सभी को नमस्कार! अत्यधिक लोड किए गए अनुप्रयोगों के विकास पर एक सम्मेलन जून में नोवोसिबिर्स्क में HighLoad ++ साइबेरिया 2019 में आयोजित किया गया था। इससे पहले Habré के लेखों में, हमने उल्लेख किया था कि हम Plesk सम्मेलनों और रिपोर्टों का एक पूर्वव्यापी आचरण करते हैं ताकि हम प्राप्त ज्ञान को न खोएं और बाद में उन्हें लागू न करें। हम आपको बताएंगे कि कौन सी रिपोर्ट हमने खुद के लिए नोट की, और आपके साथ एक पूर्वव्यापी नुस्खा भी साझा करें। आयोजक धीरे-धीरे यहां वीडियो पोस्ट कर रहे हैं:
यूट्यूब चैनल । हम जो वर्णन कर रहे हैं उसका कुछ हिस्सा पहले ही देखा जा सकता है।
रिपोर्ट अवलोकन
विक्टर एरेमेंको (मिरो)यह Redis -> PostgreSQL -> Pgbouncer + PostgreSQL -> Patroni Consul + Pgbouncer + PostgreSQL के सफल प्रवास पर एक समीक्षा रिपोर्ट है। लेखक योजनाएं देता है, स्पष्ट समाधानों के विशिष्ट नुकसान, वैकल्पिक समाधानों के बारे में बात करता है और वे फिट क्यों नहीं हुए। दिलचस्प से:
- Miro इंजीनियरों ने अपने समाधान को एक साथ रखा है ताकि अमेज़ॅन आरडीएस के लिए भुगतान न करें, और यह समाधान अब तक उन्हें सूट करता है।
- PostgreSQL के लिए कनेक्शन प्रबंधकों पर इसी तरह।
- अनुप्रयोग को रोकने के बिना क्लस्टर नोड्स को अपडेट करने की प्रक्रिया का वर्णन करता है।
- PostgreSQL को जल्दी से अपडेट करने के लिए एक चाल दिखाता है।
यह देखने के लिए उपयोगी है कि जो लोग PostgreSQL का उपयोग करते हैं या करने जा रहे हैं, और जिनके पास डेटा की बढ़ती मात्रा है।
वसीली बोगोनाटोव ( यांडेक्स )परिचयात्मक वक्ता के रूप में, उन्होंने काफ्का और रैबिटएमक्यू की कुछ विशेषताओं की तुलना की। संक्षेप में: काफ्का - एक सरल कतार, एक जटिल प्राप्तकर्ता; RabbitMQ एक जटिल कतार है, एक सरल रिसीवर है। लेखक ने कतार से संदेश देने के लिए गारंटी के प्रकारों के बारे में भी बताया। महत्वपूर्ण नोट: कोई भी कतार प्रेषक और प्राप्तकर्ता के समर्थन के बिना किसी संदेश को ठीक 1 बार वितरण सुनिश्चित नहीं कर सकती है।
रिपोर्ट YandexMQ को समर्पित है। YandexMQ (YMQ) अमेज़न SQS कतार के साथ संगत एक एपीआई है। YandexMQ की नींव यैंडेक्स डेटाबेस (YDB) है। वासिली ने YandexMQ का फायदा दिखाया, कैसे सख्त स्थिरता और विश्वसनीयता हासिल की और YMQ की वास्तुकला की समीक्षा की। YMQ प्रतिस्पर्धी उपभोक्ताओं के पैटर्न को लागू करता है - एक उपभोक्ता को एक संदेश। YMQ चिप: जब उपभोक्ता एक संदेश के लिए पूछता है, तो इसे कतार में छिपा दिया जाता है ताकि कोई और इसे प्रसंस्करण में न ले जाए। यदि प्रसंस्करण के दौरान समस्याएं हैं, तो दृश्यता के बाद संदेश फिर से कतार में दिखाई देता है। स्पीकर का दावा है कि अपाचे काफ्का को डेटा हानि की समस्या है जब प्रक्रिया अचानक मार दी जाती है, यांडेक्स मैसेजक्व्यू इसके लिए प्रतिरोधी है।

रिपोर्ट उन सभी के लिए अनुशंसित है जो कतारों की मूलभूत विशेषताओं को समझना चाहते हैं।
इवान मुराटोव (पहली निगरानी कंपनी)PostgreSQL समय श्रृंखला में डेटा को कैसे स्टोर और प्रोसेस करना है, इसकी रिपोर्ट करें।
TimescaleDB आपको चालाक विभाजन के कारण बड़ी मात्रा में स्टोर करने की अनुमति देता है, और PipelineDB सीधे PostgreSQL (साथ ही कतारों के साथ एकीकरण) में धाराओं के साथ काम प्रदान करता है।
TimescaleDB:
- यह भारी भार के तहत डेटाबेस की मात्रा में वृद्धि और विभाजन की संख्या में वृद्धि के साथ एक बहुत ही स्थिर रिकॉर्डिंग गति है, हजारों में मापा जाता है।
- आपको SQL, प्रतिकृति, बैकअप, पुनर्स्थापना, आदि जैसे मानक PostgreSQL सुविधाओं का उपयोग करने की अनुमति देता है।
- एकीकरण का एक अच्छा सेट की घोषणा की जाती है, उदाहरण के लिए, प्रोमेथियस, टेलीग्राफ, ग्राफाना, ज़ैबिक्स, कुबेरनेट्स के साथ।
- एक मुक्त खुला स्रोत संस्करण है।
मुख्य विचार: TimescaleDB मुख्य रूप से डेटा संग्रहीत करने के लिए आवश्यक है।
PipelineDB:
- आपको SQL का उपयोग करके आने वाले डेटा को लगातार संसाधित करने और परिणाम को एक तालिका में जोड़ने की अनुमति देता है।
- SQL इंटरफ़ेस है।
- शर्तों के तहत संग्रहीत प्रक्रियाओं का एक प्रदर्शन है।
- Apache Kafka और Amazon Kinesis के साथ एकीकरण संभव है।
- एक मुक्त खुला स्रोत संस्करण है।
- PipelineDB विकास 1.0 संस्करण पर जमे हुए हैं, और अब केवल बग फिक्स जारी किए गए हैं।
मुख्य विचार: मुख्य रूप से डाटा प्रोसेसिंग के लिए पाइपलाइनलाइन की जरूरत होती है।
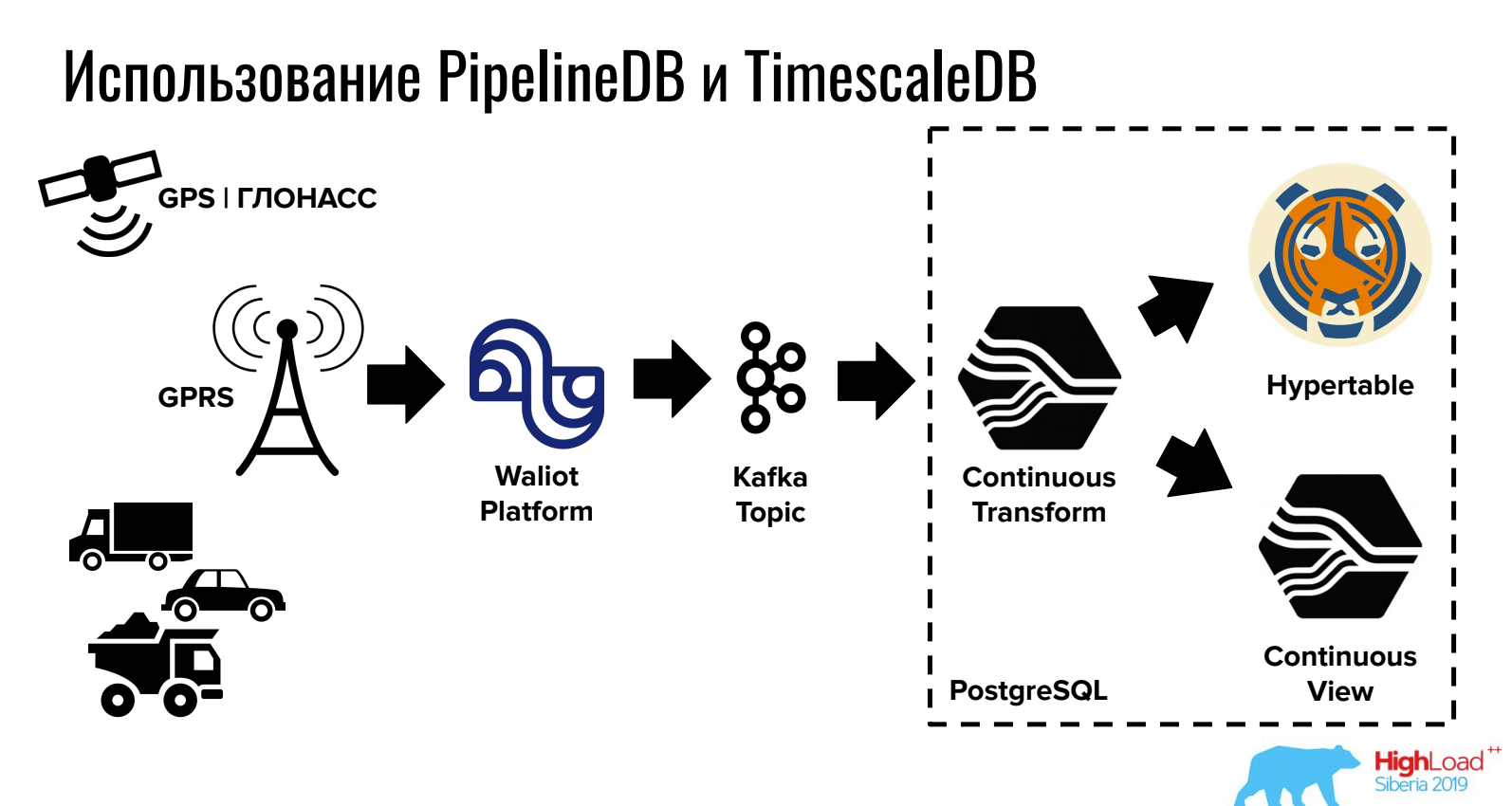
ऐसे कार्यों के लिए जहां एक संबंधपरक DBMS, NoSQL और समय श्रृंखला की आवश्यकता होती है, यह विकल्प काफी सुविधाजनक हो सकता है।
पावेल लुजानोव (व्यावसायिक पोस्टग्रैट्स)PostgreSQL, टेबल इनहेरिटेंस और टिप्स एंड ट्रिक्स के प्रदर्शन की एक अच्छी अवलोकन रिपोर्ट PostgreSQL 10, 11, 12+। वंशानुक्रम, विभाजन के माध्यम से विभाजन। यह उन सभी को देखना उपयोगी है जो PostgreSQL का उपयोग करते हैं और इसे थोड़ा तेज करना चाहते हैं।
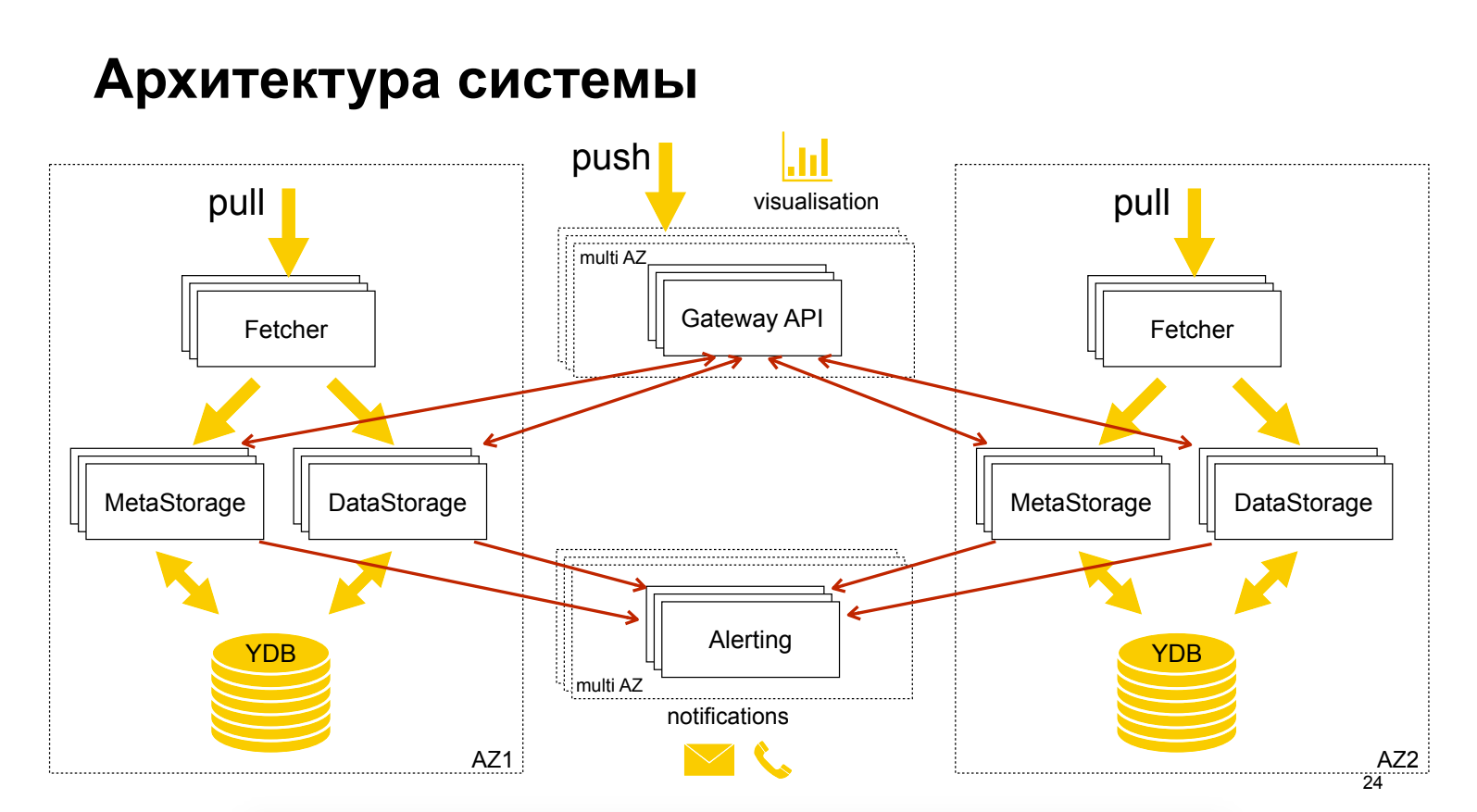
सर्गेई पोलोवो (यांडेक्स)यैंडेक्स मॉनिटरिंग क्लाउड उत्पाद के बारे में, जो अभी भी "पूर्वावलोकन" चरण में है, मुफ्त है। वास्तुकला के बारे में थोड़ा सा। एक दिलचस्प तकनीक दिखाई गई है - डेटा से मेटाडेटा को अलग करना, जो स्वतंत्र स्केलिंग और अनुकूलन को सक्षम करता है। Grafana का उपयोग GUI के रूप में किया जाता है, जबकि इसकी सूचना Grafana में नहीं होती है।
 एंड्री सालनिकोव (डेटा एग्रेत)
एंड्री सालनिकोव (डेटा एग्रेत)कई PostgreSQL सर्वर के वाणिज्यिक प्रणाली प्रशासन में अनुभव। यह बताता है कि कौन से सर्वर पैरामीटर की स्वचालित रूप से निगरानी की जाती है, कैसे कार्यों को प्राथमिकता दी जाती है।
डेटा एग्रेट व्यंजनों, चेकलिस्ट के साथ विकी में सामान्यीकृत अनुभव का उपयोग करता है - यह भविष्य के लेखों और रिपोर्टों का आधार है। वे समस्याओं और समाधानों के विवरण के साथ एक घटना डेटाबेस का उपयोग करते हैं - यह संसाधनों को महत्वपूर्ण रूप से बचाता है। PostgreSQL के साथ काम करने के लिए कई उपयोगिताओं का विमोचन किया, उन्हें लिंक प्रदान करें।
 एवगेनी सोकोलोव (यांडेक्स.मार्केट)
एवगेनी सोकोलोव (यांडेक्स.मार्केट)एक जटिल, अत्यधिक सुलभ, वितरित Yandex.Market आवेदन की वास्तुकला पर रिपोर्ट और इसके विकास, परीक्षण, अद्यतन, निगरानी के लिए प्रक्रियाओं और उपकरणों पर। दिलचस्प से:
- "स्टॉप-क्रेन" त्वरित अनुप्रयोग और कॉन्फ़िगरेशन के रोलबैक के लिए इसका समाधान है; यह नई कार्यक्षमता का परीक्षण करने में मदद करता है।
- समस्याओं के मामले में बैलेंसर द्वारा वर्तमान डेटा सेंटर से दूसरे डेटा सेंटर पर ट्रैफ़िक पुनर्निर्देशित किया जाता है।
- निगरानी के लिए ग्रेफाइट और ग्राफाना का उपयोग किया जाता है।
- एक और प्रौद्योगिकी स्टैक पर डुप्लिकेट बेसिक मॉनिटरिंग है।
- डेवलपर्स के लिए शैडो क्लस्टर का उपयोग किया जाता है, जो उपयोगकर्ता ट्रैफ़िक के भाग को डुप्लिकेट करता है। उपयोगकर्ता छाया समूह की प्रतिक्रियाओं को नहीं देखते हैं।
- A / B परीक्षण के दौरान एक स्वचालित गुणवत्ता गणना की जाती है।
 एंटोन अलेक्सेव (2GIS)
एंटोन अलेक्सेव (2GIS)ClickHouse में क्या अच्छा है और कैसे Grafana के साथ संयोजन के रूप में इसे पकाने के बारे में रिपोर्ट करें। मुख्य दिलचस्प:
- यदि पर्याप्त गति नहीं है, तो आपको नमूने का उपयोग करना चाहिए (यह तर्क दिया जाता है कि नमूने के बाद डेटा की सटीकता पर्याप्त है)। ClickHouse में नमूनाकरण - तालिका कुंजी में विभिन्न मूल्यों के अनुपात को बनाए रखते हुए एकत्रीकरण के साथ डेटा का आंशिक नमूनाकरण, आपको कई बार एकत्रीकरण में तेजी लाने की अनुमति देता है और एक ही समय में एक परिणाम होता है जो वास्तविक के बहुत करीब होता है।
- ClickHouse का उपयोग जल्दी से घटनाओं (रिपोर्ट में एक दिलचस्प उदाहरण) की जांच करने के लिए किया जा सकता है।
- ClickHouse में भी तेजी लाने के लिए MaterializedView है।
- क्वेरी और डेटा लोड करने के लिए ClickHouse HTTP इंटरफ़ेस का वर्णन किया गया है।
रिपोर्टों की समीक्षा के निष्कर्ष में, मैं यह नोट करना चाहूंगा कि हमें वास्तव में
"वीडियो कॉल: एक सम्मेलन में लाखों प्रति दिन से लेकर 100 प्रतिभागियों तक" (
अलेक्जेंडर टोबोल /
ओडनोकलास्निक ) की रिपोर्ट पसंद आई, जो कि मतदान के परिणामों के अनुसार सम्मेलन की सर्वश्रेष्ठ रिपोर्ट की सूची में शामिल थी। यह एक बड़ा अवलोकन है कि प्रतिभागियों के समूह के लिए वीडियोकांफ्रेंसिंग कैसे काम करती है। रिपोर्ट एक समझदार प्रणालीगत प्रस्तुति द्वारा प्रतिष्ठित है। यदि आपको अचानक वीडियो कॉल करना है, तो विषय क्षेत्र में अंतर्दृष्टि प्राप्त करने के लिए आप रिपोर्ट देख सकते हैं।
Plesk सम्मेलन फ्लैशबैक संरचना
और अब, मिठाई के लिए, हम कंपनी के अंदर एक पूर्वव्यापी कैसे लिखते हैं। सबसे पहले, हम सम्मेलन में भाग लेने के बाद पहले सप्ताह में रेट्रो लिखने की कोशिश करते हैं, जबकि हमारी यादें अभी भी ताजा हैं। वैसे, पूर्वव्यापी सामग्री तब लेख के आधार के रूप में काम कर सकती है, जैसा कि आप अनुमान लगा सकते हैं;)
पूर्वव्यापी लेखन का उद्देश्य केवल ज्ञान को समेकित करना नहीं है, बल्कि उन लोगों के साथ भी साझा करना है जो सम्मेलन में नहीं थे, लेकिन नवीनतम रुझानों, दिलचस्प समाधानों के बीच रखना चाहते हैं। एक तैयार सूची में देखने के लिए दिलचस्प रिपोर्टों को खोजने के लिए समय कम करने में मदद मिलती है। हम उन पाठों को लिखते हैं जो हमने अपने लिए सीखे हैं, एक नोट के साथ विशिष्ट लोगों को चिह्नित करें, आपको रिपोर्ट देखने और दूसरों के विचारों और निर्णयों के बारे में सोचने की आवश्यकता क्यों है। लिखित पाठ ध्यान केंद्रित करने और जो हम करना चाहते थे उसे खोने में मदद करते हैं। 3-6 महीनों में रिकॉर्डिंग को देखते हुए, हम समझेंगे कि क्या हम कुछ महत्वपूर्ण के बारे में भूल गए हैं।
हम कंफ्लुएंस में कंपनी में प्रलेखन संग्रहीत करते हैं, सम्मेलनों के लिए हमारे पास एक अलग पेज ट्री, लकड़ी का एक टुकड़ा होता है:
जैसा कि स्क्रीनशॉट से देखा जा सकता है, हम नेविगेशन में आसानी के लिए साल-दर-साल सामग्री निकालते हैं।
किसी विशेष सम्मेलन के लिए समर्पित पृष्ठ के अंदर, हम निम्नलिखित अनुभागों को संग्रहीत करते हैं: ईवेंट वेबसाइट, शेड्यूल, वीडियो और प्रस्तुतियों के लिंक के साथ अवलोकन, प्रतिभागियों की सूची (व्यक्तिगत रूप से और प्रसारण में), सामान्य प्रभाव (समग्र प्रभाव) और विस्तृत अवलोकन (विस्तृत अवलोकन) )। वैसे, हम एक टेम्पलेट से रेट्रो के लिए एक पेज बनाते हैं जिसमें पूरी संरचना पहले से मौजूद है। हम शीर्षकों की सामग्री भी बनाते हैं ताकि आप बहुत तेज़ी से रिपोर्ट की सूची देख सकें और वांछित पर आगे बढ़ सकें।
ओवरऑल इंप्रेशन सेक्शन सम्मेलन का एक संक्षिप्त मूल्यांकन देता है और प्रतिभागियों के इंप्रेशन देता है। यदि प्रतिभागी पिछले वर्षों में सम्मेलन में थे, तो वे अपने स्तर की तुलना कर सकते हैं और आम तौर पर कार्यक्रम में भाग लेने की उपयोगिता को समझ सकते हैं।
विस्तृत अवलोकन अनुभाग में एक तालिका है:

तालिका भरने का एक उदाहरण:

हमें उन रिपोर्ट्स के बारे में जानने में दिलचस्पी होगी जो आपको हाईलोड साइबेरिया 2019 में पसंद आईं, साथ ही साथ रेट्रोस्पेक्टिव्स के संचालन में आपके अनुभव के बारे में भी।