पिछले लेख में, हमने वॉचर का उपयोग करने की कोशिश करने के बारे में बात की और एक परीक्षण रिपोर्ट प्रस्तुत की। हम समय-समय पर एक बड़े कॉर्पोरेट या ऑपरेटर क्लाउड के संतुलन और अन्य महत्वपूर्ण कार्यों के लिए इस तरह के परीक्षण करते हैं।
समस्या को हल करने की उच्च जटिलता को हमारी परियोजना का वर्णन करने के लिए कई लेखों की आवश्यकता हो सकती है। आज हम क्लाउड में आभासी मशीनों को संतुलित करने पर श्रृंखला में दूसरा लेख प्रकाशित करते हैं।
कुछ शब्दावली
VmWare ने अपने वर्चुअलाइजेशन पर्यावरण के भार को संतुलित करने के लिए DRS (डिस्ट्रीब्यूटेड रिसोर्स शेड्यूलर) यूटिलिटी की शुरुआत की है।
जैसा कि
searchvmware.techtarget.com/definition/VMware-DRS लिखता है
“VMware DRS (डिस्ट्रिब्यूटेड रिसोर्स शेड्यूलर) एक उपयोगिता है जो एक आभासी वातावरण में उपलब्ध संसाधनों के साथ कंप्यूटिंग लोड को संतुलित करता है। उपयोगिता VMware इन्फ्रास्ट्रक्चर नामक वर्चुअलाइजेशन पैकेज का हिस्सा है।
VMware DRS का उपयोग करते हुए, उपयोगकर्ता वर्चुअल मशीनों (VMs) के बीच भौतिक संसाधनों के वितरण के नियमों को परिभाषित करते हैं। उपयोगिता को मैन्युअल या स्वचालित नियंत्रण के लिए कॉन्फ़िगर किया जा सकता है। VMware संसाधन पूल को आसानी से जोड़ा, हटाया या पुनर्गठित किया जा सकता है। यदि वांछित है, तो संसाधन पूल को विभिन्न व्यावसायिक इकाइयों के बीच अलग किया जा सकता है। यदि एक या एक से अधिक वर्चुअल मशीनों का कार्यभार नाटकीय रूप से बदलता है, तो VMware DRS भौतिक सर्वरों के बीच वर्चुअल मशीनों को पुनर्वितरित करता है। यदि समग्र कार्यभार कम हो जाता है, तो कुछ भौतिक सर्वर अस्थायी रूप से कम हो सकते हैं और कार्यभार समेकित हो सकता है। "मुझे संतुलन की आवश्यकता क्यों है?
हमारी राय में, DRS क्लाउड की एक अनिवार्य विशेषता है, हालांकि इसका मतलब यह नहीं है कि DRS का उपयोग कभी भी, कहीं भी किया जाना चाहिए। बादल के उद्देश्य और जरूरतों के आधार पर, डीआरएस और संतुलन के तरीकों के लिए अलग-अलग आवश्यकताएं हो सकती हैं। शायद ऐसी परिस्थितियां होती हैं जब संतुलन की आवश्यकता नहीं होती है। या हानिकारक भी।
यह समझने के लिए कि डीआरएस ग्राहकों को कहां और किस चीज की जरूरत है, उनके लक्ष्यों और उद्देश्यों पर विचार करें। बादलों को सार्वजनिक और निजी में विभाजित किया जा सकता है। यहां इन बादलों और ग्राहक लक्ष्यों के बीच मुख्य अंतर हैं।
हम अपने लिए निम्नलिखित निष्कर्ष निकालते हैं:
बड़े कॉर्पोरेट ग्राहकों को प्रदान किए गए
निजी बादलों के लिए, DRS प्रतिबंधों के अधीन लागू किया जा सकता है:
- संतुलन के लिए सूचना सुरक्षा और लेखा संबंध नियम;
- एक दुर्घटना की स्थिति में पर्याप्त मात्रा में संसाधनों की उपलब्धता;
- वर्चुअल मशीन डेटा एक केंद्रीकृत या वितरित भंडारण प्रणाली पर रहता है;
- प्रशासन, बैकअप और संतुलन प्रक्रियाओं की समय विविधता;
- केवल ग्राहक मेजबानों के एकत्रीकरण के भीतर संतुलन;
- केवल एक मजबूत असंतुलन के साथ संतुलन, वीएम का सबसे कुशल और सुरक्षित प्रवास (आखिरकार, प्रवास विफल हो सकता है);
- अपेक्षाकृत "शांत" आभासी मशीनों ("शोर" का माइग्रेशन) आभासी मशीनों को बहुत लंबे समय तक ले जा सकता है;
- "लागत" को ध्यान में रखते हुए संतुलन - भंडारण प्रणाली और नेटवर्क पर लोड (बड़े ग्राहकों के लिए अनुकूलित आर्किटेक्चर के साथ);
- प्रत्येक वीएम के व्यक्तिगत व्यवहार को ध्यान में रखते हुए संतुलन;
- संतुलन घंटों (रात, सप्ताहांत, छुट्टियों) के बाद वांछनीय है।
छोटे ग्राहकों के लिए सेवाएं प्रदान करने वाले
सार्वजनिक बादलों के लिए, DRS का उपयोग उन्नत सुविधाओं के साथ अक्सर किया जा सकता है:
- सूचना सुरक्षा प्रतिबंधों और आत्मीयता नियमों की कमी;
- बादल के भीतर संतुलन;
- किसी भी उचित समय पर संतुलन;
- किसी भी वीएम को संतुलित करना;
- "शोर" आभासी मशीनों को संतुलित करना (ताकि बाकी के साथ हस्तक्षेप न करें);
- वर्चुअल मशीन डेटा अक्सर स्थानीय ड्राइव पर स्थित होता है;
- औसत भंडारण और नेटवर्क प्रदर्शन के लिए लेखांकन (क्लाउड आर्किटेक्चर एकीकृत है);
- सामान्यीकृत नियमों और डेटा सेंटर व्यवहार के उपलब्ध आंकड़ों के अनुसार संतुलन।
समस्या की जटिलता
संतुलन बनाने में कठिनाई यह है कि DRS को बहुत सारे अनिश्चित कारकों के साथ काम करना चाहिए:
- ग्राहक सूचना प्रणाली में से प्रत्येक का उपयोगकर्ता व्यवहार;
- सूचना प्रणाली सर्वरों के संचालन के लिए एल्गोरिदम;
- DBMS सर्वर व्यवहार
- कंप्यूटिंग संसाधनों, भंडारण, नेटवर्क पर लोड;
- क्लाउड संसाधनों के लिए संघर्ष में सर्वर आपस में बातचीत करते हैं।
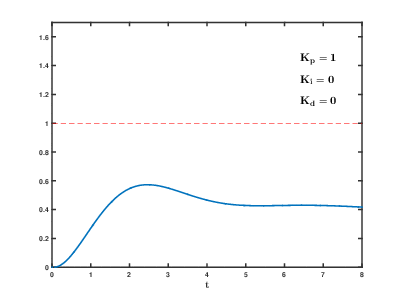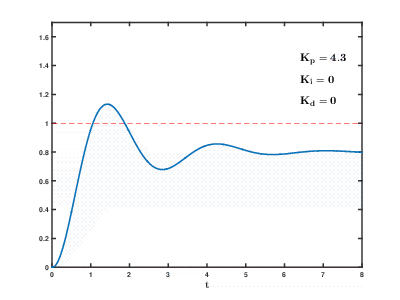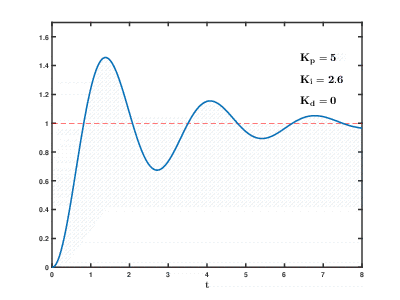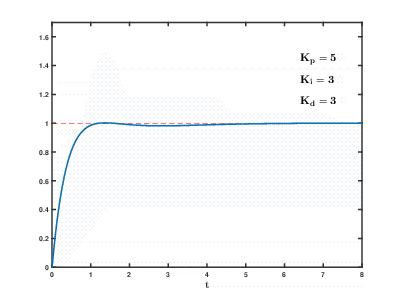
क्लाउड संसाधनों पर बड़ी संख्या में वर्चुअल एप्लिकेशन सर्वर और डेटाबेस का लोड समय के साथ होता है, परिणाम अप्रत्याशित समय के बाद अप्रत्याशित प्रभाव के साथ हो सकता है और ओवरलैप हो सकता है। यहां तक कि अपेक्षाकृत सरल प्रक्रियाओं को नियंत्रित करने के लिए (उदाहरण के लिए, एक इंजन को नियंत्रित करने के लिए, घर पर एक पानी का हीटिंग सिस्टम), स्वत: नियंत्रण प्रणालियों को जटिल
आनुपातिक-अभिन्न-विभेदक प्रतिक्रिया एल्गोरिदम का उपयोग करने की आवश्यकता होती है।

हमारा कार्य अधिक परिमाण के कई आदेश हैं जो अधिक जटिल हैं, और एक जोखिम है कि सिस्टम एक उचित समय में स्थापित मूल्यों पर भार को संतुलित करने में सक्षम नहीं होगा, भले ही उपयोगकर्ताओं से बाहरी प्रभाव उत्पन्न न हो।
हमारे विकास का इतिहास
इस समस्या को हल करने के लिए, हमने खरोंच से शुरू नहीं करने का फैसला किया, लेकिन मौजूदा अनुभव पर निर्माण किया, और इस क्षेत्र में अनुभव रखने वाले विशेषज्ञों के साथ बातचीत करना शुरू किया। सौभाग्य से, समस्याओं के बारे में हमारी समझ पूरी तरह से मेल खाती है।
स्टेज 1
हमने तंत्रिका नेटवर्क तकनीक पर आधारित एक प्रणाली का उपयोग किया, और इसके आधार पर अपने संसाधनों को अनुकूलित करने का प्रयास किया।
इस चरण की रुचि नई तकनीक का परीक्षण करने के लिए थी, और इसका महत्व समस्या को हल करने के लिए एक गैर-मानक दृष्टिकोण लागू करना था, जहां, अन्य चीजें समान हो रही हैं, मानक दृष्टिकोण व्यावहारिक रूप से स्वयं समाप्त हो गए हैं।
हमने सिस्टम शुरू किया, और हम वास्तव में संतुलन बनाते गए। हमारे क्लाउड के पैमाने ने हमें डेवलपर्स द्वारा घोषित आशावादी परिणाम प्राप्त करने की अनुमति नहीं दी, लेकिन यह स्पष्ट था कि संतुलन काम कर रहा था।
इसके अलावा, हमारे पास गंभीर सीमाएँ थीं:
- एक तंत्रिका नेटवर्क को प्रशिक्षित करने के लिए, हफ्तों या महीनों के लिए महत्वपूर्ण बदलाव के बिना आभासी मशीनों को चलाने की आवश्यकता होती है।
- एल्गोरिथ्म को पहले "ऐतिहासिक" डेटा के विश्लेषण के आधार पर अनुकूलन के लिए डिज़ाइन किया गया है।
- तंत्रिका नेटवर्क को प्रशिक्षित करने के लिए पर्याप्त मात्रा में डेटा और कंप्यूटिंग संसाधनों की आवश्यकता होती है।
- अनुकूलन और संतुलन अपेक्षाकृत कम ही किया जा सकता है - हर कुछ घंटों में एक बार, जो स्पष्ट रूप से पर्याप्त नहीं है।
स्टेज 2
चूंकि हम मामलों की स्थिति से खुश नहीं थे, इसलिए हमने सिस्टम को संशोधित करने का फैसला किया, और इसके लिए
मुख्य प्रश्न का उत्तर दिया - यह हम किसके लिए कर रहे हैं?
सबसे पहले कॉर्पोरेट ग्राहकों के लिए। इसलिए, हमें एक ऐसी प्रणाली की आवश्यकता है जो कुशलता से काम करे, उन कॉर्पोरेट प्रतिबंधों के साथ जो केवल कार्यान्वयन को सरल बनाते हैं।
दूसरा सवाल "परिचालन" शब्द का क्या अर्थ है? एक छोटी बहस के परिणामस्वरूप, हमने फैसला किया कि 5-10 मिनट की प्रतिक्रिया समय पर निर्माण करना संभव है, ताकि अल्पकालिक कूद प्रणाली में प्रतिध्वनि का परिचय न दें।
तीसरा सवाल यह है कि संतुलित सर्वरों की संख्या किस आकार को चुनना है?
यह मुद्दा खुद तय किया गया था। आमतौर पर, क्लाइंट सर्वर एग्रीगेट को बहुत बड़ा नहीं बनाते हैं, और यह एग्रीगेट्स को 30-40 सर्वर तक सीमित करने के लिए आलेख में सिफारिशों के अनुरूप है।
इसके अलावा, सर्वर पूल को खंडित करके, हम संतुलन एल्गोरिथ्म के कार्य को सरल करते हैं।
चौथा सवाल यह है कि एक तंत्रिका नेटवर्क हमें अपनी लंबी सीखने की प्रक्रिया और दुर्लभ संतुलन के साथ कितना सूट करता है? हमने सेकंड में परिणाम प्राप्त करने के लिए सरल परिचालन एल्गोरिदम के पक्ष में इसे छोड़ने का फैसला किया।
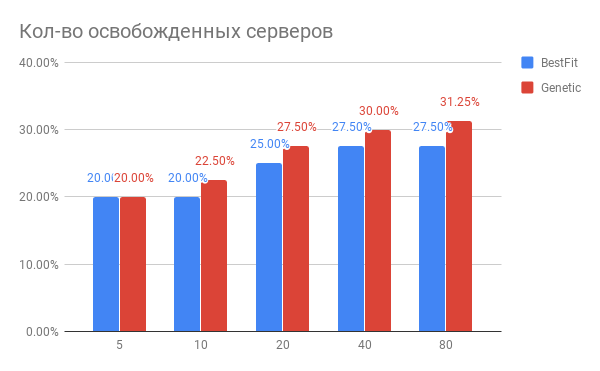
इस तरह के एल्गोरिदम और इसकी कमियों का उपयोग कर प्रणाली का विवरण
यहां पाया जा सकता
है।हमने इस प्रणाली को लागू किया और लॉन्च किया और उत्साहजनक परिणाम प्राप्त किए - अब यह नियमित रूप से क्लाउड लोड का विश्लेषण करता है और चलती मशीनों पर सिफारिशें देता है, जो काफी हद तक सही हैं। अब भी यह स्पष्ट है कि हम नई आभासी मशीनों के लिए मौजूदा संसाधनों की गुणवत्ता में सुधार के साथ 10-15% संसाधन प्राप्त कर सकते हैं।

जब RAM या CPU द्वारा असंतुलन का पता लगाया जाता है, तो सिस्टम आवश्यक वर्चुअल मशीनों का लाइव माइग्रेशन करने के लिए Tionics अनुसूचक को कमांड देता है। जैसा कि निगरानी प्रणाली से देखा जा सकता है, वर्चुअल मशीन एक (ऊपरी) से दूसरे (निचले) होस्ट में चली गई और मेमोरी को ऊपरी होस्ट (पीले हलकों में हाइलाइट किया गया) पर रखा गया, इसे क्रमशः, कम होस्ट (व्हाइट सर्कल में हाइलाइट किया गया) पर कब्जा कर लिया।
अब हम वर्तमान एल्गोरिथ्म की प्रभावशीलता का अधिक सटीक मूल्यांकन करने की कोशिश कर रहे हैं और इसमें संभावित त्रुटियों का पता लगाने की कोशिश कर रहे हैं।
स्टेज 3
ऐसा लगता है कि आप इस पर शांत हो सकते हैं, सिद्ध प्रभावशीलता की प्रतीक्षा कर सकते हैं और विषय को बंद कर सकते हैं।
लेकिन निम्नलिखित स्पष्ट अनुकूलन अवसर हमें एक नए चरण का संचालन करने के लिए प्रेरित कर रहे हैं।
- उदाहरण के लिए, यहां और यहां आंकड़े बताते हैं कि उनके प्रदर्शन में दो और चार-प्रोसेसर सिस्टम एकल-प्रोसेसर वाले लोगों की तुलना में काफी कम हैं। इसका मतलब यह है कि सभी उपयोगकर्ताओं को सिंगल-प्रोसेसर वाले की तुलना में मल्टीप्रोसेसर सिस्टम में खरीदे गए सीपीयू, रैम, एसएसडी, लैन, एफसी से काफी कम रिटर्न मिलता है।
- संसाधन नियोजक स्वयं गंभीर त्रुटियों के साथ काम कर सकते हैं, इस विषय पर यहां एक लेख है ।
- रैम और कैश की निगरानी के लिए इंटेल और एएमडी द्वारा दी गई प्रौद्योगिकियां आपको आभासी मशीनों के व्यवहार का अध्ययन करने और उन्हें इस तरह से रखने की अनुमति देती हैं कि शोर पड़ोसी शांत आभासी मशीनों के साथ हस्तक्षेप नहीं करते हैं।
- मापदंडों के सेट का विस्तार (नेटवर्क, भंडारण, आभासी मशीन प्राथमिकता, प्रवास लागत, प्रवास के लिए इसकी तत्परता)।
कुल मिलाकर
संतुलन एल्गोरिदम को बेहतर बनाने पर हमारे काम का नतीजा एक अस्पष्ट निष्कर्ष था कि आधुनिक एल्गोरिदम के कारण डेटा केंद्रों के संसाधनों (25-30%) के महत्वपूर्ण अनुकूलन को प्राप्त करना और ग्राहक सेवा की गुणवत्ता में सुधार करना संभव है।
निश्चित रूप से तंत्रिका नेटवर्क पर आधारित एल्गोरिथ्म एक दिलचस्प समाधान है, जिसे और अधिक विकास की आवश्यकता है, और मौजूदा प्रतिबंधों के कारण, यह निजी बादलों की विशेषता वाले संस्करणों पर ऐसी समस्याओं को हल करने के लिए उपयुक्त नहीं है। इसी समय, महत्वपूर्ण आकार के सार्वजनिक बादलों में, एल्गोरिथ्म ने अच्छे परिणाम दिखाए।
हम आपको निम्नलिखित लेखों में प्रोसेसर, शेड्यूलर और उच्च-स्तरीय संतुलन की क्षमताओं के बारे में अधिक बताएंगे।