लेख के बारे में
यह पोस्ट प्रोग्रामर के लिए डिज़ाइन किया गया एक छोटा नोट है जो GPU के बारे में अधिक जानकारी प्राप्त करना चाहता है। आप इसे इस विषय का परिचय मान सकते हैं। मैं [
1 ], [
2 ] और [
8 ] के साथ शुरू करने की सलाह देता हूं ताकि यह पता चल सके कि सामान्य रूप से GPU निष्पादन मॉडल कैसा दिखता है, क्योंकि हम केवल एक अलग विवरण पर विचार करेंगे। उत्सुक पाठकों के लिए, पोस्ट के अंत में सभी लिंक हैं। यदि आपको त्रुटियाँ मिलती हैं, तो मुझसे संपर्क करें।
सामग्री
- लेख के बारे में
- सामग्री
- शब्दकोश
- GPU कोर CPU कोर से कैसे अलग है?
- संगति / विसंगति क्या है?
- निष्पादन मुखौटा प्रसंस्करण उदाहरण
- काल्पनिक आईएसए
- AMD GCN ISA
- AVX512
- विसंगति से कैसे निपटें?
- संदर्भ
शब्दकोश
- GPU - ग्राफिक्स प्रोसेसिंग यूनिट, GPU
- फ्लिन का वर्गीकरण
- SIMD - एकल निर्देश एकाधिक डेटा, एकल निर्देश धारा, एकाधिक डेटा स्ट्रीम
- SIMT - एकल निर्देश कई सूत्र, एकल निर्देश धारा, कई सूत्र
- वेव (सिम) - एक स्ट्रीम जिसे SIMD मोड में निष्पादित किया जाता है
- लाइन (लेन) - SIMD मॉडल में एक अलग डेटा स्ट्रीम
- श्रीमती - एक साथ बहु-थ्रेडिंग, एक साथ मल्टीथ्रेडिंग (इंटेल हाइपर-थ्रेडिंग) [ 2 ]
- कई सूत्र कोर कंप्यूटिंग संसाधनों को साझा करते हैं
- IMT - बहुभाषी बहु-सूत्रण, वैकल्पिक रूप से बहु-सूत्रण [ 2 ]
- एकाधिक थ्रेड कर्नेल के कुल कंप्यूटिंग संसाधनों को साझा करते हैं, लेकिन केवल एक
- बीबी - मूल ब्लॉक, एक मूल ब्लॉक - अंत में एक एकल कूद के साथ निर्देशों का एक रैखिक अनुक्रम
- ILP - निर्देश स्तर समानता, अनुदेश स्तर पर समानता [ 3 ]
- आईएसए - इंस्ट्रक्शन सेट आर्किटेक्चर, इंस्ट्रक्शन सेट आर्किटेक्चर
अपनी पोस्ट में मैं इस आविष्कृत वर्गीकरण का पालन करूंगा। यह मोटे तौर पर एक आधुनिक GPU का आयोजन कैसे करता है जैसा दिखता है।
:
GPU -+
|- 0 -+
| |- 0 +
| | |- 0
| | |- 1
| | |- ...
| | +- Q-1
| |
| |- ...
| +- M-1
|
|- ...
+- N-1
* - SIMD
:
+
|- 0
|- ...
+- N-1
अन्य नाम:
- कोर को CU, SM, EU कहा जा सकता है
- एक लहर को एक वेवफ्रंट, एक हार्डवेयर थ्रेड (HW धागा), ताना, एक संदर्भ कहा जा सकता है
- एक लाइन को प्रोग्राम थ्रेड (SW थ्रेड) कहा जा सकता है
GPU कोर CPU कोर से कैसे अलग है?
GPU कोर की कोई भी वर्तमान पीढ़ी केंद्रीय प्रोसेसर की तुलना में कम शक्तिशाली है: सरल ILP / बहु-मुद्दा [
6 ] और प्रीफ़ैच [
5 ], कोई पूर्वानुमान या संक्रमण की भविष्यवाणी / रिटर्न नहीं। यह सब, छोटे कैश के साथ, चिप पर काफी बड़े क्षेत्र को मुक्त करता है, जो कई कोर से भरा होता है। मेमोरी लोडिंग / स्टोरेज मैकेनिज्म पारंपरिक सीपीयू की तुलना में चैनल की चौड़ाई को परिमाण के क्रम से अधिक (यह एकीकृत / मोबाइल जीपीयू पर लागू नहीं होता है) के साथ सामना करने में सक्षम है, लेकिन आपको इसके लिए उच्च अक्षांशों के साथ भुगतान करना होगा। विलंबता को छिपाने के लिए, GPU SMT [
2 ] का उपयोग करता है - जबकि एक लहर बेकार है, अन्य कर्नेल के मुक्त कंप्यूटिंग संसाधनों का उपयोग करते हैं। आमतौर पर एक कोर द्वारा संसाधित तरंगों की संख्या प्रयुक्त रजिस्टरों पर निर्भर करती है और एक निश्चित रजिस्टर फ़ाइल [
8 ] को आवंटित करके गतिशील रूप से निर्धारित की जाती है। निर्देशों के निष्पादन के लिए योजना हाइब्रिड है - डायनेमिक-स्टैटिक [
6 ] [
11 4.4]। SIMD मोड में निष्पादित एसएमटी कर्नेल उच्च FLOPS मान (फ़्लोटिंग-पॉइंट ऑपरेशंस प्रति सेकंड, फ़्लॉप्स, फ़्लोटिंग पॉइंट ऑपरेशंस की संख्या प्रति सेकंड) प्राप्त करते हैं।
 किंवदंती चार्ट। काला - निष्क्रिय, सफेद - सक्रिय, ग्रे - ऑफ, नीला - निष्क्रिय, लाल - लंबितचित्रा 1. 4: 2 निष्पादन इतिहास
किंवदंती चार्ट। काला - निष्क्रिय, सफेद - सक्रिय, ग्रे - ऑफ, नीला - निष्क्रिय, लाल - लंबितचित्रा 1. 4: 2 निष्पादन इतिहासछवि निष्पादन मुखौटा का इतिहास दिखाती है, जहां एक्स-अक्ष बाएं से दाएं जाने का समय दिखाता है, और वाई-अक्ष लाइन के पहचानकर्ता को ऊपर से नीचे तक दिखाता है। यदि आप अभी भी यह नहीं समझते हैं, तो निम्नलिखित अनुभागों को पढ़ने के बाद ड्राइंग पर वापस लौटें।
यह एक उदाहरण है कि GPU कोर निष्पादन इतिहास काल्पनिक कॉन्फ़िगरेशन में कैसा दिख सकता है: चार तरंगें एक नमूना और दो ALU साझा करती हैं। प्रत्येक चक्र में तरंग योजनाकार दो तरंगों से दो निर्देश जारी करता है। जब कोई तरंग मेमोरी या लंबे ALU ऑपरेशन तक पहुंच बनाते समय बेकार हो जाती है, तो शेड्यूलर एक और जोड़ी तरंगों में बदल जाता है, जिसके कारण ALU पर लगभग 100% का लगातार कब्जा होता है।
चित्रा 2. 4: 1 निष्पादन इतिहासएक ही लोड के साथ एक उदाहरण है, लेकिन इस बार अनुदेश के प्रत्येक चक्र में केवल एक तरंग मुद्दे हैं। ध्यान दें कि दूसरा ALU भूख से मर रहा है।
चित्रा 3. निष्पादन इतिहास 4: 4इस बार, प्रत्येक चक्र में चार निर्देश जारी किए गए हैं। ध्यान दें कि ALU में बहुत अधिक अनुरोध हैं, इसलिए दो तरंगें लगभग हमेशा इंतजार कर रही हैं (वास्तव में, यह योजना एल्गोरिथ्म की गलती है)।
अद्यतन निर्देशों के निष्पादन की योजना बनाने की कठिनाइयों के बारे में अधिक जानकारी के लिए, [
१२ ] देखें।
वास्तविक दुनिया में, GPU में अलग-अलग कोर कॉन्फ़िगरेशन हैं: कुछ में 40 तरंगें प्रति कोर और 4 ALU हो सकती हैं, अन्य में 7 निश्चित तरंगें और 2 ALU हैं। यह सब कई कारकों पर निर्भर करता है और वास्तुकला सिमुलेशन की श्रमसाध्य प्रक्रिया के लिए धन्यवाद निर्धारित किया जाता है।
इसके अलावा, वास्तविक SIMD ALU में वे तरंगों की तुलना में एक संकीर्ण चौड़ाई हो सकती है, और फिर इसे जारी किए गए निर्देश को संसाधित करने के लिए कई चक्र लगते हैं; कारक को "चाइम" [
3 ] लंबाई कहा जाता है।
संगति / विसंगति क्या है?
आइए निम्नलिखित कोड स्निपेट पर एक नज़र डालें:
उदाहरण 1
uint lane_id = get_lane_id(); if (lane_id & 1) {
यहां हम निर्देशों की एक धारा देखते हैं जिसमें निष्पादन पथ लाइन के निष्पादन के पहचानकर्ता पर निर्भर करता है। जाहिर है, अलग-अलग रेखाओं के अलग-अलग अर्थ होते हैं। क्या होने वाला है? इस समस्या को हल करने के लिए अलग-अलग दृष्टिकोण हैं [
4 ], लेकिन अंत में वे सभी एक ही चीज़ के बारे में करते हैं। ऐसा ही एक दृष्टिकोण निष्पादन मुखौटा है, जिसे मैं कवर करूंगा। वोल्टा से पहले और एएमडी जीसीएन जीपीयू में एनवीडिया जीपीयू में इस दृष्टिकोण का उपयोग किया गया था। निष्पादन मुखौटा का मुख्य बिंदु यह है कि हम लहर में प्रत्येक पंक्ति के लिए थोड़ा स्टोर करते हैं। यदि संबंधित लाइन निष्पादन बिट 0 है, तो जारी किए गए अगले निर्देश के लिए कोई रजिस्टर प्रभावित नहीं होगा। वास्तव में, लाइन को पूरे निष्पादित अनुदेश के प्रभाव को महसूस नहीं करना चाहिए, क्योंकि इसका निष्पादन बिट 0. है। यह निम्नानुसार काम करता है: लहर गहराई खोज क्रम में नियंत्रण प्रवाह ग्राफ के साथ यात्रा करती है, बिट्स सेट होने तक चयनित संक्रमणों के इतिहास को बचाती है। मुझे लगता है कि इसे एक उदाहरण के साथ दिखाना बेहतर है।
मान लीजिए कि हमारे पास 8. की चौड़ाई के साथ लहरें हैं। यहाँ कोड टुकड़े के लिए निष्पादन मुखौटा कैसा दिखता है:
उदाहरण 1. निष्पादन मुखौटा का इतिहास
अब अधिक जटिल उदाहरणों पर विचार करें:
उदाहरण 2
uint lane_id = get_lane_id(); for (uint i = lane_id; i < 16; i++) {
उदाहरण 3
uint lane_id = get_lane_id(); if (lane_id < 16) {
आप देख सकते हैं कि इतिहास आवश्यक है। निष्पादन मुखौटा दृष्टिकोण का उपयोग करते समय, उपकरण आमतौर पर कुछ प्रकार के स्टैक का उपयोग करता है। भोली दृष्टिकोण ट्यूपल्स (निष्पादित_मास्क, पता) के ढेर को संग्रहीत करने और अभिसरण निर्देश जोड़ने के लिए है जो स्टैक से मुखौटा निकालते हैं और लहर के लिए निर्देश सूचक को बदलते हैं। इस स्थिति में, लहर में प्रत्येक पंक्ति के लिए संपूर्ण CFG को बायपास करने के लिए पर्याप्त जानकारी होगी।
प्रदर्शन के संदर्भ में, यह सभी डेटा संग्रहण के कारण नियंत्रण प्रवाह निर्देश को संसाधित करने के लिए केवल कुछ लूप लेता है। और यह मत भूलो कि स्टैक की एक सीमित गहराई है।
अद्यतन। @ क्रैगकोल्ब के लिए धन्यवाद
, मैंने एक लेख [
13 ] पढ़ा, जिसमें कहा गया है कि एएमडी जीसीएन फोर्क / निर्देशों में शामिल होने से पहले कम थ्रेड्स [
11 4.6] से एक पथ का चयन करें, जो गारंटी देता है कि मास्क स्टैक गहराई लॉग 2 के बराबर है।
अद्यतन। जाहिर है, यह हमेशा एक shader / संरचना CFGs में एक shader में सब कुछ एम्बेड करने के लिए लगभग संभव है, और इसलिए रजिस्टरों में निष्पादन मास्क के पूरे इतिहास को संग्रहीत करता है और सीएफजी [
15 ] को दरकिनार / परिवर्तित करने की योजना बनाता है। AMDGPU के लिए LLVM बैकएंड को देखने के बाद, मुझे संकलक द्वारा जारी किए गए स्टैक हैंडलिंग का कोई सबूत नहीं मिला।
रनटाइम मास्क हार्डवेयर सपोर्ट
अब विकिपीडिया के इन नियंत्रण प्रवाह ग्राफों पर एक नज़र डालें:
चित्रा 4. नियंत्रण प्रवाह रेखांकन के कुछ प्रकारसभी मामलों को संभालने के लिए हमें मुखौटा नियंत्रण निर्देशों का न्यूनतम सेट क्या है? यहाँ यह मेरे कृत्रिम ISA में अंतर्निहित समानांतरकरण, स्पष्ट मुखौटा नियंत्रण और डेटा संघर्षों के पूरी तरह से गतिशील तुल्यकालन के साथ कैसा दिखता है:
push_mask BRANCH_END ; Push current mask and reconvergence pointer pop_mask ; Pop mask and jump to reconvergence instruction mask_nz r0.x ; Set execution bit, pop mask if all bits are zero ; Branch instruction is more complicated ; Push current mask for reconvergence ; Push mask for (r0.x == 0) for else block, if any lane takes the path ; Set mask with (r0.x != 0), fallback to else in case no bit is 1 br_push r0.x, ELSE, CONVERGE
आइए केस d पर एक नजर डालते हैं)।
A: br_push r0.x, C, D B: C: mask_nz r0.y jmp B D: ret
मैं नियंत्रण प्रवाह या आईएसए को डिजाइन करने के विश्लेषण में विशेषज्ञ नहीं हूं, इसलिए मुझे यकीन है कि ऐसा मामला है कि मेरा कृत्रिम आईएसए सामना नहीं कर पाएगा, लेकिन यह महत्वपूर्ण नहीं है, क्योंकि एक संरचित सीएफजी सभी के लिए पर्याप्त होना चाहिए।
अद्यतन। नियंत्रण प्रवाह निर्देशों के लिए GCN समर्थन के बारे में और अधिक पढ़ें: [
11 ] ch.4, और यहाँ LLVM कार्यान्वयन के बारे में: [
१५ ]।
निष्कर्ष:
- विचलन - एक ही तरंग की विभिन्न रेखाओं द्वारा चुने गए रास्तों में परिणामी अंतर
- संगति - कोई विसंगति नहीं।
निष्पादन मुखौटा प्रसंस्करण उदाहरण
काल्पनिक आईएसए
मैंने अपने कृत्रिम ISA में पिछले कोड स्निपेट संकलित किए और उन्हें SIMD32 में एक सिम्युलेटर पर चलाया। देखें कि यह निष्पादन मुखौटा कैसे संभालता है।
अद्यतन। ध्यान दें कि एक कृत्रिम सिम्युलेटर हमेशा सही रास्ता चुनता है, और यह सबसे अच्छा तरीका नहीं है।
उदाहरण 1
 चित्र 5. उदाहरण 1 का इतिहास
चित्र 5. उदाहरण 1 का इतिहासक्या आपने एक काले क्षेत्र पर ध्यान दिया है? यह समय बर्बाद हुआ। कुछ पंक्तियाँ पुनरावृति को पूरा करने के लिए दूसरों की प्रतीक्षा करती हैं।
उदाहरण 2
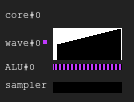 चित्र 6. उदाहरण 2 का इतिहास
चित्र 6. उदाहरण 2 का इतिहासउदाहरण 3
mov r0.x, lane_id lt.u32 r0.y, r0.x, u(16)
 चित्र 7. उदाहरण 3 का इतिहास
चित्र 7. उदाहरण 3 का इतिहासAMD GCN ISA
अद्यतन। GCN भी स्पष्ट मुखौटा प्रसंस्करण का उपयोग करता है, इसके बारे में और अधिक जानकारी यहाँ मिल सकती है: [
11 4.x]। मैंने उनके ISA से कुछ उदाहरणों को दिखाने का फैसला किया, जो कि
shader- खेल के मैदान की बदौलत ऐसा करना आसान है। शायद किसी दिन मैं एक सिम्युलेटर पाऊंगा और आरेख प्राप्त करने का प्रबंधन करूंगा।
ध्यान रखें कि कंपाइलर स्मार्ट है, इसलिए आप अन्य परिणाम प्राप्त कर सकते हैं। मैंने कंपाइलर को ट्रिक करने की कोशिश की ताकि यह मेरी शाखाओं को पॉइंटर लूप लगाकर और फिर कोडांतरक कोड को साफ न कर दे; मैं GCN विशेषज्ञ नहीं हूं, इसलिए कुछ महत्वपूर्ण
nop को छोड़ दिया जा सकता है।
यह भी ध्यान दें कि S_CBRANCH_I / G_FORK और S_CBRANCH_JOIN निर्देशों का उपयोग इन टुकड़ों में नहीं किया जाता है क्योंकि वे सरल हैं और संकलक उनका समर्थन नहीं करता है। इसलिए, दुर्भाग्य से, मास्क के ढेर पर विचार करना संभव नहीं था। यदि आप जानते हैं कि संकलक समस्या स्टैक प्रसंस्करण कैसे बनाते हैं, तो कृपया मुझे बताएं।
अद्यतन। इस
@ बाहर की जाँच करें
@ SiNGUL4RiTY एलएमवी द्वारा उपयोग किए जाने वाले एलएलवीएम बैकएंड में एक
वेक्टरकृत नियंत्रण प्रवाह को लागू करने के बारे में
बात करते हैं।
उदाहरण 1
उदाहरण 2
उदाहरण 3
AVX512
अद्यतन। @tom_forsyth ने मुझे बताया कि AVX512 एक्सटेंशन में स्पष्ट मुखौटा प्रसंस्करण भी है, इसलिए यहां कुछ उदाहरण हैं। इसके बारे में अधिक जानकारी [
14 ], 15.x और 15.6.1 में मिल सकती है। यह बिल्कुल GPU नहीं है, लेकिन इसमें अभी भी 32 बिट्स के साथ एक वास्तविक SIMD16 है। ISPC (कोडर = avx512knl-i32x16)
गॉडबॉल का उपयोग करके कोड स्निपेट बनाए गए और भारी पुन: डिज़ाइन किए गए हैं, इसलिए वे 100% सत्य नहीं हो सकते हैं।
उदाहरण 1
उदाहरण 2
उदाहरण 3
विसंगति से कैसे निपटें?
मैंने एक सरल लेकिन पूर्ण चित्रण बनाने की कोशिश की कि डायवर्जेंस लाइनों के संयोजन से अक्षमता कैसे उत्पन्न होती है।
कोड के एक साधारण टुकड़े की कल्पना करें:
uint thread_id = get_thread_id()
चलो 256 धागे बनाते हैं और उनके निष्पादन का समय मापते हैं:
चित्रा 8. विचलन सूत्र की अवधिX अक्ष प्रोग्राम स्ट्रीम की पहचानकर्ता है, y अक्ष घड़ी चक्र है; अलग-अलग कॉलम बताते हैं कि एकल-थ्रेडेड निष्पादन की तुलना में अलग-अलग तरंग दैर्ध्य के साथ बहने पर कितना समय बर्बाद होता है।
वेव रन टाइम इसमें निहित लाइनों के बीच अधिकतम रन टाइम के बराबर है। आप देख सकते हैं कि प्रदर्शन SIMD8 के साथ नाटकीय रूप से पहले से ही गिर गया है, और आगे विस्तार बस इसे थोड़ा बदतर बना देता है।
चित्रा 9. सुसंगत धागे का रनटाइमइस आंकड़े में समान कॉलम दिखाए गए हैं, लेकिन इस बार पुनरावृत्तियों की संख्या को स्ट्रीम आइडेंटिफ़ायर द्वारा सॉर्ट किया गया है, अर्थात्, समान संख्या में पुनरावृत्तियों वाली धाराएँ एक तरंग में प्रेषित होती हैं।
इस उदाहरण के लिए, निष्पादन संभावित रूप से लगभग आधा है।
बेशक, उदाहरण बहुत सरल है, लेकिन मुझे आशा है कि आप इस बिंदु को समझेंगे: निष्पादन में विसंगति डेटा की विसंगति से उपजी है, इसलिए सीएफजी सरल और डेटा संगत होना चाहिए।
उदाहरण के लिए, यदि आप एक किरण अनुरेखक लिख रहे हैं, तो आप किरणों को एक ही दिशा और स्थिति के साथ समूहित करने से लाभान्वित हो सकते हैं, क्योंकि वे बीवीएच में एक ही नोड के माध्यम से जाने की सबसे अधिक संभावना है। अधिक जानकारी के लिए [
१० ] और अन्य संबंधित लेख देखें।
यह भी उल्लेखनीय है कि हार्डवेयर स्तर पर विसंगतियों से निपटने की तकनीकें हैं, उदाहरण के लिए, डायनामिक वॉर फॉर्मेशन [
7 ] और छोटी शाखाओं के लिए निष्पादन की भविष्यवाणी की।
संदर्भ
[१]
ग्राफिक्स पाइपलाइन के माध्यम से एक यात्रा[२]
कवन फतहलियन: PARALLEL COMPUTING[३]
कंप्यूटर वास्तुकला एक मात्रात्मक दृष्टिकोण[४]
कम लागत पर ढेर-कम सिमटी पुनर्गठन[५]
माइक्रोबेन्चमार्किंग के माध्यम से GPU मेमोरी पदानुक्रम को भंग करना[६]
माइक्रोवेंचमार्किंग के माध्यम से NVIDIA वोल्टा जीपीयू आर्किटेक्चर को अलग करना[[]
डायनेमिक वॉर फॉर्मेशन एंड शेड्यूलिंग फॉर एफिशिएंट जीपीयू कंट्रोल फ्लो[
Io ]
मौरिजियो सेराटो: जीपीयू आर्किटेक्चर[९]
खिलौना GPU सिम्युलेटर[१०]
जीपीयू प्रोग्राम्स में ब्रांच डाइवर्जेंस को कम करना[११]
"वेगा" निर्देश सेट आर्किटेक्चर[१२]
जोशुआ बरिसाक: जीसीएन के लिए शेयर्ड एक्जिक्यूशन[१३]
स्पर्शरेखा वेक्टर: विचलन पर एक पाचन[१४]
इंटेल ६४ और आईए -३२ आर्किटेक्चरसॉफ्टवेयर डेवलपर मैनुअल[१५]
SIMD अनुप्रयोगों के लिए डायवर्जेंट कंट्रोल-फ्लो का सदिशीकरण