पिछले लेखों में हमने PostgreSQL
इंडेक्सिंग इंजन , एक्सेस विधियों के इंटरफ़ेस और निम्न विधियों पर चर्चा की:
हैश इंडेक्स ,
बी- ट्रीज़ ,
जीएसटी ,
एसपी-जीएसटी ,
जीआईएन , और
आरयूएम । इस लेख का विषय ब्रिन इंडेक्स है।
ब्रिन
सामान्य अवधारणा
उन अनुक्रमणिकाओं के विपरीत, जिनके साथ हम पहले ही एकत्र हो चुके हैं, ब्रिन का विचार है कि वे मेल खाने वाली पंक्तियों को देखने की बजाय निश्चित रूप से अनुपयोगी पंक्तियों को देखने से बचें। यह हमेशा एक गलत सूचकांक है: इसमें TID की तालिका पंक्तियाँ बिल्कुल नहीं होती हैं।
सरलीकृत रूप से, BRIN उन स्तंभों के लिए ठीक काम करता है जहां मान तालिका में उनके भौतिक स्थान के साथ संबद्ध होते हैं। दूसरे शब्दों में, यदि ORDER BY खंड के बिना कोई क्वेरी वस्तुतः बढ़ते या घटते क्रम में स्तंभ मान लौटाता है (और उस स्तंभ पर कोई अनुक्रमणिका नहीं हैं)।
यह पहुंच विधि बहुत बड़े विश्लेषणात्मक डेटाबेस के लिए यूरोपीय परियोजना
एक्सल के दायरे में बनाई गई थी, जिसमें कई टेराबाइट या दर्जनों टेराबाइट बड़े हैं। BRIN की एक महत्वपूर्ण विशेषता है जो हमें ऐसी तालिकाओं पर अनुक्रमित बनाने में सक्षम बनाती है जो रखरखाव का एक छोटा आकार और न्यूनतम ओवरहेड लागत है।
यह निम्नानुसार काम करता है। तालिका को उन
श्रेणियों में विभाजित किया गया
है जो कई पृष्ठ बड़े हैं (या कई ब्लॉक बड़े हैं, जो समान है) - इसलिए नाम: ब्लॉक रेंज इंडेक्स, BRIN। सूचकांक प्रत्येक सीमा में डेटा पर
सारांश जानकारी संग्रहीत करता है। एक नियम के रूप में, यह न्यूनतम और अधिकतम मान है, लेकिन यह अलग-अलग होता है, जैसा कि आगे दिखाया गया है। मान लें कि किसी क्वेरी को किया जाता है जिसमें किसी स्तंभ के लिए स्थिति होती है; यदि मांगे गए मान अंतराल में नहीं मिलते हैं, तो पूरी सीमा को छोड़ दिया जा सकता है; लेकिन अगर वे प्राप्त करते हैं, तो सभी ब्लॉकों में सभी पंक्तियों को उनके बीच मिलान वाले लोगों को चुनने के लिए देखना होगा।
BRIN को एक सूचकांक के रूप में नहीं, बल्कि अनुक्रमिक स्कैन के त्वरक के रूप में माना जाना एक गलती होगी। यदि हम प्रत्येक श्रेणी को "आभासी" विभाजन के रूप में मानते हैं तो हम विभाजन के विकल्प के रूप में ब्रिन का संबंध कर सकते हैं।
अब आइए सूचकांक की संरचना के बारे में अधिक विस्तार से चर्चा करें।
संरचना
पहले (अधिक सटीक, शून्य) पृष्ठ में मेटाडेटा शामिल है।
सारांश जानकारी वाले पृष्ठ मेटाडेटा से एक निश्चित ऑफ़सेट पर स्थित हैं। उन पृष्ठों पर प्रत्येक सूचकांक पंक्ति में एक सीमा पर सारांश जानकारी होती है।
मेटा पेज और सारांश डेटा के बीच,
रिवर्स रेंज मैप के साथ पृष्ठ (संक्षिप्त रूप में "रिवैम्प") स्थित हैं। वास्तव में, यह इसी अनुक्रमणिका पंक्तियों को संकेत (TID) का एक सरणी है।
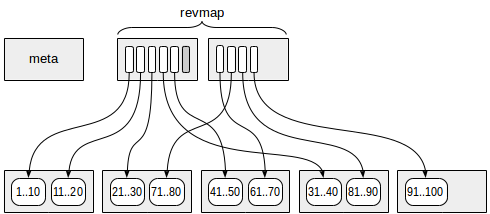
कुछ श्रेणियों के लिए, "रेवमैप" में पॉइंटर से कोई इंडेक्स पंक्ति नहीं हो सकती है (एक आकृति में ग्रे में चिह्नित है)। ऐसे में, इस सीमा को माना जाता है कि अभी तक इसकी कोई जानकारी नहीं है।
सूचकांक को स्कैन करना
यदि सूचकांक में तालिका पंक्तियों का संदर्भ नहीं है तो इसका उपयोग कैसे किया जाता है? यह पहुंच विधि निश्चित रूप से TID द्वारा पंक्तियों को TID नहीं लौटा सकती है, लेकिन यह एक बिटमैप का निर्माण कर सकती है। दो प्रकार के बिटमैप पृष्ठ हो सकते हैं: पृष्ठ पर सटीक, पंक्ति और अशुद्धि। यह एक गलत बिटमैप है जिसका उपयोग किया जाता है।
एल्गोरिथ्म सरल है। श्रेणियों का मानचित्र क्रमिक रूप से स्कैन किया जाता है (अर्थात, तालिका में उनके स्थान के क्रम में श्रेणियों को पार कर लिया जाता है)। प्रत्येक सीमा पर सारांश जानकारी के साथ सूचकांक पंक्तियों को निर्धारित करने के लिए पॉइंटर्स का उपयोग किया जाता है। यदि किसी श्रेणी में मांगी गई मान शामिल नहीं है, तो उसे छोड़ दिया जाता है, और यदि उसमें मान हो सकता है (या सारांश जानकारी अनुपलब्ध है), तो श्रेणी के सभी पृष्ठ बिटमैप में जुड़ जाते हैं। परिणामस्वरूप बिटमैप का उपयोग हमेशा की तरह किया जाता है।
सूचकांक को अद्यतन करना
यह अधिक दिलचस्प है कि तालिका को बदलने पर सूचकांक को कैसे अपडेट किया जाता है।
किसी तालिका पृष्ठ पर पंक्ति का नया संस्करण
जोड़ते समय, हम यह निर्धारित करते हैं कि यह किस सीमा में समाहित है और सारांश जानकारी के साथ सूचकांक पंक्ति को खोजने के लिए श्रेणियों के मानचित्र का उपयोग करें। ये सभी सरल अंकगणितीय ऑपरेशन हैं। उदाहरण के लिए, एक श्रेणी का आकार चार और पृष्ठ 13 पर, 42 के मान के साथ एक पंक्ति संस्करण होना चाहिए। रेंज की संख्या (शून्य से शुरू) 13/4 = 3 है, इसलिए, "रिवाम्प" में हम 3 की ऑफसेट के साथ पॉइंटर लेते हैं (इसकी क्रम संख्या चार है)।
इस श्रेणी के लिए न्यूनतम मूल्य 31 है, और अधिकतम एक 40 है। चूंकि 42 का नया मूल्य अंतराल से बाहर है, हम अधिकतम मूल्य (आंकड़ा देखें) को अपडेट करते हैं। लेकिन अगर नया मान अभी भी संग्रहीत सीमा के भीतर है, तो सूचकांक को अपडेट करने की आवश्यकता नहीं है।

यह सब उस स्थिति से संबंधित है जब पृष्ठ का नया संस्करण उस श्रेणी में होता है जिसके लिए सारांश जानकारी उपलब्ध है। जब सूचकांक बनाया जाता है, तो उपलब्ध सभी श्रेणियों के लिए सारांश जानकारी की गणना की जाती है, लेकिन जब तालिका को और विस्तारित किया जाता है, तो नए पृष्ठ हो सकते हैं जो सीमाओं से बाहर हो सकते हैं। दो विकल्प यहां उपलब्ध हैं:
- आमतौर पर सूचकांक को तुरंत अपडेट नहीं किया जाता है। यह कोई बड़ी बात नहीं है: जैसा कि पहले ही उल्लेख किया गया है, जब सूचकांक को स्कैन करते हैं, तो पूरी सीमा पर ध्यान दिया जाएगा। वास्तविक अद्यतन "वैक्यूम" के दौरान किया जाता है, या इसे "brin_summarize_new_values" फ़ंक्शन को कॉल करके मैन्युअल रूप से किया जा सकता है।
- यदि हम "ऑटोसुममाराइज" पैरामीटर के साथ सूचकांक बनाते हैं, तो अपडेट तुरंत किया जाएगा। लेकिन जब सीमा के पृष्ठ नए मानों से आबाद होते हैं, तो अपडेट अक्सर भी हो सकते हैं, इसलिए, यह पैरामीटर डिफ़ॉल्ट रूप से बंद हो जाता है।
जब नई सीमाएं होती हैं, तो "पुनरावृत्ति" का आकार बढ़ सकता है। जब भी मानचित्र, मेटा पृष्ठ और सारांश डेटा के बीच स्थित होता है, उसे दूसरे पृष्ठ द्वारा विस्तारित करने की आवश्यकता होती है, मौजूदा पंक्ति संस्करणों को कुछ अन्य पृष्ठों पर ले जाया जाता है। तो, श्रेणियों का नक्शा हमेशा मेटा पेज और सारांश डेटा के बीच स्थित होता है।
जब कोई पंक्ति
हटा दी जाती
है , तो ... कुछ नहीं होता है। हम देख सकते हैं कि कभी-कभी न्यूनतम या अधिकतम मूल्य हटा दिया जाएगा, जिस स्थिति में अंतराल को कम किया जा सकता है। लेकिन इसका पता लगाने के लिए, हमें सीमा के सभी मूल्यों को पढ़ना होगा, और यह महंगा है।
सूचकांक की शुद्धता प्रभावित नहीं होती है, लेकिन खोज को वास्तव में आवश्यकता से अधिक श्रेणियों के माध्यम से देखने की आवश्यकता हो सकती है। सामान्य तौर पर, सारांश जानकारी को ऐसे ज़ोन के लिए मैन्युअल रूप से पुनर्गणना की जा सकती है ("brin_desummarize_range" और "brin_summarize_new_values" फ़ंक्शन को कॉल करके), लेकिन हम इस तरह की आवश्यकता का पता कैसे लगा सकते हैं? वैसे भी, कोई भी पारंपरिक प्रक्रिया इसके लिए उपलब्ध नहीं है।
अंत में,
एक पंक्ति को
अपडेट करना पुराने संस्करण का एक विलोपन है और एक नया जोड़ना है।
उदाहरण
चलो
डेमो डेटाबेस की तालिकाओं से डेटा के लिए अपना खुद का मिनी डेटा वेयरहाउस बनाने की कोशिश करते हैं। मान लें कि बीआई रिपोर्टिंग के उद्देश्य के लिए, एक हवाई अड्डे से रवाना होने वाली उड़ानों को प्रतिबिंबित करने के लिए या केबिन में एक सीट की सटीकता के लिए हवाई अड्डे पर उतरा जाने के लिए एक अपसामान्य तालिका की आवश्यकता होती है। प्रत्येक हवाई अड्डे का डेटा दिन में एक बार तालिका में जोड़ा जाएगा, जब यह उचित समय क्षेत्र में मध्यरात्रि है। डेटा को न तो अपडेट किया जाएगा और न ही हटाया जाएगा।
तालिका निम्नानुसार दिखाई देगी:
demo=# create table flights_bi( airport_code char(3), airport_coord point,
हम नेस्टेड लूप का उपयोग करके डेटा को लोड करने की प्रक्रिया को अनुकरण कर सकते हैं: एक बाहरी एक - दिन (हम
एक बड़े डेटाबेस पर विचार करेंगे, इसलिए 365 दिन), और एक आंतरिक लूप - समय क्षेत्र (UTC + 02 से UTC + 12 तक) । प्रश्न बहुत लंबा है और विशेष रुचि का नहीं है, इसलिए मैं इसे स्पॉइलर के नीचे छिपा दूंगा।
भंडारण में डेटा लोड करने का अनुकरण DO $$ <<local>> DECLARE curdate date := (SELECT min(scheduled_departure) FROM flights); utc_offset interval; BEGIN WHILE (curdate <= bookings.now()::date) LOOP utc_offset := interval '12 hours'; WHILE (utc_offset >= interval '2 hours') LOOP INSERT INTO flights_bi WITH flight ( airport_code, airport_coord, flight_id, flight_no, scheduled_time, actual_time, aircraft_code, flight_type ) AS ( ;
demo=# select count(*) from flights_bi;
count ---------- 30517076 (1 row)
demo=# select pg_size_pretty(pg_total_relation_size('flights_bi'));
pg_size_pretty ---------------- 4127 MB (1 row)
हमें 30 मिलियन पंक्तियाँ और 4 जीबी मिलती हैं। इतना बड़ा आकार नहीं, लेकिन एक लैपटॉप के लिए पर्याप्त: अनुक्रमिक स्कैन ने मुझे लगभग 10 सेकंड का समय दिया।
हमें किन स्तंभों पर सूचकांक बनाना चाहिए?
चूँकि BRIN इंडेक्स का आकार छोटा और मध्यम ओवरहेड लागत होता है और अद्यतन अक्सर होता है, यदि कोई हो, तो एक दुर्लभ अवसर कई इंडेक्स "बस के मामले में" बनाने के लिए उठता है, उदाहरण के लिए, उन सभी क्षेत्रों पर, जिन पर विश्लेषक उपयोगकर्ता अपना तदर्थ प्रश्न बना सकते हैं । उपयोगी नहीं होगा - कोई बात नहीं, लेकिन यहां तक कि एक सूचकांक जो बहुत कुशल नहीं है, निश्चित रूप से अनुक्रमिक स्कैन से बेहतर काम करेगा। बेशक, ऐसे क्षेत्र हैं जिन पर सूचकांक बनाना बिल्कुल बेकार है; शुद्ध सामान्य ज्ञान उन्हें संकेत देगा।
लेकिन सलाह के इस टुकड़े तक खुद को सीमित करना अजीब होना चाहिए, इसलिए, एक और अधिक सटीक मानदंड बताने की कोशिश करें।
हमने पहले ही उल्लेख किया है कि डेटा को अपने भौतिक स्थान के साथ कुछ सहसंबंधित होना चाहिए। यहां यह याद रखना समझ में आता है कि PostgreSQL टेबल कॉलम आँकड़े इकट्ठा करता है, जिसमें सहसंबंध मूल्य शामिल हैं। नियोजक इस मान का उपयोग नियमित सूचकांक स्कैन और बिटमैप स्कैन के बीच चयन करने के लिए करता है, और हम इसका उपयोग BRIN सूचकांक की प्रयोज्यता का अनुमान लगाने के लिए कर सकते हैं।
उपरोक्त उदाहरण में, डेटा स्पष्ट रूप से दिनों ("निर्धारित_टाइम" के साथ-साथ "वास्तविक_टाइम" द्वारा - बहुत अधिक अंतर नहीं है) का आदेश दिया जाता है। ऐसा इसलिए है क्योंकि जब पंक्तियों को तालिका में जोड़ा जाता है (बिना विलोप और अपडेट के), तो वे एक के बाद एक फ़ाइल में रखी जाती हैं। डेटा लोडिंग के सिमुलेशन में हमने ORDER BY क्लॉज का भी उपयोग नहीं किया, इसलिए, एक दिन के भीतर तारीखें सामान्य रूप से, एक अनियंत्रित तरीके से मिलाई जा सकती हैं, लेकिन आदेश जगह में होना चाहिए। आइए इसकी जाँच करें:
demo=# analyze flights_bi; demo=# select attname, correlation from pg_stats where tablename='flights_bi' order by correlation desc nulls last;
attname | correlation --------------------+------------- scheduled_time | 0.999994 actual_time | 0.999994 fare_conditions | 0.796719 flight_type | 0.495937 airport_utc_offset | 0.438443 aircraft_code | 0.172262 airport_code | 0.0543143 flight_no | 0.0121366 seat_no | 0.00568042 passenger_name | 0.0046387 passenger_id | -0.00281272 airport_coord | (12 rows)
वह मान जो शून्य के करीब नहीं है (आदर्श रूप से, प्लस-माइनस एक के पास, जैसा कि इस मामले में है), हमें बताता है कि BRIN इंडेक्स उपयुक्त होगा।
यात्रा वर्ग "fare_condition" (कॉलम में तीन अद्वितीय मूल्य हैं) और उड़ान का प्रकार "उड़ान_ प्रकार" (दो अद्वितीय मूल्य) अप्रत्याशित रूप से दूसरे और तीसरे स्थान पर दिखाई दिए। यह एक भ्रम है: औपचारिक रूप से सहसंबंध उच्च है, जबकि कई क्रमिक पृष्ठों पर वास्तव में सभी संभव मानों का सामना करना पड़ेगा, जिसका अर्थ है कि ब्रिन कोई अच्छा नहीं करेगा।
टाइम ज़ोन "Airport_utc_offset" आगे जाता है: माना उदाहरण में, एक दिन के चक्र के भीतर, हवाई अड्डों को टाइम ज़ोन द्वारा "निर्माण द्वारा" आदेश दिया जाता है।
यह इन दो क्षेत्रों, समय और समय क्षेत्र है, जिसे हम आगे प्रयोग करेंगे।
सहसंबंध का कमजोर कमजोर होना
डेटा द्वारा परिवर्तित किए जाने पर "निर्माण द्वारा" सहसंबंध आसानी से कमजोर हो सकता है। और यहां मामला एक विशेष मूल्य के परिवर्तन में नहीं है, लेकिन मल्टीवेरस कॉन्सिरेन्सी कंट्रोल की संरचना में: एक पृष्ठ पर पुराना पंक्ति संस्करण हटा दिया गया है, लेकिन जहां भी मुफ्त स्थान उपलब्ध है, वहां एक नया संस्करण डाला जा सकता है। इसके कारण, अपडेट के दौरान पूरी पंक्तियाँ मिश्रित हो जाती हैं।
हम आंशिक रूप से "फिलफैक्टर" भंडारण पैरामीटर के मूल्य को कम करके और भविष्य के अपडेट के लिए एक पृष्ठ पर खाली जगह छोड़ने के द्वारा इस आशय को नियंत्रित कर सकते हैं। लेकिन क्या हम पहले से ही विशाल तालिका का आकार बढ़ाना चाहते हैं? इसके अलावा, यह विलोपन के मुद्दे को हल नहीं करता है: वे मौजूदा पंक्तियों के अंदर कहीं और स्थान खाली करके नई पंक्तियों के लिए "जाल सेट" भी करते हैं। इसके कारण, जो पंक्तियाँ अन्यथा फ़ाइल के अंत में पहुँच जाएंगी, उन्हें कुछ मनमाने स्थान पर डाला जाएगा।
वैसे, यह एक जिज्ञासु तथ्य है। चूंकि BRIN इंडेक्स में टेबल पंक्तियों के संदर्भ नहीं होते हैं, इसलिए इसकी उपलब्धता HOT अपडेट को बिल्कुल भी बाधित नहीं करना चाहिए, लेकिन यह करता है।
तो, BRIN मुख्य रूप से बड़े और यहां तक कि बड़े आकारों की तालिकाओं के लिए डिज़ाइन किया गया है जो या तो बिल्कुल अद्यतन नहीं हैं या बहुत थोड़े से अपडेट किए गए हैं। हालांकि, यह पूरी तरह से नई पंक्तियों (तालिका के अंत तक) के साथ मुकाबला करता है। यह आश्चर्यजनक नहीं है क्योंकि यह एक्सेस विधि डेटा वेयरहाउस और विश्लेषणात्मक रिपोर्टिंग की दृष्टि से बनाई गई थी।
हमें किस श्रेणी का चयन करने की आवश्यकता है?
यदि हम एक टेराबाइट टेबल से निपटते हैं, तो रेंज के आकार का चयन करते समय हमारी मुख्य चिंता शायद ब्रिन इंडेक्स को बहुत बड़ा नहीं करना है। हालांकि, हमारी स्थिति में, हम डेटा का अधिक सटीक विश्लेषण कर सकते हैं।
ऐसा करने के लिए, हम किसी स्तंभ के अनन्य मानों का चयन कर सकते हैं और देख सकते हैं कि वे कितने पृष्ठ हैं। मानों के स्थानीयकरण से BRIN इंडेक्स को लागू करने में सफलता की संभावना बढ़ जाती है। इसके अलावा, पृष्ठों की संख्या एक श्रेणी के आकार को संकेत देगी। लेकिन यदि मूल्य सभी पृष्ठों पर "फैला हुआ" है, तो BRIN बेकार है।
बेशक, हमें इस तकनीक का उपयोग डेटा की आंतरिक संरचना पर नजर रखना चाहिए। उदाहरण के लिए, यह एक अद्वितीय मूल्य के रूप में प्रत्येक तिथि (अधिक सटीक, एक टाइमस्टैम्प, समय सहित) पर विचार करने के लिए कोई मतलब नहीं है - हमें इसे दिनों के लिए गोल करने की आवश्यकता है।
तकनीकी रूप से, यह विश्लेषण छिपे हुए "ctid" कॉलम के मूल्य को देखकर किया जा सकता है, जो एक पंक्ति संस्करण (TID) को सूचक प्रदान करता है: पृष्ठ की संख्या और पृष्ठ के अंदर पंक्ति की संख्या। दुर्भाग्य से, TID को इसके दो घटकों में विघटित करने की कोई पारंपरिक तकनीक नहीं है, इसलिए, हमें पाठ प्रतिनिधित्व के माध्यम से टाइप करना होगा:
demo=# select min(numblk), round(avg(numblk)) avg, max(numblk) from ( select count(distinct (ctid::text::point)[0]) numblk from flights_bi group by scheduled_time::date ) t;
min | avg | max ------+------+------ 1192 | 1500 | 1796 (1 row)
demo=# select relpages from pg_class where relname = 'flights_bi';
relpages ---------- 528172 (1 row)
हम देख सकते हैं कि प्रत्येक दिन को समान रूप से पृष्ठों पर वितरित किया जाता है, और दिन एक-दूसरे के साथ थोड़ा मिश्रित होते हैं (1500 और गुणा 365 = 547500, जो तालिका 528172 में पृष्ठों की संख्या से थोड़ा ही बड़ा है)। यह वास्तव में वैसे भी "निर्माण द्वारा" स्पष्ट है।
यहाँ बहुमूल्य जानकारी पृष्ठों की एक विशिष्ट संख्या है। 128 पृष्ठों के पारंपरिक रेंज आकार के साथ, प्रत्येक दिन 9-14 श्रेणियों को आबाद करेगा। यह यथार्थवादी लगता है: एक विशिष्ट दिन के लिए क्वेरी के साथ, हम लगभग 10% त्रुटि की उम्मीद कर सकते हैं।
आइए कोशिश करते हैं:
demo=# create index on flights_bi using brin(scheduled_time);
सूचकांक का आकार 184 KB जितना छोटा है:
demo=# select pg_size_pretty(pg_total_relation_size('flights_bi_scheduled_time_idx'));
pg_size_pretty ---------------- 184 kB (1 row)
इस मामले में, सटीकता को खोने की कीमत पर एक सीमा के आकार में वृद्धि करना मुश्किल है। लेकिन यदि आवश्यक हो, तो हम आकार को कम कर सकते हैं, और सटीकता, इसके विपरीत, वृद्धि (सूचकांक के आकार के साथ) कर सकते हैं।
अब समय क्षेत्र को देखते हैं। यहां हम एक ब्रूट-बल दृष्टिकोण का उपयोग नहीं कर सकते हैं। सभी मानों को दिन चक्रों की संख्या से विभाजित किया जाना चाहिए क्योंकि वितरण प्रत्येक दिन के भीतर दोहराया जाता है। इसके अलावा, चूंकि कुछ ही समय क्षेत्र हैं, हम पूरे वितरण को देख सकते हैं:
demo=# select airport_utc_offset, count(distinct (ctid::text::point)[0])/365 numblk from flights_bi group by airport_utc_offset order by 2;
airport_utc_offset | numblk --------------------+-------- 12:00:00 | 6 06:00:00 | 8 02:00:00 | 10 11:00:00 | 13 08:00:00 | 28 09:00:00 | 29 10:00:00 | 40 04:00:00 | 47 07:00:00 | 110 05:00:00 | 231 03:00:00 | 932 (11 rows)
औसतन, हर बार ज़ोन के लिए डेटा एक दिन में 133 पृष्ठों को पॉप्युलेट करता है, लेकिन वितरण अत्यधिक गैर-समान है: पेट्रोपावलोव्स्क-कामचत्स्की और अनादिर छह पृष्ठों के रूप में फिट होते हैं, जबकि मॉस्को और इसके पड़ोस को उनमें से सैकड़ों की आवश्यकता होती है। किसी श्रेणी का डिफ़ॉल्ट आकार यहां अच्छा नहीं है; उदाहरण के लिए, इसे चार पृष्ठों पर सेट करें।
demo=# create index on flights_bi using brin(airport_utc_offset) with (pages_per_range=4); demo=# select pg_size_pretty(pg_total_relation_size('flights_bi_airport_utc_offset_idx'));
pg_size_pretty ---------------- 6528 kB (1 row)
निष्पादन योजना
आइए देखें कि हमारे सूचकांक कैसे काम करते हैं। आइए, किसी दिन का चयन करें, कहते हैं, एक सप्ताह पहले (डेमो डेटाबेस में, "आज" "बुकिंग.वन" फ़ंक्शन द्वारा निर्धारित किया गया है):
demo=# \set d 'bookings.now()::date - interval \'7 days\'' demo=# explain (costs off,analyze) select * from flights_bi where scheduled_time >= :d and scheduled_time < :d + interval '1 day';
QUERY PLAN -------------------------------------------------------------------------------- Bitmap Heap Scan on flights_bi (actual time=10.282..94.328 rows=83954 loops=1) Recheck Cond: ... Rows Removed by Index Recheck: 12045 Heap Blocks: lossy=1664 -> Bitmap Index Scan on flights_bi_scheduled_time_idx (actual time=3.013..3.013 rows=16640 loops=1) Index Cond: ... Planning time: 0.375 ms Execution time: 97.805 ms
जैसा कि हम देख सकते हैं, योजनाकार ने बनाए गए सूचकांक का उपयोग किया। यह कितना सही है? सूचकांक का उपयोग करके लौटे पंक्तियों की कुल संख्या के लिए क्वेरी की शर्तों (बिटमैप हीप नोड के "पंक्तियों" से मिलने वाली पंक्तियों की संख्या का अनुपात) (इसी मूल्य प्लस इंडेक्स द्वारा हटाए गए पंक्तियों को) हमें इस बारे में बताता है। इस मामले में 83954 / (83954 + 12045), जो कि लगभग 90% है, जैसा कि अपेक्षित था (यह मूल्य एक दिन से दूसरे दिन बदल जाएगा)।
बिटमैप इंडेक्स स्कैन नोड की "वास्तविक पंक्तियों" में 16640 नंबर कहाँ से उत्पन्न होता है? बात यह है कि योजना का यह नोड गलत (पृष्ठ-दर-पृष्ठ) बिटमैप बनाता है और बिटमैप को कितनी पंक्तियों को स्पर्श करेगा, इस बारे में पूरी तरह से अनभिज्ञ है, जबकि कुछ दिखाने की आवश्यकता है। इसलिए, निराशा में एक पृष्ठ में 10 पंक्तियों को शामिल किया गया है। बिटमैप में कुल 1664 पृष्ठ हैं (यह मान "हीप ब्लॉक्स: हानिपूर्ण = 1664" में दिखाया गया है); इसलिए, हमें सिर्फ 16640 मिलते हैं। कुल मिलाकर, यह एक संवेदनहीन संख्या है, जिस पर हमें ध्यान नहीं देना चाहिए।
हवाई अड्डों के बारे में कैसे? उदाहरण के लिए, चलो व्लादिवोस्तोक के समय क्षेत्र को लेते हैं, जो एक दिन में 28 पृष्ठ आबाद करता है:
demo=# explain (costs off,analyze) select * from flights_bi where airport_utc_offset = interval '8 hours';
QUERY PLAN ---------------------------------------------------------------------------------- Bitmap Heap Scan on flights_bi (actual time=75.151..192.210 rows=587353 loops=1) Recheck Cond: (airport_utc_offset = '08:00:00'::interval) Rows Removed by Index Recheck: 191318 Heap Blocks: lossy=13380 -> Bitmap Index Scan on flights_bi_airport_utc_offset_idx (actual time=74.999..74.999 rows=133800 loops=1) Index Cond: (airport_utc_offset = '08:00:00'::interval) Planning time: 0.168 ms Execution time: 212.278 ms
योजनाकार फिर से बनाए गए BRIN इंडेक्स का उपयोग करता है। सटीकता बदतर है (इस मामले में लगभग 75%), लेकिन यह उम्मीद है कि सहसंबंध कम होने के बाद से।
कई BRIN इंडेक्स (किसी भी अन्य की तरह) निश्चित रूप से बिटमैप स्तर पर शामिल हो सकते हैं। उदाहरण के लिए, एक महीने के लिए चयनित टाइम ज़ोन पर डेटा (नोटिस "बिटमैप और नोड") है:
demo=# \set d 'bookings.now()::date - interval \'60 days\'' demo=# explain (costs off,analyze) select * from flights_bi where scheduled_time >= :d and scheduled_time < :d + interval '30 days' and airport_utc_offset = interval '8 hours';
QUERY PLAN --------------------------------------------------------------------------------- Bitmap Heap Scan on flights_bi (actual time=62.046..113.849 rows=48154 loops=1) Recheck Cond: ... Rows Removed by Index Recheck: 18856 Heap Blocks: lossy=1152 -> BitmapAnd (actual time=61.777..61.777 rows=0 loops=1) -> Bitmap Index Scan on flights_bi_scheduled_time_idx (actual time=5.490..5.490 rows=435200 loops=1) Index Cond: ... -> Bitmap Index Scan on flights_bi_airport_utc_offset_idx (actual time=55.068..55.068 rows=133800 loops=1) Index Cond: ... Planning time: 0.408 ms Execution time: 115.475 ms
बी-ट्री के साथ तुलना
क्या होगा यदि हम BRIN के समान क्षेत्र पर नियमित B- ट्री इंडेक्स बनाते हैं?
demo=# create index flights_bi_scheduled_time_btree on flights_bi(scheduled_time); demo=# select pg_size_pretty(pg_total_relation_size('flights_bi_scheduled_time_btree'));
pg_size_pretty ---------------- 654 MB (1 row)
यह हमारे BRIN से
कई हजार गुना बड़ा दिखाई दिया! हालाँकि, क्वेरी को थोड़ी तेज़ी से निष्पादित किया जाता है: प्लानर ने आँकड़ों का उपयोग यह जानने के लिए किया कि डेटा को भौतिक रूप से ऑर्डर किया गया है और इसे बिटमैप बनाने की आवश्यकता नहीं है और, मुख्य रूप से, सूचकांक की स्थिति को फिर से जाँचने की आवश्यकता नहीं है:
demo=# explain (costs off,analyze) select * from flights_bi where scheduled_time >= :d and scheduled_time < :d + interval '1 day';
QUERY PLAN ---------------------------------------------------------------- Index Scan using flights_bi_scheduled_time_btree on flights_bi (actual time=0.099..79.416 rows=83954 loops=1) Index Cond: ... Planning time: 0.500 ms Execution time: 85.044 ms
ब्रिन के बारे में इतना अद्भुत है: हम दक्षता का त्याग करते हैं, लेकिन बहुत अधिक स्थान प्राप्त करते हैं।
संचालक वर्ग
minmax
डेटा प्रकारों के लिए जिनके मूल्यों की एक दूसरे के साथ तुलना की जा सकती है, सारांश जानकारी
में न्यूनतम और अधिकतम मान शामिल हैं । संबंधित ऑपरेटर कक्षाओं के नामों में "माइनमैक्स" होता है, उदाहरण के लिए, "डेट_मिनमैक्स_ओप्स"। वास्तव में, ये डेटा प्रकार हैं जो हम अब तक विचार कर रहे थे, और अधिकांश प्रकार इस प्रकार के हैं।
सम्मिलित
तुलना ऑपरेटरों को सभी डेटा प्रकारों के लिए परिभाषित नहीं किया गया है। उदाहरण के लिए, उन्हें बिंदुओं ("बिंदु" प्रकार) के लिए परिभाषित नहीं किया गया है, जो हवाई अड्डों के भौगोलिक निर्देशांक का प्रतिनिधित्व करते हैं। वैसे, यह इस कारण से है कि आंकड़े इस स्तंभ के लिए सहसंबंध नहीं दिखाते हैं।
demo=# select attname, correlation from pg_stats where tablename='flights_bi' and attname = 'airport_coord';
attname | correlation ---------------+------------- airport_coord | (1 row)
लेकिन ऐसे कई प्रकार हमें "बाउंडिंग एरिया" की अवधारणा को पेश करने में सक्षम बनाते हैं, उदाहरण के लिए, ज्यामितीय आकृतियों के लिए एक बाउंडिंग आयत। हमने विस्तार से चर्चा की कि
GiST सूचकांक इस सुविधा का उपयोग कैसे करता है। इसी तरह, BRIN भी इन प्रकार के डेटा प्रकार वाले स्तंभों पर सारांश जानकारी एकत्र करने में सक्षम बनाता है:
एक सीमा के अंदर सभी मूल्यों के लिए सीमा क्षेत्र सिर्फ सारांश मूल्य है।
GiST के विपरीत, BRIN के लिए सारांश मूल्य उसी प्रकार का होना चाहिए, जिस तरह से मूल्यों को अनुक्रमित किया जा रहा है। इसलिए, हम अंकों के लिए सूचकांक का निर्माण नहीं कर सकते, हालांकि यह स्पष्ट है कि निर्देशांक BRIN में काम कर सकते हैं: देशांतर बारीकी से समय क्षेत्र के साथ जुड़ा हुआ है। सौभाग्य से, कुछ भी नहीं है कि एक अभिव्यक्ति पर सूचकांक के निर्माण में गिरावट आयतों में बदलने के बाद। उसी समय, हम एक सीमा के आकार को एक पृष्ठ पर सेट करेंगे, बस सीमा मामले को दिखाने के लिए:
demo=# create index on flights_bi using brin (box(airport_coord)) with (pages_per_range=1);
इतनी विषम परिस्थिति में भी सूचकांक का आकार 30 एमबी जितना छोटा है:
demo=# select pg_size_pretty(pg_total_relation_size('flights_bi_box_idx'));
pg_size_pretty ---------------- 30 MB (1 row)
अब हम उन प्रश्नों को बना सकते हैं जो निर्देशांक द्वारा हवाई अड्डों को सीमित करते हैं। उदाहरण के लिए:
demo=# select airport_code, airport_name from airports where box(coordinates) <@ box '120,40,140,50';
airport_code | airport_name --------------+----------------- KHV | Khabarovsk-Novyi VVO | Vladivostok (2 rows)
हालांकि, योजनाकार हमारे सूचकांक का उपयोग करने से इंकार करेगा।
demo=# analyze flights_bi; demo=# explain select * from flights_bi where box(airport_coord) <@ box '120,40,140,50';
QUERY PLAN --------------------------------------------------------------------- Seq Scan on flights_bi (cost=0.00..985928.14 rows=30517 width=111) Filter: (box(airport_coord) <@ '(140,50),(120,40)'::box)
क्यों? चलो अनुक्रमिक स्कैन को अक्षम करें और देखें कि क्या होता है:
demo=# set enable_seqscan = off; demo=# explain select * from flights_bi where box(airport_coord) <@ box '120,40,140,50';
QUERY PLAN -------------------------------------------------------------------------------- Bitmap Heap Scan on flights_bi (cost=14079.67..1000007.81 rows=30517 width=111) Recheck Cond: (box(airport_coord) <@ '(140,50),(120,40)'::box) -> Bitmap Index Scan on flights_bi_box_idx (cost=0.00..14072.04 rows=30517076 width=0) Index Cond: (box(airport_coord) <@ '(140,50),(120,40)'::box)
ऐसा प्रतीत होता है कि सूचकांक
का उपयोग किया
जा सकता है, लेकिन योजनाकार यह मानता है कि बिटमैप को पूरी मेज पर बनाना होगा (बिटमैप इंडेक्स स्कैन नोड की "पंक्तियों को देखें), और यह कोई आश्चर्य नहीं है कि योजनाकार अनुक्रमिक स्कैन चुनता है" यह मामला। यहाँ मुद्दा यह है कि ज्यामितीय प्रकारों के लिए, PostgreSQL किसी भी आंकड़े को इकट्ठा नहीं करता है, और योजनाकार को आँख बंद करके जाना पड़ता है:
demo=# select * from pg_stats where tablename = 'flights_bi_box_idx' \gx
-[ RECORD 1 ]----------+------------------- schemaname | bookings tablename | flights_bi_box_idx attname | box inherited | f null_frac | 0 avg_width | 32 n_distinct | 0 most_common_vals | most_common_freqs | histogram_bounds | correlation | most_common_elems | most_common_elem_freqs | elem_count_histogram |
अफसोस। लेकिन सूचकांक के बारे में कोई शिकायत नहीं है - यह काम करता है और ठीक काम करता है:
demo=# explain (costs off,analyze) select * from flights_bi where box(airport_coord) <@ box '120,40,140,50';
QUERY PLAN ---------------------------------------------------------------------------------- Bitmap Heap Scan on flights_bi (actual time=158.142..315.445 rows=781790 loops=1) Recheck Cond: (box(airport_coord) <@ '(140,50),(120,40)'::box) Rows Removed by Index Recheck: 70726 Heap Blocks: lossy=14772 -> Bitmap Index Scan on flights_bi_box_idx (actual time=158.083..158.083 rows=147720 loops=1) Index Cond: (box(airport_coord) <@ '(140,50),(120,40)'::box) Planning time: 0.137 ms Execution time: 340.593 ms
निष्कर्ष इस तरह होना चाहिए: अगर कुछ भी ज्यामिति की आवश्यकता होती है तो पोस्टजीआईएस की आवश्यकता होती है। यह वैसे भी आंकड़े इकट्ठा कर सकता है।
internals
पारंपरिक विस्तार "पेजिन्सपेक्ट" हमें ब्रिन इंडेक्स के अंदर देखने में सक्षम बनाता है।
सबसे पहले, मेटैनफॉर्मेशन हमें एक श्रेणी के आकार का संकेत देगा और "पुनरावृत्ति" के लिए कितने पृष्ठ आवंटित किए गए हैं।
demo=# select * from brin_metapage_info(get_raw_page('flights_bi_scheduled_time_idx',0));
magic | version | pagesperrange | lastrevmappage ------------+---------+---------------+---------------- 0xA8109CFA | 1 | 128 | 3 (1 row)
पेज 1-3 यहां "रिवापम" के लिए आवंटित किए गए हैं, जबकि बाकी में सारांश डेटा है। "सुधार" से हम प्रत्येक सीमा के लिए सारांश डेटा के संदर्भ प्राप्त कर सकते हैं। कहते हैं, पहले 128 पृष्ठों को शामिल करते हुए पहली सीमा पर जानकारी यहाँ स्थित है:
demo=# select * from brin_revmap_data(get_raw_page('flights_bi_scheduled_time_idx',1)) limit 1;
pages --------- (6,197) (1 row)
और यह सारांश डेटा ही है:
demo=# select allnulls, hasnulls, value from brin_page_items( get_raw_page('flights_bi_scheduled_time_idx',6), 'flights_bi_scheduled_time_idx' ) where itemoffset = 197;
allnulls | hasnulls | value ----------+----------+---------------------------------------------------- f | f | {2016-08-15 02:45:00+03 .. 2016-08-15 17:15:00+03} (1 row)
अगली सीमा:
demo=# select * from brin_revmap_data(get_raw_page('flights_bi_scheduled_time_idx',1)) offset 1 limit 1;
pages --------- (6,198) (1 row)
demo=# select allnulls, hasnulls, value from brin_page_items( get_raw_page('flights_bi_scheduled_time_idx',6), 'flights_bi_scheduled_time_idx' ) where itemoffset = 198;
allnulls | hasnulls | value ----------+----------+---------------------------------------------------- f | f | {2016-08-15 06:00:00+03 .. 2016-08-15 18:55:00+03} (1 row)
और इसी तरह।
"समावेश" कक्षाओं के लिए, "मान" फ़ील्ड कुछ इस तरह प्रदर्शित करेगा
{(94.4005966186523,69.3110961914062),(77.6600036621,51.6693992614746) .. f .. f}
पहला मान अंतःस्थापित आयत है, और अंत में "f" अक्षर खाली तत्वों (पहले वाले) का अभाव है और एकात्मक मान (दूसरा वाला) का अभाव है। दरअसल, एकमात्र अपरिष्कृत मूल्य "आईपीवी 4" और "आईपीवी 6" पते ("इनट" डेटा प्रकार) हैं।
गुण
आपको उन प्रश्नों की याद दिलाता है
जो पहले ही प्रदान किए जा चुके हैं ।
निम्नलिखित पहुँच विधि के गुण हैं:
amname | name | pg_indexam_has_property --------+---------------+------------------------- brin | can_order | f brin | can_unique | f brin | can_multi_col | t brin | can_exclude | f
कई स्तंभों पर सूचकांक बनाए जा सकते हैं। इस मामले में, प्रत्येक कॉलम के लिए अपने स्वयं के सारांश आंकड़े एकत्र किए जाते हैं, लेकिन वे प्रत्येक श्रेणी के लिए एक साथ संग्रहीत होते हैं। बेशक, यह सूचकांक समझ में आता है कि क्या एक और एक ही श्रेणी का आकार सभी स्तंभों के लिए उपयुक्त है।
निम्नलिखित सूचकांक-परत गुण उपलब्ध हैं:
name | pg_index_has_property ---------------+----------------------- clusterable | f index_scan | f bitmap_scan | t backward_scan | f
जाहिर है, केवल बिटमैप स्कैन समर्थित है।
हालाँकि, क्लस्टरिंग की कमी भ्रामक लग सकती है। लगातार, चूंकि BRIN इंडेक्स पंक्तियों के भौतिक क्रम के प्रति संवेदनशील है, इसलिए यह इंडेक्स के अनुसार डेटा क्लस्टर करने में सक्षम होना तर्कसंगत होगा। लेकिन ऐसा है नहीं। हम इसके अनुसार केवल एक "नियमित" सूचकांक (बी-ट्री या जीएसटी, डेटा प्रकार के आधार पर) और क्लस्टर बना सकते हैं। वैसे, क्या आप एक बहुत बड़ी तालिका को ध्यान में रखते हुए क्लस्टर बनाना चाहते हैं? पुनर्निर्माण के लिए विशेष ताले, निष्पादन का समय और डिस्क स्थान की खपत?
स्तंभ-परत गुण निम्नलिखित हैं:
name | pg_index_column_has_property --------------------+------------------------------ asc | f desc | f nulls_first | f nulls_last | f orderable | f distance_orderable | f returnable | f search_array | f search_nulls | t
केवल उपलब्ध संपत्ति NULLs में हेरफेर करने की क्षमता है।
पर पढ़ें ।