सलाम, ख़बरों को! निम्नलिखित लेख का अनुवाद विशेष रूप से
कुबेरनेट्स-आधारित इन्फ्रास्ट्रक्चर प्लेटफॉर्म पाठ्यक्रम के छात्रों के लिए तैयार किया गया था, जो कल कक्षाएं शुरू करेंगे। चलिए शुरू करते हैं।

कुबेरनेट्स में ऑटोस्कोलिंग
ऑटो-स्केलिंग आपको संसाधनों के उपयोग के आधार पर स्वचालित रूप से वर्कलोड को बढ़ाने और घटाने की अनुमति देता है।
कुबेरनेट्स ऑटोस्कोलिंग के दो आयाम हैं:
- क्लस्टर ऑटोस्कोलर, जो नोड्यूल को स्केल करने के लिए जिम्मेदार है;
- क्षैतिज पॉड ऑटोकैसलर (एचपीए), जो एक तैनाती या प्रतिकृति सेट में स्वचालित रूप से चूल्हा की संख्या को मापता है।
क्लस्टर ऑटो-स्केलिंग का उपयोग क्षैतिज चूल्हा ऑटो-स्केलिंग के साथ गतिशील रूप से कंप्यूटिंग संसाधनों को नियंत्रित करने के लिए किया जा सकता है और सेवा स्तर समझौतों (SLAs) के अनुपालन के लिए आवश्यक सिस्टम संगामिति की डिग्री।
क्लस्टर ऑटोस्कोलिंग क्लस्टर की मेजबानी करने वाले क्लाउड इंफ्रास्ट्रक्चर प्रदाता की क्षमताओं पर अत्यधिक निर्भर है, और एचपीए आईएएएस / पीएएएस प्रदाता के स्वतंत्र रूप से काम कर सकता है।
एचपीए विकास
कुबेरनेट्स v1.1 की शुरूआत के बाद से क्षैतिज चूल्हा ऑटो-स्केलिंग में बड़े बदलाव आए हैं। एचपीए के पहले संस्करण में मापा सीपीयू खपत के आधार पर, और बाद में मेमोरी के उपयोग के आधार पर चूल्हा बढ़ाया गया। कुबेरनेट्स 1.6 ने कस्टम मेट्रिक्स नामक एक नया एपीआई पेश किया, जो कस्टम मेट्रिक्स को एचपीए एक्सेस प्रदान करता है। कुबेरनेट्स 1.7 ने एक एकत्रीकरण स्तर जोड़ा, जो तृतीय-पक्ष अनुप्रयोगों को एपीआई ऐड-ऑन के रूप में पंजीकृत करके कुबेरनेट एपीआई का विस्तार करने की अनुमति देता है।
कस्टम मेट्रिक्स एपीआई और एकत्रीकरण स्तर के लिए धन्यवाद, प्रोमेथियस जैसे मॉनिटरिंग सिस्टम एचपीए नियंत्रक को एप्लिकेशन विशिष्ट मैट्रिक्स प्रदान कर सकते हैं।
क्षैतिज चूल्हा ऑटो-स्केलिंग एक नियंत्रण लूप के रूप में कार्यान्वित किया जाता है जो समय-समय पर मुख्य मैट्रिक्स, जैसे सीपीयू और मेमोरी उपयोग, और विशिष्ट एप्लिकेशन मैट्रिक्स के लिए कस्टम मेट्रिक्स एपीआई (कस्टम मेट्रिक्स एपीआई) के लिए संसाधन मेट्रिक्स एपीआई (संसाधन मेट्रिक्स एपीआई) पर सवाल उठाता है।
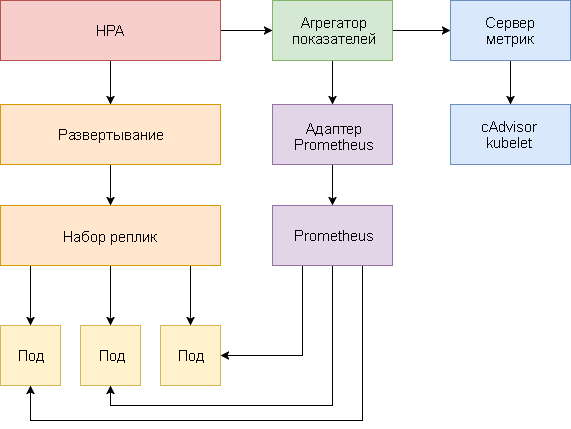
नीचे कुबेरनेट्स 1.9 और बाद के एचपीए वी 2 को कॉन्फ़िगर करने के लिए एक कदम-दर-चरण गाइड है।
- मेट्रिक्स सर्वर ऐड-इन स्थापित करें, जो कुंजी मैट्रिक्स प्रदान करता है।
- सीपीयू और मेमोरी उपयोग के आधार पर चूल्हा ऑटो-स्केलिंग कैसे काम करता है, यह देखने के लिए एक डेमो एप्लिकेशन लॉन्च करें।
- प्रोमेथियस और कस्टम एपीआई सर्वर को तैनात करें। एकत्रीकरण स्तर पर एक कस्टम एपीआई सर्वर पंजीकृत करें।
- डेमो एप्लिकेशन द्वारा प्रदान किए गए कस्टम मीट्रिक का उपयोग करके एचपीए को कॉन्फ़िगर करें।
शुरू करने से पहले, आपको गो संस्करण 1.8 (या बाद में) स्थापित करना होगा और
GOPATH में
k8s-prom- GOPATH रिपॉजिटरी को
GOPATH :
cd $GOPATH git clone https:
1. मेट्रिक्स सर्वर की स्थापना
कुबेरनेट
मेट्रिक सर्वर इंट्रा-क्लस्टर संसाधन उपयोग डेटा एग्रीगेटर है जो
हैपस्टर की जगह
लेता है । मैट्रिक्स सर्वर
kubernetes.summary_api से नोड्स और चूल्हों के लिए सीपीयू और मेमोरी उपयोग की जानकारी एकत्र करता है। सारांश एपीआई एक सर्वर के लिए Kubelet / cAdvisor डेटा मैट्रिक्स को प्रेषित करने के लिए एक स्मृति-कुशल एपीआई है।
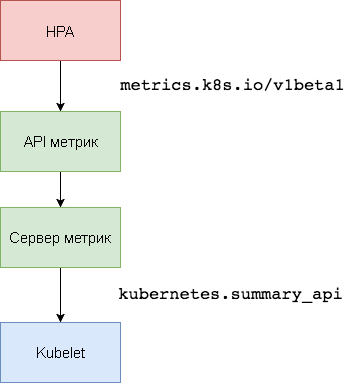
एचपीए के पहले संस्करण में, सीपीयू और मेमोरी प्राप्त करने के लिए एक हेपरस्टर एग्रीगेटर की आवश्यकता थी। HPA v2 और Kubernetes 1.8 में,
horizontal-pod-autoscaler-use-rest-clients ऑटोसालर-यूज़
horizontal-pod-autoscaler-use-rest-clients सक्षम के साथ केवल एक मीट्रिक सर्वर आवश्यक है। यह विकल्प Kubernetes 1.9 में डिफ़ॉल्ट रूप से सक्षम है। GKE 1.9 एक पूर्व-स्थापित मैट्रिक्स सर्वर के साथ आता है।
kube-system नेमस्पेस में मेट्रिक्स सर्वर का विस्तार करें:
kubectl create -f ./metrics-server
1 मिनट के बाद,
metric-server सीपीयू और मेमोरी उपयोग पर नोड्स और पॉड्स द्वारा डेटा संचारित करना शुरू कर देगा।
नोड मैट्रिक्स देखें:
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/nodes" | jq .
हृदय गति संकेतक देखें:
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/pods" | jq .
2. सीपीयू और मेमोरी उपयोग के आधार पर ऑटो-स्केलिंग
चूल्हा क्षैतिज ऑटो-स्केलिंग (एचपीए) के परीक्षण के लिए, आप एक छोटे गोलंग-आधारित वेब एप्लिकेशन का उपयोग कर सकते हैं।
default नाम स्थान में
podinfo का विस्तार करें:
kubectl create -f ./podinfo/podinfo-svc.yaml,./podinfo/podinfo-dep.yaml
http://<K8S_PUBLIC_IP>:31198 पर NodePort सेवा का उपयोग करके
podinfo संपर्क करें।
एचपीए निर्दिष्ट करें जो कम से कम दो प्रतिकृतियां और दस प्रतिकृतियों के पैमाने पर काम करेगा यदि औसत सीपीयू का उपयोग 80% से अधिक हो या यदि मेमोरी की खपत 200 MiB से ऊपर हो:
apiVersion: autoscaling/v2beta1 kind: HorizontalPodAutoscaler metadata: name: podinfo spec: scaleTargetRef: apiVersion: extensions/v1beta1 kind: Deployment name: podinfo minReplicas: 2 maxReplicas: 10 metrics: - type: Resource resource: name: cpu targetAverageUtilization: 80 - type: Resource resource: name: memory targetAverageValue: 200Mi
HPA बनाएं:
kubectl create -f ./podinfo/podinfo-hpa.yaml
कुछ सेकंड के बाद, एचपीए नियंत्रक मीट्रिक सर्वर से संपर्क करेगा और सीपीयू और मेमोरी उपयोग के बारे में जानकारी प्राप्त करेगा:
kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE podinfo Deployment/podinfo 2826240 / 200Mi, 15% / 80% 2 10 2 5m
CPU उपयोग बढ़ाने के लिए, rakyll / hey के साथ एक लोड परीक्षण करें:
#install hey go get -u github.com/rakyll/hey #do 10K requests hey -n 10000 -q 10 -c 5 http:
आप HPA घटनाओं की निगरानी इस प्रकार कर सकते हैं:
$ kubectl describe hpa Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulRescale 7m horizontal-pod-autoscaler New size: 4; reason: cpu resource utilization (percentage of request) above target Normal SuccessfulRescale 3m horizontal-pod-autoscaler New size: 8; reason: cpu resource utilization (percentage of request) above target
पॉडिनफो को अस्थायी रूप से निकालें (आपको इस गाइड के अगले चरणों में से एक में इसे फिर से भरना होगा)।
kubectl delete -f ./podinfo/podinfo-hpa.yaml,./podinfo/podinfo-dep.yaml,./podinfo/podinfo-svc.yaml
3. कस्टम मेट्रिक्स सर्वर सेटअप
कस्टम मेट्रिक्स पर आधारित स्केलिंग के लिए, दो घटकों की आवश्यकता होती है। पहला -
प्रोमेथियस टाइम सीरीज़ डेटाबेस - एप्लिकेशन मेट्रिक्स एकत्र करता है और उन्हें बचाता है। दूसरा घटक,
k8s-prometheus- एडेप्टर , कस्टम मेट्रिक्स एपीआई कुबेरनेट्स को बिल्डर द्वारा प्रदान किए गए मीट्रिक के साथ पूरक करता है।
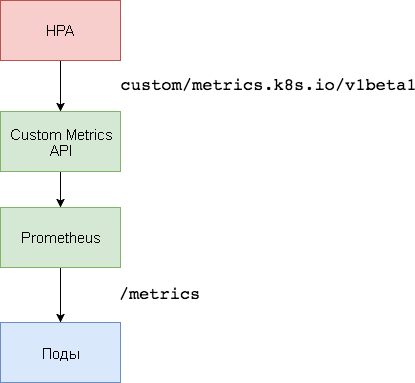
एक समर्पित नाम स्थान का उपयोग प्रोमेथियस और एडेप्टर को तैनात करने के लिए किया जाता है।
एक
monitoring नाम बनाएँ:
kubectl create -f ./namespaces.yaml
monitoring नेमस्पेस में प्रोमेथियस v2 का विस्तार करें:
kubectl create -f ./prometheus
प्रोमेथियस एडेप्टर के लिए आवश्यक टीएलएस प्रमाणपत्र उत्पन्न करें:
make certs
कस्टम मेट्रिक्स एपीआई के लिए प्रोमेथियस एडेप्टर तैनात करें:
kubectl create -f ./custom-metrics-api
प्रोमेथियस द्वारा प्रदान की गई विशेष मीट्रिक की एक सूची प्राप्त करें:
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1" | jq .
फिर
monitoring नेमस्पेस में सभी पॉड्स के लिए फाइल सिस्टम यूसेज डेटा निकालें:
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/monitoring/pods/*/fs_usage_bytes" | jq .
4. कस्टम मेट्रिक्स पर आधारित ऑटो-स्केलिंग
NodePort
podinfo सेवा बनाएं और
default नाम स्थान पर तैनात करें:
kubectl create -f ./podinfo/podinfo-svc.yaml,./podinfo/podinfo-dep.yaml
podinfo एप्लिकेशन विशेष मीट्रिक
http_requests_total पास करेगा। प्रोमेथियस एडेप्टर
_total प्रत्यय को हटा देगा और इस मीट्रिक को एक काउंटर के रूप में चिह्नित करेगा।
कस्टम मेट्रिक्स API से प्रति सेकंड कुल प्रश्नों की संख्या प्राप्त करें:
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/*/http_requests" | jq . { "kind": "MetricValueList", "apiVersion": "custom.metrics.k8s.io/v1beta1", "metadata": { "selfLink": "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/%2A/http_requests" }, "items": [ { "describedObject": { "kind": "Pod", "namespace": "default", "name": "podinfo-6b86c8ccc9-kv5g9", "apiVersion": "/__internal" }, "metricName": "http_requests", "timestamp": "2018-01-10T16:49:07Z", "value": "901m" }, { "describedObject": { "kind": "Pod", "namespace": "default", "name": "podinfo-6b86c8ccc9-nm7bl", "apiVersion": "/__internal" }, "metricName": "http_requests", "timestamp": "2018-01-10T16:49:07Z", "value": "898m" } ] }
अक्षर
m मतलब मिल
milli-units , इसलिए, उदाहरण के लिए,
901m 901 मिलीसेकंड है।
एक HPA बनाएं जो पॉडिनफो की तैनाती का विस्तार करेगा यदि अनुरोधों की संख्या 10 अनुरोध प्रति सेकंड से अधिक हो:
apiVersion: autoscaling/v2beta1 kind: HorizontalPodAutoscaler metadata: name: podinfo spec: scaleTargetRef: apiVersion: extensions/v1beta1 kind: Deployment name: podinfo minReplicas: 2 maxReplicas: 10 metrics: - type: Pods pods: metricName: http_requests targetAverageValue: 10
default नाम स्थान में HPA
podinfo विस्तार करें:
kubectl create -f ./podinfo/podinfo-hpa-custom.yaml
कुछ सेकंड के बाद, एचपीए को मेट्रिक्स एपीआई से
http_requests मान मिलेगा:
kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE podinfo Deployment/podinfo 899m / 10 2 10 2 1m
प्रति सेकंड 25 अनुरोधों के साथ पॉडिनफो सेवा के लिए लोड लागू करें:
#install hey go get -u github.com/rakyll/hey #do 10K requests rate limited at 25 QPS hey -n 10000 -q 5 -c 5 http:
कुछ मिनटों के बाद, HPA परिनियोजन को मापना शुरू करेगा:
kubectl describe hpa Name: podinfo Namespace: default Reference: Deployment/podinfo Metrics: ( current / target ) "http_requests" on pods: 9059m / 10< Min replicas: 2 Max replicas: 10 Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulRescale 2m horizontal-pod-autoscaler New size: 3; reason: pods metric http_requests above target
प्रति सेकंड अनुरोधों की वर्तमान संख्या के साथ, तैनाती कभी भी अधिकतम 10 पॉड तक नहीं पहुंच पाएगी। तीन प्रतिकृतियां 10 से कम प्रत्येक फली के लिए प्रति सेकंड अनुरोधों की संख्या बनाने के लिए पर्याप्त हैं।
लोड परीक्षण पूरा होने के बाद, एचपीए प्रतिकृतियों की प्रारंभिक संख्या में तैनाती के पैमाने को कम करेगा:
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulRescale 5m horizontal-pod-autoscaler New size: 3; reason: pods metric http_requests above target Normal SuccessfulRescale 21s horizontal-pod-autoscaler New size: 2; reason: All metrics below target
आपने देखा होगा कि ऑटो-स्केलर मैट्रिक्स में बदलाव का तुरंत जवाब नहीं देता है। डिफ़ॉल्ट रूप से, वे हर 30 सेकंड में सिंक्रनाइज़ होते हैं। इसके अलावा, स्केलिंग केवल तभी होती है जब पिछले 3-5 मिनट के दौरान वर्कलोड में वृद्धि या कमी नहीं हुई है। यह विरोधाभासी निर्णयों को रोकने में मदद करता है और क्लस्टर ऑटो-स्केलर को जोड़ने के लिए समय छोड़ देता है।
निष्कर्ष
सभी प्रणालियाँ पूरी तरह से CPU या मेमोरी उपयोग (या दोनों) के आधार पर SLA अनुपालन को लागू नहीं कर सकती हैं। ट्रैफ़िक स्पाइकों को संभालने के लिए अधिकांश वेब सर्वर और मोबाइल सर्वर को प्रति सेकंड अनुरोधों की संख्या के आधार पर ऑटोस्कोलिंग की आवश्यकता होती है।
ईटीएल अनुप्रयोगों के लिए (इंजी। ट्रांसफॉर्म लोड - "निष्कर्षण, परिवर्तन, लोडिंग" से), ऑटो-स्केलिंग को ट्रिगर किया जा सकता है, उदाहरण के लिए, जब नौकरी कतार की निर्दिष्ट सीमा लंबाई पार हो जाती है।
सभी मामलों में, प्रोमेथियस का उपयोग करते हुए अनुप्रयोगों को इंस्ट्रूमेंट करना और ऑटोस्कोलिंग के लिए आवश्यक संकेतकों को उजागर करना आपको ट्रैफ़िक स्पाइक्स के प्रसंस्करण में सुधार करने और बुनियादी ढांचे की उच्च उपलब्धता सुनिश्चित करने के लिए फाइन-ट्यून अनुप्रयोगों की अनुमति देता है।
विचार, प्रश्न, टिप्पणी?
स्लैक में चर्चा में शामिल हों!
यहाँ ऐसी सामग्री है। हम आपकी टिप्पणियों की प्रतीक्षा कर रहे हैं और आपको
पाठ्यक्रम पर देखेंगे!