
नमस्कार, हेब्र! मैं आपके लिए योनी गोल्डबर्ग द्वारा "
Node.js सर्वश्रेष्ठ प्रथाओं " के पहले अध्याय का अनुकूलित अनुवाद प्रस्तुत करता हूं। Node.js पर सिफारिशों का चयन गिथुब पर पोस्ट किया गया है, इसमें लगभग 30 टन सितारे हैं, लेकिन अभी तक Habré पर इसका उल्लेख नहीं किया गया है। मुझे लगता है कि यह जानकारी उपयोगी होगी, कम से कम शुरुआती लोगों के लिए।
1. परियोजना संरचना युक्तियाँ
1.1 घटक द्वारा अपनी परियोजना की संरचना करें
बड़े अनुप्रयोगों की सबसे खराब गलती एक बड़ी संख्या के आधार के रूप में अखंड वास्तुकला है जिसमें बड़ी संख्या में निर्भरता (स्पेगेटी कोड) है, यह संरचना विकास को धीमा कर देती है, खासकर नए कार्यों की शुरूआत। टिप - अपने कोड को अलग घटकों में अलग करें, प्रत्येक घटक के लिए, घटक मॉड्यूल के लिए अपना स्वयं का फ़ोल्डर चुनें। यह महत्वपूर्ण है कि प्रत्येक मॉड्यूल छोटा और सरल बना रहे। "विवरण" अनुभाग में, आप परियोजनाओं की सही संरचना के उदाहरण देख सकते हैं।
अन्यथा: डेवलपर्स के लिए उत्पाद विकसित करना मुश्किल होगा - नई कार्यक्षमता जोड़ना और कोड में परिवर्तन करना धीमा होगा और अन्य आश्रित घटकों को तोड़ने का एक उच्च मौका होगा। यह माना जाता है कि यदि व्यावसायिक इकाइयों को विभाजित नहीं किया जाता है, तो आवेदन को स्केल करने में समस्याएं हो सकती हैं।
विस्तृत जानकारीएक पैराग्राफ स्पष्टीकरणमध्यम आकार और उससे अधिक के अनुप्रयोगों के लिए, मोनोलिथ वास्तव में खराब हैं - कई निर्भरता वाला एक बड़ा कार्यक्रम बस समझना मुश्किल है, और यह अक्सर स्पेगेटी कोड की ओर जाता है। यहां तक कि अनुभवी प्रोग्रामर जो जानते हैं कि कैसे "मॉड्यूल तैयार करना" वास्तुशिल्प डिजाइन पर बहुत प्रयास करते हैं और वस्तुओं के बीच संबंधों में प्रत्येक परिवर्तन के परिणामों का सावधानीपूर्वक मूल्यांकन करने का प्रयास करते हैं। सबसे अच्छा विकल्प एक घटक है जो छोटे घटक कार्यक्रमों के एक सेट पर आधारित होता है: कार्यक्रम को अलग-अलग घटकों में विभाजित करते हैं जो अपनी फ़ाइलों को किसी के साथ साझा नहीं करते हैं, प्रत्येक घटक में छोटी संख्या में मॉड्यूल शामिल होने चाहिए (उदाहरण के लिए, मॉड्यूल: एपीआई, सेवा, डेटाबेस एक्सेस, परीक्षण आदि), ताकि घटक की संरचना और संरचना स्पष्ट हो। कुछ लोग इस आर्किटेक्चर को "माइक्रोसर्विस" कह सकते हैं, लेकिन यह समझना महत्वपूर्ण है कि माइक्रोसॉफ़्ट एक विनिर्देश नहीं है जिसका आपको पालन करना चाहिए, बल्कि कुछ सिद्धांतों का एक सेट। आपके अनुरोध पर, आप इन सिद्धांतों के सभी व्यक्ति और माइक्रोसिस्टवर्क वास्तुकला के सभी सिद्धांतों को अपना सकते हैं। यदि आप कोड की जटिलता कम रखते हैं तो दोनों तरीके अच्छे हैं।
आपको कम से कम घटकों के बीच की सीमाओं को परिभाषित करना होगा: उनमें से प्रत्येक के लिए अपनी परियोजना की जड़ में एक फ़ोल्डर असाइन करें और उन्हें स्टैंडअलोन बनाएं। घटक कार्यक्षमता तक पहुंच केवल एक सार्वजनिक इंटरफ़ेस या एपीआई के माध्यम से लागू की जानी चाहिए। यह आपके घटकों की सादगी को बनाए रखने का आधार है, "निर्भरता के नरक" से बचने और अपने आवेदन को पूर्ण रूप से विकसित माइक्रो-सर्विस के लिए बढ़ने दें।
ब्लॉग से उद्धरण: "स्केलिंग के लिए पूरे आवेदन को मापना आवश्यक है"MartinFowler.com ब्लॉग से
अखंड अनुप्रयोग सफल हो सकते हैं, लेकिन लोग तेजी से उनसे निराश हो रहे हैं, खासकर जब बादल को तैनात करने के बारे में सोचते हैं। किसी भी, यहां तक कि छोटे, आवेदन में परिवर्तन के लिए पूरे मोनोलिथ के विधानसभा और फिर से लेआउट की आवश्यकता होती है। एक अच्छी मॉड्यूलर संरचना को लगातार बनाए रखना अक्सर मुश्किल होता है जिसमें एक मॉड्यूल में बदलाव दूसरों को प्रभावित नहीं करता है। स्केलिंग के लिए पूरे एप्लिकेशन को स्केल करने की आवश्यकता होती है, और न केवल इसके व्यक्तिगत भागों को, निश्चित रूप से, इस दृष्टिकोण को अधिक प्रयास की आवश्यकता होती है।
ब्लॉग से उद्धरण: "आपके आवेदन की वास्तुकला किस बारे में बात कर रही है?"चाचा-बॉब ब्लॉग से
... यदि आप पुस्तकालय में हैं, तो आप इसकी वास्तुकला का प्रतिनिधित्व करते हैं: मुख्य प्रवेश द्वार, रिसेप्शन डेस्क, पढ़ने के कमरे, सम्मेलन कक्ष और बुकशेल्फ़ के साथ कई हॉल। वास्तुकला खुद कहेगी: यह भवन एक पुस्तकालय है।
तो आपके आवेदन की वास्तुकला किस बारे में बात कर रही है? जब आप शीर्ष-स्तरीय निर्देशिका संरचना और उनमें मॉड्यूल फ़ाइलों को देखते हैं, तो वे कहते हैं: मैं एक ऑनलाइन स्टोर हूं, मैं एक एकाउंटेंट हूं, मैं एक उत्पादन प्रबंधन प्रणाली हूं? या वे चिल्ला रहे हैं: मैं रेल हूँ, मैं स्प्रिंग / हाइबरनेट हूँ, मैं एएसपी हूँ?
(अनुवादक का नोट, रेल, स्प्रिंग / हाइबरनेट, एएसपी फ्रेमवर्क और वेब प्रौद्योगिकियां हैं)।
स्वायत्त घटकों के साथ उचित परियोजना संरचना उद्देश्य से फाइलों के समूहन के साथ गलत परियोजना संरचना
उद्देश्य से फाइलों के समूहन के साथ गलत परियोजना संरचना
1.2 अपने घटकों की परतों को अलग करें और उन्हें एक्सप्रेस डेटा संरचना के साथ न मिलाएं
आपके प्रत्येक घटक में "परतें" होनी चाहिए, उदाहरण के लिए, वेब, व्यावसायिक तर्क, डेटाबेस तक पहुंच के साथ काम करने के लिए, इन परतों का अपना डेटा प्रारूप तीसरे पक्ष के पुस्तकालयों के डेटा प्रारूप के साथ मिश्रित नहीं होना चाहिए। यह न केवल समस्याओं को स्पष्ट रूप से अलग करता है, बल्कि सिस्टम के सत्यापन और परीक्षण को भी बहुत सुविधाजनक बनाता है। अक्सर, एपीआई डेवलपर्स व्यावसायिक तर्क और डेटा लेयर के लिए एक्सप्रेस वेब लेयर ऑब्जेक्ट्स (जैसे रेक, रेस) पास करके परतों को मिलाते हैं - यह आपके आवेदन को निर्भर करता है और एक्सप्रेस के साथ अत्यधिक जुड़ा हुआ है।
अन्यथा: एक आवेदन के लिए जिसमें परत वस्तुओं को मिलाया जाता है, कोड परीक्षण, क्रोन कार्यों के संगठन और अन्य गैर-एक्सप्रेस कॉल प्रदान करना अधिक कठिन होता है।
विस्तृत जानकारीघटक कोड को परतों में विभाजित करें: वेब, सेवाएं और डीएएलफ्लिप पक्ष एक जीआईएफ-एनीमेशन में परतों को मिला रहा है
1.3 npm संकुल में अपनी मूलभूत उपयोगिताओं को लपेटें
अपने स्वयं के रिपॉजिटरी के साथ विभिन्न सेवाओं से युक्त एक बड़े आवेदन में, एक लॉगर, एन्क्रिप्शन, आदि के रूप में इस तरह की सार्वभौमिक उपयोगिताओं को अपने कोड के साथ लपेटा जाना चाहिए और निजी एनपीएम पैकेज के रूप में प्रस्तुत किया जाना चाहिए। यह आपको कई कोडबेस और प्रोजेक्ट्स के बीच साझा करने की अनुमति देता है।
अन्यथा: आपको अलग कोड आधारों के बीच इस कोड को साझा करने के लिए अपनी बाइक का आविष्कार करना होगा।
विस्तृत जानकारीएक पैराग्राफ स्पष्टीकरणजैसे ही परियोजना बढ़ने लगती है और आपके पास समान उपयोगिताओं का उपयोग करके विभिन्न सर्वरों पर अलग-अलग घटक होते हैं, आपको निर्भरता का प्रबंधन शुरू करना चाहिए। मैं रिपॉजिटरी के बीच आपकी उपयोगिता के कोड को नकल किए बिना कई घटकों का उपयोग करने की अनुमति कैसे दे सकता हूं इसके लिए एक विशेष उपकरण है, और इसे npm कहा जाता है ...। अपने स्वयं के कोड के साथ तृतीय-पक्ष उपयोगिता पैकेज लपेटकर प्रारंभ करें ताकि आप इसे भविष्य में आसानी से बदल सकें, और इस कोड को एक निजी npm पैकेज के रूप में प्रकाशित कर सकें। अब आपका पूरा कोड आधार उपयोगिताओं के कोड को आयात कर सकता है और सभी npm निर्भरता प्रबंधन सुविधाओं का उपयोग कर सकता है। याद रखें कि सार्वजनिक उपयोग के लिए उन्हें खोलने के बिना व्यक्तिगत उपयोग के लिए npm संकुल प्रकाशित करने के निम्नलिखित तरीके हैं:
निजी मॉड्यूल , एक
निजी रजिस्ट्री, या
स्थानीय npm संकुल ।
विभिन्न परिवेशों में अपनी स्वयं की साझा उपयोगिताओं को साझा करना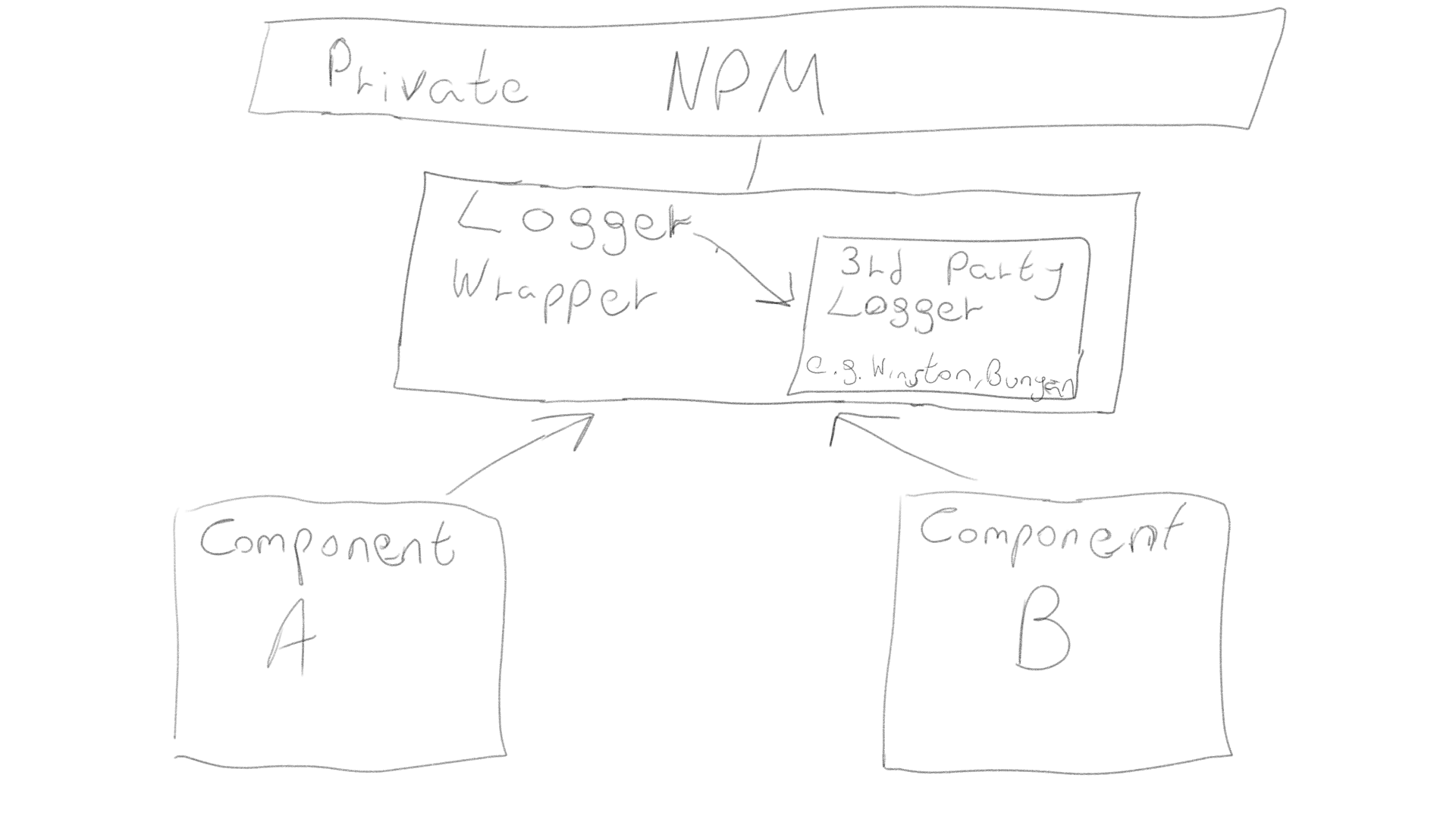
1.4 "एप्लिकेशन" और "सर्वर" में अलग एक्सप्रेस
अपने संपूर्ण एक्सप्रेस एप्लिकेशन को एक बड़ी फ़ाइल में परिभाषित करने की अप्रिय आदत से बचें, अपने 'एक्सप्रेस' कोड को कम से कम दो फ़ाइलों में विभाजित करें: एक एपीआई घोषणा (app.js) और एक www सर्वर कोड। एक और भी बेहतर संरचना के लिए, घटक मॉड्यूल में एक एपीआई घोषणा रखें।
अन्यथा: आपका एपीआई केवल HTTP कॉल के माध्यम से परीक्षण के लिए उपलब्ध होगा (जो धीमी है और कवरेज रिपोर्ट उत्पन्न करने के लिए बहुत अधिक कठिन है)। फिर भी, मुझे लगता है, यह एक फ़ाइल में कोड की सैकड़ों लाइनों के साथ काम करने में बहुत मजेदार नहीं है।
विस्तृत जानकारीएक पैराग्राफ स्पष्टीकरणहम एक्सप्रेस एप्लिकेशन जनरेटर और एप्लिकेशन डेटाबेस के निर्माण के लिए इसके दृष्टिकोण का उपयोग करने की सलाह देते हैं: एपीआई घोषणा सर्वर कॉन्फ़िगरेशन (पोर्ट डेटा, प्रोटोकॉल, आदि) से अलग होती है। यह आपको नेटवर्क कॉल किए बिना एपीआई का परीक्षण करने की अनुमति देता है, जो परीक्षण को गति देता है और कोड कवरेज मेट्रिक्स प्राप्त करना आसान बनाता है। यह आपको अलग-अलग सर्वर नेटवर्क सेटिंग्स के लिए एक ही एपीआई को लचीले ढंग से तैनात करने की भी अनुमति देता है। एक बोनस के रूप में, आपको जिम्मेदारियों का बेहतर पृथक्करण और एक क्लीनर कोड भी मिलता है।
नमूना कोड: एपीआई घोषणा, app.js में होना चाहिएvar app = express(); app.use(bodyParser.json()); app.use("/api/events", events.API); app.use("/api/forms", forms);
कोड उदाहरण: सर्वर नेटवर्क पैरामीटर, / बिन / www में होना चाहिए var app = require('../app'); var http = require('http'); var port = normalizePort(process.env.PORT || '3000'); app.set('port', port); var server = http.createServer(app);
उदाहरण: सुपरटेस्ट (एक लोकप्रिय परीक्षण पैकेज) का उपयोग करके हमारे एपीआई का परीक्षण const app = express(); app.get('/user', function(req, res) { res.status(200).json({ name: 'tobi' }); }); request(app) .get('/user') .expect('Content-Type', /json/) .expect('Content-Length', '15') .expect(200) .end(function(err, res) { if (err) throw err; });
1.5 पर्यावरण चर पर आधारित एक सुरक्षित पदानुक्रमित विन्यास का उपयोग करें
एक आदर्श कॉन्फ़िगरेशन सेटिंग प्रदान करनी चाहिए:
(1) कॉन्फ़िगरेशन फ़ाइल और पर्यावरण चर दोनों से पढ़ने की कुंजी,
(2) भंडार कोड के बाहर रहस्य रखते हुए,
(3) सेटिंग्स के साथ काम को सुविधाजनक बनाने के लिए कॉन्फ़िगरेशन फ़ाइल के पदानुक्रमित (बल्कि फ्लैट) डेटा संरचना।
ऐसे कई पैकेज हैं जो इन बिंदुओं को लागू करने में मदद कर सकते हैं, जैसे: आरसी, एनकेएफ और कॉन्फिग।
अन्यथा: इन कॉन्फ़िगरेशन आवश्यकताओं का पालन करने में विफलता एक व्यक्तिगत डेवलपर और पूरी टीम दोनों के काम में व्यवधान पैदा करेगी।
विस्तृत जानकारीएक पैराग्राफ स्पष्टीकरणजब आप कॉन्फ़िगरेशन सेटिंग्स के साथ काम कर रहे हैं, तो कई चीजें कष्टप्रद और धीमी हो सकती हैं:
1. यदि आप 100+ कुंजियों (विन्यास फाइल में उन्हें ठीक करने के बजाय) दर्ज करने की आवश्यकता है, तो पर्यावरण चर का उपयोग करते हुए सभी मापदंडों को सेट करना बहुत थकाऊ हो जाता है, हालाँकि, यदि कॉन्फ़िगरेशन केवल सेटिंग्स फ़ाइलों में निर्दिष्ट किया जाएगा, तो यह Devpsps के लिए असुविधाजनक हो सकता है। एक विश्वसनीय कॉन्फ़िगरेशन समाधान को दोनों विधियों को संयोजित करना चाहिए: दोनों कॉन्फ़िगरेशन फ़ाइलें और पैरामीटर पर्यावरण चर से ओवरराइड करते हैं।
2. यदि कॉन्फ़िगरेशन फ़ाइल "फ्लैट" JSON है (अर्थात, सभी कुंजियों को एक सूची के रूप में लिखा गया है), तो सेटिंग्स की संख्या में वृद्धि के साथ इसके साथ काम करना मुश्किल होगा। इस समस्या को सेटिंग्स अनुभागों के अनुसार कुंजी के समूहों वाले नेस्टेड संरचनाओं को बनाकर हल किया जा सकता है, अर्थात। एक पदानुक्रमित JSON डेटा संरचना व्यवस्थित करें (नीचे उदाहरण देखें)। ऐसी लाइब्रेरी हैं जो आपको इस कॉन्फ़िगरेशन को कई फ़ाइलों में संग्रहीत करने और रन समय पर उनसे डेटा को संयोजित करने की अनुमति देती हैं।
3. कॉन्फ़िगरेशन फ़ाइलों में गोपनीय जानकारी (जैसे डेटाबेस पासवर्ड) संग्रहीत करने की अनुशंसा नहीं की जाती है, लेकिन ऐसी जानकारी कहाँ और कैसे संग्रहीत की जाए, इसके लिए कोई निश्चित सुविधाजनक समाधान नहीं है। कुछ कॉन्फ़िगरेशन लाइब्रेरी आपको कॉन्फ़िगरेशन फ़ाइलों को एन्क्रिप्ट करने की अनुमति देती हैं, अन्य इन प्रविष्टियों को गिट कमिट के दौरान एन्क्रिप्ट करते हैं, या आप फाइलों में गुप्त मापदंडों को सहेज सकते हैं और पर्यावरण चर के माध्यम से तैनाती के दौरान उनके मूल्यों को सेट कर सकते हैं।
4. कुछ उन्नत कॉन्फ़िगरेशन परिदृश्यों के लिए आपको कमांड लाइन (व्रग्स) के माध्यम से कुंजी दर्ज करने या रेडिस जैसे केंद्रीकृत कैश के माध्यम से कॉन्फ़िगरेशन डेटा को सिंक्रनाइज़ करने की आवश्यकता होती है ताकि कई सर्वर एक ही डेटा का उपयोग करें।
एनपीएम पुस्तकालय हैं जो आपको इनमें से अधिकांश सिफारिशों के कार्यान्वयन में मदद करेंगे, हम आपको निम्नलिखित पुस्तकालयों पर एक नज़र डालने की सलाह देते हैं:
आरसी ,
एनकेएफ और
कॉन्फ़िगरेशन ।
कोड उदाहरण: पदानुक्रमित संरचना रिकॉर्ड को खोजने में मदद करती है और स्वैच्छिक विन्यास फाइलों के साथ काम करती है
{ // Customer module configs "Customer": { "dbConfig": { "host": "localhost", "port": 5984, "dbName": "customers" }, "credit": { "initialLimit": 100, // Set low for development "initialDays": 1 } } }
(अनुवादक के नोट, टिप्पणियों का उपयोग क्लासिक JSON फ़ाइल में नहीं किया जा सकता है। उपरोक्त उदाहरण विन्यास पुस्तकालय प्रलेखन से लिया गया है, जो टिप्पणियों से JSON फ़ाइलों को पूर्व-साफ़ करने के लिए कार्यक्षमता जोड़ता है। इसलिए, उदाहरण काफी काम कर रहा है, हालांकि, डिफ़ॉल्ट सेटिंग्स के साथ ESLint जैसे लिंटर्स हो सकते हैं। एक समान प्रारूप पर "शपथ"।
अनुवादक से आफ्टरवर्ड:
- परियोजना का वर्णन कहता है कि रूसी में अनुवाद पहले ही लॉन्च किया जा चुका है, लेकिन मुझे यह अनुवाद वहां नहीं मिला, इसलिए मैंने इस लेख को लिया।
- यदि अनुवाद आपको बहुत संक्षिप्त लगता है, तो प्रत्येक खंड में विस्तृत जानकारी का विस्तार करने का प्रयास करें।
- खेद है कि दृष्टांतों का अनुवाद नहीं किया गया।