डेटाबेस के साथ काम करने के मुख्य मुद्दे ऑपरेटिंग सिस्टम के डिवाइस की सुविधाओं से संबंधित हैं, जिस पर डेटाबेस काम करता है। लिनक्स अब डेटाबेस के लिए मुख्य ऑपरेटिंग सिस्टम है। सोलारिस, माइक्रोसॉफ्ट और यहां तक कि एचपीयूएक्स का उपयोग अभी भी उद्यम में किया जाता है, लेकिन वे कभी भी संयुक्त रूप से पहला स्थान नहीं लेंगे। लिनक्स आत्मविश्वास से जमीन हासिल कर रहा है क्योंकि अधिक से अधिक खुले स्रोत डेटाबेस हैं। इसलिए, OS के साथ डेटाबेस इंटरैक्शन का मुद्दा स्पष्ट रूप से लिनक्स डेटाबेस के बारे में है। यह अनन्त डीबी समस्या पर आधारित है - आईओ प्रदर्शन। यह अच्छा है कि हाल के वर्षों में लिनक्स IO स्टैक के एक प्रमुख ओवरहाल से गुजरा है और प्रबोधन की उम्मीद है।
Ilya Kosmodemyansky (
hydrobiont ) डेटा एग्रेट के लिए काम करता है, जो एक ऐसी कंपनी है जो पोस्टग्रेजेस्क का समर्थन और समर्थन करती है, और ओएस और डेटाबेस के बीच बातचीत के बारे में बहुत कुछ जानती है। हाईलाड ++ की एक रिपोर्ट में, इलिया ने पोस्टग्रेसीक्यू के उदाहरण का उपयोग करके आईओ और डेटाबेस की बातचीत के बारे में बात की, लेकिन यह भी दिखाया कि कैसे अन्य डेटाबेस आईओ के साथ काम करते हैं। मैंने लिनक्स आईओ स्टैक को देखा, इसमें क्या नई और अच्छी चीजें दिखाई दीं और सब कुछ वैसा क्यों नहीं है जैसा कि कुछ साल पहले था। एक उपयोगी अनुस्मारक के रूप में - नई गुठली में IO सबसिस्टम के अधिकतम प्रदर्शन के लिए PostgreSQL और लिनक्स सेटिंग्स की एक चेकलिस्ट।
रिपोर्ट वीडियो में बहुत सारे अंग्रेजी हैं, जिनमें से अधिकांश का हमने लेख में अनुवाद किया है।IO की बात क्यों करें?
फास्ट I / O डेटाबेस प्रशासक के लिए सबसे महत्वपूर्ण बात है । हर कोई जानता है कि सीपीयू के साथ काम करने में क्या बदला जा सकता है, उस मेमोरी का विस्तार किया जा सकता है, लेकिन I / O सब कुछ बर्बाद कर सकता है। यदि डिस्क के साथ बुरा है, और बहुत अधिक I / O है, तो डेटाबेस विलाप करेगा। IO एक अड़चन बन जाएगा।
सब कुछ अच्छी तरह से काम करने के लिए, आपको सब कुछ कॉन्फ़िगर करने की आवश्यकता है।
केवल डेटाबेस या केवल हार्डवेयर नहीं है - यही है। यहां तक कि उच्च-स्तरीय ओरेकल, जो स्वयं कुछ स्थानों पर एक ऑपरेटिंग सिस्टम है, को कॉन्फ़िगरेशन की आवश्यकता होती है। हम ओरेकल से "इंस्टॉलेशन गाइड" में निर्देशों को पढ़ते हैं: ऐसे कर्नेल पैरामीटर बदलें, दूसरों को बदलें - कई सेटिंग्स हैं। इस तथ्य के अलावा कि अनब्रेकेबल कर्नेल में पहले से ही ओरेकल लिनक्स के लिए डिफ़ॉल्ट रूप से वायर्ड है।
PostgreSQL और MySQL के लिए, और भी अधिक परिवर्तनों की आवश्यकता है। ऐसा इसलिए है क्योंकि ये प्रौद्योगिकियाँ OS तंत्र पर निर्भर हैं। एक DBA जो PostgreSQL, MySQL या आधुनिक NoSQL के साथ काम करता है, एक Linux ऑपरेशन इंजीनियर होना चाहिए और अलग-अलग OS नट को ट्विस्ट करना चाहिए।
हर कोई जो कर्नेल सेटिंग्स से निपटना चाहता है,
LWN में बदल जाता है। संसाधन सरल, न्यूनतर है, इसमें बहुत सारी उपयोगी जानकारी शामिल है, लेकिन
कर्नेल डेवलपर्स के लिए कर्नेल डेवलपर्स द्वारा लिखा गया था। कर्नेल डेवलपर्स क्या अच्छा लिखते हैं? कोर, लेख नहीं, इसका उपयोग कैसे करें। इसलिए, मैं आपको डेवलपर्स के लिए सब कुछ समझाने की कोशिश करूंगा, और उन्हें कर्नेल लिखने दूंगा।
सब कुछ इस तथ्य से कई बार जटिल है कि शुरू में लिनक्स कर्नेल का विकास और इसके स्टैक का प्रसंस्करण पीछे था, और हाल के वर्षों में वे बहुत जल्दी चले गए हैं। न तो लोहे और न ही उसके पीछे के लेखों के साथ डेवलपर्स।
विशिष्ट डेटाबेस
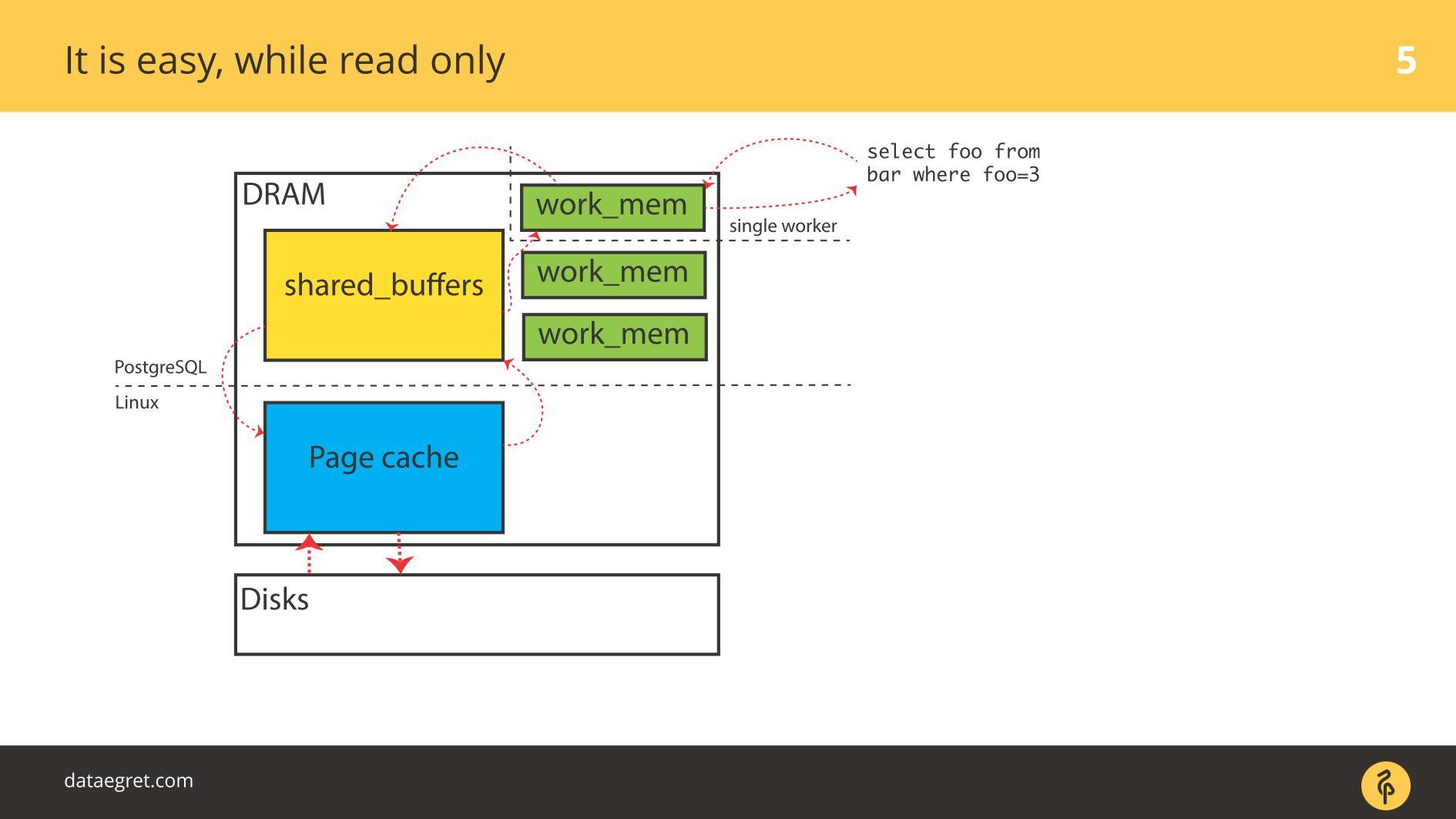
चलिए PostgreSQL के उदाहरणों से शुरू करते हैं - यहाँ बफ़र किया गया I / O है। इसमें मेमोरी साझा की गई है, जो ओएस के दृष्टिकोण से
यूजर स्पेस में आवंटित की गई है, और
कर्नेल स्पेस में
कर्नेल कैश में समान कैश
है ।
 एक आधुनिक डेटाबेस का मुख्य कार्य
एक आधुनिक डेटाबेस का मुख्य कार्य :
- मेमोरी में डिस्क से पेज उठाएं;
- जब कोई परिवर्तन होता है, तो पृष्ठों को गंदे के रूप में चिह्नित करें;
- राइट-अहेड लॉग में लिखें;
- फिर मेमोरी को सिंक्रनाइज़ करें ताकि यह डिस्क के अनुरूप हो।
PostgreSQL स्थिति में, यह एक निरंतर दौर यात्रा है: साझा मेमोरी से जो PostgreSQL पेज कैश कर्नेल में नियंत्रित करता है, और फिर पूरे लिनक्स स्टैक के माध्यम से डिस्क पर। यदि आप किसी फ़ाइल सिस्टम पर डेटाबेस का उपयोग करते हैं, तो यह किसी भी UNIX जैसी प्रणाली और किसी भी डेटाबेस के साथ इस एल्गोरिथ्म पर काम करेगा। मतभेद हैं, लेकिन महत्वहीन हैं।
ओरेकल एएसएम का उपयोग करना अलग होगा - ओरेकल खुद डिस्क के साथ इंटरैक्ट करता है। लेकिन सिद्धांत समान है: प्रत्यक्ष IO के साथ या पेज कैश के साथ, लेकिन कार्य
पूरे I / O स्टैक के माध्यम से पृष्ठों को जितनी जल्दी हो सके खींचना है , जो भी हो। और हर स्तर पर समस्याएं पैदा हो सकती हैं।
आईओ की दो समस्याएं
जबकि सब कुछ
केवल पढ़ा जाता है , कोई समस्या नहीं है। वे पढ़ते हैं और, यदि पर्याप्त मेमोरी है, तो पढ़ने के लिए आवश्यक सभी डेटा रैम में रखे जाते हैं। तथ्य यह है कि
बफ़र कैश में PostgreSQL के मामले में एक ही है, हम बहुत चिंतित नहीं हैं।
 IO के साथ पहली समस्या कैश सिंक्रोनाइज़ेशन है।
IO के साथ पहली समस्या कैश सिंक्रोनाइज़ेशन है। जब रिकॉर्डिंग की आवश्यकता होती है। इस मामले में, आपको अधिक मेमोरी को आगे और पीछे चलाना होगा।
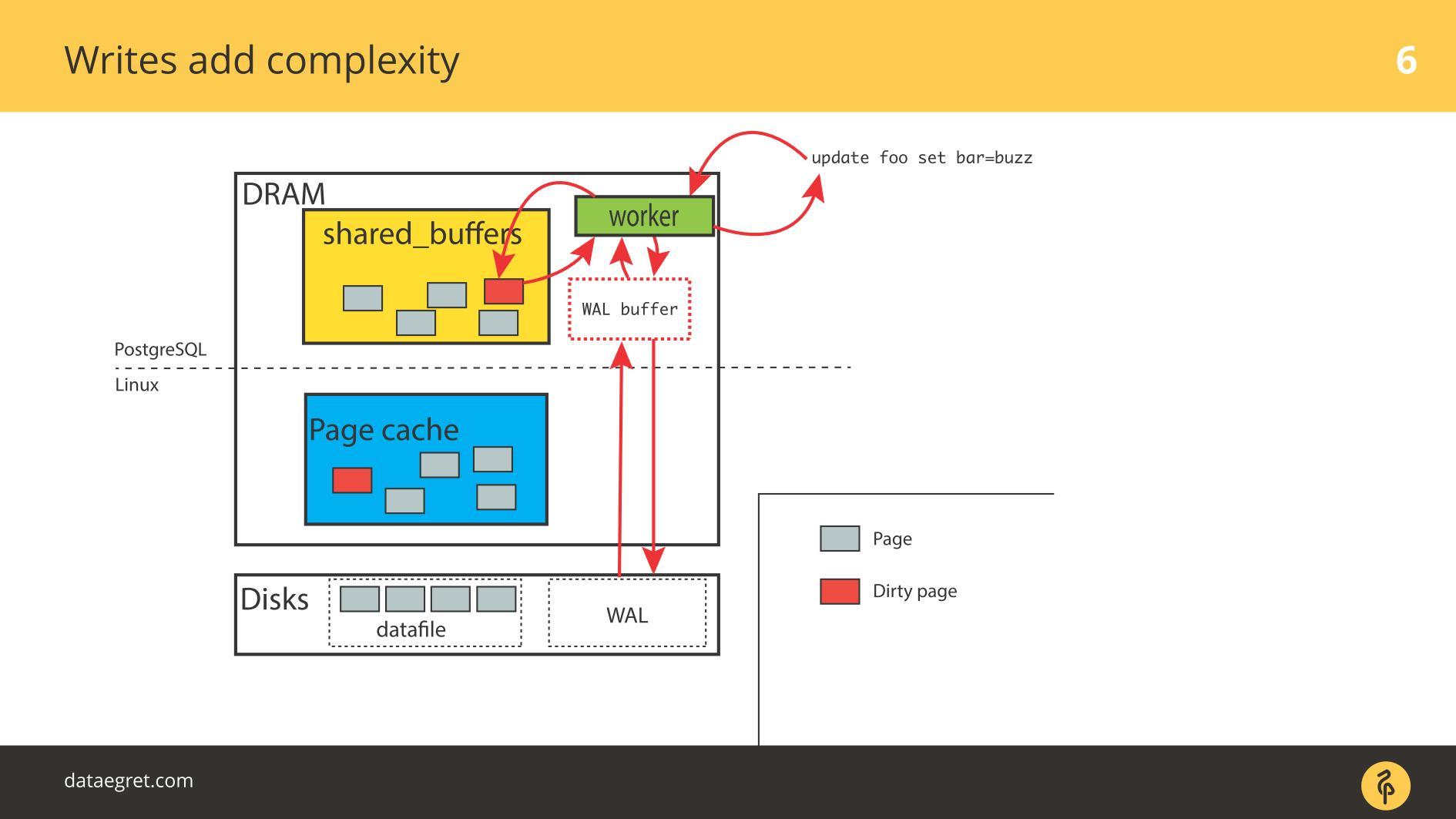
तदनुसार, आपको PostgreSQL या MySQL को कॉन्फ़िगर करने की आवश्यकता है ताकि यह सभी साझा की गई मेमोरी से डिस्क पर पहुंच जाए। PostgreSQL के मामले में - आपको अभी भी डिस्क में सब कुछ भेजने के लिए लिनक्स में गंदे पृष्ठों की पृष्ठभूमि को ठीक करने की आवश्यकता है।
दूसरी आम समस्या राइट-अहेड लॉग राइट विफलता है । ऐसा प्रतीत होता है जब लोड इतना शक्तिशाली होता है कि एक क्रमिक रूप से रिकॉर्ड किया गया लॉग डिस्क पर भी रहता है। इस स्थिति में, इसे भी जल्दी से रिकॉर्ड करना होगा।
स्थिति
कैश सिंक्रनाइज़ेशन से बहुत अलग नहीं है। PostgreSQL में, हम बड़ी संख्या में साझा बफ़र्स के साथ काम करते हैं, डेटाबेस में कुशल राइट-अहेड लॉग रिकॉर्डिंग के लिए तंत्र हैं, यह सीमा के अनुकूल है। केवल एक चीज जो लॉग को अधिक कुशल बनाने के लिए की जा सकती है वह है लिनक्स सेटिंग्स को बदलना।
डेटाबेस के साथ काम करने की मुख्य समस्याएं
साझा मेमोरी खंड बहुत बड़ा हो सकता है । मैंने 2012 में सम्मेलनों में इस बारे में बात करना शुरू किया। फिर मैंने कहा कि मेमोरी में गिरावट आई है, यहां तक कि 32 जीबी रैम वाले सर्वर भी हैं। 2019 में, पहले से ही लैपटॉप में अधिक हो सकता है, अधिक से अधिक 128, 256, आदि सर्वरों पर।
बहुत स्मृति है । बनल रिकॉर्डिंग में समय और संसाधन लगते हैं, और इसके
लिए हम जो
तकनीकों का उपयोग करते हैं, वे रूढ़िवादी हैं । डेटाबेस पुराने हैं, वे लंबे समय से विकसित किए गए हैं, वे धीरे-धीरे विकसित हो रहे हैं। डेटाबेस में तंत्र नवीनतम तकनीक के साथ बिल्कुल सही नहीं हैं।
स्मृति में पृष्ठों को सिंक्रनाइज़ करके विशाल IO परिचालनों में परिणाम होता है । जब हम कैश को सिंक्रनाइज़ करते हैं, तो IO की एक बड़ी धारा उत्पन्न होती है, और एक और समस्या उत्पन्न होती है -
हम कुछ को मोड़ नहीं सकते हैं और प्रभाव को देख सकते हैं। एक वैज्ञानिक प्रयोग में, शोधकर्ता एक पैरामीटर बदलते हैं - प्रभाव प्राप्त करें, दूसरा - प्रभाव प्राप्त करें, तीसरा। हम सफल नहीं हुए। हम PostgreSQL में कुछ मापदंडों को मोड़ते हैं, चौकियों को कॉन्फ़िगर करते हैं - हमने प्रभाव नहीं देखा। फिर कम से कम कुछ परिणाम पकड़ने के लिए पूरे स्टैक को फिर से कॉन्फ़िगर करें। ट्विस्ट एक पैरामीटर काम नहीं करता है - हम एक ही बार में सब कुछ कॉन्फ़िगर करने के लिए मजबूर हैं।
अधिकांश PostgreSQL IOs पृष्ठ सिंक्रनाइज़ेशन उत्पन्न करते हैं: चौकियों और अन्य तुल्यकालन तंत्र। यदि आपने PostgreSQL के साथ काम किया है, तो आपने समय-समय पर चार्ट में "आरी" दिखाई देने पर चौकियों को स्पाइक्स देखा होगा। पहले, कई को इस समस्या का सामना करना पड़ा, लेकिन अब इसे कैसे ठीक किया जाए, इस पर मैनुअल हैं, यह आसान हो गया है।
SSDs आज स्थिति को बहुत बचाते हैं। PostgreSQL में, कुछ शायद ही कभी मूल्य रिकॉर्ड पर सीधे रहता है। सब कुछ सिंक्रनाइज़ेशन पर निर्भर करता है: जब एक चेकपॉइंट होता है, तो fsync को बुलाया जाता है और एक चेकपॉइंट को दूसरे पर "हिट" करने का एक प्रकार है। बहुत ज्यादा आई.ओ. एक चेकपॉइंट अभी तक समाप्त नहीं हुआ है, अपने सभी fsyncs को पूरा नहीं किया है, लेकिन पहले से ही एक और चेकपॉइंट अर्जित किया है, और यह शुरू हो गया है!
PostgreSQL में एक अनूठी विशेषता है -
ऑटोवैक्यूम । यह डेटाबेस आर्किटेक्चर के लिए बैसाखी का एक लंबा इतिहास है। यदि ऑटोवैक्यूम विफल हो जाता है, तो वे आमतौर पर इसे स्थापित करते हैं ताकि यह आक्रामक रूप से काम करे और बाकी के साथ हस्तक्षेप न करे: बहुत सारे ऑटोवेक्यूम कार्यकर्ता होते हैं, अक्सर थोड़ा सा ट्रिपिंग करते हैं, जल्दी से टेबल प्रसंस्करण करते हैं। अन्यथा, डीडीएल और ताले के साथ समस्याएं होंगी।
लेकिन जब ऑटोवैक्यूम आक्रामक होता है, तो यह आईओ पर चबाना शुरू कर देता है।
अगर ऑटोकैसम को चौकियों पर लगाया जाता है, तो अधिकांश समय लगभग 100% पुनर्नवीनीकरण होते हैं, और यह समस्याओं का स्रोत है।
अजीब तरह से पर्याप्त है, एक
कैश रीफिल समस्या है। वह आमतौर पर डीबीए के लिए कम जाना जाता है। एक विशिष्ट उदाहरण: डेटाबेस शुरू हुआ, और कुछ समय के लिए सब कुछ उदास रूप से धीमा हो जाता है। इसलिए, भले ही आपके पास बहुत सी रैम हो, अच्छे डिस्क खरीदें ताकि स्टैक कैश को गर्म कर सके।
यह सब गंभीरता से प्रदर्शन को प्रभावित करता है। डेटाबेस को पुनरारंभ करने के तुरंत बाद समस्याएं शुरू नहीं होती हैं, लेकिन बाद में। उदाहरण के लिए, चेकपॉइंट पास हुआ और पूरे डेटाबेस में कई पृष्ठ गंदे हैं। उन्हें डिस्क पर कॉपी किया जाता है क्योंकि आपको उन्हें सिंक्रनाइज़ करने की आवश्यकता होती है। फिर अनुरोध डिस्क से पृष्ठों के एक नए संस्करण के लिए पूछते हैं, और डेटाबेस sags। रेखांकन दिखाएगा कि कैश कैसे प्रत्येक चेकपॉइंट के बाद फिर से लोड करने के लिए एक निश्चित प्रतिशत में योगदान देता है।
डेटाबेस के इनपुट / आउटपुट में सबसे अप्रिय बात
कार्यकर्ता IO है। जब प्रत्येक कार्यकर्ता जो आपसे अनुरोध करता है, वह अपना IO उत्पन्न करना शुरू कर देता है। Oracle में, यह इसके साथ आसान है, लेकिन PostgreSQL में यह एक समस्या है।
वर्कर IO के साथ समस्याओं के कई कारण हैं: डिस्क से नए पृष्ठों को "पोस्ट" करने के लिए पर्याप्त कैश नहीं है। उदाहरण के लिए, ऐसा होता है कि सभी बफ़र्स साझा किए जाते हैं, वे सभी गंदे होते हैं, चौकियों अभी तक नहीं हुई हैं। कार्यकर्ता को सबसे सरल चयन करने के लिए, आपको कहीं से कैश लेने की आवश्यकता है। ऐसा करने के लिए, आपको सबसे पहले इसे डिस्क पर सहेजने की आवश्यकता है। आपके पास एक विशेष चेकपॉइंट प्रक्रिया नहीं है, और कार्यकर्ता मुफ्त में fsync शुरू करता है और इसे कुछ नया करता है।
यह एक और भी बड़ी समस्या खड़ी करता है: कार्यकर्ता एक गैर-विशिष्ट चीज है, और पूरी प्रक्रिया को बिल्कुल भी अनुकूलित नहीं किया गया है। लिनक्स स्तर पर कहीं न कहीं इसे अनुकूलित करना संभव है, लेकिन पोस्टग्रेक्सेल में यह एक आपातकालीन उपाय है।
DB के लिए मुख्य IO समस्या
जब हम कुछ सेट करते हैं तो हम किस समस्या का समाधान करते हैं? हम डिस्क और मेमोरी के बीच गंदे पृष्ठों की यात्रा को अधिकतम करना चाहते हैं।
लेकिन अक्सर ऐसा होता है कि ये चीजें सीधे डिस्क को नहीं छूती हैं। एक विशिष्ट मामला - आपको एक बहुत बड़ा लोड औसत दिखाई देता है। ऐसा क्यों? क्योंकि कोई डिस्क का इंतजार कर रहा है, और अन्य सभी प्रक्रियाएं भी इंतजार कर रही हैं। ऐसा लगता है कि डिस्क का कोई स्पष्ट डिस्क उपयोग नहीं है, बस कुछ ने वहां डिस्क को अवरुद्ध कर दिया है, और समस्या वैसे भी इनपुट / आउटपुट के साथ है।
डेटाबेस I / O समस्याएं हमेशा केवल डिस्क की चिंता नहीं करती हैं।
सब कुछ इस समस्या में शामिल है: डिस्क, मेमोरी, सीपीयू, आईओ शेड्यूलर, फाइल सिस्टम और डेटाबेस सेटिंग्स। अब चलो स्टैक के माध्यम से चलते हैं, देखें कि इसके साथ क्या करना है, और लिनक्स में किन अच्छी चीजों का आविष्कार किया गया है ताकि सब कुछ बेहतर हो सके।
डिस्क
कई वर्षों के लिए, डिस्क बहुत धीमी थी और कोई भी संक्रमण के चरणों की विलंबता या अनुकूलन में शामिल नहीं था। Fsyncs का अनुकूलन करने का कोई मतलब नहीं था। डिस्क कताई थी, सिर एक फोनोग्राफ रिकॉर्ड की तरह इसके साथ आगे बढ़ रहे थे, और fsyncs इतना लंबा था कि समस्याएं सामने नहीं आईं।
स्मृति
डेटाबेस को ट्यून किए बिना शीर्ष प्रश्नों को देखना बेकार है। आप साझा मेमोरी आदि की पर्याप्त मात्रा को कॉन्फ़िगर करेंगे, और आपके पास एक नई शीर्ष क्वेरी होगी - आपको इसे फिर से कॉन्फ़िगर करना होगा। यहाँ भी वही कहानी है। इस गणना से पूरा लिनक्स स्टैक बनाया गया था।
बैंडविड्थ और विलंबता
थ्रूपुट को अधिकतम करके IO प्रदर्शन को अधिकतम करना एक बिंदु तक आसान है। PostgreSQL में एक सहायक PageWriter प्रक्रिया का आविष्कार किया गया था जो कि चेकपॉइंट को अनलोड करता है। कार्य समानांतर हो गया है, लेकिन समानता के अतिरिक्त के लिए अभी भी जमीनी कार्य है। और विलंबता को कम करने के लिए अंतिम मील का कार्य है, जिसके लिए सुपर प्रौद्योगिकियों की आवश्यकता होती है।
ये सुपर प्रौद्योगिकियां एसएसडी हैं। जब वे दिखाई दिए, तो विलंबता तेजी से गिर गई। लेकिन स्टैक के अन्य सभी चरणों में, समस्याएं दिखाई दीं: डेटाबेस निर्माताओं की ओर से और लिनक्स निर्माताओं से दोनों। समस्याओं पर ध्यान देने की आवश्यकता है।
लिनक्स कर्नेल विकास के रूप में डेटाबेस विकास अधिकतम थ्रूपुट के आसपास केंद्रित है। कताई डिस्क के I / O युग के अनुकूलन के लिए कई तरीके SSD के लिए इतने अच्छे नहीं हैं।
बीच में, हमें वर्तमान लिनक्स बुनियादी ढांचे के लिए बैक अप के लिए मजबूर किया गया था, लेकिन नए डिस्क के साथ। हमने निर्माता से बड़ी संख्या में विभिन्न IOPS के प्रदर्शन परीक्षण देखे, और डेटाबेस में कोई बेहतर नहीं हुआ, क्योंकि डेटाबेस केवल और केवल IOPS के बारे में ही नहीं है। अक्सर ऐसा होता है कि हम 50,000 IOPS प्रति सेकंड छोड़ सकते हैं, जो अच्छा है। लेकिन अगर हम विलंबता नहीं जानते हैं, इसके वितरण को नहीं जानते हैं, तो हम प्रदर्शन के बारे में कुछ नहीं कह सकते हैं। कुछ बिंदु पर, डेटाबेस चेकपॉइंट करना शुरू कर देगा, और विलंबता नाटकीय रूप से बढ़ जाएगी।
एक लंबे समय के लिए, अब के रूप में, यह virtuala डेटाबेस पर एक बड़ी प्रदर्शन समस्या रही है। वर्चुअल IO को असमान विलंबता की विशेषता है, जो निश्चित रूप से, समस्याओं को भी बढ़ाता है।
IO स्टैक। जैसा कि पहले था
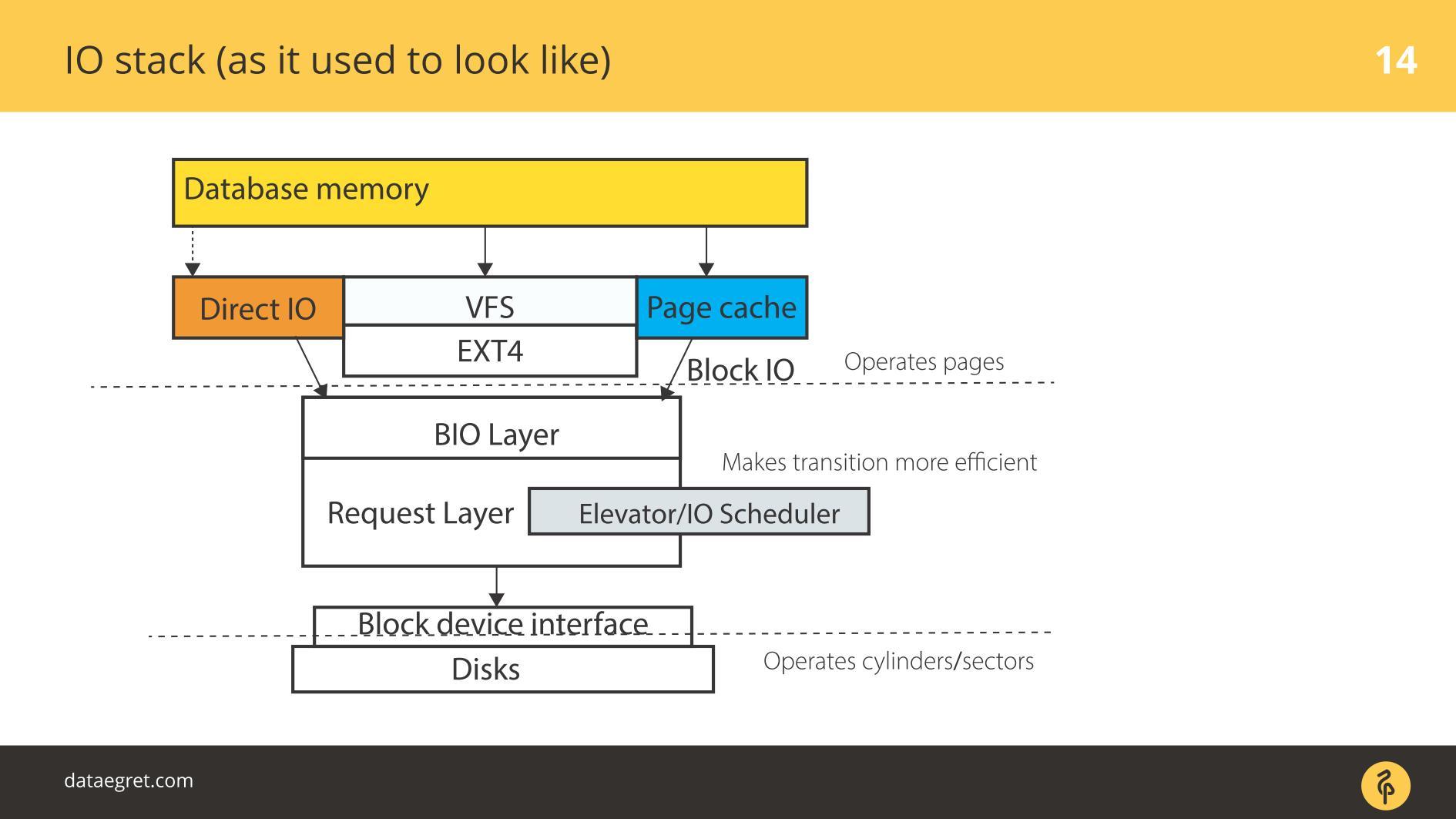
उपयोगकर्ता स्थान है - वह मेमोरी, जिसे डेटाबेस द्वारा ही प्रबंधित किया जाता है। एक DB में कॉन्फ़िगर किया गया है ताकि सब कुछ उसी तरह काम करे जैसा उसे करना चाहिए। यह एक अलग रिपोर्ट में किया जा सकता है, और एक भी नहीं। फिर सब कुछ अनिवार्य रूप से पेज कैश के माध्यम से या डायरेक्ट आईओ इंटरफेस के माध्यम से
ब्लॉक इनपुट / आउटपुट परत में प्रवेश करता है।
एक फ़ाइल सिस्टम इंटरफ़ेस की कल्पना करें। वे पृष्ठ जो बफ़र कैश में थे, क्योंकि वे मूल रूप से डेटाबेस में थे, यानी ब्लॉक, इसके माध्यम से आते हैं। ब्लॉक IO परत निम्नलिखित के साथ संबंधित है। एक सी संरचना है जो कर्नेल में एक ब्लॉक का वर्णन करती है। संरचना इन ब्लॉकों को लेती है और इनपुट या आउटपुट अनुरोधों के वैक्टर (सरणियों) से उन्हें इकट्ठा करती है। BIO लेयर के नीचे आवश्यक लेयर है। इस परत पर वेक्टर्स एकत्र किए जाते हैं और आगे जाएंगे।
लंबे समय से, लिनक्स में इन दो परतों को चुंबकीय डिस्क पर कुशल रिकॉर्डिंग के लिए तेज किया गया था। संक्रमण के बिना ऐसा करना असंभव था। ऐसे ब्लॉक हैं जो डेटाबेस से प्रबंधित करने के लिए सुविधाजनक हैं। इन ब्लॉकों को वैक्टर में इकट्ठा करना आवश्यक है जो आसानी से डिस्क पर लिखे गए हैं ताकि वे आस-पास कहीं झूठ बोलें। इसे प्रभावी ढंग से काम करने के लिए, वे एलीवेटर्स, या शेड्यूलर IO के साथ आए।
लिफ्ट
एलेवेटर मुख्य रूप से वैक्टर के संयोजन और छंटाई में शामिल थे। ब्लॉक के लिए सभी क्रम में एसडी ड्राइवर - क्वासिडिस्क ड्राइवर - रिकॉर्डिंग ब्लॉक उसके लिए सुविधाजनक क्रम में आने के लिए। ड्राइवर ने ब्लॉकों से अपने क्षेत्रों में अनुवाद किया और डिस्क पर लिखा।
समस्या यह थी कि कई बदलाव करना आवश्यक था, और प्रत्येक में इष्टतम प्रक्रिया के अपने स्वयं के तर्क को लागू करना था।
लिफ्ट: कर्नेल 2.6 तक
कर्नेल 2.6 से पहले, लिनुस एलेवेटर था - सबसे आदिम आईओ शेड्यूलर, जो आपके द्वारा लिखा गया है, जो अनुमान लगाता है। लंबे समय तक उन्हें बिल्कुल अस्थिर और अच्छा माना जाता था, जब तक कि उन्होंने कुछ नया विकसित नहीं किया।
लिनस एलेवेटर को बहुत समस्याएँ थीं।
उन्होंने कहा कि कैसे और अधिक कुशलता से रिकॉर्ड करने के लिए के अनुसार संयुक्त और हल । घूर्णन यांत्रिक डिस्क के मामले में, इसने "
भुखमरी" का उद्भव किया: एक स्थिति जहां रिकॉर्डिंग दक्षता डिस्क के रोटेशन पर निर्भर करती है। यदि आपको अचानक एक ही समय में प्रभावी ढंग से पढ़ने की आवश्यकता है, लेकिन यह पहले से ही गलत तरीके से घुमाया गया है, तो यह ऐसी डिस्क से खराब पढ़ा जाता है।
धीरे-धीरे, यह स्पष्ट हो गया कि यह एक अक्षम तरीका है। इसलिए, कर्नेल 2.6 से शुरू होकर, शेड्यूलरों का एक पूरा चिड़ियाघर दिखाई देने लगा, जो विभिन्न कार्यों के लिए अभिप्रेत था।
लिफ्ट: 2.6 और 3 के बीच
कई लोग इन शेड्यूलर्स को ऑपरेटिंग सिस्टम शेड्यूलर्स के साथ भ्रमित करते हैं क्योंकि उनके समान नाम हैं।
CFQ - पूरी तरह से फेयर क्युइंग OS शेड्यूलर्स के समान नहीं है। बस नाम समान हैं। यह एक सार्वभौमिक अनुसूचक के रूप में गढ़ा गया था।
एक सार्वभौमिक अनुसूचक क्या है? क्या आपको लगता है कि आपके पास एक औसत लोड है या, इसके विपरीत, एक अद्वितीय? डेटाबेस में बहुत खराब बहुमुखी प्रतिभा है। यूनिवर्सल लोड की कल्पना एक नियमित लैपटॉप के रूप में की जा सकती है। वहां सब कुछ होता है: हम संगीत सुनते हैं, खेलते हैं, टेक्स्ट टाइप करते हैं। इसके लिए, केवल सार्वभौमिक शेड्यूलर लिखे गए थे।
यूनिवर्सल शेड्यूलर का मुख्य कार्य: लिनक्स के मामले में, प्रत्येक वर्चुअल टर्मिनल और प्रक्रिया के लिए, एक अनुरोध कतार बनाएं। जब हम एक ऑडियो प्लेयर में संगीत सुनना चाहते हैं, तो खिलाड़ी के लिए IO एक कतार लेता है। अगर हम cp कमांड का उपयोग करके कुछ बैकअप लेना चाहते हैं, तो कुछ और शामिल है।
डेटाबेस के मामले में, एक समस्या होती है। एक नियम के रूप में, एक डेटाबेस एक प्रक्रिया है जो शुरू हुई, और ऑपरेशन के दौरान समानांतर प्रक्रियाएं उत्पन्न हुईं जो हमेशा एक ही I / O कतार में समाप्त होती हैं। कारण यह है कि यह एक ही आवेदन, एक ही मूल प्रक्रिया है। बहुत छोटे भार के लिए, इस तरह के शेड्यूलिंग उपयुक्त थे, बाकी के लिए इसका कोई मतलब नहीं था। यदि संभव हो तो इसे बंद करना और उपयोग नहीं करना आसान था।
धीरे-धीरे,
डेडलाइन शेड्यूलर दिखाई दिया - यह अधिक चालाक तरीके से काम करता है, लेकिन मूल रूप से यह कताई डिस्क के लिए विलय और छंटनी है। एक विशिष्ट डिस्क सबसिस्टम के डिजाइन को देखते हुए, हम उन्हें इष्टतम तरीके से लिखने के लिए ब्लॉक वैक्टर इकट्ठा करते हैं। उन्हें
भुखमरी की समस्या कम थी, लेकिन वे वहाँ थे।
इसलिए, तीसरे लिनक्स कर्नेल के करीब
कोई नहीं या
कोई नहीं दिखाई दिया, जिसने एसएसडी के प्रसार के साथ बहुत बेहतर काम किया। शेड्यूलर नूप को शामिल करते हुए, हम वास्तव में शेड्यूलिंग को अक्षम करते हैं: सीएफक्यू और समय सीमा के अनुसार कोई छंटनी, विलय, और समान चीजें नहीं हैं।
यह एसएसडी के साथ बेहतर काम करता है, क्योंकि एसएसडी स्वाभाविक रूप से समानांतर हैं: इसमें मेमोरी सेल हैं। एक पीसीआई बोर्ड पर रटना करने के लिए इन तत्वों का जितना अधिक होगा, उतना ही कुशल होगा।
SSD, विचार के दृष्टिकोण से, इसके कुछ अन्य शासकों से समयबद्धक, कुछ वैक्टर एकत्र करता है और उन्हें कहीं भेजता है। यह सब एक फ़नल के साथ समाप्त होता है। तो हम SSDs की संगति को मारते हैं, उन्हें पूर्ण रूप से उपयोग नहीं करते हैं। इसलिए, एक साधारण शटडाउन, जब वैक्टर बिना किसी छँटाई के बेतरतीब ढंग से चलते हैं, प्रदर्शन के मामले में बेहतर काम किया। इस वजह से, यह माना जाता है कि यादृच्छिक पढ़ता है, यादृच्छिक लेखन SSDs पर बेहतर होता है।
लिफ्ट: 3.13 बाद में
कर्नेल 3.13 से शुरू होकर,
blk-mq दिखाई दिया । थोड़ा पहले एक प्रोटोटाइप था, लेकिन 3.13 में पहली बार एक कार्यशील संस्करण दिखाई दिया।
Blk-mq एक अनुसूचक के रूप में
शुरू हुआ , लेकिन इसे एक अनुसूचक कहना मुश्किल है - यह वास्तुकला में अकेला खड़ा है। यह कर्नेल में अनुरोध परत के लिए एक प्रतिस्थापन है। धीरे-धीरे, blk-mq के विकास ने पूरे लिनक्स I / O स्टैक का एक बड़ा ओवरहाल किया।
विचार यह है: आइए / ओ के लिए कुशल संगति करने के लिए एसएसडी की मूल क्षमता का उपयोग करें। आप कितने समानांतर I / O स्ट्रीम का उपयोग कर सकते हैं इसके आधार पर, ईमानदार कतारें हैं जिनके माध्यम से हम बस एसएसडी पर लिखते हैं। रिकॉर्डिंग के लिए प्रत्येक सीपीयू की अपनी कतार होती है।
वर्तमान में
blk-mq सक्रिय रूप से विकसित और काम कर रहा है। इसका उपयोग न करने का कोई कारण नहीं है। आधुनिक कोर में, 4 और ऊपर से,
ब्लेक-एमके से, लाभ ध्यान देने योग्य है - 5-10% नहीं, लेकिन काफी अधिक।
SSDs के साथ काम करने के लिए blk-mq शायद सबसे अच्छा विकल्प है।
अपने वर्तमान रूप में,
blk-mq सीधे
NVMe ड्राइवर लिनक्स से जुड़ा हुआ है। लिनक्स के लिए न केवल एक ड्राइवर है, बल्कि माइक्रोसॉफ्ट के लिए एक ड्राइवर भी है। लेकिन
blk-mq और NVMe ड्राइवर बनाने का विचार लिनक्स स्टैक का बहुत प्रसंस्करण है, जिससे डेटाबेस को लाभ हुआ है।
कई कंपनियों के एक संघ ने एक विनिर्देश बनाने का फैसला किया, यह बहुत ही प्रोटोकॉल है। अब यह पहले से ही उत्पादन संस्करण में स्थानीय PCIe SSDs के लिए ठीक काम करता है। प्रकाश सरणियों के लिए लगभग तैयार समाधान जो प्रकाशिकी के माध्यम से जुड़े हुए हैं।
Blk-mq ड्राइवर और NVMe एक अनुसूचक से अधिक हैं। सिस्टम का उद्देश्य अनुरोधों के पूरे स्तर को बदलना है।
आइए इसे समझने के लिए इसमें गोता लगाएँ। एनवीएमई विनिर्देश बड़ा है, इसलिए हम सभी विवरणों पर विचार नहीं करेंगे, लेकिन बस उन पर जाएं।
लिफ्ट के लिए पुराना तरीका

सबसे सरल मामला: एक सीपीयू है, इसकी बारी है, और किसी तरह हम डिस्क पर जाते हैं।
अधिक उन्नत लिफ्टों ने अलग तरीके से काम किया। कई सीपीयू और कई कतारें हैं। किसी तरह, उदाहरण के लिए, जिसके आधार पर माता-पिता डेटाबेस श्रमिकों की प्रक्रिया को बंद कर देते हैं, IO डिस्क पर कतारबद्ध हो जाता है।
लिफ्ट के लिए एक नया तरीका
blk-mq एक पूरी तरह से नया तरीका है। प्रत्येक CPU, प्रत्येक NUMA ज़ोन बदले में अपना इनपुट / आउटपुट जोड़ता है। इसके अलावा, डेटा डिस्क पर गिरता है, चाहे कितना भी जुड़ा हो, क्योंकि ड्राइवर नया है। कोई एसडी ड्राइवर नहीं है जो सिलेंडर, ब्लॉक की अवधारणाओं के साथ काम करता है।
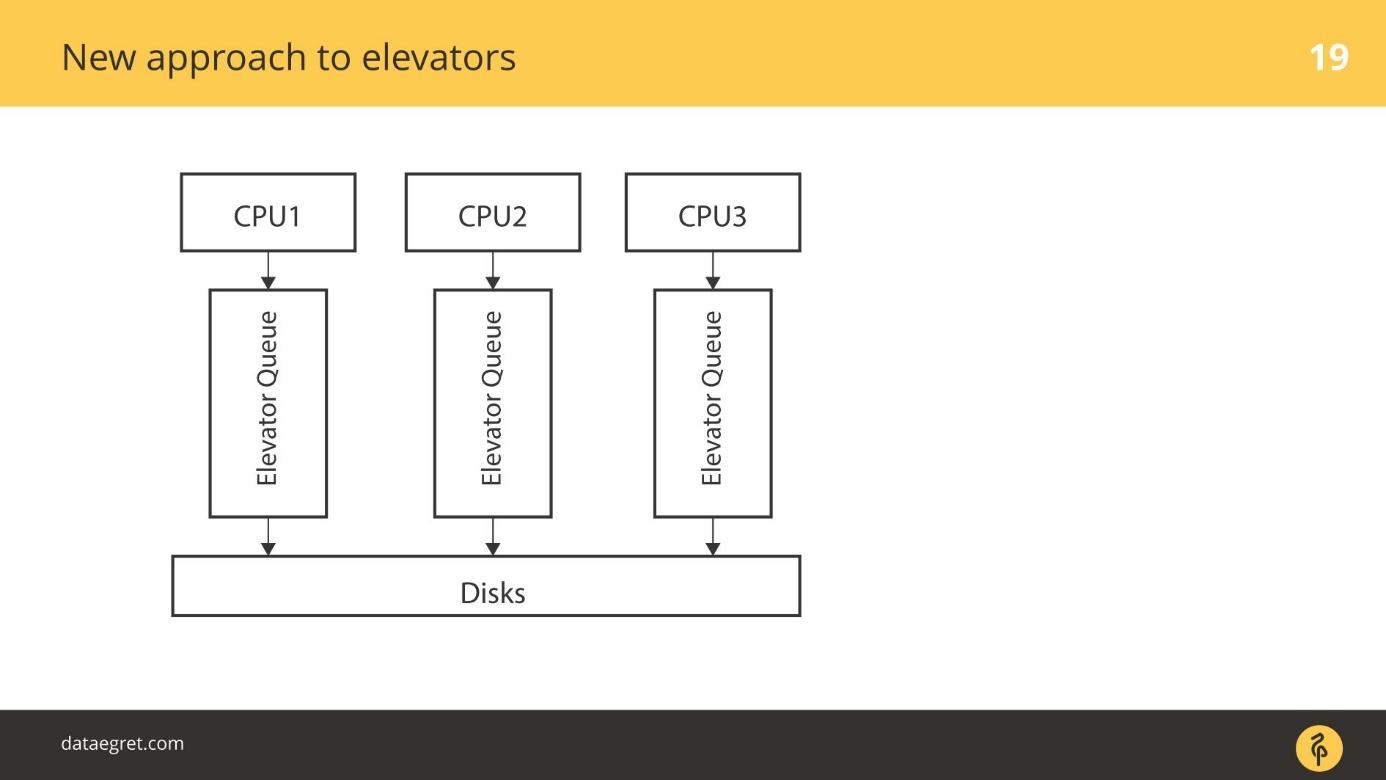
एक संक्रमण काल था। कुछ बिंदु पर, RAID सरणियों के सभी विक्रेताओं ने ऐड-ऑन बेचना शुरू कर दिया जो उन्हें RAID कैश को बायपास करने की अनुमति देता है। यदि एसएसडी जुड़े हुए हैं, तो सीधे वहां लिखें। उन्होंने अपने उत्पादों के लिए SD ड्राइवर का उपयोग करना बंद कर दिया, जैसे blq-mq।
ब्लाक-माक के साथ नया ढेर
इस प्रकार स्टैक एक नए रूप में दिखता है।

ऊपर से सब कुछ यथावत रहता है। उदाहरण के लिए, डेटाबेस बहुत पीछे हैं। I / O डेटाबेस से पहले की तरह, ब्लॉक IO परत में आता है। वहाँ बहुत
blk-mq है जो क्वेरी लेयर को प्रतिस्थापित करता है, शेड्यूलर को नहीं।
कर्नेल 3.13 में, संपूर्ण अनुकूलन उसी पर समाप्त हो गया, लेकिन नई तकनीकों का उपयोग आधुनिक कर्नेल में किया जाता है।
ब्लेक-एमक्यू के लिए विशेष शेड्यूलर दिखाई देने लगे, जो मजबूत समानता के लिए डिज़ाइन किए गए हैं। Linux schedulers IO — Kyber BFQ.
blk-mq .
BFQ — Budget Fair Queueing — FQ . , . BFQ — scheduler . IO. IO, / . , . — . BFQ, , .
Kyber — . BFQ, . Kyber scheduler . — CPU . Kyber .
—
blk-mq SD- . , , , IO-. blk-mq NVMe driver . .
— latency, . SSD, — . -, , NVMe-, blk-mq , . .
Linux IO
/ Linux.
, , , Elevators, .
, , .
NVM Express
NVM Express NVMe — , , SSD. Linux. Linux — .
. 20 / SSD , NVMe , , —
32 / . SD , , .
, , .
एक बार डेटाबेस को घूर्णन डिस्क के लिए और उन्हें उन्मुख करने के लिए लिखा गया था - उदाहरण के लिए, उन्हें बी-ट्री के रूप में अनुक्रमित किया गया है। सवाल उठता है:
क्या एनवीएमई के लिए डेटाबेस तैयार हैं ? क्या डेटाबेस ऐसे भार को चबाने में सक्षम हैं?
अभी तक नहीं, लेकिन वे आदत डाल रहे हैं। PostgreSQL मेलिंग सूची में हाल ही में
pwrite() और इसी तरह की कुछ चीजें थीं। PostgreSQL और MySQL डेवलपर्स कर्नेल डेवलपर्स के साथ बातचीत करते हैं। बेशक, मैं और अधिक बातचीत करना चाहूंगा।
हाल ही में विकास
पिछले डेढ़ साल में, NVMe ने
IO मतदान जोड़ा है।
सबसे पहले उच्च विलंबता के साथ कताई डिस्क थे। फिर एसएसडी आए, जो बहुत तेज हैं। लेकिन एक जाम था: fsync चलता है, रिकॉर्डिंग शुरू होती है, और बहुत कम स्तर पर - चालक में गहरी, सीधे एक अनुरोध हार्डवेयर के टुकड़े को भेजा जाता है - इसे लिखो।
तंत्र सरल था - उन्होंने इसे भेजा और हम तब तक इंतजार करते हैं जब तक कि बाधा संसाधित नहीं हो जाती। कताई डिस्क पर लिखने की तुलना में इंटरप्ट प्रोसेसिंग की प्रतीक्षा करना कोई समस्या नहीं है। प्रतीक्षा करने में इतना समय लगा कि जैसे ही रिकॉर्डिंग समाप्त हुई, व्यवधान ने काम किया।
चूंकि एसएसडी बहुत जल्दी लिखता है, रिकॉर्डिंग के बारे में हार्डवेयर के टुकड़े को मतदान करने के लिए एक तंत्र जबरन दिखाई दिया है। पहले संस्करणों में, I / O गति में वृद्धि इस तथ्य के कारण 50% तक पहुंच गई कि हम एक रुकावट की प्रतीक्षा नहीं कर रहे हैं, लेकिन हम सक्रिय रूप से रिकॉर्ड के बारे में लोहे के टुकड़े से पूछ रहे हैं।
इस तंत्र को IO मतदान कहा जाता है ।
इसे हाल के संस्करणों में पेश किया गया था। संस्करण 4.12 में,
IO अनुसूचियां दिखाई दीं, विशेष रूप से
blk-mq और NVMe के साथ काम करने के लिए तेज किया गया, जिसके बारे में मैंने कहा कि
Kyber और BFQ । वे पहले से ही आधिकारिक रूप से कर्नेल में हैं, उनका उपयोग किया जा सकता है।
अब प्रयोग करने योग्य रूप में तथाकथित
IO टैगिंग है । ज्यादातर बादल और आभासी मशीनों के निर्माता इस विकास में योगदान देंगे। मोटे तौर पर, एक विशिष्ट एप्लिकेशन से इनपुट से निपटा जा सकता है और इसे प्राथमिकता दे सकता है। डेटाबेस अभी इसके लिए तैयार नहीं हैं, लेकिन बने रहें। मुझे लगता है कि यह जल्द ही मुख्यधारा में आ जाएगा।
डायरेक्ट IO नोट्स
PostgreSQL डायरेक्ट IO का समर्थन नहीं करता है, और कई मुद्दे हैं जो समर्थन को सक्षम करना मुश्किल बनाते हैं । अब यह केवल मूल्य के लिए समर्थित है, और केवल अगर प्रतिकृति सक्षम नहीं है।
बहुत सारे ओएस-विशिष्ट कोड लिखना आवश्यक
है , और अब हर कोई इससे बचता है।
इस तथ्य के बावजूद कि लिनक्स प्रत्यक्ष IO के विचार पर भारी शपथ लेता है और इसे कैसे लागू किया जाता है, सभी डेटाबेस वहां जाते हैं। Oracle और MySQL में, डायरेक्ट IO का भारी उपयोग किया जाता है। PostgreSQL एकमात्र ऐसा डेटाबेस है जिसे डायरेक्ट IO बर्दाश्त नहीं करता है।
सूची की जाँच करें
PostgreSQL में fsync आश्चर्य से खुद को कैसे सुरक्षित रखें:
- कम लगातार और बड़ा होने के लिए चौकियों की स्थापना करें।
- चेकपॉइंट की मदद के लिए बैकग्राउंड राइटर सेट करें।
- ऑटोवैक्म को खींचो ताकि कोई अनावश्यक अचूक I / O न हो।
परंपरा के अनुसार, नवंबर में हम हाईलाड ++ पर स्कोल्कोवो में अत्यधिक भरी हुई सेवाओं के पेशेवर डेवलपर्स की प्रतीक्षा कर रहे हैं। अभी भी एक रिपोर्ट के लिए आवेदन करने के लिए एक महीना है, लेकिन हमने पहले ही कार्यक्रम के लिए पहली रिपोर्ट स्वीकार कर ली है। हमारे न्यूज़लेटर के लिए साइन अप करें और नए विषयों के बारे में जानें।