डेटा का संग्रह, भंडारण, रूपांतरण और प्रस्तुति डेटा इंजीनियरों के सामने मुख्य चुनौतियां हैं। बिजनेस इंटेलिजेंस बुश विभाग प्रति दिन उपयोगकर्ता उपकरणों से भेजे गए 20 बिलियन से अधिक ईवेंट प्राप्त करता है और इनकमिंग डेटा का 2 टीबी प्रोसेस करता है।
इस सभी डेटा का अध्ययन और व्याख्या हमेशा एक तुच्छ कार्य नहीं है, कभी-कभी यह तैयार डेटाबेस की क्षमताओं से परे जाने के लिए आवश्यक हो जाता है। और अगर आपके पास साहस है और कुछ नया करने का फैसला किया है, तो आपको पहले खुद को मौजूदा समाधानों के कार्य सिद्धांतों से परिचित करना चाहिए।
एक शब्द में, जिज्ञासु और मजबूत दिमाग वाले डेवलपर्स, इस लेख को संबोधित किया गया है। इसमें आप एक उदाहरण के रूप में डेमो लैंग्वेज पिगलेटिकूल का उपयोग करके रिलेशनल डेटाबेस में क्वेरी निष्पादन के पारंपरिक मॉडल का वर्णन पाएंगे।
सामग्री
प्रागितिहास
इंजीनियरों का हमारा समूह बैकएंड और इंटरफेस में लगा हुआ है, कंपनी के भीतर डेटा के विश्लेषण और अनुसंधान के अवसर प्रदान कर रहा है (वैसे, हम विस्तार कर रहे हैं)। हमारे मानक उपकरण दर्जनों सर्वर (Exasol) और सैकड़ों मशीनों (Hive और Presto) के लिए एक Hadoop क्लस्टर का वितरित डेटाबेस हैं।
इन डेटाबेस के अधिकांश प्रश्न विश्लेषणात्मक हैं, जो कि सैकड़ों-हजारों से लेकर अरबों के रिकॉर्ड को प्रभावित करते हैं। उनके निष्पादन में उपयोग किए गए समाधान और अनुरोध की जटिलता के आधार पर मिनट, दसियों मिनट या यहां तक कि घंटे लगते हैं। उपयोगकर्ता-विश्लेषक के मैनुअल काम के साथ, ऐसे समय को स्वीकार्य माना जाता है, लेकिन उपयोगकर्ता इंटरफ़ेस के माध्यम से इंटरैक्टिव अनुसंधान के लिए उपयुक्त नहीं है।
समय के साथ, हमने लोकप्रिय विश्लेषणात्मक प्रश्नों और प्रश्नों पर प्रकाश डाला, जो SQL के संदर्भ में निर्धारित करना मुश्किल है , और उनके लिए छोटे विशेष डेटाबेस विकसित किए हैं। वे हल्के संपीड़न एल्गोरिदम (उदाहरण के लिए, स्ट्रीमवेट) के लिए उपयुक्त प्रारूप में डेटा का एक सबसेट संग्रहीत करते हैं, जो आपको कई दिनों तक एक मशीन में डेटा संग्रहीत करने और सेकंड में प्रश्नों को निष्पादित करने की अनुमति देता है।
इन डेटा और उनके दुभाषियों के लिए पहली क्वेरी भाषाओं को एक कूबड़ पर लागू किया गया था, हमें उन्हें लगातार परिष्कृत करना था, और हर बार इसे अस्वीकार्य रूप से लंबा समय लगता था।
क्वेरी भाषाएँ पर्याप्त लचीली नहीं थीं, हालांकि उनकी क्षमताओं को सीमित करने के लिए कोई स्पष्ट कारण नहीं थे। नतीजतन, हम एसक्यूएल दुभाषियों के डेवलपर्स के अनुभव की ओर मुड़ गए, धन्यवाद जिसके कारण हम उन समस्याओं को आंशिक रूप से हल करने में सक्षम थे जो उत्पन्न हुई थीं।
नीचे मैं रिलेशनल डेटाबेस में सबसे आम क्वेरी निष्पादन मॉडल के बारे में बात करूंगा - ज्वालामुखी। आदिम एसक्यूएल बोली के व्याख्याकार का स्रोत कोड, पिगलेटक्यूल , लेख से जुड़ा हुआ है , इसलिए जो कोई भी इच्छुक है वह आसानी से भंडार में विवरण से परिचित हो सकता है।
SQL दुभाषिया संरचना
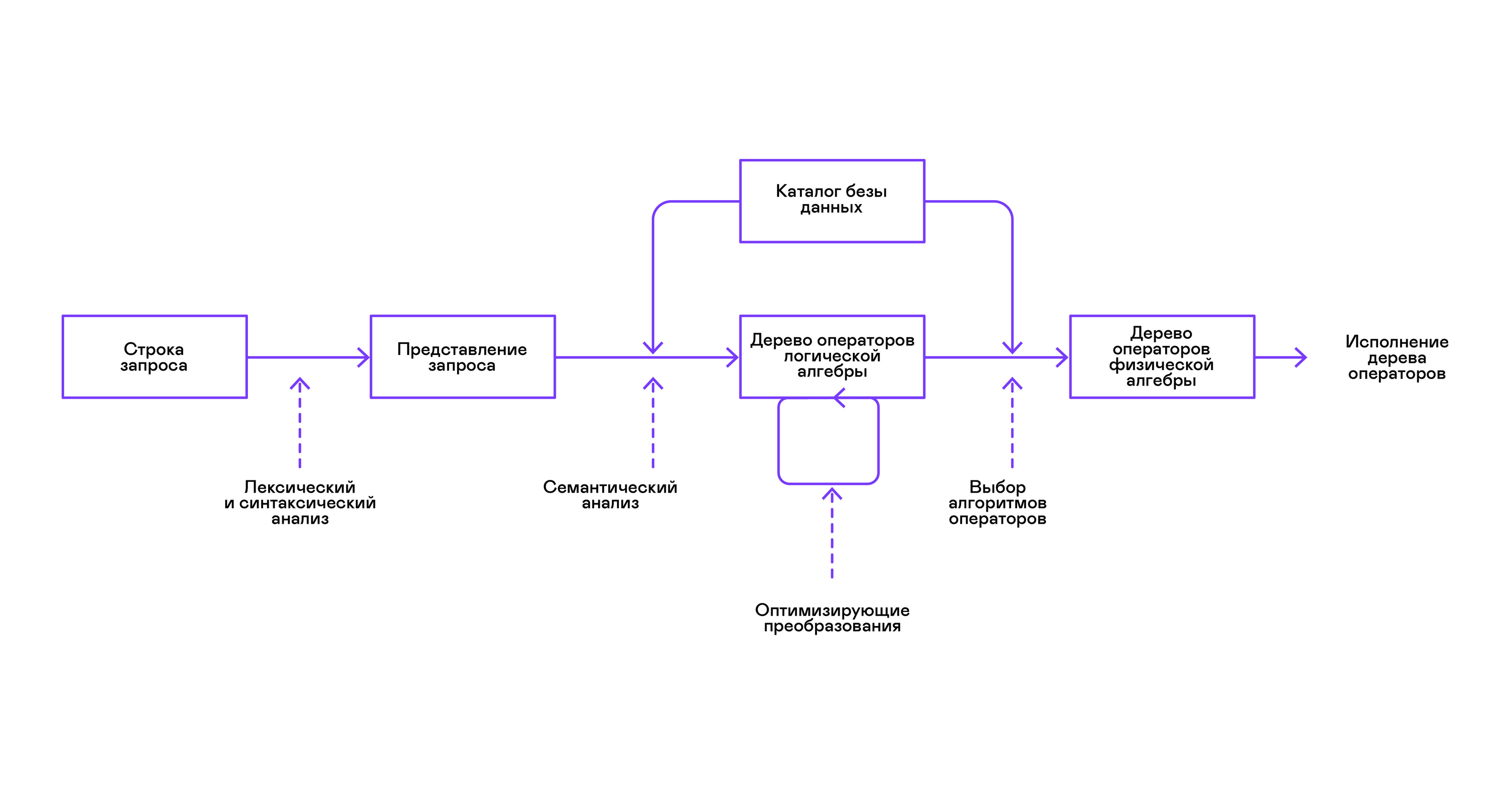
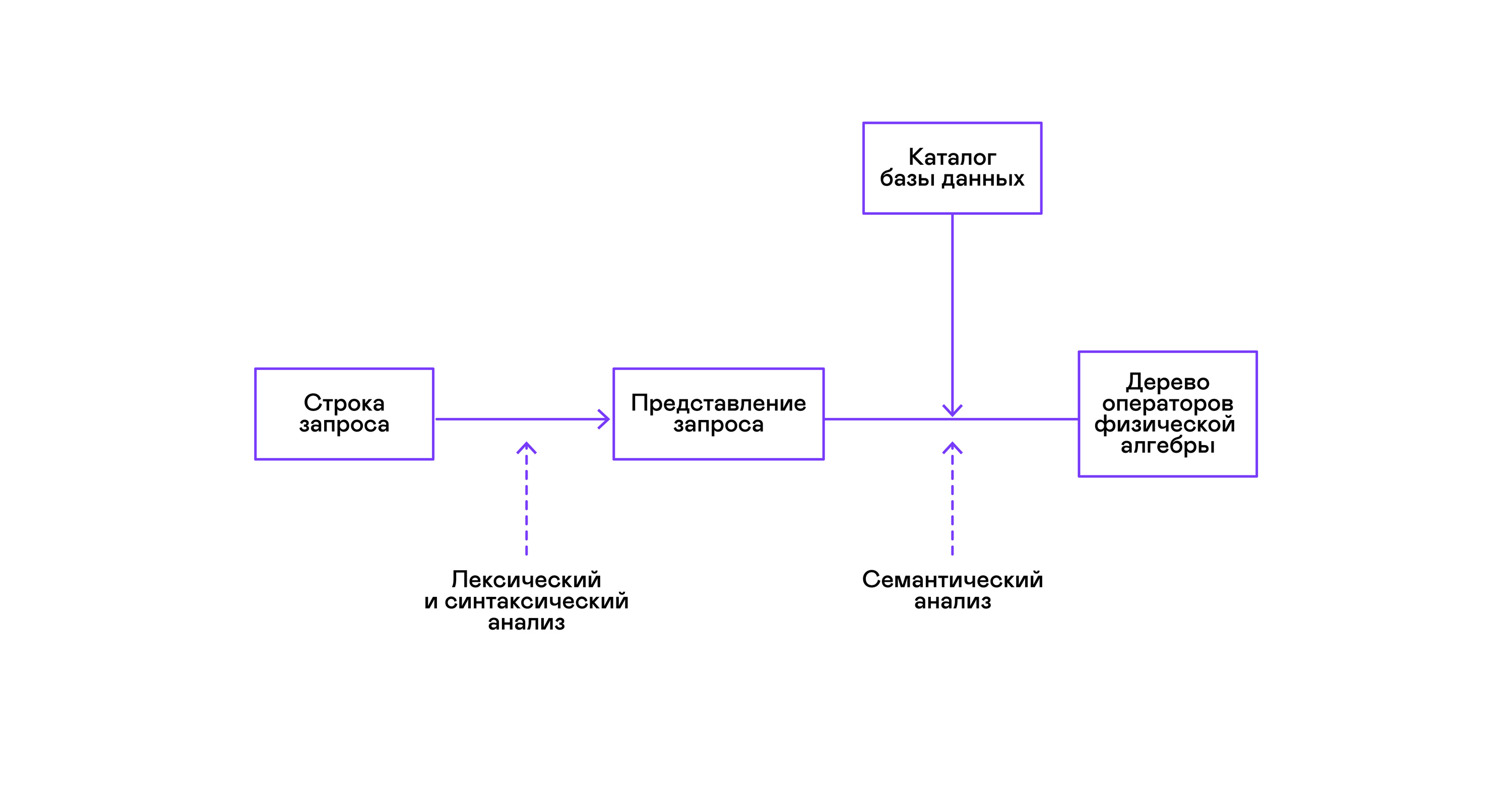
अधिकांश लोकप्रिय डेटाबेस एक घोषणात्मक SQL क्वेरी भाषा के रूप में डेटा के लिए एक इंटरफ़ेस प्रदान करते हैं। एक स्ट्रिंग के रूप में एक क्वेरी पार्सर द्वारा एक सार वाक्यविन्यास के पेड़ के समान क्वेरी के विवरण में परिवर्तित की जाती है। इस चरण में पहले से ही सरल प्रश्नों को निष्पादित करना संभव है, हालांकि, परिवर्तनों और बाद के निष्पादन के अनुकूलन के लिए, यह प्रतिनिधित्व असुविधाजनक है। मेरे लिए ज्ञात डेटाबेस में, इन उद्देश्यों के लिए मध्यवर्ती अभ्यावेदन प्रस्तुत किए जाते हैं।
संबंधपरक बीजगणित मध्यवर्ती अभ्यावेदन के लिए एक मॉडल बन गया। यह एक ऐसी भाषा है जहां डेटा पर किए गए रूपांतरण ( ऑपरेटर्स ) स्पष्ट रूप से वर्णित हैं: एक विधेय के अनुसार डेटा का एक सबसेट चुनना, विभिन्न स्रोतों से डेटा का संयोजन, आदि। इसके अलावा, रिलेशनल बीजगणित गणितीय अर्थ में एक बीजगणित है, अर्थात्, बड़ी संख्या में समकक्ष। परिवर्तनों। इसलिए, रिलेशनल बीजगणित ऑपरेटरों के एक पेड़ के रूप में एक क्वेरी पर अनुकूलन परिवर्तनों को पूरा करना सुविधाजनक है।
डेटाबेस में आंतरिक अभ्यावेदन और मूल संबंधपरक बीजगणित के बीच महत्वपूर्ण अंतर हैं, इसलिए इसे तार्किक बीजगणित कहना अधिक सही है ।
किसी क्वेरी की वैधता का सत्यापन आमतौर पर तार्किक बीजगणित ऑपरेटरों में क्वेरी के प्रारंभिक प्रतिनिधित्व को संकलित करते समय किया जाता है और पारंपरिक संकलक में सिमेंटिक विश्लेषण के चरण से मेल खाता है। डेटाबेस में प्रतीक तालिका की भूमिका डेटाबेस निर्देशिका द्वारा निभाई जाती है , जो डेटाबेस स्कीमा और मेटाडेटा के बारे में जानकारी संग्रहीत करता है: टेबल, टेबल कॉलम, इंडेक्स, उपयोगकर्ता अधिकार, आदि।
सामान्य-उद्देश्य वाले व्याख्याताओं की तुलना में, डेटाबेस दुभाषियों की एक और ख़ासियत है: डेटा की मात्रा और मेटा-जानकारी में डेटा के बारे में अंतर जिससे प्रश्न किए जाने हैं। तालिकाओं, या संबंधपरक बीजगणित के संदर्भ में, डेटा की एक अलग राशि हो सकती है, कुछ कॉलम (संबंध विशेषताएँ ) अनुक्रमित किए जा सकते हैं, आदि, जो डेटाबेस स्कीमा और तालिकाओं में डेटा की मात्रा के आधार पर, क्वेरी को अलग-अलग एल्गोरिदम द्वारा किया जाना चाहिए। , और उन्हें एक अलग क्रम में उपयोग करें।
इस समस्या को हल करने के लिए, एक और मध्यवर्ती प्रतिनिधित्व पेश किया जाता है - भौतिक बीजगणित । स्तंभों पर अनुक्रमित की उपलब्धता के आधार पर, तालिकाओं में डेटा की मात्रा, और तार्किक बीजगणित के पेड़ की संरचना, भौतिक बीजगणित के पेड़ के विभिन्न रूपों की पेशकश की जाती है, जिसमें से सबसे अच्छा विकल्प चुना जाता है। यह वह पेड़ है जिसे डेटाबेस में क्वेरी प्लान के रूप में दिखाया गया है। पारंपरिक संकलक में, यह चरण सशर्त रूप से रजिस्टर आवंटन, नियोजन और निर्देश चयन के चरणों से मेल खाता है।
दुभाषिया के काम में अंतिम चरण सीधे भौतिक बीजगणित के ऑपरेटरों के पेड़ का निष्पादन है।
ज्वालामुखी मॉडल और क्वेरी निष्पादन
भौतिक बीजगणित वृक्ष दुभाषियों का उपयोग हमेशा बंद वाणिज्यिक डेटाबेस में किया गया है, लेकिन अकादमिक साहित्य आमतौर पर प्रायोगिक ऑप्टिमाइज़र ज्वालामुखी को संदर्भित करता है, जिसे 90 के दशक में विकसित किया गया था।
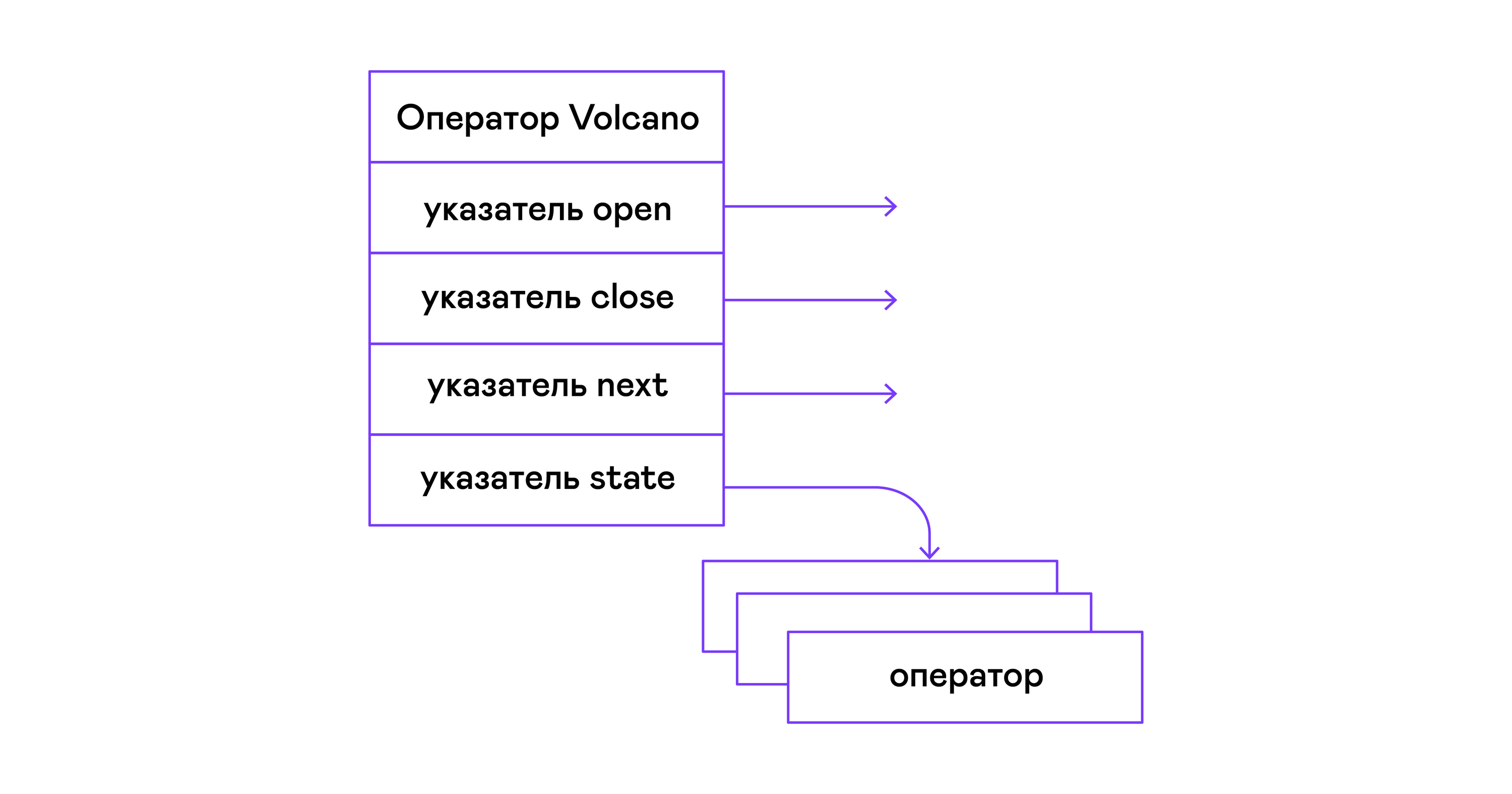
ज्वालामुखी मॉडल में, भौतिक बीजगणित के एक पेड़ के प्रत्येक ऑपरेटर तीन कार्यों के साथ एक संरचना में बदल जाता है: खुला, अगला, करीब। कार्यों के अलावा, ऑपरेटर में एक ऑपरेटिंग राज्य - राज्य होता है। ओपन फंक्शन स्टेटमेंट को शुरू करता है, अगला फंक्शन या तो अगले ट्यूपल (इंग्लिश ट्यूपल), या NULL पर वापस जाता है, अगर कोई ट्यूपल नहीं बचा है, तो क्लोज फंक्शन स्टेटमेंट को समाप्त कर देता है:
ऑपरेटरों को भौतिक बीजगणित के ऑपरेटरों के एक पेड़ के रूप में घोंसला बनाया जा सकता है। प्रत्येक ऑपरेटर, इस प्रकार, एक वास्तविक माध्यम पर मौजूद संबंध या एक आभासी संबंध, जो नेस्टेड ऑपरेटरों के ट्यूल को एनेमरेट करके बनाया गया है, के ट्यूपलों पर आधारित होता है:
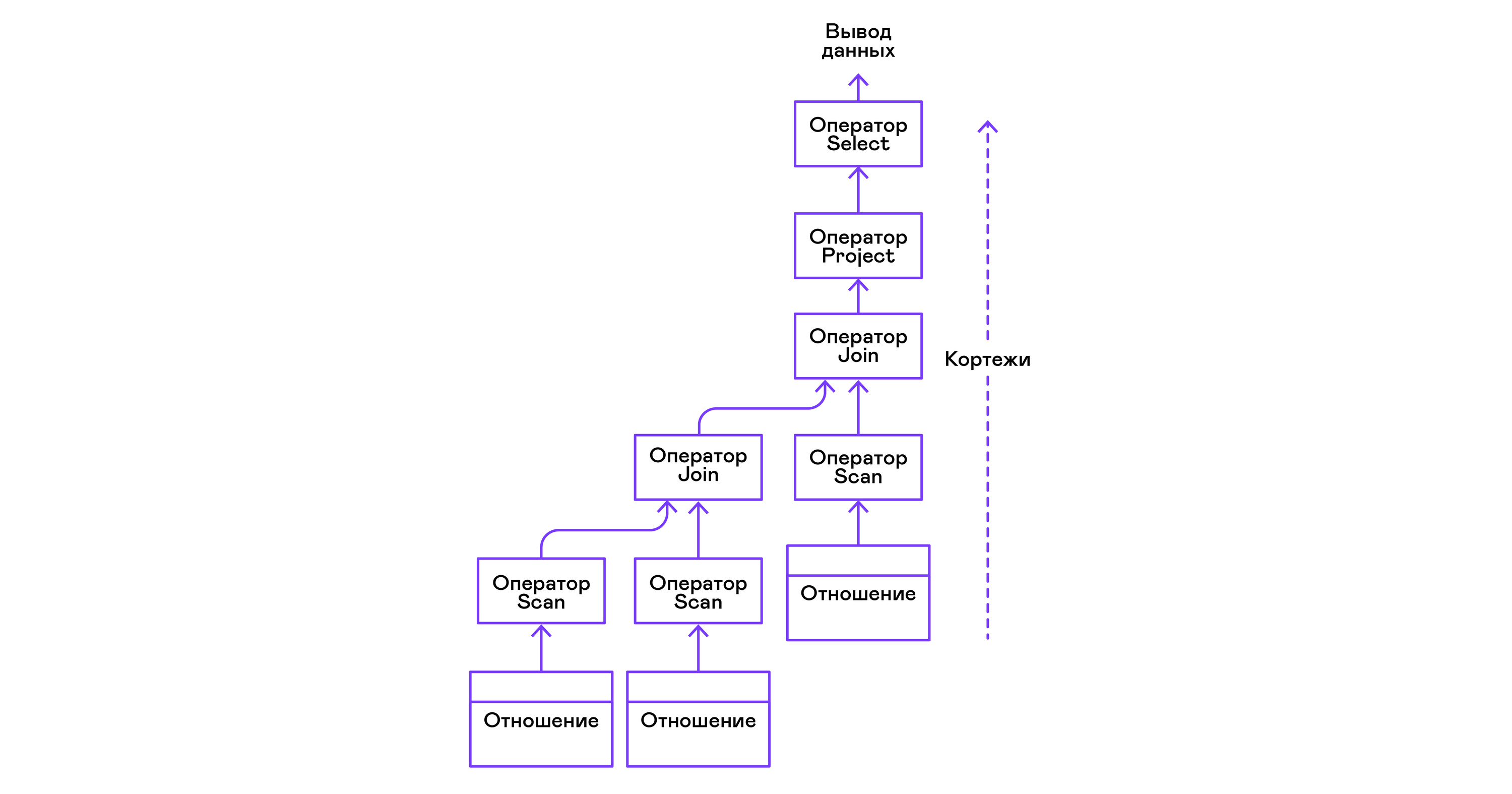
आधुनिक उच्च-स्तरीय भाषाओं के संदर्भ में, ऐसे ऑपरेटरों का पेड़ पुनरावृत्तियों का एक झरना है।
यहां तक कि संबंधपरक DBMS में औद्योगिक क्वेरी दुभाषियों को ज्वालामुखी मॉडल से हटा दिया जाता है, इसीलिए मैंने इसे पिगलेटिक इंटरप्रेटर के आधार के रूप में लिया।
PigletQL
मॉडल को प्रदर्शित करने के लिए, मैंने सीमित क्वेरी भाषा पिगलेटक्यूएल के दुभाषिया को विकसित किया। यह सी में लिखा गया है, एसक्यूएल की शैली में तालिकाओं के निर्माण का समर्थन करता है, लेकिन एक ही प्रकार तक सीमित है - 32-बिट सकारात्मक पूर्णांक। सभी टेबल स्मृति में हैं। सिस्टम एक एकल थ्रेड में संचालित होता है और इसमें लेनदेन तंत्र नहीं होता है।
PigletQL में कोई ऑप्टिमाइज़र नहीं है, और SELECT क्वेरीज़ को सीधे भौतिक बीजगणित के ऑपरेटर ट्री में संकलित किया जाता है। शेष प्रश्न (क्रिएट टेबल और इनसर्ट) प्राथमिक आंतरिक विचारों से सीधे काम करते हैं।
PigletQL में उदाहरण उपयोगकर्ता सत्र:
> ./pigletql > CREATE TABLE tab1 (col1,col2,col3); > INSERT INTO tab1 VALUES (1,2,3); > INSERT INTO tab1 VALUES (4,5,6); > SELECT col1,col2,col3 FROM tab1; col1 col2 col3 1 2 3 4 5 6 rows: 2 > SELECT col1 FROM tab1 ORDER BY col1 DESC; col1 4 1 rows: 2
लेक्सिकल और पार्सर
पिगलेटेक एक बहुत ही सरल भाषा है, और इसके कार्यान्वयन को लेक्सिकल और पार्सिंग विश्लेषण के चरणों में आवश्यक नहीं था।
लेक्सिकल विश्लेषक हाथ से लिखा गया है। क्वेरी स्ट्रिंग से एक विश्लेषक ऑब्जेक्ट ( scanner_t ) बनाया जाता है, जो एक-एक करके टोकन निकालता है:
scanner_t *scanner_create(const char *string); void scanner_destroy(scanner_t *scanner); token_t scanner_next(scanner_t *scanner);
पार्सिंग को पुनरावर्ती वंश विधि का उपयोग करके किया जाता है। सबसे पहले, parser_t ऑब्जेक्ट बनाया जाता है , जो लेक्सिकल एनालाइज़र (स्कैनर_टी) प्राप्त करने के बाद, अनुरोध के बारे में जानकारी के साथ क्वेरी_टी ऑब्जेक्ट को भरता है:
query_t *query_create(void); void query_destroy(query_t *query); parser_t *parser_create(void); void parser_destroy(parser_t *parser); bool parser_parse(parser_t *parser, scanner_t *scanner, query_t *query);
Query_t में पार्स करने का नतीजा PigletQL द्वारा समर्थित तीन प्रकार के क्वेरी में से एक है:
typedef enum query_tag { QUERY_SELECT, QUERY_CREATE_TABLE, QUERY_INSERT, } query_tag; typedef struct query_t { query_tag tag; union { query_select_t select; query_create_table_t create_table; query_insert_t insert; } as; } query_t;
PigletQL में क्वेरी का सबसे जटिल प्रकार SELECT है। यह डेटा संरचना से query_select_t से मेल खाती है:
typedef struct query_select_t { attr_name_t attr_names[MAX_ATTR_NUM]; uint16_t attr_num; rel_name_t rel_names[MAX_REL_NUM]; uint16_t rel_num; query_predicate_t predicates[MAX_PRED_NUM]; uint16_t pred_num; bool has_order; attr_name_t order_by_attr; sort_order_t order_type; } query_select_t;
संरचना में क्वेरी का विवरण (उपयोगकर्ता द्वारा मांगी गई विशेषताओं का एक सरणी), डेटा स्रोतों की एक सूची - रिश्ते, फ़िल्टरिंग ट्यूपल्स की भविष्यवाणी करता है, और परिणामों को सॉर्ट करने के लिए उपयोग की जाने वाली विशेषता के बारे में जानकारी शामिल है।
शब्दार्थ विश्लेषक
नियमित एसक्यूएल में शब्दार्थ विश्लेषण चरण में सूचीबद्ध तालिकाओं के अस्तित्व की जाँच करना, तालिकाओं में कॉलम और क्वेरी के भावों की जाँच करना शामिल है। तालिकाओं और स्तंभों से संबंधित जांच के लिए, डेटाबेस निर्देशिका का उपयोग किया जाता है, जहां डेटा संरचना के बारे में सभी जानकारी संग्रहीत होती है।
PigletQL में कोई जटिल अभिव्यक्तियाँ नहीं हैं, इसलिए तालिका और स्तंभों के कैटलॉग मेटाडेटा की जाँच करने के लिए क्वेरी जाँच कम हो जाती है। उदाहरण के लिए, चयनित क्वेरीज़, validate_select फ़ंक्शन द्वारा मान्य हैं। मैं इसे संक्षिप्त रूप में लाऊंगा:
static bool validate_select(catalogue_t *cat, const query_select_t *query) { for (size_t rel_i = 0; rel_i < query->rel_num; rel_i++) { if (catalogue_get_relation(cat, query->rel_names[rel_i])) continue; fprintf(stderr, "Error: relation '%s' does not exist\n", query->rel_names[rel_i]); return false; } if (!rel_names_unique(query->rel_names, query->rel_num)) return false; if (!attr_names_unique(query->attr_names, query->attr_num)) return false; return true; }
यदि अनुरोध मान्य है, तो अगला कदम पार्स ट्री को ऑपरेटर ट्री में संकलित करना है।
एक इंटरमीडिएट दृश्य में प्रश्न संकलन
पूर्ण-रूप से SQL व्याख्याताओं में, आमतौर पर दो मध्यवर्ती प्रतिनिधित्व होते हैं: तार्किक और भौतिक बीजगणित।
एक साधारण पिगलेटेक दुभाषिया अपने पार्सिंग पेड़ों, यानी, क्वेरी_क्रिएट_टेबल_ट और क्वेरी_इन्टर_ट संरचनाओं से सीधे टेट और इनसेट प्रश्नों का निर्माण करता है । अधिक जटिल चयनित प्रश्नों को एक एकल मध्यवर्ती प्रतिनिधित्व में संकलित किया जाता है, जिसे दुभाषिया द्वारा निष्पादित किया जाएगा।
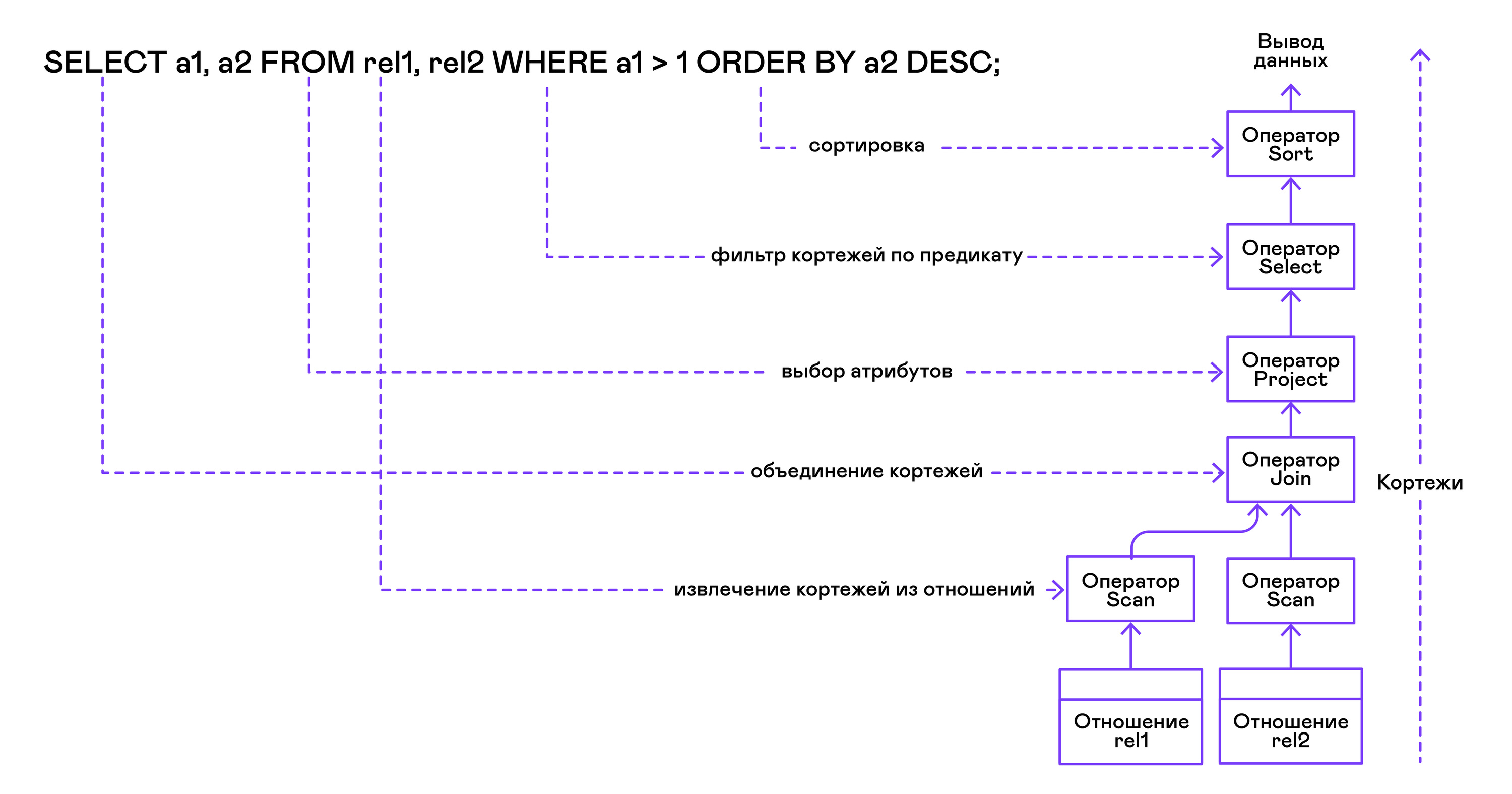
ऑपरेटर ट्री को निम्नलिखित अनुक्रम में पत्तियों से जड़ तक बनाया गया है:
क्वेरी के दाहिने हिस्से से ("... से रिश्ता 1, रिश्ता 2, ..."), वांछित संबंधों के नाम प्राप्त किए जाते हैं, जिनमें से प्रत्येक के लिए एक स्कैन स्टेटमेंट बनाया जाता है।
संबंधों से ट्यूपल्स को निकालते हुए, स्कैन ऑपरेटरों को ज्वाइन ऑपरेटर के माध्यम से एक बाएं तरफा बाइनरी ट्री में जोड़ा जाता है।
उपयोगकर्ता द्वारा अनुरोध किए गए गुण ("चयन attr1, attr2, ...") प्रोजेक्ट स्टेटमेंट द्वारा चुने गए हैं।
यदि कोई विधेय निर्दिष्ट किया जाता है ("... जहां = 1 और b> 10 ..."), तो ऊपर दिए गए पेड़ में चयन विवरण जोड़ा जाता है।
यदि परिणाम को सॉर्ट करने के लिए विधि निर्दिष्ट है ("... ORDER BY attr1 DESC"), तो सॉर्ट ऑपरेटर को पेड़ के शीर्ष पर जोड़ा जाता है।
PigletQL कोड में संकलन:
operator_t *compile_select(catalogue_t *cat, const query_select_t *query) { operator_t *root_op = NULL; { size_t rel_i = 0; relation_t *rel = catalogue_get_relation(cat, query->rel_names[rel_i]); root_op = scan_op_create(rel); rel_i += 1; for (; rel_i < query->rel_num; rel_i++) { rel = catalogue_get_relation(cat, query->rel_names[rel_i]); operator_t *scan_op = scan_op_create(rel); root_op = join_op_create(root_op, scan_op); } } root_op = proj_op_create(root_op, query->attr_names, query->attr_num); if (query->pred_num > 0) { operator_t *select_op = select_op_create(root_op); for (size_t pred_i = 0; pred_i < query->pred_num; pred_i++) { query_predicate_t predicate = query->predicates[pred_i]; } root_op = select_op; } if (query->has_order) root_op = sort_op_create(root_op, query->order_by_attr, query->order_type); return root_op; }
पेड़ बनने के बाद, अनुकूलन परिवर्तन आमतौर पर किए जाते हैं, लेकिन पिगलेटेक तुरंत मध्यवर्ती प्रतिनिधित्व के निष्पादन के चरण तक पहुंचता है।
एक अंतरिम प्रस्तुति का निष्पादन
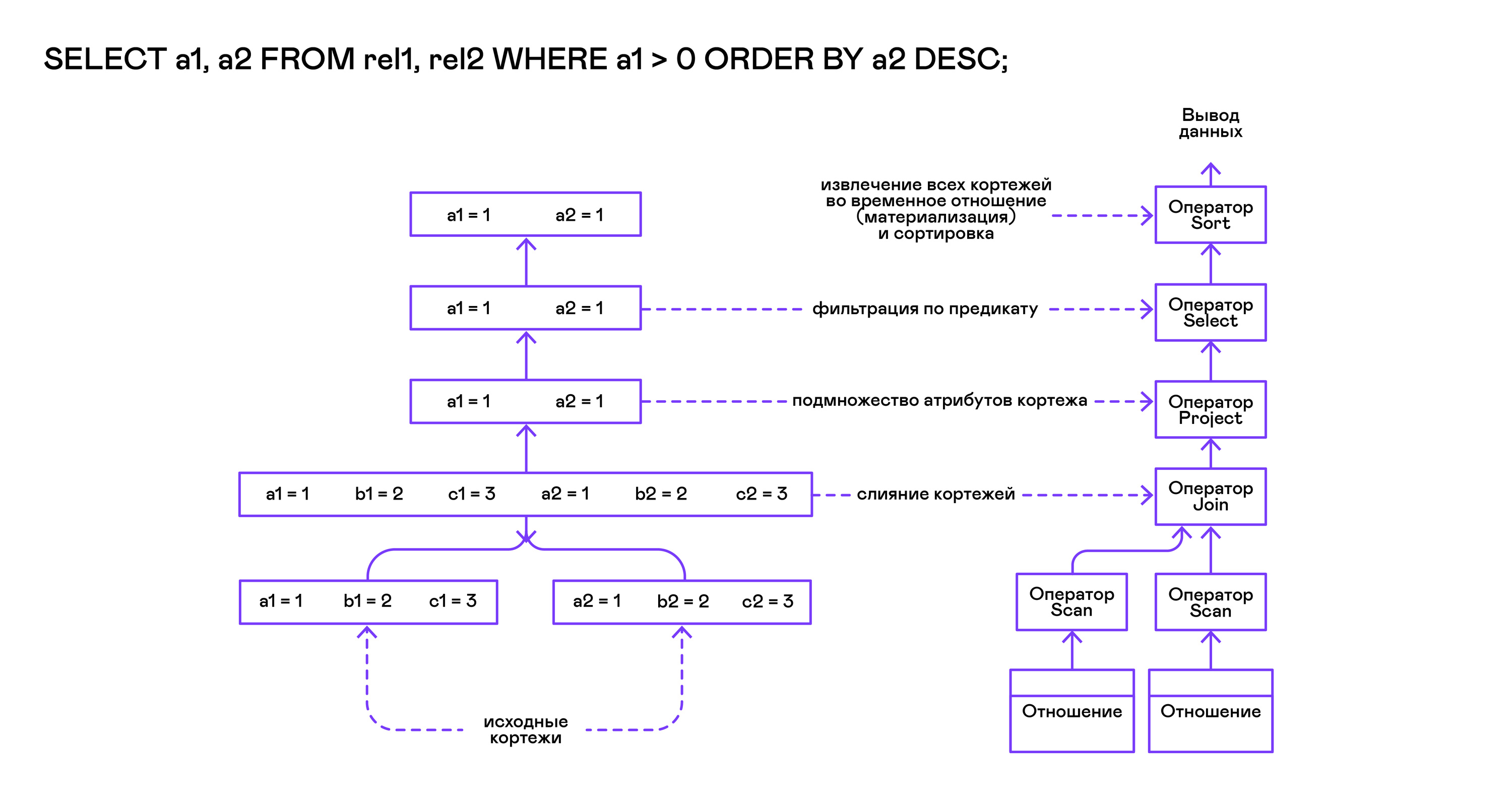
ज्वालामुखी मॉडल का तात्पर्य तीन सामान्य खुले / अगले / निकट संचालन के माध्यम से ऑपरेटरों के साथ काम करने के लिए एक इंटरफ़ेस से है। संक्षेप में, प्रत्येक ज्वालामुखी कथन एक पुनरावृत्त है जिसमें से एक-एक करके टुपल्स को "खींचा" जाता है, इसलिए निष्पादन के लिए इस दृष्टिकोण को पुल मॉडल भी कहा जाता है।
इन पुनरावृत्तियों में से प्रत्येक स्वयं नेस्टेड पुनरावृत्तियों के समान कार्यों को कॉल कर सकते हैं, मध्यवर्ती परिणामों के साथ अस्थायी तालिकाओं को बना सकते हैं, और आने वाले टुपल्स को परिवर्तित कर सकते हैं।
PigletQL में चयनित प्रश्नों का निष्पादन:
bool eval_select(catalogue_t *cat, const query_select_t *query) { operator_t *root_op = compile_select(cat, query); { root_op->open(root_op->state); size_t tuples_received = 0; tuple_t *tuple = NULL; while((tuple = root_op->next(root_op->state))) { if (tuples_received == 0) dump_tuple_header(tuple); dump_tuple(tuple); tuples_received++; } printf("rows: %zu\n", tuples_received); root_op->close(root_op->state); } root_op->destroy(root_op); return true; }
अनुरोध को पहले compile_select फ़ंक्शन द्वारा संकलित किया जाता है, जो ऑपरेटर ट्री की जड़ को लौटाता है, जिसके बाद उसी खुले / अगले / करीबी फ़ंक्शन को रूट ऑपरेटर पर कॉल किया जाता है। प्रत्येक अगले रिटर्न के लिए कॉल करता है या तो अगले ट्यूपल या NULL। उत्तरार्द्ध मामले में, इसका मतलब है कि सभी ट्यूपल्स को निकाला गया है, और करीबी पुनरावृत्त फ़ंक्शन को बुलाया जाना चाहिए।
परिणामी ट्यूपल्स को तालिका द्वारा मानक आउटपुट स्ट्रीम में पुनर्गणना और आउटपुट किया जाता है।
ऑपरेटरों
पिगलेटिक के बारे में सबसे दिलचस्प बात ऑपरेटर पेड़ है। मैं उनमें से कुछ का उपकरण दिखाऊंगा।
ऑपरेटरों के पास एक सामान्य इंटरफ़ेस होता है और इसमें ओपन / नेक्स्ट / क्लोज फंक्शन के पॉइंटर्स होते हैं और एक अतिरिक्त डिसऑर्डर फ़ंक्शन होता है, जो एक ही समय में पूरे ऑपरेटर ट्री के संसाधनों को रिलीज़ करता है:
typedef void (*op_open)(void *state); typedef tuple_t *(*op_next)(void *state); typedef void (*op_close)(void *state); typedef void (*op_destroy)(operator_t *op); struct operator_t { op_open open; op_next next; op_close close; op_destroy destroy; void *state; } ;
कार्यों के अलावा, ऑपरेटर में एक मनमाना आंतरिक स्थिति (राज्य सूचक) हो सकती है।
नीचे मैं दो दिलचस्प ऑपरेटरों के उपकरण का विश्लेषण करूंगा: सबसे सरल स्कैन और मध्यवर्ती संबंध प्रकार बनाना।
स्कैन स्टेटमेंट
किसी भी क्वेरी को शुरू करने वाला स्टेटमेंट स्कैन है। वह बस रिश्ते के सभी tuples से गुजरता है। स्कैन की आंतरिक स्थिति उस संबंध के लिए एक संकेतक है जहां से ट्यूपल्स को पुनः प्राप्त किया जाएगा, संबंध में अगले ट्यूपल का सूचकांक और उपयोगकर्ता को दिए गए वर्तमान ट्यूपल के लिए एक लिंक संरचना:
typedef struct scan_op_state_t { const relation_t *relation; uint32_t next_tuple_i; tuple_t current_tuple; } scan_op_state_t;
स्कैन स्टेट स्टेट बनाने के लिए, आपको सोर्स रिलेशन की आवश्यकता होती है; बाकी सब (संबंधित कार्यों के लिए संकेत) पहले से ही जाना जाता है:
operator_t *scan_op_create(const relation_t *relation) { operator_t *op = calloc(1, sizeof(*op)); assert(op); *op = (operator_t) { .open = scan_op_open, .next = scan_op_next, .close = scan_op_close, .destroy = scan_op_destroy, }; scan_op_state_t *state = calloc(1, sizeof(*state)); assert(state); *state = (scan_op_state_t) { .relation = relation, .next_tuple_i = 0, .current_tuple.tag = TUPLE_SOURCE, .current_tuple.as.source.tuple_i = 0, .current_tuple.as.source.relation = relation, }; op->state = state; return op; }
संबंध के पहले तत्व पर वापस स्कैन लिंक के मामले में खुला / बंद संचालन:
void scan_op_open(void *state) { scan_op_state_t *op_state = (typeof(op_state)) state; op_state->next_tuple_i = 0; tuple_t *current_tuple = &op_state->current_tuple; current_tuple->as.source.tuple_i = 0; } void scan_op_close(void *state) { scan_op_state_t *op_state = (typeof(op_state)) state; op_state->next_tuple_i = 0; tuple_t *current_tuple = &op_state->current_tuple; current_tuple->as.source.tuple_i = 0; }
अगला कॉल या तो अगला टपल लौटाता है, या NULL अगर रिलेशन में अधिक ट्यूपल नहीं हैं:
tuple_t *scan_op_next(void *state) { scan_op_state_t *op_state = (typeof(op_state)) state; if (op_state->next_tuple_i >= op_state->relation->tuple_num) return NULL; tuple_source_t *source_tuple = &op_state->current_tuple.as.source; source_tuple->tuple_i = op_state->next_tuple_i; op_state->next_tuple_i++; return &op_state->current_tuple; }
क्रमबद्ध कथन
सॉर्ट स्टेटमेंट उपयोगकर्ता द्वारा निर्दिष्ट क्रम में ट्यूपल का उत्पादन करता है। ऐसा करने के लिए, नेस्टेड ऑपरेटरों से प्राप्त ट्यूपल्स के साथ एक अस्थायी संबंध बनाएं और इसे सॉर्ट करें।
ऑपरेटर की आंतरिक स्थिति :
typedef struct sort_op_state_t { operator_t *source; attr_name_t sort_attr_name; sort_order_t sort_order; relation_t *tmp_relation; operator_t *tmp_relation_scan_op; } sort_op_state_t;
समय अनुपात (tmp_relation) पर अनुरोध (Sort_attr_name और Sort_order) में निर्दिष्ट विशेषताओं के अनुसार छंटनी की जाती है। यह सब तब होता है जब खुला कार्य कहा जाता है:
void sort_op_open(void *state) { sort_op_state_t *op_state = (typeof(op_state)) state; operator_t *source = op_state->source; source->open(source->state); tuple_t *tuple = NULL; while((tuple = source->next(source->state))) { if (!op_state->tmp_relation) { op_state->tmp_relation = relation_create_for_tuple(tuple); assert(op_state->tmp_relation); op_state->tmp_relation_scan_op = scan_op_create(op_state->tmp_relation); } relation_append_tuple(op_state->tmp_relation, tuple); } source->close(source->state); relation_order_by(op_state->tmp_relation, op_state->sort_attr_name, op_state->sort_order); op_state->tmp_relation_scan_op->open(op_state->tmp_relation_scan_op->state); }
अस्थायी संबंध के तत्वों की गणना अस्थायी संचालक tmp_relation_scan_op द्वारा की जाती है:
tuple_t *sort_op_next(void *state) { sort_op_state_t *op_state = (typeof(op_state)) state; return op_state->tmp_relation_scan_op->next(op_state->tmp_relation_scan_op->state);; }
करीबी समारोह में अस्थायी संबंध को निपटाया जाता है:
void sort_op_close(void *state) { sort_op_state_t *op_state = (typeof(op_state)) state; if (op_state->tmp_relation) { op_state->tmp_relation_scan_op->close(op_state->tmp_relation_scan_op->state); scan_op_destroy(op_state->tmp_relation_scan_op); relation_destroy(op_state->tmp_relation); op_state->tmp_relation = NULL; } }
यहां आप स्पष्ट रूप से देख सकते हैं कि अनुक्रमणिका के बिना स्तंभों पर संचालन क्यों काफी समय ले सकता है।
काम के उदाहरण
मैं पिगलेटिक प्रश्नों और भौतिक बीजगणित के संबंधित पेड़ों के कुछ उदाहरण दूंगा।
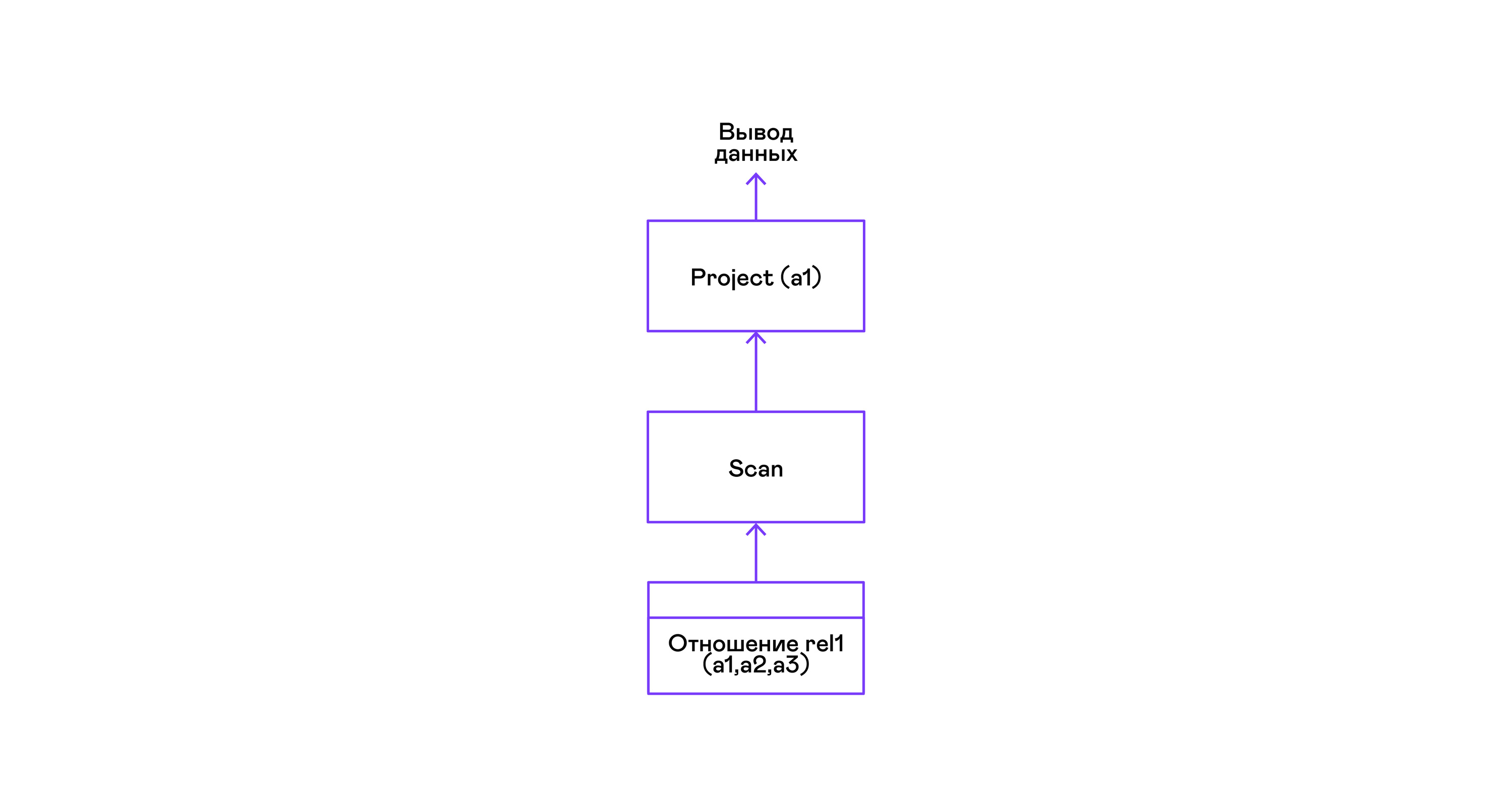
सबसे सरल उदाहरण जहां एक संबंध से सभी tuples चयनित हैं:
> ./pigletql > create table rel1 (a1,a2,a3); > insert into rel1 values (1,2,3); > insert into rel1 values (4,5,6); > select a1 from rel1; a1 1 4 rows: 2 >
सरलतम प्रश्नों के लिए, स्कैन संबंध से केवल टुपल्स प्राप्त करने के लिए उपयोग किया जाता है, और ट्यूपर से एकमात्र प्रोजेक्ट विशेषता का चयन करता है:
एक विधेय के साथ tuples चुनना:
> ./pigletql > create table rel1 (a1,a2,a3); > insert into rel1 values (1,2,3); > insert into rel1 values (4,5,6); > select a1 from rel1 where a1 > 3; a1 4 rows: 1 >
चुनिंदा बयान के द्वारा भविष्यवाणी व्यक्त की जाती है:
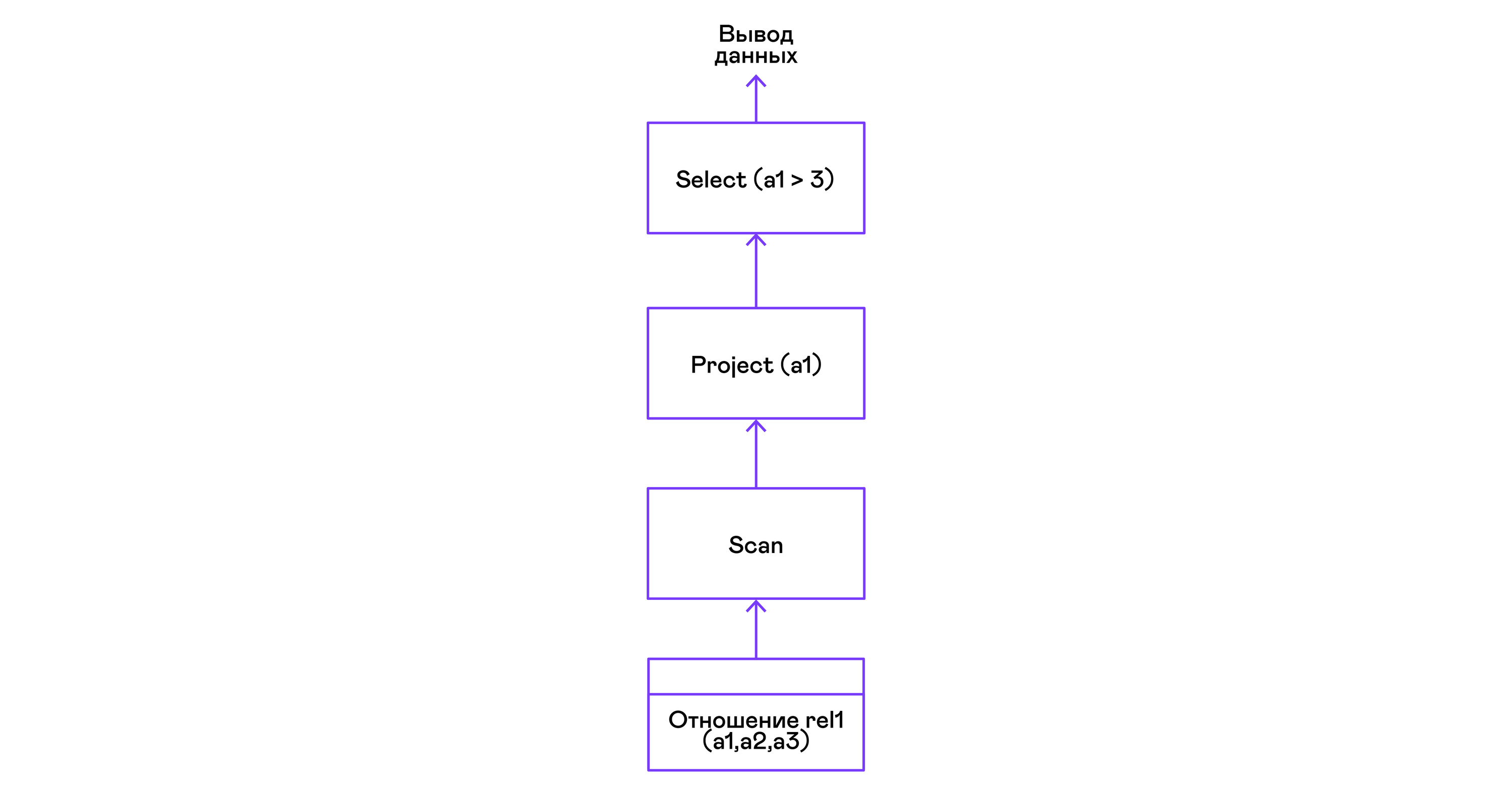
छँटाई के साथ tuples का चयन:
> ./pigletql > create table rel1 (a1,a2,a3); > insert into rel1 values (1,2,3); > insert into rel1 values (4,5,6); > select a1 from rel1 order by a1 desc; a1 4 1 rows: 2
ओपन कॉल में स्कैन सॉर्ट ऑपरेटर एक अस्थायी संबंध बनाता है ( भौतिक करता है ), वहां आने वाले सभी ट्यूपल्स को रखता है, और पूरे को सॉर्ट करता है। उसके बाद, अगली कॉल में, यह उपयोगकर्ता द्वारा निर्दिष्ट क्रम में अस्थायी संबंध से ट्यूपल्स को संक्रमित करता है:

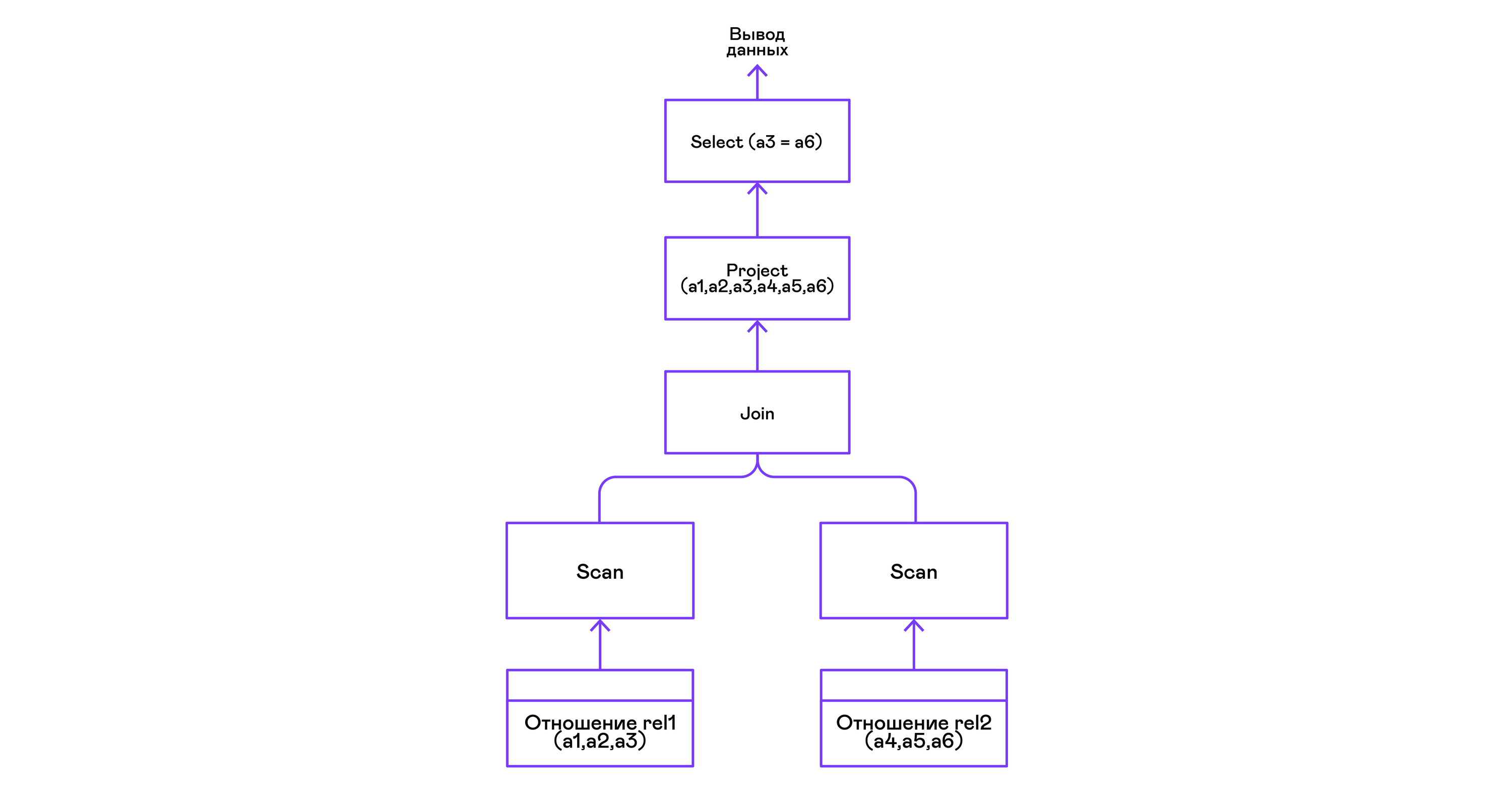
एक विधेय के साथ दो संबंधों के संयोजन
> ./pigletql > create table rel1 (a1,a2,a3); > insert into rel1 values (1,2,3); > insert into rel1 values (4,5,6); > create table rel2 (a4,a5,a6); > insert into rel2 values (7,8,6); > insert into rel2 values (9,10,6); > select a1,a2,a3,a4,a5,a6 from rel1, rel2 where a3=a6; a1 a2 a3 a4 a5 a6 4 5 6 7 8 6 4 5 6 9 10 6 rows: 2
पिगलेटेक में शामिल ऑपरेटर किसी भी जटिल एल्गोरिदम का उपयोग नहीं करता है, लेकिन बस बाएं और दाएं उपप्रकारों के ट्यूपल्स के सेट से कार्टेशियन उत्पाद बनाता है। यह बहुत अक्षम है, लेकिन एक डेमो दुभाषिया के लिए यह करेगा:
निष्कर्ष
अंत में, मैं ध्यान देता हूं कि यदि आप एसक्यूएल के समान भाषा की व्याख्या कर रहे हैं, तो आपको संभवतः कई उपलब्ध रिलेशनल डेटाबेस में से किसी एक को लेना चाहिए। हजारों व्यक्ति-वर्षों को आधुनिक ऑप्टिमाइज़र और लोकप्रिय डेटाबेस के क्वेरी दुभाषियों में निवेश किया गया है, और यहां तक कि सबसे सरल सामान्य-उद्देश्य डेटाबेस को विकसित करने में वर्षों लगते हैं।
डेमो भाषा पिगलेटक्यूएल एसक्यूपी इंटरप्रेटर के काम का अनुकरण करती है, लेकिन वास्तव में हम ज्वालामुखी वास्तुकला के केवल व्यक्तिगत तत्वों का उपयोग करते हैं और केवल उन (दुर्लभ!) प्रकार के प्रश्नों के लिए जो रिलेशनल मॉडल के ढांचे में व्यक्त करना मुश्किल है।
फिर भी, मैं दोहराता हूं: यहां तक कि ऐसे दुभाषियों की वास्तुकला के साथ एक सतही परिचय उन मामलों में उपयोगी है जहां डेटा धाराओं के साथ लचीले ढंग से काम करना आवश्यक है।
साहित्य
यदि आप डेटाबेस के विकास के बुनियादी मुद्दों में रुचि रखते हैं, तो पुस्तकें "डेटाबेस सिस्टम कार्यान्वयन" (गार्सिया-मोलिना एच।, उलमैन जेडी, विडोम जे। 2000) से बेहतर हैं, आपको नहीं मिलेगा।
इसका एकमात्र दोष एक सैद्धांतिक अभिविन्यास है। व्यक्तिगत रूप से, मुझे यह पसंद है जब कोड या यहां तक कि एक डेमो प्रोजेक्ट के ठोस उदाहरण सामग्री से जुड़े होते हैं। इसके लिए, आप "डेटाबेस डिजाइन और कार्यान्वयन" (Sciore E., 2008) पुस्तक का उल्लेख कर सकते हैं, जो जावा में एक रिलेशनल डेटाबेस के लिए पूरा कोड प्रदान करता है।
सबसे लोकप्रिय संबंधपरक डेटाबेस अभी भी ज्वालामुखी की थीम पर विविधताओं का उपयोग करते हैं। मूल प्रकाशन एक बहुत ही सुलभ भाषा में लिखा गया है और इसे Google विद्वान पर आसानी से पाया जा सकता है: "ज्वालामुखी - एक एक्स्टेंसिबल और समानांतर क्वेरी मूल्यांकन प्रणाली" (ग्रेफ जी, 1994)।
हालाँकि पिछले कुछ दशकों में SQL दुभाषिए काफी बदल गए हैं, लेकिन इन प्रणालियों की सामान्य संरचना बहुत लंबे समय से नहीं बदली है। आप एक लेखक द्वारा एक समीक्षा पत्र से इसका अनुमान लगा सकते हैं, "बड़े डेटाबेस के लिए क्वेरी मूल्यांकन तकनीक" (ग्रैफ जी। 1993)।