लेख में, मैं आपको बताऊंगा कि हमने पोस्टग्रेसीक्यूएल गलती सहिष्णुता मुद्दे पर कैसे संपर्क किया, यह हमारे लिए क्यों महत्वपूर्ण हो गया है, और अंत में क्या हुआ।
हमारे पास अत्यधिक भरी हुई सेवा है: दुनिया भर में 2.5 मिलियन उपयोगकर्ता, हर दिन 50K + सक्रिय उपयोगकर्ता। सर्वर आयरलैंड के एक क्षेत्र में ऐमाज़ोन में स्थित हैं: ऑपरेशन में लगातार 100+ विभिन्न सर्वर होते हैं, जिनमें से लगभग 50 डेटाबेस के साथ होते हैं।
संपूर्ण बैकएंड एक बड़ा अखंड स्टेटफुल जावा एप्लिकेशन है जो क्लाइंट के लिए एक निरंतर वेबस्कैट कनेक्शन रखता है। एक बोर्ड पर कई उपयोगकर्ताओं के एक साथ काम के साथ, वे सभी वास्तविक समय में परिवर्तन देखते हैं, क्योंकि हम डेटाबेस में प्रत्येक परिवर्तन को रिकॉर्ड करते हैं। हमारे डेटाबेस में प्रति सेकंड लगभग 10K प्रश्न हैं। रेडिस में चरम भार पर, हम प्रति सेकंड 80-100K प्रश्नों पर लिखते हैं।

हमने Redis से PostgreSQL में स्विच क्यों किया
प्रारंभ में, हमारी सेवा ने Redis के साथ काम किया, जो एक कुंजी-मूल्य रिपॉजिटरी है जो सर्वर के रैम में सभी डेटा को संग्रहीत करता है।
रेडिस के पेशेवरों:
- उच्च प्रतिक्रिया दर, के रूप में सब कुछ स्मृति में संग्रहीत है;
- बैकअप और प्रतिकृति की सुविधा।
हमारे लिए विपक्ष Redis:
- कोई वास्तविक लेनदेन नहीं हैं। हमने अपने आवेदन के स्तर पर उन्हें अनुकरण करने की कोशिश की। दुर्भाग्य से, यह हमेशा अच्छी तरह से काम नहीं करता था और बहुत जटिल कोड लिखने की आवश्यकता होती थी।
- डेटा की मात्रा मेमोरी की मात्रा से सीमित है। जैसे-जैसे डेटा की मात्रा बढ़ेगी, मेमोरी बढ़ेगी, और अंत में, हम चयनित इंस्टेंस की विशेषताओं में चलेंगे, जिन्हें एडब्ल्यूएस में इंस्टेंस के प्रकार को बदलने के लिए हमारी सेवा को रोकना होगा।
- निम्न विलंबता स्तर को लगातार बनाए रखना आवश्यक है, जैसा कि हमारे पास बहुत बड़ी संख्या में अनुरोध हैं। हमारे लिए इष्टतम विलंब स्तर 17-20 एमएस है। 30-40 एमएस के स्तर पर, हमें अपने आवेदन के अनुरोधों और सेवा की गिरावट के लंबे जवाब मिलते हैं। दुर्भाग्य से, सितंबर 2018 में हमारे साथ ऐसा हुआ, जब किसी कारण से रेडिस के उदाहरणों में सामान्य से 2 गुना अधिक विलंबता मिली। समस्या को हल करने के लिए, हमने बिना रखरखाव के लिए दिन के मध्य में सेवा बंद कर दी और समस्याग्रस्त रेडिस उदाहरण को बदल दिया।
- कोड में मामूली त्रुटियों के साथ भी डेटा असंगति प्राप्त करना आसान है और फिर इस डेटा को ठीक करने के लिए कोड लिखने में बहुत समय व्यतीत करना है।
हमने नुकसान को ध्यान में रखा और महसूस किया कि सामान्य लेन-देन और विलंबता पर कम निर्भरता के साथ हमें कुछ अधिक सुविधाजनक स्थानांतरित करने की आवश्यकता है। एक अध्ययन का आयोजन किया, कई विकल्पों का विश्लेषण किया और PostgreSQL को चुना।
हम 1.5 साल के लिए एक नए डेटाबेस में जा रहे हैं और केवल डेटा का एक छोटा सा हिस्सा स्थानांतरित कर दिया है, इसलिए अब हम Redis और PostgreSQL के साथ मिलकर काम कर रहे हैं। डेटाबेस के बीच डेटा ले जाने और स्विच करने के चरणों के बारे में अधिक जानकारी
मेरे सहयोगी ने एक
लेख में लिखी है।
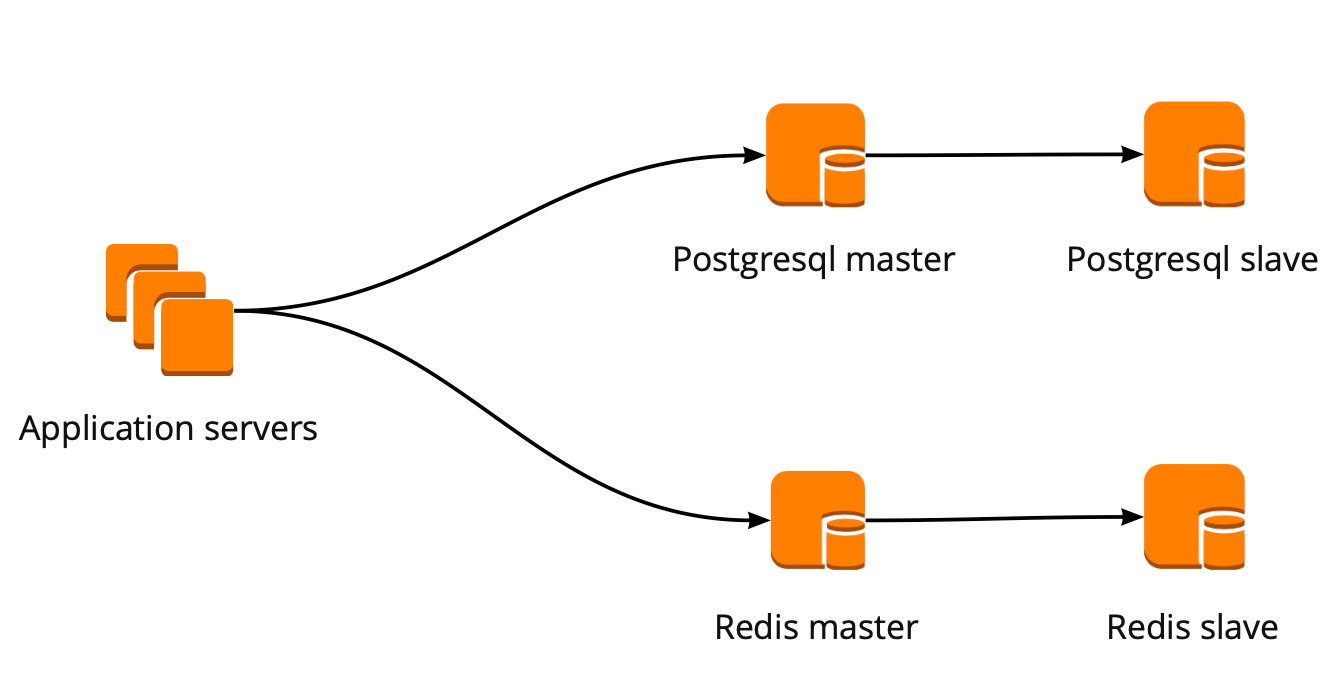
जब हमने बस आगे बढ़ना शुरू किया, तो हमारे आवेदन ने डेटाबेस के साथ सीधे काम किया और रेडिस और पोस्टग्रेसीएस विज़ार्ड में बदल गया। PostgreSQL क्लस्टर में एक मास्टर और एक एसिंक्रोनस प्रतिकृति प्रतिकृति शामिल थी। डेटाबेस संचालन योजना इस प्रकार दिखाई देती है:
PgBouncer परिनियोजन
जब हम आगे बढ़ रहे थे, तो उत्पाद भी विकसित हो गया: उपयोगकर्ताओं की संख्या और पोस्टग्रेक्यूएल के साथ काम करने वाले सर्वरों की संख्या में वृद्धि हुई, और हम कनेक्शनों को याद करने लगे। PostgreSQL प्रत्येक कनेक्शन के लिए एक अलग प्रक्रिया बनाता है और संसाधनों की खपत करता है। आप एक निश्चित बिंदु तक कनेक्शन की संख्या बढ़ा सकते हैं, अन्यथा गैर-इष्टतम डेटाबेस ऑपरेशन प्राप्त करने का एक मौका है। इस स्थिति में आदर्श विकल्प एक कनेक्शन प्रबंधक की पसंद होगा जो आधार के सामने खड़ा होगा।
हमारे पास कनेक्शन प्रबंधक के लिए दो विकल्प थे: Pgpool और PgBouncer। लेकिन पहले डेटाबेस के साथ काम करने के लेनदेन मोड का समर्थन नहीं करता है, इसलिए हमने PgBouncer को चुना।
हमने निम्नलिखित कार्य योजना बनाई है: हमारा आवेदन एक PgBouncer तक पहुँचता है, इसके बाद मास्टर्स पोस्टग्रैसक्यूएल, और प्रत्येक मास्टर के पीछे, एसिंक्रोनस प्रतिकृति के साथ एक प्रतिकृति।

उसी समय, हम PostgreSQL में डेटा की पूरी मात्रा को संग्रहीत नहीं कर सकते थे, और डेटाबेस के साथ काम करने की गति हमारे लिए महत्वपूर्ण थी, इसलिए हमने आवेदन स्तर पर PostgreSQL को तेज करना शुरू कर दिया। ऊपर वर्णित योजना इसके लिए अपेक्षाकृत सुविधाजनक है: एक नया PostgreSQL शार्क को जोड़ते समय, यह PgBouncer कॉन्फ़िगरेशन को अपडेट करने के लिए पर्याप्त है और एप्लिकेशन तुरंत नए शार्क के साथ काम कर सकता है।
PgBouncer दोष सहिष्णुता
इस योजना ने तब तक काम किया जब तक कि केवल PgBouncer उदाहरण की मृत्यु नहीं हुई। हम एडब्ल्यूएस में स्थित हैं, जहां सभी उदाहरण हार्डवेयर पर चल रहे हैं जो समय-समय पर मर जाते हैं। ऐसे मामलों में, उदाहरण बस नए हार्डवेयर में जाता है और फिर से काम करता है। यह PgBouncer के साथ हुआ, लेकिन यह अनुपलब्ध हो गया। इस गिरावट का परिणाम 25 मिनट के लिए हमारी सेवा की दुर्गमता थी। AWS ऐसी स्थितियों के लिए उपयोगकर्ता की ओर से अतिरेक का उपयोग करने की सिफारिश करता है, जो उस समय हमारे साथ लागू नहीं किया गया था।
उसके बाद, हमने गंभीरता से PgBouncer और PostgreSQL क्लस्टर की सहिष्णुता के बारे में सोचा, क्योंकि इसी तरह की स्थिति हमारे AWS खाते में किसी भी उदाहरण के साथ फिर से हो सकती है।
हमने निम्न प्रकार से PgBouncer फॉल्ट टॉलरेंस स्कीम का निर्माण किया: सभी एप्लिकेशन सर्वर नेटवर्क लोड बैलेंसर तक पहुंचते हैं, जिसके पीछे दो PgBouncer हैं। PgBouncer में से प्रत्येक प्रत्येक शार्क के एक ही मास्टर PostgreSQL को देखता है। यदि AWS का उदाहरण फिर से क्रैश हो जाता है, तो सभी ट्रैफ़िक को दूसरे PgBouncer के माध्यम से पुनर्निर्देशित किया जाता है। दोष सहिष्णुता नेटवर्क लोड बैलेंसर AWS प्रदान करता है।
यह योजना आपको आसानी से नए PgBouncer सर्वर जोड़ने की अनुमति देती है।

एक PostgreSQL विफलता क्लस्टर बनाना
इस समस्या को हल करने के लिए, हमने अलग-अलग विकल्पों पर विचार किया: स्व-लिखित विफलता, repmgr, AWS RDS, पेट्रोनी।
स्व-लिखित स्क्रिप्ट
वे मास्टर के काम की निगरानी कर सकते हैं और, इसके गिरने की स्थिति में, मास्टर को प्रतिकृति को बढ़ावा देने और Pggouncer के कॉन्फ़िगरेशन को अपडेट कर सकते हैं।
इस दृष्टिकोण के फायदे अधिकतम सादगी हैं, क्योंकि आप स्वयं स्क्रिप्ट लिखते हैं और समझते हैं कि वे कैसे काम करते हैं।
विपक्ष:
- गुरु की मृत्यु नहीं हो सकती है, इसके बजाय, एक नेटवर्क विफलता हो सकती है। यह जानने के बिना विफलता, मास्टर को प्रतिकृति को आगे बढ़ाएगी, और पुराने मास्टर काम करना जारी रखेंगे। परिणामस्वरूप, हमें मास्टर की भूमिका में दो सर्वर मिलते हैं और हमें पता नहीं चलता कि उनमें से कौन सा नवीनतम डेटा है। इस स्थिति को विभाजित-मस्तिष्क भी कहा जाता है;
- हम एक प्रतिकृति के बिना रह गए थे। हमारे कॉन्फ़िगरेशन में, मास्टर और एक प्रतिकृति, स्विच करने के बाद, यह मास्टर के पास जाता है और हमारे पास अब प्रतिकृतियां नहीं होती हैं, इसलिए हमें मैन्युअल रूप से एक नई प्रतिकृति जोड़ना होगा;
- हमें फेलओवर ऑपरेशन की अतिरिक्त निगरानी की आवश्यकता है, जबकि हमारे पास 12 PostgreSQL शार्क हैं, जिसका अर्थ है कि हमें 12 क्लस्टर की निगरानी करनी चाहिए। यदि आप शार्क की संख्या बढ़ाते हैं, तो आपको अभी भी विफलता को अपडेट करने के लिए याद रखना चाहिए।
स्व-लिखित विफलता बहुत जटिल दिखती है और इसे गैर-तुच्छ समर्थन की आवश्यकता होती है। एक एकल पोस्टग्रैसक्यूएल क्लस्टर के साथ, यह सबसे आसान विकल्प होगा, लेकिन यह पैमाने पर नहीं है, इसलिए यह हमारे लिए उपयुक्त नहीं है।
Repmgr
PostgreSQL समूहों के लिए प्रतिकृति प्रबंधक, जो एक PostgreSQL क्लस्टर के संचालन का प्रबंधन कर सकता है। उसी समय, इसमें कोई स्वचालित विफलता "बॉक्स से बाहर" नहीं है, इसलिए काम के लिए आपको तैयार समाधान के शीर्ष पर अपना खुद का "आवरण" लिखना होगा। इसलिए सब कुछ स्व-लिखित पटकथा की तुलना में और भी जटिल हो सकता है, इसलिए हमने रेपग्रे की कोशिश भी नहीं की।
AWS आरडीएस
यह हमारे लिए आपकी जरूरत की हर चीज का समर्थन करता है, जानता है कि कैसे बैकअप और एक कनेक्शन पूल का समर्थन करता है। इसमें स्वचालित स्विचिंग है: मास्टर की मृत्यु पर, प्रतिकृति नया मास्टर बन जाता है, और एडब्ल्यूएस नए मास्टर को डीएनएस रिकॉर्ड बदल देता है, जबकि प्रतिकृतियां अलग-अलग AZ में हो सकती हैं।
नुकसान में सूक्ष्म सेटिंग्स की कमी शामिल है। ठीक-ट्यूनिंग के एक उदाहरण के रूप में: हमारे उदाहरणों पर tcp कनेक्शन के लिए प्रतिबंध हैं, जो दुर्भाग्य से, आरडीएस में नहीं किया जा सकता है:
net.ipv4.tcp_keepalive_time=10 net.ipv4.tcp_keepalive_intvl=1 net.ipv4.tcp_keepalive_probes=5 net.ipv4.tcp_retries2=3
इसके अलावा, एडब्ल्यूएस आरडीएस की कीमत नियमित आवृत्ति मूल्य से लगभग दो गुना अधिक है, जो इस निर्णय को खारिज करने का मुख्य कारण था।
Patroni
यह PostgreSQL को अच्छे प्रलेखन, स्वचालित विफलता और गीथब स्रोत कोड के साथ प्रबंधित करने के लिए एक अजगर टेम्पलेट है।
पेट्रोनी के पेशेवरों:
- प्रत्येक कॉन्फ़िगरेशन पैरामीटर को चित्रित किया गया है, यह स्पष्ट है कि यह कैसे काम करता है;
- स्वचालित विफलता बॉक्स से बाहर काम करती है;
- यह अजगर में लिखा गया है, और चूंकि हम खुद अजगर में बहुत लिखते हैं, इसलिए हमारे लिए समस्याओं से निपटना आसान होगा और संभवतः, परियोजना के विकास में भी मदद मिलेगी;
- यह पूरी तरह से PostgreSQL को नियंत्रित करता है, आपको एक बार में क्लस्टर के सभी नोड्स पर कॉन्फ़िगरेशन को बदलने की अनुमति देता है, और यदि नए कॉन्फ़िगरेशन को लागू करने के लिए क्लस्टर पुनरारंभ की आवश्यकता होती है, तो यह फिर से Patroni का उपयोग करके किया जा सकता है।
विपक्ष:
- प्रलेखन से यह स्पष्ट नहीं है कि PgBouncer के साथ कैसे काम किया जाए। हालाँकि इसे माइनस कहना मुश्किल है, क्योंकि पेट्रोनी का काम पोस्टग्रेसीक्यूएल का प्रबंधन करना है, और पेट्रोनी का कनेक्शन कैसे चलेगा यह हमारी समस्या है;
- बड़े संस्करणों पर पेट्रोनी के कार्यान्वयन के कुछ उदाहरण हैं, जबकि खरोंच से कार्यान्वयन के कई उदाहरण हैं।
परिणामस्वरूप, एक विफलता क्लस्टर बनाने के लिए, हमने पेट्रोनी को चुना।
पेट्रोनी कार्यान्वयन प्रक्रिया
पेट्रोनी से पहले, हमारे पास कॉन्फ़िगरेशन में 12 पोस्टग्रेसीएसडी शार्क थे, एक मास्टर और एक प्रतिकृति एसिंक्रोनस प्रतिकृति के साथ। एप्लिकेशन सर्वर ने नेटवर्क लोड बैलेंसर के माध्यम से डेटाबेस तक पहुंच बनाई, जिसके पीछे PgBouncer के साथ दो उदाहरण थे, और उनके पीछे सभी PostgreSQL सर्वर थे।
पेट्रोनी को लागू करने के लिए, हमें एक वितरित क्लस्टर कॉन्फ़िगरेशन रिपॉजिटरी का चयन करना होगा। पेट्रोनी वितरित कॉन्फ़िगरेशन स्टोरेज सिस्टम जैसे कि etcd, Zookeeper, Consul के साथ काम करता है। हमारे पास सिर्फ ठेस पर काम करने वाले कौंसल क्लस्टर है जो वॉल्ट के साथ मिलकर काम करता है और हम अब इसका उपयोग नहीं करते हैं। अपने इच्छित उद्देश्य के लिए कौंसुल का उपयोग शुरू करने का एक बड़ा कारण।
कैसे संरक्षक के साथ संरक्षक काम करता है
हमारे पास एक कॉन्सल क्लस्टर है, जिसमें तीन नोड्स होते हैं, और एक पैट्रोनी क्लस्टर, जिसमें एक लीडर और एक प्रतिकृति होती है (पैट्रोनी में, एक मास्टर को क्लस्टर लीडर कहा जाता है, और दासों को प्रतिकृतियां कहा जाता है)। पेट्रोनी क्लस्टर का प्रत्येक उदाहरण लगातार क्लस्टर स्थिति की जानकारी को कंसल को भेजता है। इसलिए, कौंसल से आप हमेशा पाट्रोनी क्लस्टर के वर्तमान कॉन्फ़िगरेशन का पता लगा सकते हैं और इस समय कौन नेता है।

पेट्रोनी को कौंसुल से जोड़ने के लिए, आधिकारिक दस्तावेज का अध्ययन करना पर्याप्त है, जो कहता है कि आपको होस्ट को http या https प्रारूप में निर्दिष्ट करने की आवश्यकता है, यह निर्भर करता है कि हम कंसुल के साथ कैसे काम करते हैं, और कनेक्शन योजना, वैकल्पिक रूप से:
host: the host:port for the Consul endpoint, in format: http(s)://host:port scheme: (optional) http or https, defaults to http
यह सरल दिखता है, लेकिन यहां से नुकसान की शुरुआत होती है। कंसल के साथ हम https के माध्यम से एक सुरक्षित कनेक्शन पर काम कर रहे हैं और हमारा कनेक्शन विन्यास इस तरह दिखेगा:
consul: host: https://server.production.consul:8080 verify: true cacert: {{ consul_cacert }} cert: {{ consul_cert }} key: {{ consul_key }}
लेकिन वह काम नहीं करता है। प्रारंभ में, पेट्रोनी कौंसुल से जुड़ नहीं सकता है, क्योंकि यह वैसे भी http का पालन करने की कोशिश करता है।
पेट्रोनी के स्रोत कोड ने समस्या से निपटने में मदद की। अच्छी बात यह अजगर में लिखा है। यह पता चला है कि मेजबान पैरामीटर को पूरी तरह से पार्स नहीं किया गया है, और योजना में प्रोटोकॉल निर्दिष्ट किया जाना चाहिए। यहाँ हमारे साथ काम करने के लिए काम कर रहे कॉन्फ़िगरेशन ब्लॉक है:
consul: host: server.production.consul:8080 scheme: https verify: true cacert: {{ consul_cacert }} cert: {{ consul_cert }} key: {{ consul_key }}
कौंसुल टेम्पलेट
इसलिए, हमने एक विन्यास के लिए भंडारण को चुना है। अब आपको यह समझने की जरूरत है कि पैट्रॉनी क्लस्टर में लीडर को बदलते समय PgBouncer अपना कॉन्फ़िगरेशन कैसे स्विच करेगा। प्रलेखन इस प्रश्न का उत्तर नहीं देता है, क्योंकि वहाँ, सिद्धांत रूप में, PgBouncer के साथ काम का वर्णन नहीं किया गया है।
समाधान की तलाश में, हमें एक लेख मिला (मुझे नाम याद नहीं है, दुर्भाग्य से), जहां यह लिखा गया था कि PgBouncer और Patroni को जोड़ने में कौंसल-टेम्पलेट ने बहुत मदद की। इसने हमें कॉन्सुल-टेम्प्लेट के काम का अध्ययन करने के लिए प्रेरित किया।
यह पता चला कि कॉन्सल-टेम्पलेट लगातार कॉन्सल में पोस्टग्रेसीक्यूएल क्लस्टर के कॉन्फ़िगरेशन की निगरानी करता है। जब नेता बदलता है, तो वह PgBouncer कॉन्फ़िगरेशन को अपडेट करता है और इसे रिबूट करने के लिए एक कमांड भेजता है।
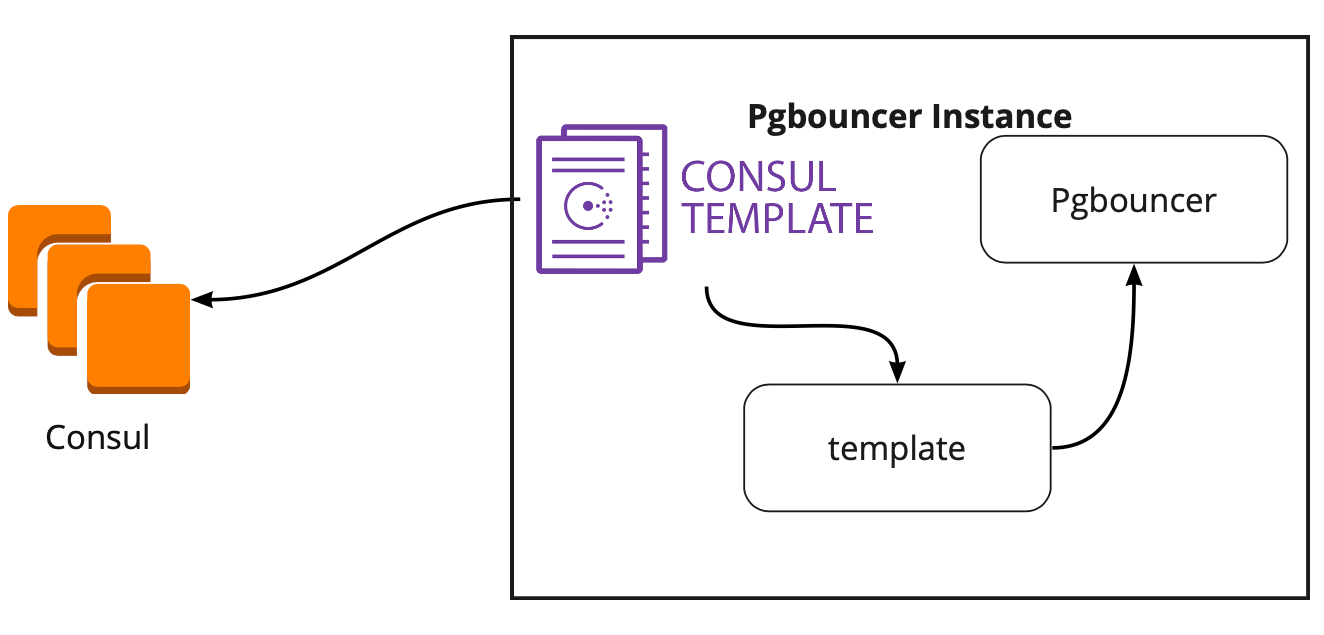
टेम्प्लेट का बड़ा प्लस यह है कि इसे कोड के रूप में संग्रहीत किया जाता है, इसलिए एक नया शार्क जोड़ते समय, यह एक नई प्रतिबद्धता बनाने और कोड के रूप में इन्फ्रास्ट्रक्चर के सिद्धांत का समर्थन करते हुए, स्वचालित मोड में टेम्पलेट को अपडेट करने के लिए पर्याप्त है।
पेट्रोनी के साथ नई वास्तुकला
परिणामस्वरूप, हमें यह कार्य योजना मिली:

सभी एप्लिकेशन सर्वर बैलेंसर का उपयोग करते हैं → दो उदाहरण PgBouncer इसके पीछे हैं → प्रत्येक उदाहरण पर एक onsul-टेम्पलेट लॉन्च किया गया है, जो प्रत्येक Patroni क्लस्टर की स्थिति की निगरानी करता है और PgBouncer कॉन्फ़िगरेशन की प्रासंगिकता पर नज़र रखता है, जो प्रत्येक क्लस्टर के वर्तमान नेता से अनुरोध करता है।
मैनुअल परीक्षण
कार्यक्रम शुरू करने से पहले, हमने इस सर्किट को एक छोटे परीक्षण वातावरण पर लॉन्च किया और स्वचालित स्विचिंग के संचालन की जांच की। उन्होंने बोर्ड खोला, स्टिकर को स्थानांतरित किया और उस पल में क्लस्टर के नेता को "मार" दिया। AWS में, बस कंसोल के माध्यम से इंस्टेंस को बंद करें।

स्टिकर 10-20 सेकंड के भीतर वापस आ गया, और फिर फिर से सामान्य रूप से चलना शुरू कर दिया। इसका मतलब यह है कि पेट्रोनी क्लस्टर ने सही ढंग से काम किया: इसने नेता को बदल दिया, कौंसुल को सूचना भेजी और कंसल-टेम्पलेट ने तुरंत इस जानकारी को उठाया, PgBouncer कॉन्फ़िगरेशन को बदल दिया और पुनः लोड करने के लिए कमांड भेजा।
उच्च भार के तहत कैसे जीवित रहें और न्यूनतम डाउनटाइम बनाए रखें?
सब कुछ महान काम करता है! लेकिन नए सवाल उठते हैं: यह उच्च भार के तहत कैसे काम करेगा? कैसे जल्दी और सुरक्षित रूप से उत्पादन में सब कुछ रोल करें?
परीक्षण वातावरण जिसमें हम लोड परीक्षण करते हैं, हमें पहले प्रश्न का उत्तर देने में मदद करता है। यह वास्तुकला में उत्पादन के लिए पूरी तरह से समान है और परीक्षण डेटा उत्पन्न किया है, जो उत्पादन के लिए मात्रा में लगभग बराबर हैं। हम परीक्षण के दौरान PostgreSQL जादूगरों में से एक को "मार" करने का निर्णय लेते हैं और देखते हैं कि क्या होता है। लेकिन इससे पहले, स्वचालित रोलिंग की जांच करना महत्वपूर्ण है, क्योंकि इस वातावरण पर हमारे पास कई पोस्टग्रेसीएसडी शार्क हैं, इसलिए हमें बेचने से पहले कॉन्फ़िगरेशन स्क्रिप्ट का उत्कृष्ट परीक्षण मिलेगा।
दोनों कार्य महत्वाकांक्षी दिखते हैं, लेकिन हमारे पास PostgreSQL 9.6 है। शायद हम तुरंत 11.2 में अपग्रेड करेंगे?
हम इसे 2 चरणों में करने का निर्णय लेते हैं: पहले 11.2 पर अपग्रेड करें, फिर पेट्रोनी लॉन्च करें।
PostgreSQL अपडेट
PostgreSQL के संस्करण को जल्दी से अपग्रेड करने के लिए, आपको
-k विकल्प का उपयोग करना चाहिए, जो डिस्क पर एक कड़ी बनाता है और आपके डेटा को कॉपी करने की कोई आवश्यकता नहीं है। 300-400 जीबी के आधार पर, अपडेट में 1 सेकंड लगता है।
हमारे पास बहुत अधिक शार्क हैं, इसलिए अपडेट को स्वचालित रूप से करने की आवश्यकता है। ऐसा करने के लिए, हमने Ansible playbook लिखी है, जो हमारे लिए संपूर्ण अपडेट प्रक्रिया करती है:
/usr/lib/postgresql/11/bin/pg_upgrade \ <b>--link \</b> --old-datadir='' --new-datadir='' \ --old-bindir='' --new-bindir='' \ --old-options=' -c config_file=' \ --new-options=' -c config_file='
यहां यह ध्यान रखना महत्वपूर्ण है कि अपग्रेड शुरू करने से पहले, अपग्रेड की संभावना के बारे में सुनिश्चित करने के लिए इसे
-चेक पैरामीटर के साथ निष्पादित करना आवश्यक है। हमारी स्क्रिप्ट अपग्रेड के लिए कॉन्फिगरेशन का विकल्प भी बनाती है। स्क्रिप्ट हमने 30 सेकंड में पूरी की, यह एक उत्कृष्ट परिणाम है।
पेट्रोनी लॉन्च करें
दूसरी समस्या को हल करने के लिए, बस पेट्रोनी के विन्यास को देखें। आधिकारिक रिपॉजिटरी में initdb के साथ एक उदाहरण कॉन्फ़िगरेशन है, जो एक नए डेटाबेस को आरम्भ करने के लिए जिम्मेदार है जब पैट्रोनी पहली बार लॉन्च किया गया था। लेकिन चूंकि हमारे पास एक तैयार-निर्मित डेटाबेस है, इसलिए हमने इस खंड को कॉन्फ़िगरेशन से हटा दिया है।
जब हमने तैयार PostgreSQL क्लस्टर पर पेट्रोनी स्थापित करना शुरू किया और इसे चलाने के लिए, हमें एक नई समस्या का सामना करना पड़ा: दोनों सर्वरों ने नेता के रूप में शुरू किया। पेट्रोनी क्लस्टर की प्रारंभिक स्थिति के बारे में कुछ भी नहीं जानता है और दोनों सर्वरों को एक ही नाम के साथ दो अलग-अलग समूहों के रूप में शुरू करने की कोशिश करता है। इस समस्या को हल करने के लिए, दास पर डेटा निर्देशिका हटाएं:
rm -rf /var/lib/postgresql/
यह केवल दास पर किया जाना चाहिए!एक स्वच्छ प्रतिकृति को जोड़ने पर, पेट्रोनी एक बेसबैकअप नेता बनाता है और इसे प्रतिकृति पर पुनर्स्थापित करता है, और फिर वॉल-लॉग द्वारा वर्तमान स्थिति के साथ पकड़ लेता है।
हमारे सामने एक और कठिनाई यह है कि सभी PostgreSQL समूहों को डिफ़ॉल्ट रूप से मुख्य कहा जाता है। जब प्रत्येक क्लस्टर दूसरे के बारे में कुछ नहीं जानता है, तो यह सामान्य है। लेकिन जब आप पेट्रोनी का उपयोग करना चाहते हैं, तो सभी समूहों का एक अनूठा नाम होना चाहिए। समाधान PostgreSQL कॉन्फ़िगरेशन में क्लस्टर नाम को बदलना है।
लोड परीक्षण
हमने एक परीक्षण शुरू किया जो बोर्डों पर उपयोगकर्ताओं के काम का अनुकरण करता है। जब लोड हमारे औसत दैनिक मूल्य पर पहुंच गया, तो हमने उसी परीक्षण को दोहराया, हमने लीडर पोस्टग्रेक्यूएल के साथ एक उदाहरण को बंद कर दिया। ऑटोमैटिक फेलओवर ने हमारी अपेक्षा के अनुसार काम किया: पेट्रोनी ने नेता बदल दिया, कंसल-टेम्प्लेट ने PgBouncer के कॉन्फ़िगरेशन को अपडेट किया और पुनः लोड करने के लिए कमांड भेजा। ग्राफाना में हमारे ग्राफ के अनुसार, यह स्पष्ट था कि डेटाबेस से जुड़ने से संबंधित सर्वर से 20-30 सेकंड की देरी और त्रुटियों की एक छोटी राशि है। यह एक सामान्य स्थिति है, ऐसे मूल्य हमारी विफलता के लिए मान्य हैं और निश्चित रूप से सेवा के डाउनटाइम से बेहतर हैं।
उत्पादन के लिए पेट्रोनी का उत्पादन
परिणामस्वरूप, हमें निम्नलिखित योजना मिली:
- PgBouncer सर्वर पर कॉन्सल-टेम्प्लेट तैनात करें और लॉन्च करें;
- 11.2 संस्करण के लिए पोस्टग्रेक्यूएल अपडेट;
- क्लस्टर नाम परिवर्तन;
- एक पेट्रोनी क्लस्टर शुरू करना।
उसी समय, हमारी योजना आपको लगभग किसी भी समय पहली वस्तु बनाने की अनुमति देती है, हम प्रत्येक PgBouncer को काम से निकाल सकते हैं और उस पर एक तैनाती निष्पादित कर सकते हैं और कौंसुल-टेम्पलेट लॉन्च कर सकते हैं। तो हमने किया।
त्वरित रोलिंग के लिए, हमने Ansible का उपयोग किया, क्योंकि हमने पहले से ही एक परीक्षण वातावरण पर सभी प्लेबुक की जांच की, और प्रत्येक स्क्रिप्ट के लिए पूर्ण स्क्रिप्ट का निष्पादन समय 1.5 से 2 मिनट तक था। हम अपनी सेवा को रोके बिना प्रत्येक शार्क के लिए बारी-बारी से सब कुछ रोल कर सकते हैं, लेकिन हमें हर पोस्टग्रेक्यूएल को कुछ मिनटों के लिए बंद करना होगा। इस मामले में, जिन उपयोगकर्ताओं का डेटा इस शार्क पर है, वे इस समय पूरी तरह से काम नहीं कर सकते हैं, और यह हमारे लिए अस्वीकार्य है।
इस स्थिति से बाहर का रास्ता नियोजित रखरखाव था, जो हर 3 महीने में होता है। यह अनुसूचित काम के लिए एक खिड़की है जब हम अपनी सेवा पूरी तरह से बंद कर देते हैं और डेटाबेस इंस्टेंसेस को अपडेट करते हैं। अगली खिड़की आने में एक सप्ताह बाकी था, और हमने बस इंतजार करने और आगे की तैयारी करने का फैसला किया। प्रतीक्षा के दौरान, हमने अतिरिक्त रूप से सुनिश्चित किया: प्रत्येक PostgreSQL शार्क के लिए हमने नवीनतम डेटा को सहेजने में विफलता के मामले में एक अतिरिक्त प्रतिकृति को उठाया, और प्रत्येक शार्क के लिए एक नया उदाहरण जोड़ा, जो कि पेटीएम क्लस्टर में एक नया प्रतिकृति बन जाए ताकि डेटा को हटाने के लिए एक कमांड निष्पादित न हो। । यह सब त्रुटि के जोखिम को कम करने में मदद करता है।

हमने अपनी सेवा को फिर से शुरू किया, सब कुछ जैसा कि होना चाहिए, उपयोगकर्ताओं ने काम करना जारी रखा, लेकिन ग्राफ़ पर हमने कॉन्सुल सर्वर पर असामान्य रूप से उच्च भार देखा।
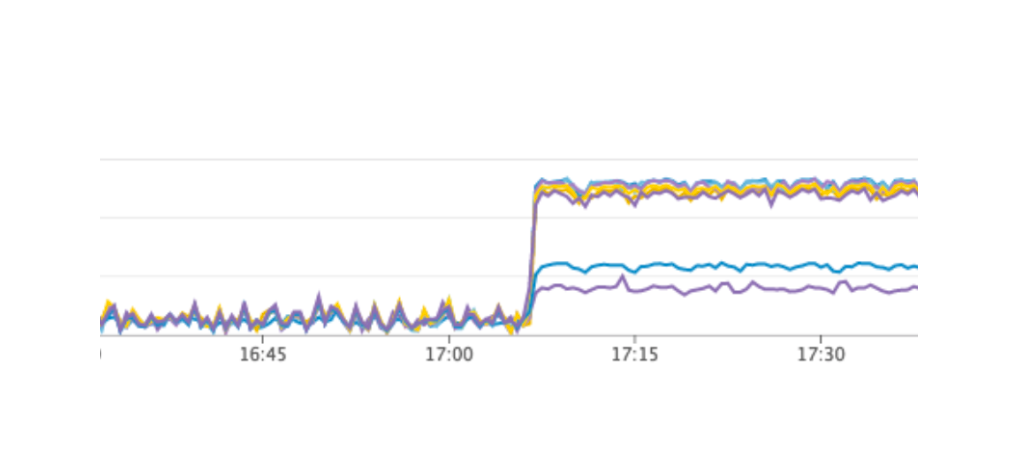
हमने इसे परीक्षण के माहौल पर क्यों नहीं देखा? यह समस्या बहुत अच्छी तरह से बताती है कि इन्फ्रास्ट्रक्चर के सिद्धांत को कोड के रूप में पालन करना और पूरे बुनियादी ढांचे को परिष्कृत करना आवश्यक है, परीक्षण वातावरण से शुरू होता है और उत्पादन के साथ समाप्त होता है। अन्यथा, जिस तरह की समस्या हमें मिली, उसे प्राप्त करना बहुत आसान है। क्या हुआ? कॉन्सुल पहले उत्पादन पर दिखाई दिया, और फिर परीक्षण वातावरण पर, परिणामस्वरूप, परीक्षण वातावरण पर, कॉन्सल का संस्करण उत्पादन की तुलना में अधिक था। बस एक रिलीज में, एक सीपीयू लीक को कॉन्सुल-टेम्प्लेट के साथ काम करते समय हल किया गया था। इसलिए, हमने केवल कॉन्सल को अपडेट किया, इस प्रकार समस्या को हल किया।
पेट्रोनी क्लस्टर को पुनरारंभ करें
हालाँकि, हमें एक नई समस्या मिली जिसके बारे में हमें पता भी नहीं था। कॉन्सल को अपडेट करते समय, हम कॉन्सुल लीव कमांड का उपयोग करके बस कॉन्सल नोड को क्लस्टर से हटा देते हैं → पैट्रोनी किसी अन्य कॉन्सुल सर्वर से जुड़ जाता है → सब कुछ काम करता है। लेकिन जब हम कंसूल क्लस्टर के अंतिम उदाहरण पर पहुँचे और उसे कंसुल अवकाश आदेश भेजा, तो सभी पैट्रोनी क्लस्टर बस फिर से चालू हो गए, और लॉग में हमने निम्न त्रुटि देखी:
ERROR: get_cluster Traceback (most recent call last): ... RetryFailedError: 'Exceeded retry deadline' ERROR: Error communicating with DCS <b>LOG: database system is shut down</b>
पेट्रोनी क्लस्टर अपने क्लस्टर के बारे में जानकारी प्राप्त करने और फिर से शुरू करने में असमर्थ था।
समाधान खोजने के लिए, हमने गितुब पर मुद्दे के माध्यम से पेट्रोनी के लेखकों से संपर्क किया। उन्होंने हमारी कॉन्फ़िगरेशन फ़ाइलों में सुधार का सुझाव दिया:
consul: consul.checks: [] bootstrap: dcs: retry_timeout: 8
हम एक परीक्षण वातावरण पर समस्या को दोहराने में सक्षम थे और वहां इन मापदंडों का परीक्षण किया, लेकिन, दुर्भाग्य से, उन्होंने काम नहीं किया।
समस्या अभी भी अनसुलझी है। हम निम्नलिखित समाधानों को आजमाते हैं:
- Patroni क्लस्टर के प्रत्येक उदाहरण पर कौंसुल-एजेंट का उपयोग करें;
- कोड में समस्या को ठीक करें।
हम उस स्थान को समझते हैं जहां त्रुटि हुई: समस्या संभवतः डिफ़ॉल्ट टाइमआउट का उपयोग कर रही है, जो कॉन्फ़िगरेशन फ़ाइल के माध्यम से ओवरराइड नहीं की जाती है। जब अंतिम कॉन्सुल सर्वर को क्लस्टर से हटा दिया जाता है, तो पूरा कॉन्सल क्लस्टर एक सेकंड से अधिक के लिए जमा हो जाता है, इस वजह से पेट्रोनी क्लस्टर की स्थिति प्राप्त नहीं कर सकता है और पूरी तरह से पूरे क्लस्टर को पुनरारंभ करता है।
सौभाग्य से, हम किसी भी अधिक त्रुटि को पूरा नहीं करते थे।
पटरानी का उपयोग करने के परिणाम
पेट्रोनी के सफल प्रक्षेपण के बाद, हमने प्रत्येक क्लस्टर में एक अतिरिक्त प्रतिकृति जोड़ी। अब प्रत्येक क्लस्टर में एक कोरम की समानता है: एक नेता और दो प्रतिकृतियां - स्विच करते समय विभाजन-मस्तिष्क के मामले के खिलाफ बीमा करने के लिए।
पेट्रोनी तीन महीने से अधिक समय से उत्पादन पर काम कर रही है। इस समय के दौरान, वह पहले से ही हमारी मदद करने में सफल रहा है। हाल ही में, AWS में एक समूह के नेता की मृत्यु हो गई, स्वचालित विफलता ने काम किया, और उपयोगकर्ताओं ने काम करना जारी रखा। पेट्रोनी ने अपना मुख्य कार्य पूरा किया।
पेट्रोनी के उपयोग का एक छोटा सारांश:- एक विन्यास के परिवर्तन की सुविधा। यह एक उदाहरण पर कॉन्फ़िगरेशन को बदलने के लिए पर्याप्त है और इसे पूरे क्लस्टर पर खींच लिया जाएगा। यदि नए कॉन्फ़िगरेशन को लागू करने के लिए रिबूट आवश्यक है, तो पेट्रोनी यह रिपोर्ट करेगा। पेट्रोनी एकल कमांड के साथ पूरे क्लस्टर को पुनः आरंभ कर सकती है, जो बहुत सुविधाजनक भी है।
- स्वचालित फेलओवर काम करता है और पहले से ही हमारी मदद करने में कामयाब रहा है।
- एप्लिकेशन डाउनटाइम के बिना PostgreSQL अपडेट। आपको पहले प्रतिकृतियों को नए संस्करण में अपग्रेड करना होगा, फिर पेट्रोनी क्लस्टर में लीडर को बदलना होगा और पुराने लीडर को अपडेट करना होगा। इस मामले में, स्वचालित विफलता का आवश्यक परीक्षण होता है।