कुछ समय पहले, SObjectizer के एक रिलीज़ पर चर्चा में, हमसे पूछा गया था: "क्या डेटा-प्रोसेसिंग पाइपलाइन का वर्णन करने के लिए डीएसएल बनाना संभव है?" दूसरे शब्दों में, क्या ऐसा कुछ लिखना संभव है:
A | B | C | D
और एक कार्यशील पाइपलाइन प्राप्त करें जहां संदेश ए से बी और फिर सी से जा रहे हैं, और फिर डी के साथ नियंत्रण है कि बी को ठीक उसी प्रकार प्राप्त होता है जो ए रिटर्न देता है। और C ठीक उसी प्रकार प्राप्त करता है जिस प्रकार B वापस आता है। और इसी तरह।
यह आश्चर्यजनक रूप से सरल समाधान के साथ एक दिलचस्प काम था। उदाहरण के लिए, यह है कि पाइपलाइन का निर्माण कैसा दिख सकता है:
auto pipeline = make_pipeline(env, stage(A) | stage(B) | stage(C) | stage(D));
या, एक अधिक जटिल मामले में (जो नीचे चर्चा की जाएगी):
auto pipeline = make_pipeline( sobj.environment(), stage(validation) | stage(conversion) | broadcast( stage(archiving), stage(distribution), stage(range_checking) | stage(alarm_detector{}) | broadcast( stage(alarm_initiator), stage( []( const alarm_detected & v ) { alarm_distribution( cerr, v ); } ) ) ) );
इस लेख में, हम ऐसे पाइपलाइन डीएसएल के कार्यान्वयन के बारे में बात करेंगे। हम stage() से संबंधित अधिकांश भागों stage() , broadcast() और operator|() C ++ टेम्पलेट्स के उपयोग के कई उदाहरणों के साथ कार्य करेंगे। इसलिए मुझे आशा है कि यह उन पाठकों के लिए भी दिलचस्प होगा, जिन्हें SObjectizer के बारे में जानकारी नहीं है (यदि आपने कभी भी SObjectizer के बारे में नहीं सुना है तो इस टूल का अवलोकन करें)।
प्रयुक्त डेमो के बारे में शब्दों की एक जोड़ी
लेख में प्रयुक्त उदाहरण SCADA क्षेत्र में मेरे पुराने (और बल्कि भूल गए) अनुभव से प्रभावित हुआ है।
डेमो का विचार कुछ सेंसर से पढ़े गए डेटा की हैंडलिंग है। डेटा को कुछ अवधि के साथ एक सेंसर से अधिग्रहित किया जाता है, फिर उस डेटा को मान्य किया जाना चाहिए (गलत डेटा को नजरअंदाज किया जाना चाहिए) और वास्तविक मूल्यों में बदल दिया जाता है। उदाहरण के लिए, एक सेंसर से पढ़ा गया कच्चा डेटा दो 8-बिट पूर्णांक मान हो सकता है और उन मानों को एक फ़्लोटिंग-पॉइंट नंबर में परिवर्तित किया जाना चाहिए।
फिर वैध और परिवर्तित मूल्यों को संग्रहीत किया जाना चाहिए, कहीं वितरित किया जाना चाहिए (उदाहरण के लिए अलग-अलग नोड्स पर, उदाहरण के लिए), "अलार्म" के लिए जाँच की जाती है (यदि मान सुरक्षित सीमाओं से बाहर हैं तो विशेष रूप से नियंत्रित किया जाना चाहिए)। ये ऑपरेशन स्वतंत्र हैं और समानांतर में किए जा सकते हैं।
पता चला अलार्म से संबंधित संचालन समानांतर में भी किया जा सकता है: एक "अलार्म" शुरू किया जाना चाहिए (इसलिए वर्तमान नोड पर SCADA का हिस्सा इस पर प्रतिक्रिया कर सकता है) और "अलार्म" के बारे में जानकारी अन्यत्र वितरित की जानी चाहिए (उदाहरण के लिए) : एक ऐतिहासिक डेटाबेस में संग्रहीत और / या SCADA ऑपरेटर के प्रदर्शन पर कल्पना)।
इस तर्क को इस तरह से पाठ रूप में व्यक्त किया जा सकता है:
optional(valid_raw_data) = validate(raw_data); if valid_raw_data is not empty then { converted_value = convert(valid_raw_data); do_async archive(converted_value); do_async distribute(converted_value); do_async { optional(suspicious_value) = check_range(converted_value); if suspicious_value is not empty then { optional(alarm) = detect_alarm(suspicious_value); if alarm is not empty then { do_async initiate_alarm(alarm); do_async distribute_alarm(alam); } } } }
या, चित्रमय रूप में:

यह एक कृत्रिम उदाहरण है, लेकिन इसमें कुछ दिलचस्प चीजें हैं जो मैं दिखाना चाहता हूं। पहला एक पाइप लाइन में समानांतर चरणों की उपस्थिति है (ऑपरेशन broadcast() बस उसी के कारण मौजूद है)। दूसरा कुछ अवस्थाओं में राज्य की उपस्थिति है। उदाहरण के लिए, अलार्म_डेटेटर स्टेटफुल स्टेज है।
पाइपलाइन की क्षमता
एक पाइपलाइन अलग-अलग चरणों से बनाई गई है। प्रत्येक चरण एक कार्य या निम्नलिखित प्रारूप का एक फ़नकार है:
opt<Out> func(const In &);
या
void func(const In &);
चरण जो void वापस करते हैं, उन्हें केवल एक पाइपलाइन के अंतिम चरण के रूप में इस्तेमाल किया जा सकता है।
चरण एक श्रृंखला में बंधे होते हैं। प्रत्येक अगले चरण में पिछले चरण द्वारा लौटाया गया ऑब्जेक्ट प्राप्त होता है। यदि पिछला चरण खाली हो जाता है opt<Out> मान फिर अगला चरण नहीं कहा जाता है।
एक विशेष broadcast चरण है। इसका निर्माण कई पाइपलाइनों से किया गया है। एक broadcast चरण पिछले चरण से एक वस्तु प्राप्त करता है और इसे प्रत्येक सहायक पाइपलाइन को प्रसारित करता है।
पाइपलाइन के दृष्टिकोण से, broadcast चरण निम्न प्रारूप के एक समारोह की तरह दिखता है:
void func(const In &);
क्योंकि broadcast चरण से कोई वापसी मूल्य नहीं है एक broadcast चरण केवल एक पाइपलाइन में अंतिम चरण हो सकता है।
पाइपलाइन चरण एक वैकल्पिक मान क्यों लौटाता है?
ऐसा इसलिए है क्योंकि कुछ आवक मूल्यों को छोड़ने की आवश्यकता है। उदाहरण के लिए, validate चरण एक कच्चा मान गलत होने पर कुछ भी नहीं लौटाता है, और इसे संभालने का कोई अर्थ नहीं है।
एक अन्य उदाहरण: alarm_detector चरण कुछ भी नहीं देता है यदि वर्तमान संदिग्ध मान एक नया अलार्म केस उत्पन्न नहीं करता है।
कार्यान्वयन का विवरण
आइए आवेदन तर्क से संबंधित डेटा प्रकारों और कार्यों से शुरू करें। चर्चा किए गए उदाहरण में, निम्न डेटा प्रकारों का उपयोग सूचनाओं को एक चरण से दूसरे चरण में भेजने के लिए किया जाता है:
हमारे पाइप लाइन के पहले चरण में raw_value का एक उदाहरण बन रहा है। इस raw_value में raw_measure ऑब्जेक्ट के रूप में एक सेंसर से प्राप्त जानकारी शामिल है। फिर raw_value में बदल valid_raw_value । तब valid_raw_value , calulated_measure के रूप में एक वास्तविक सेंसर के मूल्य के साथ valid_raw_value बदल गया। यदि sensor_value के sensor_value में एक संदिग्ध मान है, तो suspicious_value का एक उदाहरण उत्पन्न होता है। और उस suspicious_value alarm_detected बाद में alarm_detected उदाहरण में alarm_detected जा सकता है।
या, चित्रमय रूप में:

अब हम अपने पाइपलाइन चरणों के कार्यान्वयन पर एक नज़र डाल सकते हैं:
बस stage_result_t , make_result और make_empty जैसे सामान छोड़ें, हम अगले भाग में इसकी चर्चा करेंगे।
मुझे उम्मीद है कि उन चरणों के कोड बल्कि तुच्छ। एकमात्र भाग जिसे कुछ अतिरिक्त स्पष्टीकरण की आवश्यकता होती है, वह है alarm_detector चरण का कार्यान्वयन।
उस उदाहरण में, एक अलार्म केवल तभी शुरू किया जाता है जब 25ms टाइम विंडो में कम से कम दो संदिग्ध_वायु हों। इसलिए हमें alarm_detector स्टेज पर पिछले alarm_detector उदाहरण का समय याद रखना होगा। ऐसा इसलिए है क्योंकि alarm_detector एक फ़ंक्शन कॉल ऑपरेटर के साथ एक स्टेटफुल alarm_detector रूप में कार्यान्वित किया जाता है।
चरण :: std के बजाय SObjectizer का प्रकार लौटाते हैं :: वैकल्पिक
मैंने पहले कहा था कि मंच वैकल्पिक मूल्य लौटा सकता है। लेकिन std::optional का उपयोग कोड में नहीं किया जाता है, विभिन्न प्रकार के stage_result_t को चरणों के कार्यान्वयन में देखा जा सकता है।
ऐसा इसलिए है क्योंकि एसओबीजेलाइज़र के कुछ विशिष्ट यहां अपनी भूमिका निभाते हैं। लौटाए गए मानों को SObjectizer के एजेंटों (उर्फ अभिनेताओं) के बीच संदेशों के रूप में वितरित किया जाएगा। SObjectizer में प्रत्येक संदेश को गतिशील रूप से आवंटित ऑब्जेक्ट के रूप में भेजा जाता है। इसलिए हमारे यहां कुछ "अनुकूलन" हैं: std::optional की वापसी के बजाय std::optional और फिर एक नया संदेश ऑब्जेक्ट आवंटित करना, हम बस एक संदेश ऑब्जेक्ट आवंटित करते हैं और इसे एक स्मार्ट पॉइंटर लौटाते हैं।
वास्तव में, stage_result_t , एसओबीजेलाइज़र के साझा किए गए एनालॉग के लिए केवल एक stage_result_t है:
template< typename M > using stage_result_t = message_holder_t< M >;
और make_result और make_empty stage_result_t साथ या वास्तविक मूल्य के बिना निर्माण के लिए सिर्फ सहायक कार्य हैं:
template< typename M, typename... Args > stage_result_t< M > make_result( Args &&... args ) { return stage_result_t< M >::make(forward< Args >(args)...); } template< typename M > stage_result_t< M > make_empty() { return stage_result_t< M >(); }
सादगी के लिए यह कहना सुरक्षित है कि validation चरण इस तरह व्यक्त किया जा सकता है:
std::shared_ptr< valid_raw_value > validation( const raw_value & v ) { if( 0x7 >= v.m_data.m_high_bits ) return std::make_shared< valid_raw_value >( v.m_data ); else return std::shared_ptr< valid_raw_value >{}; }
लेकिन, SObjectizer के विशिष्ट होने के कारण, हम std::shared_ptr share_ptr का उपयोग नहीं कर सकते हैं और so_5::message_holder_t प्रकार से so_5::message_holder_t । और हम उस विशिष्ट को stage_result_t पीछे stage_result_t , make_result और make_empty ।
stage_handler_t और stage_builder_t जुदाई
पाइपलाइन कार्यान्वयन का एक महत्वपूर्ण बिंदु स्टेज हैंडलर और स्टेज बिल्डर अवधारणाओं का पृथक्करण है। यह सरलता के लिए किया जाता है। इन अवधारणाओं की उपस्थिति ने मुझे पाइपलाइन की परिभाषा में दो कदम रखने की अनुमति दी।
पहले चरण में, एक उपयोगकर्ता पाइपलाइन चरणों का वर्णन करता है। नतीजतन, मुझे stage_t का एक उदाहरण मिलता है जो सभी पाइपलाइन चरणों को अंदर रखता है।
दूसरे चरण में, अंतर्निहित SObjectizer के एजेंटों का एक सेट बनाया गया है। वे एजेंट पिछले चरणों के परिणामों के साथ संदेश प्राप्त करते हैं और वास्तविक चरण संचालकों को कॉल करते हैं, फिर परिणामों को अगले चरणों में भेजते हैं।
लेकिन एजेंटों के इस सेट को बनाने के लिए हर चरण में एक स्टेज बिल्डर होना चाहिए । स्टेज बिल्डर को एक कारखाने के रूप में देखा जा सकता है जो एक अंतर्निहित SObjectizer एजेंट बनाता है।
इसलिए हमारा निम्नलिखित संबंध है: प्रत्येक पाइपलाइन चरण दो ऑब्जेक्ट्स का निर्माण करता है: स्टेज हैंडलर जो स्टेज से संबंधित तर्क रखता है, और स्टेज बिल्डर जो उचित समय पर स्टेज हैंडलर को कॉल करने के लिए एक अंतर्निहित SObjectizer का एजेंट बनाता है:

स्टेज हैंडलर निम्नलिखित तरीके से दर्शाया गया है:
template< typename In, typename Out > class stage_handler_t { public : using traits = handler_traits_t< In, Out >; using func_type = function< typename traits::output(const typename traits::input &) >; stage_handler_t( func_type handler ) : m_handler( move(handler) ) {} template< typename Callable > stage_handler_t( Callable handler ) : m_handler( handler ) {} typename traits::output operator()( const typename traits::input & a ) const { return m_handler( a ); } private : func_type m_handler; };
जहाँ handler_traits_t को निम्न तरीके से परिभाषित किया गया है:
स्टेज बिल्डर को सिर्फ std::function द्वारा दर्शाया जाता std::function :
using stage_builder_t = function< mbox_t(coop_t &, mbox_t) >;
सहायक प्रकार lambda_traits_t और callable_traits_t
क्योंकि चरणों को नि: शुल्क फ़ंक्शन या alarm_detector द्वारा दर्शाया जा सकता है (जैसे कि alarm_detector क्लास के उदाहरण या अनाम कंपाइलर-जनरेट किए गए वर्ग जो लैम्ब्डा का प्रतिनिधित्व करते हैं), हमें चरण के तर्क और रिटर्न वैल्यू के प्रकारों का पता लगाने के लिए कुछ सहायकों की आवश्यकता है। मैंने उस उद्देश्य के लिए निम्नलिखित कोड का उपयोग किया:
मुझे उम्मीद है कि यह कोड C ++ के अच्छे ज्ञान वाले पाठकों के लिए काफी समझ में आएगा। यदि नहीं, तो बेझिझक मुझे टिप्पणियों में पूछें, मुझे विवरण में lambda_traits_t और callable_traits_t पीछे के तर्क की व्याख्या करने में खुशी होगी।
चरण (), प्रसारण () और ऑपरेटर | () फ़ंक्शन
अब हम मुख्य पाइपलाइन-निर्माण कार्यों के अंदर देख सकते हैं। लेकिन इससे पहले, एक खाका वर्ग के स्तर की परिभाषा पर एक नज़र stage_t :
template< typename In, typename Out > struct stage_t { stage_builder_t m_builder; };
यह एक बहुत ही सरल संरचना है, जो कि केवल stage_bulder_t उदाहरण प्रस्तुत करती है। टेम्पलेट पैरामीटर stage_t अंदर उपयोग नहीं किए stage_t , इसलिए वे यहां क्यों मौजूद हैं?
वे पाइपलाइन चरणों के बीच संगतता के संकलन-समय की जाँच के लिए आवश्यक हैं। हम जल्द ही देखेंगे।
आइए सरलतम पाइपलाइन-निर्माण कार्य को देखें, stage() :
template< typename Callable, typename In = typename callable_traits_t< Callable >::arg_type, typename Out = typename callable_traits_t< Callable >::result_type > stage_t< In, Out > stage( Callable handler ) { stage_builder_t builder{ [h = std::move(handler)]( coop_t & coop, mbox_t next_stage) -> mbox_t { return coop.make_agent< a_stage_point_t<In, Out> >( std::move(h), std::move(next_stage) ) ->so_direct_mbox(); } }; return { std::move(builder) }; }
यह एक एकल पैरामीटर के रूप में एक वास्तविक चरण हैंडलर प्राप्त करता है। यह एक फंक्शन या लैम्ब्डा-फंक्शन या फन्क्टर का पॉइंटर हो सकता है। callable_traits_t टेम्पलेट के पीछे "टेम्पलेट मैजिक" के कारण चरण के इनपुट और आउटपुट स्वचालित रूप से कट जाते हैं।
स्टेज बिल्डर का एक उदाहरण अंदर बनाया गया है और उस stage() के परिणाम के रूप में एक नया stage_t ऑब्जेक्ट में वापस आ गया है। एक वास्तविक स्टेज हैंडलर को स्टेज बिल्डर लैम्ब्डा द्वारा कैप्चर किया जाता है, इसका उपयोग तब अंतर्निहित SObjectizer के एजेंट के निर्माण के लिए किया जाएगा (हम अगले भाग में इसके बारे में बोलेंगे)।
समीक्षा करने के लिए अगला कार्य operator|() जो दो चरणों को एक साथ जोड़ता है और एक नया चरण लौटाता है:
template< typename In, typename Out1, typename Out2 > stage_t< In, Out2 > operator|( stage_t< In, Out1 > && prev, stage_t< Out1, Out2 > && next ) { return { stage_builder_t{ [prev, next]( coop_t & coop, mbox_t next_stage ) -> mbox_t { auto m = next.m_builder( coop, std::move(next_stage) ); return prev.m_builder( coop, std::move(m) ); } } }; }
operator|() का तर्क समझाने का सबसे सरल तरीका operator|() एक चित्र बनाने की कोशिश करना है। मान लेते हैं कि हमारे पास अभिव्यक्ति है:
stage(A) | stage(B) | stage(C) | stage(B)
यह अभिव्यक्ति इस तरह से बदल जाएगी:

वहां हम यह भी देख सकते हैं कि कंपाइल-टाइम टाइप-चेकिंग कैसे काम कर रही है: operator|() की परिभाषा operator|() आवश्यकता है कि पहले चरण का आउटपुट प्रकार दूसरे चरण का इनपुट है। यदि ऐसा नहीं है तो कोड संकलित नहीं किया जाएगा।
और अब हम सबसे जटिल पाइपलाइन-बिल्डिंग फ़ंक्शन, broadcast() पर एक नज़र डाल सकते हैं। समारोह ही सरल है:
template< typename In, typename Out, typename... Rest > stage_t< In, void > broadcast( stage_t< In, Out > && first, Rest &&... stages ) { stage_builder_t builder{ [broadcasts = collect_sink_builders( move(first), forward< Rest >(stages)...)] ( coop_t & coop, mbox_t ) -> mbox_t { vector< mbox_t > mboxes; mboxes.reserve( broadcasts.size() ); for( const auto & b : broadcasts ) mboxes.emplace_back( b( coop, mbox_t{} ) ); return broadcast_mbox_t::make( coop.environment(), std::move(mboxes) ); } }; return { std::move(builder) }; }
एक साधारण चरण और प्रसारण-मंच के बीच मुख्य अंतर यह है कि प्रसारण-चरण में सहायक चरण बिल्डरों का वेक्टर पकड़ना होता है। इसलिए हमें उस वेक्टर को बनाना होगा और इसे ब्रॉडकास्ट-स्टेज के मुख्य स्टेज बिल्डर में डालना होगा। उसकी वजह से, हम broadcast() अंदर एक collect_sink_builders की कैप्चर सूची में collect_sink_builders कॉल को देख सकते हैं:
stage_builder_t builder{ [broadcasts = collect_sink_builders( move(first), forward< Rest >(stages)...)]
यदि हम collect_sink_builder में देखते हैं, तो हम निम्नलिखित कोड देखेंगे:
कंपाइल-टाइम टाइप-चेकिंग यहाँ भी काम करती है: यह इसलिए है क्योंकि 'in' टाइप करके स्पष्ट रूप से पैरामीटर किए जाने वाले move_sink_builder_to को कॉल किया जाता है। इसका मतलब है कि फॉर्म में एक कॉल collect_sink_builders(stage_t<In1, Out1>, stage_t<In2, Out2>, ...) संकलन त्रुटि का कारण move_sink_builder_to<In1>(receiver, stage_t<In2, Out2>, ...) क्योंकि कंपाइलर move_sink_builder_to<In1>(receiver, stage_t<In2, Out2>, ...) ।
मैं यह भी नोट कर सकता हूं कि क्योंकि broadcast() लिए सहायक पाइपलाइनों की गिनती broadcast() संकलन-समय पर ज्ञात है, हम std::vector बजाय std::array उपयोग कर सकते हैं और कुछ मेमोरी आवंटन से बच सकते हैं। लेकिन std::vector का उपयोग यहाँ केवल सादगी के लिए किया जाता है।
चरणों और SObjectizer के एजेंटों / mboxes के बीच संबंध
पाइपलाइन के कार्यान्वयन के पीछे का विचार हर पाइपलाइन चरण के लिए एक अलग एजेंट का निर्माण है। एक एजेंट एक इनकमिंग संदेश प्राप्त करता है, उसे संबंधित चरण हैंडलर को भेजता है, परिणाम का विश्लेषण करता है और, यदि परिणाम खाली नहीं है, तो परिणाम को अगले चरण में आने वाले संदेश के रूप में भेजता है। यह निम्नलिखित अनुक्रम आरेख द्वारा चित्रित किया जा सकता है:

कुछ SObjectizer से संबंधित चीजों पर चर्चा की जानी है, कम से कम संक्षेप में। यदि आपको ऐसे विवरणों में कोई दिलचस्पी नहीं है, तो आप नीचे दिए गए अनुभागों को छोड़ सकते हैं और सीधे निष्कर्ष पर जा सकते हैं।
कूपर एक साथ काम करने के लिए एजेंटों का एक समूह है
एजेंटों को व्यक्तिगत रूप से नहीं बल्कि कॉप्स नाम के समूहों में एसोबिजाइज़र में पेश किया जाता है। कॉप एजेंटों का एक समूह है जिसे एक साथ काम करना चाहिए और समूह के किसी एक एजेंट के गायब होने पर काम जारी रखने का कोई मतलब नहीं है।
अतः SObjectizer में एजेंटों का परिचय, कॉप उदाहरण के निर्माण की तरह दिखता है, उस उदाहरण को उपयुक्त एजेंटों के साथ भरना और फिर कॉप को SObjectizer में पंजीकृत करना।
उसके कारण एक स्टेज बिल्डर के लिए पहला तर्क एक नए कॉप का संदर्भ है। यह कॉप make_pipeline() फ़ंक्शन (नीचे चर्चा की गई) में बनाया गया है, फिर यह स्टेज बिल्डरों द्वारा पॉपुलेटेड है और फिर पंजीकृत (फिर से make_pipeline() फ़ंक्शन) में बनाया गया है।
संदेश बॉक्स
SObjectizer कई संगामिति-संबंधित मॉडल लागू करता है। अभिनेता मॉडल उनमें से सिर्फ एक है। उस वजह से, एसोबिजाइज़र अन्य अभिनेता फ्रेमवर्क से काफी भिन्न हो सकता है। एक अंतर संदेशों के लिए संबोधन योजना है।
SObjectizer में संदेश अभिनेताओं को नहीं बल्कि संदेश बॉक्स (mboxes) को संबोधित किया जाता है। अभिनेताओं को एक mbox से संदेशों की सदस्यता लेनी होती है। यदि कोई अभिनेता किसी विशेष संदेश प्रकार से mbox से सदस्यता लेता है, तो उसे उस प्रकार के संदेश प्राप्त होंगे:
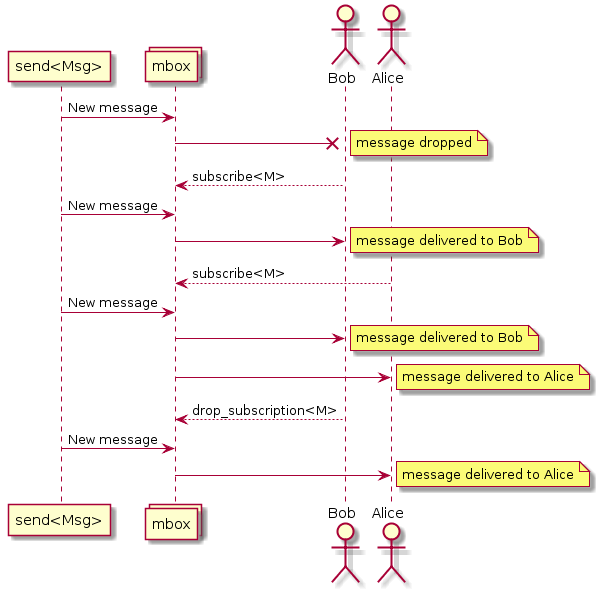
यह तथ्य महत्वपूर्ण है क्योंकि एक चरण से दूसरे चरण में संदेश भेजना आवश्यक है। इसका मतलब है कि हर चरण में उसका बॉक्स होना चाहिए और उस बॉक्स को पिछले चरण के लिए जाना जाना चाहिए।
SObjectizer में प्रत्येक अभिनेता (उर्फ एजेंट) का प्रत्यक्ष बॉक्स है। यह एमबॉक्स केवल मालिक एजेंट के साथ जुड़ा हुआ है और किसी अन्य एजेंट द्वारा उपयोग नहीं किया जा सकता है। चरणों के लिए बनाए गए एजेंटों के प्रत्यक्ष बॉक्स का उपयोग चरणों की बातचीत के लिए किया जाएगा।
यह SObjectizer की विशिष्ट विशेषता कुछ पाइपलाइन-कार्यान्वयन विवरणों को निर्धारित करती है।
पहला तथ्य यह है कि स्टेज बिल्डर में निम्नलिखित प्रोटोटाइप है:
mbox_t builder(coop_t &, mbox_t);
इसका मतलब है कि स्टेज बिल्डर को अगले चरण का एक बॉक्स प्राप्त होता है और उसे एक नया एजेंट बनाना चाहिए जो उस बॉक्स में स्टेज के परिणाम भेजेगा। नए एजेंट का एक बॉक्स स्टेज बिल्डर द्वारा लौटाया जाना चाहिए। उस mbox का उपयोग पिछले चरण के लिए एक एजेंट के निर्माण के लिए किया जाएगा।
दूसरा तथ्य यह है कि चरणों के लिए एजेंट आरक्षित क्रम में बनाए जाते हैं। इसका मतलब है कि अगर हमारे पास पाइपलाइन है:
stage(A) | stage(B) | stage(C)
स्टेज सी के लिए एक एजेंट पहले बनाया जाएगा, फिर इसके एमबॉक्स का उपयोग स्टेज बी के लिए एजेंट के निर्माण के लिए किया जाएगा, और फिर स्टेज ए के लिए एजेंट के निर्माण के लिए बी-स्टेज एजेंट के एमबॉक्स का उपयोग किया जाएगा।
यह भी ध्यान देने योग्य है कि operator|() एजेंट नहीं बनाता है:
stage_builder_t{ [prev, next]( coop_t & coop, mbox_t next_stage ) -> mbox_t { auto m = next.m_builder( coop, std::move(next_stage) ); return prev.m_builder( coop, std::move(m) ); } }
operator|() एक बिल्डर बनाता है जो केवल अन्य बिल्डरों को कॉल करता है लेकिन अतिरिक्त एजेंटों का परिचय नहीं देता है। तो मामले के लिए:
stage(A) | stage(B)
केवल दो एजेंट बनाए जाएंगे (ए-स्टेज और बी-स्टेज के लिए) और फिर उन्हें operator|() द्वारा बनाए गए स्टेज बिल्ड में एक साथ जोड़ा जाएगा। operator|()
broadcast() कार्यान्वयन के लिए कोई एजेंट नहीं है
प्रसारण चरण को लागू करने का एक स्पष्ट तरीका एक विशेष एजेंट बनाना है जो आने वाले संदेश प्राप्त करेगा और फिर उस संदेश को गंतव्य mboxes की सूची में फिर से भेज देगा। इस तरह का उपयोग वर्णित पाइपलाइन डीएसएल के पहले कार्यान्वयन में किया गया था ।
लेकिन हमारा साथी प्रोजेक्ट, so5extra , अब mbox का एक विशेष संस्करण है: एक प्रसारण। वह एमबॉक्स ठीक वही करता है जो यहां आवश्यक है: यह एक नया संदेश लेता है और इसे डेस्टिनेशन बॉक्स के सेट तक पहुंचाता है।
इसकी वजह से अलग प्रसारण एजेंट बनाने की कोई आवश्यकता नहीं है, हम सिर्फ so5extra से प्रसारण mbox का उपयोग कर सकते हैं:
स्टेज-एजेंट का कार्यान्वयन
अब हम स्टेज एजेंट के कार्यान्वयन पर एक नज़र डाल सकते हैं:
यदि आप SObjectizer की मूल बातें समझते हैं तो यह बहुत तुच्छ है। यदि नहीं तो कुछ शब्दों में समझाना काफी कठिन होगा (इसलिए बेझिझक टिप्पणी में सवाल पूछ सकते हैं)।
a_stage_point_t एजेंट का मुख्य कार्यान्वयन प्रकार के संदेश के लिए एक सदस्यता बनाता है। जब इस प्रकार का संदेश आता है तो स्टेज हैंडलर कहलाता है। यदि स्टेज हैंडलर वास्तविक परिणाम देता है, तो परिणाम अगले चरण में भेजा जाता है (यदि वह चरण मौजूद है)।
मामले के लिए a_stage_point_t का एक संस्करण भी है जब संबंधित चरण टर्मिनल चरण है और अगला चरण नहीं हो सकता है।
a_stage_point_t का कार्यान्वयन थोड़ा जटिल लग सकता है, लेकिन मेरा विश्वास करो, यह मेरे द्वारा लिखे गए सबसे सरल एजेंटों में से एक है।
make_pipeline () फ़ंक्शन
यह अंतिम पाइपलाइन-निर्माण कार्य, make_pipeline() पर चर्चा करने का समय है:
template< typename In, typename Out, typename... Args > mbox_t make_pipeline(
यहां न कोई जादू है और न ही कोई आश्चर्य। हमें पाइपलाइन के अंतर्निहित एजेंटों के लिए एक नया कॉप बनाने की आवश्यकता है, उस कॉप को एजेंटों के साथ एक शीर्ष-स्तरीय स्टेज बिल्डर को कॉल करके भरें, और फिर उस कॉप को सोबिजाइज़र में पंजीकृत करें। वह सब।
make_pipeline() का परिणाम पाइप लाइन के बाएं-सबसे (पहले) चरण का make_pipeline() । उस mbox का उपयोग पाइपलाइन को संदेश भेजने के लिए किया जाना चाहिए।
सिमुलेशन और इसके साथ प्रयोग
तो अब हमारे पास हमारे एप्लिकेशन लॉजिक के लिए डेटा प्रकार और फ़ंक्शंस हैं और उन फ़ंक्शंस को डेटा-प्रोसेसिंग पाइपलाइन में चलाने के लिए उपकरण हैं। चलो इसे करते हैं और एक परिणाम देखते हैं:
int main() {
यदि हम उस उदाहरण को चलाते हैं तो हम निम्नलिखित आउटपुट देखेंगे:
archiving (0,0) distributing (0,0) archiving (0,5) distributing (0,5) archiving (0,10) distributing (0,10) archiving (0,15) distributing (0,15) archiving (0,20) distributing (0,20) archiving (0,25) distributing (0,25) archiving (0,30) distributing (0,30) ... archiving (0,105) distributing (0,105) archiving (0,110) distributing (0,110) === alarm (0) === alarm_distribution (0) archiving (0,115) distributing (0,115) archiving (0,120) distributing (0,120) === alarm (0) === alarm_distribution (0)
यह काम करता है।
लेकिन ऐसा लगता है कि हमारी पाइपलाइन के चरण क्रमिक रूप से काम करते हैं, एक के बाद एक, है न?
हाँ, यह है। ऐसा इसलिए है क्योंकि सभी पाइपलाइन एजेंट डिफ़ॉल्ट SObjectizer के डिस्पैचर से बंधे हैं। और वह डिस्पैचर सभी एजेंटों के संदेश प्रसंस्करण की सेवा के लिए सिर्फ एक श्रमिक धागे का उपयोग करता है।
लेकिन इसे आसानी से बदला जा सकता है। बस make_pipeline() कॉल के लिए एक अतिरिक्त तर्क पास करें:
यह एक नया थ्रेड पूल बनाता है और उस पूल में सभी पाइपलाइन एजेंटों को बांधता है। प्रत्येक एजेंट को अन्य एजेंटों से स्वतंत्र रूप से पूल द्वारा सेवा दी जाएगी।
यदि हम संशोधित उदाहरण चलाते हैं तो हम कुछ ऐसा देख सकते हैं:
archiving (0,0) distributing (0,0) distributing (0,5) archiving (0,5) archiving (0,10) distributing (0,10) distributing (archiving (0,15) 0,15) archiving (0,20) distributing (0,20) archiving (0,25) distributing (0,25) archiving (0,distributing (030) ,30) ... archiving (0,distributing (0,105) 105) archiving (0,alarm_distribution (0) distributing (0,=== alarm (0) === 110) 110) archiving (distributing (0,0,115) 115) archiving (distributing (=== alarm (0) === 0alarm_distribution (0) 0,120) ,120)
इसलिए हम देख सकते हैं कि पाइपलाइन के विभिन्न चरण समानांतर में काम करते हैं।
लेकिन क्या आगे जाकर विभिन्न डिस्पैचरों में चरणों को बांधने की क्षमता है?
हां, यह संभव है, लेकिन हमें stage() फ़ंक्शन के लिए एक और अधिभार लागू करना होगा:
template< typename Callable, typename In = typename callable_traits_t< Callable >::arg_type, typename Out = typename callable_traits_t< Callable >::result_type > stage_t< In, Out > stage( disp_binder_shptr_t disp_binder, Callable handler ) { stage_builder_t builder{ [binder = std::move(disp_binder), h = std::move(handler)]( coop_t & coop, mbox_t next_stage) -> mbox_t { return coop.make_agent_with_binder< a_stage_point_t<In, Out> >( std::move(binder), std::move(h), std::move(next_stage) ) ->so_direct_mbox(); } }; return { std::move(builder) }; }
This version of stage() accepts not only a stage handler but also a dispatcher binder. Dispatcher binder is a way to bind an agent to the particular dispatcher. So to assign a stage to a specific working context we can create an appropriate dispatcher and then pass the binder to that dispatcher to stage() function. Let's do that:
In that case stages archiving , distribution , alarm_initiator and alarm_distribution will work on own worker threads. All other stages will work on the same single worker thread.
The conclusion
This was an interesting experiment and I was surprised how easy SObjectizer could be used in something like reactive programming or data-flow programming.
However, I don't think that pipeline DSL can be practically meaningful. It's too simple and, maybe not flexible enough. But, I hope, it can be a base for more interesting experiments for those why need to deal with different workflows and data-processing pipelines. At least as a base for some ideas in that area. C++ language a rather good here and some (not so complicated) template magic can help to catch various errors at compile-time.
In conclusion, I want to say that we see SObjectizer not as a specialized tool for solving a particular problem, but as a basic set of tools to be used in solutions for different problems. And, more importantly, that basic set can be extended for your needs. Just take a look at SObjectizer , try it, and share your feedback. Maybe you missed something in SObjectizer? Perhaps you don't like something? Tell us , and we can try to help you.
If you want to help further development of SObjectizer, please share a reference to it or to this article somewhere you want (Reddit, HackerNews, LinkedIn, Facebook, Twitter, ...). The more attention and the more feedback, the more new features will be incorporated into SObjectizer.
And many thanks for reading this ;)
पुनश्च। The source code for that example can be found in that repository .