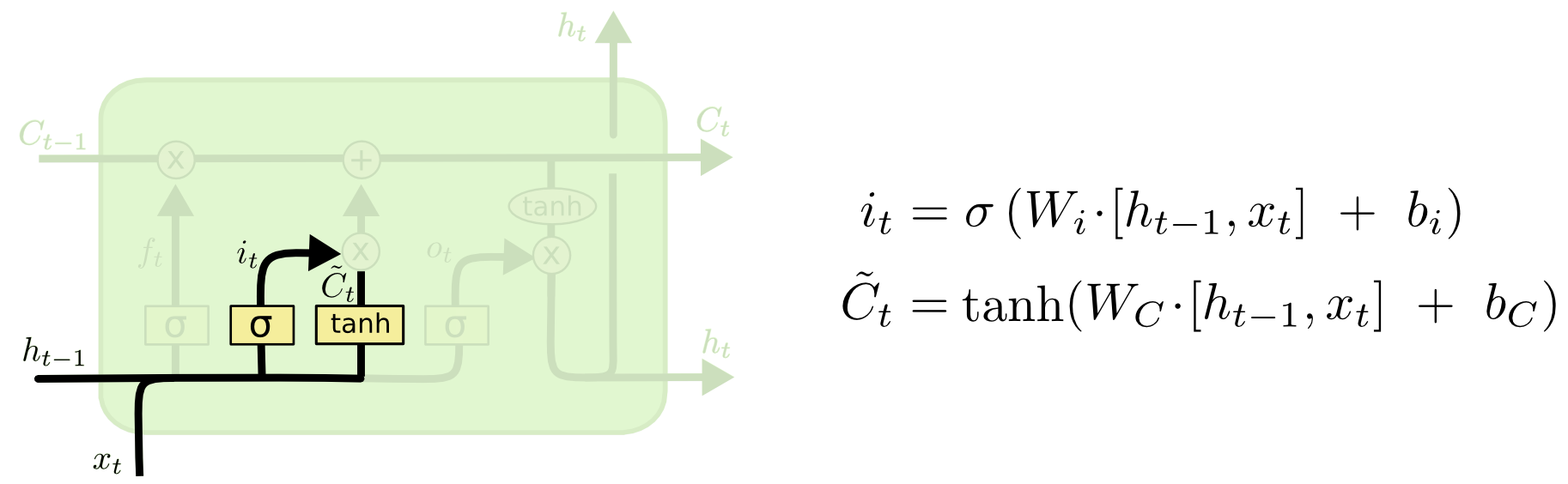
आने वाला गेट
अगला, हम i t की गणना करते हैं, जो यह निर्धारित करेगा कि हम मेमोरी सेल के किन मूल्यों को अपडेट करना चाहते हैं, और
अद्यतन के लिए उम्मीदवार के मूल्यों की गणना करता है।
मेमोरी सेल
इसके बाद, मेमोरी मान वर्तमान स्थिति में हम जो कुछ भूल गए थे और जो हमने जोड़ा था, उसका सुपरपोजिशन है

मॉडल आउटपुट
मॉडल इंट्रेंस क्या है - तीन चीजों का संयोजन: वर्तमान इनपुट प्रतीक, पिछली भविष्यवाणी और मॉडल मेमोरी

कोड
मॉडल का मूल तर्क नीचे एक नियम के रूप में प्रस्तुत किया गया है - यह पूरे कोड का लगभग 5-10% है, बाकी कोड डेटा की तैयारी, प्रसंस्करण और प्रसंस्करण के साथ-साथ मानव-पठनीय रूप में आउटपुट है।
यहां आप पहले से प्रशिक्षित मॉडल के साथ कोड चला सकते हैं।
model = Sequential()
निर्मित हेडर के उदाहरण
व्यक्तिगत नमूना:
python powershell
(डॉ। स्ट्रैंगेलोव के यादृच्छिक मॉडल संदर्भ विशेष रूप से प्रसन्न हैं)
तापमान क्या है (DL के संदर्भ में)
आउटपुट में, मॉडल शब्द के w वजन x w उत्पन्न करता है - हमारे पास विकल्प हैं कि इन वज़न को प्रायिकेशन्स p (w) में कैसे बदलें, उदाहरण के लिए, सूत्र का उपयोग करते हुए:
जहां टी एक निशुल्क पैरामीटर है (भौतिक विज्ञान में यह है कि तापमान सांख्यिकीय रूप से कैसे निर्धारित किया जाता है - इसलिए नाम), कम तापमान - उच्चतर घातांक और अधिक वजन सभी संभावना को दूर ले जाएगा, अर्थात, मॉडल अधिकतम के साथ केवल कुछ शब्दों की भविष्यवाणी करेगा वज़न, यदि तापमान अधिक है, तो वितरण एक समान और अधिक "रचनात्मक" की ओर बढ़ेगा। यह हमें उपलब्ध डेटा और मॉडल की सशर्त रचनात्मकता का सही ढंग से पालन करने के बीच संतुलन को नियंत्रित करने का अवसर देता है।
मॉडल आउटपुट उदाहरण using temperature 0.03 python sql azure federations 2 temperature 0.04 devcon 2013 temperature 0.05 python temperature 0.06 jbreak 2 10 19 temperature 0.07 temperature 0.08 php 10 temperature 0.09 unix oracle temperature 0.1 php temperature 0.11 android android studio github vue js php ruby temperature 0.12 asp net temperature 0.13 google glass using temperature 0.14 android temperature 0.15 python android sql azure federations 2 temperature 0.16 windows python using temperature 0.17 scala apache solr 1 c, 2 3 temperature 0.18 python cpatext content security policy temperature 0.190 52 28 27 nes c 1 3 scanner temperature 0.2 google chrome ms ie
निष्कर्ष
- LSTM आर्किटेक्चर मॉडल अच्छे और स्पष्ट रूप से अनुक्रम करते हैं
- व्याकरण और तर्क अक्सर पीड़ित होते हैं - दो स्थानों पर सबसे अधिक संभावना समस्याएं: पहला, मेमोरी डिवाइस काफी सरल है और सभी नियमों और संदर्भ को पकड़ नहीं सकता है; दूसरा, मामले की शक्ति - डाटासेट काफी छोटा है और बहुत अधिक विविध नहीं है
- रूसी भाषा के बड़े मामले में बेहतर भाषा मॉडल और उनके निहितार्थ के संस्करण पर एक नज़र डालना दिलचस्प होगा - यह समझने के लिए कि क्या वास्तुकला और एक अधिक शक्तिशाली मामला इन समस्याओं को हल करता है
- कुछ सुर्खियों में अविश्वसनीय रूप से हास्यास्पद और आत्म-विडंबना सामने आई, उदाहरण के लिए, "... और इसके लिए दोष क्यों"
- उदाहरण के लिए, हमर शीर्षकों की कुछ नियमितताएँ देखते हैं, उदाहरण के लिए, "हमने बनाया \ निर्मित \", एक स्पष्ट संकेतक जो लोग हबर पर व्यक्तिगत कहानियों को साझा करना पसंद करते हैं