इतना समय पहले नहीं, मुझे हमारी कंपनी के लिए एक नए बीआई-सिस्टम पर स्विच करने के कार्य के साथ सामना करना पड़ा था। चूंकि मुझे इस मुद्दे पर गहराई से और पूरी तरह से गोता लगाना था, इसलिए मैंने सम्मानित समुदाय के साथ इस पर अपने विचार साझा करने का फैसला किया।

इंटरनेट पर इस विषय पर कई लेख हैं, लेकिन, मेरे महान आश्चर्य के लिए, उन्होंने सही उपकरण चुनने के बारे में मेरे कई सवालों के जवाब नहीं दिए और कुछ हद तक सतही थे। परीक्षण के 3 सप्ताह के भीतर, हमने 4 टूल का परीक्षण किया:
झांकी, लुक, पेरिस्कोप / सीसेन, मोड एनालिटिक्स । इन उपकरणों पर मुख्य रूप से इस लेख में चर्चा की जाएगी। मुझे तुरंत कहना होगा कि प्रस्तावित लेख लेखक की निजी राय है, जो एक छोटी लेकिन बहुत तेजी से बढ़ती आईटी कंपनी की जरूरतों को दर्शाती है :)
बाजार के बारे में कुछ शब्द
अब, बीआई बाजार में काफी दिलचस्प बदलाव हो रहे हैं, समेकन चल रहा है, बड़े क्लाउड प्रौद्योगिकी खिलाड़ी डेटा (डेटा स्टोरेज, प्रोसेसिंग, विज़ुअलाइज़ेशन) के साथ काम करने के सभी पहलुओं को खड़ी करके अपनी स्थिति को मजबूत करने की कोशिश कर रहे हैं। पिछले कुछ महीनों में, 5 प्रमुख अधिग्रहण हुए हैं: Google ने लुकर खरीदा, सेल्सफोर्स ने झांकी खरीदी, सिसेन्स ने पेरिस्कोप डेटा खरीदा, लोगी एनालिटिक्स ने ज़ूमडाटा खरीदा, एलर्टेक्स ने क्लियरस्टोरी डेटा खरीदा। हम विलय और अधिग्रहण के कॉर्पोरेट जगत में आगे गोता नहीं लगाएंगे, यह ध्यान देने योग्य है कि
बीआई उपकरण के नए मालिकों के मूल्य निर्धारण और संरक्षणवादी नीतियों दोनों में और बदलाव की उम्मीद की जा सकती है (जैसा कि हाल ही में Google द्वारा खरीदे जाने के कुछ समय बाद ही एलोमा टूल ने हमें खुश कर दिया था) Google BigQuery :) को छोड़कर सभी डेटा स्रोतों का समर्थन करना बंद करें)।
सिद्धांत की बिट
इसलिए, मैं एक छोटे से सैद्धांतिक भाग के साथ शुरुआत करना चाहता था, क्योंकि अब सिद्धांत के बिना कहाँ। जैसा कि गार्टनर हमें बताता है, एक बीआई प्रणाली एक शब्द है जो सॉफ्टवेयर उत्पादों, उपकरणों, बुनियादी ढांचे और सर्वोत्तम प्रथाओं को जोड़ती है, जो हमें निर्णयों को सुधारने और अनुकूलित करने की अनुमति देती है [1]। इस परिभाषा में डेटा स्टोरेज और ईटीएल भी शामिल है। इस अनुच्छेद में, मैं डेटा दृश्य और विश्लेषण के लिए एक संकीर्ण खंड, अर्थात्, सॉफ्टवेयर उत्पादों पर ध्यान केंद्रित करने का प्रस्ताव करता हूं।
कंपनी के लिए मूल्य बनाने के पिरामिड में (मुझे अंजीर 0 में इस स्पष्ट संरचना की एक और प्रस्तुति का प्रस्ताव करने का साहस था), बीआई उपकरण रिकॉर्ड और प्रारंभिक डेटा प्रसंस्करण (ईटीएल) के भंडारण के लिए ब्लॉक के बाद स्थित हैं।
यह समझना महत्वपूर्ण है -
इस मामले में सबसे अच्छा अभ्यास ईटीएल और बीआई कार्यों का अलगाव है । डेटा के साथ काम करने की एक अधिक पारदर्शी प्रक्रिया के अलावा, आप एक सॉफ़्टवेयर समाधान से भी बंधे नहीं होंगे और प्रत्येक ETL और BI कार्यों के लिए सबसे उपयुक्त उपकरण चुनने में सक्षम होंगे। एक अच्छी तरह से संरचित ETL प्रक्रिया और डेटा टेबल्स की एक इष्टतम वास्तुकला के साथ, आप आम तौर पर विशेष सॉफ्टवेयर का उपयोग किए बिना सभी व्यावसायिक मुद्दों के 80% को बंद कर सकते हैं। यह निश्चित रूप से, विश्लेषकों और डीएस की महत्वपूर्ण भागीदारी की आवश्यकता होगी। इसलिए, हम मुख्य प्रश्न पर आते हैं: हमें वास्तव में बीआई सॉफ्टवेयर उत्पाद से सबसे पहले क्या चाहिए?
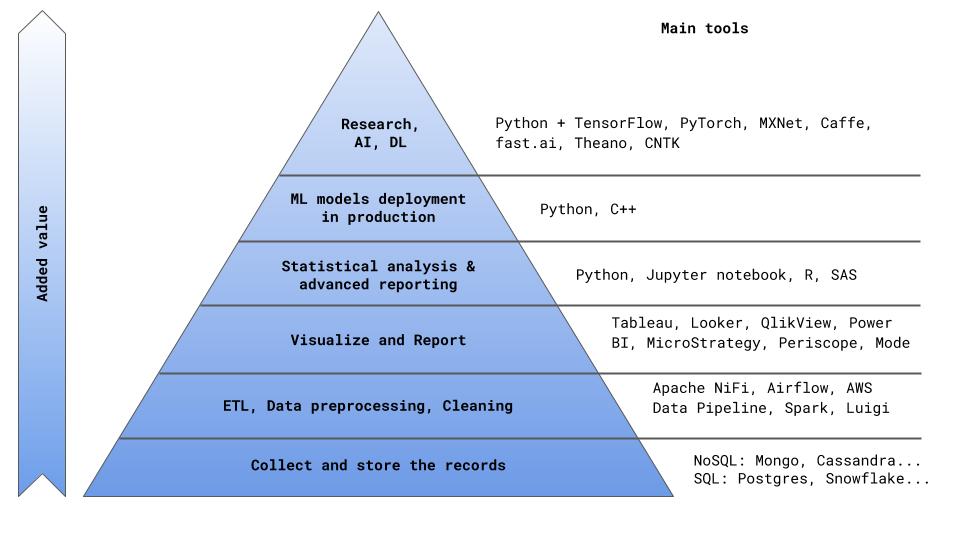
अंजीर। 0
एक बीआई सॉफ्टवेयर उत्पाद चुनने के लिए मुख्य मानदंड
जैसा कि हम पहले ही समझ चुके हैं, एक पूरे के रूप में कंपनी के सभी प्रमुख मैट्रिक्स और प्रदर्शन संकेतक ईटीएल प्रक्रिया के हिस्से के रूप में पहले से तैयार किए गए डेटाबेस में विश्लेषणात्मक तालिकाओं से सीधे लिए जा सकते हैं (मैं आपको अगले लेख में बताऊंगा कि ईटीएल प्रक्रिया को कैसे बेहतर बनाया जाए। इस बीच, मैं एक टीज़र दूंगा कि यह इतना महत्वपूर्ण क्यों है: कागल पोल के अनुसार, मुख्य कठिनाई यह है कि डीएस का आधा गंदा डेटा है [2])। इस मामले में मुख्य समस्या, जाहिर है, विश्लेषकों के समय का उपयोग करने की जटिलता और अक्षमता होगी। पूर्ण-विकसित उत्पाद बनाने के बजाय, विश्लेषक / डीएस हर समय संकेतक तैयार करेंगे, मैट्रिक्स की गणना करेंगे, संख्याओं में विसंगतियों की जांच करेंगे, SQL कोड में त्रुटियों की तलाश करेंगे और अन्य अनैतिक गतिविधियां करेंगे। यहां मुझे विश्वास है कि विश्लेषकों / डीएस को मुख्य बात यह है कि एक ऐसा उत्पाद बनाना चाहिए जो लंबे समय में कंपनी के लिए मूल्य लाए। यह या तो एक निपटान / भविष्य कहनेवाला सेवा हो सकती है, जिसका परिणाम कंपनी के मुख्य उत्पाद (उदाहरण के लिए, एक यात्रा की लागत / समय की गणना के लिए एक एल्गोरिथ्म) का हिस्सा है या, कहें, ग्राहकों के बीच आदेशों को वितरित करने के लिए एक एल्गोरिथ्म, या एक पूर्ण-विश्लेषणात्मक विश्लेषण रिपोर्ट है जो उपयोगकर्ताओं के बहिर्वाह के कारणों और MAU में कमी की पहचान करती है। ।
इसलिए, एक विश्लेषणात्मक प्रणाली को चुनने का मुख्य मानदंड
विश्लेषकों को तदर्थ समस्याओं और तरलता से जितना संभव हो उतराई करने की
क्षमता होनी चाहिए
। यह कैसे प्राप्त किया जा सकता है? वास्तव में, दो विकल्प हैं: ए) स्वचालित, बी) प्रतिनिधि। दूसरे पैराग्राफ से मेरा मतलब है कि अब लोकप्रिय वाक्यांश
सेल्फ सर्विस - व्यवसायों को डेटा में खुद को प्रस्तुत करने का अवसर देना।
यही है, विश्लेषकों ने एक बार एक सॉफ़्टवेयर उत्पाद सेट किया है: डेटा क्यूब्स बनाएं, क्यूब्स के स्वचालित अपडेट को सेट करें (उदाहरण के लिए, हर रात), स्वचालित रूप से रिपोर्ट भेजें, कई डैशबोर्ड विज़ार्ड तैयार करें और उपयोगकर्ताओं को उत्पाद का उपयोग करने का तरीका सिखाएं। इसके अलावा, व्यवसाय विभिन्न डेटा एकत्रीकरण और सरल और समझने योग्य
ड्रैग एंड ड्रॉप विकल्प का उपयोग करके फ़िल्टर करने के लिए आवश्यक संकेतकों की गणना करके, अपनी अतिरिक्त आवश्यकताओं को स्वतंत्र रूप से प्रदान करता है।
रिपोर्टिंग प्रक्रिया की सादगी के अलावा,
क्वेरी निष्पादन गति भी महत्वपूर्ण है । किसी दूसरे शहर के लिए डेटा या मैट्रिक्स लोड करने के लिए पिछले महीने के लिए कोई भी 15 मिनट इंतजार नहीं करेगा। इस समस्या को हल करने के लिए, कई आम तौर पर स्वीकृत दृष्टिकोण हैं। उनमें से एक
OLAP (ऑनलाइन विश्लेषणात्मक प्रसंस्करण) डेटा क्यूब्स का निर्माण है। OLAP क्यूब्स में, डेटा प्रकारों को आयामों (आयामों) में विभाजित किया जाता है - ये ऐसे क्षेत्र हैं जिनके द्वारा एकत्रीकरण किया जा सकता है (उदाहरण के लिए, शहर, देश, उत्पाद, समय अंतराल, भुगतान प्रकार ...), और माप के लिए माप की गणना की जाती है। (उदा। यात्राओं की संख्या, राजस्व, नए उपयोगकर्ताओं की संख्या, औसत जांच, ...)। डेटा क्यूब्स एक अधिक शक्तिशाली उपकरण है जो आपको पूर्व-एकत्रित डेटा और गणना की गई मीट्रिक का उपयोग करके बहुत तेज़ी से परिणाम देने की अनुमति देता है। OLAP क्यूब्स का फ्लिप पक्ष तथ्य यह है कि सभी डेटा पूर्व-एकत्र किए गए हैं और अगले क्यूब के निर्माण तक नहीं बदलते हैं। यदि आपको डेटा एकत्रीकरण या एक मीट्रिक की आवश्यकता है जो मूल रूप से गणना नहीं की गई थी, या यदि आपको अधिक हाल के डेटा की आवश्यकता है, तो आपको डेटा क्यूब को
फिर से
बनाने की आवश्यकता है।
डेटा के साथ काम करने की गति को बढ़ाने के लिए एक अन्य समाधान
इन-मेमोरी समाधान है । मेमोरी डेटाबेस (IMDB) में अधिकतम प्रदर्शन प्रदान करने के लिए डिज़ाइन किया गया है जब डेटा को स्टोर करने के लिए पर्याप्त रैम है। जबकि संबंधपरक डेटाबेस को अधिकतम प्रदर्शन प्रदान करने के लिए डिज़ाइन किया गया है जब डेटा पूरी तरह से रैम में नहीं रखा जाता है, और धीमी डिस्क I / O को वास्तविक समय में प्रदर्शन किया जाना चाहिए। कई आधुनिक उपकरण इन दोनों समाधानों को जोड़ते हैं (उदाहरण के लिए, सीसेन, झांकी, आईबीएम कॉग्नोस, माइक्रोस्ट्रैटी, आदि)।
इससे पहले, हमने व्यावसायिक उपयोगकर्ताओं के लिए बीआई उपकरण का उपयोग करने की सरलता और सुविधा के बारे में बात की थी। विश्लेषकों / डीएस के लिए एक
सुविधाजनक डैशबोर्ड विकास और रिलीज प्रक्रिया स्थापित करना महत्वपूर्ण है। यहां स्थिति किसी भी अन्य आईटी उत्पाद के समान है - आपको एक त्वरित और सुविधाजनक तैनाती प्रक्रिया (
रैपिड तैनाती समय ) की आवश्यकता है, साथ ही साथ विचारशील विकास प्रक्रिया, परीक्षण, कोड समीक्षा, रिलीज, संस्करण नियंत्रण, टीम सहयोग। यह सब वर्कफ़्लो की अवधारणा द्वारा संयुक्त है।
इस प्रकार, हम
बीआई सॉफ्टवेयर उत्पाद के लिए प्रमुख आवश्यकताओं के लिए आते हैं। उन्हीं आवश्यकताओं ने गति-मानचित्र का आधार बनाया, जिसके आधार पर हमने अंततः एक उत्पाद आपूर्तिकर्ता को चुना।
तालिका 1. बीआई उपकरण चयन मानदंड।
हमारी टीम के भीतर मतदान परिणामों की अंतिम तालिका इस प्रकार है:
तालिका 2. एक बीआई उपकरण चुनने के लिए मतदान परिणाम।
व्यावसायिक उपयोगकर्ताओं (वे उत्पाद के चयन में भी भाग लेते हैं) की ओर से, वोटों को झांकी और लुकर के बीच समान रूप से विभाजित किया गया था। परिणामस्वरूप, लुकर के पक्ष में चुनाव किया गया। लुकर क्यों और उपकरण के बीच मूलभूत अंतर क्या हैं, अब हम चर्चा करेंगे।
विस्तृत उपकरण विवरण
तो, चलिए BI-tools के वर्णन से शुरू करते हैं।
चित्रमय तसवीर
(यहां हम एक विस्तारित सेवा पैकेज के बारे में बात करेंगे: झांकी ऑनलाइन)
- UX + ड्रैग एंड ड्रॉप।
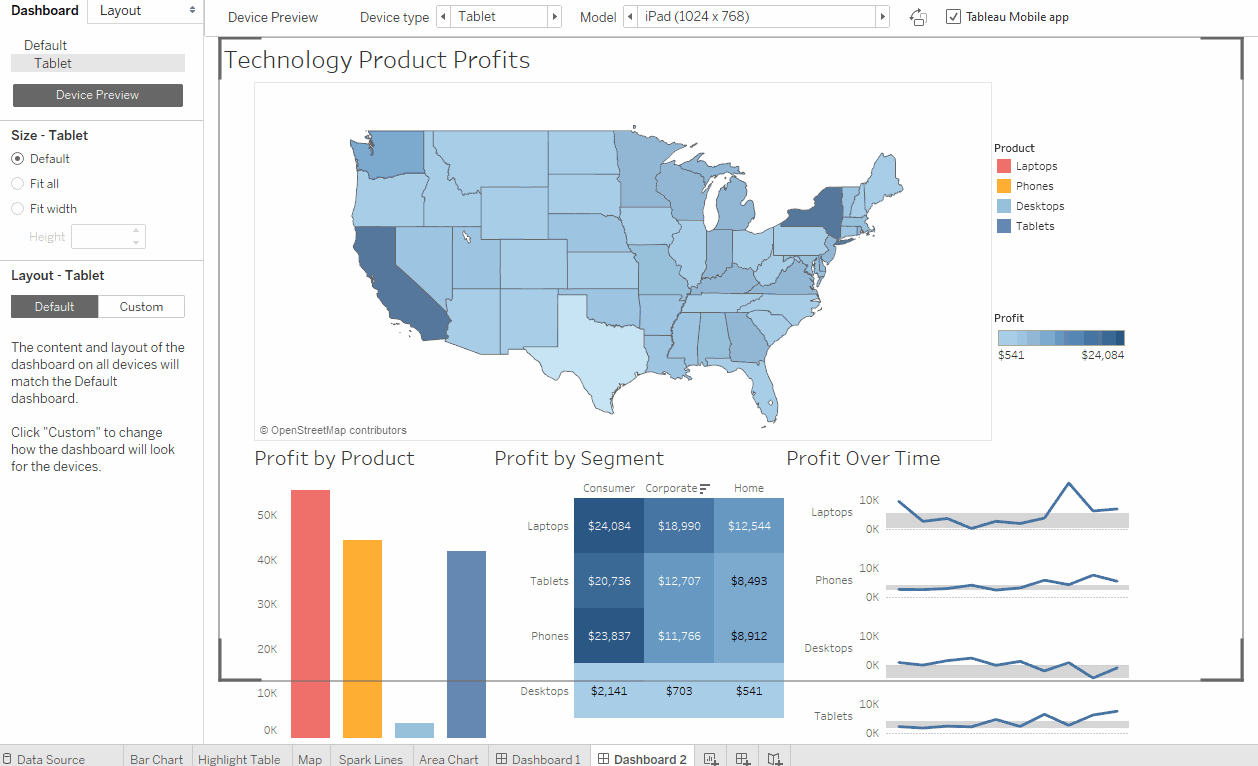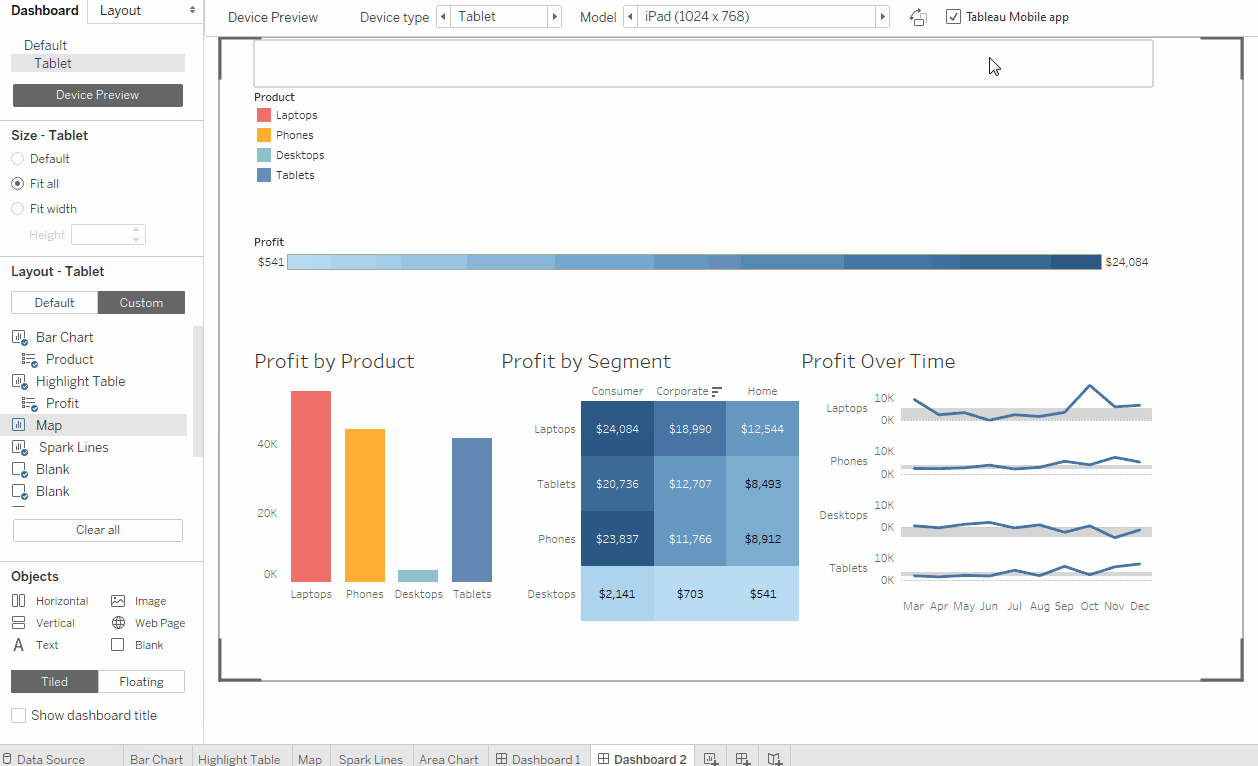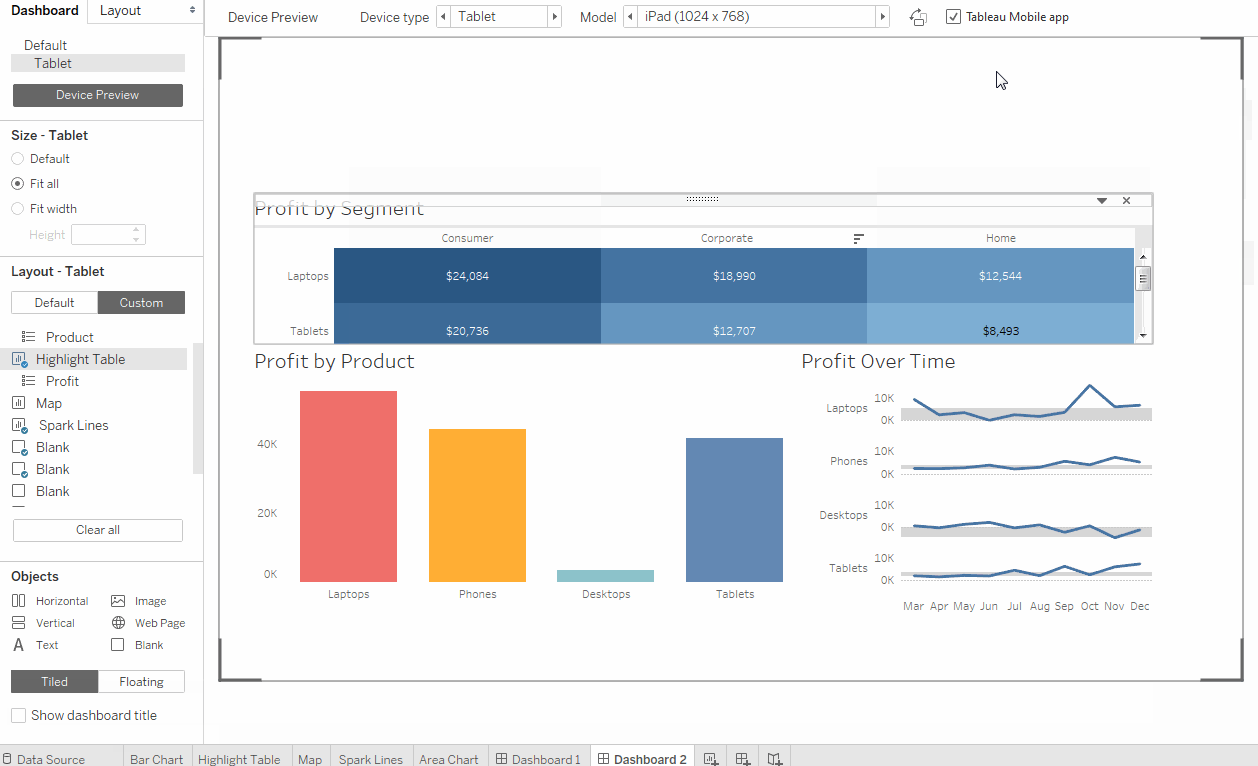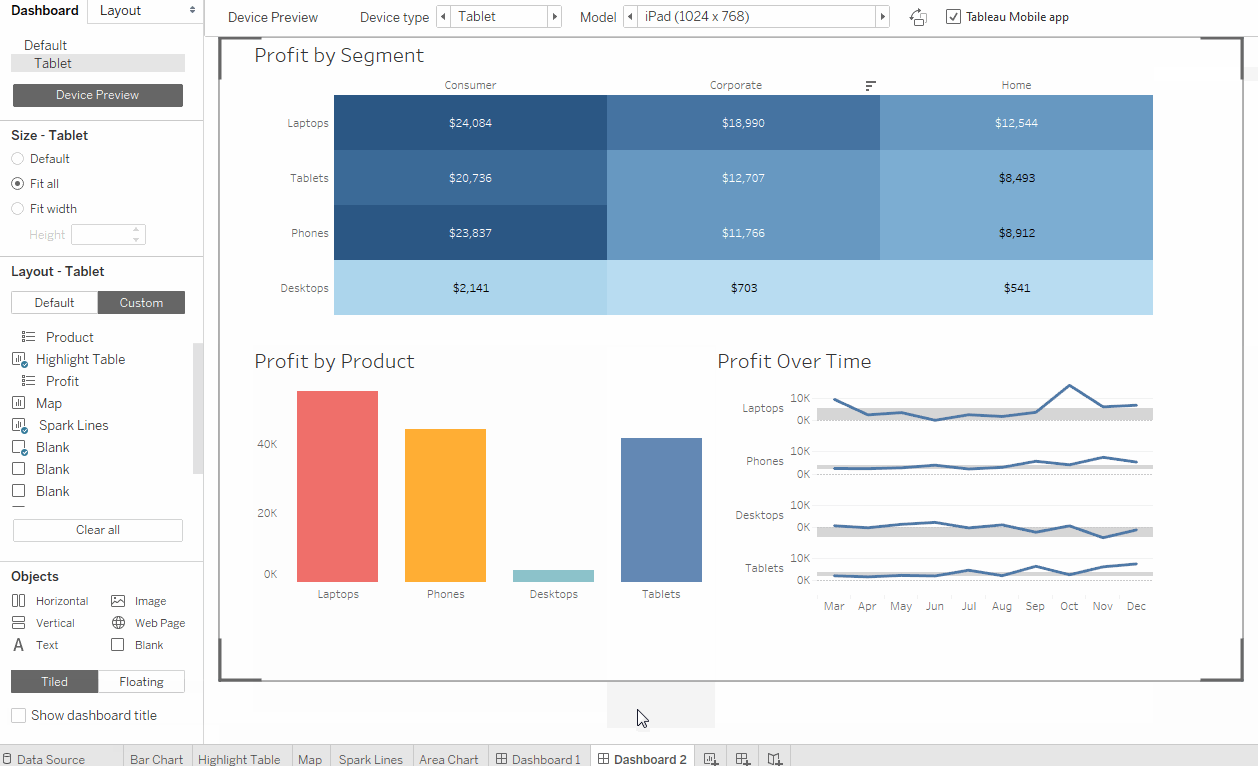
2003 के बाद से बाजार पर झांकी एक काफी पुराना उपकरण है, और ऐसा महसूस होता है कि तब से इंटरफ़ेस बहुत बदल नहीं गया है। आप विंडोज एक्सपी (छवि 1, अंजीर। 2) की शैली में पॉप-अप और ड्रॉप-डाउन विकल्पों से डर सकते हैं। लेकिन बहुत जल्दी आप उपकरण की बुनियादी कार्यक्षमता के लिए उपयोग कर सकते हैं और मास्टर कर सकते हैं। झांकी एक्सेल के कई उन्नत संस्करण की याद दिलाती है, इसमें टैब (वर्कशीट) और डैशबोर्ड (डैशबोर्ड) हैं - वर्कशीट पर प्राप्त विज़ुअलाइज़ेशन का एक संयोजन। ड्रैग एंड ड्रॉप विकल्प का उपयोग करना काफी आसान है, ग्राफ़ पर फ़िल्टर आसानी से कॉन्फ़िगर किए जाते हैं और बदलते हैं (चित्र 3, अंजीर। 4)। झांकी में सेवा के दो संस्करण हैं: डेस्कटॉप और डेस्कटॉप + ऑनलाइन। डेस्कटॉप अधिक पुराने जमाने का है - यह वास्तव में, उन्नत एक्सेल है। परीक्षण अवधि के लिए ऑनलाइन संस्करण अक्सर विचारशील था और कभी-कभी आपके काम को सहेजे बिना पृष्ठ को अपडेट करने में समाप्त हो जाता था।
अंजीर। 1
अंजीर। 2
अंजीर। 3
अंजीर। 4
- डेटा हैंडलिंग।
झांकी बहुत तेज़ी से डेटा को संभालती है, डेटा के बड़े संस्करणों (20 मिलियन से अधिक रिकॉर्ड) पर भी सेकंड के मामले में समय फिल्टर या एकत्रीकरण होता है। जैसा कि हमने पहले ही कहा, इसके लिए, झांकी में OLAP डेटा क्यूब्स और इन-मेमोरी डेटा इंजन दोनों का उपयोग किया जाता है। झांकी का दावा है कि उनके आंतरिक इन-मेमोरी समाधान हाइपर के लिए धन्यवाद, क्वेरी निष्पादन की गति 5 गुना बढ़ गई है ।
डेटा क्यूब्स को टैब्ले डेस्कटॉप के स्थानीय संस्करण पर कॉन्फ़िगर किया जा सकता है और नेटवर्क सर्वर पर डाउनलोड या अपडेट किया जा सकता है, इस स्थिति में क्यूब असेंबली के पिछले संस्करण पर निर्मित सभी डैशबोर्ड स्वचालित रूप से अपडेट हो जाएंगे। अपडेट क्यूब्स को स्वचालित रूप से कॉन्फ़िगर किया जा सकता है, उदाहरण के लिए, रात में। क्यूब को इकट्ठा करते समय सभी माप और माप (आयाम और उपाय) अग्रिम में निर्धारित किए जाते हैं और विधानसभा के अगले संस्करण तक नहीं बदलते हैं। झांकी में डेटा क्यूब्स के उपयोग के साथ, डेटाबेस को सीधे एक्सेस करना संभव है, इसे लाइव कनेक्शन कहा जाता है, इस मामले में गति बहुत कम होगी, लेकिन डेटा अधिक प्रासंगिक होगा। एक डेटा क्यूब को इकट्ठा करने की प्रक्रिया काफी सरल है, मुख्य बात यह है कि कई तालिकाओं (जॉइन) (छवि 5) को इकट्ठा करने के लिए सही फ़ील्ड का चयन करना है।
अंजीर। 5
- कार्यप्रवाह।
यह इस बिंदु के कारण है कि हमने भविष्य में झांकी का चयन नहीं किया। इस पैरामीटर के अनुसार, झांकी उद्योग से काफी पिछड़ गई और डैशबोर्ड के विकास और रिलीज को आसान बनाने के लिए कोई उपकरण नहीं दे सकी। झांकी संस्करण नियंत्रण, कोड समीक्षा, टीम सहयोग प्रदान नहीं करती है, और न ही एक अच्छी तरह से सोचा हुआ विकास और परीक्षण वातावरण है। यह ठीक इस वजह से है कि कंपनियां अक्सर अधिक उन्नत उपकरणों के पक्ष में झांकी को छोड़ देती हैं। पहले से ही डेटा क्यूब्स और डैशबोर्ड बनाने में शामिल कुछ कर्मचारियों के साथ, भ्रम की स्थिति पैदा हो सकती है - जहां डेटा के नवीनतम संस्करण को खोजने के लिए, कौन से मैट्रिक्स का उपयोग किया जा सकता है और कौन सा नहीं। डेटा अखंडता की कमी है, जो सिस्टम में दिखाई देने वाले मैट्रिक्स में व्यवसाय के प्रति अविश्वास की ओर ले जाता है।
- दृश्य।
डेटा विज़ुअलाइज़ेशन के संदर्भ में, झांकी एक बहुत शक्तिशाली उपकरण है। आप हर स्वाद और रंग (चित्र 6) के लिए चार्ट और ग्राफ़ पा सकते हैं। डेटा विज़ुअलाइज़ेशन - पृष्ठ, एक्सेल की तरह, आप टैब के बीच स्विच कर सकते हैं।
अंजीर। 6
- सहायता।
झांकी के समर्थन के दृष्टिकोण से, यह मुझे बहुत ग्राहक-उन्मुख नहीं लग रहा था, मुझे ज्यादातर सवालों के जवाब खुद ही खोजने थे। सौभाग्य से, झांकी में एक बड़ा समुदाय है जहां आप ज्यादातर सवालों के जवाब पा सकते हैं।
- सांख्यिकी।
झांकी में पायथन के साथ एकीकृत करने की क्षमता है, अधिक विवरण पाया जा सकता है।
- मूल्य।
कीमतें बाजार के लिए बहुत मानक हैं , आधिकारिक वेबसाइट पर पाई जा सकती हैं। मूल्य उपयोगकर्ता के स्तर (डेवलपर, एक्सप्लोरर, दर्शक) पर निर्भर करता है, विवरण वहां पाया जा सकता है। 10 डेवलपर्स, 25 एक्सप्लोसर्स और 100 दर्शकों की गणना करते समय, प्रति वर्ष $ 39,000 / वर्ष निकलता है।
देखनेवाला
- UX + ड्रैग एंड ड्रॉप।
लुकर एक अपेक्षाकृत युवा कंपनी है, जिसकी स्थापना 2012 में हुई थी। UX उपयोगकर्ता के लिए मूल रूप से स्पष्ट और सरल है, ड्रैग एंड ड्रॉप को आसानी से लागू किया जाता है (चित्र 7)।
अंजीर। 7
- डेटा हैंडलिंग।
लुक में डेटा के साथ काम करना झांकी की तुलना में काफी धीमा है । मुख्य कारण यह है कि लुकर डेटाबेस को सीधे OLAP क्यूब्स बनाए बिना प्रश्न बनाता है। जैसा कि हमने चर्चा की, इस दृष्टिकोण के अपने फायदे हैं - यह तथ्य कि डेटा हमेशा ताज़ा रहता है और कोई भी डेटा एकत्रीकरण किया जा सकता है। लुकर जटिल प्रश्नों को तेज करने के लिए एक उपकरण भी प्रदान करता है - कैश्ड क्वेरी , यानी प्रश्नों को कैश करने की क्षमता।
- कार्यप्रवाह।
हमारे द्वारा परीक्षण किए गए सभी बीआई टूल की तुलना में लुकर का मुख्य लाभ इसकी अच्छी तरह से सोचा गया डैशबोर्ड विकास और रिलीज प्रक्रिया है । लुकर जीथब का उपयोग करके संस्करण नियंत्रण को एकीकृत करता है। विकास पर्यावरण (उत्पादन मोड ) और उत्पादक पर्यावरण (छवि 8) भी अच्छी तरह से अलग हैं। लुकर का एक और लाभ यह है कि डेटा मॉडलिंग की पहुंच एक ही हाथों में बनी हुई है - डेटा मॉडल का केवल एक मास्टर संस्करण है, जो अखंडता सुनिश्चित करता है।
यहाँ यह भी बताया गया है कि डेटा मॉडलिंग के लिए अतिरिक्त सुविधाओं के साथ लुकर का SQL भाषा का अपना एनालॉग है - LookML। यह एक काफी सरल और लचीला उपकरण है जो आपको ड्रैग एंड ड्रॉप कार्यक्षमता को अनुकूलित करने की अनुमति देता है और कई नए विकल्प (चित्र। 9) जोड़ता है।
अंजीर। 8
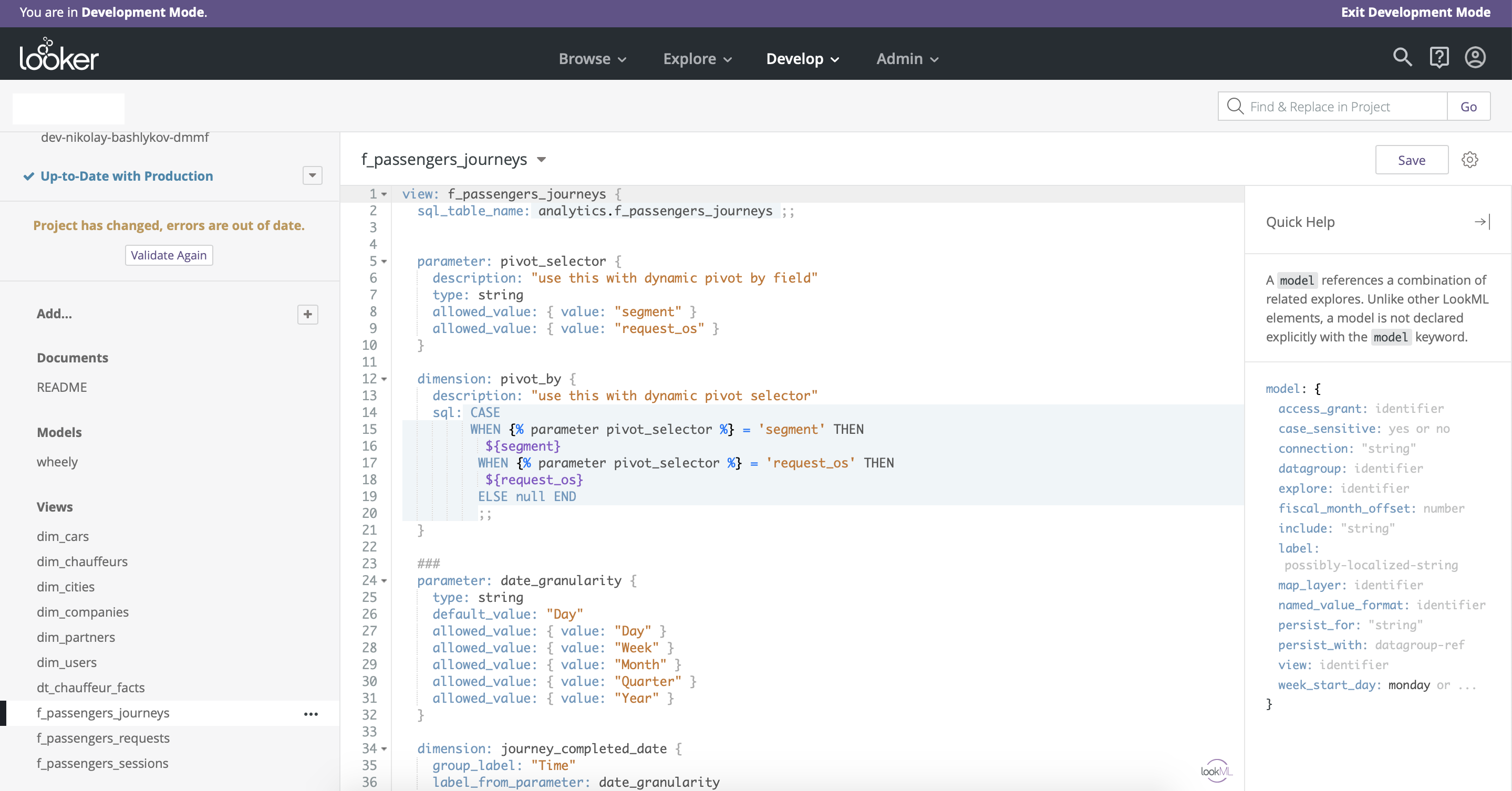
अंजीर। 9
- दृश्य।
विज़ुअलाइज़ेशन के दृष्टिकोण से, व्यूअर झांकी के लिए ज्यादा नीच नहीं है, इसमें आप अपने स्वाद के लिए कोई भी चार्ट और चार्ट पा सकते हैं। झांकी के विपरीत, चार्ट का संगठन लंबवत है, जहां संगठन को पृष्ठांकित किया गया है (छवि 10, चित्र 11)। व्यवसाय उपयोगकर्ताओं के लिए एक उपयोगी विशेषता नीचे ड्रिल है - पूर्वनिर्धारित आयामों में चयनित डेटा को विभाजित करने की क्षमता।
अंजीर। 10
अंजीर। 11
- सहायता।
लुकर में व्यवसाय सलाहकारों और तकनीकी विशेषज्ञों का समर्थन, मुझे कहना होगा, आश्चर्य की बात थी - हम किसी भी मुद्दे पर आधे घंटे में एक वीडियो कॉल शेड्यूल कर सकते हैं और पूर्ण उत्तर प्राप्त कर सकते हैं। ऐसा लगता है कि लुकर वास्तव में अपने ग्राहकों को महत्व देते हैं और अपने जीवन को सरल बनाने की कोशिश करते हैं।
- सांख्यिकी।
लुकर के पास Python के लिए API - Look API और SDK हैं, उनकी मदद से आप Python से लुकर से कनेक्ट कर सकते हैं और आवश्यक जानकारी डाउनलोड कर सकते हैं, फिर Python में आवश्यक ट्रांसफ़ॉर्मेशन और सांख्यिकीय विश्लेषण कर सकते हैं और परिणाम को डैशबोर्ड में मौजूद आउटपुट के बाद डेटाबेस में वापस लोड कर सकते हैं।
- मूल्य।
व्यूअर की लागत झांकी से काफी अधिक है , उपयोगकर्ताओं के एक समान सेट के लिए लुकर झांकी की तुलना में लगभग 2 गुना अधिक महंगा है - लगभग $ 60,000 / वर्ष।
पेरिस्कोप
- UX + ड्रैग एंड ड्रॉप।
पेरिस्कोप सीमित कार्यक्षमता वाला एक काफी आसान उपयोग है । एक ड्रैग एंड ड्रॉप फंक्शन भी है, लेकिन अलग-अलग चार्ट के लिए फिल्टर अलग से बनाने होंगे, जो असुविधाजनक है (चित्र 12)। थोड़ी अधिक जटिल क्वेरी बनाने के लिए आप SQL के बिना नहीं कर सकते।
अंजीर। 12
- डेटा हैंडलिंग।
पेरिस्कोप में OLAP क्यूब्स और क्वेरी कैशिंग के बीच एक क्रॉस है। इसमें, आप व्यू बना सकते हैं और उन्हें कैश कर सकते हैं। दृश्य कोई भी SQL-क्वेरी है, इसके कैशिंग के लिए इस दृश्य (चित्र 13) की सेटिंग में 'भौतिक' बटन पर क्लिक करना आवश्यक है। आप एक 'प्रकाशित' दृश्य भी प्रकाशित कर सकते हैं ताकि आप इसे ड्रैग एंड ड्रॉप के लिए उपयोग कर सकें।
अंजीर। 13
- कार्यप्रवाह।
पेरिस्कोप प्रो गिट का उपयोग करके संस्करण नियंत्रण को एकीकृत करता है। किसी भी डैशबोर्ड में परिवर्तनों के इतिहास को देखने और पिछले संस्करण में वापस रोल करने का अवसर भी है।
- दृश्य।
चार्ट और चार्ट का सेट बहुत सीमित है; आप यहां की विविधता को झांकी या लुकर के रूप में नहीं पा सकते हैं।
- सहायता।
समर्थन काफी परिचालन है, यदि आप संशोधन करते हैं कि समर्थन केंद्र प्रशांत मानक समय पर संचालित होता है। 24 घंटों के भीतर, आपको निश्चित रूप से प्रतिक्रिया मिलेगी।
- सांख्यिकी।
पेरिस्कोप का अजगर के साथ एकीकरण है। अधिक विवरण यहां पाया जा सकता है ।
- मूल्य।
Periscope Pro की लागत लगभग Tableau की तरह होगी: $ 35,000।
मोड विश्लेषिकी
- UX + ड्रैग एंड ड्रॉप।
मोड इन उपकरणों में सबसे सरल है। इसका मुख्य अंतर पाइथन के साथ एकीकरण और जुपिटर नोटबुक (चित्र 14) के आधार पर विश्लेषणात्मक रिपोर्ट बनाने की क्षमता है। यदि आपने जुपिटर नोटबुक का उपयोग करके विश्लेषणात्मक रिपोर्ट बनाने की प्रक्रिया का निर्माण नहीं किया है, तो यह उपकरण आपके लिए उपयोगी हो सकता है। मोड बल्कि पूर्ण-विकसित BI सिस्टम के अतिरिक्त है, इसकी कार्यक्षमता बहुत ही सीमित है, डैशबोर्ड बनाने के लिए, आप 27 हजार से अधिक लाइनों के तालिकाओं का उपयोग कर सकते हैं, जो उपकरण की क्षमताओं को सीमित करता है (चित्र 15)। अन्यथा, आपको डेटा एकत्र करने और विज़ुअलाइज़ेशन के लिए एक छोटी आयाम तालिका (छवि 16) प्राप्त करने के लिए प्रत्येक ग्राफ़ के लिए अलग-अलग एसक्यूएल प्रश्न लिखने की आवश्यकता है।
अंजीर। 14
अंजीर। 15
अंजीर। 16
- डेटा हैंडलिंग।
मोड में जैसे, डेटा हैंडलिंग गायब है। सभी प्रश्न सीधे डेटाबेस से किए जाते हैं, मुख्य तालिकाओं को कैश करने का कोई तरीका नहीं है।
- कार्यप्रवाह।
जीथब के साथ मोड का एकीकरण है, अधिक विवरण यहां पाया जा सकता है ।
- दृश्य।
डेटा विज़ुअलाइज़ेशन का सेट बहुत सीमित है, 6-7 प्रकार के रेखांकन हैं।
- सहायता।
परीक्षण अवधि के दौरान, समर्थन काफी चालू था।
- सांख्यिकी।
जैसा कि पहले ही उल्लेख किया गया है, मोड अच्छी तरह से पायथन के साथ एकीकृत है, जो आपको ज्यूपिटर नोटबुक का उपयोग करके उपयोगकर्ता के अनुकूल विश्लेषणात्मक रिपोर्ट बनाने की अनुमति देता है।
- मूल्य।
मोड, विचित्र रूप से पर्याप्त, अपनी क्षमताओं के लिए काफी महंगा है - लगभग $ 50,000 / वर्ष।
निष्कर्ष
एक बीआई उपकरण प्रदाता की पसंद को पूरी तरह से संपर्क किया जाना चाहिए, व्यापार उपयोगकर्ताओं के समर्थन के साथ और एक उपकरण चुनने के लिए मुख्य मानदंड को परिभाषित करना (अधिमानतः गति मानचित्र के रूप में)। इस आलेख में प्रस्तुत मानदंड मुख्य रूप से डेटा के साथ काम करने की दक्षता में सुधार लाने, जानकारी निकालने की प्रक्रिया को सरल बनाने, डेटा विज़ुअलाइज़ेशन की गुणवत्ता में सुधार और विश्लेषकों पर बोझ को कम करने के उद्देश्य से हैं।सूत्रों का कहना है
- गार्टनर, बिजनेस इंटेलिजेंस - बीआई - गार्टनर आईटी ग्लोसरी
- Kaggle
- झांकी - हाइपर
- ZDNet - Salesforce-Tableau, अन्य BI सौदे प्रवाहित होते हैं
- झांकी वेबसाइट
- देखने वाली वेबसाइट
- पेरिस्कोप वेबसाइट
- मोड एनालिटिक्स वेबसाइट