तिथि करने के लिए, बिट्रिक्स 24 सेवा में सैकड़ों गीगाबिट ट्रैफ़िक नहीं हैं, सर्वरों का बहुत बड़ा बेड़ा नहीं है (हालाँकि, मौजूदा बहुत सारे हैं)। लेकिन कई ग्राहकों के लिए, यह कंपनी में काम करने का मुख्य उपकरण है, यह एक वास्तविक व्यवसाय-महत्वपूर्ण अनुप्रयोग है। इसलिए, गिरना - अच्छी तरह से, कोई रास्ता नहीं। लेकिन अगर गिरावट हुई तो क्या हुआ, लेकिन सेवा ने इतनी जल्दी "बगावत" की कि किसी को कुछ नज़र नहीं आया? और आप काम की गुणवत्ता और ग्राहकों की संख्या को खोए बिना विफलता को कैसे लागू करते हैं? Bitrix24 क्लाउड सेवाओं के निदेशक अलेक्जेंडर डेमिडोव ने हमारे ब्लॉग के बारे में बताया कि उत्पाद के अस्तित्व के 7 वर्षों में बैकअप सिस्टम कैसे विकसित हुआ है।

“सास के रूप में, हमने 7 साल पहले बिट्रिक्स 24 लॉन्च किया था। मुख्य कठिनाई, शायद, निम्नलिखित थी: सास के रूप में सार्वजनिक रूप से लॉन्च करने से पहले, यह उत्पाद केवल एक बॉक्सिंग समाधान के प्रारूप में मौजूद था। ग्राहकों ने इसे हमसे खरीदा, अपने सर्वर पर रखा, एक कॉर्पोरेट पोर्टल स्थापित किया - कर्मचारी संचार, फ़ाइल भंडारण, कार्य प्रबंधन, सीआरएम, यह सब एक सामान्य समाधान है। और 2012 तक, हमने फैसला किया कि हम इसे सास के रूप में लॉन्च करना चाहते हैं, इसे स्वयं प्रशासित करते हैं, दोष सहिष्णुता और विश्वसनीयता प्रदान करते हैं। हमने प्रक्रिया में अनुभव प्राप्त किया, क्योंकि तब तक हमारे पास बस नहीं था - हम केवल सॉफ्टवेयर निर्माता थे, सेवा प्रदाता नहीं।
सेवा को शुरू करते समय, हम समझ गए कि सबसे महत्वपूर्ण बात यह है कि सेवा की गलती सहिष्णुता, विश्वसनीयता और निरंतर उपलब्धता सुनिश्चित करना है, क्योंकि यदि आपके पास एक साधारण नियमित वेबसाइट, एक स्टोर, उदाहरण के लिए, और यह आप से गिर गया है और एक घंटे झूठ है - केवल आप ही पीड़ित हैं, तो आप आदेश खो देते हैं। , आप ग्राहकों को खो देते हैं, लेकिन अपने ग्राहक के लिए खुद - उसके लिए यह बहुत महत्वपूर्ण नहीं है। वह परेशान था, ज़ाहिर है, लेकिन गया और दूसरी साइट पर खरीदा गया। और अगर यह एक ऐसा एप्लिकेशन है जो कंपनी के भीतर काम करता है, संचार, समाधान से जुड़ा हुआ है, तो सबसे महत्वपूर्ण बात यह है कि उपयोगकर्ताओं का विश्वास जीतना है, अर्थात् उन्हें नीचे नहीं आने देना है और न गिरना है। क्योंकि अगर अंदर कोई चीज काम न करे तो सभी काम उठ सकते हैं।
बिट्रिक्स। 24 सास के रूप में
पहला प्रोटोटाइप हमने 2011 में सार्वजनिक लॉन्च से एक साल पहले इकट्ठा किया था। लगभग एक सप्ताह में इकट्ठा, देखा, मुड़ - वह भी काम कर रहा था। यही है, फॉर्म में जाना संभव था, वहां पोर्टल का नाम दर्ज करें, एक नया पोर्टल सामने आ रहा था, एक उपयोगकर्ता आधार स्थापित किया जा रहा था। हमने इसे देखा, सिद्धांत में उत्पाद का मूल्यांकन किया, इसे बंद कर दिया, और एक साल बाद इसे अंतिम रूप दिया। क्योंकि हमारे पास एक बड़ा काम था: हम दो अलग-अलग कोड आधार नहीं बनाना चाहते थे, हम एक अलग बॉक्सिंग उत्पाद, अलग से क्लाउड समाधान का समर्थन नहीं करना चाहते थे - हम एक ही कोड के भीतर यह सब करना चाहते थे।

उस समय एक विशिष्ट वेब एप्लिकेशन एक सर्वर है जिस पर कुछ php कोड चल रहा है, mysql आधार, फाइलें डाउनलोड की जा रही हैं, दस्तावेज़, चित्र अपलोड डैडी में डाल दिए गए हैं - ठीक है, यह सब काम करता है। काश, इस पर गंभीर रूप से टिकाऊ वेब सेवा चलाना असंभव है। वितरित कैश वहां समर्थित नहीं है, डेटाबेस प्रतिकृति समर्थित नहीं है।
हमने आवश्यकताओं को तैयार किया: यह क्षमता विभिन्न स्थानों में स्थित है, प्रतिकृति का समर्थन करने के लिए, आदर्श रूप से विभिन्न भौगोलिक रूप से वितरित डेटा केंद्रों में स्थित है। उत्पाद के तर्क को अलग करें और, वास्तव में, डेटा का भंडारण। डायनामिक रूप से लोड के अनुसार स्केल करने में सक्षम हो सकते हैं, आम तौर पर स्टैटिक्स बनाते हैं। इन विचारों से, वास्तव में, उत्पाद के लिए आवश्यकताएं थीं, जो हमने वर्ष के दौरान विकसित की थीं। इस समय के दौरान, एक मंच में जो एकीकृत हो गया - बॉक्सिंग समाधानों के लिए, हमारी अपनी सेवा के लिए - हमने उन चीजों के लिए समर्थन किया, जिनकी हमें जरूरत थी। उत्पाद के स्तर पर mysql प्रतिकृति के लिए समर्थन: अर्थात, डेवलपर जो कोड लिखता है वह इस बारे में नहीं सोचता है कि उसके अनुरोधों को कैसे वितरित किया जाएगा, वह हमारे एपीआई का उपयोग करता है, और हम स्वामी और दासों के बीच अनुरोधों को सही ढंग से लिख और पढ़ सकते हैं।
हमने विभिन्न क्लाउड ऑब्जेक्ट स्टोर्स के लिए उत्पाद-स्तरीय समर्थन बनाया: Google संग्रहण, अमेज़ॅन एस 3, - प्लस, ओपन स्टैक स्विफ्ट के लिए समर्थन। इसलिए, यह एक सेवा के रूप में और एक बॉक्सिंग समाधान के साथ काम करने वाले डेवलपर्स के लिए हमारे लिए सुविधाजनक था: यदि वे सिर्फ काम के लिए हमारी एपीआई का उपयोग करते हैं, तो वे यह नहीं सोचते हैं कि फ़ाइल को कहां सहेजा जाएगा, या तो स्थानीय रूप से फ़ाइल सिस्टम पर या ऑब्जेक्ट फ़ाइल संग्रहण में। ।
परिणामस्वरूप, हमने तुरंत निर्णय लिया कि हम एक संपूर्ण डेटा केंद्र के स्तर पर आरक्षित करेंगे। 2012 में, हमने पूरी तरह से अमेज़ॅन AWS में लॉन्च किया, क्योंकि हमारे पास पहले से ही इस प्लेटफ़ॉर्म के साथ अनुभव था - हमारी अपनी वेबसाइट वहां होस्ट की गई थी। हम इस तथ्य से आकर्षित हुए कि अमेज़ॅन के प्रत्येक क्षेत्र में कई एक्सेस ज़ोन हैं - वास्तव में, उनकी शब्दावली में, कई डेटा सेंटर जो एक दूसरे से कम या ज्यादा स्वतंत्र हैं और हमें एक पूरे डेटा सेंटर के स्तर पर आरक्षित करने की अनुमति देते हैं: यदि यह अचानक विफल हो जाता है, मास्टर-मास्टर डेटाबेस को दोहराया जाता है, वेब एप्लिकेशन सर्वर आरक्षित होते हैं, और स्थैतिक को s3 ऑब्जेक्ट स्टोरेज में ले जाया जाता है। लोड संतुलित है - उस समय अमेजन एल्ब, लेकिन थोड़ी देर बाद हम अपने स्वयं के बैलेंसरों में आए, क्योंकि हमें एक अधिक जटिल तर्क की आवश्यकता थी।
वे जो चाहते थे, वह मिल गया ...
सभी बुनियादी चीजें जो हम प्रदान करना चाहते थे - सर्वर की गलती सहिष्णुता, वेब अनुप्रयोग, डेटाबेस - सब कुछ अच्छी तरह से काम किया। सबसे सरल परिदृश्य: यदि कुछ वेब एप्लिकेशन विफल हो जाते हैं, तो सब कुछ सरल है - उन्हें शेष राशि से बंद कर दिया गया है।

मशीन बैलेंसर (तब यह एक अमेजोनियन एल्ब था) जिसने मशीन को अस्वस्थ रूप से चिह्नित किया था, उन पर लोड वितरण को बंद कर दिया। Amazonian autoscaling ने काम किया: जब भार बढ़ता गया, तो नई कारों को ऑटोसालिंग समूह में जोड़ा गया, लोड को नई कारों में वितरित किया गया - सब कुछ ठीक था। हमारे बैलेंसरों के साथ, तर्क लगभग एक ही है: यदि एप्लिकेशन सर्वर के साथ कुछ होता है, तो हम इसमें से अनुरोधों को हटा देते हैं, इन मशीनों को बाहर फेंक देते हैं, नए शुरू करते हैं और काम करना जारी रखते हैं। इन सभी वर्षों की योजना थोड़ी बदल गई है, लेकिन काम करना जारी है: यह सरल, समझने योग्य है, और इसके साथ कोई कठिनाई नहीं है।
हम पूरी दुनिया में काम करते हैं, ग्राहकों का शिखर भार पूरी तरह से अलग है, और, एक अच्छे तरीके से, हमें किसी भी समय हमारे सिस्टम के किसी भी घटक के साथ कुछ रखरखाव कार्य करने में सक्षम होना चाहिए - ग्राहकों के लिए अदृश्य रूप से। इसलिए, हमारे पास दूसरे डेटा सेंटर पर लोड को पुनर्वितरित करते हुए, डेटाबेस को काम से बंद करने का अवसर है।
यह सब कैसे काम करता है? - हम ट्रैफ़िक को एक कार्यशील डेटा केंद्र पर ले जाते हैं - यदि यह डेटा सेंटर में कोई दुर्घटना है, तो पूरी तरह से, यदि यह किसी एक बेस के साथ हमारा नियोजित कार्य है, तो हम इन क्लाइंट्स की सेवा करने वाले ट्रैफ़िक का हिस्सा हैं, एक दूसरे डेटा सेंटर पर जाएँ, यह रुक जाता है प्रतिकृति। यदि आपको वेब एप्लिकेशन के लिए नई मशीनों की आवश्यकता है, क्योंकि दूसरे डेटा सेंटर पर लोड बढ़ गया है, तो वे स्वचालित रूप से शुरू हो जाते हैं। हम काम खत्म करते हैं, प्रतिकृति बहाल की जाती है, और हम पूरे लोड को वापस करते हैं। यदि हमें दूसरे डीसी में कुछ काम को दर्पण करने की आवश्यकता है, उदाहरण के लिए, सिस्टम अपडेट स्थापित करें या दूसरे डेटाबेस में सेटिंग्स को बदलें, तो, सामान्य तौर पर, हम उसी चीज को दोहराते हैं, बस दूसरे तरीके से। और अगर यह एक दुर्घटना है, तो हम सब कुछ एक ट्राइट में करते हैं: मॉनिटरिंग सिस्टम में हम इवेंट-हैंडलर तंत्र का उपयोग करते हैं। यदि कई जाँचें हमारे लिए काम करती हैं और स्थिति गंभीर हो जाती है, तो यह हैंडलर लॉन्च किया जाता है, एक हैंडलर जो इस या उस तर्क को निष्पादित कर सकता है। प्रत्येक डेटाबेस के लिए, हमने पंजीकृत किया है कि कौन सा सर्वर इसके लिए विफल है, और जहां अनुपलब्ध है, तो आपको ट्रैफ़िक स्विच करना होगा। हम - जैसा कि यह ऐतिहासिक रूप से विकसित हुआ है - एक रूप या किसी अन्य नाग या इसके किसी भी कांटे का उपयोग करें। सिद्धांत रूप में, समान तंत्र लगभग किसी भी निगरानी प्रणाली में मौजूद हैं, हम अभी तक कुछ अधिक जटिल का उपयोग नहीं कर रहे हैं, लेकिन शायद किसी दिन हम करेंगे। अब निगरानी को अक्षमता से चालू किया जाता है और कुछ स्विच करने की क्षमता होती है।
क्या हमने सब कुछ आरक्षित कर दिया है?
हमारे पास संयुक्त राज्य अमेरिका से कई ग्राहक हैं, यूरोप से कई ग्राहक हैं, कई ग्राहक जो पूर्व - जापान, सिंगापुर और इतने पर करीब हैं। बेशक, रूस में ग्राहकों का एक बड़ा हिस्सा। यानी काम एक क्षेत्र में होने से बहुत दूर है। उपयोगकर्ता एक त्वरित प्रतिक्रिया चाहते हैं, विभिन्न स्थानीय कानूनों का पालन करने के लिए आवश्यकताएं हैं, और प्रत्येक क्षेत्र के भीतर हम दो डेटा केंद्रों के लिए आरक्षित करते हैं, साथ ही कुछ अतिरिक्त सेवाएं हैं जो फिर से, एक क्षेत्र के अंदर जगह के लिए सुविधाजनक हैं - उन ग्राहकों के लिए जो इस में हैं क्षेत्र का काम। बाकी हैंडलर, प्राधिकरण सर्वर, वे क्लाइंट के लिए कम महत्वपूर्ण हैं, आप उनके बीच एक छोटी स्वीकार्य देरी के साथ स्विच कर सकते हैं, लेकिन आप साइकिल का आविष्कार नहीं करना चाहते हैं, उन्हें कैसे मॉनिटर करना है और उनके साथ क्या करना है। इसलिए, अधिकतम हम मौजूदा समाधानों का उपयोग करने की कोशिश कर रहे हैं, न कि अतिरिक्त उत्पादों में कुछ क्षमता विकसित करने के लिए। और कहीं न कहीं, हम तुच्छता से dns स्तर पर स्विचिंग का उपयोग करते हैं, और हम उसी dns के साथ सेवा की आजीविका निर्धारित करते हैं। अमेज़ॅन के पास रूट 53 सेवा है, लेकिन यह सिर्फ डीएनएस नहीं है जिसमें आप सब कुछ रिकॉर्ड कर सकते हैं, यह बहुत अधिक लचीला और सुविधाजनक है। इसके माध्यम से, आप भू-वितरण के साथ भू-वितरित सेवाओं का निर्माण कर सकते हैं, जब आप यह निर्धारित करने के लिए उपयोग करते हैं कि ग्राहक कहां से आया था और उन्हें कुछ रिकॉर्ड दिए गए हैं - इसके साथ आप फेलओवर आर्किटेक्चर का निर्माण कर सकते हैं। उसी स्वास्थ्य-जांच को रूट 53 में कॉन्फ़िगर किया गया है, आप उन एंडपॉइंट्स को निर्दिष्ट करते हैं जो मॉनिटर किए जाते हैं, मैट्रिक्स सेट करते हैं, और निर्दिष्ट करते हैं कि कौन-से प्रोटोकॉल सेवा की लाइनिंग का निर्धारण करते हैं - टीसीपी, http, https; चेक की आवृत्ति सेट करें जो यह निर्धारित करता है कि सेवा लाइव है या नहीं। और डीएनएस में ही आप यह निर्धारित करते हैं कि प्राथमिक क्या होगा, द्वितीयक क्या होगा, जहां स्विच करना है यदि मार्ग 53 के अंदर स्वास्थ्य-जांच शुरू हो जाती है। यह सब कुछ अन्य उपकरणों के साथ किया जा सकता है, लेकिन क्या अधिक सुविधाजनक है - एक बार कॉन्फ़िगर किया गया है और फिर इसके बारे में मत सोचो। हम कैसे जांच करते हैं, हम कैसे स्विच करते हैं: सब कुछ अपने आप काम करता है।
पहला "लेकिन" : कैसे और कैसे मार्ग 53 को ही आरक्षित करना है? क्या ऐसा होता है अगर उसके साथ कुछ होता है? सौभाग्य से, हमने इस रेक पर कभी कदम नहीं रखा है, लेकिन फिर, मेरे सामने मेरी एक कहानी होगी कि हमने क्यों सोचा कि हमें अभी भी आरक्षित करने की आवश्यकता है। यहाँ हम पहले से पुआल बिछाते हैं। दिन में कई बार हम सभी मार्गों को पूरा करते हैं जो हमारे पास मार्ग 53 में हैं। अमेज़ॅन की एपीआई आपको उन्हें JSON में सुरक्षित रूप से सबमिट करने की अनुमति देती है, और हमने कई अनावश्यक सर्वर उठाए हैं, जहां हम इसे रूपांतरित करते हैं, इसे कॉन्फ़िगर के रूप में अपलोड करते हैं और, मोटे तौर पर बोलते हुए, एक बैकअप कॉन्फ़िगरेशन होता है। जिस स्थिति में हम इसे मैन्युअल रूप से तैनात कर सकते हैं, हम dns सेटिंग्स डेटा नहीं खोएंगे।
दूसरा "लेकिन" : क्या इस तस्वीर में आरक्षित नहीं है? बैलेंसर खुद! हमने क्षेत्र द्वारा ग्राहकों के वितरण को बहुत सरल बना दिया है। हमारे पास bitrix24.ru, bitrix24.com, .de डोमेन हैं - अब 13 अलग-अलग डोमेन हैं जो बहुत अलग-अलग क्षेत्रों में काम करते हैं। हम निम्नलिखित पर आए हैं: प्रत्येक क्षेत्र के अपने स्वयं के बैलेंसर्स हैं। यह क्षेत्र द्वारा वितरित करने के लिए अधिक सुविधाजनक है, यह निर्भर करता है कि नेटवर्क पर पीक लोड कहां है। यदि यह किसी एक बैलेंसर के स्तर पर असफलता है, तो इसे बस डीमोशन किया जाता है और डीएनएस से हटा दिया जाता है। यदि बैलेंसरों के एक समूह के साथ कोई समस्या होती है, तो उन्हें अन्य साइटों पर आरक्षित किया जाता है, और उनके बीच स्विचिंग उसी मार्ग 53 का उपयोग करके की जाती है, क्योंकि एक छोटी सी ttl के कारण, स्विचिंग अधिकतम 2, 3, 5 मिनट के लिए होती है।
तीसरा "लेकिन" : क्या अभी तक आरक्षित नहीं किया गया है? S3, सही है। हम, s3 में उपयोगकर्ताओं द्वारा संग्रहीत फ़ाइलों को रखकर, ईमानदारी से मानते हैं कि यह कवच-भेदी था और वहां आरक्षित रखने की कोई आवश्यकता नहीं थी। लेकिन इतिहास दिखाता है कि अलग तरह से क्या होता है। सामान्य तौर पर, अमेज़ॅन एस 3 को एक मौलिक सेवा के रूप में वर्णित करता है, क्योंकि अमेज़ॅन स्वयं एस 3 का उपयोग मशीनों, कॉन्फ़िगरेशन, एएमआई छवियों, स्नैपशॉट्स की छवियों को संग्रहीत करने के लिए करता है ... और यदि एस 3 दुर्घटनाग्रस्त हो जाता है, जैसा कि इन 7 वर्षों में एक बार हुआ, हम कितना बिट्रिक्स 24 का उपयोग कर रहे हैं, यह एक प्रशंसक द्वारा पीछा किया जाता है। सब कुछ का एक समूह खींचता है - आभासी मशीनों, एपि खराबी और इतने पर शुरू करने की दुर्गमता।
और S3 गिर सकता है - यह एक बार हुआ। इसलिए, हम निम्नलिखित योजना में आए: कुछ साल पहले रूस में कोई गंभीर वस्तु सार्वजनिक भंडारण नहीं थी, और हम अपने स्वयं के कुछ करने के विकल्प पर विचार कर रहे थे ... सौभाग्य से, हमने ऐसा करना शुरू नहीं किया, क्योंकि हम उस परीक्षा में खुदाई करेंगे जो कि नहीं हुई थी के पास, और शायद यह किया होगा। अब Mail.ru में s3- संगत स्टोरेज हैं, यांडेक्स के पास है, और कई प्रदाताओं के पास अभी भी है। नतीजतन, हम इस निष्कर्ष पर पहुंचे कि हम चाहते हैं, सबसे पहले, एक बैकअप, और दूसरी बात, स्थानीय प्रतियों के साथ काम करने की क्षमता। एक विशेष रूसी क्षेत्र के लिए, हम Mail.ru Hotbox सेवा का उपयोग करते हैं, जो कि s3 के साथ संगत है। हमें आवेदन के अंदर कोड के लिए किसी भी गंभीर संशोधन की आवश्यकता नहीं है, और हमने निम्नलिखित तंत्र बनाया: s3 में ऐसे ट्रिगर हैं जो ऑब्जेक्ट बनाने / हटाने पर काम करते हैं, अमेज़ॅन के पास लैम्ब्डा जैसी सेवा है - यह सर्वर रहित रनिंग कोड है जो केवल निष्पादित करेगा जब कुछ ट्रिगर चालू होते हैं।
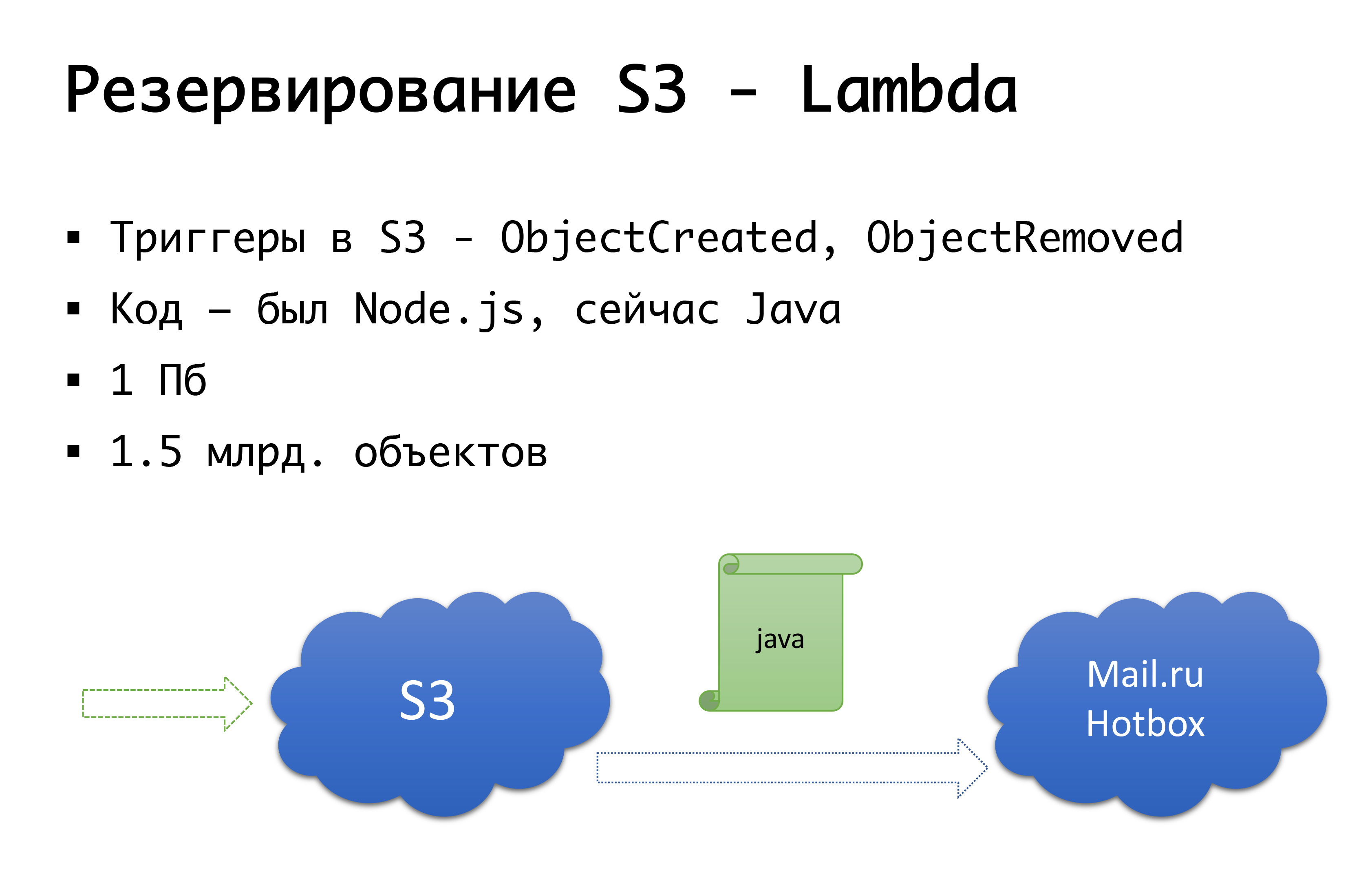
हमने इसे बहुत सरलता से किया: यदि हमारा ट्रिगर आग लगाता है, तो हम उस कोड को निष्पादित करते हैं जो ऑब्जेक्ट को Mail.ru रिपॉजिटरी में कॉपी करेगा। पूरी तरह से डेटा की स्थानीय प्रतियों के साथ काम करना शुरू करने के लिए, हमें रिवर्स सिंक्रोनाइज़ेशन की भी आवश्यकता होती है, ताकि रूसी खंड में स्थित ग्राहक भंडारण के साथ काम कर सकें जो उनके करीब है। मेल अपनी रिपॉजिटरी में ट्रिगर्स को पूरा करने वाला है - बुनियादी ढांचे के स्तर पर पहले से ही रिवर्स सिंक्रोनाइज़ेशन करना संभव होगा, लेकिन अभी हम अपने कोड के स्तर पर ऐसा कर रहे हैं। यदि हम देखते हैं कि ग्राहक ने किसी प्रकार की फ़ाइल रखी है, तो हमारे कोड स्तर पर हम घटना को कतार में रखते हैं, इसे संसाधित करते हैं और रिवर्स प्रतिकृति करते हैं। यह बुरा क्यों है: यदि हमारे उत्पाद के बाहर हमारी वस्तुओं के साथ किसी तरह का काम होता है, अर्थात कुछ बाहरी तरीकों से, हम इसे ध्यान में नहीं रखेंगे। इसलिए, हम अंत तक इंतजार करते हैं जब ट्रिगर स्टोरेज स्तर पर दिखाई देते हैं ताकि कोई फर्क नहीं पड़ता कि हम कोड को कहां से चलाते हैं, जो वस्तु हमारे पास आई वह दूसरे तरीके से कॉपी की गई है।
प्रत्येक ग्राहक के लिए कोड स्तर पर, दोनों रिपॉजिटरी पंजीकृत हैं: एक को मुख्य माना जाता है, दूसरा बैकअप है। यदि सब कुछ ठीक है, तो हम उस स्टोरेज के साथ काम करते हैं जो हमारे करीब है: अर्थात्, हमारे ग्राहक जो अमेज़न पर हैं, वे S3 के साथ काम करते हैं, और जो रूस में काम करते हैं, वे हॉटबॉक्स के साथ काम करते हैं। यदि चेकबॉक्स काम करता है, तो विफलता को हमसे कनेक्ट करना चाहिए, और हम ग्राहकों को दूसरे स्टोरेज पर स्विच करेंगे। हम इस ध्वज को क्षेत्र द्वारा स्वतंत्र रूप से सेट कर सकते हैं और उन्हें आगे और पीछे स्विच कर सकते हैं। व्यवहार में, हमने अभी तक इसका उपयोग नहीं किया है, लेकिन हमने इस तंत्र की कल्पना की है और हमें लगता है कि किसी दिन हमें इस स्विच की आवश्यकता होगी और इसका उपयोग करना होगा। एक बार पहले ही हो चुका है।
ओह, और आपका अमेज़न बच गया ...
यह अप्रैल रूस में टेलीग्राम के ताले की शुरुआत की सालगिरह है। इसके तहत सबसे अधिक प्रभावित प्रदाता अमेज़न है। और, दुर्भाग्य से, दुनिया भर में काम करने वाली रूसी कंपनियों को अधिक नुकसान उठाना पड़ा।
यदि कंपनी वैश्विक है और इसके लिए रूस एक बहुत छोटा खंड है, तो 3-5% - ठीक है, एक तरह से या किसी अन्य, आप उन्हें दान कर सकते हैं।
यदि यह पूरी तरह से रूसी कंपनी है - मुझे यकीन है कि आपको स्थानीय रूप से पता लगाने की आवश्यकता है - ठीक है, यह सिर्फ इतना है कि उपयोगकर्ता स्वयं सुविधाजनक, आरामदायक होंगे, कम जोखिम होगा।
और अगर यह एक ऐसी कंपनी है जो विश्व स्तर पर काम करती है, और इसके पास रूस से और दुनिया भर के ग्राहकों के लगभग बराबर शेयर हैं? सेगमेंट की कनेक्टिविटी महत्वपूर्ण है, और उन्हें वैसे भी एक-दूसरे के साथ काम करना चाहिए।
मार्च 2018 के अंत में, Roskomnadzor ने सबसे बड़े ऑपरेटरों को एक पत्र भेजा, जिसमें कहा गया था कि वे कई मिलियन आईपी अमेज़ॅन को ब्लॉक करने की योजना बना रहे हैं ... ज़ेलो मैसेंजर। इन बहुत प्रदाताओं के लिए धन्यवाद - उन्होंने सफलतापूर्वक सभी को पत्र लीक किया, और एक समझ थी कि अमेज़ॅन के साथ कनेक्टिविटी अलग हो सकती है। यह शुक्रवार था, हम घबराहट में सर्वर.ru से सहयोगियों के पास भागे, शब्दों के साथ: "दोस्तों, हमें कई सर्वरों की आवश्यकता है जो रूस में नहीं होंगे, अमेज़ॅन में नहीं, लेकिन, उदाहरण के लिए, एम्स्टर्डम में कहीं," कम से कम किसी भी तरह से अपने स्वयं के वीपीएन और प्रॉक्सी को कुछ एंडपॉइंट के लिए सक्षम करने के लिए, जिसे हम बिल्कुल भी प्रभावित नहीं कर सकते हैं, उदाहरण के लिए उसी s3 के एंडपॉइंट्स - हम एक नई सेवा बढ़ाने और एक और आईपी प्राप्त करने की कोशिश नहीं कर सकते, हम आपको अभी भी वहां पहुंचने की आवश्यकता है। कुछ दिनों में, हमने इन सर्वरों को स्थापित किया, उन्हें उठाया, और सामान्य तौर पर, ताले की शुरुआत के लिए तैयार किया। यह उत्सुक है कि आईएलवी, प्रचार और उभरे घबराहट को देखते हुए कहा: "नहीं, हम अब कुछ भी ब्लॉक नहीं करेंगे।" (लेकिन यह ठीक उसी क्षण तक है जब वे टेलीग्राम को ब्लॉक करना शुरू कर देते हैं।) बाईपास विकल्प सेट करने और यह महसूस करने के बाद कि उन्होंने लॉक में प्रवेश नहीं किया है, हम, फिर भी, पूरी चीज को नष्ट नहीं करते हैं। तो, बस मामले में।

और 2019 में, हम अभी भी ताले की स्थितियों में रहते हैं। मैंने कल रात देखा: लगभग एक मिलियन आईपी अवरुद्ध होना जारी है। सच है, अमेज़ॅन लगभग पूरी तरह से अनब्लॉक हो गया, शिखर में 20 मिलियन पते तक पहुंच गया ... सामान्य तौर पर, वास्तविकता यह है कि कनेक्टिविटी, अच्छी कनेक्टिविटी - यह नहीं हो सकता है। एकाएक। यह तकनीकी कारणों से नहीं हो सकता है - आग, उत्खनन, यह सब। या, जैसा कि हमने देखा है, पूरी तरह से तकनीकी नहीं है। इसलिए, कोई भी बड़ा और बड़ा, अपने स्वयं के एएस-कामी के साथ, शायद इसे अन्य तरीकों से आगे बढ़ा सकता है - प्रत्यक्ष कनेक्ट और अन्य चीजें पहले से ही एल 2 स्तर पर हैं। लेकिन एक साधारण संस्करण में, जैसे कि हम या उससे भी छोटे, आप कर सकते हैं, बस के मामले में, सर्वरों के स्तर पर अतिरेक होता है, अग्रिम वीपीएन, प्रॉक्सी में कॉन्फ़िगर किया गया, उन खंडों में कॉन्फ़िगरेशन को जल्दी से स्विच करने की क्षमता के साथ जो आप महत्वपूर्ण कनेक्टिविटी हैं। । यह हमारे लिए एक से अधिक बार उपयोगी था, जब अमेज़ॅन लॉक शुरू हुए, हमने सबसे खराब स्थिति में एस 3 ट्रैफिक के माध्यम से जाने दिया, लेकिन धीरे-धीरे यह सब गलत हो गया।
और कैसे आरक्षित करें ... पूरे प्रदाता?
अब पूरे अमेज़ॅन की विफलता के मामले में हमारे पास कोई परिदृश्य नहीं है। हमारे पास रूस के लिए एक समान परिदृश्य है। हम रूस में एक प्रदाता द्वारा होस्ट किए गए थे, जिनसे हमने कई साइटों को चुना था। और एक साल पहले हम एक समस्या में भाग गए: भले ही ये दो डेटा केंद्र हैं, प्रदाता के नेटवर्क कॉन्फ़िगरेशन के स्तर पर पहले से ही समस्याएं हो सकती हैं जो दोनों डेटा केंद्रों को वैसे भी प्रभावित करेगा। और हम दोनों साइटों पर दुर्गमता प्राप्त कर सकते हैं। बेशक, वही हुआ। हमने अंततः वास्तुकला को फिर से परिभाषित किया। यह बहुत बदल नहीं गया है, लेकिन रूस के लिए अब हमारे पास दो साइट हैं, जो एक प्रदाता नहीं हैं, लेकिन दो अलग-अलग हैं। यदि उनमें से एक विफल हो जाता है, तो हम दूसरे पर स्विच कर सकते हैं।
Hypothetically, हम अमेज़न के लिए एक और प्रदाता के स्तर पर आरक्षित करने पर विचार कर रहे हैं; शायद Google, शायद कोई और ... लेकिन अभी तक हमने अभ्यास में देखा है कि अगर अमेज़न समान उपलब्धता क्षेत्र के स्तर पर दुर्घटनाग्रस्त हो जाता है, तो पूरे क्षेत्र के स्तर पर दुर्घटनाएँ काफी दुर्लभ हैं। इसलिए, हमारे पास सैद्धांतिक रूप से यह विचार है कि, शायद, हम एक आरक्षण करेंगे "अमेज़न अमेज़ॅन नहीं है," लेकिन व्यवहार में यह अभी तक मौजूद नहीं है।
स्वचालन के बारे में कुछ शब्द
क्या आपको हमेशा स्वचालन की आवश्यकता है? यह Dunning-Krueger प्रभाव को याद करने के लिए उपयुक्त है। एक्स-एक्सिस पर, हमारा ज्ञान और अनुभव, जिसे हम प्राप्त कर रहे हैं, और वाई-एक्सिस पर - हमारे कार्यों में आत्मविश्वास। पहले तो हम कुछ भी नहीं जानते हैं और बिल्कुल भी सुनिश्चित नहीं हैं। तब हम थोड़ा जानते हैं और मेगा-कॉन्फिडेंट हो जाते हैं - यह तथाकथित "मूर्खता का चरम" है, चित्र "मनोभ्रंश और साहस" द्वारा अच्छी तरह से चित्रित किया गया है। इसके अलावा हम पहले ही थोड़ा सीख चुके हैं और लड़ाई में जाने के लिए तैयार हैं। फिर हम कुछ मेगा-सीरियस रेक पर कदम रखते हैं, जब हमें कुछ पता लगता है तो निराशा की घाटी में गिर जाते हैं, लेकिन वास्तव में हम बहुत कुछ नहीं जानते हैं। फिर, जैसा कि आप अनुभव प्राप्त करते हैं, हम और अधिक आश्वस्त हो जाते हैं।
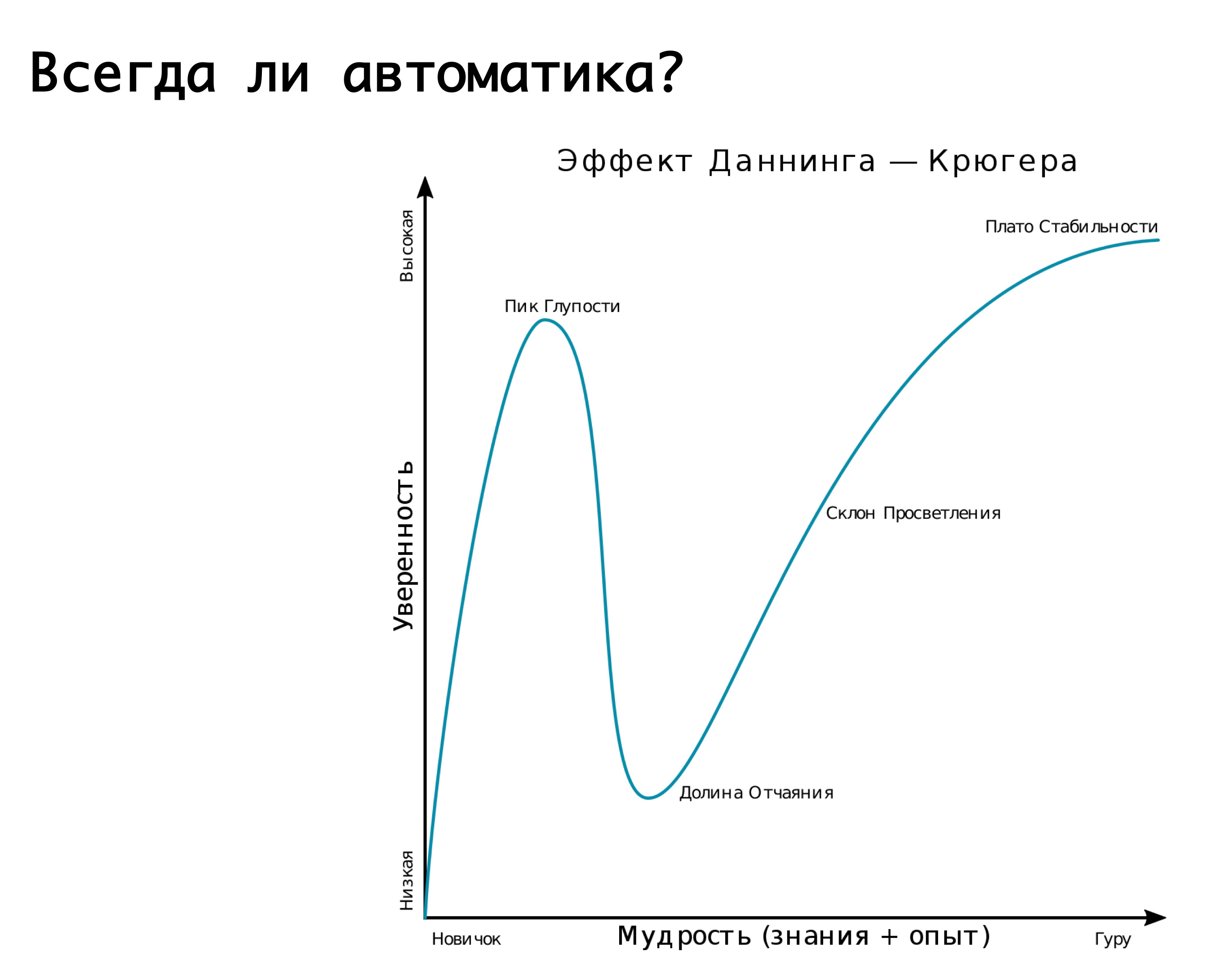
एक या किसी अन्य दुर्घटना के लिए स्वचालित रूप से स्विच करने के बारे में हमारा तर्क इस ग्राफ द्वारा बहुत अच्छी तरह से वर्णित है। — , . , , , . -: false positive, - , , -, . , - — . , . , . लेकिन! , , , , , , …
7 , , - , — -, , , , — — . - , , , . — , , — . , - — s3, , . , , - - . . , , — : , — ? , - , , - «, ».
पूर्णतावाद और वास्तविक ताकतों के बीच एक उचित समझौता, समय, पैसा जो आप उस योजना पर खर्च कर सकते हैं जो आपके पास अंततः होगा।यह पाठ कॉन्फ्रेंस अपडाइम डे 4 में अलेक्जेंडर डेमिडोव की रिपोर्ट का एक पूरक और विस्तारित संस्करण है ।