ClickHouse लगातार स्ट्रिंग प्रसंस्करण कार्यों का सामना करता है। उदाहरण के लिए, खोज, UTF-8 स्ट्रिंग्स के गुणों की गणना करना, या कुछ अधिक विदेशी, चाहे वह केस-संवेदी खोज हो या संपीड़ित डेटा खोज।
यह सब इस तथ्य के साथ शुरू हुआ कि ClickHouse विकास प्रबंधक लेसहा मिलोविडोव o6CuFl2Q ने हायर स्कूल ऑफ इकोनॉमिक्स में कंप्यूटर विज्ञान संकाय में हमारे पास आए और टर्म पेपर और डिप्लोमा के लिए भारी संख्या में विषयों की पेशकश की। जब मैंने क्लिकहाउस में "स्मार्ट स्ट्रिंग प्रोसेसिंग एल्गोरिदम देखा" (मैं, एक व्यक्ति जो विभिन्न एल्गोरिदम में रुचि रखता है, प्रायोगिक वाले सहित), मैंने तुरंत सबसे अच्छे डिप्लोमा बनाने की योजना बनाई। मेरी खुशी और अभिव्यक्ति को निम्नानुसार वर्णित किया जा सकता है:

ClickHouse
क्लिकहाउस ने ध्यान से मेमोरी में डेटा स्टोरेज के संगठन को सोचा है - कॉलम में। प्रत्येक कॉलम के अंत में 16-बाइट रजिस्टर के सुरक्षित पढ़ने के लिए 15 बाइट्स का एक पैडिंग है। उदाहरण के लिए, ColumnString स्टोर ऑफ़सेट के साथ-साथ स्ट्रिंग को समाप्त कर देता है। ऐसे सरणियों के साथ काम करना बहुत सुविधाजनक है।

ColumnFixedString, ColumnConst और LowCardinality भी हैं, लेकिन हम आज उनके बारे में इतने विस्तार से बात नहीं करेंगे। इस बिंदु पर मुख्य बिंदु यह है कि पूंछ के सुरक्षित पढ़ने के लिए डिज़ाइन केवल सुंदर है, और डेटा की स्थानीयता भी प्रसंस्करण में भूमिका निभाती है।
पदार्थ खोज
सबसे अधिक संभावना है, आप एक स्ट्रिंग में एक विकल्प खोजने के लिए कई अलग-अलग एल्गोरिदम को जानते हैं। हम उन लोगों के बारे में बात करेंगे जिनका उपयोग ClickHouse में किया जाता है। पहले हम कुछ परिभाषाएँ प्रस्तुत करते हैं:
- haystack - वह रेखा जिसमें हम देख रहे हैं; आमतौर पर लंबाई n द्वारा निरूपित की जाती है।
- सुई - स्ट्रिंग या नियमित अभिव्यक्ति जिसे हम ढूंढ रहे हैं; लंबाई m द्वारा चिह्नित की जाएगी।
बड़ी संख्या में एल्गोरिदम का अध्ययन करने के बाद, मैं कह सकता हूं कि खोज एल्गोरिदम के विकल्प के 2 (अधिकतम 3) प्रकार हैं। पहला एक रूप या किसी अन्य प्रत्यय संरचना का निर्माण है। दूसरा प्रकार मेमोरी तुलना के आधार पर एल्गोरिदम है। राबिन-कार्प एल्गोरिथ्म भी है, जो हैश का उपयोग करता है, लेकिन यह अपनी तरह का काफी अनूठा है। सबसे तेज़ एल्गोरिथ्म मौजूद नहीं है, यह सब वर्णमाला के आकार, सुई की लंबाई, घटाव और घटना की आवृत्ति पर निर्भर करता है।
विभिन्न एल्गोरिदम के बारे में यहां पढ़ें। और यहाँ सबसे लोकप्रिय एल्गोरिदम हैं:
- नट - मॉरिस - प्रैट,
- बोयर - मूर,
- बोयर - मूर - हॉर्सपूल,
- राबिन - कार्प,
- डबल-पक्षीय (ग्लिम्क में "मेमेम" कहा जाता है),
- BNDM।
सूची जारी होती है। हम ClickHouse में ईमानदारी से सब कुछ करने की कोशिश की, लेकिन अंत में हम एक और अधिक असाधारण संस्करण पर बस गए।
वोल्निट्स्की एल्गोरिदम
एल्गोरिथ्म 2010 के अंत में प्रोग्रामर लियोनिद वोल्निट्स्की के ब्लॉग पर प्रकाशित हुआ था। यह बोयर-मूर-हॉर्सपूल एल्गोरिथ्म की याद दिलाता है, केवल एक बेहतर संस्करण है।
यदि m <4 , तो मानक खोज एल्गोरिथ्म का उपयोग किया जाता है। आकार के खुले पते के साथ एक हैश तालिका में अंत से सभी बड़ेग्राम (लगातार 2 बाइट्स) सुई को बचाएं । सिग्मा | 2 तत्व (व्यवहार में, ये 2 16 तत्व हैं), जहां इस आश्रम के वंशज मूल्य होंगे, और स्वयं आश्रम एक ही समय में हैश और इंडेक्स होंगे। प्रारंभिक स्थिति हैस्टैक की शुरुआत से स्थिति m - 2 पर होगी। हम चरण 1 - 1 के साथ हैस्टैक का पालन करते हैं, इस स्थिति से अगले आश्रम को देखते हैं और हैश तालिका में आश्रम से सभी मूल्यों पर विचार करें। फिर हम स्मृति के दो टुकड़ों की तुलना सामान्य एल्गोरिथ्म से करेंगे। जो पूंछ बनी हुई है, उसे उसी एल्गोरिदम द्वारा संसाधित किया जाएगा।
चरण एम - 1 को इस तरह से चुना जाता है कि यदि किसी हस्टैक में सुई की घटना होती है, तो हम निश्चित रूप से इस प्रविष्टि के आश्रम पर विचार करेंगे - जिससे यह सुनिश्चित होगा कि हम प्रवेश में स्थिति की वापसी करते हैं। पहली घटना इस तथ्य से गारंटीकृत है कि हम सूचकांक को हैश टेबल के अंत से बिग्राम द्वारा जोड़ते हैं। इसका मतलब यह है कि जब हम बाएं से दाएं जाते हैं, तो हम सबसे पहले रेखा के अंत से (शायद शुरुआत में पूरी तरह से अनावश्यक आश्रमों पर विचार कर रहे हैं) बीग्रामों पर विचार करेंगे, फिर शुरुआत के करीब।
एक उदाहरण पर विचार करें। बता दें कि abacabaac और सुई के बराबर है। हैश टेबल {aa : 0, ac : 1, ca : 2} ।
0 1 2 3 4 5 6 7 8 9 abacabaaca ^ -
हम लोग आश्रम को देखते हैं। सुई में, हम समानता में स्थानापन्न हैं:
0 1 2 3 4 5 6 7 8 9 abacabaaca aaca
मेल नहीं हुआ। ac बाद हैश टेबल में कोई प्रविष्टियाँ नहीं हैं, हम चरण 3 के साथ कदम रखते हैं:
0 1 2 3 4 5 6 7 8 9 abacabaaca ^ -
हैश टेबल में कोई भी बड़ा ba नहीं है, आगे बढ़ो:
0 1 2 3 4 5 6 7 8 9 abacabaaca ^ -
सुई में एक बिग्राम ca है, हम ऑफसेट को देखते हैं और प्रविष्टि पाते हैं:
0 1 2 3 4 5 6 7 8 9 abacabaaca aaca
एल्गोरिथ्म के कई फायदे हैं। सबसे पहले, आपको ढेर पर मेमोरी आवंटित करने की आवश्यकता नहीं है, और स्टैक पर 64 केबी अब कुछ पारलौकिक नहीं हैं। दूसरे, प्रोसेसर के लिए मोडुलो लेने के लिए 2 16 एक उत्कृष्ट संख्या है; ये सिर्फ Movzwl निर्देश हैं (या, जैसा कि हम मजाक करते हैं, "movsvl") और परिवार।
औसतन, यह एल्गोरिथ्म सबसे अच्छा साबित हुआ। हमने Yandex.Metrica से डेटा लिया, अनुरोध लगभग वास्तविक हैं। एक स्ट्रीम गति, अधिक बेहतर है, केएमपी: नॉट - मॉरिस - प्रैट एल्गोरिथ्म, बीएम: बोयर - मूर, बीएमएच: बोयर - मूर - हॉर्सपूल।
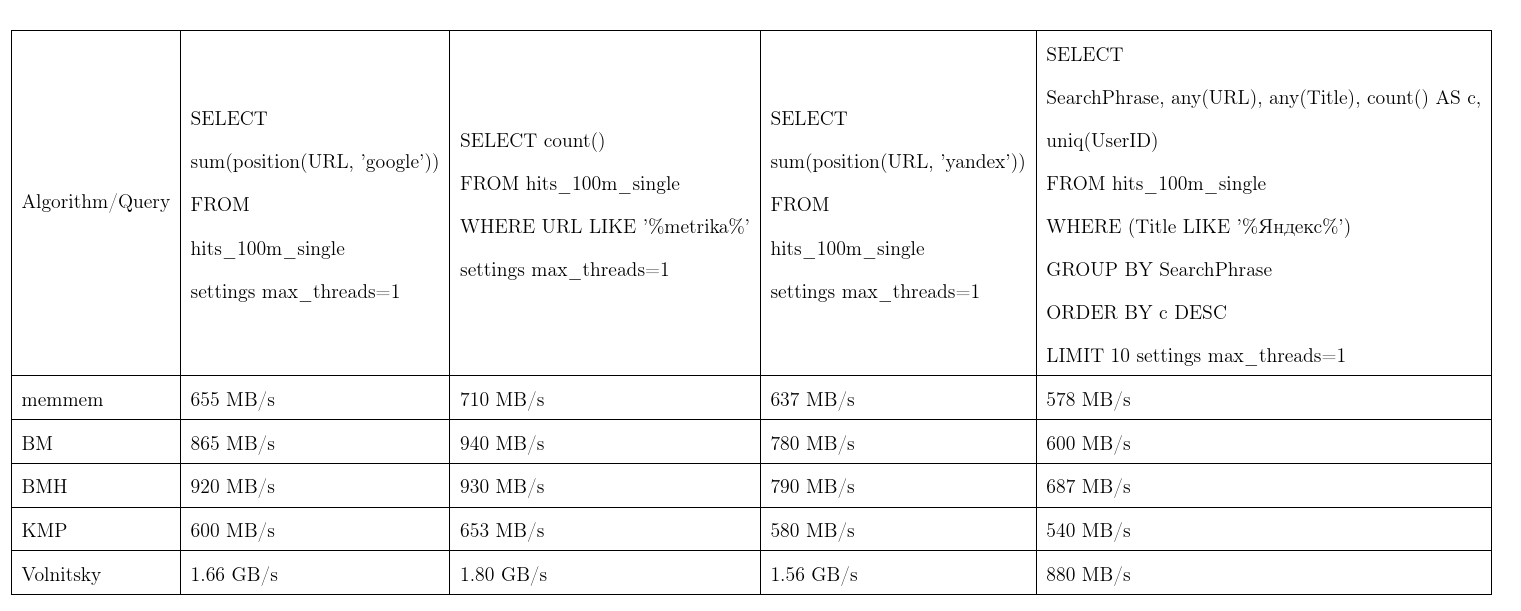
निराधार नहीं होने के लिए, एल्गोरिथ्म द्विघात समय का काम कर सकता है:

इसका उपयोग position(Column, ConstNeedle) फंक्शन position(Column, ConstNeedle) , और यह रेग्युलर एक्सप्रेशन position(Column, ConstNeedle) लिए ऑप्टिमाइज़ेशन का काम करता है।
नियमित अभिव्यक्ति खोज
हम आपको बताएंगे कि कैसे ClickHouse नियमित अभिव्यक्ति खोजों का अनुकूलन करता है। कई नियमित अभिव्यक्तियों में अंदर एक विकल्प होता है, जो एक हिस्टैक के अंदर होना चाहिए। एक परिमित राज्य मशीन का निर्माण नहीं करने और इसके खिलाफ जांच करने के लिए, हम ऐसे पदार्थों को अलग कर देंगे।
ऐसा करने के लिए काफी सरल है: किसी भी उद्घाटन कोष्ठक नेस्टिंग के स्तर को बढ़ाते हैं, किसी भी समापन कोष्ठक में कमी आती है; नियमित अभिव्यक्तियों के लिए विशिष्ट वर्ण भी हैं (उदा। ',' * ','? ',' \ w ', आदि)। हमें स्तर पर सभी सबस्ट्रिंग प्राप्त करने की आवश्यकता है। एक उदाहरण पर विचार करें:
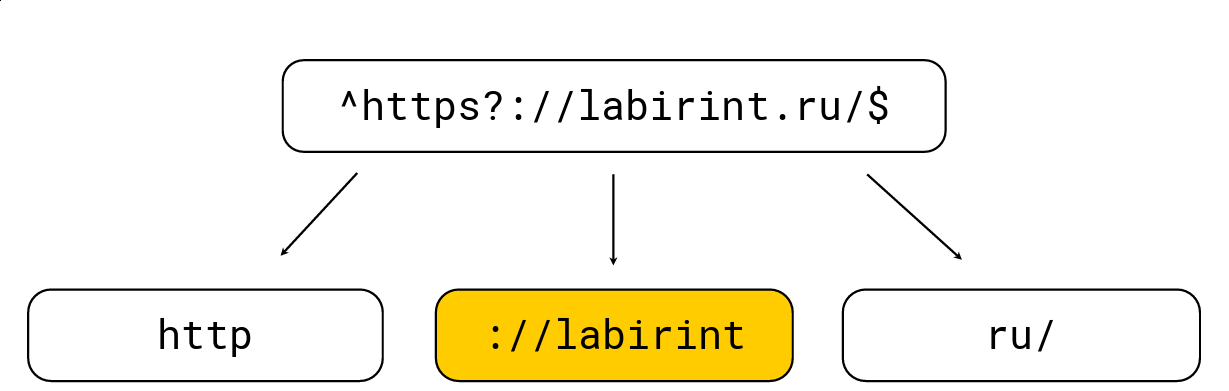
हम इसे उन सबस्ट्रिंग्स में तोड़ते हैं जो नियमित अभिव्यक्ति से प्रभावित होना चाहिए, जिसके बाद हम अधिकतम लंबाई का चयन करते हैं, इस पर उम्मीदवारों की तलाश करते हैं और फिर सामान्य RE2 नियमित अभिव्यक्ति इंजन के साथ जांच करते हैं। ऊपर की तस्वीर में एक नियमित अभिव्यक्ति है, यह सामान्य RE2 इंजन द्वारा 736 एमबी / एस पर संसाधित किया जाता है, हाइपरस्कैन (इसके बारे में थोड़ी देर बाद) 1.6 जीबी / एस का प्रबंधन करता है, और हम विस्मय के साथ 1.69 जीबी / एस प्रति कोर का प्रबंधन करते हैं LZ4। सामान्य तौर पर, इस तरह के अनुकूलन सतह पर होते हैं और नियमित अभिव्यक्तियों की खोज में बहुत तेजी लाते हैं, लेकिन अक्सर यह उपकरण में लागू नहीं होता है, जो मुझे बहुत आश्चर्यचकित करता है।
इस एल्गोरिथ्म का उपयोग करके LIKE कीवर्ड को भी ऑप्टिमाइज़ किया गया है, LIKE के बाद ही बहुत ही सरल रेगुलर एक्सप्रेशन %%%%%%% (मनमाने ढंग से प्रतिस्थापन) और _ (मनमाना चरित्र) में आ सकता है।
दुर्भाग्य से, सभी नियमित अभिव्यक्तियाँ इस तरह के अनुकूलन के अधीन नहीं हैं, उदाहरण के लिए, yandex|google यह संभव है कि उन पदार्थों को स्पष्ट रूप से अलग करना असंभव है जो कि हैस्टैक में होने चाहिए। इसलिए, हम पूरी तरह से अलग समाधान के साथ आए।
कई सबस्ट्रिंग्स की खोज करें
समस्या यह है कि बहुत सी सुई है, और मैं समझना चाहता हूं कि क्या उनमें से कम से कम एक हिस्टैक में शामिल है। ऐसी खोज के लिए काफी शास्त्रीय तरीके हैं, उदाहरण के लिए, अहो-कोरसिक एल्गोरिथ्म। लेकिन वह हमारे कार्य के लिए बहुत तेज नहीं था। हम इस बारे में थोड़ी देर बाद बात करेंगे।
Lesch ClickHouse गैर-मानक समाधानों से प्यार करता है, इसलिए हमने कुछ अलग करने की कोशिश करने का फैसला किया और, शायद, खुद एक नया खोज एल्गोरिदम बना। और उन्होंने किया।
हमने वोल्न्त्स्की एल्गोरिथ्म को देखा और इसे संशोधित किया ताकि यह एक ही बार में कई सबस्ट्रिंग की खोज करने लगे। ऐसा करने के लिए, आपको बस सभी पंक्तियों के बिग्रेड को जोड़ने और हैश तालिका में पंक्ति सूचकांक को संग्रहीत करने की आवश्यकता है। चरण को कम से कम सभी सुई लंबाई माइनस 1 से फिर से संपत्ति की गारंटी देने के लिए चुना जाएगा कि अगर कोई घटना होती है तो हम अपने आश्रम को देखेंगे। हैश टेबल 128 केबी तक बढ़ जाएगी (255 से अधिक लंबी लाइनें मानक एल्गोरिथ्म द्वारा संसाधित होती हैं, हम 256 सुइयों से अधिक नहीं मानेंगे)। मैं बहुत आलसी हूं, इसलिए यहां प्रस्तुति से एक उदाहरण है (ऊपर से नीचे तक बाएं से दाएं पढ़ें):


हमने यह देखना शुरू किया कि इस तरह का एल्गोरिदम दूसरों की तुलना में कैसे व्यवहार करता है (वास्तविक डेटा से पंक्तियाँ ली गई हैं)। और छोटी संख्या में लाइनों के लिए, वह सब कुछ करता है (उतराई के साथ गति का संकेत दिया जाता है - लगभग 2.5 जीबी / एस)।
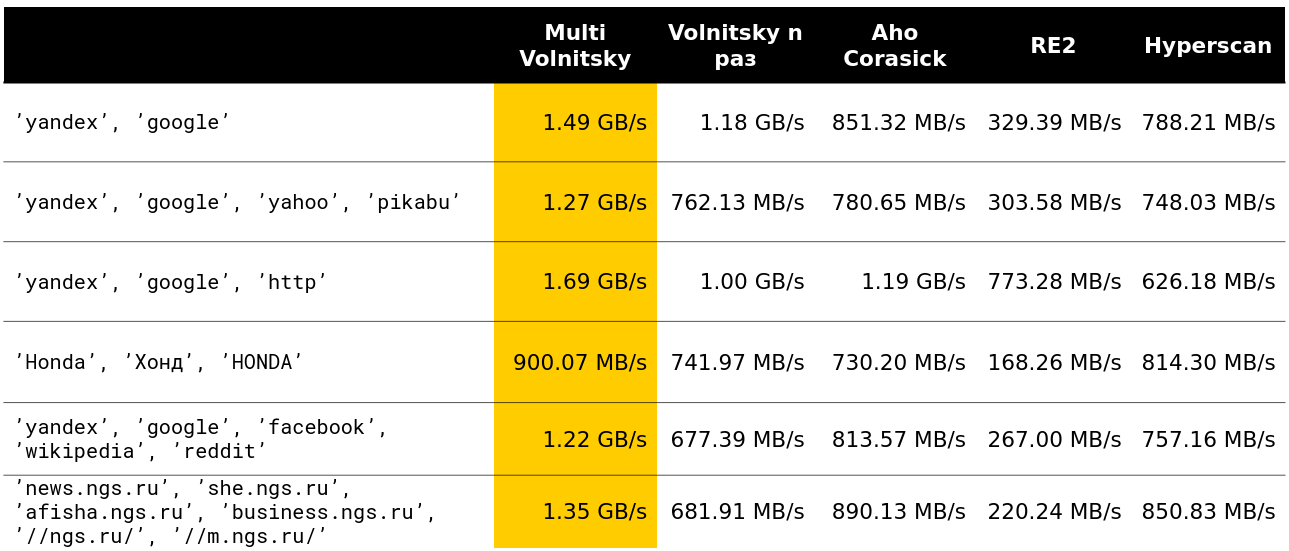
फिर यह दिलचस्प हो गया। उदाहरण के लिए, बड़ी संख्या में समान बीगर के साथ, हम कुछ प्रतियोगियों से हार जाते हैं। यह समझ में आता है - हम स्मृति के कई टुकड़ों और नीचा दिखाना शुरू करते हैं।

यदि सुई की न्यूनतम लंबाई काफी बड़ी है तो आप ज्यादा तेजी नहीं ला सकते। जाहिर है, हमारे पास इसके लिए कुछ भी भुगतान किए बिना हिस्टैक के पूरे टुकड़ों को छोड़ने के अधिक अवसर हैं।

टिपिंग बिंदु कहीं 13-15 लाइनों पर शुरू होता है। क्लस्टर पर मैंने जो अनुरोध देखे उनमें से लगभग 97% 15 पंक्तियों से कम थे:
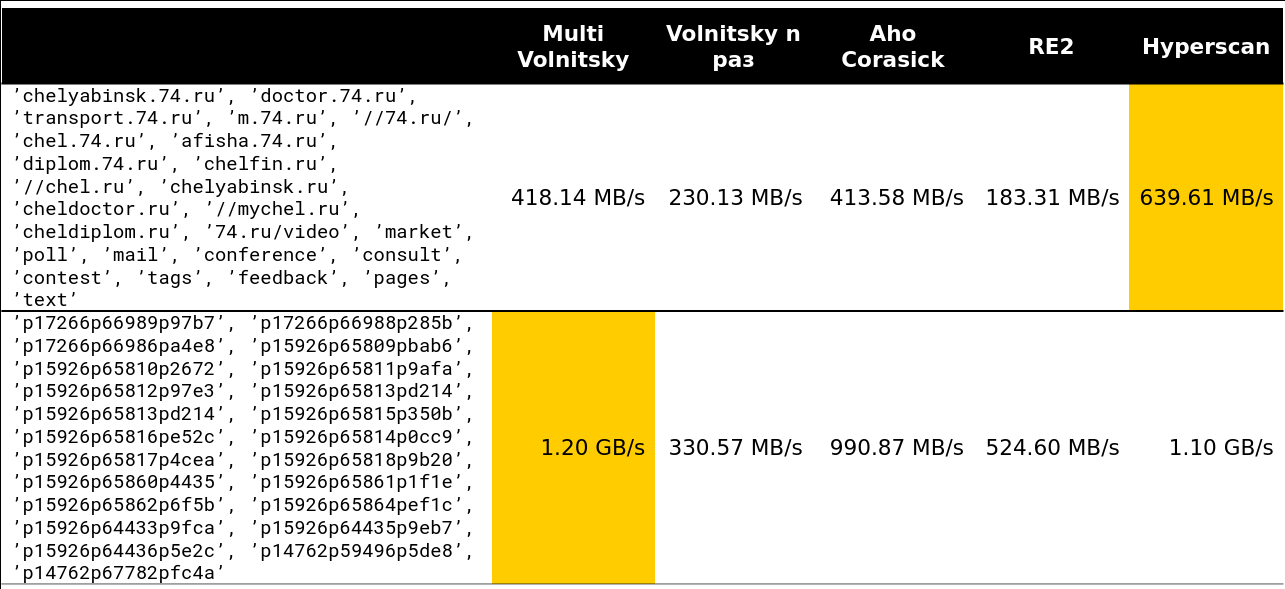
खैर, एक बहुत ही डरावनी तस्वीर - 41 पंक्तियाँ, कई दोहराते हुए बड़े शब्द:

परिणामस्वरूप, ClickHouse (19.5) में हमने इस एल्गोरिथ्म के माध्यम से निम्नलिखित कार्य कार्यान्वित किए:
- multiSearchAny(h, [n_1, ..., n_k]) - 1, यदि कम से कम सुइयों में से एक multiSearchAny(h, [n_1, ..., n_k]) में है।
- multiSearchFirstPosition(h, [n_1, ..., n_k]) - यदि नहीं पाया जाता है तो एक बार (एक से) या 0 में प्रवेश की सबसे बाईं स्थिति।
- multiSearchFirstIndex(h, [n_1, ..., n_k]) - सबसे बाईं सुई सूचकांक, जो कि multiSearchFirstIndex(h, [n_1, ..., n_k]) में पाया गया था; 0 अगर नहीं मिला।
- multiSearchAllPositions(h, [n_1, ..., n_k]) - सभी सुइयों के सभी पहले स्थान, एक सरणी देता है।
प्रत्यय हैं -UTF8 (हम सामान्य नहीं करते हैं) -CaseInsensitive (हम अलग-अलग केस के साथ 4 बीग्राम जोड़ते हैं), -CaseInsensitiveUTF8 (वहाँ एक शर्त है कि अपरकेस और लोअरकेस अक्षर बाइट्स की समान संख्या होनी चाहिए)। कार्यान्वयन यहाँ देखें।
उसके बाद, हमने सोचा कि क्या हम कई नियमित अभिव्यक्तियों के साथ कुछ ऐसा कर सकते हैं। और उन्हें एक समाधान मिला जो पहले से ही बेंचमार्क में खराब हो गया था।
कई नियमित अभिव्यक्तियों द्वारा खोजें
हाइपरस्कैन इंटेल से एक पुस्तकालय है जो कई नियमित अभिव्यक्तियों के लिए तुरंत खोज करता है। यह उन उपशब्दों को नियमित अभिव्यक्तियों से अलग करने के लिए उत्तराधिकार का उपयोग करता है, जिनके बारे में हमने लिखा था, और Glushkov automaton के लिए खोज करने के लिए बहुत से SIMDs (एल्गोरिथ्म को टेडी कहा जाता है)।
सामान्य तौर पर, सब कुछ नियमित अभिव्यक्तियों के लिए खोज से अधिकतम प्राप्त करने की सर्वोत्तम परंपराओं में है। पुस्तकालय वास्तव में वही करता है जो उसके कार्यों में घोषित किया जाता है।

सौभाग्य से, ClickHouse में मेरे विकास के महीने में, मैं प्रश्नों के एक सभ्य वर्ग पर 12 साल के विकास से आगे निकलने में सक्षम था और मैं इससे बहुत प्रसन्न हूं।
यांडेक्स में, हाइपरस्कैन लाइब्रेरी का उपयोग एंटीस्पैम में भी किया जाता है। समीक्षाओं को देखते हुए, वह शांति से हजारों नियमित अभिव्यक्तियों को संसाधित करती है और जल्दी से उनके लिए खोज करती है।
पुस्तकालय के कई नुकसान हैं। पहली बार सेवन की जाने वाली स्मृति की अघोषित मात्रा है और एक अजीब विशेषता है कि हिस्टैक 2 32 बाइट्स से कम होना चाहिए। दूसरा - आप मुफ्त में पहला स्थान नहीं छोड़ सकते हैं, सबसे बाईं ओर स्थित सुई सूचकांक आदि और तीसरा माइनस - नीले रंग से बाहर कुछ कीड़े हैं। इसलिए, ClickHouse में, हमने हाइपरस्कैन का उपयोग करते हुए निम्नलिखित कार्यों को लागू किया:
- multiMatchAny(h, [n_1, ..., n_k]) - 1, यदि कम से कम एक सुइयां multiMatchAny(h, [n_1, ..., n_k]) आईं।
- multiMatchAnyIndex(h, [n_1, ..., n_k]) - सुई से कोई भी सूचकांक जो multiMatchAnyIndex(h, [n_1, ..., n_k]) से multiMatchAnyIndex(h, [n_1, ..., n_k]) ।
हम रुचि रखते हैं, लेकिन आप वास्तव में नहीं, बल्कि लगभग कैसे खोज सकते हैं? और कई समाधानों के साथ आया।
अनुमानित खोज
अनुमानित खोज में मानक लेवेंसाइटिन दूरी है - न्यूनतम संख्या जो वर्णों को प्रतिस्थापित किया जा सकता है, जोड़ा जा सकता है और एक स्ट्रिंग बी से लंबाई n की एक स्ट्रिंग बी प्राप्त करने के लिए इसे हटाया जा सकता है। दुर्भाग्य से, भोले गतिशील प्रोग्रामिंग एल्गोरिथ्म O (mn) के लिए काम करता है; शाद के सर्वश्रेष्ठ दिमाग इसे ओ (एमएन / लॉग मैक्स (एन, एम)) में कर सकते हैं ; O ((n + m) , अल्फ़ा) के बारे में सोचना आसान है, जहाँ अल्फ़ा जवाब है; विज्ञान इसे O के लिए कर सकता है ((अल्फा - | n - m |) मिनट (m, n, अल्फा) + m + n) (एल्गोरिथ्म सरल है, कम से कम ShAD में पढ़ें) या, यदि थोड़ा स्पष्ट है, तो O (अल्फा): 2 + मीटर के लिए + एन) । अभी भी एक माइनस है: सबसे खराब स्थिति बहुपद में द्विघात समय से छुटकारा पाना सबसे असंभव है - पीटर इंडिक ने इस बारे में बहुत शक्तिशाली लेख लिखा।
एक व्यायाम है: कल्पना कीजिए कि लेवेंसहाइट दूरी में एक चरित्र को बदलने के लिए आप एक दो नहीं, बल्कि दो का जुर्माना देते हैं; फिर O ((n + m) लॉग (n + m)) के लिए एक एल्गोरिथ्म के साथ आते हैं।
यह अभी भी बहुत लंबा और महंगा काम नहीं करता है। लेकिन इस तरह की दूरी की मदद से हमने प्रश्नों में टाइपोस का पता लगाया।
लेवेंसहाइट दूरी के अलावा, एक हेमिंगिंग दूरी है। उसके साथ, भी, सब कुछ बहुत बुरा है, लेकिन लेवेंसहाइट दूरी के साथ थोड़ा बेहतर है। यह वर्णों को हटाने को ध्यान में नहीं रखता है, लेकिन केवल एक ही लंबाई की दो पंक्तियों के लिए उन वर्णों की संख्या पर विचार करता है जिनमें वे भिन्न होते हैं। इसलिए, यदि हम लंबाई m <n के तारों के लिए दूरी का उपयोग करते हैं, तो केवल निकटतम सब्सट्रेट की खोज में।
ऐसी विसंगतियों की गणना कैसे करें (n - m + 1 तत्वों की एक सरणी d, जहां d [i] ओवरले की शुरुआत से i-th में विभिन्न वर्णों की संख्या है) O (! | सिग्मा | (n m) लॉग (n + m) के लिए) ) ? पहले, करो | सिग्मा | बिट मास्क यह दर्शाता है कि क्या यह प्रतीक माना जाने वाला समान है। अगला, हम सिग्मा मास्क में से प्रत्येक के लिए उत्तर की गणना करते हैं और जोड़ते हैं - हमें मूल उत्तर मिलता है।
एक उदाहरण पर विचार करें। abba , स्थानापन्न ba , द्विआधारी वर्णमाला। हमें 2 मास्क 1001, 01 और 0110, 10 मिलते हैं।
a 1001 01 - 0 01 - 0 01 - 1
b 0110 10 - 0 10 - 1 10 - 1
हमें सरणी [0, 1, 2] मिलती है - यह लगभग सही उत्तर है। लेकिन ध्यान दें कि प्रत्येक अक्षर के लिए, मैचों की संख्या केवल एक निश्चित बाइनरी सुई और सभी हैस्टैक सब्सट्रिंग्स का स्केलर उत्पाद है। और इसके लिए, निश्चित रूप से, एक तेजी से फूरियर रूपांतरण है!
उन लोगों के लिए जो यह नहीं जानते हैं: एफएफटी एक समय ओ (एन लॉग एन) में दो मीटर की बहुपद की डिग्री दे सकता है, बशर्ते कि गुणांक के साथ काम प्रति यूनिट समय पर किया जाता है। संकल्प स्केलर उत्पादों के समान हैं। यह पहले बहुपद के गुणांक को डुप्लिकेट करने के लिए पर्याप्त है, और शून्य की आवश्यक संख्या के साथ दूसरे का विस्तार और पूरक करता है, फिर हम एक बाइनरी स्ट्रिंग के सभी स्केलर उत्पाद प्राप्त करते हैं और दूसरे के सभी सबस्ट्रिंग ओ (एन लॉग एन) में - किसी तरह का जादू! लेकिन मेरा विश्वास करो, यह बिल्कुल वास्तविक है, और कभी-कभी लोग ऐसा करते हैं।
लेकिन ClickHouse में नहीं। हमारे लिए, साथ काम करना | सिग्मा | = 30 पहले से ही बड़ा है, और एफएफटी प्रोसेसर के लिए सबसे सुखद व्यावहारिक एल्गोरिथ्म नहीं है या, जैसा कि वे आम लोगों में कहते हैं, "निरंतर बड़ा है।"
इसलिए, हमने अन्य मैट्रिक्स को देखने का फैसला किया। हम जैव सूचना विज्ञान के लिए गए, जहां लोग एन-ग्राम दूरी का उपयोग करते हैं। वास्तव में, हम सभी एन-ग्राम घास और सुई लेते हैं, इन एन-ग्राम के साथ 2 मल्टीसेट्स पर विचार करें। फिर हम सममित अंतर लेते हैं और एन-ग्राम के साथ दो मल्टीसिस के कार्डिनिटी के योग से विभाजित करते हैं। हमें 0 से 1 तक एक संख्या मिलती है - 0 के करीब, रेखाएं समान हैं। एक उदाहरण पर विचार करें जहां n = 4 :
abcda → {abcd, bcda}; Size = 2 bcdab → {bcda, cdab}; Size = 2 . |{abcd, cdab}| / (2 + 2) = 0.5
नतीजतन, हमने 4-ग्राम की दूरी बनाई और वहां एसएसई से विचारों का एक गुच्छा चिपका दिया, और हमने डबल-बाइट crc32 हैश के कार्यान्वयन को थोड़ा कमजोर कर दिया।
कार्यान्वयन की जाँच करें। सावधानी: संकलक के लिए बहुत सम्मोहक और अनुकूलित कोड।
मैं आपको विशेष रूप से सलाह देता हूं कि ASCII और रूसी कोड बिंदुओं के लिए निचले मामले को कास्टिंग के लिए गंदे हैक पर ध्यान दें।
- ngramDistance(haystack, needle) - 0 से 1 तक एक संख्या देता है; करीब 0, अधिक लाइनें एक दूसरे के समान हैं।
-UTF8, -CaseInsensitive, -CaseInsensitiveUTF8 (रूसियों और ASCII के लिए गंदा हैक)।
हाइपरस्कैन अभी भी खड़ा नहीं है - इसकी अनुमानित खोज के लिए कार्यक्षमता है: आप उन पंक्तियों की खोज कर सकते हैं जो लेवेंसहाइट की निरंतर दूरी से नियमित अभिव्यक्ति की तरह दिखती हैं। एक दूरी + 1 ऑटोमेटन बनाया गया है, जो एक चरित्र को हटाने, बदलने या सम्मिलित करने के द्वारा परस्पर जुड़ा हुआ है, जिसका अर्थ है "ठीक", जिसके बाद यह जांचने के लिए सामान्य एल्गोरिथ्म कि क्या एक ऑटोमेटन एक विशेष लाइन को स्वीकार करता है, लागू होता है। ClickHouse में, हमने उन्हें निम्नलिखित नामों के तहत लागू किया:
- multiFuzzyMatchAny(haystack, distance, [n_1, ..., n_k]) - मल्टीमाचैनी के समान, केवल दूरी के साथ।
- multiFuzzyMatchAnyIndex(haystack, distance, [n_1, ..., n_k]) - केवल दूरी के साथ multiMatchAnyIndex के समान।
बढ़ती दूरी के साथ , गति बहुत कम होने लगती है, लेकिन अभी भी काफी सभ्य स्तर पर बनी हुई है।
खोज को समाप्त करें और UTF-8 स्ट्रिंग्स को संसाधित करने के लिए नीचे उतरें। काफी दिलचस्प बातें भी हुईं।
UTF-8 लाइन प्रसंस्करण
मैं मानता हूं कि UTF-8 एनकोडेड स्ट्रिंग्स में भोले-भाले कार्यान्वयन की छत के माध्यम से तोड़ना मुश्किल था। विशेष रूप से SIMD को पेंच करना मुश्किल था। मैं यह कैसे करना है पर कुछ विचार साझा करूंगा।
याद रखें कि वैध UTF-8 अनुक्रम कैसा दिखता है:
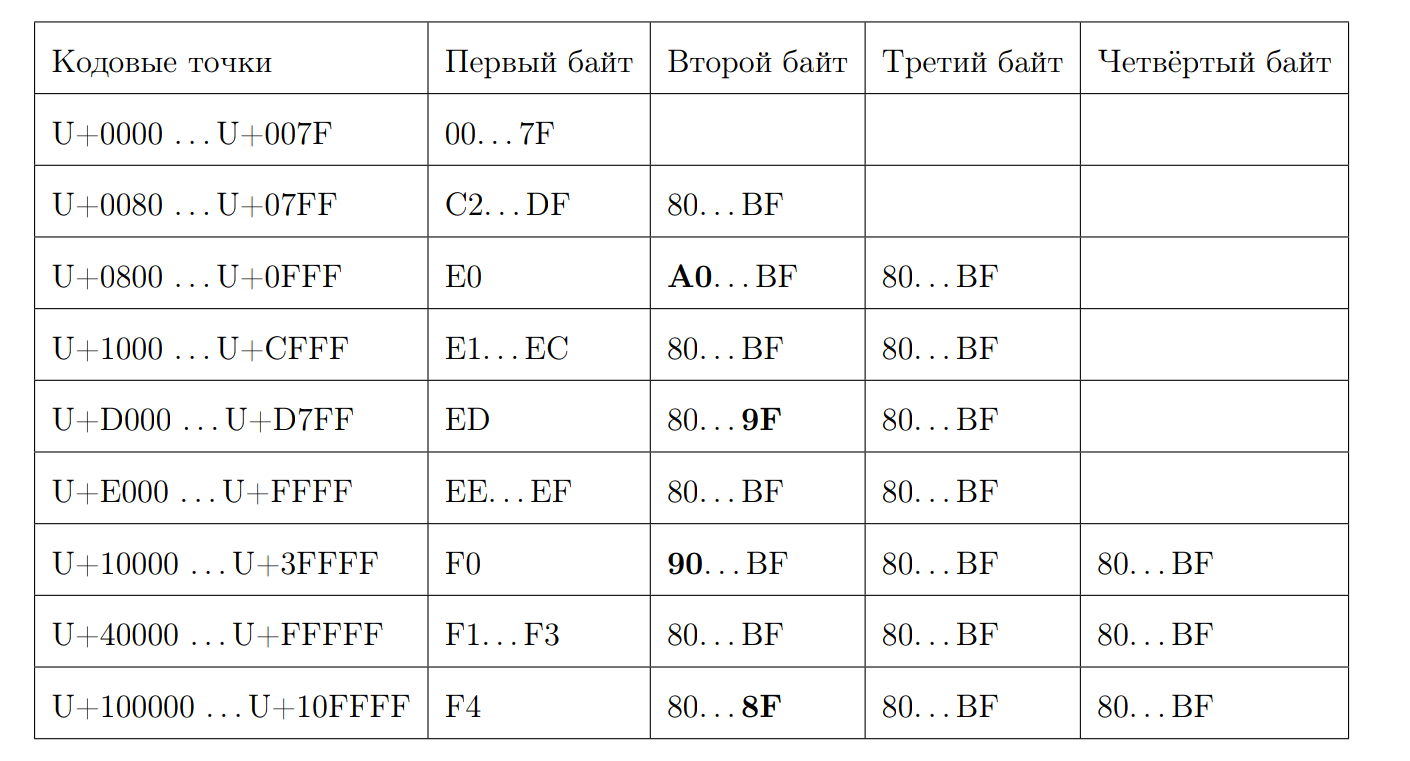
आइए पहले बाइट द्वारा कोड बिंदु की लंबाई की गणना करने का प्रयास करें। यह वह जगह है जहाँ बिट जादू शुरू होता है। फिर से हम कुछ गुण लिखते हैं:
- 0xC पर शुरू और 0xD पर 2 बाइट्स हैं
- 0xC2 = 11 0 00010
- 0xDF = 11 0 11111
- 0xE0 = 111 0 0000
- 0xF4 = 1111 0 100, 0xF4 से आगे कुछ भी नहीं है, लेकिन अगर 0xF8 था, तो एक अलग कहानी होगी
- उत्तर 7 पहले शून्य से अंत की स्थिति, यदि यह ASCII वर्ण नहीं है
हम लंबाई की गणना करते हैं:
inline size_t seqLength(const UInt8 first_octet) { if (first_octet < 0x80u) return 1; const auto first_zero = bitScanReverse(static_cast<UInt8>(~first_octet)); return 7 - first_zero; }
सौभाग्य से, हमारे पास स्टॉक निर्देश हैं जो शून्य बिट्स की संख्या की गणना कर सकते हैं, सबसे महत्वपूर्ण लोगों के साथ शुरू करते हैं।
f = __builtin_clz(val)
गणना करें
unsigned int bitScanReverse(unsigned int x) { return 31 - __builtin_clz(x); }
आइए SIMD के माध्यम से कोड बिंदुओं द्वारा UTF-8 स्ट्रिंग की लंबाई की गणना करने का प्रयास करें। ऐसा करने के लिए, प्रत्येक बाइट को एक हस्ताक्षरित संख्या के रूप में देखें और निम्नलिखित गुणों पर ध्यान दें:
- 0xBF = -65
- 0x80 = -128
- 0xC2 = -62
- 0x7F = 127
- सभी प्रथम बाइट्स [0xC2, 0x7F] में हैं
- सभी गैर-प्रथम बाइट्स [0x80, 0xBF] में हैं
एल्गोरिथ्म काफी सरल है। प्रत्येक बाइट की तुलना -65 से करें और, यदि यह इस संख्या से अधिक है, तो एक जोड़ें। यदि हम SIMD का उपयोग करना चाहते हैं, तो यह इनपुट स्ट्रीम से 16 बाइट्स का सामान्य भार है। फिर एक बाइट तुलना है, जो एक सकारात्मक परिणाम के मामले में बाइट 0xFF देगा, और एक नकारात्मक के मामले में - 0x00। फिर pmovmskb निर्देश, जो रजिस्टर के प्रत्येक बाइट के उच्च बिट्स को इकट्ठा करेगा। फिर अंडरस्कोर की संख्या बढ़ जाती है, हम popcnt SSE4 निर्देश के लिए आंतरिक का उपयोग करते हैं। इस एल्गोरिथ्म की योजना एक उदाहरण द्वारा स्पष्ट की जा सकती है:

यह पता चला है कि अपघटन के साथ, प्रति कोर प्रसंस्करण 1.5 जीबी / एस होगा।
कार्यों को कहा जाता है:
- lengthUTF8(string) - सही ढंग से एन्कोडेड UTF-8 स्ट्रिंग की लंबाई लौटाता है, कुछ को अमान्य माना जाता है, एक अपवाद नहीं फेंका गया है।
हम और आगे बढ़ गए क्योंकि हम UTF-8 स्ट्रिंग प्रसंस्करण के साथ और भी अधिक कार्य करना चाहते थे। उदाहरण के लिए, वैध यूटीएफ -8 अभिव्यक्ति की वैधता और कास्टिंग के लिए जाँच।
वैधता की जांच करने के लिए, मैंने ClickHouse के लिए अनुकूलित https://github.com/cyb70289/utf8/ लिया, (वास्तव में बस पूंछ के प्रसंस्करण को बदल दिया) और भोली एल्गोरिथ्म के लिए 900 एमबी / एस की तुलना में 1.22 जीबी / एस की गति प्राप्त की। । मैं स्वयं एल्गोरिथ्म का वर्णन नहीं करूंगा, यह धारणा के लिए काफी जटिल है।
isValidUTF8(string) - 1 रिटर्न देता है यदि स्ट्रिंग सही ढंग से UTF-8 के साथ एनकोडेड है, अन्यथा 0।
- toValidUTF8(string) - अमान्य UTF-8 वर्णों को D (U + FFFD) वर्ण से बदल देता है। सभी लगातार अमान्य वर्ण एक प्रतिस्थापन चरित्र में ढह जाते हैं। कोई रॉकेट साइंस नहीं।
सामान्य तौर पर, UTF-8 लाइनों में, सुखद-स्थिर स्थिर योजना के कारण, ऐसी चीज़ के साथ आना हमेशा मुश्किल होता है जिसे अच्छी तरह से अनुकूलित किया जाता है।
आगे क्या है?
आपको याद दिला दूं कि यह मेरी थीसिस थी। बेशक, मैंने उसे 10/10 के लिए बचाव किया। हम पहले से ही उसके साथ हाईलोड + साइबेरिया गए थे (हालांकि मुझे ऐसा लग रहा था कि वह किसी के लिए कम दिलचस्पी थी)। प्रस्तुति देखें । मुझे यह पसंद आया कि थीसिस का व्यावहारिक हिस्सा काफी दिलचस्प शोध के परिणामस्वरूप हुआ। और यहाँ डिप्लोमा ही है। इसके बहुत सारे टाइपोस हैं, क्योंकि कोई भी इसे नहीं पढ़ता है। :)
डिप्लोमा की तैयारी के हिस्से के रूप में, मैंने इसी तरह के अन्य कार्यों का एक समूह किया (लिंक पूल अनुरोध के लिए नेतृत्व करता है):
- 2 बार अनुकूलित कॉकटैट फ़ंक्शन ;
- अनुरोधों के लिए सबसे सरल अजगर प्रारूप बनाया ;
- त्वरित LZ4 4% से ;
- मैंने ARMD और PPC64LE के लिए SIMD पर बहुत अच्छा काम किया ;
- और उन्होंने एफसीएस के कुछ छात्रों को क्लिकहाउस में डिप्लोमा के साथ सलाह दी।
अंत में, यह पता चला कि, मेरे अनुभव में, हर महीने लेसा ने मुझे जप करने की कोशिश की हाई-परफॉर्मेंस कोड लिखने के लिए ClickHouse सबसे सुखद प्रणाली है, जहां प्रलेखन, टिप्पणियां, उत्कृष्ट डेवलपर और डेप्स समर्थन हैं। ClickHouse वास्तव में कमाल है। JSON स्वरूपों को बदलने से थक गए? लेसा में आओ और किसी भी स्तर के कार्य के लिए पूछें - वह इसे आपके लिए प्रदान करेगा, और सप्ताहांत में आपको कोड लिखने से बहुत खुशी मिलेगी।
लेकिन ClickHouse और इसके डिजाइन की सभी उपलब्धियों के साथ, यह शायद उनके बारे में नहीं है। मुख्य रूप से उनमें नहीं।
मैं एफसीएस में 4 साल के स्नातक अध्ययन से गुजरा, जून में मैंने एचएसई से सम्मान के साथ स्नातक की उपाधि प्राप्त की, डेढ़ साल यांडेक्स में एक भयानक टीम में काम किया, अच्छी तरह से पंप किया। इस समय कुल अनुभव के बिना और लोहा पोस्ट में लिखा कुछ भी काम नहीं किया होगा। यदि आप इससे अधिकतम लेते हैं, तो एफसीएन बहुत अच्छा है। एफसीएन पर मेरे मजाकिया साहसिक कार्य में बैठक के लिए वाना पुजेरेवस्की आइवन_पूज्यरेवस्की , इग्नाट कोलेस्निकेंको , ग्लीब इवस्ट्रोपोव , मैक्स बबेंको मैक्सिम_बेंको को धन्यवाद। और उन सभी शिक्षकों का भी धन्यवाद जिन्होंने मुझे कुछ सिखाया।