रूसी में पूर्ण पाठ्यक्रम
इस लिंक पर पाया जा सकता है।
इस लिंक पर मूल अंग्रेजी पाठ्यक्रम उपलब्ध है।
 हर 2-3 दिनों में नए व्याख्यान निर्धारित होते हैं।
हर 2-3 दिनों में नए व्याख्यान निर्धारित होते हैं।सेबस्टियन ट्रून, सीईओ उडेसिटी के साथ साक्षात्कार
- तो, हम फिर से आपके और हमारे साथ हैं, पहले की तरह, सेबस्टियन। हम बस पूरी तरह से जुड़े परतों, उन घने परतों पर चर्चा करना चाहते हैं। इससे पहले, मैं एक प्रश्न पूछना चाहूंगा। क्या सीमाएँ हैं और कौन सी मुख्य बाधाएँ हैं जो गहन शिक्षा के रास्ते में खड़ी होंगी और अगले 10 वर्षों में इसका सबसे बड़ा प्रभाव पड़ेगा? सब कुछ इतनी तेजी से बदलता है! आपको क्या लगता है कि अगले "बड़ी बात" होगी?
- मैं दो बातें कहूंगा। पहला सामान्य एआई एक से अधिक कार्य के लिए है। यह महान है! लोग एक से अधिक समस्याओं का समाधान कर सकते हैं और कभी भी ऐसा नहीं करना चाहिए। दूसरा बाजार में तकनीक ला रहा है। मेरे लिए, मशीन लर्निंग की ख़ासियत यह है कि यह कंप्यूटरों को डेटा में अवलोकन करने और पैटर्न खोजने की क्षमता प्रदान करता है, जो लोगों को बेहतर बनाने में मदद करता है - विशेषज्ञ स्तर पर! मशीन लर्निंग का इस्तेमाल कानून, चिकित्सा, स्वायत्त कारों में किया जा सकता है। ऐसे अनुप्रयोगों का विकास करें क्योंकि वे एक बड़ी राशि ला सकते हैं, लेकिन सबसे महत्वपूर्ण बात यह है कि आपके पास दुनिया को बहुत बेहतर जगह बनाने का अवसर है।
"मैं वास्तव में जिस तरह से आप गहरी सीखने की एक तस्वीर और उसके आवेदन में सब कुछ कहते हैं, वह पसंद है - यह सिर्फ एक उपकरण है जो आपको किसी विशेष समस्या को हल करने में मदद कर सकता है।
- हाँ, बिल्कुल! अतुल्य उपकरण, सही?
- हाँ, हाँ, मैं आपसे पूरी तरह सहमत हूँ!
"लगभग एक मानव मस्तिष्क की तरह!"
- आपने वीडियो कोर्स के पहले भाग में हमारे पहले साक्षात्कार में चिकित्सा अनुप्रयोगों का उल्लेख किया है। किन अनुप्रयोगों में, आपकी राय में, गहरी शिक्षा का उपयोग सबसे बड़ी खुशी और आश्चर्य का कारण बनता है?
- बहुत कुछ! बहुत! चिकित्सा उन क्षेत्रों की छोटी सूची पर है जो सक्रिय रूप से गहरी शिक्षा का उपयोग करते हैं। मैंने कुछ महीने पहले अपनी बहन को खो दिया था, वह कैंसर से बीमार थी, जो बहुत दुख की बात है। मुझे लगता है कि कई बीमारियां हैं जो पहले पता चल सकती थीं - प्रारंभिक अवस्था में, उनके विकास की प्रक्रिया को ठीक करना या धीमा करना संभव बनाता है। यह विचार, वास्तव में, कुछ उपकरणों को घर (स्मार्ट होम) में स्थानांतरित करना है, जिससे कि स्वास्थ्य में ऐसे विचलन का पता लगाना संभव हो जाता है, जब व्यक्ति स्वयं उन्हें देखता है। मैं यह भी जोड़ूंगा - सब कुछ दोहराया जाता है, किसी भी कार्यालय का काम, जहां आप एक ही प्रकार के कार्यों को बार-बार करते हैं, उदाहरण के लिए, बहीखाता पद्धति। यहां तक कि मैं, सीईओ के रूप में, कई दोहरावदार कार्रवाई करता हूं। यह उन्हें स्वचालित करने के लिए बहुत अच्छा होगा, यहां तक कि मेल पत्राचार के साथ भी काम करें!
- मैं आपसे असहमत नहीं हो सकता! इस पाठ में, हम छात्रों को एक तंत्रिका नेटवर्क परत के साथ एक पाठ्यक्रम में पेश करेंगे, जिसे घने-परत कहा जाता है। क्या आप हमें अधिक विस्तार से बता सकते हैं कि आप पूरी तरह से जुड़ी हुई परतों के बारे में क्या सोचते हैं?
- तो, आइए इस तथ्य से शुरू करें कि प्रत्येक नेटवर्क को अलग-अलग तरीकों से जोड़ा जा सकता है। उनमें से कुछ में बहुत तंग कनेक्टिविटी हो सकती है, जो आपको बड़े नेटवर्क के खिलाफ स्केलिंग और "जीत" में कुछ लाभ प्राप्त करने की अनुमति देती है। कभी-कभी आपको पता नहीं होता है कि आपको कितने कनेक्शनों की आवश्यकता है, इसलिए आप हर चीज को हर चीज से जोड़ते हैं - इसे पूरी तरह से कनेक्टेड लेयर कहा जाता है। मैं जोड़ता हूं कि इस दृष्टिकोण में बहुत अधिक संरचित की तुलना में बहुत अधिक शक्ति और क्षमता है।
- मैं आपसे पूरी तरह सहमत हूँ! पूरी तरह से जुड़े परतों के बारे में थोड़ा और जानने में हमारी मदद करने के लिए धन्यवाद। मैं उस क्षण का इंतजार कर रहा हूं जब हम अंत में उन्हें लागू करना और कोड लिखना शुरू करते हैं।
- मज़ा आ गया! यह वास्तव में मजेदार होगा!
परिचय
- आपका स्वागत है! अंतिम पाठ में, आपने यह पता लगाया कि TensorFlow और Keras का उपयोग करके अपने पहले तंत्रिका नेटवर्क का निर्माण कैसे करें, तंत्रिका नेटवर्क कैसे काम करते हैं, और प्रशिक्षण (प्रशिक्षण) प्रक्रिया कैसे काम करती है। विशेष रूप से, हमने देखा कि मॉडल को डिग्री सेल्सियस को डिग्री फ़ारेनहाइट में बदलने के लिए कैसे प्रशिक्षित किया जाए।

- हम पूरी तरह से जुड़े परतों (घने परतों) की अवधारणा से भी परिचित हो गए, तंत्रिका नेटवर्क में सबसे महत्वपूर्ण परत है। लेकिन इस पाठ में हम बहुत अधिक शांत चीजें करेंगे! इस पाठ में, हम एक तंत्रिका नेटवर्क विकसित करेंगे जो कपड़ों के तत्वों और छवियों को पहचान सकता है। जैसा कि हमने पहले बताया, मशीन लर्निंग "लेबल" नामक इनपुट का उपयोग करता है और आउटपुट "लेबल" कहलाता है, जिसके द्वारा मॉडल सीखता है और एक परिवर्तन एल्गोरिथ्म पाता है। इसलिए, सबसे पहले, हमें कपड़ों के विभिन्न तत्वों को पहचानने के लिए तंत्रिका नेटवर्क को प्रशिक्षित करने के लिए कई उदाहरणों की आवश्यकता होगी। मैं आपको याद दिलाता हूं कि प्रशिक्षण के लिए एक उदाहरण मूल्यों की एक जोड़ी है - एक इनपुट सुविधा और एक आउटपुट लेबल, जो एक तंत्रिका नेटवर्क के इनपुट को खिलाया जाता है। हमारे नए उदाहरण में, छवि को इनपुट के रूप में उपयोग किया जाएगा, और आउटपुट लेबल को कपड़ों की श्रेणी होनी चाहिए, जिसमें चित्र में दिखाए गए कपड़े आइटम हैं। सौभाग्य से, इस तरह के डेटासेट पहले से मौजूद हैं। इसे फैशन MNIST कहा जाता है। हम अगले भाग में इस डेटासेट पर करीब से नज़र डालेंगे।
फैशन MNIST डेटासेट
MNIST डेटासेट की दुनिया में आपका स्वागत है! तो, हमारे सेट में 28x28 छवियां शामिल हैं, जिनमें से प्रत्येक पिक्सेल ग्रे की एक छाया का प्रतिनिधित्व करता है।

डेटा सेट में टी-शर्ट, टॉप, सैंडल और यहां तक कि बूट की छवियां हैं। यहां हमारे MNIST डेटासेट में पूरी सूची दी गई है:
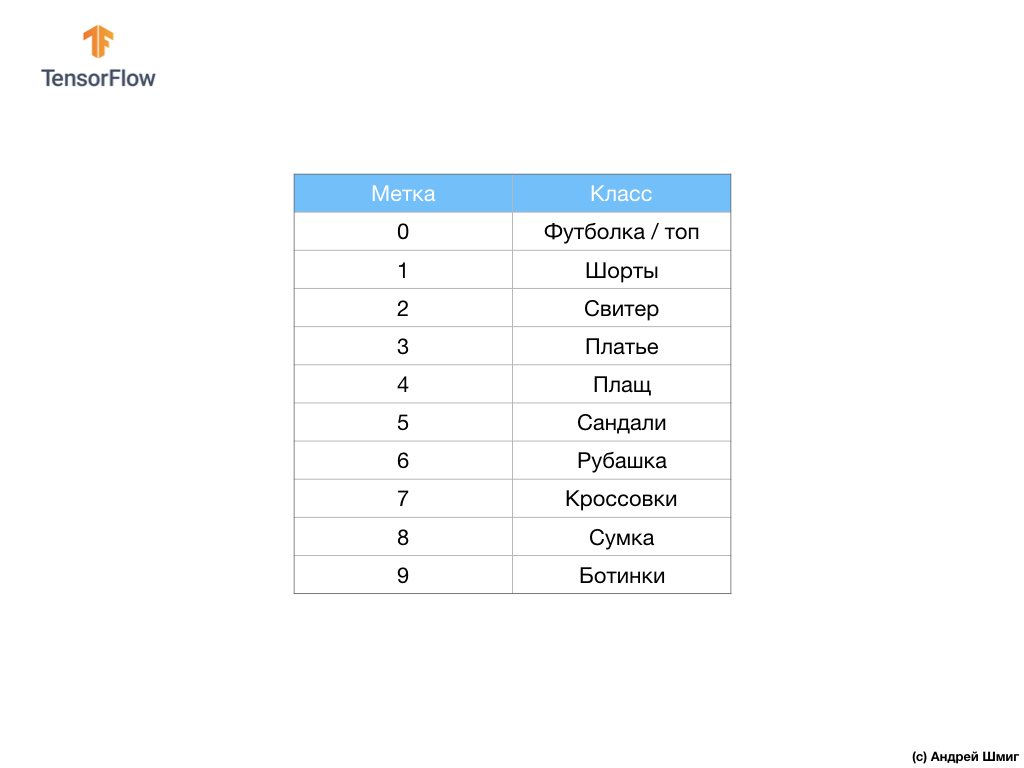
प्रत्येक इनपुट छवि उपरोक्त लेबल में से एक से मेल खाती है। फैशन एमएनआईएसटी डेटासेट में 70,000 चित्र हैं, इसलिए हमारे पास शुरुआत करने और काम करने के लिए एक जगह है। इन 70,000 में से, हम तंत्रिका नेटवर्क को प्रशिक्षित करने के लिए 60,000 का उपयोग करेंगे।
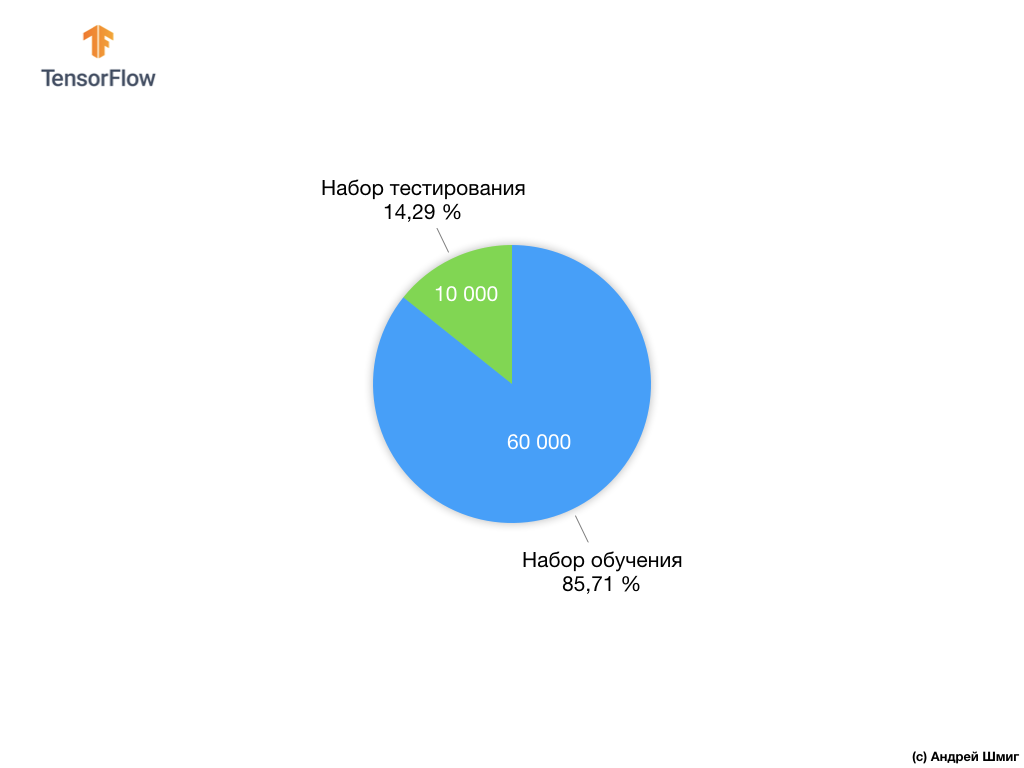
और हम शेष 10,000 तत्वों का उपयोग करके यह जांच करेंगे कि हमारे तंत्रिका नेटवर्क ने कपड़ों के तत्वों को कितनी अच्छी तरह सीखा है। बाद में हम बताएंगे कि हमने डेटा सेट को ट्रेनिंग सेट और टेस्ट सेट में क्यों विभाजित किया।
तो यहाँ हमारा फ़ैशन MNIST डेटासेट है।
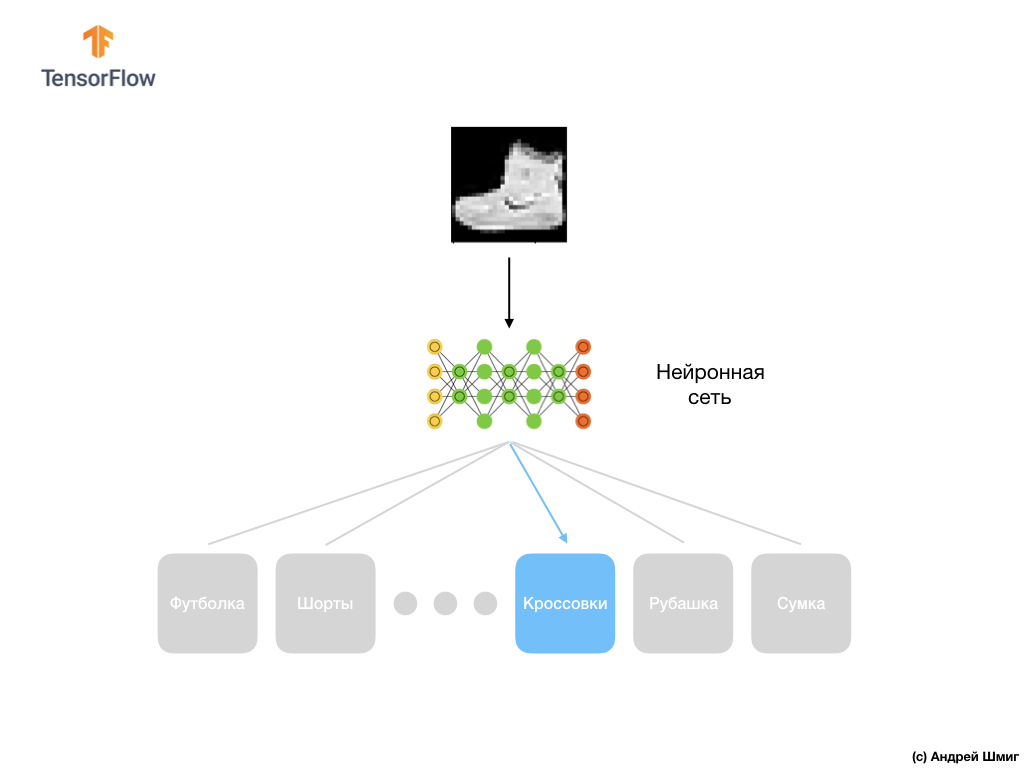
याद रखें, डेटासेट में प्रत्येक छवि ग्रे के रंगों में आकार 28x28 की एक छवि है, जिसका अर्थ है कि प्रत्येक छवि आकार में 784 बाइट्स है। हमारा कार्य एक तंत्रिका नेटवर्क बनाना है, जो इनपुट पर इन 784 बाइट्स को प्राप्त करता है, और आउटपुट रिटर्न पर 10 में से किस श्रेणी के कपड़े उपलब्ध हैं, यह इनपुट पर लागू तत्व के अंतर्गत आता है।
तंत्रिका नेटवर्क
इस पाठ में, हम एक गहरे तंत्रिका नेटवर्क का उपयोग करेंगे जो फैशन MNIST डेटासेट से छवियों को वर्गीकृत करना सीखता है।
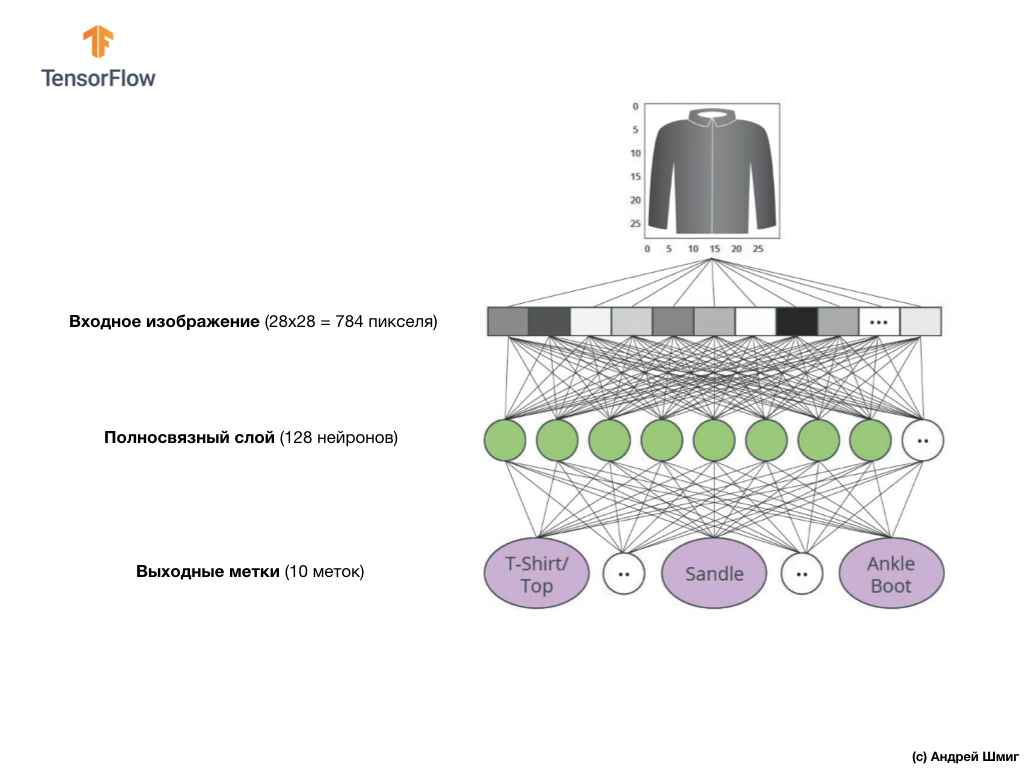
ऊपर दी गई छवि से पता चलता है कि हमारा तंत्रिका नेटवर्क कैसा दिखेगा। आइए इसे और अधिक विस्तार से देखें।
हमारे तंत्रिका नेटवर्क का इनपुट मूल्य 784 की लंबाई के साथ एक आयामी आयाम है, इस कारण की लंबाई है कि प्रत्येक छवि 28x28 पिक्सेल (छवि में कुल = 784 पिक्सेल) है, जिसे हम एक-आयामी सरणी में बदल देंगे। एक 2D छवि को वेक्टर में परिवर्तित करने की प्रक्रिया को समतल कहा जाता है और इसे चौरसाई परत - एक चपटा परत के माध्यम से कार्यान्वित किया जाता है।
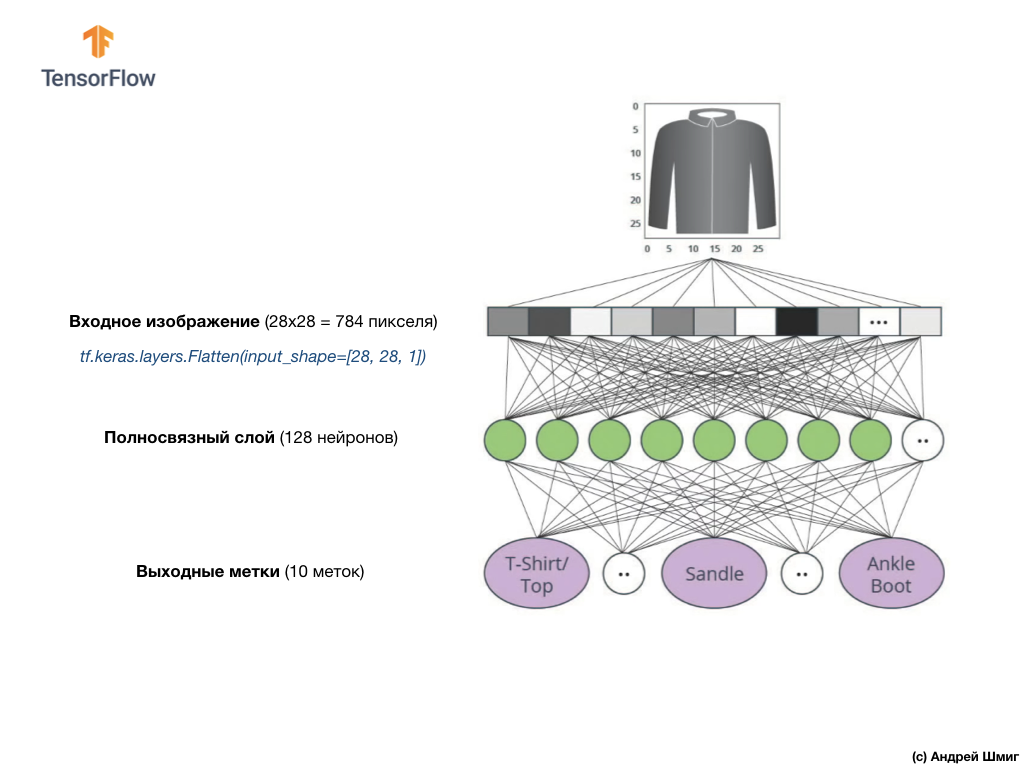
आप उपयुक्त परत बनाकर चौरसाई कर सकते हैं:
tf.keras.layers.Flatten(input_shape=[28, 28, 1])
यह परत 28x28 पिक्सेल 2 डी छवि (प्रत्येक पिक्सेल के लिए ग्रे के रंगों के लिए 1 बाइट) को 784 पिक्सेल के 1 डी सरणी में परिवर्तित करती है।
इनपुट मान पूरी तरह से हमारी पहली
dense नेटवर्क परत के साथ जुड़े होंगे, जिसका आकार हमने 128 न्यूरॉन्स के बराबर चुना था।
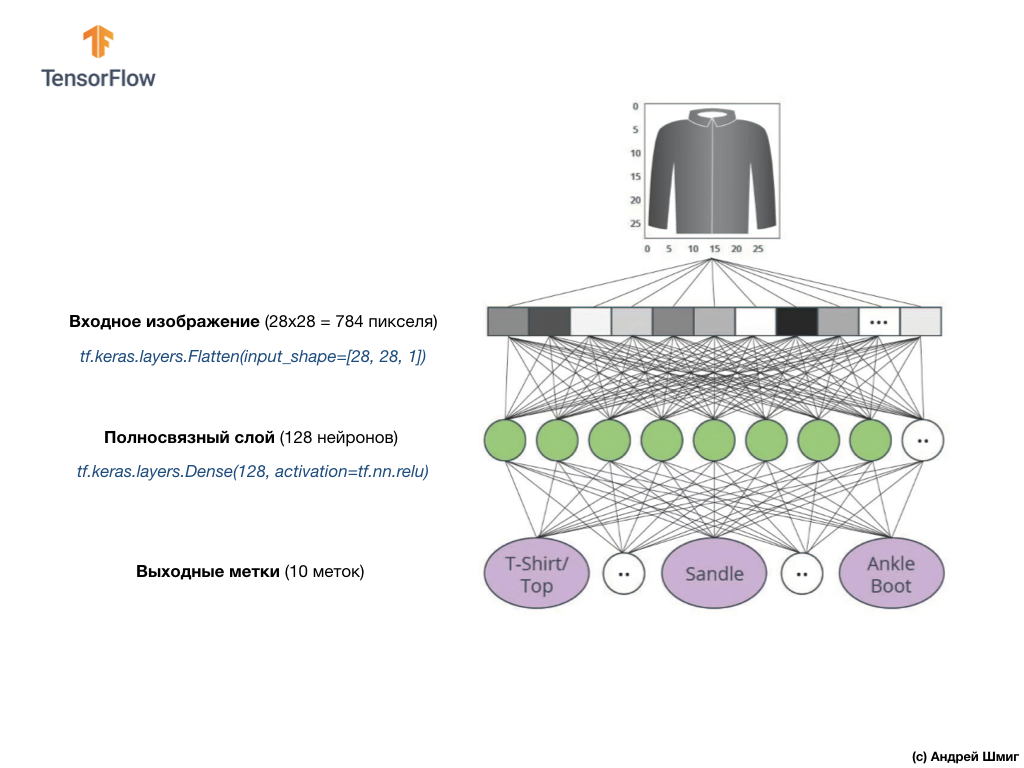
यहाँ कोड में इस परत का निर्माण कैसा दिखेगा:
tf.keras.layers.Dense(128, activation=tf.nn.relu)
इसे रोको!
tf.nn.relu क्या है? डिग्री सेल्सियस को डिग्री फ़ारेनहाइट में परिवर्तित करते समय हमने अपने पिछले तंत्रिका नेटवर्क उदाहरण में इसका उपयोग नहीं किया था! लब्बोलुआब यह है कि वर्तमान कार्य उस तथ्य की तुलना में बहुत अधिक जटिल है जिसका उपयोग तथ्य-खोज उदाहरण के रूप में किया गया था - डिग्री सेल्सियस को डिग्री फ़ारेनहाइट में परिवर्तित करना।
ReLU एक गणितीय कार्य है जिसे हम अपनी पूरी तरह से जुड़ी हुई परत में जोड़ते हैं और जो हमारे नेटवर्क को अधिक शक्ति प्रदान करता है। वास्तव में, यह हमारी पूरी तरह से जुड़ी हुई परत के लिए एक छोटा सा विस्तार है, जो हमारे तंत्रिका नेटवर्क को अधिक जटिल समस्याओं को हल करने की अनुमति देता है। हम विवरण में नहीं जाएंगे, लेकिन नीचे कुछ और विस्तृत जानकारी मिल सकती है।
अंत में, हमारी अंतिम परत, जिसे आउटपुट लेयर के रूप में भी जाना जाता है, में 10 न्यूरॉन्स होते हैं। इसमें 10 न्यूरॉन्स होते हैं क्योंकि हमारे फैशन MNIST डेटासेट में 10 कपड़ों की श्रेणियां होती हैं। इन 10 आउटपुट मानों में से प्रत्येक संभावना का प्रतिनिधित्व करेगा कि इनपुट छवि इस कपड़ों की श्रेणी में है। दूसरे शब्दों में, ये मूल्य आउटपुट पर 10 कपड़ों की श्रेणियों में से एक विशिष्ट के साथ दायर की गई छवि की भविष्यवाणी और सहसंबंध की शुद्धता में मॉडल के "आत्मविश्वास" को दर्शाते हैं। उदाहरण के लिए, क्या संभावना है कि छवि एक पोशाक, स्नीकर्स, जूते आदि दिखाती है।
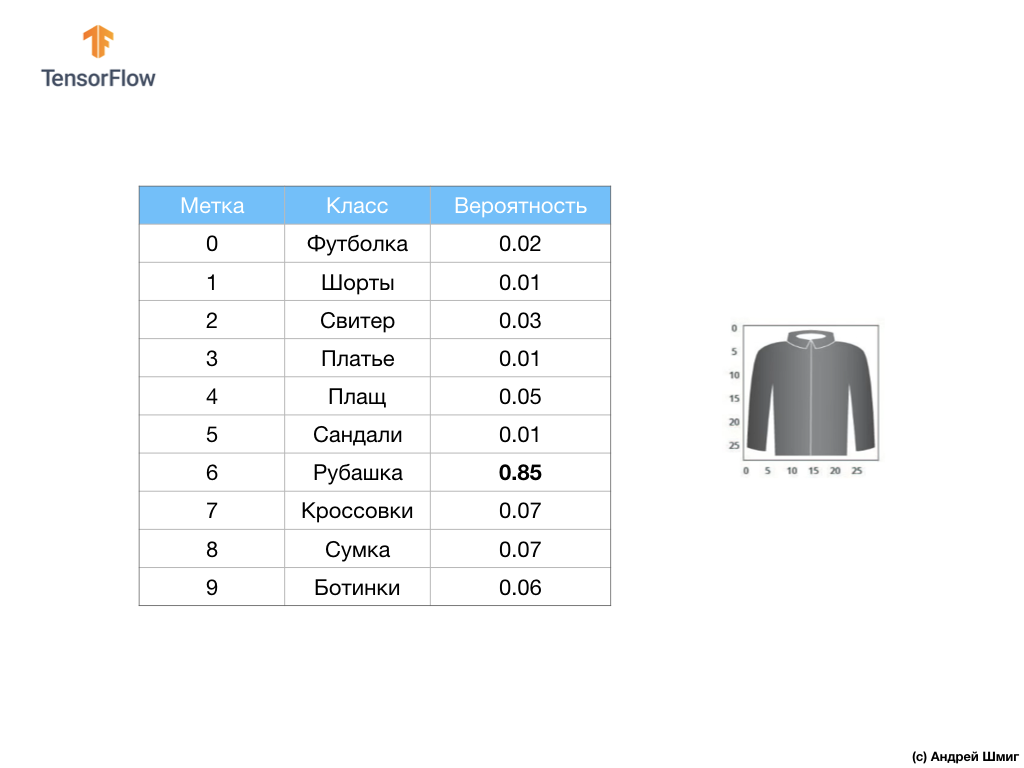
उदाहरण के लिए, यदि एक शर्ट की छवि को हमारे तंत्रिका नेटवर्क के इनपुट पर भेजा जाता है, तो मॉडल हमें परिणाम दे सकता है जैसे कि आप ऊपर की छवि में देखते हैं - आउटपुट लेबल से मेल खाते इनपुट छवि की संभावना।
यदि आप ध्यान देते हैं, तो आप देखेंगे कि सबसे बड़ी संभावना - 0.85 टैग 6 को संदर्भित करता है, जो शर्ट से मेल खाती है। मॉडल 85% सुनिश्चित है कि शर्ट पर छवि। आमतौर पर, शर्ट की तरह दिखने वाली चीजों की भी उच्च संभावना रेटिंग होगी, और कम से कम समान चीजों की रेटिंग की संभावना कम होगी।
चूंकि सभी 10 आउटपुट मान प्रायिकताओं के अनुरूप होते हैं, जब इन सभी मूल्यों को हम जोड़ते हैं। 1. इन 10 मूल्यों को प्रायिकता वितरण भी कहा जाता है।
अब हमें प्रत्येक लेबल के लिए बहुत संभावनाओं की गणना करने के लिए एक आउटपुट लेयर की आवश्यकता है।

और हम निम्नलिखित कमांड के साथ ऐसा करेंगे:
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
वास्तव में, जब भी हम तंत्रिका नेटवर्क बनाते हैं जो वर्गीकरण की समस्याओं को हल करते हैं, तो हम हमेशा तंत्रिका नेटवर्क की अंतिम परत के रूप में पूरी तरह से जुड़े परत का उपयोग करते हैं। तंत्रिका नेटवर्क की अंतिम परत में कक्षाओं की संख्या के बराबर न्यूरॉन्स की संख्या होनी चाहिए, जिससे हम
softmax निर्धारित करते हैं और सॉफ्टमैक्स सक्रियण फ़ंक्शन का उपयोग करते हैं।
ReLU - न्यूरॉन सक्रियण फ़ंक्शन
इस पाठ में, हमने
ReLU बारे में बात की, जो हमारे तंत्रिका नेटवर्क की क्षमताओं का विस्तार करता है और इसे अतिरिक्त शक्ति देता है।
ReLU एक गणितीय फ़ंक्शन है जो इस तरह दिखता है:
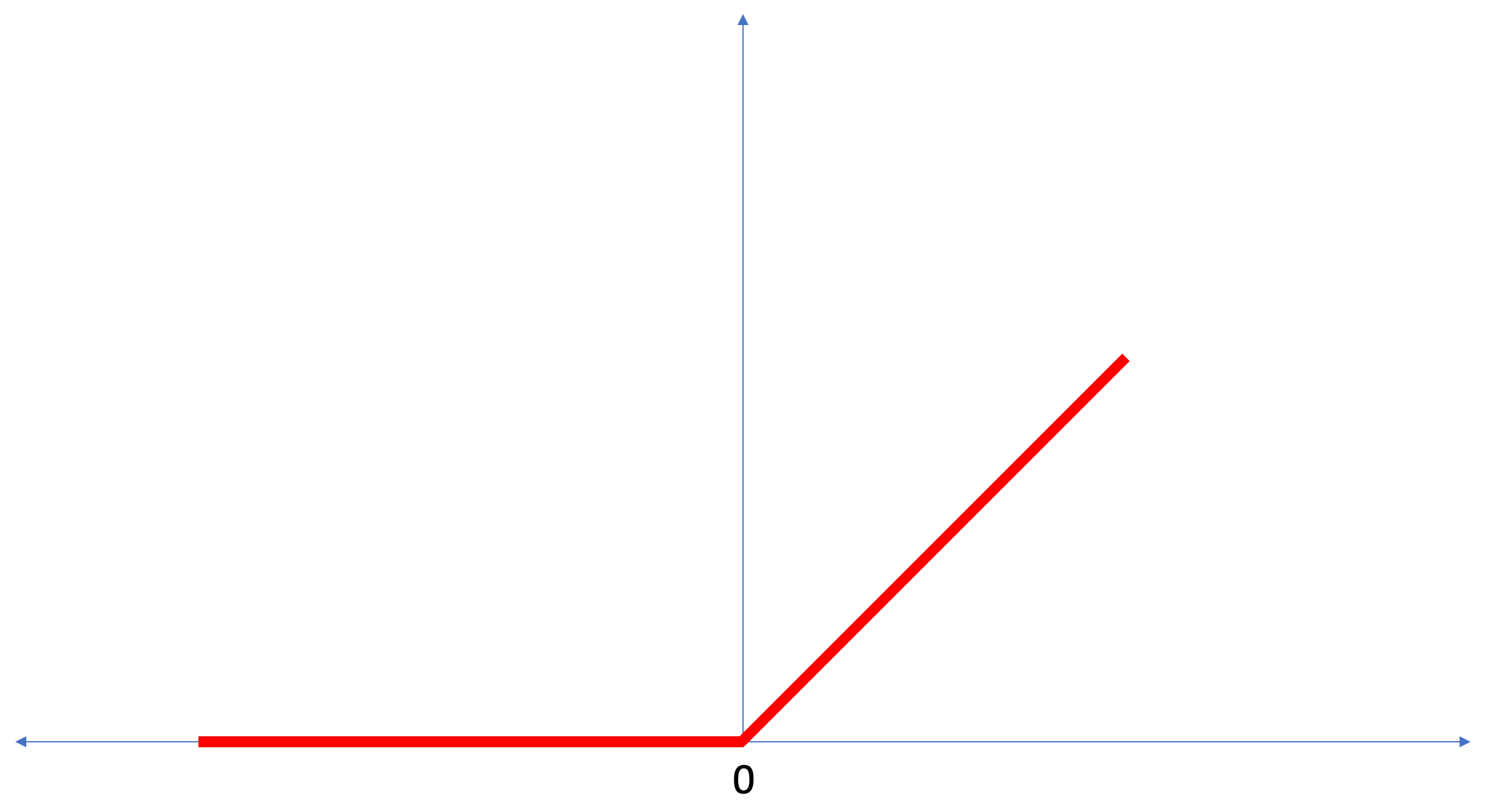
ReLU फ़ंक्शन रिटर्न 0 है यदि इनपुट मान एक नकारात्मक मान या शून्य था, तो अन्य सभी मामलों में फ़ंक्शन मूल इनपुट मान लौटाएगा।
ReLU गैर-रैखिक समस्याओं को हल करना संभव बनाता है।
डिग्री सेल्सियस को डिग्री फ़ारेनहाइट में बदलना एक रैखिक कार्य है, क्योंकि अभिव्यक्ति
f = 1.8*c + 32 रेखा का समीकरण है -
y = m*x + b । लेकिन अधिकांश कार्य जिन्हें हम हल करना चाहते हैं, वे गैर-रैखिक हैं। ऐसे मामलों में, ReLU सक्रियण फ़ंक्शन को हमारी पूरी तरह से जुड़ी हुई परत में जोड़ने से इस तरह के कार्य में मदद मिल सकती है।
ReLU केवल एक प्रकार का सक्रियण कार्य है। सक्रियण फ़ंक्शन जैसे सिग्मॉइड, ReLU, ELU, tanh हैं, हालांकि, यह
ReLU जिसे अक्सर डिफ़ॉल्ट सक्रियण फ़ंक्शन के रूप में उपयोग किया जाता है। मॉडल बनाने और उपयोग करने के लिए जिसमें ReLU शामिल है, आपको यह समझने की आवश्यकता नहीं है कि यह आंतरिक रूप से कैसे काम करता है। यदि आप अभी भी बेहतर समझना चाहते हैं, तो हम
इस लेख की सलाह देते हैं।
आइए इस पाठ में पेश किए गए नए शब्दों को देखें:
- चौरसाई - एक 2 डी छवि को 1 डी वेक्टर में परिवर्तित करने की प्रक्रिया;
- ReLU एक सक्रियण फ़ंक्शन है जो मॉडल को गैर-रैखिक समस्याओं को हल करने की अनुमति देता है;
- सॉफ्टमैक्स - एक फ़ंक्शन जो प्रत्येक संभावित आउटपुट वर्ग के लिए संभावनाओं की गणना करता है;
- वर्गीकरण - दो या अधिक श्रेणियों (वर्गों) के बीच के अंतर को निर्धारित करने के लिए मशीन सीखने के कार्यों का एक वर्ग।
प्रशिक्षण और परीक्षण
जब कोई मॉडल, मशीन लर्निंग के किसी भी मॉडल को प्रशिक्षित करता है, तो डेटा सेट को कम से कम दो अलग-अलग सेटों में विभाजित करना आवश्यक होता है - प्रशिक्षण के लिए उपयोग किया जाने वाला डेटा सेट और परीक्षण के लिए उपयोग किया जाने वाला डेटा सेट। इस भाग में हम समझेंगे कि ऐसा करने के लायक क्यों है।
आइए याद करें कि कैसे हमने फैशन एमएनआईएसटी से अपना डेटा सेट वितरित किया जिसमें 70,000 प्रतियां थीं।
हमने 70,000 को दो भागों में विभाजित करने का प्रस्ताव रखा - पहले भाग में, प्रशिक्षण के लिए 60,000 और दूसरे भाग में परीक्षण के लिए 10,000। इस तरह के दृष्टिकोण की आवश्यकता निम्न तथ्य के कारण होती है: मॉडल को 60,000 प्रतियों पर प्रशिक्षित किए जाने के बाद, परिणामों की जांच करना आवश्यक है और उदाहरणों पर इसके काम की प्रभावशीलता की जांच करना जो अभी तक उस डेटा सेट में नहीं थे जिस पर मॉडल को प्रशिक्षित किया गया था।
अपने तरीके से, यह स्कूल में एक परीक्षा उत्तीर्ण करने जैसा है। परीक्षा उत्तीर्ण करने से पहले, आप परिश्रम से किसी विशेष वर्ग की समस्याओं को हल करने में लगे रहते हैं। फिर, परीक्षा में, आप समस्याओं के एक ही वर्ग में आते हैं, लेकिन विभिन्न इनपुट डेटा के साथ। प्रशिक्षण के दौरान समान डेटा जमा करने का कोई मतलब नहीं है, अन्यथा निर्णय याद रखने के लिए कार्य कम हो जाएगा, और समाधान मॉडल की खोज नहीं होगी। यही कारण है कि परीक्षा में आपको उन कार्यों का सामना करना पड़ता है जो पहले पाठ्यक्रम में नहीं थे। केवल इस तरह से हम यह सत्यापित कर सकते हैं कि मॉडल ने सामान्य समाधान सीखा है या नहीं।
यही बात मशीन लर्निंग के साथ भी होती है। आप कुछ डेटा दिखाते हैं जो कुछ निश्चित कार्यों का प्रतिनिधित्व करते हैं जिन्हें आप सीखना चाहते हैं कि कैसे हल करना है। हमारे मामले में, फैशन MNIST से सेट किए गए डेटा के साथ, हम चाहते हैं कि तंत्रिका नेटवर्क उस श्रेणी को निर्धारित करने में सक्षम हो जिसमें छवि में कपड़े तत्व है। यही कारण है कि हम अपने मॉडल को 60,000 उदाहरणों पर प्रशिक्षित करते हैं जिसमें सभी श्रेणियों के कपड़े शामिल हैं। प्रशिक्षण के बाद, हम मॉडल की प्रभावशीलता की जांच करना चाहते हैं, इसलिए हम कपड़ों के शेष 10,000 वस्तुओं को खिलाते हैं जो मॉडल ने अभी तक "देखा" नहीं है। यदि हमने ऐसा नहीं करने का फैसला किया है, तो 10,000 उदाहरणों के साथ परीक्षण नहीं करना है, हम यह निश्चितता के साथ नहीं कह पाएंगे कि क्या हमारे मॉडल को वास्तव में कपड़ों के आइटम के वर्ग को निर्धारित करने के लिए प्रशिक्षित किया गया था या यदि उसे इनपुट + आउटपुट मान के सभी जोड़े याद थे।
यही कारण है कि मशीन लर्निंग में हमारे पास हमेशा प्रशिक्षण के लिए डेटासेट और परीक्षण के लिए डेटासेट होता है।
TensorFlow रेडी-टू-
यूज़ ट्रेनिंग डेटा का एक संग्रह है।
डेटा सेट को आमतौर पर कई ब्लॉकों में विभाजित किया जाता है, जिनमें से प्रत्येक का उपयोग तंत्रिका नेटवर्क के प्रशिक्षण और परीक्षण के एक निश्चित चरण में किया जाता है। इस भाग में हम बात करते हैं:
- प्रशिक्षण डेटा सेट : एक तंत्रिका नेटवर्क के प्रशिक्षण के लिए एक डेटा सेट;
- परीक्षण डेटा सेट : एक तंत्रिका नेटवर्क की दक्षता को सत्यापित करने के लिए डिज़ाइन किया गया डेटा सेट;
किसी अन्य डेटासेट पर विचार करें, जिसे मैं सत्यापन डेटासेट कहता हूं। इस डेटा सेट का उपयोग केवल प्रशिक्षण के
दौरान मॉडल
को प्रशिक्षित
करने के लिए नहीं किया जाता
है । इसलिए, जब हमारा मॉडल कई प्रशिक्षण चक्रों के माध्यम से चला गया है, तो हम इसे हमारे परीक्षण डेटा सेट और परिणामों को देखते हैं। उदाहरण के लिए, यदि प्रशिक्षण के दौरान नुकसान फ़ंक्शन का मूल्य कम हो जाता है, और परीक्षण डेटा सेट पर सटीकता बिगड़ जाती है, तो इसका मतलब है कि हमारा मॉडल बस इनपुट-आउटपुट मानों के जोड़े को याद करता है।
मॉडल भविष्यवाणियों की अंतिम सटीकता को मापने के लिए सत्यापन डेटा सेट को प्रशिक्षण के बहुत अंत में पुन: उपयोग किया जाता है।
प्रशिक्षण और डेटा सेट की अधिक
जानकारी के लिए
, Google क्रैश कोर्स देखें ।
कोलैब में व्यावहारिक हिस्सा
अंग्रेजी में मूल कोलैब का लिंक और रूसी कोलैब का लिंक ।
कपड़ों की वस्तुओं की छवियों का वर्गीकरण
पाठ के इस भाग में, हम कपड़े, स्नीकर्स, शर्ट, टी-शर्ट आदि जैसे कपड़ों के तत्वों की छवियों को वर्गीकृत करने के लिए एक तंत्रिका नेटवर्क का निर्माण और प्रशिक्षण देंगे।
यदि कुछ क्षण स्पष्ट नहीं हैं तो यह सब ठीक है। इस पाठ्यक्रम का उद्देश्य आपको TensorFlow से परिचित कराना है और साथ ही इसके कार्य के एल्गोरिदम की व्याख्या करना और TensorFlow का उपयोग करने वाली परियोजनाओं के बारे में आम समझ विकसित करना है, बजाय कार्यान्वयन के विवरणों में तल्लीन करना।
इस भाग में, हम
tf.keras उपयोग
tf.keras , जो TensorFlow में मॉडल और प्रशिक्षण मॉडल के लिए एक उच्च-स्तरीय एपीआई है।
निर्भरता स्थापित करना और आयात करना
हमें
एक TensorFlow डेटासेट की आवश्यकता होगी, एक एपीआई जो कई सेवाओं द्वारा प्रदान किए गए डेटासेट लोडिंग और
एक्सेसिंग को सरल करता है। हमें कुछ सहायक पुस्तकालयों की भी आवश्यकता होगी।
!pip install -U tensorflow_datasets
from __future__ import absolute_import, division, print_function, unicode_literals
फैशन MNIST डेटासेट आयात करें
यह उदाहरण फैशन एमएनआईएसटी डेटासेट का उपयोग करता है, जिसमें ग्रेस्केल में 10 श्रेणियों में कपड़ों की वस्तुओं की 70,000 छवियां हैं। चित्र निम्न संकल्प (28x28 पिक्सेल) में कपड़े आइटम हैं, जैसा कि नीचे दिखाया गया है:

फैशन MNIST का उपयोग क्लासिक MNIST डेटासेट के प्रतिस्थापन के रूप में किया जाता है - जिसका उपयोग अक्सर "हैलो, वर्ल्ड!" के रूप में किया जाता है। मशीन सीखने और कंप्यूटर की दृष्टि में। एमएनआईएसटी डेटासेट में हाथ से लिखी संख्या (0, 1, 2, आदि) की छवियां एक ही प्रारूप में होती हैं जैसे हमारे उदाहरण में कपड़े की वस्तुएं।
हमारे उदाहरण में, हम विविधता के कारण फैशन MNIST का उपयोग करते हैं और क्योंकि यह कार्य MNIST डेटा सेट पर एक विशिष्ट समस्या को हल करने की तुलना में कार्यान्वयन के दृष्टिकोण से अधिक दिलचस्प है। दोनों डेटा सेट काफी छोटे हैं, इसलिए, उन्हें एल्गोरिथ्म की सही संचालन क्षमता की जांच करने के लिए उपयोग किया जाता है। मशीन सीखने, परीक्षण और डिबगिंग कोड सीखने के लिए महान डेटासेट।
हम प्रशिक्षण और छवि वर्गीकरण की सटीकता का परीक्षण करने के लिए नेटवर्क और 10,000 छवियों को प्रशिक्षित करने के लिए 60,000 छवियों का उपयोग करेंगे। आप API का उपयोग करके सीधे TensorFlow के माध्यम से फ़ैशन MNIST डेटासेट तक पहुँच सकते हैं:
dataset, metadata = tfds.load('fashion_mnist', as_supervised=True, with_info=True) train_dataset, test_dataset = dataset['train'], dataset['test']
डेटा सेट को लोड करके हम मेटाडेटा, एक प्रशिक्षण डेटा सेट और एक परीक्षण डेटा सेट प्राप्त करते हैं।
- मॉडल को `train_dataset` से एक डेटासेट पर प्रशिक्षित किया जाता है
- मॉडल का परीक्षण एक डेटासेट पर `test_dataset` से किया गया है
छवियां दो-आयामी
2828 हैं, जहां प्रत्येक सेल में मान अंतराल में हो सकते हैं
[0, 255] । लेबल - पूर्णांक का एक सरणी, जहां प्रत्येक मान अंतराल में है
[0, 9] । ये लेबल आउटपुट इमेज क्लास के अनुरूप हैं:
प्रत्येक छवि एक टैग से संबंधित है। चूँकि कक्षा के नाम मूल डेटा सेट में समाहित नहीं हैं, इसलिए जब हम चित्र बनाते हैं तो उन्हें भविष्य के उपयोग के लिए सहेजते हैं:
class_names = [' / ', "", "", "", "", "", "", "", "", ""]
हम डेटा पर शोध करते हैं
आइए मॉडल के प्रशिक्षण से पहले प्रशिक्षण सेट में प्रस्तुत किए गए डेटा के प्रारूप और संरचना का अध्ययन करें। निम्न कोड दिखाएगा कि 60,000 छवियां प्रशिक्षण डेटासेट में हैं, और 10,000 छवियां परीक्षण डेटासेट में हैं:
num_train_examples = metadata.splits['train'].num_examples num_test_examples = metadata.splits['test'].num_examples print(' : {}'.format(num_train_examples)) print(' : {}'.format(num_test_examples))
डेटा प्रीप्रोसेसिंग
छवि में प्रत्येक पिक्सेल का मूल्य सीमा
[0,255] । मॉडल को सही ढंग से काम करने के लिए, इन मूल्यों को सामान्य किया जाना चाहिए - अंतराल में मूल्यों में कमी
[0,1] । इसलिए, थोड़ा कम, हम सामान्यीकरण फ़ंक्शन को घोषित करते हैं और लागू करते हैं, और फिर प्रशिक्षण और परीक्षण डेटा सेट में प्रत्येक छवि पर लागू होते हैं।
def normalize(images, labels): images = tf.cast(images, tf.float32) images /= 255 return images, labels
हम संसाधित डेटा का अध्ययन करते हैं
आइए इस पर एक नज़र डालने के लिए एक चित्र बनाते हैं:
हम प्रशिक्षण डेटा सेट से पहले 25 छवियों को प्रदर्शित करते हैं और प्रत्येक छवि के तहत हम यह संकेत देते हैं कि यह किस वर्ग का है।
सुनिश्चित करें कि डेटा सही प्रारूप में है और हम नेटवर्क बनाने और प्रशिक्षण शुरू करने के लिए तैयार हैं।
plt.figure(figsize=(10,10)) i = 0 for (image, label) in test_dataset.take(25): image = image.numpy().reshape((28,28)) plt.subplot(5,5,i+1) plt.xticks([]) plt.yticks([]) plt.grid(False) plt.imshow(image, cmap=plt.cm.binary) plt.xlabel(class_names[label]) i += 1 plt.show()

एक मॉडल का निर्माण
एक तंत्रिका नेटवर्क के निर्माण के लिए ट्यूनिंग परतों की आवश्यकता होती है, और फिर अनुकूलन और हानि कार्यों के साथ एक मॉडल को इकट्ठा करना।
परतों को अनुकूलित करें
तंत्रिका नेटवर्क के निर्माण में मूल तत्व परत है। परत उस डेटा से दृश्य को निकालती है जो इसके इनपुट में आया था। जुड़े कई परतों के काम का नतीजा, हमें एक दृष्टिकोण मिलता है जो समस्या को हल करने के लिए समझ में आता है।
अधिकांश समय आप गहरी शिक्षा प्राप्त करते हुए सरल परतों के बीच संबंध बना रहे होंगे। अधिकांश परतें, उदाहरण के लिए, जैसे tf.keras.layers.Dense, में ऐसे मापदंडों का एक समूह होता है जिन्हें सीखने की प्रक्रिया के दौरान "फिट" किया जा सकता है।
model = tf.keras.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28, 1)), tf.keras.layers.Dense(128, activation=tf.nn.relu), tf.keras.layers.Dense(10, activation=tf.nn.softmax) ])
नेटवर्क में तीन परतें होती हैं:
- इनपुट
tf.keras.layers.Flatten - यह परत आकार 784 (28 * 28) के साथ 1D-array में छवियों को 28x28 पिक्सेल में परिवर्तित करती है। इस परत पर, हमारे पास प्रशिक्षण के लिए कोई पैरामीटर नहीं है, क्योंकि यह परत केवल इनपुट डेटा के रूपांतरण से संबंधित है। - छिपी हुई परत
tf.keras.layers.Dense - 128 न्यूरॉन्स की एक कसकर जुड़ी हुई परत। प्रत्येक न्यूरॉन (नोड) इनपुट के रूप में पिछली परत से सभी 784 मूल्यों को लेता है, प्रशिक्षण के दौरान आंतरिक भार और विस्थापन के अनुसार इनपुट मूल्यों को बदलता है, और अगली परत के लिए एक एकल मान लौटाता है। - आउटपुट लेयर
ts.keras.layers.Dense - ts.keras.layers.Dense - softmax में 10 न्यूरॉन्स होते हैं, जिनमें से प्रत्येक कपड़े तत्व के एक विशेष वर्ग का प्रतिनिधित्व करता है। पिछली परत की तरह, प्रत्येक न्यूरॉन पिछली परत के सभी 128 न्यूरॉन्स के इनपुट मूल्यों को प्राप्त करता है। इस परत पर प्रत्येक न्यूरॉन का वजन और विस्थापन प्रशिक्षण के दौरान बदल जाता है ताकि परिणामी मूल्य अंतराल [0,1] और इस वर्ग के लिए छवि की संभावना का प्रतिनिधित्व करता है। 10 न्यूरॉन्स के सभी आउटपुट मानों का योग 1 है।
मॉडल संकलित करें
इससे पहले कि हम मॉडल का प्रशिक्षण शुरू करें, यह कुछ और सेटिंग्स के लायक है। जब संकलन विधि कहा जाता है, तो ये सेटिंग्स मॉडल असेंबली के दौरान बनाई जाती हैं:
- हानि फ़ंक्शन - अनुमानित मूल्य से वांछित मूल्य कितनी दूर है, यह मापने के लिए एक एल्गोरिथ्म।
- अनुकूलन फ़ंक्शन - नुकसान फ़ंक्शन को कम करने के लिए मॉडल के आंतरिक मापदंडों (वजन और ऑफसेट) के लिए एक एल्गोरिथ्म;
- मैट्रिक्स - प्रशिक्षण प्रक्रिया और परीक्षण की निगरानी के लिए उपयोग किया जाता है। नीचे दिए गए उदाहरण में
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
हम मॉडल को प्रशिक्षित करते हैं
सबसे पहले, हम प्रशिक्षण डेटा सेट पर प्रशिक्षण के दौरान क्रियाओं का क्रम निर्धारित करते हैं:
dataset.repeat() के dataset.repeat() को dataset.repeat() अनंत समय dataset.repeat() विधि का उपयोग करते हुए अनंत बार dataset.repeat() जो dataset.repeat() पैरामीटर, जो नीचे वर्णित है, प्रदर्शन किए जाने वाले सभी प्रशिक्षण पुनरावृत्तियों की संख्या निर्धारित करता है)dataset.shuffle(60000) इनपुट के क्रम से हमारे मॉडल के प्रशिक्षण को प्रभावित नहीं करता है ताकि dataset.shuffle(60000) सभी dataset.shuffle(60000) किया जा सके।dataset.batch(32) विधि मॉडल के आंतरिक प्रशिक्षण को model.fit लिए 32 छवियों और लेबल के ब्लॉक का उपयोग model.fit लिए model.fit प्रशिक्षण model.fit बताती है।
model.fit विधि को कॉल करके प्रशिक्षण होता है:
- मॉडल इनपुट के लिए
train_dataset भेजता है। - मॉडल लेबल के साथ इनपुट छवि से मेल खाना सीखता है।
- पैरामीटर
epochs=5 प्रशिक्षण सत्रों की संख्या को डेटा सेट पर 5 पूर्ण प्रशिक्षण पुनरावृत्तियों तक सीमित करता है, जो अंततः हमें 5 * 60,000 = 300,000 उदाहरणों पर प्रशिक्षण देता है।
(आप
steps_per_epoch पैरामीटर को अनदेखा कर सकते हैं, जल्द ही इस पैरामीटर को विधि से बाहर रखा जाएगा)।
BATCH_SIZE = 32 train_dataset = train_dataset.repeat().shuffle(num_train_examples).batch(BATCH_SIZE) test_dataset = test_dataset.batch(BATCH_SIZE)
model.fit(train_dataset, epochs=5, steps_per_epoch=math.ceil(num_train_examples/BATCH_SIZE))
और यहाँ निष्कर्ष है:
Epoch 1/5
1875/1875 [==============================] - 26s 14ms/step - loss: 0.4921 - acc: 0.8267
Epoch 2/5
1875/1875 [==============================] - 20s 11ms/step - loss: 0.3652 - acc: 0.8686
Epoch 3/5
1875/1875 [==============================] - 20s 11ms/step - loss: 0.3341 - acc: 0.8782
Epoch 4/5
1875/1875 [==============================] - 19s 10ms/step - loss: 0.3111 - acc: 0.8858
Epoch 5/5
1875/1875 [==============================] - 16s 8ms/step - loss: 0.2911 - acc: 0.8922
मॉडल प्रशिक्षण के दौरान, प्रत्येक प्रशिक्षण यात्रा के लिए नुकसान फ़ंक्शन और सटीकता मीट्रिक का मूल्य प्रदर्शित किया जाता है। यह मॉडल प्रशिक्षण डेटा पर लगभग 0.88 (88%) की सटीकता प्राप्त करता है।
शुद्धता की जांच करें
आइए देखें कि परीक्षण डेटा पर मॉडल किस सटीकता का उत्पादन करता है। हम उन सभी उदाहरणों का उपयोग करेंगे जो हमारे पास सटीकता की जाँच के लिए परीक्षण डेटा सेट में हैं।
test_loss, test_accuracy = model.evaluate(test_dataset, steps=math.ceil(num_test_examples/BATCH_SIZE)) print(" : ", test_accuracy)
निष्कर्ष:
313/313 [==============================] - 1s 5ms/step - loss: 0.3440 - acc: 0.8793
: 0.8793
जैसा कि आप देख सकते हैं, परीक्षण डेटा सेट पर सटीकता प्रशिक्षण डेटा सेट पर सटीकता से कम है। यह काफी सामान्य है क्योंकि मॉडल को train_dataset डेटा पर प्रशिक्षित किया गया था। जब कोई मॉडल ऐसे चित्रों को दिखाता है जो उसने पहले कभी नहीं देखा है (train_dataset डेटासेट से), तो यह स्पष्ट है कि वर्गीकरण दक्षता घट जाएगी।
भविष्यवाणी और अन्वेषण करें
हम कुछ छवियों के लिए पूर्वानुमान प्राप्त करने के लिए प्रशिक्षित मॉडल का उपयोग कर सकते हैं।
for test_images, test_labels in test_dataset.take(1): test_images = test_images.numpy() test_labels = test_labels.numpy() predictions = model.predict(test_images)
predictions.shape
निष्कर्ष: ऊपर दिए गए उदाहरण में, मॉडल ने प्रत्येक परीक्षण इनपुट छवि के लिए लेबल की भविष्यवाणी की। आइए पहले भविष्यवाणी को देखें:(32, 10)
predictions[0]
निष्कर्ष: array([3.1365351e-05, 9.0029374e-08, 5.0016739e-03, 6.3597057e-05, 6.8342477e-02, 1.0856857e-08, 9.2655218e-01, 1.8982398e-09, 8.4999456e-06, 1.0296091e-09], dtype=float32)
याद रखें कि मॉडल की भविष्यवाणी 10 मानों की एक सरणी है। ये मान उस मॉडल के "आत्मविश्वास" का वर्णन करते हैं जो इनपुट छवि एक निश्चित वर्ग (कपड़े की वस्तु) से संबंधित है। हम इस प्रकार अधिकतम मूल्य देख सकते हैं: np.argmax(predictions[0])
निष्कर्ष: 6
इसका मतलब है कि मॉडल को सबसे अधिक भरोसा था कि यह छवि 6 लेबल वाले वर्ग (class_names [6]) की है। हम जाँच कर सकते हैं और सुनिश्चित कर सकते हैं कि परिणाम सही है और यह सही है: test_labels[0]
6
हम सभी इनपुट छवियों और 10 वर्गों के लिए इसी मॉडल की भविष्यवाणी प्रदर्शित कर सकते हैं: def plot_image(i, predictions_array, true_labels, images): predictions_array, true_label, img = predictions_array[i], true_label[i], images[i] plt.grid(False) plt.xticks([]) plt.yticks([]) plt.imshow(img[...,0], cmap=plt.cm.binary) predicted_label = np.argmax(predictions_array) if predicted_label == true_label: color = 'blue' else: color = 'red' plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label], 100 * np.max(predictions_array), class_names[true_label]), color=color) def plot_value_array(i, predictions_array, true_label): predictions_array, true_label = predictions_array[i], true_label[i] plt.grid(False) plt.xticks([]) plt.yticks([]) thisplot = plt.bar(range(10), predictions_array, color="#777777") plt.ylim([0, 1]) predicted_label = np.argmax(predictions_array) thisplot[predicted_label].set_color('red') thisplot[true_label].set_color('blue')
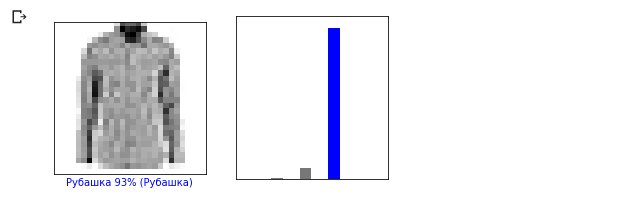
आइए 0 वें छवि पर एक नज़र डालें, मॉडल की भविष्यवाणी और पूर्वानुमान की सरणी का परिणाम। i = 0 plt.figure(figsize=(6,3)) plt.subplot(1,2,1) plot_image(i, predictions, test_labels, test_images) plt.subplot(1,2,2) plot_value_array(i, predictions, test_labels)
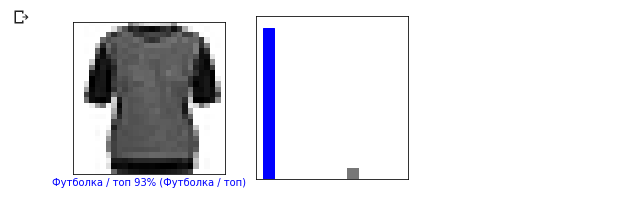
i = 12 plt.figure(figsize=(6,3)) plt.subplot(1,2,1) plot_image(i, predictions, test_labels, test_images) plt.subplot(1,2,2) plot_value_array(i, predictions, test_labels)
 आइए अब कुछ छवियों को उनके संबंधित पूर्वानुमानों के साथ प्रदर्शित करते हैं। सही भविष्यवाणियां नीली हैं, गलत भविष्यवाणियां लाल हैं। छवि के नीचे का मूल्य विश्वास का प्रतिशत दर्शाता है कि इनपुट छवि इस वर्ग से मेल खाती है। कृपया ध्यान दें कि "आत्मविश्वास" का मूल्य अधिक होने पर भी परिणाम गलत हो सकता है।
आइए अब कुछ छवियों को उनके संबंधित पूर्वानुमानों के साथ प्रदर्शित करते हैं। सही भविष्यवाणियां नीली हैं, गलत भविष्यवाणियां लाल हैं। छवि के नीचे का मूल्य विश्वास का प्रतिशत दर्शाता है कि इनपुट छवि इस वर्ग से मेल खाती है। कृपया ध्यान दें कि "आत्मविश्वास" का मूल्य अधिक होने पर भी परिणाम गलत हो सकता है। num_rows = 5 num_cols = 3 num_images = num_rows * num_cols plt.figure(figsize=(2*2*num_cols, 2*num_rows)) for i in range(num_images): plt.subplot(num_rows, 2*num_cols, 2*i + 1) plot_image(i, predictions, test_labels, test_images) plt.subplot(num_rows, 2*num_cols, 2*i + 2) plot_value_array(i, predictions, test_labels)
 एकल छवि के लिए लेबल की भविष्यवाणी करने के लिए प्रशिक्षित मॉडल का उपयोग करें:
एकल छवि के लिए लेबल की भविष्यवाणी करने के लिए प्रशिक्षित मॉडल का उपयोग करें: img = test_images[0] print(img.shape)
निष्कर्ष: (28, 28, 1)
tf.kerasब्लॉक (संग्रह) द्वारा भविष्यवाणियों के लिए मॉडल को अनुकूलित किया गया है। इसलिए, इस तथ्य के बावजूद कि हम एक तत्व का उपयोग करते हैं, आपको इसे सूची में जोड़ने की आवश्यकता है: img = np.array([img]) print(img.shape)
निष्कर्ष:(1, 28, 28, 1)अब हम परिणाम की भविष्यवाणी करेंगे: predictions_single = model.predict(img) print(predictions_single)
निष्कर्ष: [[3.1365438e-05 9.0029722e-08 5.0016833e-03 6.3597123e-05 6.8342514e-02 1.0856857e-08 9.2655218e-01 1.8982469e-09 8.4999692e-06 1.0296091e-09]]
plot_value_array(0, predictions_single, test_labels) _ = plt.xticks(range(10), class_names, rotation=45)
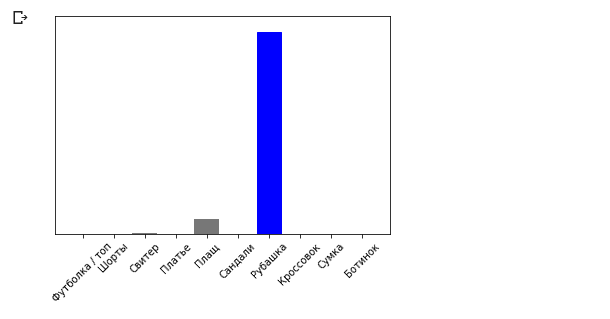 Model.predict विधि एक इनपुट ब्लॉक से एक छवि के लिए सूचियों (सरणियों की एक सरणी) की एक सूची देता है। हमें अपनी एकल इनपुट छवि के लिए एकमात्र परिणाम मिलता है:
Model.predict विधि एक इनपुट ब्लॉक से एक छवि के लिए सूचियों (सरणियों की एक सरणी) की एक सूची देता है। हमें अपनी एकल इनपुट छवि के लिए एकमात्र परिणाम मिलता है: np.argmax(predictions_single[0])
निष्कर्ष: 6
पहले की तरह, मॉडल ने लेबल 6 (शर्ट) की भविष्यवाणी की थी।अभ्यास
विभिन्न मॉडलों के साथ प्रयोग करें और देखें कि सटीकता कैसे बदल जाएगी। विशेष रूप से, निम्नलिखित सेटिंग्स को बदलने का प्रयास करें:- 1 के लिए युगांतर पैरामीटर सेट करें;
- छिपी हुई परत में न्यूरॉन्स की संख्या को बदलें, उदाहरण के लिए, 10 से 512 के कम मूल्य से और देखें कि पूर्वानुमान मॉडल की सटीकता कैसे बदल जाएगी;
- समतल परत (चौरसाई परत) और अंतिम घने-परत के बीच अतिरिक्त परतें जोड़ें, इस परत पर न्यूरॉन्स की संख्या के साथ प्रयोग करें;
- पिक्सेल मानों को सामान्य न करें और देखें कि क्या होता है।
GPU सक्रिय करने के लिए याद रखें ताकि सभी गणना तेज हो ( Runtime -> Change runtime type -> Hardware accelertor -> GPU)। इसके अलावा, यदि आपको ऑपरेशन के दौरान समस्या आती है, तो वैश्विक पर्यावरण सेटिंग्स को रीसेट करने का प्रयास करें:Edit -> Clear all outputsRuntime -> Reset all runtimes
डिग्री सेल्सियस वीएस MNIST
— . , , .
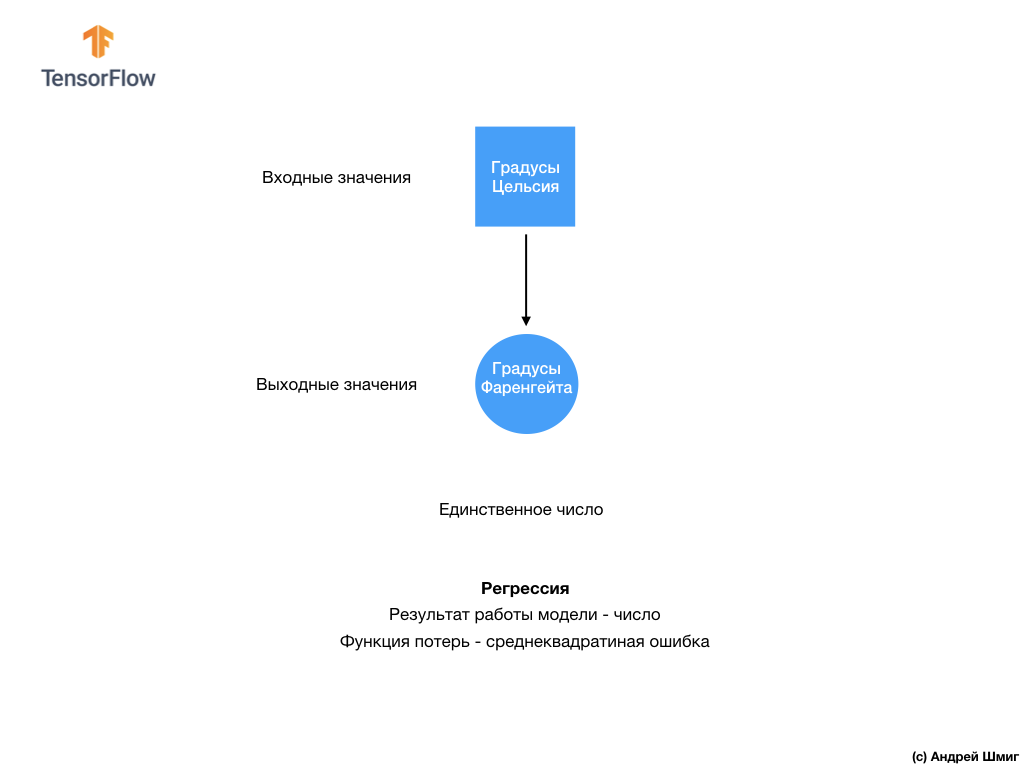
10 , , .
.
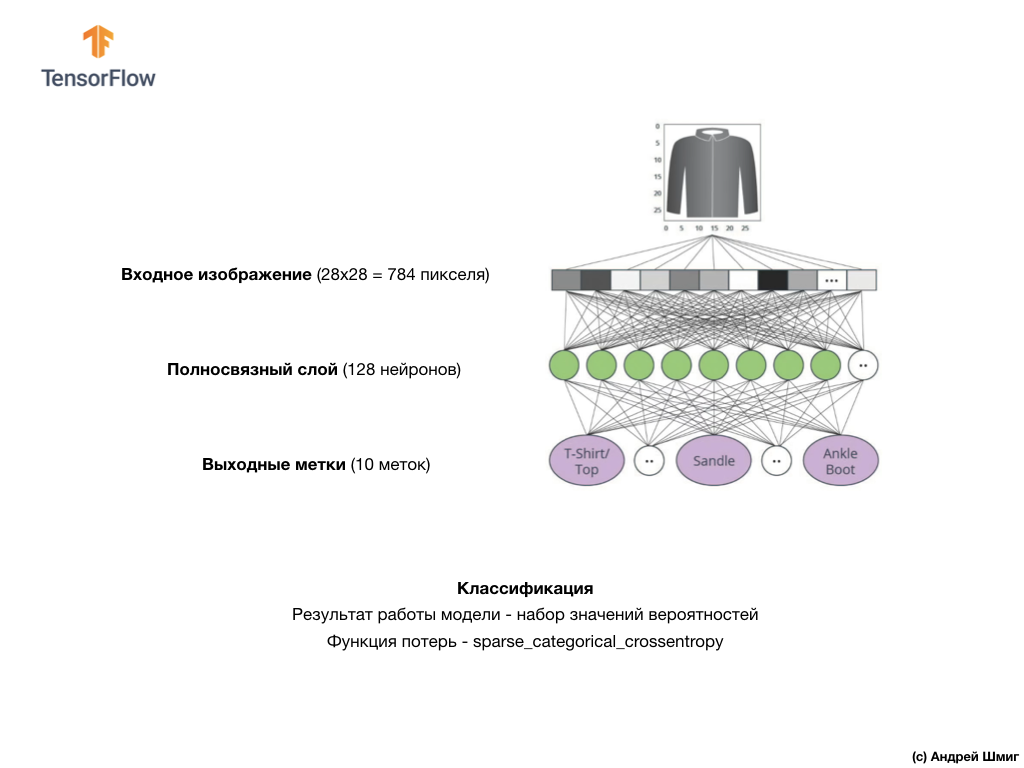
, ,
. . , , .
, ,
. («» , ). , 10 , , — , .
आइए समस्याओं के इन दो वर्गों - प्रतिगमन और वर्गीकरण के बीच अंतर को संक्षेप और ध्यान दें ।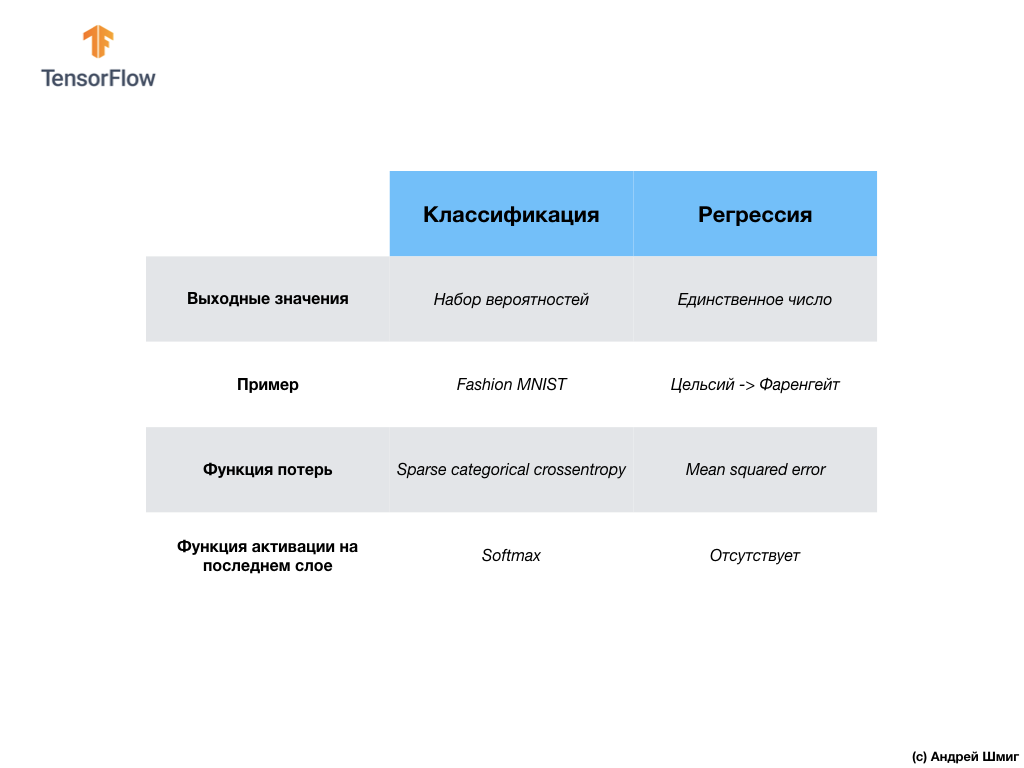 बधाई हो, आपने दो प्रकार के तंत्रिका नेटवर्क का अध्ययन किया है! अगले व्याख्यान के लिए तैयार हो जाइए, वहां हम एक नए प्रकार के तंत्रिका नेटवर्क - दृढ़ तंत्रिका नेटवर्क (CNN) का अध्ययन करेंगे।
बधाई हो, आपने दो प्रकार के तंत्रिका नेटवर्क का अध्ययन किया है! अगले व्याख्यान के लिए तैयार हो जाइए, वहां हम एक नए प्रकार के तंत्रिका नेटवर्क - दृढ़ तंत्रिका नेटवर्क (CNN) का अध्ययन करेंगे।परिणाम
. Fashion MNIST, 70 000 . 60 000 , 10 000 . () 2D 2828 1D 784 . 128 10 , (, ). 10 .
softmax .
.
- : , , , .
- : , . , Fashion MNIST, 10 , ( ). , softmax , .
-वीडियो प्रकाशन के कुछ दिनों बाद सामने आता है और इसे लेख में जोड़ा जाता है।
... और मानक कॉल-टू-एक्शन - साइन अप करें, एक प्लस लगाएं और शेयर करें :)
यूट्यूबतारVKontakte