आपकी सेवा के उपयोगकर्ता जितने अधिक होंगे, उतनी अधिक संभावना होगी कि उन्हें मदद की आवश्यकता होगी। तकनीकी सहायता चैट एक स्पष्ट लेकिन महंगी समाधान है। लेकिन अगर आप मशीन लर्निंग तकनीक का उपयोग करते हैं, तो आप कुछ पैसे बचा सकते हैं।
बॉट अब सरल सवालों के जवाब दे सकता है। इसके अलावा, चैटबॉट को उपयोगकर्ता के इरादों को निर्धारित करने और संदर्भ को पकड़ने के लिए सिखाया जा सकता है ताकि वह मानव हस्तक्षेप के बिना उपयोगकर्ताओं की अधिकांश समस्याओं को हल कर सके। यह कैसे करें, व्लादिस्लाव ब्लिनोव और वलेरी बारानोवा, लोकप्रिय सहायक ओलेग के डेवलपर्स, यह पता लगाने में मदद करेंगे।
चैट बॉट को विकसित करने के कार्य में सरल तरीकों से अधिक जटिल लोगों की ओर बढ़ते हुए, हम व्यावहारिक कार्यान्वयन मुद्दों का विश्लेषण करेंगे और देखेंगे कि गुणवत्ता लाभ क्या प्राप्त किया जा सकता है और इसकी लागत कितनी होगी।
व्लादिस्लाव ब्लिनोव टिंकऑफ़ में संवाद प्रणालियों के एक वरिष्ठ डेवलपर हैं, जो अक्सर संक्षिप्त रूप से फेंकता है: एमएल, एनएलपी, डीएल, आदि। इसके अलावा, स्नातक विद्यालय मशीन सीखने और तंत्रिका नेटवर्क के माध्यम से हास्य के मॉडलिंग की जांच करता है।
वेलेरिया बारानोवा 5 साल से अधिक समय से पायथन में एनएलपी क्षेत्र में अच्छी चीजें लिख रही हैं। अब इंटरेक्टिव सिस्टम की टीम में टिंकफ चैट बॉट बनाती है और छात्रों के लिए मशीन लर्निंग कोर्स सिखाती है। वह कम्प्यूटेशनल हास्य के क्षेत्र में अनुसंधान में भी लगी हुई है, अर्थात् वह एआई को चुटकुले समझने और नए लोगों के साथ आने के लिए सिखाती है - वेलेरिया और व्लादिस्लाव इस बारे में यूटडाटा कॉन्फ में
बात करेंगे ।
Tinkoff Bank की सेवाओं का उपयोग लाखों लोग करते हैं। ऐसे कई उपयोगकर्ताओं के लिए चौबीसों घंटे सहायता प्रदान करने के लिए, एक बड़े कर्मचारी की आवश्यकता होती है, जो सेवा की उच्च लागत की ओर जाता है। यह तर्कसंगत लगता है कि उपयोगकर्ताओं के लोकप्रिय सवालों का जवाब चैट बॉट का उपयोग करके स्वचालित रूप से दिया जा सकता है।
उपयोगकर्ता का इरादा या इरादा
एक चैटबोट की जरूरत की पहली चीज यह समझना है
कि उपयोगकर्ता क्या चाहता है । इस कार्य को इरादों या इरादों का वर्गीकरण कहा जाता है। इसके अलावा, सभी मॉडलों और दृष्टिकोणों को इस कार्य के ढांचे में माना जाएगा।
आइए इंटेंट्स के वर्गीकरण का एक उदाहरण देखें। यदि आप लिखते हैं: "डेरा के सौ हस्तांतरण", चैट बॉट ओलेग समझ जाएगा कि यह एक धन हस्तांतरण का इरादा है, अर्थात्, उपयोगकर्ता का पैसा हस्तांतरण करने का इरादा है। या यों कहें कि लैरा को 100 रूबल की राशि के हस्तांतरण की आवश्यकता है।
हम तरीकों की तुलना करेंगे और परीक्षण नमूने पर उनके काम की गुणवत्ता का परीक्षण करेंगे, जिसमें उपयोगकर्ताओं के साथ वास्तविक संवाद शामिल हैं। हमारे नमूने में 30,000 से अधिक चिह्नित उदाहरण और 170 इरादे हैं, उदाहरण के लिए: सिनेमा में जाना, रेस्तरां खोजना, जमा करना या बंद करना आदि। ओलेग की अपनी राय बहुत कुछ है, और वह सिर्फ आपके साथ बातचीत कर सकता है।
शब्दकोश वर्गीकरण
इंटेंट को वर्गीकृत करने के कार्य में सबसे सरल काम
एक शब्दकोश का
उपयोग करना है । उदाहरण के लिए, यदि उपयोगकर्ता के वाक्यांश में "अनुवाद" शब्द दिखाई देता है, तो विचार करें कि धन हस्तांतरण किया जाना चाहिए।
आइए ऐसे सरल दृष्टिकोण की गुणवत्ता को देखें।
यदि क्लासिफायर उपयोगकर्ता के इरादे को "अनुवाद" शब्द द्वारा "मनी ट्रांसफर" के रूप में परिभाषित करता है, तो गुणवत्ता पहले से ही काफी अधिक होगी। परिशुद्धता - 88%, जबकि पूर्णता कम है, केवल 23% के बराबर है। यह समझ में आता है: शब्द "अनुवाद" कहने की सभी संभावनाओं का वर्णन नहीं करता है "किसी को धन हस्तांतरित करें"।
हालाँकि, इस दृष्टिकोण के फायदे हैं:
- कोई लेबल नमूनाकरण की आवश्यकता नहीं है (यदि आप मॉडल का अध्ययन नहीं करते हैं, तो नमूना लेने की आवश्यकता नहीं है)
- आप उच्च सटीकता प्राप्त कर सकते हैं यदि आप शब्दकोशों को अच्छी तरह से संकलित करते हैं (लेकिन इसमें समय और संसाधन लगेगा)।
हालांकि, इस तरह के समाधान की पूर्णता कम होने की संभावना है, क्योंकि किसी भी वर्ग के सभी रूपों का वर्णन करना मुश्किल है।
एक प्रतिधारण पर विचार करें। अगर मनी ट्रांसफर के इरादे के अलावा, "ट्रांसफर" में दूसरा इरादा भी शामिल हो सकता है - "ऑपरेटर को ट्रांसफर"। जब हम ऑपरेटर में एक नया अनुवाद करने का इरादा जोड़ते हैं, तो हमें अलग परिणाम मिलते हैं।
सटीकता 18 बिंदुओं से कम हो जाती है, जबकि, निश्चित रूप से पूर्णता नहीं बढ़ती है। यह दर्शाता है कि अधिक उन्नत दृष्टिकोण की आवश्यकता है।
पाठ विश्लेषण
मशीन सीखने का उपयोग करने से पहले, आपको यह समझने की आवश्यकता है कि पाठ को वेक्टर के रूप में कैसे प्रस्तुत किया जाए। सबसे आसान तरीकों में से
एक tf-idf वेक्टर का
उपयोग करना है ।
Tf-idf वेक्टर उपयोगकर्ता के वाक्यांश में प्रत्येक शब्द की घटना को ध्यान में रखता है और संग्रह में शब्दों की कुल घटना को ध्यान में रखता है। विभिन्न ग्रंथों में अक्सर पाए जाने वाले शब्दों का इस वेक्टर प्रतिनिधित्व में कम वजन होता है।
आइए tf-idf प्रतिनिधित्व पर रैखिक मॉडल की गुणवत्ता देखें (हमारे मामले में, लॉजिस्टिक प्रतिगमन)।
नतीजतन,
पूर्णता में तेजी से
वृद्धि हुई , और शब्दकोश के उपयोग के साथ सटीकता बनी रही, एफ 1-माप (सटीकता और पूर्णता के बीच भारित हार्मोनिक मतलब) में भी वृद्धि हुई। यही है, मॉडल खुद पहले से ही समझता है कि कौन से शब्द किस इरादे के लिए महत्वपूर्ण हैं - आपको खुद कुछ भी आविष्कार करने की आवश्यकता नहीं है।
डेटा विज़ुअलाइज़ेशन
डेटा विज़ुअलाइज़ेशन समझने में मदद करता है कि इंटेंस कैसे दिखते हैं, वे अंतरिक्ष में कितनी अच्छी तरह से समूहीकृत हैं। लेकिन हम सीधे बड़े आयाम के कारण tf-idf अभ्यावेदन की कल्पना नहीं कर सकते हैं, इसलिए हम
आयाम संपीड़न विधि - t-SNE का उपयोग करेंगे।
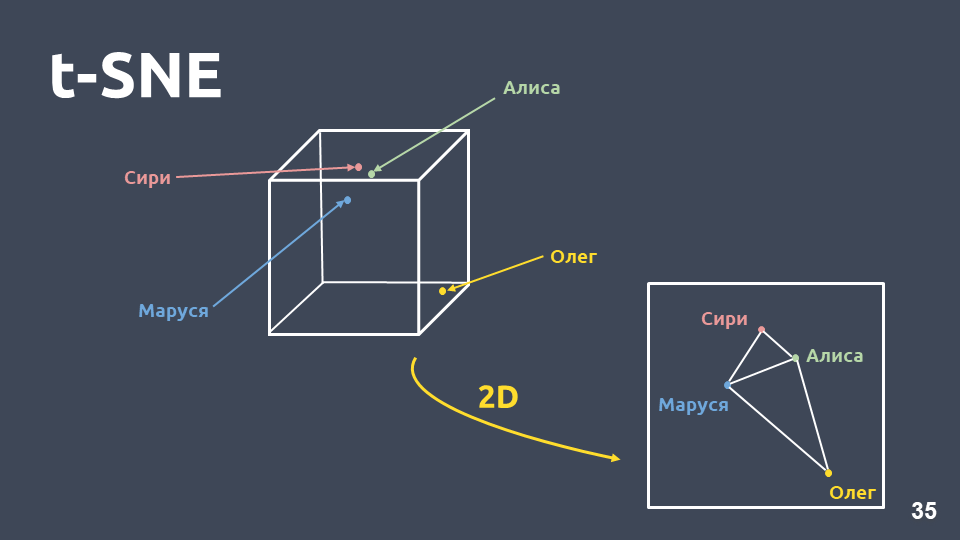
इस पद्धति और पीसीए के बीच मुख्य अंतर यह है कि जब दो-आयामी स्थान पर स्थानांतरित किया जाता है,
तो वस्तुओं के बीच की सापेक्ष दूरी संरक्षित होती है ।
t-idf (शीर्ष 10 इरादे) पर t-SNE, F1 स्कोर 0.92हमारे संग्रह में होने वाले शीर्ष 10 इरादों को ऊपर प्रस्तुत किया गया है। हरे रंग के डॉट्स हैं जो किसी भी इरादे से संबंधित नहीं हैं, और 10 क्लस्टर जो अलग-अलग रंगों के साथ चिह्नित हैं, अलग-अलग इरादे हैं। यह देखा जा सकता है कि उनमें से कुछ बहुत अच्छी तरह से समूहबद्ध हैं। भारित
एफ 1-माप 0.92 है - यह काफी अधिक है, आप पहले से ही इसके साथ काम कर सकते हैं।
इसलिए tf-idf पर एक रैखिक क्लासिफायरफ़ायर के साथ:
- तुलनीय सटीकता के साथ, शब्दकोश का उपयोग करने की तुलना में बहुत अधिक पूर्णता;
- यह सोचने की जरूरत नहीं है कि कौन से शब्द किस इरादे के अनुरूप हैं।
लेकिन इसके नुकसान भी हैं:
- सीमित शब्दावली, आप केवल उन शब्दों के लिए वजन प्राप्त कर सकते हैं जो प्रशिक्षण नमूने में मौजूद हैं;
- रीफ़्रेशिंग पर ध्यान नहीं दिया जाता है;
- पाठ में आने वाले शब्दों पर ध्यान नहीं दिया जाता है।
मिलावत
आइए हम रीफ़्रेशिंग की समस्या पर अधिक विस्तार से विचार करें।
Tf-idf वैक्टर केवल उन ग्रंथों के करीब हो सकते हैं जो शब्दों में प्रतिच्छेद करते हैं। वैक्टर के बीच निकटता की गणना उनके बीच के कोण के कोसाइन के माध्यम से की जा सकती है। सदिश निरूपण tf-idf में cosine निकटता की गणना विशिष्ट उदाहरणों के लिए की जाती है।
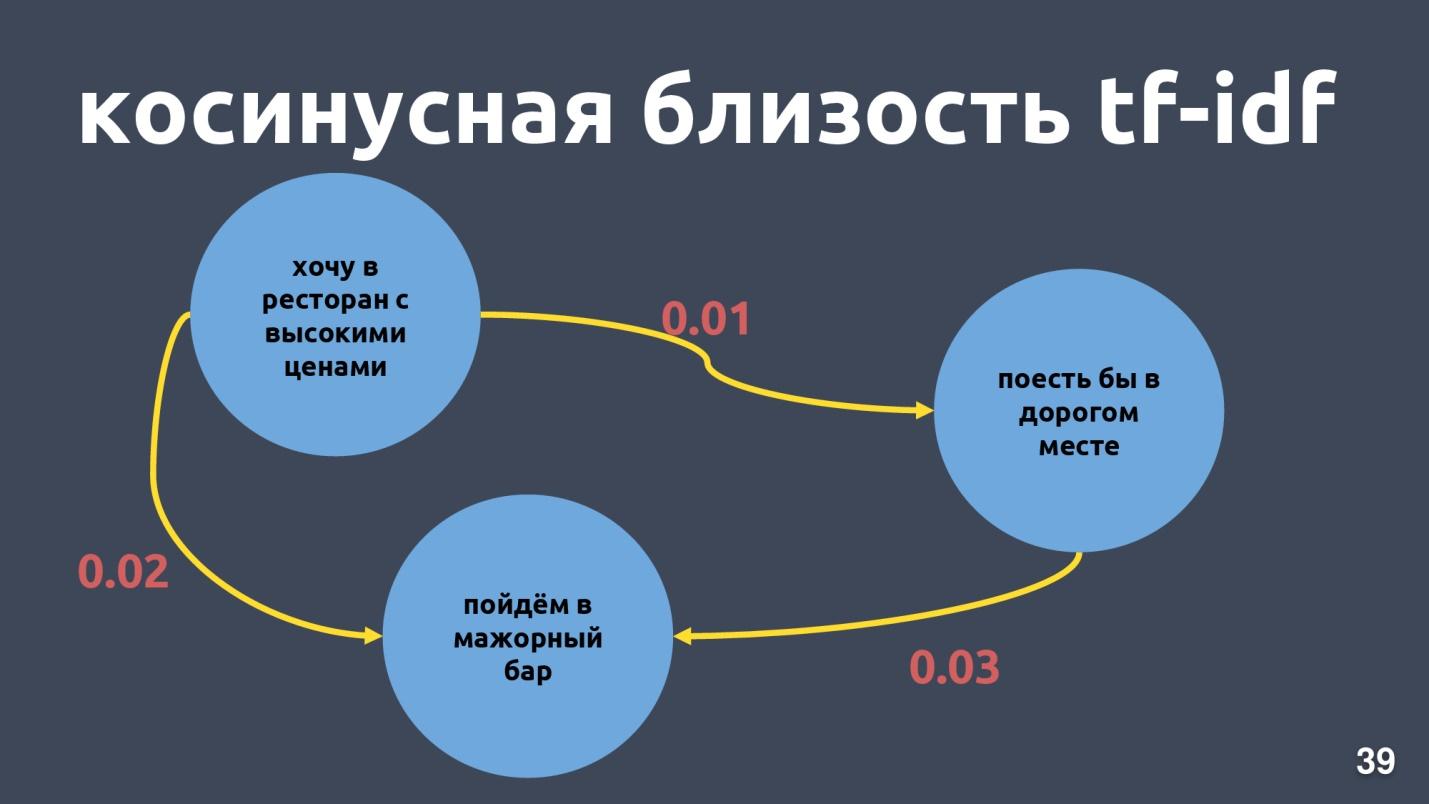
ये tf-idf वेक्टर प्रतिनिधित्व के लिए बहुत करीबी वाक्यांश नहीं हैं, हालांकि हमारे लिए यह एक ही इरादा है और एक ही वर्ग है।
इस बारे में क्या किया जा सकता है? उदाहरण के लिए, एक संख्या के बजाय, आप एक शब्द को पूरे वेक्टर के रूप में दर्शा सकते हैं - इसे "शब्द एम्बेडिंग" कहा जाता है।
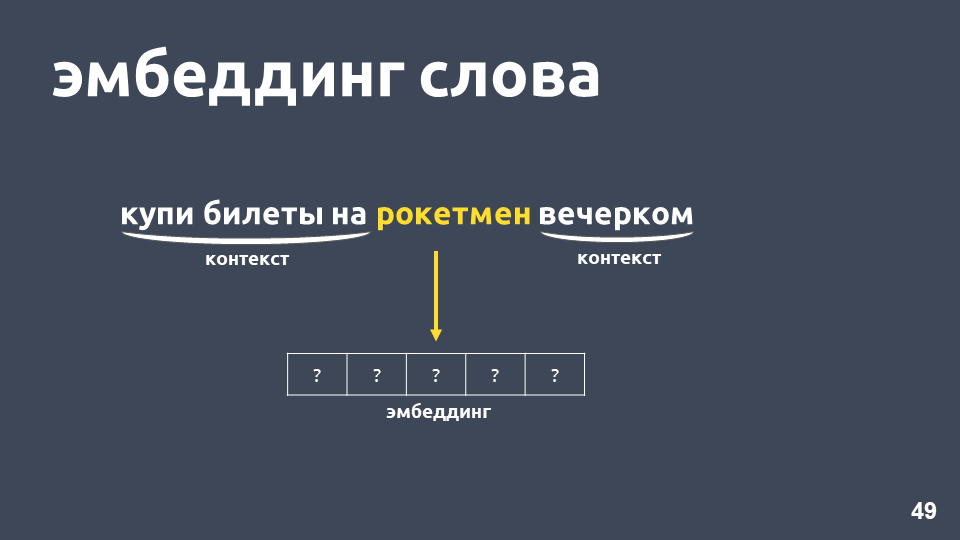
इस समस्या को हल करने के लिए सबसे लोकप्रिय मॉडल में से एक 2013 में प्रस्तावित किया गया था। इसे
शब्द 2vec कहा जाता है और इसका व्यापक रूप से उपयोग किया जाता है।
Word2vec सीखने के तरीकों में से एक लगभग निम्नानुसार काम करता है: हम पाठ लेते हैं, हम संदर्भ से कुछ शब्द लेते हैं और इसे बाहर निकालते हैं, फिर हम संदर्भ से एक और यादृच्छिक शब्द लेते हैं और दोनों शब्दों को एक-गर्म वैक्टर के रूप में पेश करते हैं। शब्दकोश आयाम के अनुसार एक-गर्म वेक्टर एक वेक्टर है, जहां केवल शब्दकोश में शब्द के सूचकांक के अनुरूप समन्वय होता है, जिसका मान 1 होता है, शेष 0।
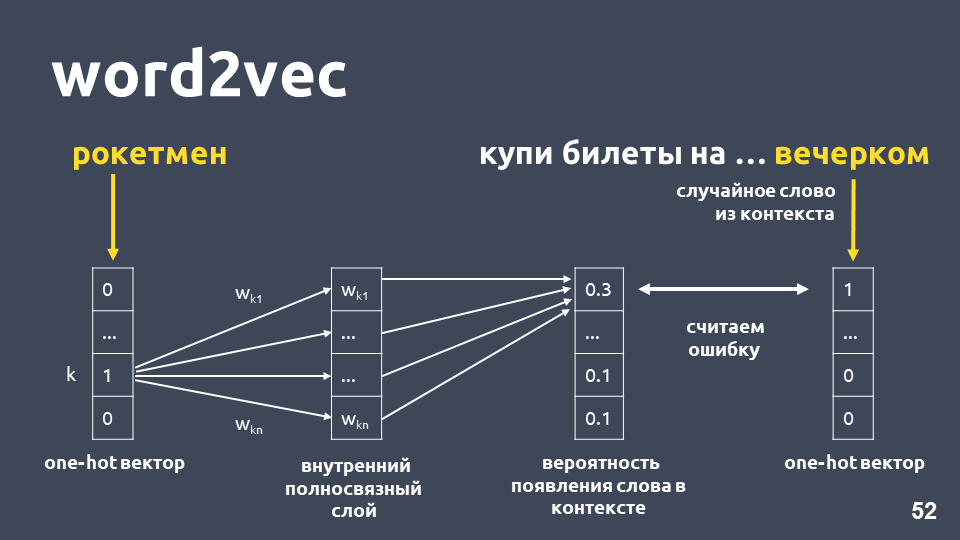
अगला, हम संदर्भ में अगले शब्द की भविष्यवाणी करने के लिए, "शाम को" शब्द का उपयोग करने के लिए "रॉकेटमैन" शब्द का उपयोग करने के लिए आंतरिक परत पर सक्रियण के बिना एक साधारण एकल-परत तंत्रिका नेटवर्क को प्रशिक्षित करते हैं। आउटपुट पर, हम शब्दकोश से सभी शब्दों के लिए संभाव्यता वितरण प्राप्त करते हैं जो निम्नानुसार है। चूंकि हम जानते हैं कि शब्द वास्तव में क्या था, हम त्रुटि की गणना कर सकते हैं, भार अपडेट कर सकते हैं, आदि।

हमारे नमूने पर प्रशिक्षण के परिणामस्वरूप प्राप्त अद्यतन भार शब्द एम्बेडिंग है।
संख्या के बजाय एम्बेडिंग का उपयोग करने का लाभ, सबसे पहले,
उस संदर्भ को ध्यान में रखा जाता है । एक लोकप्रिय उदाहरण: ट्रम्प और पुतिन शब्द 2vec में करीब हैं क्योंकि वे दोनों राष्ट्रपति हैं और अक्सर ग्रंथों में एक साथ उपयोग किए जाते हैं।
प्रशिक्षण नमूने में पाए गए शब्दों के लिए, आप बस एम्बेडिंग मैट्रिक्स लेते हैं, शब्द के सूचकांक द्वारा इसका वेक्टर लेते हैं, और एम्बेडिंग प्राप्त करते हैं।
ऐसा लगता है कि सब कुछ ठीक है, सिवाय इसके कि आपके मैट्रिक्स में कुछ शब्द नहीं हो सकते हैं, क्योंकि मॉडल ने उन्हें प्रशिक्षण के दौरान नहीं देखा था। अपरिचित शब्दों (आउट-ऑफ-शब्दावली) की समस्या से निपटने के लिए, 2014 में वे word2vec -
fasttext के संशोधन के साथ आए।
फास्टटेक्स निम्नानुसार काम करता है: यदि शब्द शब्दकोश में नहीं है, तो इसे प्रतीकात्मक n- ग्राम में विभाजित किया जाता है, प्रत्येक के लिए n-ग्राम एम्बेडिंग को n-ग्राम के एम्बेडिंग के मैट्रिक्स से लिया जाता है (जो शब्द2vec की तरह प्रशिक्षित होते हैं, एम्बेडिंग औसत होते हैं, और एक वेक्टर प्राप्त होता है।
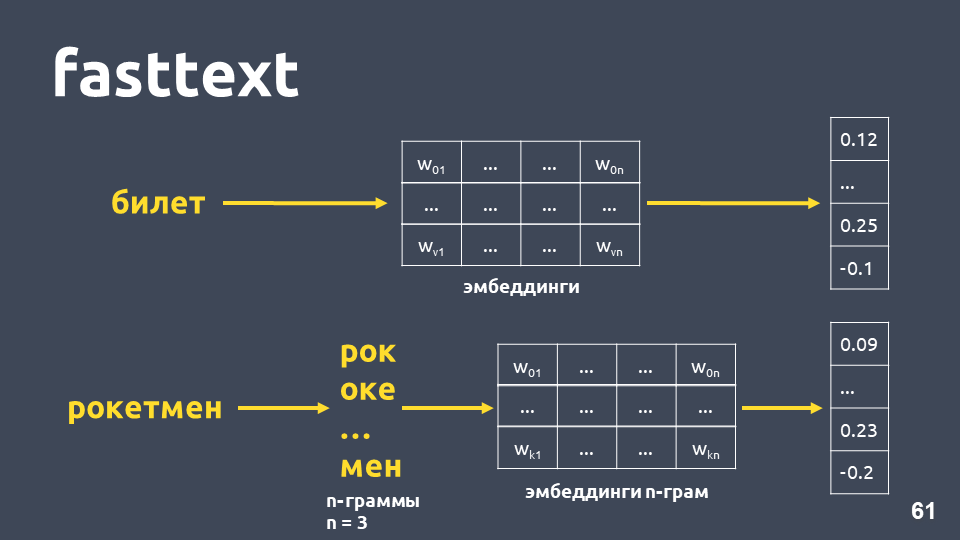
कुल मिलाकर, हमें ऐसे शब्द मिलते हैं जो हमारे शब्दकोश में नहीं हैं। अब हम
अपरिचित शब्दों के लिए भी समानता की गणना कर सकते हैं। और, काफी महत्वपूर्ण बात, रूसी, अंग्रेजी और चीनी के लिए प्रशिक्षित मॉडल हैं, उदाहरण के लिए, फेसबुक और
दीपपावलोव परियोजना, इसलिए आप इसे जल्दी से अपनी पाइपलाइन में शामिल कर सकते हैं।
लेकिन नुकसान ये रहे:- पूरे पाठ वेक्टर के लिए मॉडल का उपयोग नहीं किया जाता है। एक सामान्य पाठ वेक्टर प्राप्त करने के लिए, आपको कुछ सोचने की आवश्यकता है: आईडीएफ-वेट द्वारा गुणा के साथ औसत, या औसत और यह अलग-अलग कार्यों में अलग-अलग काम कर सकता है।
- एक शब्द के लिए वेक्टर अभी भी एक है, संदर्भ की परवाह किए बिना। Word2vec किसी भी संदर्भ के लिए एक शब्द वेक्टर को प्रशिक्षित करता है जिसमें शब्द होता है। बहु-मूल्यवान शब्दों के लिए (जैसे, उदाहरण के लिए, भाषा) एक और एक ही वेक्टर होगा।
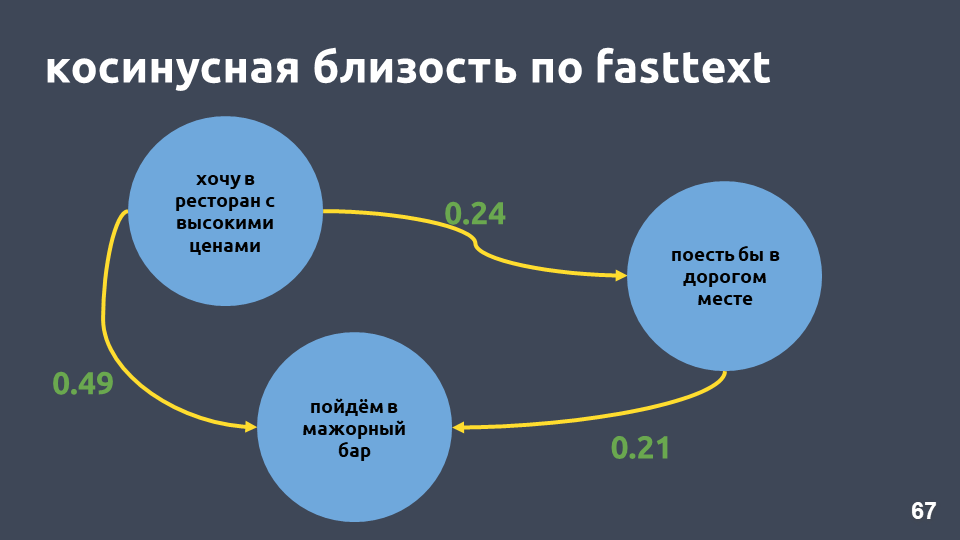
वास्तव में, फास्टटेक्स में हमारे उदाहरण में कॉज़ाइन निकटता tf-idf में कॉज़ीन निकटता से अधिक है, भले ही इन वाक्यांशों में केवल "सामान्य रूप में" हो।
t-SNE फास्टटेक्स पर (शीर्ष 10 इरादे), F1 स्कोर: 0.86हालांकि, जब टी-एसएनई अपघटन पर फास्टटेक्स के परिणामों की कल्पना करते हैं, तो इरादे क्लस्टर टफ-आईडीएफ की तुलना में बहुत खराब होते हैं। यहां एफ 1 का माप 0.92 के बजाय 0.86 है।
हमने एक प्रयोग किया: संयुक्त tf-idf और fasttext वैक्टर। गुणवत्ता बिल्कुल वैसी ही है, जब केवल tf-idf का उपयोग किया जाता है। यह सभी कार्यों के लिए सही नहीं है, ऐसी समस्याएं हैं जहां संयुक्त tf-idf और fasttext सिर्फ tf-idf से बेहतर काम करते हैं, या जहां fasttext tf-idf से बेहतर काम करता है। आपको प्रयोग करने और प्रयास करने की आवश्यकता है।
आइए इरादों की संख्या बढ़ाने की कोशिश करें (याद रखें कि हमारे पास उनमें से 170 हैं)। नीचे tf-idf वैक्टर पर शीर्ष 30 इरादों के लिए क्लस्टर हैं।
t-idf पर t-SNE (शीर्ष 30 इरादे), F1 स्कोर 0, 85 (10 पर यह 0.92 था)गुणवत्ता 7 अंक गिरती है, और अब हम एक स्पष्ट क्लस्टर संरचना नहीं देखते हैं।
आइए उन ग्रंथों के उदाहरणों को देखें जो भ्रमित होने लगे, क्योंकि और अधिक उदाहरण जोड़े गए थे जो शब्दार्थ और शब्दों में अंतर करते हैं।
उदाहरण के लिए: "और यदि आप एक डिपॉजिट खोलते हैं, तो उस पर ब्याज क्या है?" और "और मैं 7 प्रतिशत का योगदान देना चाहता हूं।" बहुत समान वाक्यांश, लेकिन ये अलग इरादे हैं। पहले मामले में, एक व्यक्ति जमा के लिए शर्तों को जानना चाहता है, और दूसरे मामले में, जमा को खोलने के लिए। ऐसे ग्रंथों को अलग-अलग वर्गों में विभाजित करने के लिए, हमें कुछ और जटिल -
गहन सीखने की आवश्यकता है ।
भाषा मॉडल
हम पाठ का एक वेक्टर प्राप्त करना चाहते हैं और, विशेष रूप से, एक शब्द का वेक्टर, जो उपयोग के संदर्भ पर निर्भर करेगा। ऐसे वेक्टर को प्राप्त करने का मानक तरीका
भाषा मॉडल से एम्बेडिंग का
उपयोग करना है ।
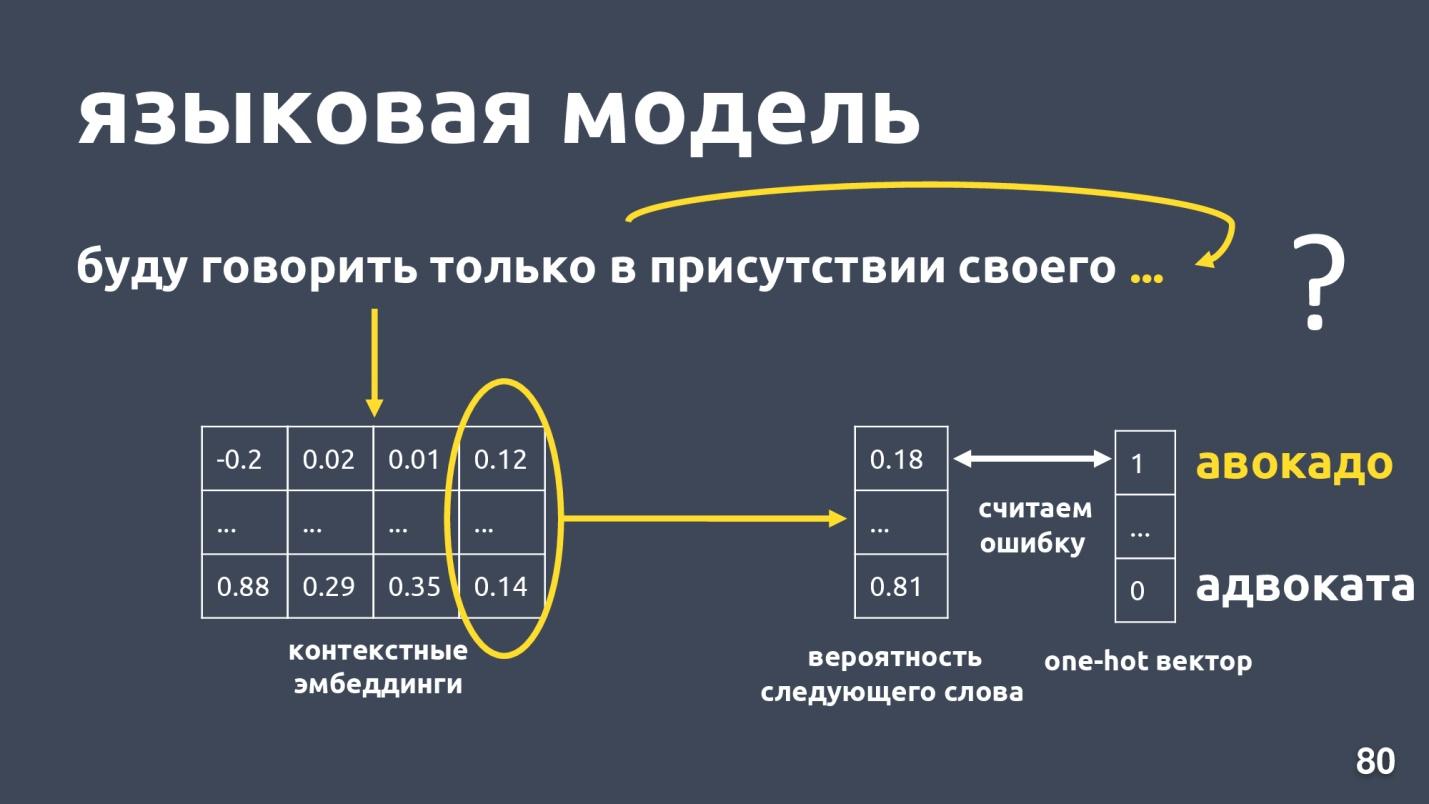
भाषा मॉडल भाषा मॉडलिंग की समस्या को हल करता है। और यह कार्य क्या है? उदाहरण के लिए शब्दों का एक क्रम होने दें: "मैं केवल अपनी खुद की उपस्थिति में बोलूंगा ...", और हम अनुक्रम में अगले शब्द की भविष्यवाणी करने की कोशिश कर रहे हैं। भाषा मॉडल एम्बेडिंग के लिए संदर्भ प्रदान करता है। प्रत्येक शब्द के लिए प्रासंगिक एम्बेडिंग और वैक्टर प्राप्त करने के बाद, व्यक्ति अगले शब्द की संभावना का अनुमान लगा सकता है।
एक शब्दकोश आयाम वेक्टर है, और प्रत्येक शब्द को अगले होने की संभावना सौंपी गई है। हम फिर से जानते हैं कि कौन सा शब्द वास्तव में था, एक गलती पर विचार करें और मॉडल को प्रशिक्षित करें।
काफी कुछ भाषा मॉडल हैं, क्या पिछले साल उछाल था? और कई अलग-अलग आर्किटेक्चर प्रस्तावित किए गए हैं। उनमें से एक
एलमो है ।
एल्मो
ELMo मॉडल का विचार पहले पाठ में प्रत्येक शब्द के लिए एक प्रतीकात्मक शब्द एम्बेडिंग का निर्माण करना है, और फिर उनके लिए एक
LSTM नेटवर्क को इस तरह से लागू करना है कि एम्बेडिंग को ध्यान में रखा जाता है जो उस संदर्भ को ध्यान में रखता है जिसमें शब्द होता है।
आइए हम जांच करें कि प्रतीकात्मक एम्बेडिंग कैसे प्राप्त की जाती है: हम शब्द को प्रतीकों में तोड़ते हैं, प्रत्येक प्रतीक के लिए एक एम्बेडिंग परत लागू करते हैं और एक एम्बेडिंग मैट्रिक्स प्राप्त करते हैं। जब केवल प्रतीकों की बात आती है, तो ऐसे मैट्रिक्स का आयाम छोटा होता है। फिर, एक-आयामी कन्वेंशन को एम्बेडिंग मैट्रिक्स पर लागू किया जाता है, जैसा कि आमतौर पर एनएलपी में किया जाता है, अंत में अधिकतम पूलिंग के साथ, एक वेक्टर प्राप्त होता है। इस वेक्टर पर एक दो-परत, तथाकथित
राजमार्ग नेटवर्क लागू होता है, जो
किसी शब्द के
सामान्य वेक्टर की गणना करता
है ।
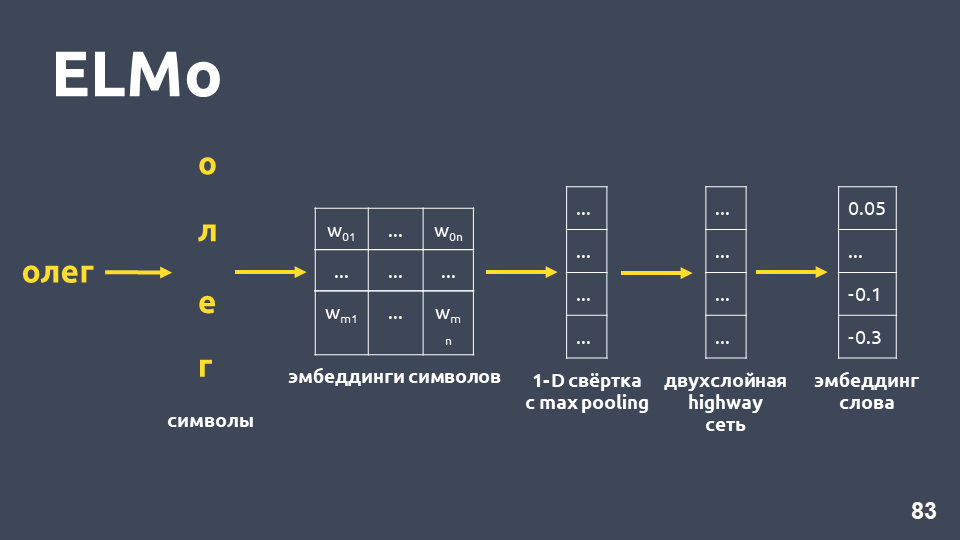
इसके अलावा, मॉडल किसी ऐसे शब्द के लिए भी एम्बेडिंग की परिकल्पना का निर्माण करेगा, जो प्रशिक्षण सेट में नहीं मिला था।
प्रत्येक शब्द के लिए प्रतीकात्मक एम्बेडिंग प्राप्त करने के बाद, हम उनके लिए दो-परत BiLSTM नेटवर्क लागू करते हैं।
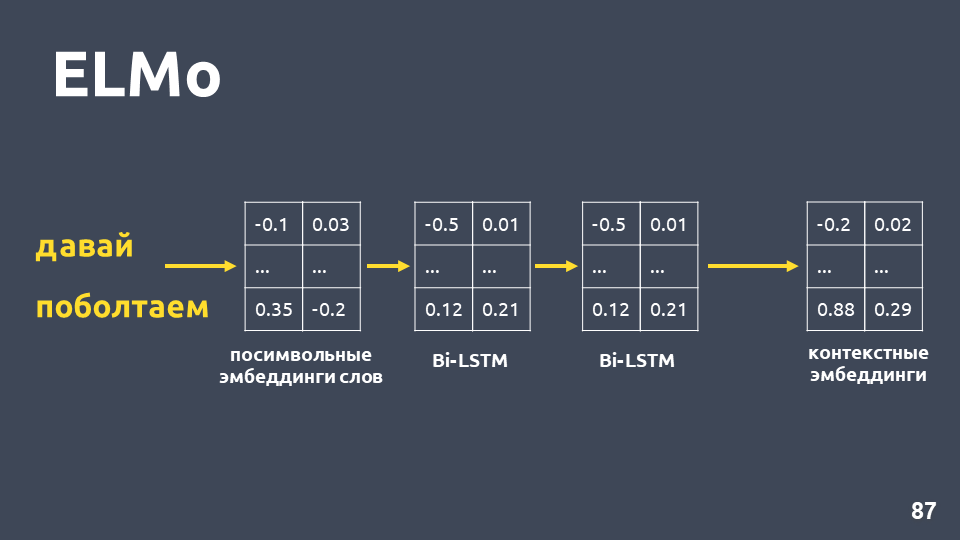
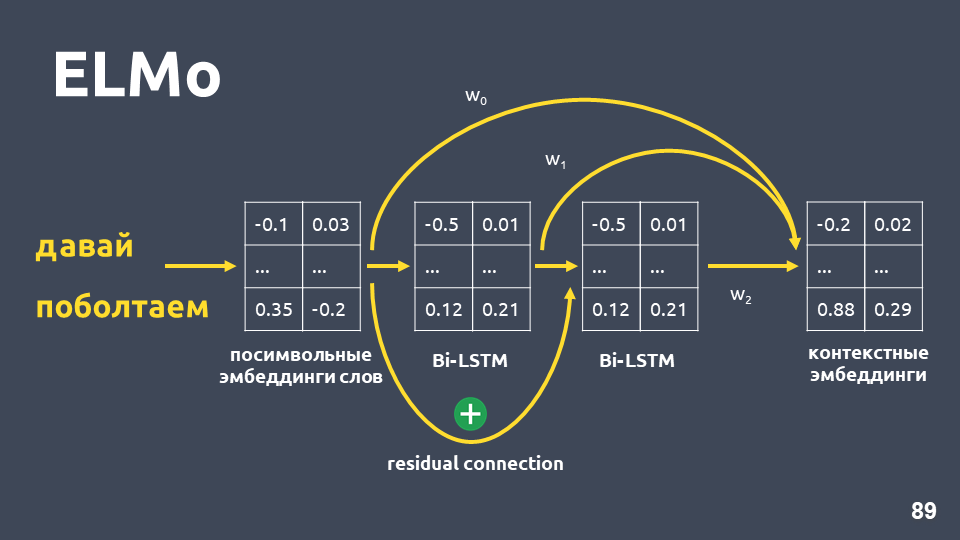
दो-परत BiLSTM नेटवर्क को लागू करने के बाद, आमतौर पर अंतिम परत के छिपे हुए राज्यों को आमतौर पर लिया जाता है, और यह माना जाता है कि यह प्रासंगिक एम्बेडिंग है। लेकिन एलमो में दो विशेषताएं हैं:
- पहले LSTM परत के इनपुट और इसके आउटपुट के बीच अवशिष्ट संबंध । लुप्त होती ग्रेडिएंट्स की समस्या से बचने के लिए LSTM इनपुट को आउटपुट में जोड़ा जाता है।
- एलमो के लेखक प्रत्येक शब्द के लिए प्रतीकात्मक एम्बेडिंग के संयोजन का प्रस्ताव रखते हैं, पहली LSTM परत का उत्पादन और कुछ भार के साथ दूसरी LSTM परत का आउटपुट जो प्रत्येक कार्य के लिए चुना जाता है। यह निम्न-स्तरीय सुविधाओं और उच्च-स्तरीय विशेषताओं दोनों को ध्यान में रखना आवश्यक है जो LSTM की पहली और दूसरी परतें देते हैं।
हमारी समस्या में, हमने इन तीन एम्बेडिंग का एक सरल औसत उपयोग किया और इस प्रकार प्रत्येक शब्द के लिए प्रासंगिक एम्बेडिंग प्राप्त की।
भाषा मॉडल निम्नलिखित लाभ प्रदान करता है:
- किसी शब्द का वेक्टर उस संदर्भ पर निर्भर करता है जिसमें शब्द का उपयोग किया जाता है। यही है, उदाहरण के लिए, शरीर के हिस्से और भाषाई शब्द के अर्थ में "भाषा" शब्द के लिए, हमें अलग-अलग वैक्टर मिलते हैं।
- जैसा कि शब्द 2vec और फास्टटेक्स के मामले में, कई प्रशिक्षित मॉडल हैं, उदाहरण के लिए, दीपपावलोव परियोजना से। आप तैयार मॉडल ले सकते हैं और अपने कार्य में लागू करने का प्रयास कर सकते हैं।
- आपको अब यह सोचने की आवश्यकता नहीं है कि वैक्टर शब्द को कैसे औसत किया जाए। ELMo मॉडल तुरंत सभी पाठों का एक वेक्टर तैयार करता है।
- आप अपने कार्य के लिए भाषा मॉडल को पुनः प्राप्त कर सकते हैं, इसके लिए विभिन्न तरीके हैं, उदाहरण के लिए, ULMFiT।
केवल माइनस ही रहता है -
भाषा मॉडल इस बात की गारंटी नहीं देता है कि जो पाठ एक ही वर्ग के हैं, यानी एक इरादे के हैं, वे वेक्टर स्थान के करीब होंगे।
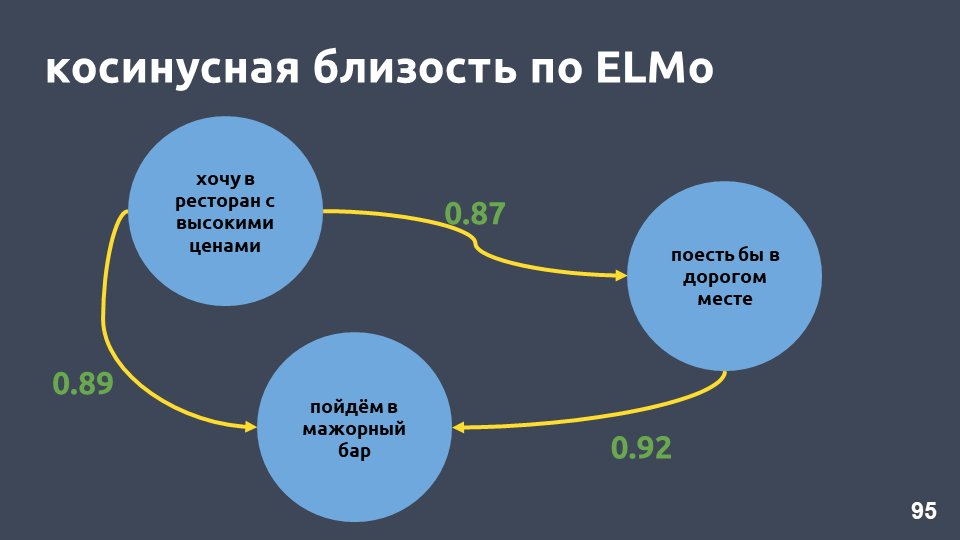
हमारे रेस्तरां उदाहरण में, एल्मो मॉडल के अनुसार कोसाइन मूल्य वास्तव में अधिक हो गए।
एल एसएनओ (शीर्ष 10 इरादों) पर t-SNE, F1 स्कोर 0.93 (0.92 tf-idf द्वारा)शीर्ष 10 इरादों वाले क्लस्टर भी अधिक स्पष्ट हैं। ऊपर दिए गए आंकड़े में, सभी 10 क्लस्टर स्पष्ट रूप से दिखाई दे रहे हैं, जबकि सटीकता थोड़ी बढ़ गई है।
ELMo पर t-SNE (शीर्ष 30 इरादे) F1 स्कोर 0.86 (tf-idf द्वारा 0.85)शीर्ष 30 इरादों के लिए, क्लस्टर संरचना अभी भी संरक्षित है, और एक बिंदु से गुणवत्ता में वृद्धि भी है।
लेकिन ऐसे मॉडल में कोई गारंटी नहीं है कि प्रस्ताव "और यदि आप जमा खोलते हैं, तो उन पर ब्याज क्या है?" और "और मैं 7 प्रतिशत योगदान देना चाहता हूं" एक दूसरे से बहुत दूर होगा, हालांकि वे अलग-अलग वर्गों में रहते हैं। एलमो के साथ, हम बस भाषा मॉडल सीखते हैं, और यदि शब्दार्थ समान रूप से पाठ करते हैं, तो वे करीब होंगे।
एल्मो को हमारी कक्षाओं के बारे में कुछ भी नहीं पता है , लेकिन आप कक्षा लेबल का उपयोग करके अंतरिक्ष में एक ही इरादे के पाठ वैक्टर को एक साथ ला सकते हैं।
स्याम देश का नेटवर्क
टेक्स्ट वेक्टराइज़ेशन और इरादों के दो उदाहरणों के लिए अपने पसंदीदा न्यूरल नेटवर्क आर्किटेक्चर को लें। प्रत्येक उदाहरण के लिए हमें एम्बेडिंग मिलती है, और फिर हम उनके बीच कोसनी दूरी की गणना करते हैं।
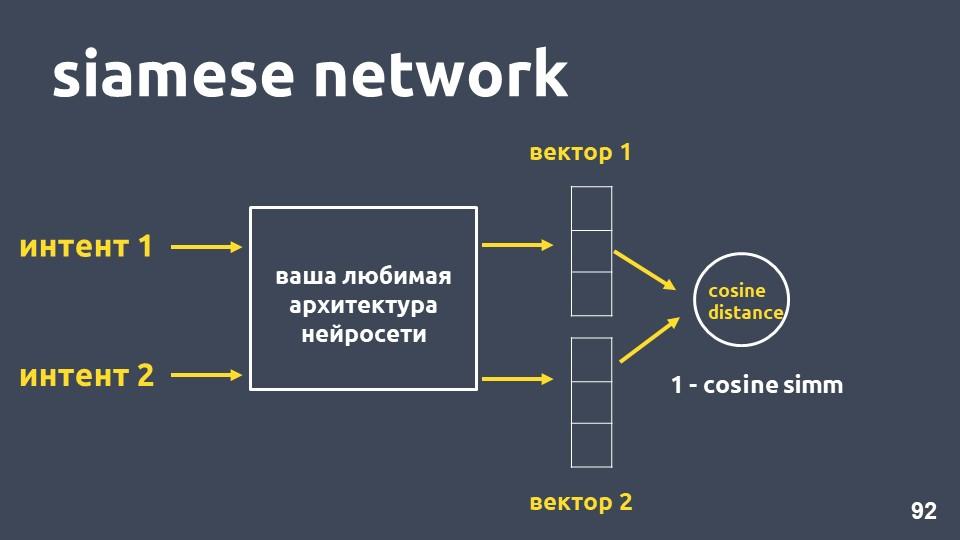
कोसाइन की दूरी एक माइनस के बराबर है जिसे हम पहले मिले थे।
इस दृष्टिकोण को
सियामी नेटवर्क कहा जाता है।
हम एक ही कक्षा से ग्रंथ चाहते हैं, उदाहरण के लिए, "स्थानान्तरण करें" और "पैसा फेंकें," अंतरिक्ष में बंद होने के लिए। यही है, उनके वैक्टर के बीच कोसाइन दूरी यथासंभव छोटी होनी चाहिए, आदर्श रूप से शून्य। और अलग-अलग इरादों से संबंधित ग्रंथों को जितना संभव हो उतना अलग करना चाहिए।
लेकिन व्यवहार में, प्रशिक्षण की यह विधि इतनी अच्छी तरह से काम नहीं करती है, क्योंकि विभिन्न वर्गों की वस्तुएं एक दूसरे से पर्याप्त रूप से दूरस्थ नहीं होती हैं।
"ट्रिपल लॉस" नामक हानि फ़ंक्शन बहुत बेहतर काम करता है। इसमें त्रिगुण नामक वस्तुओं के त्रिगुणों का उपयोग किया जाता है।
चित्रण एक ट्रिपल को दर्शाता है: एक नीले वृत्त में एक लंगर वस्तु, हरे रंग में एक सकारात्मक वस्तु और एक लाल वृत्त में एक नकारात्मक वस्तु। नकारात्मक वस्तु और लंगर विभिन्न वर्गों में हैं, और सकारात्मक और लंगर एक में हैं।

हम यह सुनिश्चित करना चाहते हैं कि प्रशिक्षण के बाद सकारात्मक वस्तु एंकर से नकारात्मक के करीब हो। ऐसा करने के लिए, हम वस्तुओं के जोड़े के बीच कोसिन की दूरी पर विचार करते हैं और हाइपरपैरिमेट - "मार्जिन" को पेश करते हैं - वह दूरी जो हम सकारात्मक और नकारात्मक वस्तुओं के बीच होने की उम्मीद करते हैं।

हानि फ़ंक्शन इस तरह दिखता है:
दूसरे शब्दों में, प्रशिक्षण के दौरान, हम यह प्राप्त करते हैं कि सकारात्मक वस्तु नकारात्मक, कम से कम मार्जिन से लंगर के करीब है। यदि नुकसान फ़ंक्शन शून्य है, तो यह काम करता है, और हम प्रशिक्षण समाप्त करते हैं, अन्यथा हम उद्देश्य फ़ंक्शन को कम करना जारी रखते हैं।
हमने मॉडल को प्रशिक्षित करने के बाद, हमें अभी भी एक क्लासिफायरियर नहीं मिलता है, यह केवल ऐसे एम्बेडिंग प्राप्त करने के लिए एक विधि है जो एक इरादे में झूठ बोलने वाले ऑब्जेक्ट्स में पास वैक्टर होने की सबसे अधिक संभावना है।
जब हमें मॉडल मिला, हम एम्बेडिंग के शीर्ष पर एक अलग वर्गीकरण विधि का उपयोग कर सकते हैं।
KNN एक अच्छा फिट है, क्योंकि हम पहले ही हासिल कर चुके हैं कि एम्बेडिंग की एक अलग क्लस्टर संरचना है।
याद रखें कि केएनएन कैसे ग्रंथों के लिए काम करता है: पाठ का एक तत्व लें, इसके लिए एम्बेडिंग करें, इसे वेक्टर स्थान में अनुवाद करें, और फिर देखें कि इसका पड़ोसी कौन है। पड़ोसियों के बीच, हम सबसे लगातार वर्ग पर विचार करते हैं और निष्कर्ष निकालते हैं कि नई वस्तु इस वर्ग से संबंधित है।
हमारे द्वारा उपयोग किए जाने वाले एम्बेडिंग का आयाम 300 है, और प्रशिक्षण नमूने में लगभग 500,000 ऑब्जेक्ट हैं। निकटतम पड़ोसियों को खोजने के लिए मानक तरीके प्रदर्शन के मामले में हमारे अनुरूप नहीं हैं। हमने
HNSW विधि -
Hierarchical Navigable Small World का उपयोग किया ।
नेविगेबल स्मॉल वर्ल्ड एक जुड़ा हुआ ग्राफ है जिसमें वर्टिकल के बीच कुछ किनारे होते हैं जो कि बड़ी दूरी पर होते हैं, और पास के वर्टिकल के बीच कई एज होते हैं। हमारे मामले में, किनारे की लंबाई को कोसाइन दूरी से निर्धारित किया जाएगा, अर्थात। , , .
, Hierarchical. , , , . .
, , , , .
, , , , , . , , ,
— 0,95-0,99 , .
, , , ,
. .
, . , . .
t-SNE siamese (-10 ), F1 score 0,95 (0,93 ELMo)t-SNE siamese (-30 ), F1 score 0,87 (0,86 ELMo)10 ELMo, 30 — , .
परिणाम
, , , 2-5, . , , , 20-30 . , .
, , , tf-idf . , , , .
, word2vec fasttext. , , . , , , .
, , ELMo. , , , , , .
ELMo, , .
, - . . , . , , . , , .. , .
:— «Deep Learning vs common sense» — UseData Conf . , - , 18 , , .
, , , , 16 UseData Conf .