सभी को नमस्कार। मैं आपको माइक्रोसर्विस के बारे में बताता हूं, लेकिन पोस्ट में वादिम मैडिसन की तुलना में "माइक्रोसेपर के बारे में हमें क्या पता है" की तुलना में थोड़ा अलग दृष्टिकोण से। सामान्य तौर पर, मैं खुद को एक डेटाबेस डेवलपर मानता हूं। माइक्रोसर्विसेस का इससे क्या लेना-देना है? एविटो उपयोग करता है: वर्टिका, पोस्टग्रेसीक्यूएल, रेडिस, मोंगोबीडी, टारनटूल, वोल्ट्टीडीबी, SQLite ... कुल मिलाकर, हमारे पास 849+ सेवाओं के लिए 456+ डेटाबेस हैं। और किसी तरह आपको इसके साथ रहने की जरूरत है।
इस पोस्ट में मैं आपको बताऊंगा कि हमने माइक्रोसेस्क आर्किटेक्चर में डेटा डिस्कवरी को कैसे लागू किया। यह पोस्ट Highload ++ 2018 के साथ मेरी रिपोर्ट की एक मुफ्त प्रतिलिपि है, वीडियो को यहां देखा जा सकता है ।

हर किसी को पता होना चाहिए कि आधारों के संदर्भ में एक माइक्रोसवर्क वास्तुकला कैसे बनाई जानी चाहिए। यहां वह पैटर्न है, जो हर कोई आमतौर पर शुरू करता है। सेवाओं के बीच एक सामान्य आधार है। स्लाइड पर, नारंगी आयताकार सेवाएं हैं, उनके बीच एक सामान्य आधार है।
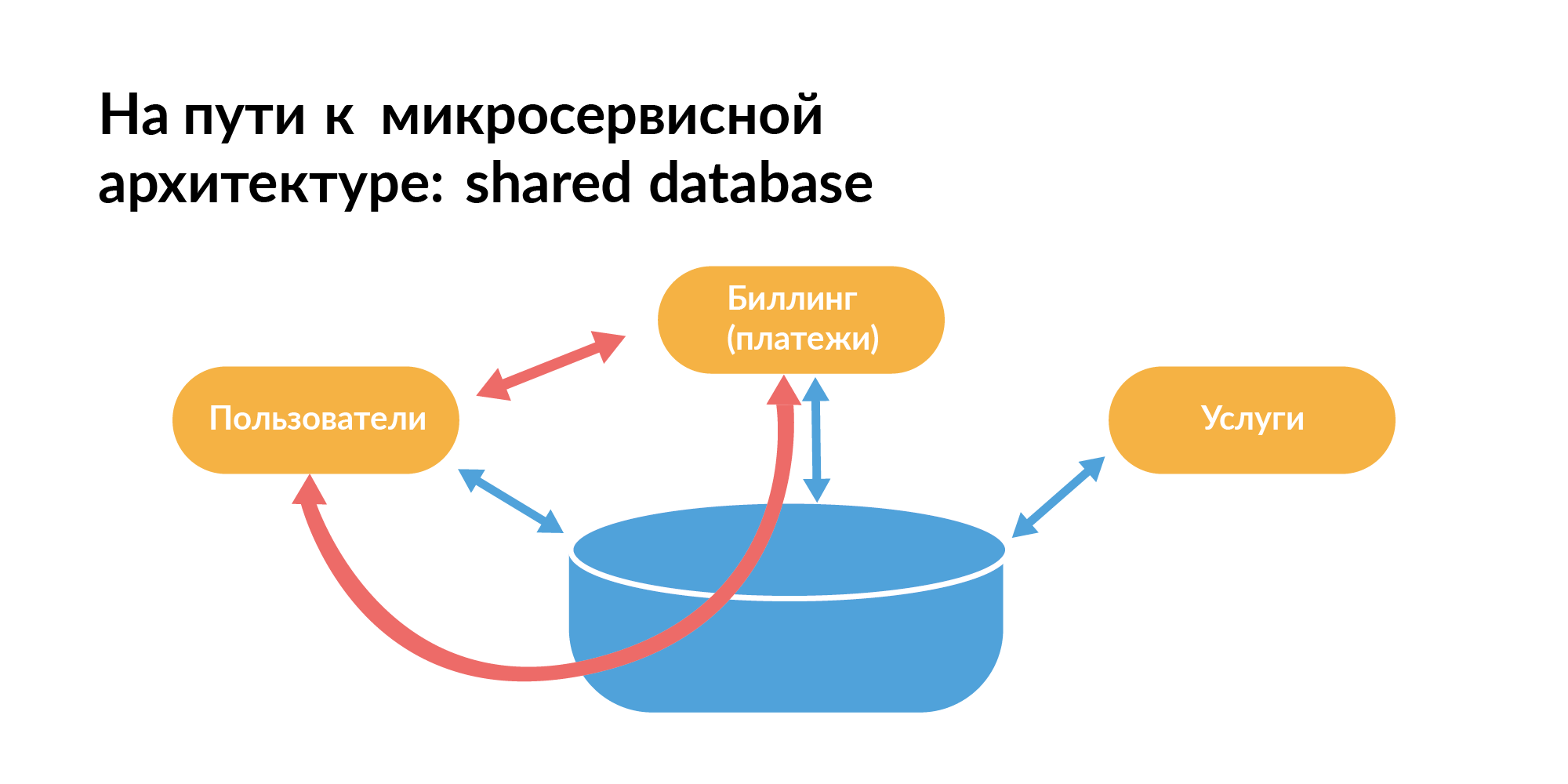
आप इस तरह से नहीं रह सकते, क्योंकि आप अलगाव में सेवाओं का परीक्षण नहीं कर सकते, जब उनके बीच सीधे संचार के अलावा, डेटाबेस के माध्यम से भी संचार होता है। एक सेवा अनुरोध किसी अन्य सेवा को धीमा कर सकता है। यह बुरा है।

माइक्रोसैस आर्किटेक्चर के लिए डेटाबेस के साथ काम करने के दृष्टिकोण से, डेटाबेस-प्रति-सेवा पैटर्न का उपयोग किया जाना चाहिए - प्रत्येक सेवा का अपना डेटाबेस होता है। यदि डेटाबेस में बहुत अधिक शार्क हैं, तो आधार को साझा किया जाना चाहिए ताकि वे सिंक्रनाइज़ हो जाएं। यह एक सिद्धांत है, लेकिन वास्तव में ऐसा नहीं है।

वास्तविक कंपनियों में, वे न केवल माइक्रोसर्विसेज का उपयोग करते हैं, बल्कि एक मोनोलिथ भी हैं। सही ढंग से लिखी गई सेवाएँ हैं। और पुरानी सेवाएं हैं जो अभी भी एक सामान्य आधार पैटर्न का उपयोग करती हैं।
वादिम मैडिसन ने अपनी प्रस्तुति में इस तस्वीर को जुड़ाव के साथ दिखाया। केवल उन्होंने इसे एक घटक के बिना दिखाया, और इसमें नेटवर्क एक समान था। केंद्र में इस नेटवर्क में एक बिंदु है जो कई बिंदुओं (माइक्रोसर्विस) से जुड़ा है। यह एक मोनोलिथ है। यह आरेख में छोटा है। लेकिन वास्तव में, मोनोलिथ बड़ा है। जब हम एक वास्तविक कंपनी के बारे में बात करते हैं, तो आपको सूक्ष्मजीवों के सह-अस्तित्व, जन्म और आउटगोइंग की बारीकियों को समझने की आवश्यकता है, लेकिन फिर भी महत्वपूर्ण अखंड वास्तुकला।
नियोजन स्तर पर एक माइक्रोसिस्ट आर्किटेक्चर के लिए एक मोनोलिथ फिर से कैसे लिखता है? बेशक, यह डोमेन मॉडलिंग है। हर जगह यह कहता है कि आपको डोमेन मॉडलिंग करने की आवश्यकता है। लेकिन, उदाहरण के लिए, हमने कई सालों तक एविटो में डोमेन मॉडलिंग के बिना माइक्रोसॉफ़्ट बनाए। फिर मैंने इसे और डेटाबेस डेवलपर्स को लिया। हम संपूर्ण डेटा धाराओं से अवगत हैं। यह ज्ञान एक डोमेन मॉडल को डिजाइन करने में मदद करता है।

डेटा की खोज की एक क्लासिक व्याख्या है - यह विभिन्न निष्कर्षों पर बिखरे हुए डेटा के साथ काम करने के लिए है ताकि कुल निष्कर्ष निकाला जा सके और कोई भी सही निष्कर्ष निकाला जा सके। यह वास्तव में सभी विपणन बकवास है। ये परिभाषाएँ हैं कि कैसे सभी डेटा को माइक्रोसॉफ़्ट से स्टोरेज में डाउनलोड किया जाए। इसके बारे में मैंने कई साल पहले रिपोर्ट की थी, हम इस पर ध्यान नहीं देंगे।
मैं आपको एक अन्य प्रक्रिया के बारे में बताऊंगा, जो कि माइक्रो सर्विस पर स्विच करने की प्रक्रिया के करीब है। मैं एक तरीका दिखाना चाहता हूं कि आप कैसे डेटा के संदर्भ में एक सतत विकसित प्रणाली की जटिलता को समझ सकते हैं, जो कि माइक्रोसोर्सेज के संदर्भ में है। सैकड़ों सेवाओं, ठिकानों, टीमों, लोगों की पूरी तस्वीर कहाँ देखें? वास्तव में, यह प्रश्न रिपोर्ट का मुख्य विचार है।

इस microservice वास्तुकला में नहीं मरने के लिए, आप एक डिजिटल जुड़वां की जरूरत है। आपकी कंपनी हर उस चीज़ की समग्रता है जो तकनीकी आधारभूत संरचना प्रदान करती है। आपको इन सभी कठिनाइयों की एक पर्याप्त छवि बनाने की आवश्यकता है, जिसके आधार पर आप समस्याओं को जल्दी से हल कर सकते हैं। और यह एक विश्लेषणात्मक भंडार नहीं है।

ऐसे डिजिटल ट्विन के लिए हम कौन से कार्य निर्धारित कर सकते हैं? आखिरकार, यह सब सरलतम डेटा खोज के साथ शुरू हुआ।
सवाल:
- क्या सेवाएं महत्वपूर्ण डेटा संग्रहीत करती हैं?
- किस व्यक्तिगत डेटा में संग्रहीत नहीं है?
- आपके पास सैकड़ों ठिकाने हैं। क्या व्यक्तिगत डेटा है? और किसमें नहीं?
- सेवाओं के बीच महत्वपूर्ण डेटा प्रवाह कैसे होता है?
- उदाहरण के लिए, सेवा में व्यक्तिगत डेटा नहीं था, और फिर वह बस को सुनना शुरू कर दिया, और वे दिखाई दिए। जब वे मिटाए जाते हैं तो डेटा की प्रतिलिपि कहाँ होती है?
- कौन किस डेटा के साथ काम कर सकता है?
- कौन सेवा के माध्यम से सीधे पहुंच सकता है, कुछ डेटाबेस के माध्यम से, कुछ बस के माध्यम से?
- कौन एक अन्य सेवा के माध्यम से एपीआई हैंडल (अनुरोध) को खींच सकता है और कुछ डाउनलोड कर सकता है?
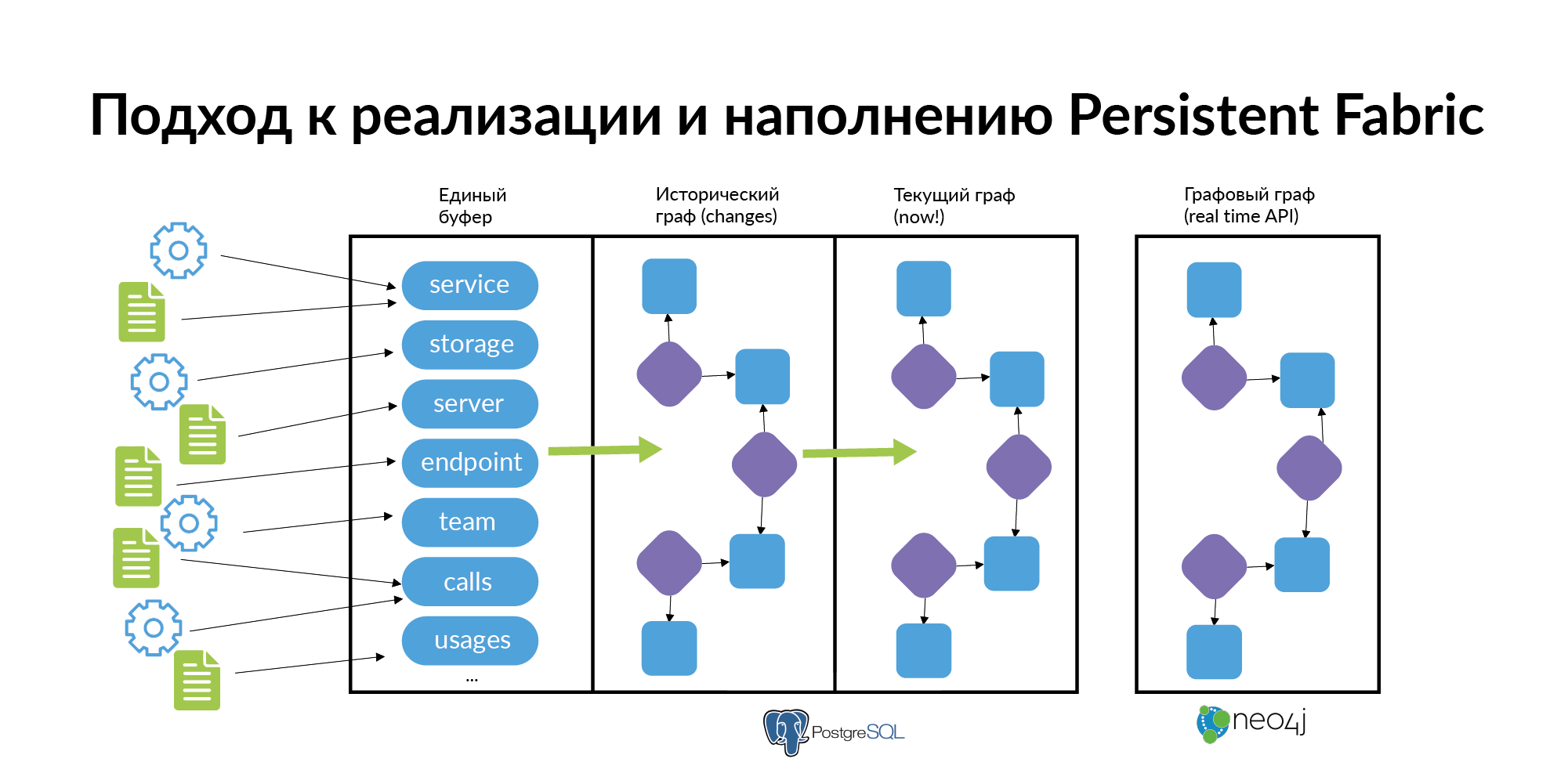
इन सवालों का जवाब लगभग हमेशा तत्वों का एक ग्राफ, रिश्तों का एक ग्राफ है। इस ग्राफ को ताजा आंकड़ों के साथ भरा, अद्यतन और बनाए रखा जाना चाहिए। हमने इस ग्राफ को परसेंट फैब्रिक (अनुवाद में - याद रखने वाला कपड़ा) कहने का फैसला किया। यहाँ उसका दृश्य है।
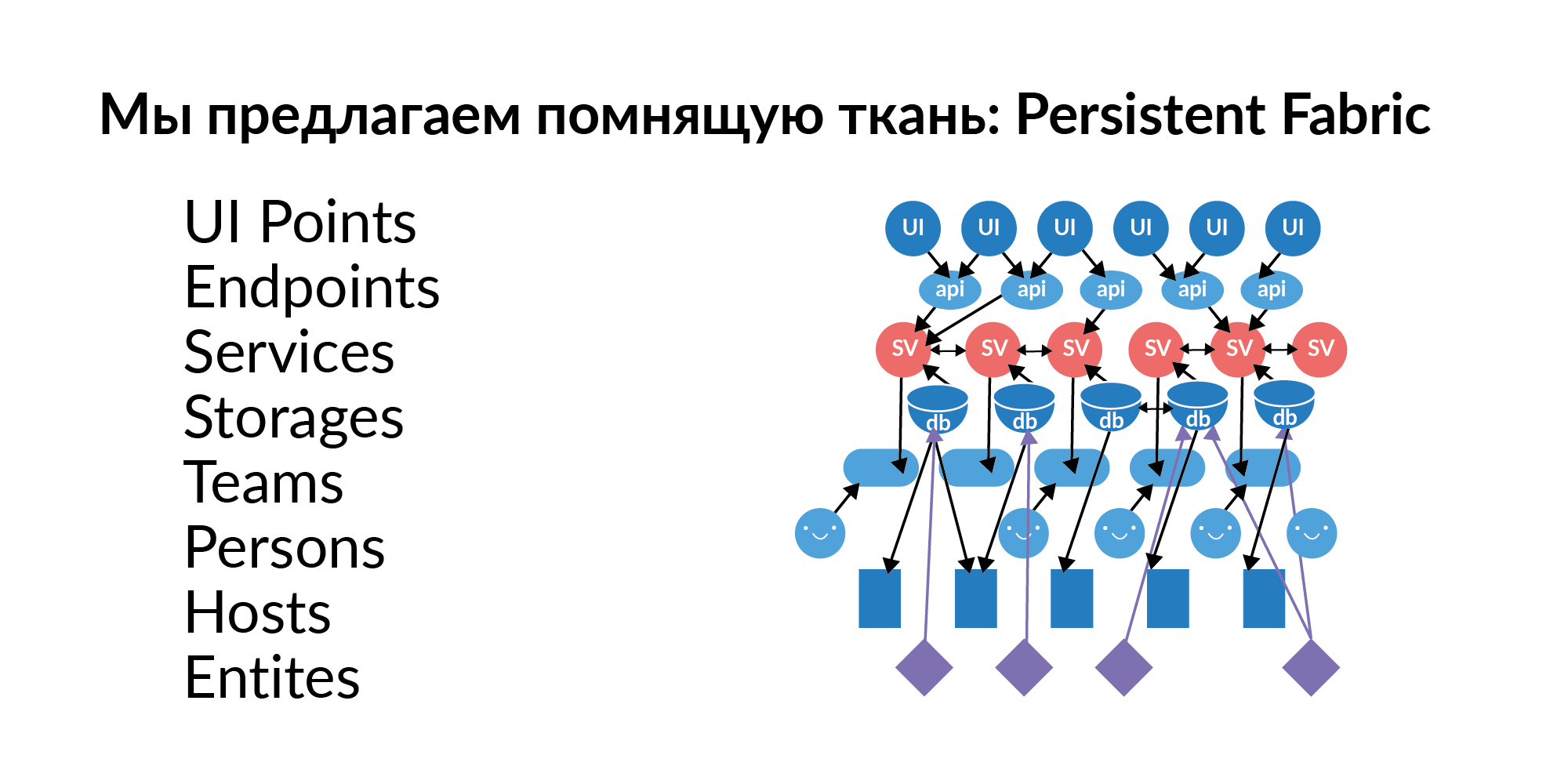
आइए देखें कि इस याद रखने वाले कपड़े में क्या हो सकता है।
इंटरफ़ेस बिंदु । ये ग्राफिक इंटरफ़ेस के साथ उपयोगकर्ता इंटरैक्शन के तत्व हैं। एक पृष्ठ पर कई UI बिंदु हो सकते हैं। ये हैं, अपेक्षाकृत बोलने, कस्टम कुंजी क्रियाएँ।
समापन बिंदु । यूआई अंक झटका समापन बिंदु। रूसी परंपरा में, इसे पेन कहा जाता है। सेवाओं के हैंडल। समापन बिंदु सेवाओं को खींचते हैं।
सेवाएं। सैकड़ों सेवाएं। सेवाएँ एक दूसरे से जुड़ी हुई हैं। हम समझते हैं कि कौन सी सेवा सेवा खींच सकती है। हम समझते हैं कि यूआई अंक पर कॉल करने से चेन में कौन सी सेवाएं कॉल की जा सकती हैं।
मामले (एक तार्किक अर्थ में) । भंडारण अवधि के रूप में आधार बुरा लगता है, क्योंकि यह शब्द कुछ विश्लेषणात्मक को संदर्भित करता है। अब हम डेटाबेस को स्टोरेज मानते हैं। उदाहरण के लिए, Redis, PostgreSQL, टारनटूल। यदि कोई सेवा डेटाबेस का उपयोग करती है, तो यह आमतौर पर कई डेटाबेस का उपयोग करती है।
- लंबी अवधि के डेटा भंडारण के लिए, उदाहरण के लिए, PostgreSQL।
- रेडिस का उपयोग कैश के रूप में किया जाता है।
- टारनटूल, जो डेटा स्ट्रीम में कुछ गणना कर सकता है।
मेजबान। डेटाबेस में मेजबानों की तैनाती है। एक आधार, एक रेडिस वास्तव में 16 मशीनों (मास्टर रिंग) पर और दूसरा 16 जीवित दास पर रह सकता है। यह इस बात की समझ देता है कि आपको किन सर्वरों तक पहुंच को प्रतिबंधित करना है ताकि कुछ महत्वपूर्ण डेटा लीक न हो।
संस्थाओं । डेटाबेस में संस्थाओं को संग्रहीत किया जाता है। संस्थाओं के उदाहरण: उपयोगकर्ता, घोषणा, भुगतान। संस्थाओं को कई डेटाबेस में संग्रहीत किया जा सकता है। और यहां यह जानना महत्वपूर्ण नहीं है कि यह इकाई है। यह जानना महत्वपूर्ण है कि इस इकाई का एक स्रोत गोल्डन सोर्स है। गोल्डन सोर्स वह आधार है जहां एक इकाई बनाई और संपादित की जाती है। अन्य सभी आधार कार्यात्मक कैश हैं। एक महत्वपूर्ण बिंदु। यदि, भगवान न करे, एक इकाई के पास दो स्वर्ण स्रोत हैं, तो अलग किए गए स्रोतों का एक श्रमसाध्य समन्वय आवश्यक है। यदि हम इस सेवा को नई कार्यक्षमता के साथ समृद्ध करना चाहते हैं, तो डेटाबेस में जो इकाइयाँ हैं, उन्हें सेवा तक पहुँच दी जानी चाहिए।
टीमें । टीमें जो स्वयं सेवाएं प्रदान करती हैं। एक सेवा जो टीमों से संबंधित नहीं है वह एक खराब सेवा है। किसी को जिम्मेदार ठहराना उसके लिए कठिन है।
अब मैं वादिम मैडिसन की रिपोर्ट के साथ दृढ़ता से संबंध स्थापित करूंगा, क्योंकि उन्होंने उल्लेख किया है कि जो व्यक्ति अंतिम प्रतिबद्ध था, वह सेवाओं में परिलक्षित होता है। यह एक अच्छा शुरुआती बिंदु है। लेकिन लंबे समय में, यह बुरा है, क्योंकि जो व्यक्ति आखिरी प्रतिबद्ध है वह छोड़ सकता है।
इसलिए, आपको टीम, उनमें मौजूद लोगों और उनकी भूमिका को जानना होगा। हमें ऐसा सरल ग्राफ मिला है, जहां प्रत्येक परत पर कई सौ तत्व हैं। क्या आप एक ऐसी प्रणाली जानते हैं, जहां यह सब संग्रहीत किया जा सकता है?
प्रमुख बिंदु। इस परसेंट फैब्रिक को जीने के लिए, इसे सिर्फ एक बार भरना नहीं चाहिए। सेवाएं बनाई जाती हैं, वे मर जाते हैं, भंडारण आवंटित किया जाता है, वे सर्वर के चारों ओर घूमते हैं, टीमें बनाई जाती हैं, टूट जाती हैं, लोग अन्य टीमों में स्विच करते हैं। प्रविष्टियाँ नई हैं, नई सेवाओं में जोड़ी गई हैं, हटा दी गई हैं। जीयूआई के दृष्टिकोण से एंडपॉइंट बनाए जाते हैं, पंजीकृत होते हैं, उपयोगकर्ता प्रक्षेपवक्र भी फिर से तैयार किए जाते हैं। सबसे महत्वपूर्ण बात यह नहीं है कि कहीं न कहीं आपको इसे तकनीकी रूप से संग्रहीत करने की आवश्यकता है। सबसे महत्वपूर्ण बात यह है कि हर पर्सेंटली फैब्रिक लेयर को नया और नया बनाया जाए। यह अद्यतन है।
मैं परतों के माध्यम से चलने का प्रस्ताव करता हूं। मैं यह बताऊंगा कि हम इसे कैसे करते हैं। मैं दिखाऊंगा कि यह व्यक्तिगत परतों के स्तर पर कैसे किया जा सकता है।

टीम के बारे में जानकारी 1 सी के संगठनात्मक ढांचे से ली जा सकती है। यहां मैं यह बताना चाहता हूं कि परसेंट फैब्रिक को आबाद करने के लिए पूरे विशालकाय ग्राफ को भरने की जरूरत नहीं है। प्रत्येक परत को सही ढंग से भरने की आवश्यकता है।

लोगों की जानकारी LDAP से ली जा सकती है। एक व्यक्ति अलग-अलग टीमों में अलग-अलग भूमिकाएँ ले सकता है। यह बिल्कुल सामान्य है। अब हमने एविटो पीपल सिस्टम बनाया है और इसमें से हम लोगों को टीमों और उनकी भूमिकाओं के लिए बाध्य करते हैं। सबसे महत्वपूर्ण बात यह है कि इस तरह के सरल डेटा इसलिए जाते हैं ताकि वे कम से कम लिंक के सिरों पर लिंक रखें, ताकि टीम के नाम 1 सी संगठनात्मक संरचना से टीमों के अनुरूप हों।
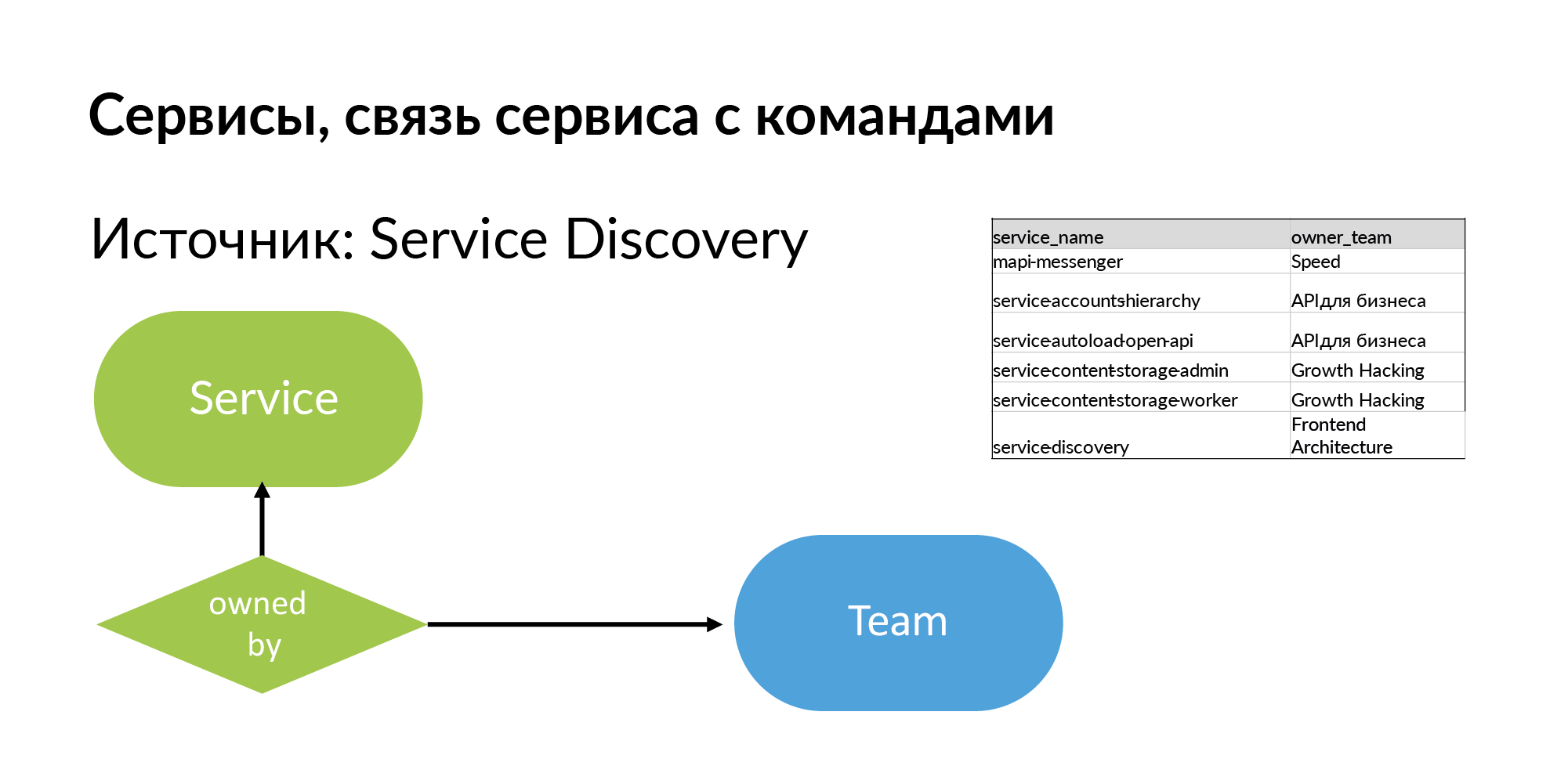
सेवाएं। सेवा के लिए आपको नाम और टीम प्राप्त करने की आवश्यकता है जो इसका मालिक है। स्रोत सेवा डिस्कवरी है। यह वह प्रणाली है जिसका उल्लेख वादिम मैडिसन ने एटलस नाम से किया है। एटलस सेवाओं की एक सामान्य रजिस्ट्री है।
यह समझना उपयोगी है कि एटलस जैसे लगभग सभी सिस्टम 95% सेवाओं के बारे में जानकारी संग्रहीत करते हैं। ऐसी प्रणालियों में 5% सेवाएँ अनुपस्थित हैं, क्योंकि एटलस में पंजीकरण के बिना बनाई गई पुरानी सेवाएं। और जब आप इस योजना के साथ काम करना शुरू करते हैं, तो आपको लगता है कि आप क्या याद कर रहे हैं।

भंडारण सामान्य रिपोजिटरी हैं। यह PostgreSQL, MongoDB, Memcache, Vertica हो सकता है। हमारे पास स्टोरेज डिस्कवरी के कई स्रोत हैं। NoSQL डेटाबेस एटलस के अपने आधे हिस्से का उपयोग करते हैं। PostgreSQL डेटाबेस के बारे में जानकारी के लिए, yaml पार्सिंग का उपयोग किया जाता है। लेकिन वे अपने स्टोरेज डिस्कवरी को अधिक सही बनाना चाहते हैं।
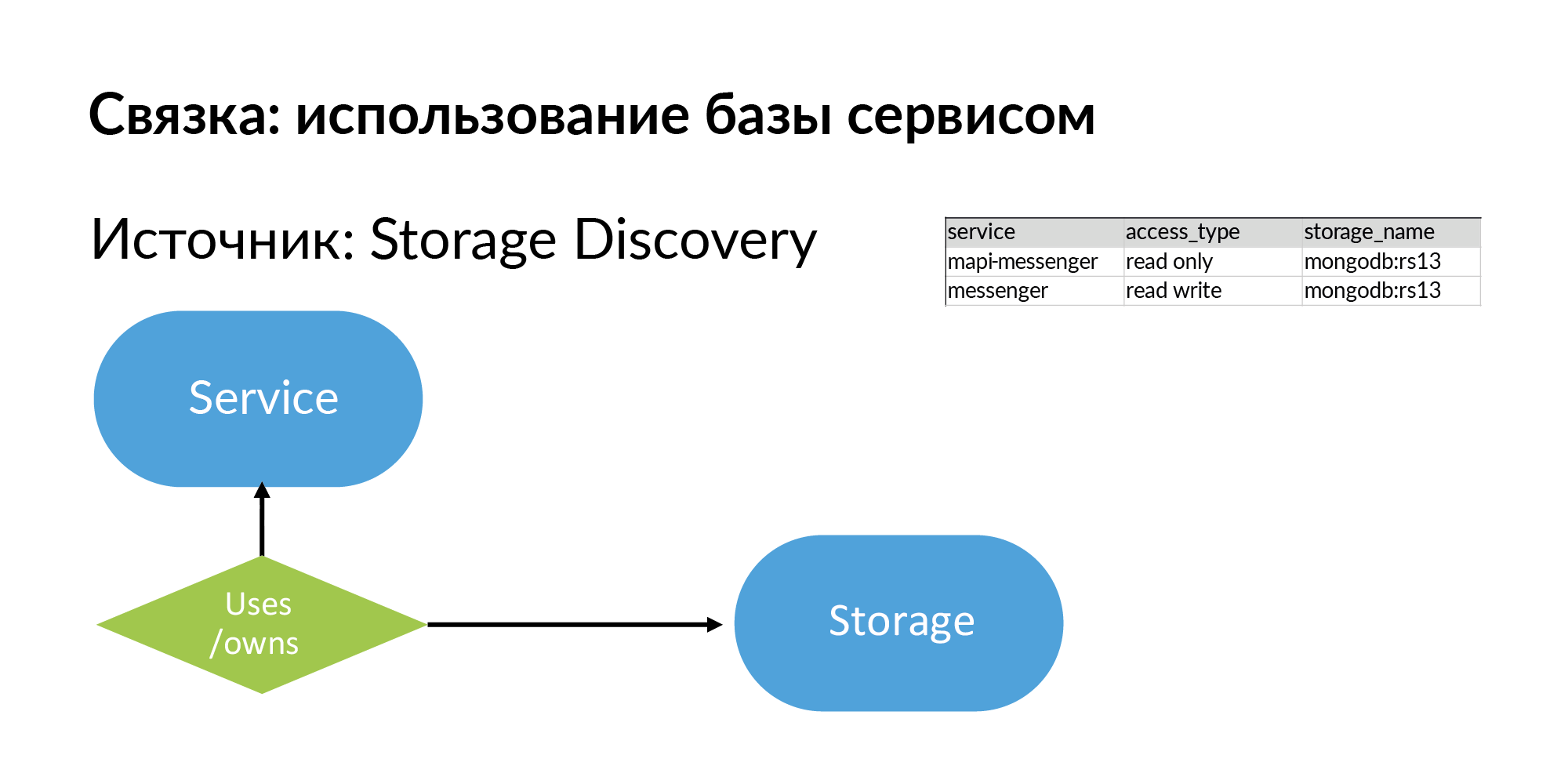
इसलिए, स्टोरेज और सेवा के उपयोग, अच्छी तरह से या मालिक (ये अलग-अलग प्रकार) के भंडारण के बारे में जानकारी है। देखें, मैंने जो कुछ भी वर्णित किया है, वह सिद्धांत रूप में, काफी सरल है, इसे Google पत्रक में भी भरा जा सकता है।
इससे क्या हो सकता है? आइए कल्पना करें कि यह एक ग्राफ है। ग्राफ के साथ कैसे काम करें? इसे ग्राफ बेस में जोड़ें। उदाहरण के लिए, Neo4j में। ये पहले से ही वास्तविक प्रश्नों के उदाहरण हैं और इन प्रश्नों के परिणामों के उदाहरण हैं।
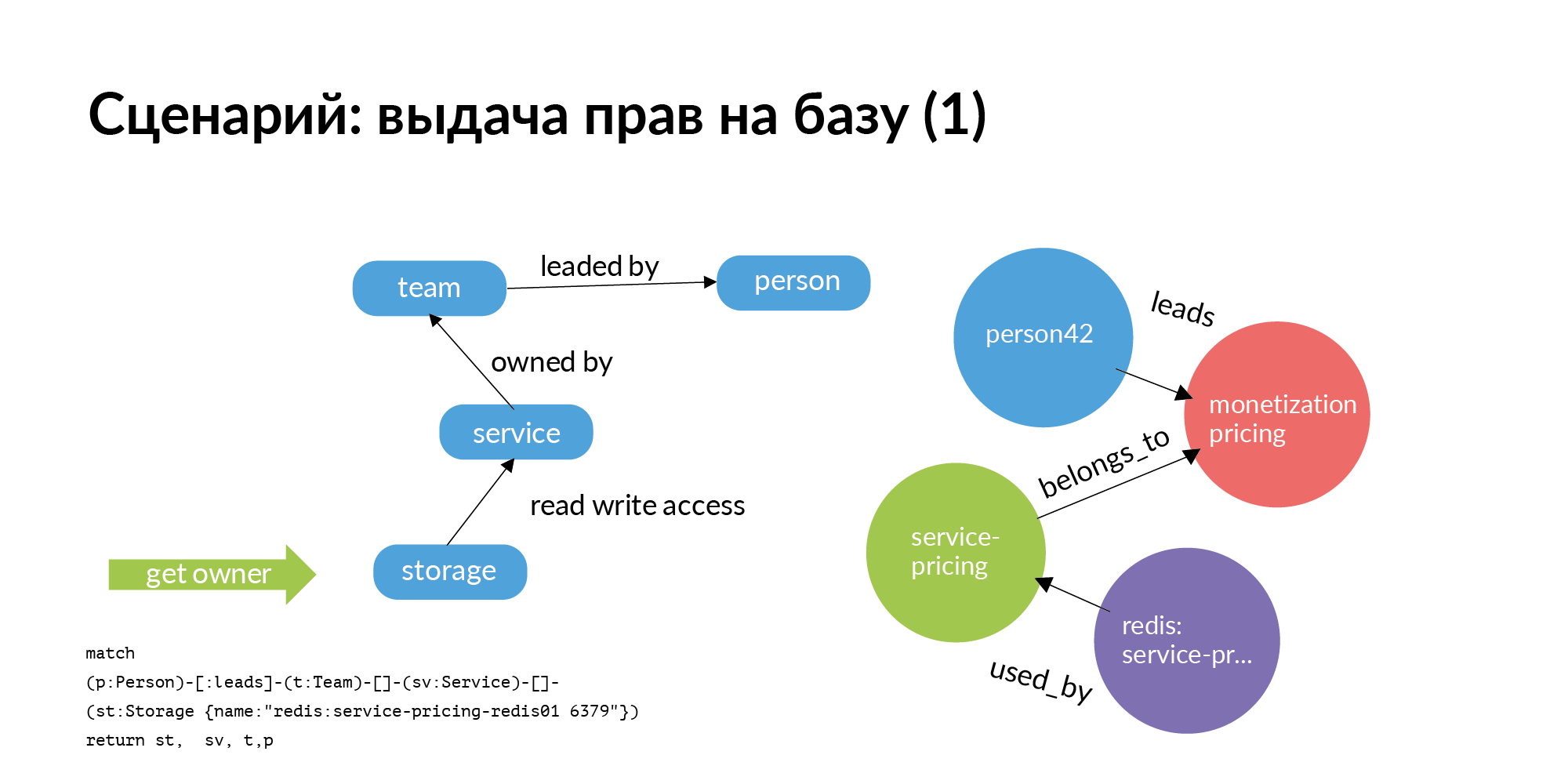
पहला परिदृश्य। हमें आधार के अधिकार जारी करने की आवश्यकता है। सेवा में आधार सख्ती से होना चाहिए। इसमें केवल इस सेवा और उस टीम के सदस्यों को ही शामिल किया जाना चाहिए जो इस सेवा के मालिक हैं। लेकिन हम वास्तविक दुनिया में रहते हैं। अक्सर, अन्य टीमों को किसी अन्य सेवा के आधार पर जाना उपयोगी लगता है। प्रश्न: अधिकारों के अनुदान के बारे में कौन पूछे? वास्तव में बड़ी समस्या सैकड़ों ठिकानों को समझने की है कि प्रभारी कौन है। इस तथ्य के बावजूद कि किसने इसे बनाया, बहुत पहले छोड़ दिया, या किसी अन्य स्थिति में स्थानांतरित कर दिया, या इसके साथ काम करने वाले सभी को याद नहीं है।
और यहाँ सबसे सरल ग्राफ क्वेरी (Neo4j) है। आपको भंडारण तक पहुंच की आवश्यकता है। आप भंडारण से उस सेवा तक जाते हैं जो इसका मालिक है। उस टीम के पास जाएं जो सेवा का मालिक है। सेवा के लिए आगे, आपको पता चल जाएगा कि इस TechLead टीम के पास कौन है। एविटो में, उत्पाद टीमों में एक तकनीकी प्रबंधक और एक उत्पाद प्रबंधक होता है जो आधारों के साथ मदद नहीं कर सकता है। अनुरोध का केवल आधा हिस्सा वास्तव में स्लाइड पर प्रदर्शित होता है। भंडारण तक पहुंच एक परमाणु संचालन नहीं है। भंडारण तक पहुंचने के लिए, आपको उन सर्वरों तक पहुंचने की आवश्यकता है जिन पर यह स्थापित है। यह एक बहुत ही दिलचस्प अलग काम है।
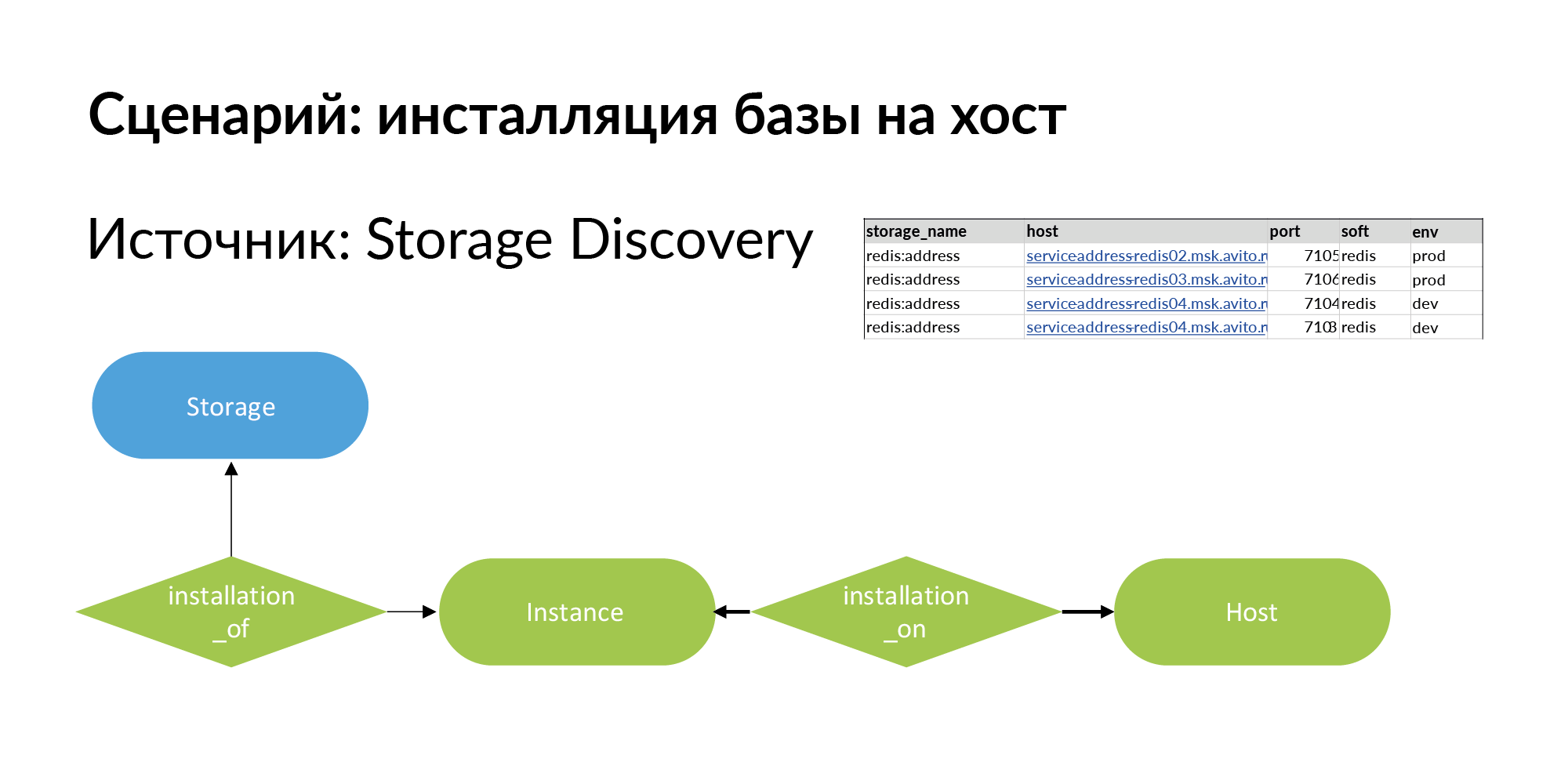
इसे हल करने के लिए, हम एक नई इकाई जोड़ते हैं। यह एक स्थापना है। यहाँ पारिभाषिक समस्या है। भंडारण है, उदाहरण के लिए रेडिस बेस (रेडिस: पता)। एक मेजबान है - यह एक भौतिक मशीन, एक lxc कंटेनर, कुबेरनेट्स हो सकता है। होस्ट पर संग्रहण स्थापित करना जिसे हम इंस्टेंस कहते हैं।
तीन होस्ट पर इसकी चार स्थापनाएं हो सकती हैं, जैसा कि ऊपर दिए गए उदाहरण में दिखाया गया है। उत्पादन के लिए भंडारण प्रदर्शन बढ़ाने के लिए अलग-अलग भौतिक मशीनों पर स्थापित करने के लिए बुद्धिमान है। एक देव वातावरण के लिए, आपको बस एक होस्ट पर स्थापित करना होगा और रेडिस को विभिन्न पोर्ट असाइन करना होगा।

आधार को अधिकार जारी करने का पहला अनुरोध प्रमुख के पास गया। मुखिया ने पुष्टि की कि अधिकार दिए जा सकते हैं।
इसके बाद अनुरोध का दूसरा भाग आता है। भंडारण से दूसरा अनुरोध उदाहरण और होस्ट के लिए जाता है। यह अनुरोध संबंधित वातावरण के लिए सभी स्थापनाओं पर विचार करता है। स्लाइड पर उत्पादन वातावरण के लिए एक उदाहरण है। इसके आधार पर, विशिष्ट मेजबानों और विशिष्ट बंदरगाहों से जुड़ने के अधिकार पहले से ही जारी हैं। यह एक गैर-टीम कर्मचारी के लिए अनुदान अनुरोध का एक उदाहरण था।

एक उदाहरण पर विचार करें जब एक टीम को एक नया कर्मचारी लेने की आवश्यकता होती है। उसे इस सेवा के सभी स्टोरेज तक (शुरुआत के लिए - केवल पढ़ने के लिए) पहुंच प्रदान करनी होगी। स्लाइड पर, अधूरी चयन वाली असली टीम। ग्रीन सर्कल टीम लीडर हैं। गुलाबी मंडलियां टीमें हैं। पीली सेवाएं हैं। कई पीली सेवाओं में नीला भंडारण होता है। ग्रे मेजबान हैं। वायलेट मेजबानों पर भंडारण की स्थापना है। यह एक छोटी इकाई के लिए एक उदाहरण है। लेकिन कई इकाइयाँ हैं जिनकी सेवाएं 7 नहीं हैं, लेकिन 27 हैं। ऐसी इकाइयों के लिए, चित्र बड़ा होगा। यदि आप परसेंट फैब्रिक का उपयोग करते हैं, तो आप इसमें अनुरोध कर सकते हैं और किसी सूची में उत्तर प्राप्त कर सकते हैं।

आइए हमारे स्मार्ट फैब्रिक को भरना जारी रखें और व्यावसायिक संस्थाओं के बारे में बात करें। एविटो में एंटिटीज घोषणाओं, उपयोगकर्ताओं, भुगतानों और इसी तरह की हैं। डेटा वेयरहाउस के बारे में मेरे प्रकाशनों ( HP वर्टिका, से डेटा वेयरहाउस, बिग डेटा , वर्टिका + एंकर मॉडलिंग = अपना मशरूम उगाना शुरू करना ), आप जानते हैं कि एविटो में इन संस्थाओं के सैकड़ों हैं। वास्तव में, उन सभी को लॉग इन करने की आवश्यकता नहीं है। मुझे संस्थाओं की सूची कहां से मिल सकती है? विश्लेषणात्मक भंडार से। आप इस बारे में जानकारी अपलोड कर सकते हैं कि उन्हें यह इकाई कहाँ से मिली। पहले चरण में, यह पर्याप्त है।
इसके अलावा हम इस ज्ञान को विकसित करते हैं: प्रत्येक इकाई के लिए हम रिपॉजिटरी की एक सूची बनाते हैं जहां यह है। हम यह भी संकेत देते हैं कि भंडारण इकाई को कैश के रूप में संग्रहीत करता है या भंडारण इकाई को स्वर्ण स्रोत के रूप में संग्रहीत करता है, अर्थात यह इसका प्राथमिक स्रोत है।

जब आप इस कॉलम को भरते हैं, तो आपके पास अनुरोध करने का अवसर होता है। आपके पास कुछ इकाई है, और आपको यह समझने की आवश्यकता है: इकाई किन सेवाओं में रहती है, यह कहां पर प्रतिबिंबित होती है, किस संग्रहण में, किस होस्ट पर स्थापित है? उदाहरण के लिए, व्यक्तिगत डेटा संसाधित करते समय, आपको लॉग फ़ाइलों को नष्ट करने की आवश्यकता होती है। ऐसा करने के लिए, यह समझना बहुत महत्वपूर्ण है कि लॉग फाइल किस भौतिक मशीन पर बनी रह सकती है।
स्लाइड एक काल्पनिक इकाई के लिए एक सरल क्वेरी दर्शाती है। भंडारण की मात्रा कम हो जाती है ताकि ग्राफ स्लाइड पर फिट हो जाए। लाल घेरे संस्थाएं हैं। ब्लू सर्कल ऐसे आधार हैं जहां यह इकाई स्थित है। बाकी पिछली स्लाइड्स में है: ग्रे सर्कल होस्ट हैं, बैंगनी सर्कल होस्ट पर स्टोरेज इंस्टॉलेशन हैं।
तदनुसार, यदि आप PCI DSS के माध्यम से जाना चाहते हैं, तो आपको कुछ संस्थाओं तक पहुंच को प्रतिबंधित करना होगा। ऐसा करने के लिए, आपको ग्रे सर्कल तक पहुंच को प्रतिबंधित करना होगा। यदि आपको वास्तविक समय तक पहुंच की आवश्यकता है, तो हम बैंगनी सर्कल तक पहुंच को बंद कर देते हैं। यह स्थैतिक जानकारी है।
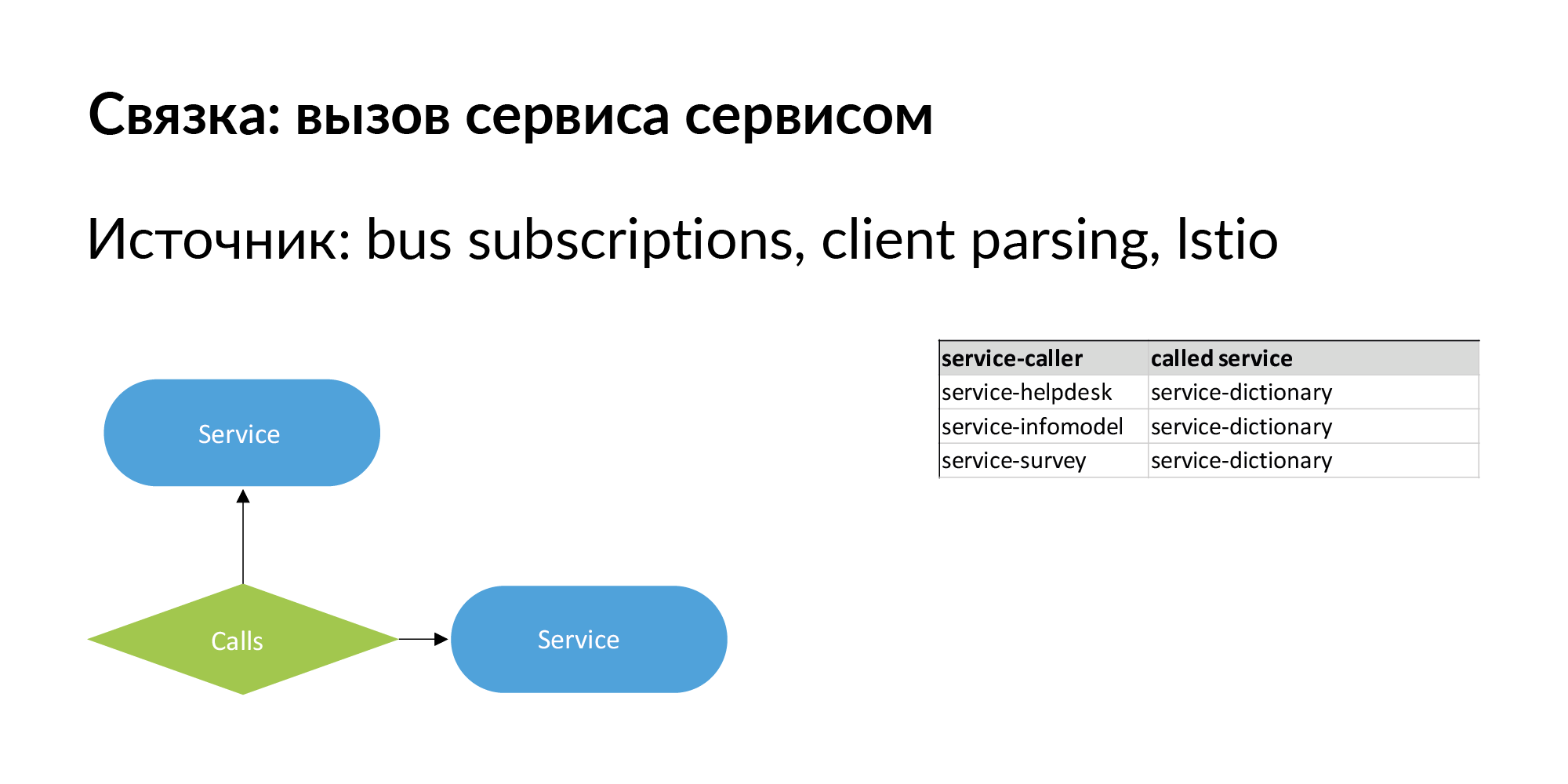
जब हम microservice वास्तुकला के बारे में बात करते हैं, तो सबसे महत्वपूर्ण बात यह है कि यह बदलता है। संस्थाओं के बीच न केवल एक पदानुक्रमित संबंध होना जरूरी है, बल्कि रिश्तों को भी प्रभावित करना है। सेवाओं का एक गुच्छा एकल-स्तरीय कनेक्शन का एक उदाहरण है, जिसे हमने अच्छी तरह से पंप किया है और उपयोग करते हैं। फ़ॉर्म का एक बंडल "सेवा कॉल सेवा" है। प्रत्यक्ष कॉल के बारे में जानकारी है - सेवा किसी अन्य सेवा के एपीआई को कॉल करती है।
फॉर्म के कनेक्शन के बारे में भी जानकारी होनी चाहिए: सेवा नंबर 1 घटनाओं को बस (कतार) में भेजता है, और सेवा नंबर 2 को इस घटना के लिए सदस्यता दी जाती है। यह एक बस से गुजरने वाले एक एसिंक्रोनस धीमे कनेक्शन की तरह है। यह संबंध डेटा आंदोलन के संदर्भ में भी महत्वपूर्ण है। इस तरह के लिंक का उपयोग करके, आप सेवाओं के संचालन की जांच कर सकते हैं यदि जिस सेवा के लिए उन्होंने सदस्यता ली है उसका संस्करण बदल गया है।
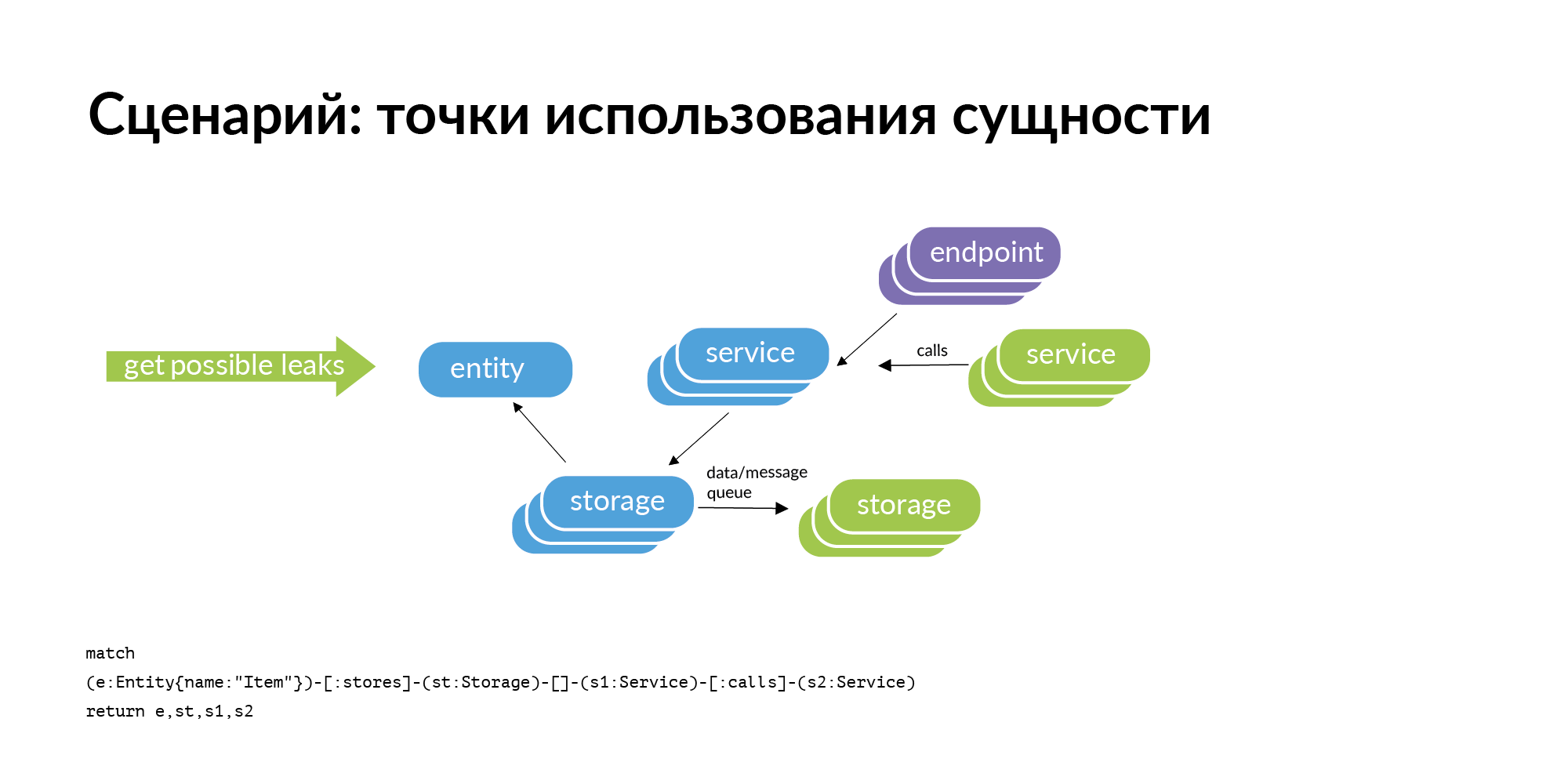
एक इकाई है और हम जानते हैं कि यह निश्चित भंडारण में संग्रहीत है। यदि हम इकाई का उपयोग करने के बिंदु खोजने की समस्या पर विचार करते हैं, तो हमारे साथ उत्पन्न होने वाली स्पष्ट क्वेरी परिधि की जांच है। भंडारण कुछ सेवाओं से संबंधित है। परिधि से इस इकाई का रिसाव (प्रतिलिपि) कहां हो सकता है? यह सेवा कॉल के माध्यम से लीक हो सकता है। सेवा ने उपयोगकर्ता से संपर्क किया, प्राप्त किया और उसे बनाए रखा। यह टायरों के माध्यम से लीक हो सकता है। टायर आपको RabbitMQ, Londiste का उपयोग करके एक-दूसरे से जोड़ सकते हैं। लोंडिस्ट स्लाइड पर, हमने इसे अभी तक लोड नहीं किया है। लेकिन कॉल पहले से लोड हैं।
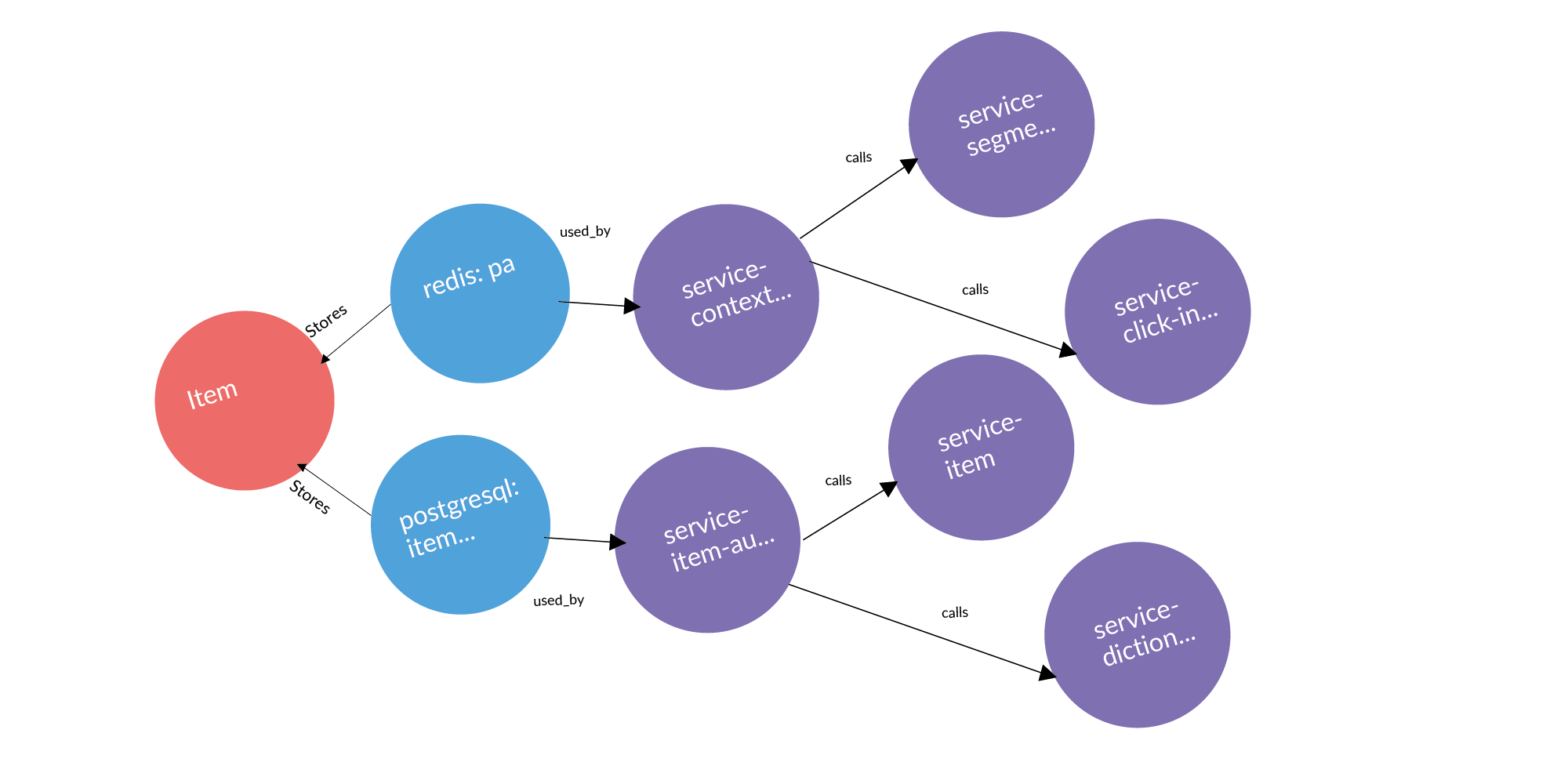
यहां एक वास्तविक अनुरोध का एक उदाहरण है: एक विज्ञापन, दो डेटाबेस जहां इसे संग्रहीत किया जाता है, दो सेवाएं जो इन डेटाबेसों के मालिक हैं। तीन कॉलम के बाद ऐसी सेवाएं हैं जो इस इकाई के मालिक हैं। ये संभावित रिसाव बिंदु जोड़ने लायक हैं।

अंतिम बिंदु। वादिम ने उल्लेख किया कि आप समापन बिंदु सेवाओं की एक रजिस्ट्री बनाने के लिए प्रलेखन का उपयोग कर सकते हैं। आप यह जानकारी निगरानी से भी प्राप्त कर सकते हैं। यदि समापन बिंदु महत्वपूर्ण है, तो डेवलपर्स खुद इसे निगरानी में जोड़ देंगे। यदि एंडपॉइंट की निगरानी नहीं की जाती है, तो हमें इसकी आवश्यकता नहीं है।
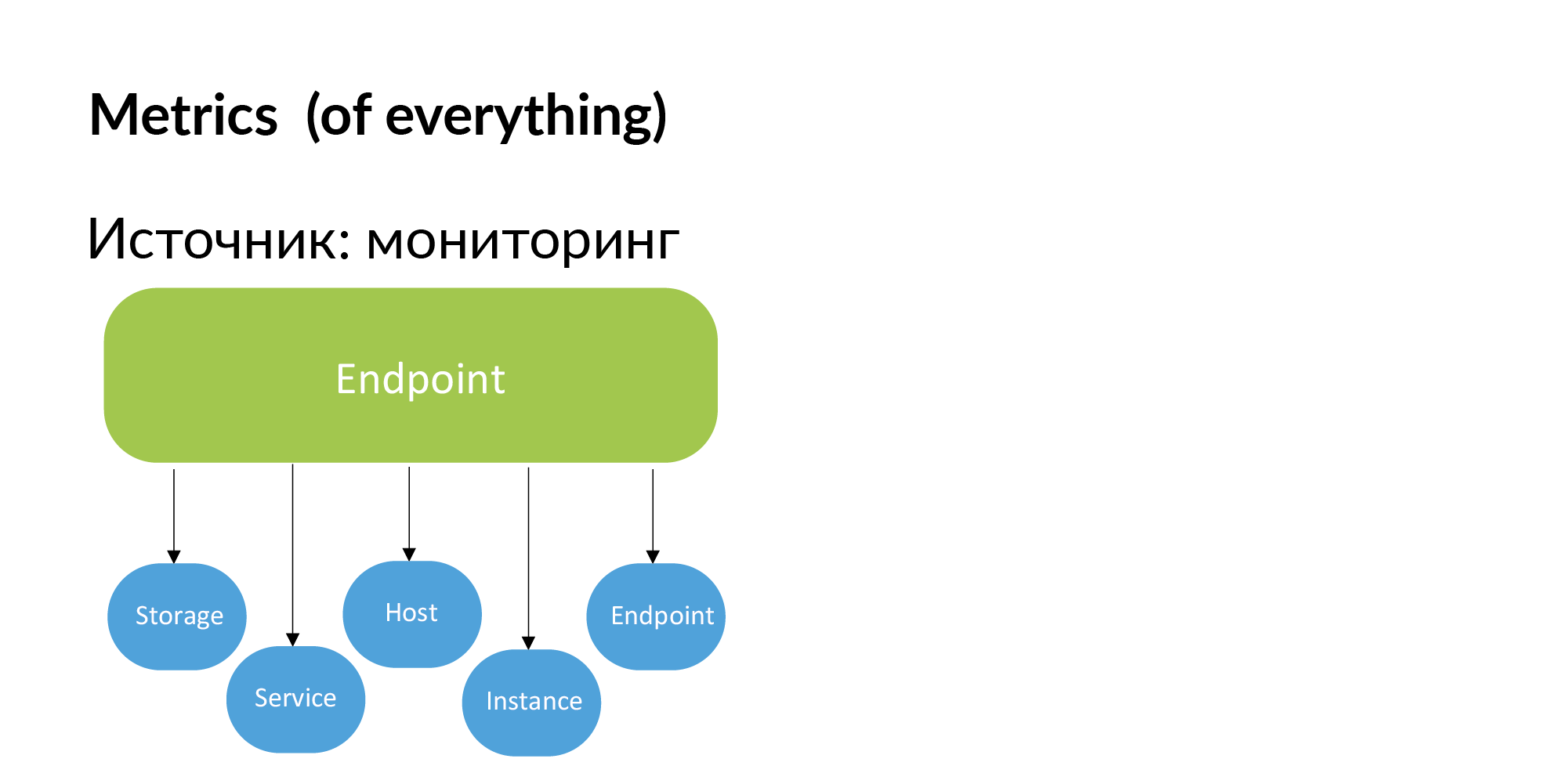
तदनुसार, निगरानी से मैट्रिक्स प्राप्त किया जा सकता है। उदाहरण के लिए, (डेटाबेस शार्प्स) और एंडपॉइंट को होस्ट करने के लिए, सेवाओं के लिए भंडारण के मैट्रिक्स को बांधना

जब आप एक विफलता का सामना करते हैं, उदाहरण के लिए, एंडपॉइंट 500 का HTTP कोड जारी करता है, तो समस्या की जड़ को ट्रैक करने के लिए, आपको इस समापन बिंदु के लिए एक अनुरोध करने की आवश्यकता है। एंडपॉइंट से सेवा पर जाएं, उन सेवाओं पर जाएं जिन्हें यह सेवा कॉल करती है, सेवाओं से स्टोरेज पर जाती हैं, स्टोरेज से इंस्टेंस और होस्ट पर जाती हैं।
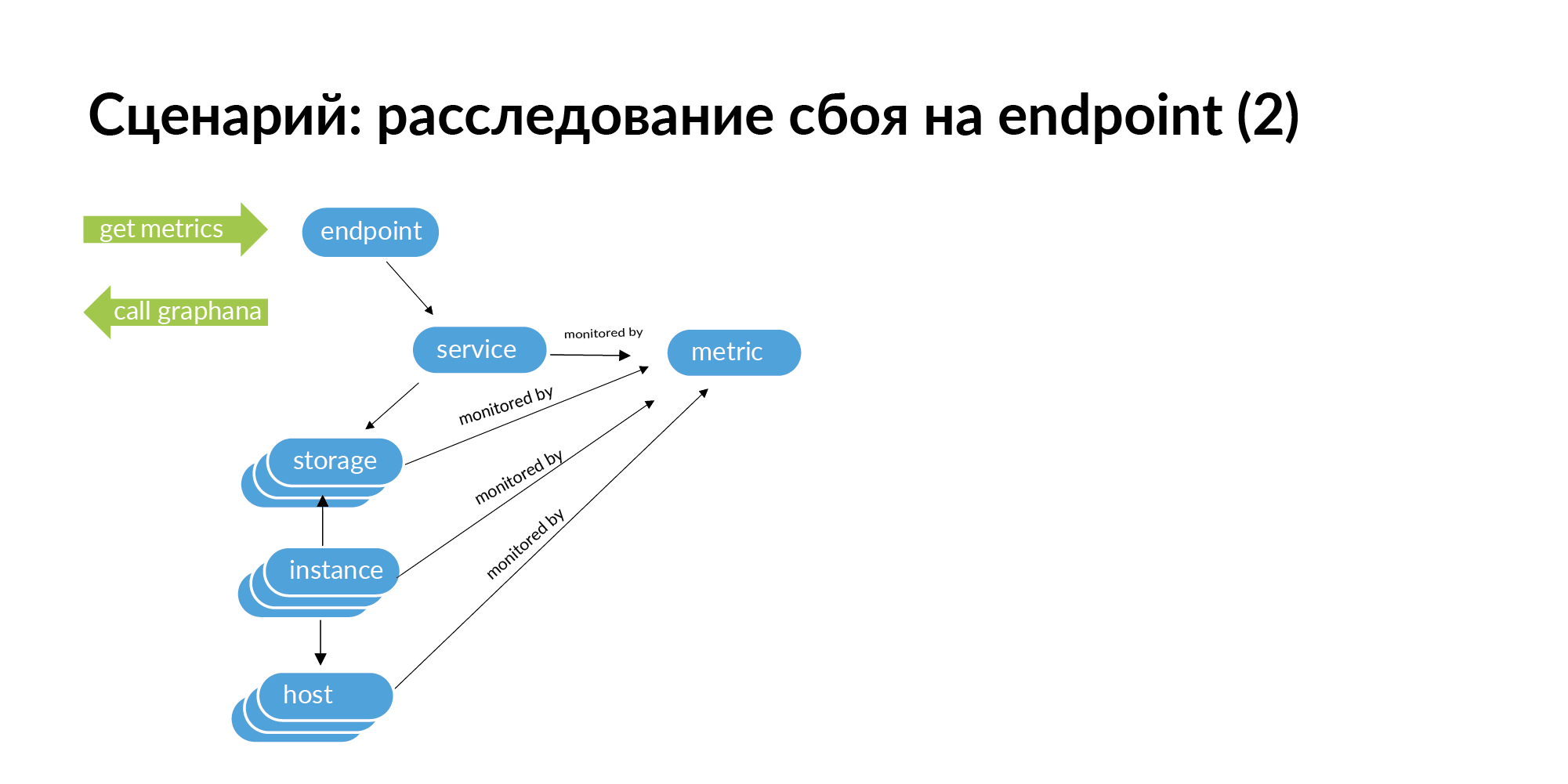
इसके अलावा, यदि आप इस ग्राफ को नीचे ले जाते हैं, तो इसके आधार पर आप निगरानी के लिए पहचानकर्ताओं की सूची प्राप्त कर सकते हैं। आप इस संपूर्ण बिंदु को नीचे की ओर देख सकते हैं, जो विफलता का कारण हो सकता है। माइक्रोसॉर्फ़ आर्किटेक्चर में, एंडपॉइंट पर एक विफलता कुछ सर्वर पर एक नेटवर्क विफलता के कारण हो सकती है जिस पर एक डेटाबेस शार्क तैनात है। यह निगरानी में देखा जा सकता है, लेकिन एक बड़ी सेवा संरचना के साथ, निगरानी में सभी सेवाओं की जांच करना बहुत श्रमसाध्य है।

परीक्षण। पर्याप्त रूप से एक microservice का परीक्षण करने के लिए, आपको अन्य सेवाओं के साथ सेवा की जांच करने की आवश्यकता है जो इसे काम करने की आवश्यकता है। , . . . , . .
, , , production. , . — , , .
, . , . . .
— , . .
- . . . . storage. — . endpoint. , , .. .
- . «» . , , , connection, connection , . , . ( , Anchor Modeling ). . « ». . Neo4j, .
- , . . , UI points frontend , backend , storage DBA, DevOps , .
in-progress
.
(Londiste, PGQ, RabbitMQ).
. UI points . . (Persistent Fabric), UI points, Endpoint, . , , , , .