
उच्च गुणवत्ता वाले कैमरों के साथ मोबाइल फोन के आगमन के साथ, हमने अपने जीवन में उज्ज्वल और यादगार क्षणों के अधिक से अधिक चित्र और वीडियो बनाना शुरू कर दिया। हम में से कई के पास फोटो अभिलेखागार हैं जो दशकों में वापस आते हैं और हजारों चित्रों को शामिल करते हैं जिससे उन्हें नेविगेट करने में मुश्किल होती है। बस याद रखें कि कुछ साल पहले ब्याज की तस्वीर ढूंढने में कितना समय लगा था।
Mail.ru क्लाउड का एक उद्देश्य अपने स्वयं के फोटो और वीडियो अभिलेखागार तक पहुंचने और खोज करने के लिए सबसे अच्छे साधन प्रदान करना है। इस उद्देश्य के लिए, हम Mail.ru पर कंप्यूटर विज़न टीम ने स्मार्ट इमेज प्रोसेसिंग के लिए सिस्टम बनाए और कार्यान्वित किए हैं: ऑब्जेक्ट द्वारा खोजें, दृश्य द्वारा, चेहरे से, आदि। एक और शानदार तकनीक लैंडमार्क मान्यता है। आज, मैं आपको बताने जा रहा हूं कि कैसे हमने डीप लर्निंग का उपयोग करके इसे वास्तविकता बना दिया।
स्थिति की कल्पना करें: आप अपनी छुट्टी से तस्वीरों के भार के साथ लौटते हैं। अपने दोस्तों से बात करते हुए, आपको देखने लायक जगह की तस्वीर दिखाने के लिए कहा जाता है, जैसे महल, महल, पिरामिड, मंदिर, झील, झरना, पहाड़, इत्यादि। आप अपने गैलरी फोल्डर को स्क्रॉल करने के लिए दौड़ते हैं जो वास्तव में अच्छा है। सबसे अधिक संभावना है, यह सैकड़ों छवियों के बीच खो गया है, और आप कहते हैं कि आप इसे बाद में दिखाएंगे।
हम एल्बम में उपयोगकर्ता फ़ोटो को समूहीकृत करके इस समस्या को हल करते हैं। यह आपको कुछ ही क्लिक में उन चित्रों को ढूंढने देगा जिनकी आपको आवश्यकता है। अब हमारे पास चेहरे, ऑब्जेक्ट और दृश्य द्वारा संकलित एल्बम हैं, और लैंडमार्क द्वारा भी।
स्थलों के साथ तस्वीरें आवश्यक हैं क्योंकि वे अक्सर हमारे जीवन पर प्रकाश डालते हैं (उदाहरण के लिए यात्राएं)। ये पृष्ठभूमि में कुछ वास्तुकला या जंगल के साथ चित्र हो सकते हैं। यही कारण है कि हम ऐसी छवियों का पता लगाने और उन्हें आसानी से उपयोगकर्ताओं के लिए उपलब्ध करना चाहते हैं।
ऐतिहासिक मान्यता की ख़ासियत
यहाँ एक अति सूक्ष्म अंतर है: कोई केवल एक मॉडल को नहीं सिखाता है और इसका कारण स्थलों को तुरंत पहचानता है - कई चुनौतियां हैं।
सबसे पहले, हम स्पष्ट रूप से नहीं बता सकते हैं कि "लैंडमार्क" वास्तव में क्या है। हम यह नहीं बता सकते हैं कि एक इमारत एक मील का पत्थर क्यों है, जबकि इसके बगल में एक और नहीं है। यह एक औपचारिक अवधारणा नहीं है, जो मान्यता कार्य को निर्दिष्ट करने के लिए इसे और अधिक जटिल बनाता है।
दूसरा, स्थल अविश्वसनीय रूप से विविध हैं। ये ऐतिहासिक या सांस्कृतिक मूल्य की इमारतें हो सकती हैं, जैसे मंदिर, महल या महल। वैकल्पिक रूप से, ये सभी प्रकार के स्मारक हो सकते हैं। या प्राकृतिक विशेषताएं: झीलों, घाटी, झरने और इतने पर। इसके अलावा, एक एकल मॉडल है जो उन सभी स्थलों को खोजने में सक्षम होना चाहिए।
तीसरा, स्थलों के साथ चित्र बहुत कम हैं। हमारे अनुमानों के अनुसार, वे उपयोगकर्ता फ़ोटो के केवल 1 से 3 प्रतिशत तक खाते हैं। इसीलिए हम पहचान में गलतियाँ नहीं कर सकते क्योंकि अगर हम किसी को बिना लैंडमार्क के फोटो दिखाते हैं, तो यह काफी स्पष्ट होगा और इससे प्रतिकूल प्रतिक्रिया होगी। या, इसके विपरीत, कल्पना कीजिए कि आप न्यूयॉर्क में एक ऐसे व्यक्ति के साथ रुचि के स्थान के साथ एक तस्वीर दिखाते हैं जो कभी भी संयुक्त राज्य में नहीं रहा है। इस प्रकार, मान्यता मॉडल में कम FPR (झूठी सकारात्मक दर) होना चाहिए।
चौथा, लगभग 50% उपयोगकर्ता या इससे भी अधिक आमतौर पर जियो डेटा बचत को अक्षम करते हैं। हमें इसे ध्यान में रखना होगा और स्थान की पहचान करने के लिए केवल छवि का उपयोग करना होगा। आज, अधिकांश सेवाएं किसी तरह से स्थलों को संभालने में सक्षम हैं, छवि गुणों से जियोडेटा का उपयोग करती हैं। हालांकि, हमारी प्रारंभिक आवश्यकताएं अधिक कठोर थीं।
अब मैं आपको कुछ उदाहरण दिखाता हूं।
यहां तीन लुक-अलाइक ऑब्जेक्ट, फ्रांस में तीन गोथिक कैथेड्रल हैं। बाईं ओर अमीन्स कैथेड्रल है, बीच में एक रिम्स कैथेड्रल है, और नोट्रे-डेम डे पेरिस दाईं ओर है।

यहां तक कि एक इंसान को करीब से देखने और यह देखने के लिए कुछ समय की आवश्यकता होती है कि ये अलग-अलग कैथेड्रल हैं, लेकिन इंजन को ऐसा करने में सक्षम होना चाहिए, और एक मानव की तुलना में तेजी से भी।
यहां एक और चुनौती है: यहां तीनों तस्वीरों में नोट्रे-डेम डे पेरिस को अलग-अलग कोणों से शूट किया गया है। तस्वीरें काफी अलग हैं, लेकिन उन्हें अभी भी पहचानने और पुनर्प्राप्त करने की आवश्यकता है।

प्राकृतिक विशेषताएं वास्तुकला से पूरी तरह से अलग हैं। बाईं ओर इज़राइल में कैसरिया है, दाईं ओर म्यूनिख में एंग्लिसचर गार्टन है।

ये तस्वीरें मॉडल को अनुमान लगाने के लिए बहुत कम सुराग देती हैं।
हमारी विधि
हमारी विधि पूरी तरह से गहरे संवेदी तंत्रिका नेटवर्क पर आधारित है। हमने जो प्रशिक्षण रणनीति चुनी वह तथाकथित पाठ्यक्रम सीखने की थी जिसका अर्थ है कई चरणों में सीखना। जियो डेटा के साथ और उसके बिना अधिक दक्षता हासिल करने के लिए, हमने एक विशिष्ट निष्कर्ष निकाला। मैं आपको प्रत्येक चरण के बारे में अधिक विस्तार से बताता हूं।
डेटा सेट
डेटा मशीन लर्निंग का ईंधन है। सबसे पहले, हमें मॉडल को सिखाने के लिए एक साथ डेटा सेट प्राप्त करना था।
हमने दुनिया को 4 क्षेत्रों में विभाजित किया है, प्रत्येक का उपयोग सीखने की प्रक्रिया में एक विशिष्ट कदम पर किया जाता है। फिर, हमने प्रत्येक क्षेत्र के देशों का चयन किया, प्रत्येक देश के शहरों की एक सूची चुनी, और तस्वीरों का एक बैंक एकत्र किया। नीचे कुछ उदाहरण दिए गए हैं।

सबसे पहले, हमने अपने मॉडल को प्राप्त डेटाबेस से सीखने का प्रयास किया। नतीजे खराब रहे। हमारे विश्लेषण से पता चला कि डेटा गंदा था। प्रत्येक मील के पत्थर की पहचान के साथ बहुत अधिक शोर हस्तक्षेप था। हम क्या करने वाले थे? यह महंगा, बोझिल होगा, और मैन्युअल रूप से डेटा के सभी थोक की समीक्षा करने के लिए बहुत बुद्धिमान नहीं है। इसलिए, हमने स्वचालित डेटाबेस सफाई के लिए एक प्रक्रिया तैयार की है जहां मैनुअल हैंडलिंग का उपयोग केवल एक चरण में किया जाता है: हमने प्रत्येक लैंडमार्क के लिए 3 से 5 संदर्भ तस्वीरों को हैंडपैक किया है जो निश्चित रूप से अधिक या कम उपयुक्त कोण पर वांछित वस्तु दिखाते हैं। यह काफी तेजी से काम करता है क्योंकि इस तरह के संदर्भ डेटा की मात्रा पूरे डेटाबेस की तुलना में छोटी है। फिर गहरी सजातीय तंत्रिका नेटवर्क पर आधारित स्वचालित सफाई की जाती है।
इसके अलावा, मैं "एम्बेडिंग" शब्द का उपयोग करने जा रहा हूं जिसके द्वारा मेरा मतलब निम्नलिखित है। हमारे पास एक दृढ़ तंत्रिका नेटवर्क है। हमने इसे वस्तुओं को वर्गीकृत करने के लिए प्रशिक्षित किया, फिर हमने अंतिम वर्गीकरण परत को काट दिया, कुछ छवियों को उठाया, उन्हें नेटवर्क द्वारा विश्लेषण किया, और आउटपुट पर एक संख्यात्मक वेक्टर प्राप्त किया। इसे मैं एम्बेडिंग कहूंगा।
जैसा कि मैंने पहले कहा था, हमने अपने डेटाबेस के कुछ हिस्सों के लिए सीखने की प्रक्रिया को कई चरणों में व्यवस्थित किया। तो, पहले, हम या तो तंत्रिका नेटवर्क को पूर्ववर्ती चरण या प्रारंभिक नेटवर्क से लेते हैं।
हमारे पास एक लैंडमार्क की संदर्भ तस्वीरें हैं, उन्हें नेटवर्क द्वारा संसाधित करें और कई एम्बेडिंग प्राप्त करें। अब हम डेटा सफाई के लिए आगे बढ़ सकते हैं। हम लैंडमार्क के लिए निर्धारित डेटा से सभी तस्वीरें लेते हैं और प्रत्येक के पास नेटवर्क द्वारा संसाधित किया जाता है। हम कुछ एम्बेडिंग प्राप्त करते हैं और प्रत्येक के लिए संदर्भ एम्बेडिंग की दूरी निर्धारित करते हैं। फिर, हम औसत दूरी निर्धारित करते हैं और, अगर यह कुछ सीमा से अधिक है, जो एल्गोरिथ्म का एक पैरामीटर है, तो ऑब्जेक्ट को गैर-लैंडमार्क के रूप में व्यवहार करें। यदि औसत दूरी सीमा से कम है, तो हम तस्वीर रखते हैं।
नतीजतन, हमारे पास एक डेटाबेस था जिसमें 70 देशों के 500 से अधिक शहरों के 11 हजार से अधिक स्थल थे, जिसमें 2.3 मिलियन से अधिक तस्वीरें थीं। याद रखें कि तस्वीरों के प्रमुख भाग में कोई स्थान नहीं है। हमें इसे किसी तरह अपने मॉडलों को बताने की जरूरत है। इस कारण से, हमने अपने डेटाबेस में स्थलों के बिना 900 हजार फ़ोटो जोड़े और परिणामी डेटा सेट के साथ हमारे मॉडल को प्रशिक्षित किया।
हमने सीखने की गुणवत्ता को मापने के लिए एक ऑफ़लाइन परीक्षण शुरू किया। यह देखते हुए कि सभी तस्वीरों के 1 से 3% हिस्से में ही लैंड होते हैं, हमने मैन्युअल रूप से 290 चित्रों का एक सेट संकलित किया, जो एक मील का पत्थर दिखा। वे तस्वीरें काफी विविध और जटिल थीं, जिनमें विभिन्न कोणों से बड़ी संख्या में वस्तुओं को गोली मारकर मॉडल के लिए परीक्षण को यथासंभव कठिन बना दिया गया था। इसी पैटर्न का अनुसरण करते हुए, हमने स्थलों के बिना 11 हजार तस्वीरें लीं, बल्कि जटिल भी, और हमने उन वस्तुओं को खोजने की कोशिश की, जो हमारे डेटाबेस में स्थलों की तरह दिखती थीं।
सीखने की गुणवत्ता का मूल्यांकन करने के लिए, हम अपने मॉडल की सटीकता को मापते हैं, जिसमें दोनों स्थलों के साथ और बिना फोटो का उपयोग किए। ये हमारे दो मुख्य मैट्रिक्स हैं।
मौजूदा दृष्टिकोण
साहित्य में ऐतिहासिक मान्यता के बारे में अपेक्षाकृत कम जानकारी है। अधिकांश समाधान स्थानीय सुविधाओं पर आधारित हैं। मुख्य विचार यह है कि हमारे पास कुछ क्वेरी चित्र और डेटाबेस से एक तस्वीर है। स्थानीय विशेषताएं - प्रमुख बिंदु - पाए जाते हैं और फिर मेल खाते हैं। यदि मैचों की संख्या पर्याप्त है, तो हम निष्कर्ष निकालते हैं कि हमने एक मील का पत्थर पाया है।
वर्तमान में, Google द्वारा दी जाने वाली DELF (डीप लोकल फीचर्स) सबसे अच्छी विधि है, जो गहरे सीखने के साथ स्थानीय विशेषताओं को जोड़ती है। कन्वेन्शन नेटवर्क द्वारा संसाधित इनपुट इमेज होने से, हम कुछ DELF सुविधाएँ प्राप्त करते हैं।
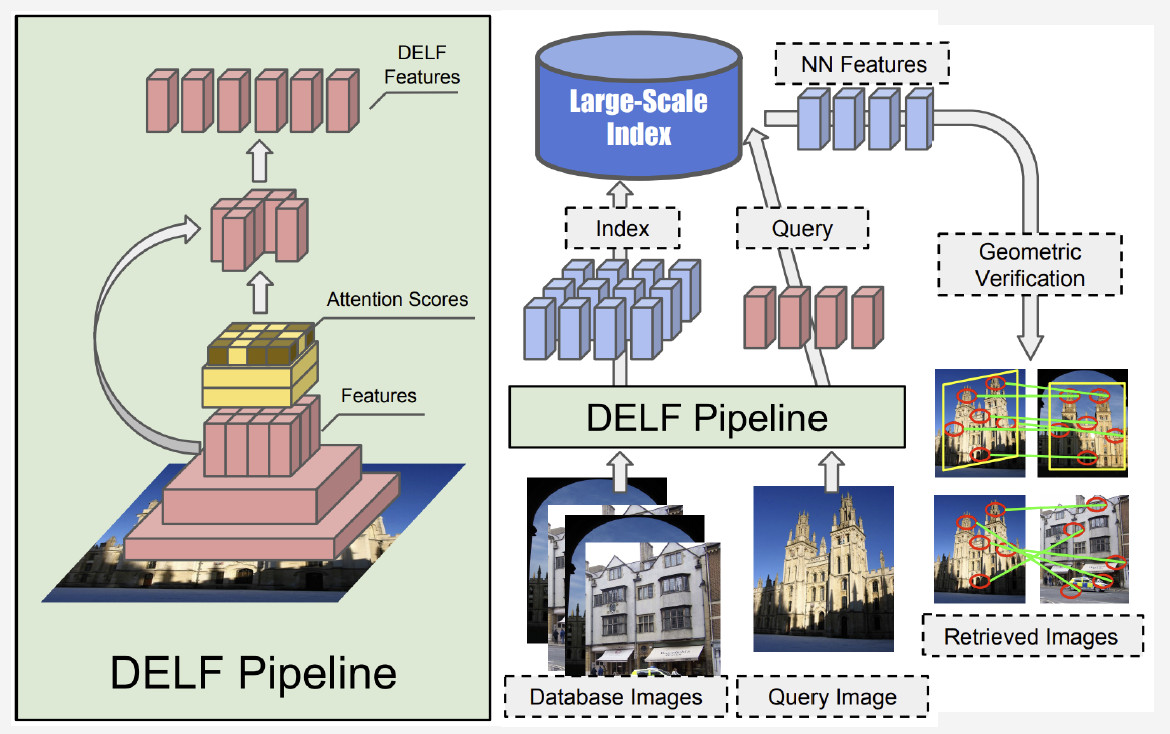
लैंडमार्क मान्यता कैसे काम करती है? हमारे पास तस्वीरों की एक बैंक और एक इनपुट छवि है, और हम जानना चाहते हैं कि यह एक लैंडमार्क दिखाता है या नहीं। सभी तस्वीरों के DELF नेटवर्क को चलाकर, डेटाबेस और इनपुट छवि के लिए संबंधित विशेषताएं प्राप्त की जा सकती हैं। फिर हम निकटतम-पड़ोसी विधि द्वारा एक खोज करते हैं और आउटपुट पर सुविधाओं के साथ उम्मीदवार चित्र प्राप्त करते हैं। हम विशेषताओं का मिलान करने के लिए ज्यामितीय सत्यापन का उपयोग करते हैं: यदि सफल होता है, तो हम निष्कर्ष निकालते हैं कि चित्र एक लैंडमार्क दिखाता है।
संवादी तंत्रिका नेटवर्क
डीप लर्निंग के लिए प्री-ट्रेनिंग महत्वपूर्ण है। इसलिए हमने अपने तंत्रिका नेटवर्क को पूर्व-प्रशिक्षित करने के लिए दृश्यों के एक डेटाबेस का उपयोग किया। इस तरह क्यों? एक दृश्य एक बहु वस्तु है जिसमें बड़ी संख्या में अन्य ऑब्जेक्ट शामिल हैं। लैंडमार्क एक दृश्य का एक उदाहरण है। इस तरह के एक डेटाबेस के साथ मॉडल को पूर्व-प्रशिक्षण करके, हम इसे कुछ निम्न-स्तरीय विशेषताओं का विचार दे सकते हैं, जो तब सफल लैंडमार्क मान्यता के लिए सामान्यीकृत हो सकते हैं।
हमने मॉडल के रूप में अवशिष्ट नेटवर्क परिवार से एक तंत्रिका नेटवर्क का उपयोग किया। ऐसे नेटवर्क का महत्वपूर्ण अंतर यह है कि वे एक अवशिष्ट ब्लॉक का उपयोग करते हैं जिसमें स्किप कनेक्शन शामिल होता है जो एक संकेत को वज़न के साथ परतों पर कूदने और स्वतंत्र रूप से पारित करने की अनुमति देता है। इस तरह की वास्तुकला उच्च गुणवत्ता के साथ गहरे नेटवर्क को प्रशिक्षित करना और गायब होने वाले ढाल प्रभाव को नियंत्रित करना संभव बनाती है, जो प्रशिक्षण के लिए आवश्यक है।
हमारा मॉडल वाइड ResNet-50-2, ResNet-50 का एक संस्करण है, जहां आंतरिक अड़चन ब्लॉक में दीक्षांत समारोह की संख्या दोगुनी है।

नेटवर्क बहुत अच्छा प्रदर्शन करता है। हमने अपने दृश्य डेटाबेस के साथ इसका परीक्षण किया, और यहां परिणाम हैं:
वाइड ResNet ने ResNet-200 की तुलना में लगभग दोगुना काम किया। आखिरकार, यह गति है जो उत्पादन के लिए महत्वपूर्ण है। इन सभी विचारों को देखते हुए, हमने अपने मुख्य तंत्रिका नेटवर्क के रूप में वाइड रेनेट -50-2 को चुना।
ट्रेनिंग
हमें अपने नेटवर्क को प्रशिक्षित करने के लिए एक हानि फ़ंक्शन की आवश्यकता है हमने इसे लेने के लिए मीट्रिक सीखने के दृष्टिकोण का उपयोग करने का फैसला किया: एक तंत्रिका नेटवर्क को प्रशिक्षित किया जाता है ताकि एक ही वर्ग के झुंड एक क्लस्टर में आइटम हों, जबकि विभिन्न वर्गों के क्लस्टर यथासंभव अलग किए जा सकें। गंतव्यों के लिए, हमने केंद्र के नुकसान का इस्तेमाल किया जो कुछ केंद्र की ओर एक वर्ग के तत्वों को खींचता है। इस दृष्टिकोण की एक महत्वपूर्ण विशेषता यह है कि इसके लिए नकारात्मक नमूने की आवश्यकता नहीं होती है, जो बाद के युगों में करना एक कठिन काम हो जाता है।
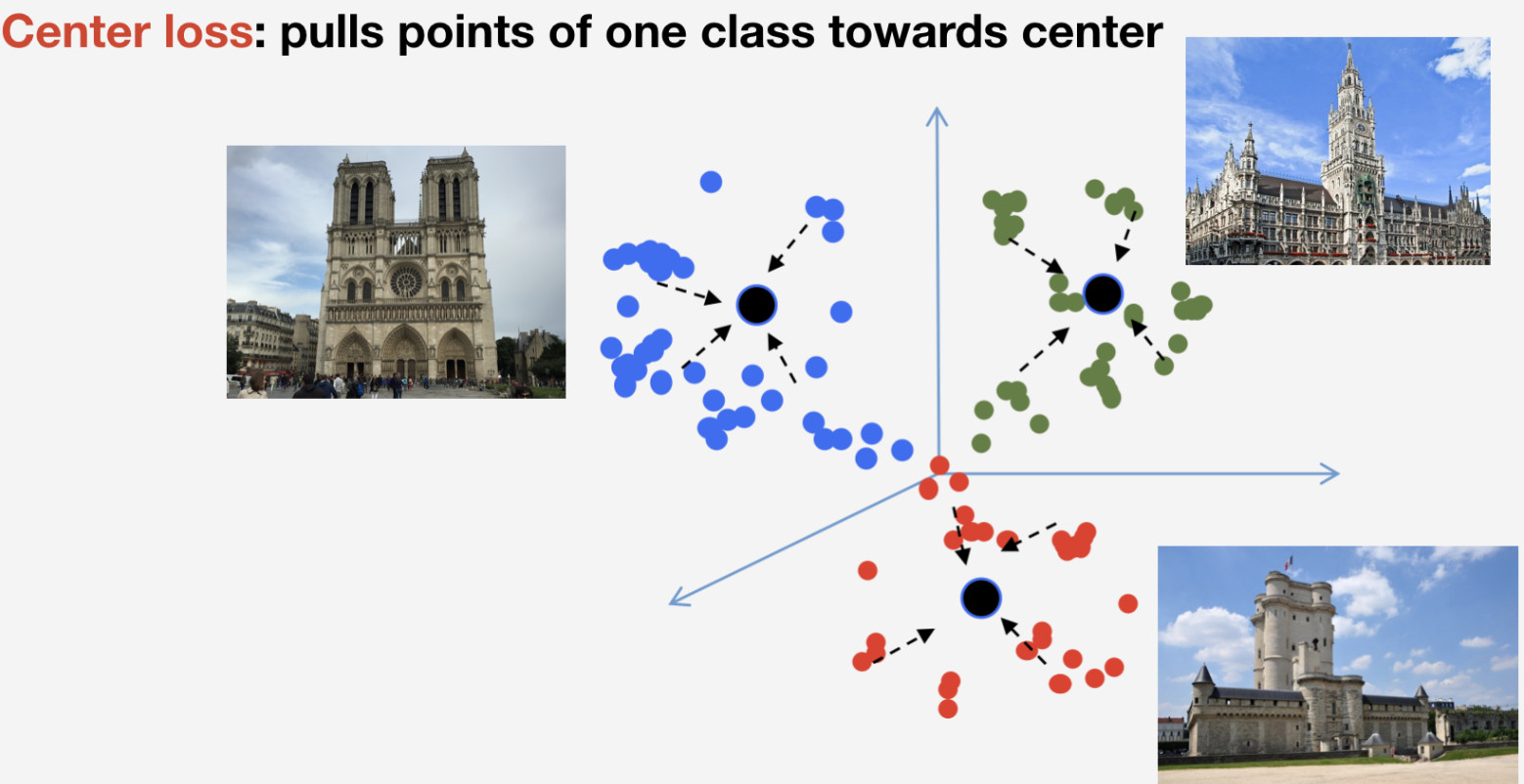
याद रखें कि हमारे पास स्थलों की n कक्षाएं हैं और एक और "गैर-ऐतिहासिक" वर्ग है जिसके लिए केंद्र हानि का उपयोग नहीं किया जाता है। हम मानते हैं कि एक लैंडमार्क एक समान वस्तु है, और इसकी संरचना है, इसलिए यह इसके केंद्र को निर्धारित करने के लिए समझ में आता है। गैर-लैंडमार्क के रूप में, यह जो कुछ भी संदर्भित कर सकता है, इसलिए इसके लिए केंद्र निर्धारित करने का कोई मतलब नहीं है।
हमने फिर यह सब एक साथ रखा, और प्रशिक्षण के लिए हमारा मॉडल है। इसमें तीन प्रमुख भाग शामिल हैं:
- वाइड रेसनेट 50-2 जटिल तंत्रिका नेटवर्क दृश्यों के एक डेटाबेस के साथ पूर्व-प्रशिक्षित;
- एम्बेडिंग भाग में पूरी तरह से जुड़ी परत और बैच मानक परत शामिल है;
- क्लासिफायर जो पूरी तरह से जुड़ा हुआ परत है, उसके बाद सॉफ्टमैक्स लॉस और सेंटर लॉस शामिल है।

जैसा कि आपको याद है, हमारा डेटाबेस क्षेत्र द्वारा 4 भागों में विभाजित है। हम इन 4 भागों का उपयोग एक पाठ्यक्रम सीखने के प्रतिमान में करते हैं। हमारे पास एक वर्तमान डेटासेट है, और सीखने के प्रत्येक चरण में, हम प्रशिक्षण के लिए एक नया डेटासेट प्राप्त करने के लिए दुनिया का एक और हिस्सा जोड़ते हैं।
मॉडल में तीन भाग शामिल हैं, और हम प्रशिक्षण प्रक्रिया में प्रत्येक के लिए एक विशिष्ट सीखने की दर का उपयोग करते हैं। यह आवश्यक है कि नेटवर्क हमारे द्वारा जोड़े गए नए डेटासेट भाग से स्थलों को सीखने में सक्षम हो और पहले से सीखे गए डेटा को याद रखे। कई प्रयोगों ने इस दृष्टिकोण को सबसे कुशल साबित किया।
इसलिए, हमने अपने मॉडल को प्रशिक्षित किया है। अब हमें यह महसूस करने की जरूरत है कि यह कैसे काम करता है। आइए हम छवि के उस भाग को खोजने के लिए कक्षा सक्रियण मानचित्र का उपयोग करें, जिस पर हमारा तंत्रिका नेटवर्क सबसे अधिक आसानी से प्रतिक्रिया करता है। नीचे दी गई तस्वीर पहली पंक्ति में इनपुट चित्र दिखाती है, और पिछली चरण में हमने जिस नेटवर्क से प्रशिक्षण लिया है, उसी वर्ग के सक्रियण मानचित्र के साथ छवियों को दूसरी पंक्ति में दिखाया गया है।

हीट मैप दिखाता है कि छवि के किन हिस्सों में नेटवर्क द्वारा अधिक भाग लिया जाता है। जैसा कि कक्षा सक्रियण मानचित्र द्वारा दिखाया गया है, हमारे तंत्रिका नेटवर्क ने लैंडमार्क की अवधारणा को सफलतापूर्वक सीखा है।
अनुमान
अब हमें इस ज्ञान का उपयोग किसी भी तरह से चीजों को करने के लिए करना होगा। चूंकि हमने प्रशिक्षण के लिए केंद्र के नुकसान का इस्तेमाल किया है, इसलिए अनुमान के मामले में, यह स्थलों के लिए केंद्रक को निर्धारित करने के लिए काफी तार्किक प्रतीत होता है।
ऐसा करने के लिए, हम सेंट पीटर्सबर्ग में कांस्य घुड़सवार, कुछ लैंडमार्क के लिए प्रशिक्षण सेट से छवियों का एक हिस्सा लेते हैं। फिर हमने उन्हें नेटवर्क द्वारा संसाधित किया है, एम्बेडिंग प्राप्त करते हैं, औसत निकालते हैं, और एक सेंट्रोइड प्राप्त करते हैं।
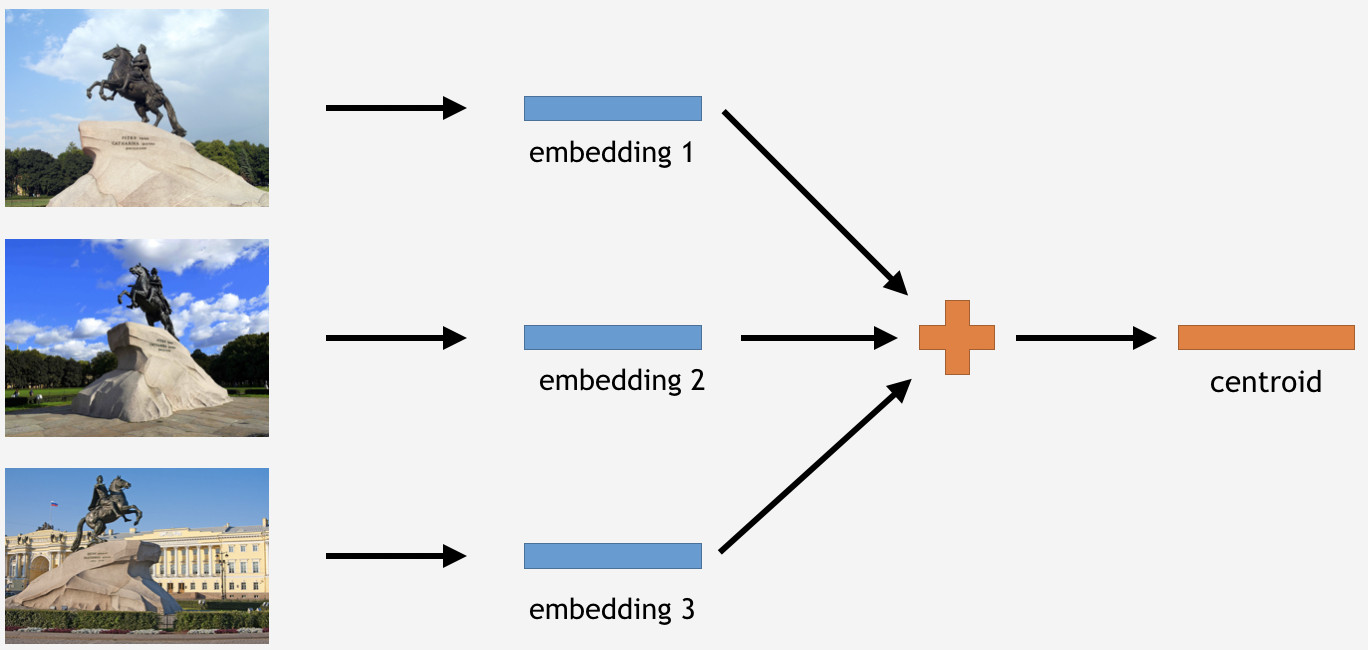
हालांकि, यहां एक सवाल है: प्रति मील कितने सेंट्रोइड्स इसे प्राप्त करने के लिए समझ में आता है? प्रारंभ में, यह स्पष्ट और तार्किक प्रतीत होता है: एक केन्द्रक। बिल्कुल नहीं, जैसा कि यह निकला। हमने शुरू में एकल सेंट्रोइड भी बनाने का फैसला किया, और परिणाम बुरा नहीं था। तो कई सेंट्रोइड्स क्यों?
पहला, हमारे पास मौजूद डेटा इतना साफ नहीं है। हालांकि हमने डेटासेट को साफ कर दिया है, हमने केवल स्पष्ट अपशिष्ट डेटा को हटा दिया है। हालांकि, अभी भी चित्र स्पष्ट रूप से बर्बाद नहीं हो सकते हैं, लेकिन परिणाम को प्रतिकूल रूप से प्रभावित कर सकते हैं।
उदाहरण के लिए, मेरे पास सेंट पीटर्सबर्ग में एक लैंडमार्क क्लास विंटर पैलेस है। मैं इसके लिए एक केन्द्रक प्राप्त करना चाहता हूं। हालांकि, इसके डेटासेट में पैलेस स्क्वायर और जनरल हेडक्वार्टर आर्क के साथ कुछ तस्वीरें शामिल हैं, क्योंकि ये ऑब्जेक्ट एक-दूसरे के करीब हैं। यदि सभी छवियों के लिए केन्द्रक निर्धारित किया जाना है, तो परिणाम इतना स्थिर नहीं होगा। हमें जो करने की जरूरत है, वह है कि किसी तरह तंत्रिका नेटवर्क से निकले उनके एम्बेडिंग, केवल सेंट्रोइड लें जो विंटर पैलेस से संबंधित हैं, और परिणामी डेटा का उपयोग करके औसतन।

दूसरा, तस्वीरें अलग-अलग कोणों से ली गई होंगी।
यहाँ इस तरह के व्यवहार का एक उदाहरण है जो ब्रुफ्स के बेल्फ़्री के साथ सचित्र है। इसके लिए दो सेंट्रोइड निकाले गए हैं। छवि में शीर्ष पंक्ति में, वे तस्वीरें हैं जो पहले सेंट्रोइड के करीब हैं, और दूसरी पंक्ति में - वे जो दूसरे सेंट्रोइड के करीब हैं।

पहले सेंट्रोइड अधिक "भव्य" तस्वीरों के साथ काम करते हैं जो ब्रूज के बाजार क्षेत्र में कम दूरी पर लिए गए थे। दूसरा सेंट्रोइड विशेष गलियों में दूर से ली गई तस्वीरों से संबंधित है।
जैसा कि यह पता चला है, प्रति लैंडमार्क वर्ग में कई सेंटीरोइड प्राप्त करके, हम उस लैंडमार्क के लिए अलग-अलग कैमरा कोणों पर विचार कर सकते हैं।
तो, कैसे हम उन सेटों को प्राप्त करने के लिए सेंटीरोइड प्राप्त करते हैं? हम प्रत्येक लैंडमार्क के लिए डेटासेट में श्रेणीबद्ध क्लस्टरिंग (पूर्ण लिंक) लागू करते हैं। हम इसका उपयोग वैध समूहों को खोजने के लिए करते हैं जिनसे सेंट्रोइड निकाले जाने हैं। मान्य क्लस्टरों से हमारा मतलब है कि क्लस्टरिंग के परिणामस्वरूप कम से कम 50 तस्वीरें शामिल हैं। अन्य समूहों को अस्वीकार कर दिया जाता है। नतीजतन, हमने लगभग 20% स्थलों को एक सेंटीमीटर से अधिक के साथ प्राप्त किया।
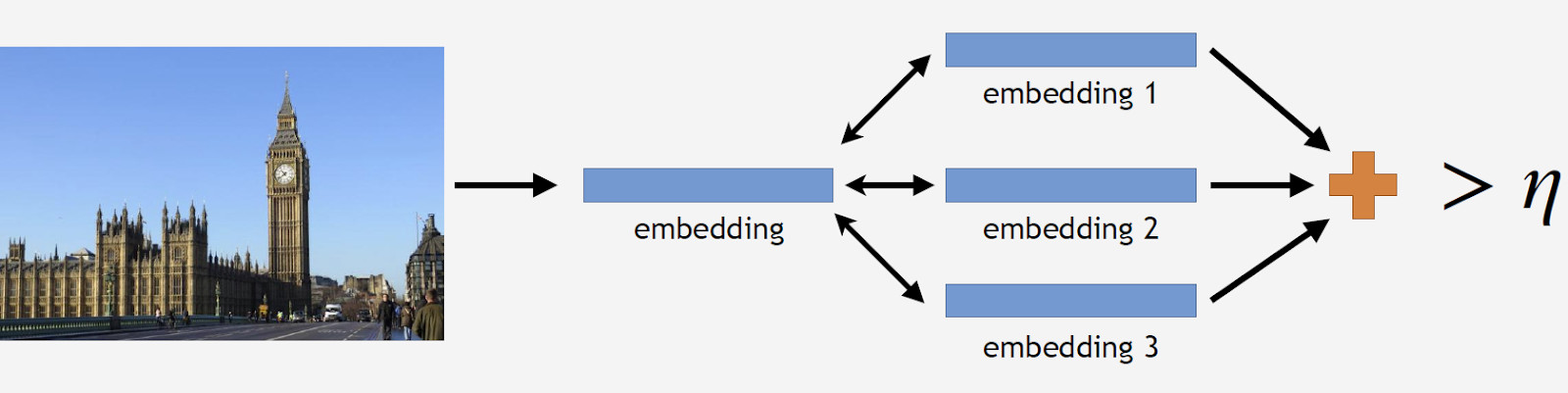
अब जिक्र है। यह दो चरणों में प्राप्त किया जाता है: सबसे पहले, हम इनपुट इमेज को हमारे कनफ्यूज़नल न्यूरल नेटवर्क में फीड करते हैं और एम्बेडिंग प्राप्त करते हैं, और फिर डॉट उत्पाद का उपयोग करके सेंट्रोइड्स के साथ एम्बेडिंग का मिलान करते हैं। यदि छवियों में जियो डेटा है, तो हम खोज को सेंट्रोइड्स तक सीमित कर देते हैं, जो छवि स्थान से 1x1 किमी वर्ग के भीतर स्थित स्थलों को संदर्भित करता है। यह बाद में मिलान के लिए अधिक सटीक खोज और निम्न सीमा को सक्षम करता है। यदि परिणामस्वरूप दूरी थ्रेशोल्ड से अधिक है जो एल्गोरिथ्म का एक पैरामीटर है, तो हम यह निष्कर्ष निकालते हैं कि एक फोटो में अधिकतम डॉट उत्पाद मूल्य के साथ एक लैंडमार्क है। यदि यह कम है, तो यह एक गैर-लैंडमार्क फोटो है।
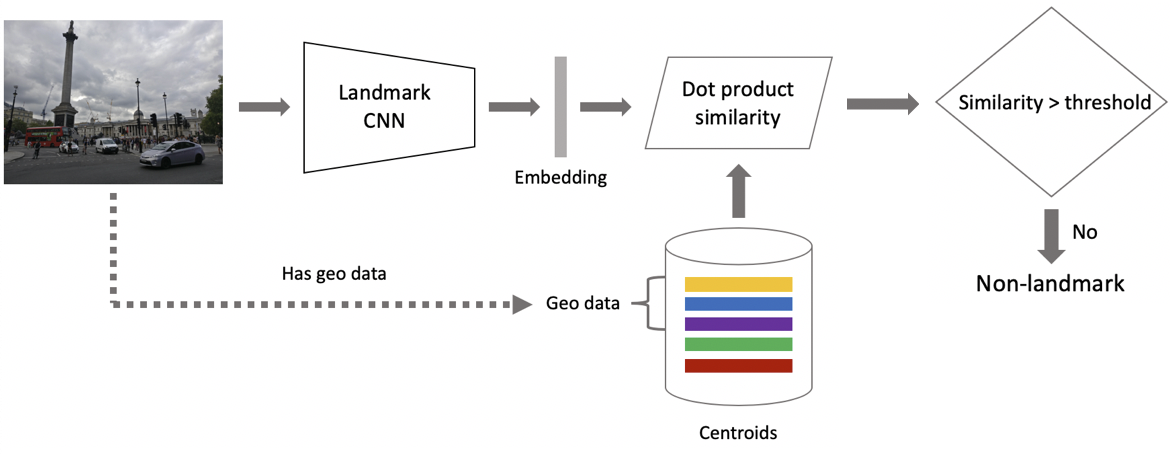
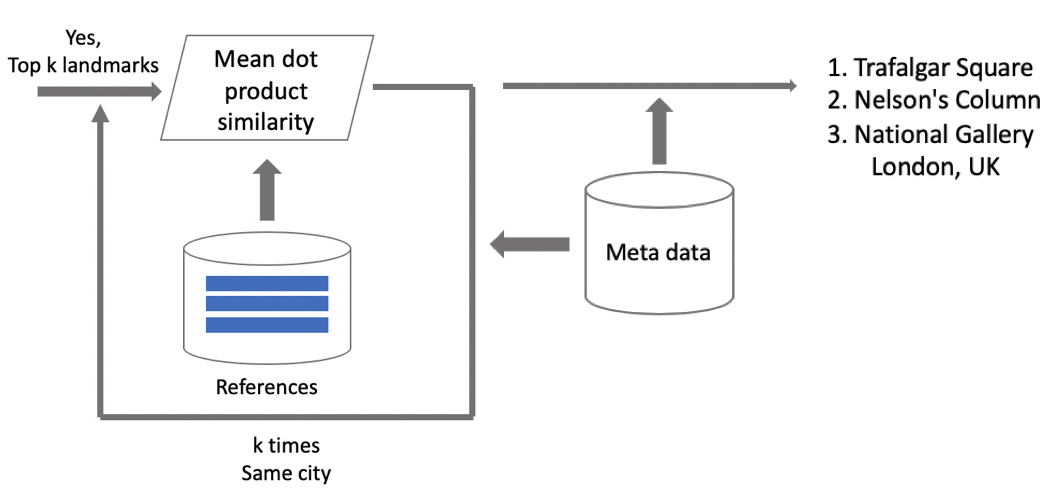
मान लीजिए कि एक फोटो में एक लैंडमार्क है। यदि हमारे पास जियो डेटा है, तो हम इसका उपयोग करते हैं और एक उत्तर प्राप्त करते हैं। यदि जियो डेटा अनुपलब्ध है, तो हम एक अतिरिक्त चेक चलाते हैं। जब हम डेटासेट साफ कर रहे थे, तो हमने प्रत्येक वर्ग के लिए संदर्भ चित्रों का एक समूह बनाया। हम उनके लिए एम्बेडिंग निर्धारित कर सकते हैं, और फिर क्वेरी इमेज की एम्बेडिंग के लिए उनसे औसत दूरी प्राप्त कर सकते हैं। यदि यह कुछ सीमा से अधिक है, तो सत्यापन पारित हो जाता है, और हम मेटाडेटा में लाते हैं और एक परिणाम प्राप्त करते हैं। यह ध्यान रखना महत्वपूर्ण है कि हम इस प्रक्रिया को कई स्थलों के लिए चला सकते हैं जो एक छवि में पाए गए हैं।
परीक्षणों के परिणाम
हमने अपने मॉडल की तुलना DELF के साथ की, जिसके लिए हमने उन मापदंडों को लिया जिनके साथ यह हमारे परीक्षण में सर्वश्रेष्ठ प्रदर्शन दिखाएगा। परिणाम लगभग समान हैं।
फिर हमने स्थलों को दो प्रकारों में वर्गीकृत किया: अक्सर (डेटाबेस में 100 से अधिक तस्वीरें), जो कि परीक्षण में सभी स्थलों के 87% और दुर्लभ हैं। हमारा मॉडल लगातार लोगों के साथ अच्छा काम करता है: 85.3% सटीक। दुर्लभ स्थलों के साथ, हमारे पास 46% था जो भी बुरा नहीं था, जिसका अर्थ है कि हमारे दृष्टिकोण ने कुछ आंकड़ों के साथ भी काफी अच्छा काम किया।
फिर हमने उपयोगकर्ता फ़ोटो के साथ ए / बी परीक्षण चलाया। नतीजतन, क्लाउड स्पेस खरीद रूपांतरण दर में 10% की वृद्धि हुई, मोबाइल ऐप ने रूपांतरण दर को 3% घटा दिया, और एल्बम विचारों की संख्या में 13% की वृद्धि हुई।
आइए हम अपनी गति की तुलना DELF से करते हैं। GPU के साथ, DELF को 7 नेटवर्क रन की आवश्यकता होती है क्योंकि यह 7 छवि पैमानों का उपयोग करता है, जबकि हमारा दृष्टिकोण केवल 1 का उपयोग करता है। CPU के साथ, DELF निकटतम पड़ोसी विधि द्वारा एक लंबी खोज और एक बहुत लंबी ज्यामितीय सत्यापन का उपयोग करता है। अंत में, सीपीयू के साथ हमारी विधि 15 गुना तेज थी। हमारा दृष्टिकोण दोनों मामलों में उच्च गति दिखाता है, जो उत्पादन के लिए महत्वपूर्ण है।
परिणाम: अवकाश से यादें
इस लेख की शुरुआत में, मैंने स्क्रॉल करने और वांछित लैंडमार्क चित्रों को खोजने के लिए एक समाधान का उल्लेख किया। यहाँ यह है।
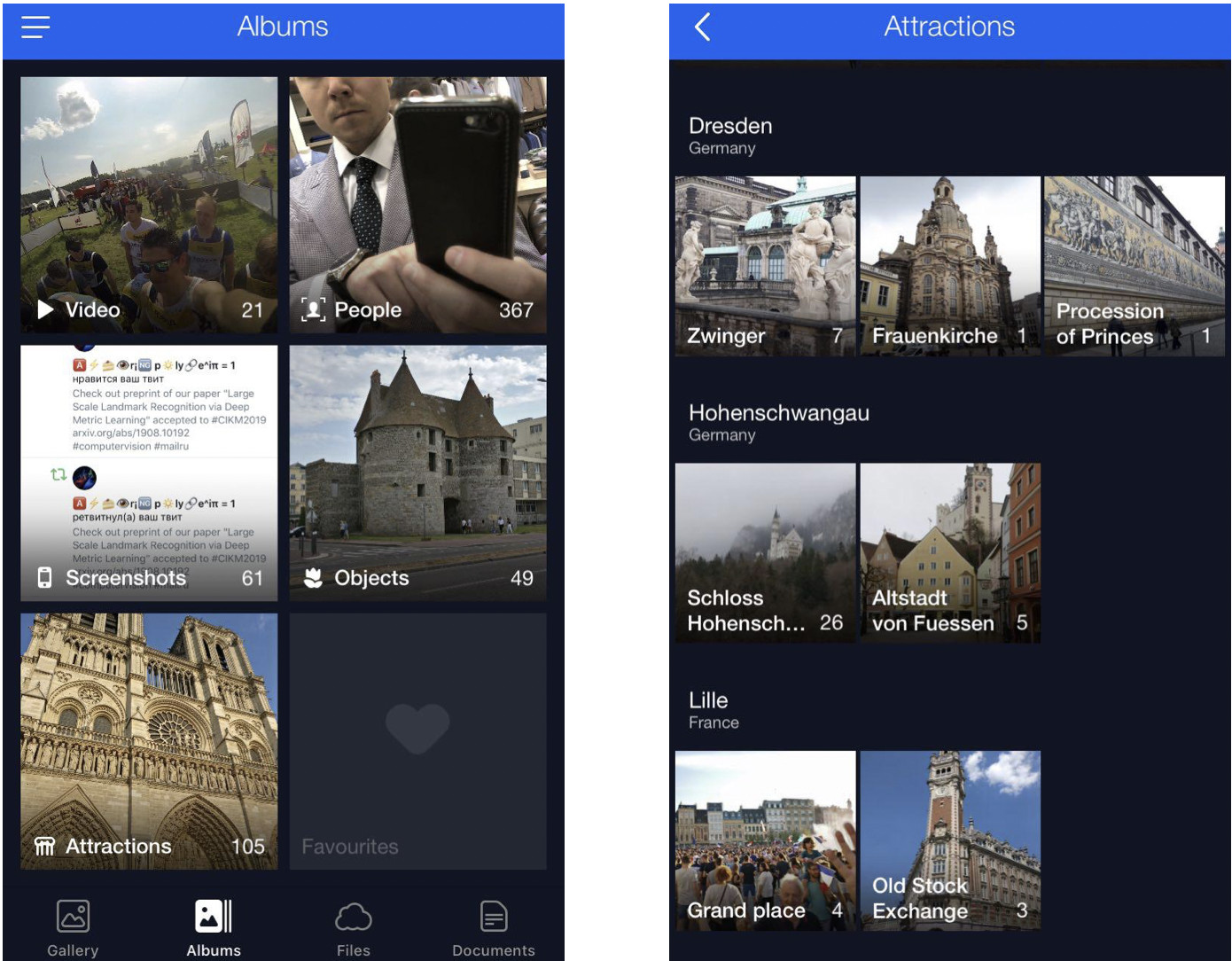
यह मेरा क्लाउड है जहां सभी तस्वीरों को एल्बम में वर्गीकृत किया गया है। एल्बम "पीपल", "ऑब्जेक्ट" और "आकर्षण" हैं। आकर्षण एल्बम में, स्थलों को उन एल्बमों में वर्गीकृत किया जाता है जो शहर द्वारा समूहीकृत होते हैं। Dresdner Zwinger पर एक क्लिक केवल इस मील के पत्थर की तस्वीरों के साथ एक एल्बम खोलता है।
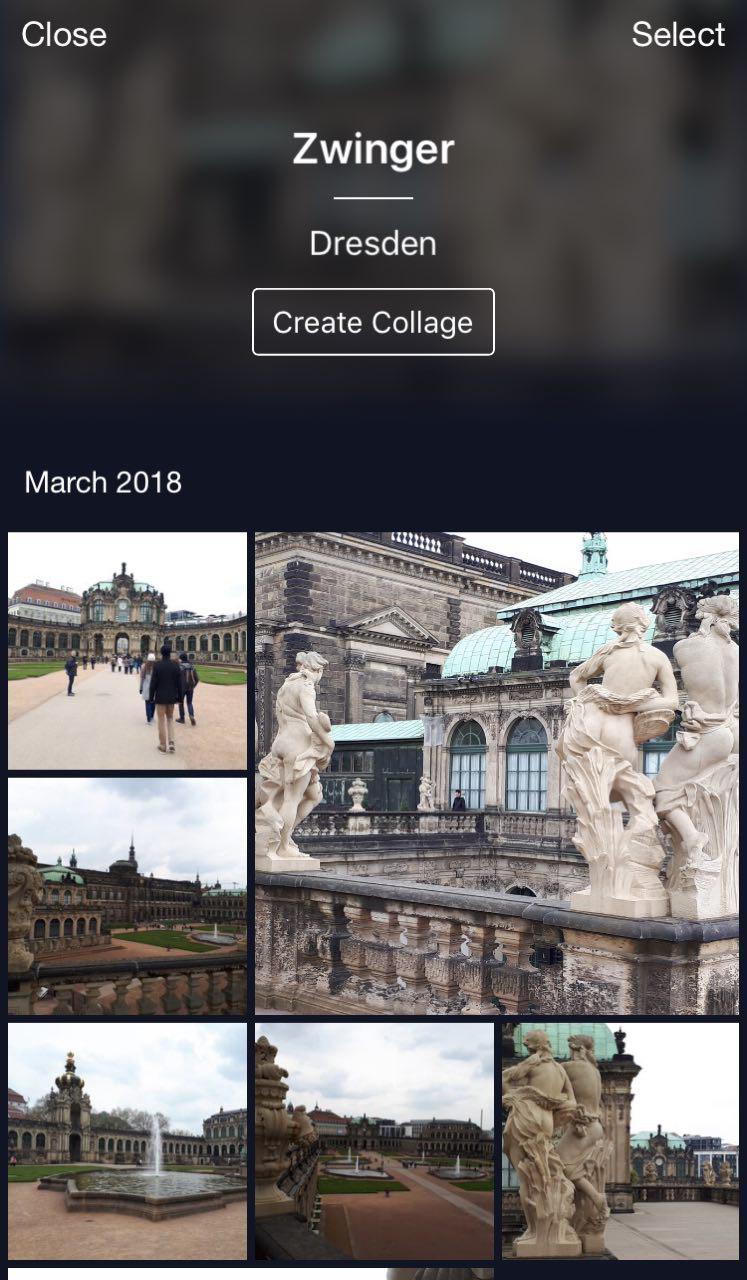
एक उपयोगी विशेषता: आप छुट्टी पर जा सकते हैं, कुछ फ़ोटो ले सकते हैं और उन्हें अपने क्लाउड में संग्रहीत कर सकते हैं। बाद में, जब आप उन्हें इंस्टाग्राम पर अपलोड करना चाहते हैं या दोस्तों और परिवार के साथ साझा करना चाहते हैं, तो आपको बहुत लंबी खोज और खोज नहीं करनी होगी - वांछित तस्वीरें बस कुछ ही क्लिक में उपलब्ध होंगी।
निष्कर्ष
मुझे हमारे समाधान की प्रमुख विशेषताओं की याद दिलाएं।
- अर्ध-स्वचालित डेटाबेस सफाई। प्रारंभिक मानचित्रण के लिए थोड़ा मैनुअल काम की आवश्यकता होती है, और फिर तंत्रिका नेटवर्क बाकी काम करेगा। यह नए डेटा को जल्दी से साफ करने और मॉडल का पुन: उपयोग करने की अनुमति देता है।
- हम गहन संवेदी तंत्रिका नेटवर्क और गहरी मीट्रिक सीखने का उपयोग करते हैं जो हमें कक्षाओं में संरचना को कुशलतापूर्वक सीखने की अनुमति देता है।
- हमने प्रशिक्षण अधिगम का उपयोग किया है, अर्थात् भागों में प्रशिक्षण, प्रशिक्षण प्रतिमान के रूप में। यह दृष्टिकोण हमारे लिए बहुत मददगार रहा है। हम कई सेंट्रोइड्स का उपयोग करते हैं, जो क्लीनर डेटा का उपयोग करने और स्थलों के विभिन्न विचारों को खोजने की अनुमति देते हैं।
ऐसा लग सकता है कि वस्तु मान्यता एक तुच्छ कार्य है। हालांकि, वास्तविक जीवन की उपयोगकर्ता की जरूरतों की खोज करने पर, हमें नई पहचान जैसे लैंडमार्क मान्यता मिल जाती है। यह तकनीक तंत्रिका नेटवर्क का उपयोग करके लोगों को दुनिया के बारे में कुछ नया बताना संभव बनाती है। यह बहुत उत्साहजनक और प्रेरक है!