परिचय
कुछ साल पहले, हमने तय किया कि यह .NET कोड में SIMD कोड को सपोर्ट करने का समय है । हमने System.Numerics नामस्थान को Vector<T> Vector4 Vector<T> Vector4 Vector<T> और Vector<T> । ये प्रकार जब भी संभव हो वेक्टर निर्देश बनाने, एक्सेस करने और हेरफेर करने के लिए एक सामान्य-उद्देश्य एपीआई का प्रतिनिधित्व करते हैं। वे उन मामलों के लिए सॉफ्टवेयर संगतता भी प्रदान करते हैं जहां हार्डवेयर उपयुक्त निर्देशों का समर्थन नहीं करता है। इसने कम से कम रिफैक्टरिंग के साथ, कई एल्गोरिदम को वेक्टर करने की अनुमति दी। जैसा कि यह हो सकता है, इस दृष्टिकोण की व्यापकता आधुनिक हार्डवेयर, वेक्टर निर्देशों पर सभी उपलब्ध का पूरा लाभ प्राप्त करने के लिए आवेदन करना मुश्किल बना देती है। इसके अलावा, आधुनिक हार्डवेयर कई विशिष्ट, गैर-वेक्टर, निर्देश प्रदान करता है जो प्रदर्शन में काफी सुधार कर सकते हैं। इस लेख में, मैं बात करूंगा कि कैसे हमने .NET कोर 3.0 में इन सीमाओं को दरकिनार किया।

नोट: अभी तक इंट्रिसिक्स अनुवाद के लिए कोई स्थापित शब्द नहीं है । लेख के अंत में अनुवाद विकल्प के लिए एक वोट है। यदि हम एक अच्छा विकल्प चुनते हैं, तो हम लेख को बदल देंगे
अंतर्निहित कार्य क्या हैं
.NET कोर 3.0 में, हमने हार्डवेयर-विशिष्ट बिल्ट-इन फ़ंक्शन (दूर WF) नामक नई कार्यक्षमता जोड़ी है। यह कार्यक्षमता कई विशिष्ट हार्डवेयर निर्देशों तक पहुंच प्रदान करती है, जिन्हें केवल अधिक सामान्य-उद्देश्य तंत्र द्वारा प्रस्तुत नहीं किया जा सकता है। वे मौजूदा SIMD निर्देशों से अलग हैं कि उनके पास एक सामान्य उद्देश्य नहीं है (नए WFs क्रॉस-प्लेटफ़ॉर्म नहीं हैं और उनकी वास्तुकला सॉफ्टवेयर संगतता प्रदान नहीं करती है)। इसके बजाय, वे .NET डेवलपर्स के लिए सीधे मंच और हार्डवेयर-विशिष्ट कार्यक्षमता प्रदान करते हैं। मौजूदा SIMD फ़ंक्शंस, उदाहरण के लिए, क्रॉस-प्लेटफ़ॉर्म, सॉफ़्टवेयर संगतता प्रदान करते हैं, और वे अंतर्निहित हार्डवेयर से थोड़ा सार होते हैं। यह अमूर्त महंगा हो सकता है, इसके अलावा, यह कुछ कार्यक्षमता के प्रकटीकरण को रोक सकता है (जब, उदाहरण के लिए, कार्यक्षमता मौजूद नहीं है, या सभी लक्ष्य प्लेटफार्मों पर अनुकरण करना मुश्किल है)।
नए अंतर्निहित फ़ंक्शन और समर्थित प्रकार, System.Runtime.Intrinsics अंतर्गत स्थित हैं। .NET कोर 3.0 के लिए, इस समय, एक System.Runtime.Intrinsics.X86 । हम अन्य प्लेटफार्मों जैसे System.Runtime.Intrinsics.Arm लिए अंतर्निहित कार्यों का समर्थन करने पर काम कर रहे हैं।
प्लेटफ़ॉर्म-विशिष्ट नामस्थानों के तहत, WF को उन कक्षाओं में वर्गीकृत किया जाता है जो तार्किक रूप से एकीकृत हार्डवेयर निर्देशों (अक्सर निर्देश सेट आर्किटेक्चर (ISA)) के समूहों का प्रतिनिधित्व करते हैं। प्रत्येक वर्ग एक IsSupported संपत्ति प्रदान करता है IsSupported इंगित करता है कि कोड जिस हार्डवेयर पर चल रहा है वह निर्देशों के इस सेट का समर्थन करता है। इसके अलावा, प्रत्येक ऐसे वर्ग में निर्देशों के संगत सेट में मैप की गई विधियों का एक सेट होता है। कभी-कभी एक अतिरिक्त उपवर्ग होता है जो समान अनुदेश सेट के एक भाग से मेल खाता है, जो विशिष्ट हार्डवेयर द्वारा सीमित (समर्थित) हो सकता है। उदाहरण के लिए, Lzcnt वर्ग अग्रणी शून्य गणना के लिए निर्देशों तक पहुंच प्रदान करता है। उसके पास X64 64 नामक एक उपवर्ग है, जिसमें केवल 64-बिट वास्तुकला वाले मशीनों पर उपयोग किए जाने वाले इन निर्देशों का रूप शामिल है।
इनमें से कुछ वर्ग प्रकृति में स्वाभाविक रूप से पदानुक्रमित हैं। उदाहरण के लिए, यदि Lzcnt.X64.IsSupported सही है, तो Lzcnt.IsSupported भी सही लौटना चाहिए, क्योंकि यह एक स्पष्ट उपवर्ग है। या, उदाहरण के लिए, यदि Sse2.IsSupported सही है, तो Sse.IsSupported सही Sse.IsSupported चाहिए, क्योंकि Sse2 स्पष्ट रूप से Sse से विरासत में Sse । हालांकि, यह ध्यान देने योग्य है कि वर्ग नामों की समानता उनके वंशानुगत पदानुक्रम से संबंधित होने का सूचक नहीं है। उदाहरण के लिए, Bmi2 विरासत Bmi2 नहीं मिला है, इसलिए निर्देश के इन दो सेटों के लिए IsSupported द्वारा लौटाए गए मान अलग-अलग होंगे। इन वर्गों के विकास में मूलभूत सिद्धांत आईएसए विनिर्देशों की स्पष्ट प्रस्तुति थी। SSE2 को SSE1 के लिए समर्थन की आवश्यकता होती है, इसलिए जो वर्ग उनका प्रतिनिधित्व करते हैं वे विरासत से संबंधित हैं। उसी समय, बीएमआई 2 को बीएमआई 1 के लिए समर्थन की आवश्यकता नहीं होती है, इसलिए हमने विरासत का उपयोग नहीं किया। निम्नलिखित उपरोक्त एपीआई का एक उदाहरण है।
namespace System.Runtime.Intrinsics.X86 { public abstract class Sse { public static bool IsSupported { get; } public static Vector128<float> Add(Vector128<float> left, Vector128<float> right); // Additional APIs public abstract class X64 { public static bool IsSupported { get; } public static long ConvertToInt64(Vector128<float> value); // Additional APIs } } public abstract class Sse2 : Sse { public static new bool IsSupported { get; } public static Vector128<byte> Add(Vector128<byte> left, Vector128<byte> right); // Additional APIs public new abstract class X64 : Sse.X64 { public static bool IsSupported { get; } public static long ConvertToInt64(Vector128<double> value); // Additional APIs } } }
आप निम्न लिंक source.dot.net या GitHub पर dotnet / coreclr पर स्रोत कोड में अधिक देख सकते हैं
IsSupported जाँचों IsSupported JIT कंपाइलर द्वारा रन-टाइम स्थिरांक (जब अनुकूलन सक्षम किया जाता है) के रूप में संसाधित किया जाता है, इसलिए आपको कई ISAs, प्लेटफ़ॉर्म या आर्किटेक्चर का समर्थन करने के लिए क्रॉस-संकलन की आवश्यकता नहीं होती है। इसके बजाय, आपको केवल कोड का उपयोग करना होगा if अभिव्यक्तियों का उपयोग करना, जिसके परिणामस्वरूप अप्रयुक्त कोड शाखाएं (यानी उन शाखाएं जो सशर्त विवरण में चर के मूल्य के कारण पहुंच योग्य नहीं हैं) को मूल कोड उत्पन्न होने पर छोड़ दिया जाएगा।
यह महत्वपूर्ण है कि संबंधित IsSupported का सत्यापन अंतर्निहित हार्डवेयर कमांड के उपयोग से पहले हो। यदि ऐसा कोई चेक नहीं है, तो कोड जो प्लेटफ़ॉर्म / आर्किटेक्चर पर चलने वाले प्लेटफ़ॉर्म-विशिष्ट कमांड का उपयोग करता है, जहां ये कमांड समर्थित नहीं हैं, एक PlatformNotSupportedException रनटाइम अपवाद को फेंक देगा।
वे क्या लाभ प्रदान करते हैं?
बेशक, हार्डवेयर-विशिष्ट अंतर्निहित कार्य सभी के लिए नहीं हैं , लेकिन उनका उपयोग गणनाओं के साथ लोड किए गए संचालन में प्रदर्शन को बेहतर बनाने के लिए किया जा सकता है। CoreFX और ML.NET इन तरीकों का उपयोग मेमोरी को कॉपी करने, किसी एरे या स्ट्रिंग में किसी एलिमेंट के इंडेक्स को खोजने, इमेज का आकार बदलने, या वैक्टर / मैट्रेस / टेनर्स के साथ काम करने के लिए करते हैं। कुछ कोड का मैनुअल वैरिएशन जो एक अड़चन के रूप में सामने आया था, वह सुनने में भी सरल हो सकता है। कोड का वैश्वीकरण, वास्तव में, एक समय में कई ऑपरेशन करना है, सामान्य तौर पर, SIMD निर्देशों (एक निर्देश धारा, कई डेटा स्ट्रीम) का उपयोग करके।
इससे पहले कि आप कुछ कोड को सदिश करने का निर्णय लें, आपको यह सुनिश्चित करने के लिए रूपरेखा तैयार करनी होगी कि यह कोड वास्तव में "हॉट स्पॉट" का हिस्सा है (और, इसलिए, आपका अनुकूलन एक महत्वपूर्ण प्रदर्शन को बढ़ावा देगा)। वेक्टराइजेशन के प्रत्येक चरण में प्रोफाइलिंग करना भी महत्वपूर्ण है, क्योंकि सभी कोड के वेक्टराइजेशन से उत्पादकता नहीं बढ़ती है।
एक साधारण एल्गोरिथ्म का वैश्वीकरण
अंतर्निहित कार्यों के उपयोग को स्पष्ट करने के लिए , हम किसी सरणी या श्रेणी के सभी तत्वों को समेटने के लिए एल्गोरिथ्म लेते हैं। इस तरह का कोड वैश्वीकरण के लिए एक आदर्श उम्मीदवार है, क्योंकि प्रत्येक पुनरावृत्ति पर, एक ही तुच्छ ऑपरेशन किया जाता है।
इस तरह के एक एल्गोरिथ्म का एक उदाहरण कार्यान्वयन निम्नानुसार लग सकता है:
public int Sum(ReadOnlySpan<int> source) { int result = 0; for (int i = 0; i < source.Length; i++) { result += source[i]; } return result; }
यह कोड काफी सरल और सीधा है, लेकिन एक ही समय में बड़े इनपुट डेटा के लिए पर्याप्त धीमा है, जैसा कि प्रति चलना केवल एक तुच्छ ऑपरेशन करता है।
BenchmarkDotNet=v0.11.5, OS=Windows 10.0.18362 AMD Ryzen 7 1800X, 1 CPU, 16 logical and 8 physical cores .NET Core SDK=3.0.100-preview9-013775 [Host] : .NET Core 3.0.0-preview9-19410-10 (CoreCLR 4.700.19.40902, CoreFX 4.700.19.40917), 64bit RyuJIT [AttachedDebugger] DefaultJob : .NET Core 3.0.0-preview9-19410-10 (CoreCLR 4.700.19.40902, CoreFX 4.700.19.40917), 64bit RyuJIT
तैनाती चक्रों के माध्यम से उत्पादकता बढ़ाएँ
कोड प्रदर्शन में सुधार के लिए आधुनिक प्रोसेसर के पास विभिन्न विकल्प हैं। एकल-थ्रेडेड अनुप्रयोगों के लिए, एक ऐसा विकल्प एक प्रोसेसर चक्र में कई आदिम संचालन करना है।
अधिकांश आधुनिक प्रोसेसर एक घड़ी चक्र (इष्टतम परिस्थितियों में) में चार अतिरिक्त संचालन कर सकते हैं, जिसके परिणामस्वरूप, कोड के सही "लेआउट" के साथ, आप कभी-कभी एकल थ्रेडेड कार्यान्वयन में भी प्रदर्शन में सुधार कर सकते हैं।
यद्यपि जेआईटी अपने दम पर अनियंत्रित लूप का प्रदर्शन कर सकता है, लेकिन जेआईटी उत्पन्न कोड के आकार के कारण इस तरह का निर्णय लेने में रूढ़िवादी है। इसलिए, कोड में, मैन्युअल रूप से लूप की तैनाती करना फायदेमंद हो सकता है।
आप ऊपर दिए गए कोड में लूप का विस्तार इस प्रकार कर सकते हैं:
public unsafe int SumUnrolled(ReadOnlySpan<int> source) { int result = 0; int i = 0; int lastBlockIndex = source.Length - (source.Length % 4); // Pin source so we can elide the bounds checks fixed (int* pSource = source) { while (i < lastBlockIndex) { result += pSource[i + 0]; result += pSource[i + 1]; result += pSource[i + 2]; result += pSource[i + 3]; i += 4; } while (i < source.Length) { result += pSource[i]; i += 1; } } return result; }
यह कोड थोड़ा अधिक जटिल है, लेकिन यह हार्डवेयर सुविधाओं का बेहतर उपयोग करता है।
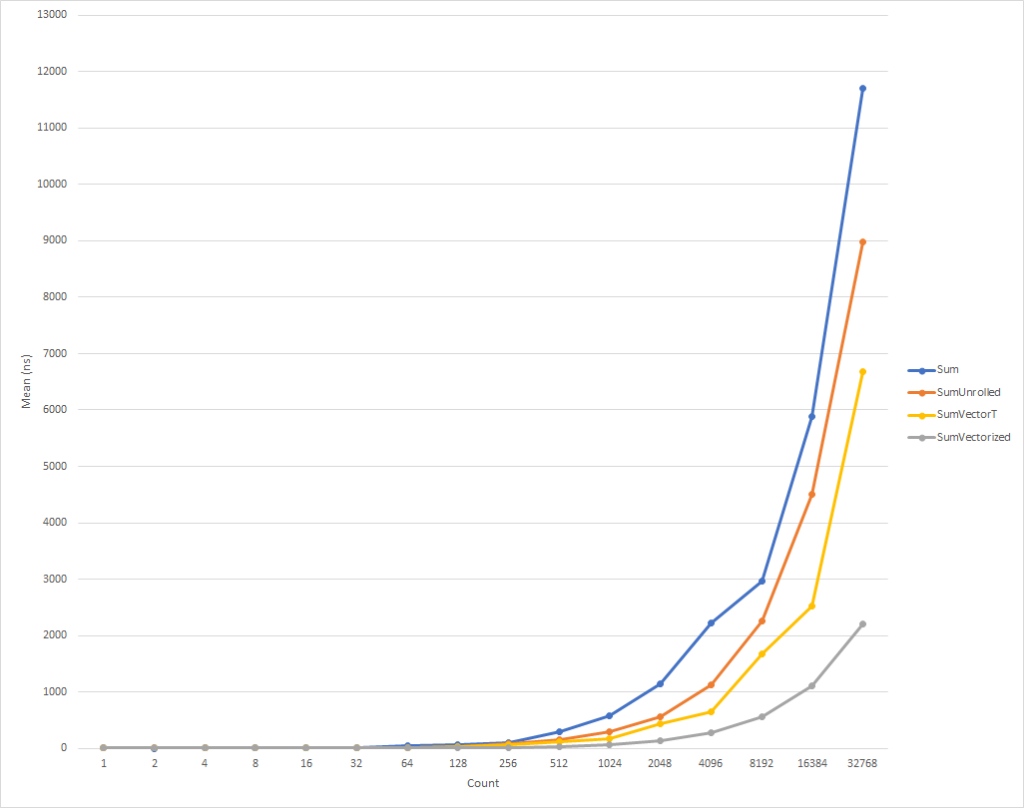
वास्तव में छोटे छोरों के लिए, यह कोड थोड़ा धीमा चलता है। लेकिन आठ तत्वों के इनपुट डेटा के लिए यह प्रवृत्ति पहले से ही बदल रही है, जिसके बाद निष्पादन की गति बढ़नी शुरू हो जाती है (32 हजार तत्वों के लिए अनुकूलित कोड का निष्पादन समय, मूल संस्करण के समय से 26% कम है)। यह ध्यान देने योग्य है कि ऐसे अनुकूलन हमेशा उत्पादकता में वृद्धि नहीं करते हैं। उदाहरण के लिए, टाइप float तत्वों के साथ संग्रह के साथ काम करते समय, एल्गोरिथ्म float "तैनात" संस्करण में मूल एक के समान गति होती है। इसलिए, प्रोफाइलिंग को अंजाम देना बहुत जरूरी है।

लूप वेक्टर के माध्यम से उत्पादकता बढ़ाएं
जैसा कि हो सकता है, लेकिन हम अभी भी इस कोड को थोड़ा अनुकूलित कर सकते हैं। SIMD निर्देश प्रदर्शन को बेहतर बनाने के लिए आधुनिक प्रोसेसर द्वारा प्रदान किया गया एक और विकल्प है। एक निर्देश का उपयोग करते हुए, वे आपको एक ही घड़ी चक्र में कई ऑपरेशन करने की अनुमति देते हैं। यह प्रत्यक्ष लूप अनफोल्डिंग से बेहतर हो सकता है, क्योंकि वास्तव में, एक ही काम किया जाता है, लेकिन उत्पन्न कोड की थोड़ी मात्रा के साथ।
स्पष्ट करने के लिए, प्रत्येक अतिरिक्त ऑपरेशन, एक तैनात चक्र में, 4 बाइट्स लेता है। इस प्रकार, हमें विस्तारित रूप में जोड़ के 4 संचालन के लिए 16 बाइट्स की आवश्यकता है। इसी समय, SIMD अतिरिक्त निर्देश 4 अतिरिक्त संचालन भी करता है, लेकिन केवल 4 बाइट्स लेता है। इसका मतलब है कि हमारे पास सीपीयू के लिए कम निर्देश हैं। इसके अलावा, एक SIMD अनुदेश के मामले में, सीपीयू धारणा बना सकता है और अनुकूलन कर सकता है, लेकिन यह इस लेख के दायरे से परे है। इससे भी बेहतर यह है कि आधुनिक प्रोसेसर एक समय में एक से अधिक SIMD अनुदेश निष्पादित कर सकते हैं, अर्थात, कुछ मामलों में, आप एक मिश्रित रणनीति लागू कर सकते हैं, उसी समय एक आंशिक चक्र स्कैन और वेक्टराइजेशन कर सकते हैं।
सामान्य तौर पर, आपको अपने कार्यों के लिए Vector<T> सामान्य उद्देश्य वर्ग को देखकर शुरू करना होगा। वह नई डब्ल्यूएफएस की तरह, सिमडी निर्देशों को एम्बेड करेगा, लेकिन साथ ही, इस वर्ग की बहुमुखी प्रतिभा को देखते हुए, वह "मैनुअल" कोडिंग की संख्या को कम कर सकता है।
कोड इस तरह दिख सकता है:
public int SumVectorT(ReadOnlySpan<int> source) { int result = 0; Vector<int> vresult = Vector<int>.Zero; int i = 0; int lastBlockIndex = source.Length - (source.Length % Vector<int>.Count); while (i < lastBlockIndex) { vresult += new Vector<int>(source.Slice(i)); i += Vector<int>.Count; } for (int n = 0; n < Vector<int>.Count; n++) { result += vresult[n]; } while (i < source.Length) { result += source[i]; i += 1; } return result; }
यह कोड तेजी से काम करता है, लेकिन अंतिम राशि की गणना करते समय हमें प्रत्येक तत्व को अलग से संदर्भित करने के लिए मजबूर किया जाता है। इसके अलावा, Vector<T> में एक सटीक परिभाषित आकार नहीं है, और भिन्न हो सकते हैं, उन उपकरणों पर निर्भर करता है जिनके आधार पर कोड चल रहा है। हार्डवेयर-विशिष्ट अंतर्निहित फ़ंक्शन अतिरिक्त कार्यक्षमता प्रदान करते हैं जो इस कोड को थोड़ा सुधार सकते हैं और इसे थोड़ा तेज़ कर सकते हैं (अतिरिक्त कोड जटिलता और रखरखाव आवश्यकताओं की लागत पर)।

नोट इस आलेख के लिए, मैंने आंतरिक कॉन्फ़िगरेशन पैरामीटर ( COMPlus_SIMD16ByteOnly=1 ) का उपयोग करके Vector<T> आकार को 16 बाइट्स के बराबर बनाया। इस ट्वीक ने SumVectorT साथ SumVectorizedSse तुलना करते समय परिणामों को सामान्य किया और हमें कोड को सरल रखने की अनुमति दी। विशेष रूप से, यह एक सशर्त कूद लिखने से if (Avx2.IsSupported) { } । यह कोड Sse2 के कोड के लगभग समान है, लेकिन Vector256<T> (32-बाइट) के साथ काम करता है और लूप के एक पुनरावृत्ति में और भी अधिक तत्वों को संसाधित करता है।
इस प्रकार, नए अंतर्निहित कार्यों का उपयोग करते हुए, कोड को निम्नानुसार फिर से लिखा जा सकता है:
public int SumVectorized(ReadOnlySpan<int> source) { if (Sse2.IsSupported) { return SumVectorizedSse2(source); } else { return SumVectorT(source); } } public unsafe int SumVectorizedSse2(ReadOnlySpan<int> source) { int result; fixed (int* pSource = source) { Vector128<int> vresult = Vector128<int>.Zero; int i = 0; int lastBlockIndex = source.Length - (source.Length % 4); while (i < lastBlockIndex) { vresult = Sse2.Add(vresult, Sse2.LoadVector128(pSource + i)); i += 4; } if (Ssse3.IsSupported) { vresult = Ssse3.HorizontalAdd(vresult, vresult); vresult = Ssse3.HorizontalAdd(vresult, vresult); } else { vresult = Sse2.Add(vresult, Sse2.Shuffle(vresult, 0x4E)); vresult = Sse2.Add(vresult, Sse2.Shuffle(vresult, 0xB1)); } result = vresult.ToScalar(); while (i < source.Length) { result += pSource[i]; i += 1; } } return result; }
यह कोड, फिर से थोड़ा अधिक जटिल है, लेकिन यह सबसे छोटे इनपुट सेटों को छोड़कर सभी के लिए काफी तेज है। 32 हजार तत्वों के लिए, यह कोड विस्तारित चक्र की तुलना में 75% तेजी से निष्पादित होता है, और उदाहरण के स्रोत कोड की तुलना में 81% अधिक तेजी से होता है।
आपने देखा कि हमने कुछ IsSupported चेक लिखे। पहले एक जाँच करता है कि क्या वर्तमान हार्डवेयर अंतर्निहित फ़ंक्शन के आवश्यक सेट का समर्थन करता है , यदि नहीं, तो स्वीप और Vector<T> संयोजन के माध्यम से अनुकूलन किया जाता है। बाद वाला विकल्प एआरएम / एआरएम 64 जैसे प्लेटफार्मों के लिए चुना जाएगा जो आवश्यक निर्देश सेट का समर्थन नहीं करते हैं, या यदि सेट को प्लेटफॉर्म के लिए अक्षम कर दिया गया है। SumVectorizedSse2 विधि में दूसरा IsSupported परीक्षण, अतिरिक्त अनुकूलन के लिए उपयोग किया जाता है यदि हार्डवेयर Ssse3 निर्देश Ssse3 का समर्थन करता है।
अन्यथा, अधिकांश तर्क अनिवार्य रूप से विस्तारित लूप के लिए समान हैं। Vector128<T> एक 128-बिट प्रकार है जिसमें Vector128<T>.Count 128 Vector128<T>.Count । तत्व शामिल हैं। इस मामले में, uint , जो स्वयं 32-बिट है, में 4 (128/32) तत्व हो सकते हैं, यह है कि हमने लूप कैसे लॉन्च किया।
निष्कर्ष
नए अंतर्निहित फ़ंक्शन आपको उस मशीन की हार्डवेयर-विशिष्ट कार्यक्षमता का लाभ उठाने का अवसर देते हैं, जिस पर आप कोड चलाते हैं। X86 और X64 के लिए 15 सेटों पर लगभग 1,500 API वितरित किए गए हैं, एक लेख में वर्णन करने के लिए बहुत सारे हैं। अड़चनों की पहचान करने के लिए कोड को प्रोफाइल करके, आप उस कोड का हिस्सा निर्धारित कर सकते हैं जो वैश्वीकरण से लाभान्वित करता है और एक बहुत अच्छा प्रदर्शन को बढ़ावा देता है। ऐसे कई परिदृश्य हैं जहां वेक्टराइज़ेशन लागू किया जा सकता है और लूप अनफॉल्डिंग केवल शुरुआत है।
जो कोई भी अधिक उदाहरण देखना चाहता है, वह फ्रेमवर्क में निर्मित कार्यों ( डॉटनेट और एस्पनेट देखें), या अन्य सामुदायिक लेखों में उपयोग के लिए देख सकता है। और यद्यपि वर्तमान डब्ल्यूएफ विशाल हैं, फिर भी बहुत अधिक कार्यक्षमता है जिसे पेश करने की आवश्यकता है। यदि आपके पास कार्यक्षमता है जिसे आप पेश करना चाहते हैं, तो GitHub पर dotnet / corefx के माध्यम से अपने एपीआई अनुरोध को पंजीकृत करने के लिए स्वतंत्र महसूस करें। एपीआई समीक्षा प्रक्रिया यहां वर्णित है और चरण 1 में निर्दिष्ट एपीआई अनुरोध टेम्पलेट का एक अच्छा उदाहरण है।
विशेष धन्यवाद
मैं हमारे समुदाय Fei पेंग (@fiigii) और Jacek Blaszczynski (@ 4creators) के सदस्यों को विशेष रूप से व्यक्त करना चाहूंगा कि वे एसएफएफ को लागू करने में उनकी मदद के लिए, साथ ही समुदाय के सभी सदस्यों को इस कार्यक्षमता के विकास, कार्यान्वयन और आसानी के बारे में मूल्यवान प्रतिक्रिया दें।
अनुवाद के बाद
मैं .NET प्लेटफ़ॉर्म के विकास का निरीक्षण करना पसंद करता हूं, और, विशेष रूप से, सी # भाषा। C ++ की दुनिया से आ रहा है, और डेल्फी और जावा में विकसित होने का बहुत कम अनुभव है, मैं C # में प्रोग्राम लिखना शुरू करने में बहुत सहज था। 2006 में, यह प्रोग्रामिंग भाषा (भाषा स्वयं) मुझे प्रबंधित कचरा संग्रह और क्रॉस-प्लेटफॉर्म की दुनिया में जावा की तुलना में अधिक संक्षिप्त और व्यावहारिक लग रही थी। इसलिए, मेरी पसंद C # पर गिर गई, और मुझे इसका पछतावा नहीं था। किसी भाषा के विकास में पहला चरण केवल उसका स्वरूप था। 2006 तक, C # ने उस समय की सर्वश्रेष्ठ भाषाओं और प्लेटफ़ॉर्म: C ++ / Java / Delphi में मौजूद सभी सर्वश्रेष्ठ को अवशोषित कर लिया। 2010 में, एफ # सार्वजनिक हो गया। यह .NET की दुनिया में इसे पेश करने के लक्ष्य के साथ कार्यात्मक प्रतिमान का अध्ययन करने के लिए एक प्रायोगिक मंच था। प्रयोगों का परिणाम सी # के विकास में अगला चरण था - एफपी की ओर अपनी क्षमताओं का विस्तार, अनाम फ़ंक्शंस की शुरुआत के माध्यम से, लैम्ब्डा एक्सप्रेशन और, अंततः, LINQ। भाषा के इस विस्तार ने C # को मेरे दृष्टिकोण से, सामान्य-उद्देश्य वाली भाषा में सबसे उन्नत बना दिया। अगला विकासवादी कदम संगामिति और अतुल्यकालिक समर्थन से संबंधित था। टास्क / टास्क <टी>, टीपीएल की पूरी अवधारणा, LINQ के विकास - PLINQ, और अंत में, async या प्रतीक्षा है। , - , .NET C# — . Span<T> Memory<T>, ValueTask/ValueTask<T>, IAsyncDispose, ref readonly struct in, foreach, IO.Streams. GC . , — . , .NET C#, , . ( ) .