End2End भाषण मान्यता क्या है, और इसकी आवश्यकता क्यों है? शास्त्रीय दृष्टिकोण से इसका अंतर क्या है? और क्यों, एक अच्छे End2End- आधारित मॉडल के प्रशिक्षण के लिए, हमें आज अपनी पोस्ट में बड़ी मात्रा में डेटा की आवश्यकता है।
भाषण मान्यता के लिए क्लासिक दृष्टिकोण
End2End दृष्टिकोण के बारे में बात करने से पहले, आपको पहले भाषण मान्यता के लिए क्लासिक दृष्टिकोण के बारे में बात करनी चाहिए। वह क्या पसंद है?

फ़ीचर निष्कर्षण
वास्तव में, यह एक्शन ब्लॉक का पूरी तरह से रैखिक अनुक्रम नहीं है। आइए प्रत्येक ब्लॉक पर अधिक विस्तार से ध्यान दें। हमारे पास कुछ प्रकार के इनपुट भाषण हैं, यह पहले ब्लॉक - फ़ीचर एक्सट्रैक्शन पर पड़ता है। यह एक ब्लॉक है जो भाषण से संकेत खींचता है। यह ध्यान रखना चाहिए कि भाषण स्वयं एक जटिल चीज है। आपको किसी तरह इसके साथ काम करने में सक्षम होने की आवश्यकता है, इसलिए सिग्नल प्रोसेसिंग सिद्धांत से सुविधाओं को अलग करने के लिए मानक तरीके हैं। उदाहरण के लिए, मेल-सेप्स्ट्रल गुणांक (एमएफसीसी) और इसी तरह।
ध्वनिक मॉडल
अगला घटक ध्वनिक मॉडल है। यह गहरे तंत्रिका नेटवर्क पर आधारित हो सकता है, या गाऊसी वितरण और छिपे हुए मार्कोव मॉडल के मिश्रण के आधार पर। इसका मुख्य लक्ष्य ध्वनिक संकेत के एक सेक्शन से प्राप्त करना है, इस सेक्शन में विभिन्न फोनमों के प्रायिकता वितरण।
अगला डिकोडर आता है, जो अंतिम चरण से परिणाम के आधार पर ग्राफ में सबसे अधिक संभावित पथ की खोज करता है। बचाव में अंतिम स्पर्श बचाव है, जिसका मुख्य कार्य परिकल्पना को फिर से तौलना और अंतिम परिणाम देना है।
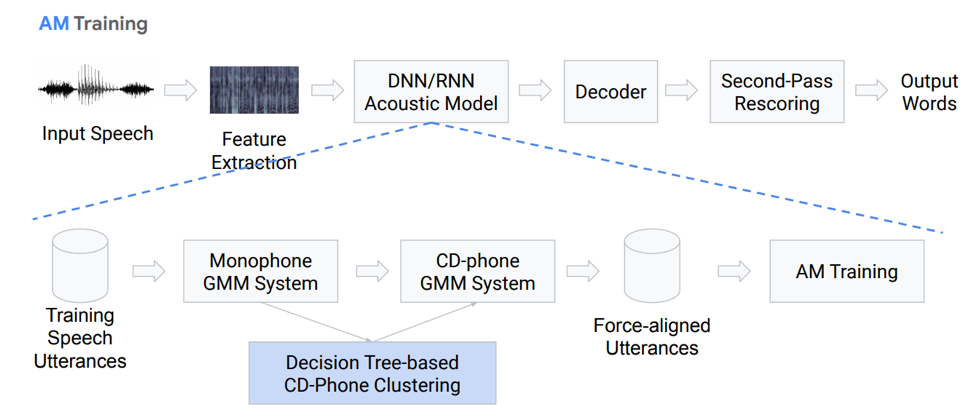
आइए ध्वनिक मॉडल पर अधिक विस्तार से ध्यान दें। वह क्या है? हमारे पास कुछ वॉयस रिकॉर्डिंग हैं जो GMM (मोनोरल गौसेवी मिक्स) या HMM पर आधारित एक निश्चित प्रणाली में प्रवेश करती हैं। यही है, हमारे पास स्वरों के रूप में अभ्यावेदन हैं, हम मोनोफोन का उपयोग करते हैं, अर्थात् संदर्भ-स्वतंत्र स्वर हैं। इनसे आगे, हम गौसियन डिस्ट्रीब्यूशन के मिश्रणों को संदर्भ-संवेदी स्वरों के आधार पर बनाते हैं। यह निर्णय पेड़ों के आधार पर क्लस्टरिंग का उपयोग करता है।
फिर हम संरेखण बनाने की कोशिश करते हैं। इस तरह की पूरी तरह से गैर-तुच्छ पद्धति हमें एक ध्वनिक मॉडल प्राप्त करने की अनुमति देती है। यह बहुत सरल नहीं है, वास्तव में यह और भी जटिल है, इसमें कई बारीकियां, विशेषताएं हैं। लेकिन इसके परिणामस्वरूप, सैकड़ों घंटों पर प्रशिक्षित एक मॉडल बहुत अच्छी तरह से ध्वनिकी अनुकरण करने में सक्षम है।

विकोडक
डिकोडर क्या है? यह वह मॉड्यूल है जो HCLG ग्राफ के अनुसार सबसे संभावित संक्रमण मार्ग का चयन करता है, जिसमें 4 भाग होते हैं:
एच मॉड्यूल एचएमएम पर आधारित है
C संदर्भ निर्भरता मॉड्यूल
एल उच्चारण मॉड्यूल
जी भाषा मॉडल मॉड्यूल
हम इन चार घटकों पर एक ग्राफ बनाते हैं, जिसके आधार पर हम अपनी ध्वनिक विशेषताओं को कुछ मौखिक निर्माणों में डिकोड करेंगे।
प्लस या माइनस, यह स्पष्ट है कि शास्त्रीय दृष्टिकोण बल्कि बोझिल और कठिन है, इसे प्रशिक्षित करना मुश्किल है, क्योंकि इसमें बड़ी संख्या में अलग-अलग हिस्से होते हैं, जिनमें से प्रत्येक के लिए आपको प्रशिक्षण के लिए अपना डेटा तैयार करने की आवश्यकता होती है।
II End2End दृष्टिकोण
तो End2End भाषण मान्यता क्या है और इसकी आवश्यकता क्यों है? यह एक निश्चित प्रणाली है, जिसे सीधे अंगूरों (अक्षरों) या शब्दों के अनुक्रम में ध्वनिक संकेतों के अनुक्रम को प्रतिबिंबित करने के लिए डिज़ाइन किया गया है। आप यह भी कह सकते हैं कि यह एक ऐसी प्रणाली है जो मानदंडों का अनुकूलन करती है जो सीधे गुणवत्ता मूल्यांकन के अंतिम मीट्रिक को प्रभावित करती है। उदाहरण के लिए, हमारा कार्य विशेष रूप से शब्द त्रुटि दर है। जैसा कि मैंने कहा, इन जटिल बहु-मंच घटकों को एक सरल घटक के रूप में प्रस्तुत करने के लिए केवल एक प्रेरणा है - इनपुट भाषण से सीधे आउटपुट शब्दों या अंगूरों को प्रदर्शित करेगा।
सिमुलेशन समस्या
यहां हमें तुरंत एक समस्या है: ध्वनि भाषण एक अनुक्रम है, और आउटपुट में हमें एक अनुक्रम देने की भी आवश्यकता है। और 2006 तक, इसे मॉडल करने का कोई पर्याप्त तरीका नहीं था। मॉडलिंग की समस्या क्या है? कॉम्प्लेक्स मार्कअप बनाने के लिए प्रत्येक रिकॉर्ड की आवश्यकता थी, जिसका अर्थ है कि हम किसी विशेष ध्वनि या अक्षर को किस सेकंड में देखते हैं। यह एक बहुत ही बोझिल जटिल लेआउट है और इसलिए इस विषय पर बड़ी संख्या में अध्ययन नहीं किए गए हैं। 2006 में, एलेक्स ग्रेव्स "कनेक्शनिस्ट टेम्पोरल क्लासिफिकेशन" (CTC) द्वारा एक दिलचस्प लेख प्रकाशित किया गया था, जिसमें यह समस्या, सिद्धांत रूप में, हल की गई है। लेकिन लेख प्रकाशित किया गया था, और उस समय पर्याप्त कंप्यूटिंग शक्ति नहीं थी। और वास्तविक कार्य भाषण मान्यता एल्गोरिदम बहुत बाद में दिखाई दिए।
कुल मिलाकर, हमारे पास: CTC एल्गोरिथ्म एलेक्स ग्राव्स द्वारा तेरह साल पहले प्रस्तावित किया गया था, एक उपकरण के रूप में जो आपको इस जटिल मार्कअप की आवश्यकता के बिना ध्वनिक मॉडल को प्रशिक्षित / प्रशिक्षित करने की अनुमति देता है - इनपुट और आउटपुट अनुक्रम फ्रेम के संरेखण। इस एल्गोरिथ्म के आधार पर, काम शुरू में दिखाई दिया जो पूर्ण एंडेंडेंड नहीं था, इसके परिणामस्वरूप फोनीम जारी किए गए थे। यह ध्यान देने योग्य है कि एसटीएस पर आधारित संदर्भ-संवेदनशील स्वर स्वतंत्र भाषण की मान्यता में सर्वश्रेष्ठ परिणामों में से एक को प्राप्त करते हैं। लेकिन यह भी ध्यान देने योग्य है कि यह एल्गोरिदम, सीधे शब्दों में लागू किया गया है, इस समय कहीं पीछे रहता है।

एसटीएस क्या है
अब हम विस्तार से थोड़ा और बात करेंगे कि एसटीएस क्या है, और इसकी आवश्यकता क्यों है, यह क्या कार्य करता है। ध्वनि और प्रतिलेखन के बीच फ्रेम-बाय-फ्रेम संरेखण की आवश्यकता के बिना ध्वनिक मॉडल को प्रशिक्षित करने के लिए एसटीएस आवश्यक है। फ़्रेम-बाय-फ़्रेम संरेखण तब होता है जब हम कहते हैं कि ध्वनि से एक विशेष फ्रेम प्रतिलेखन से ऐसे फ्रेम से मेल खाती है। हमारे पास एक पारंपरिक एन्कोडर है जो एक इनपुट के रूप में ध्वनिक संकेतों को स्वीकार करता है - यह राज्य के कुछ प्रकार के छिपी देता है, जिसके आधार पर हमें सॉफ्टमैक्स का उपयोग करके सशर्त संभावनाएं मिलती हैं। एनकोडर में आमतौर पर LSTM की कई परतें या RNN की अन्य विविधताएँ होती हैं। यह ध्यान देने योग्य है कि एसटीएस सामान्य पात्रों के अलावा एक विशेष चरित्र के साथ संचालित होता है जिसे एक खाली चरित्र या एक खाली प्रतीक कहा जाता है। इस समस्या को हल करने के लिए जो इस तथ्य के कारण उत्पन्न होती है कि प्रत्येक ध्वनिक फ्रेम में प्रतिलेखन में एक फ्रेम नहीं है और इसके विपरीत, (हमारे पास पत्र हैं या ध्वनियां हैं जो बहुत लंबे समय तक ध्वनि करते हैं और छोटी ध्वनियां हैं, ध्वनियों को दोहराते हैं), और वहां यह खाली प्रतीक है।
एसटीएस ही वर्णों के अनुक्रम की अंतिम संभावना को अधिकतम करने और संभावित संरेखण को सामान्य बनाने का इरादा है। चूंकि हम तंत्रिका नेटवर्क में इस एल्गोरिथ्म का उपयोग करना चाहते हैं, इसलिए यह समझा जाता है कि हमें यह समझना चाहिए कि ऑपरेशन के आगे और पीछे के तरीके कैसे काम करते हैं। हम इस एल्गोरिथ्म के संचालन के गणितीय औचित्य और सुविधाओं पर ध्यान नहीं देंगे, अन्यथा इसमें बहुत लंबा समय लगेगा।
हमारे पास क्या है: एसटीएस एल्गोरिथ्म पर आधारित पहला एएसआर 2014 में दिखाई देता है। फिर से, एलेक्स ग्रेव्स ने चरित्र-दर-अक्षर एसटीएस पर आधारित एक प्रकाशन प्रस्तुत किया जो सीधे शब्दों में इनपुट भाषण को प्रदर्शित करता है। इस लेख में उन्होंने एक टिप्पणी की है कि एक अच्छा परिणाम प्राप्त करने के लिए बाहरी ध्वनि मॉडल का उपयोग करना महत्वपूर्ण है।
एल्गोरिथ्म में सुधार करने के 5 तरीके
उपरोक्त एल्गोरिथ्म में कई अलग-अलग विविधताएं और सुधार हैं। उदाहरण के लिए, हाल ही में पांच सबसे लोकप्रिय हैं।
• भाषा मॉडल पहले पास के दौरान डिकोडिंग में शामिल है
ओ [हुनुन एट अल।, 2014] [मास एट अल।, 2015]: एक एलएम के साथ प्रत्यक्ष पहली-पास डिकोडिंग के रूप में [ग्रेव्स एंड जेटली, 2014] में बचाव करने का विरोध किया।
o [मियाओ एट अल।, 2015]: डब्ल्यूएफएसटी, ओपन सोर्स टूलकिट के साथ डिकोडिंग के लिए ईईएसएन फ्रेमवर्क
• GPU पर बड़े पैमाने पर प्रशिक्षण; डेटा ऑगमेंटेशन कई भाषाएं
ओ [हुनुन एट अल।, 2014; डीपस्पीच] [अमोदी एट अल।, 2015; DeepSpeech2]: बड़े पैमाने पर GPU प्रशिक्षण; डेटा ऑगमेंटेशन; मंदारिन और अंग्रेजी
• लंबी इकाइयों का उपयोग: वर्णों के बजाय शब्द
o [सोल्टौ एट अल।, 2017]: वर्ड-लेवल सीटीसी लक्ष्य, 125,000 घंटे के भाषण पर प्रशिक्षित। एक पारंपरिक प्रणाली की तुलना में करीब या उससे बेहतर प्रदर्शन, यहां तक कि एलएम का उपयोग किए बिना!
o [Audhkhasi et al।, 2017]: स्विचबोर्ड पर प्रत्यक्ष ध्वनिकी-से-वर्ड मॉडल
यह दीपस्पीच के कार्यान्वयन पर ध्यान देने के लायक है, जो कि एंडीएंड सीटीसी समाधान के एक अच्छे उदाहरण के रूप में और एक भिन्नता का उपयोग करता है जो एक मौखिक स्तर का उपयोग करता है। लेकिन एक चेतावनी है: इस तरह के एक मॉडल को प्रशिक्षित करने के लिए, आपको 125 हजार घंटे के लेबल डेटा की आवश्यकता होती है, जो वास्तव में कठोर वास्तविकताओं में काफी है।
एसटीएस के बारे में ध्यान देना महत्वपूर्ण है
- मुद्दे या चूक। दक्षता के लिए, स्वतंत्रता के बारे में धारणा बनाना महत्वपूर्ण है। यही है, एसटीएस मानता है कि विभिन्न फ़्रेमों में नेटवर्क का आउटपुट सशर्त रूप से स्वतंत्र है, जो वास्तव में गलत है। लेकिन यह धारणा सरल बनाने के लिए बनाई गई है, इसके बिना, सब कुछ बहुत अधिक जटिल हो जाता है।
- एसटीएस मॉडल से अच्छा प्रदर्शन प्राप्त करने के लिए, बाहरी भाषा मॉडल के उपयोग की आवश्यकता होती है, क्योंकि प्रत्यक्ष लालची डिकोडिंग बहुत अच्छी तरह से काम नहीं करती है।
ध्यान दें
इस एसटीएस के लिए हमारे पास क्या विकल्प है? यह शायद किसी के लिए कोई रहस्य नहीं है कि ध्यान या "ध्यान" जैसी कोई चीज है, जिसने कुछ हद तक क्रांति की और सीधे मशीन अनुवाद के कार्यों से चला गया। और अब सभी अनुक्रम-अनुक्रम मॉडलिंग के अधिकांश निर्णय इस तंत्र पर आधारित हैं। वह क्या पसंद है? आइए इसे जानने की कोशिश करते हैं। भाषण मान्यता कार्यों में ध्यान के बारे में पहली बार, 2015 में प्रकाशन दिखाई दिए। किसी ने चेन और चेरोव्स्की ने एक ही समय में दो समान और असंतुष्ट प्रकाशन जारी किए।
आइए हम पहले स्थान पर रहें - इसे सुनो, उपस्थित और मंत्र कहा जाता है। हमारे क्लासिक सिमुलेशन में, उस अनुक्रम में जहां हमारे पास एक एनकोडर और डिकोडर है, एक और तत्व जोड़ा जाता है, जिसे ध्यान कहा जाता है। ईकोडर उन कार्यों को करेगा जो कि ध्वनिक मॉडल प्रदर्शन करने के लिए उपयोग किया जाता है। इसका कार्य इनपुट भाषण को उच्च-स्तरीय ध्वनिक विशेषताओं में बदलना है। हमारा डिकोडर उन कार्यों को करेगा जो हमने पहले भाषा मॉडल और उच्चारण मॉडल (लेक्सिकॉन) का प्रदर्शन किया था, यह पिछले आउटपुट से एक फ़ंक्शन के रूप में प्रत्येक आउटपुट टोकन को स्वचालित रूप से भविष्यवाणी करेगा। और ध्यान स्वयं सीधे कहेंगे कि इस आउटपुट की भविष्यवाणी करने के लिए कौन सा इनपुट फ्रेम सबसे अधिक प्रासंगिक / महत्वपूर्ण है।
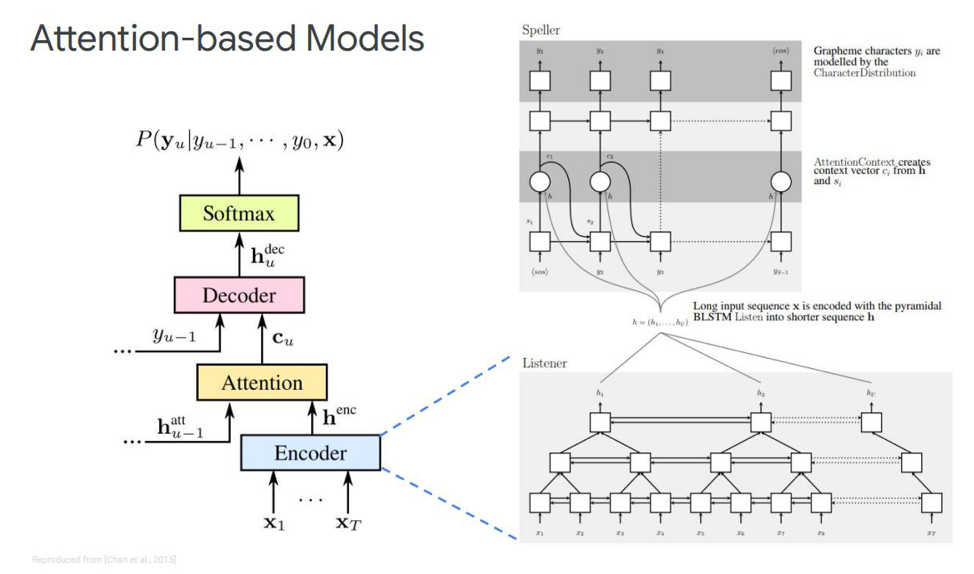
ये ब्लॉक क्या हैं? लेख में इको-एनकोडर को एक श्रोता के रूप में वर्णित किया गया है, यह एक क्लासिक द्वि-दिशात्मक RNN है जो LSTM या किसी अन्य चीज़ पर आधारित है। सामान्य तौर पर, कुछ भी नया नहीं है - सिस्टम केवल इनपुट अनुक्रम को जटिल सुविधाओं में अनुकरण करता है।
ध्यान, दूसरी ओर, इन वैक्टरों से एक निश्चित संदर्भ वेक्टर सी बनाता है, जो डिकोडर को सीधे सही ढंग से डिकोड करने में मदद करेगा, स्वयं डिकोडर, जो उदाहरण के लिए, कुछ एलएसटीएम भी हैं, जो इस ध्यान परत पर इनपुट अनुक्रम में डिकोड किया जाएगा, जिसने पहले से ही सबसे महत्वपूर्ण राज्य संकेतों को उजागर किया है। वर्णों के कुछ आउटपुट अनुक्रम।
स्वयं इस अटेंशन के अलग-अलग निरूपण भी हैं - जो कि चेन और चारोस्की द्वारा जारी इन दो प्रकाशनों के बीच का अंतर है। वे अलग अटेंशन का इस्तेमाल करते हैं। चेन डॉट-प्रोडक्ट अटेंशन का उपयोग करता है, और चारोस्की एडिटिव अटेंशन का उपयोग करता है।

आगे कहाँ जाना है?
यह एक ऑनलाइन या गैर-ऑनलाइन भाषण मान्यता के मामलों में प्राप्त की गई सभी प्रमुख उपलब्धियां हैं। यहां क्या सुधार संभव हैं? आगे कहाँ जाना है? सबसे स्पष्ट सीधे अंगूरों का उपयोग करने के बजाय शब्दों के टुकड़ों पर एक मॉडल का उपयोग है। यह कुछ अलग तरह के महापाप या कुछ और हो सकते हैं।
शब्द स्लाइस का उपयोग करने के लिए प्रेरणा क्या है? आमतौर पर, मौखिक स्तर के भाषा मॉडल में अंगूर के स्तर की तुलना में बहुत कम गड़बड़ी होती है। शब्दों के मॉडलिंग के टुकड़े आपको भाषा मॉडल का एक मजबूत डिकोडर बनाने की अनुमति देते हैं। और लंबे समय तक तत्वों को मॉडलिंग करने से LSTM पर आधारित डिकोडर में मेमोरी दक्षता में सुधार हो सकता है। यह आपको आवृत्ति शब्दों के लिए संभावित रूप से याद रखने की अनुमति भी देता है। लंबे तत्व कम चरणों में डिकोडिंग की अनुमति देते हैं, जो सीधे इस मॉडल के निष्कासन को तेज करता है।
इसके अलावा, शब्दों के टुकड़ों पर एक मॉडल हमें ओओवी (शब्दावली से बाहर) शब्दों की समस्या को हल करने की अनुमति देता है जो भाषा मॉडल में उत्पन्न होते हैं, क्योंकि हम किसी भी शब्द को शब्दों के टुकड़ों के साथ मॉडल कर सकते हैं। और यह ध्यान देने योग्य है कि इस तरह के मॉडल को प्रशिक्षण डेटा सेट पर एक भाषा मॉडल की संभावना को अधिकतम करने के लिए प्रशिक्षित किया जाता है। ये मॉडल स्थिति-निर्भर हैं, और हम डिकोडिंग के लिए लालची एल्गोरिथ्म का उपयोग कर सकते हैं।
शब्दों के टुकड़ों के मॉडल के अलावा और क्या सुधार हो सकते हैं? मल्टी-हेड ध्यान नामक एक तंत्र है। यह पहली बार 2017 में मशीन अनुवाद के लिए वर्णित किया गया था। मल्टी-हेड ध्यान एक तंत्र का अर्थ है जिसमें कई तथाकथित सिर होते हैं जो आपको इस समान ध्यान का एक अलग वितरण उत्पन्न करने की अनुमति देते हैं, जो परिणामों को सीधे सुधारता है।
ऑनलाइन मॉडल
हम सबसे दिलचस्प भाग से गुजरते हैं - ये ऑनलाइन मॉडल हैं। यह ध्यान रखना महत्वपूर्ण है कि LAS स्ट्रीमिंग नहीं है। यही है, यह मॉडल ऑनलाइन डिकोडिंग मोड में काम नहीं कर सकता है। हम आज तक के दो सबसे लोकप्रिय ऑनलाइन मॉडल पर विचार करेंगे। आरएनएन ट्रांसड्यूसर और न्यूरल ट्रांसड्यूसर।
आरएनएन ट्रांसड्यूसर को 2012-2017 में ग्रेव्स द्वारा प्रस्तावित किया गया था। मुख्य विचार एक पुनरावर्ती मॉडल की मदद से हमारे एसटीएस मॉडल को थोड़ा जटिल करना है।
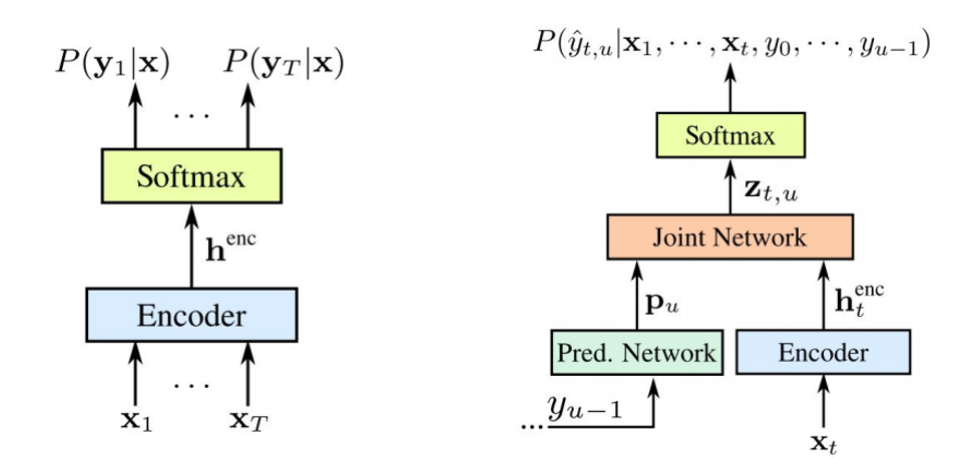
यह ध्यान देने योग्य है कि दोनों घटकों को उपलब्ध ध्वनिक डेटा पर एक साथ प्रशिक्षित किया जाता है। एसटीएस की तरह, इस दृष्टिकोण को प्रशिक्षण डेटा सेट में फ्रेम संरेखण की आवश्यकता नहीं है। जैसा कि हम तस्वीर में देखते हैं: बाईं ओर हमारा क्लासिक एसटीएस है, और दाईं ओर आरएनएन ट्रांसड्यूसर है। और हमारे पास दो नए तत्व हैं -
पूर्वनिर्धारित नेटवर्क और
ज्वाइन नेटवर्क ।
एसटीएस एनकोडर बिल्कुल समान है - यह इनपुट स्तर आरएनएन है, जो सभी अनुक्रमों के साथ वितरण को निर्धारित करता है सभी इनपुट अनुक्रमों की इनपुट अनुक्रम की लंबाई से अधिक नहीं है - यह 2006 में ग्रेव्स द्वारा वर्णित किया गया था। हालाँकि, ऐसे टेक्स्ट-टू-स्पीच रूपांतरणों के कार्य को भी बाहर रखा गया है, जहाँ इनपुट अनुक्रम STS के इनपुट अनुक्रम की तुलना में लंबे समय तक आउटपुट के बीच संबंध नहीं बनाते हैं। ट्रांसड्यूसर इस बहुत एसटीएस का विस्तार करता है, जो सभी लंबाई के आउटपुट अनुक्रमों के वितरण का निर्धारण करता है और संयुक्त रूप से इनपुट-आउटपुट और आउटपुट-आउटपुट की निर्भरता को मॉडलिंग करता है।
यह पता चलता है कि हमारा मॉडल अंततः इनपुट से आउटपुट की निर्भरता और अंतिम चरण के आउटपुट से आउटपुट को संभालने में सक्षम है।
तो एक
अनुमानित नेटवर्क या एक पूर्वानुमान नेटवर्क क्या है? वह पिछले तत्वों को ध्यान में रखते हुए प्रत्येक तत्व को मॉडल करने की कोशिश करती है, इसलिए, यह अगले चरण के पूर्वानुमान के साथ मानक आरएनएन के समान है। केवल शून्य परिकल्पना करने की अतिरिक्त क्षमता के साथ।
जैसा कि हम चित्र में देखते हैं, हमारे पास एक पूर्वनिर्धारित नेटवर्क है, जो आउटपुट के पिछले मूल्य को प्राप्त करता है, और एक एनकोडर है, जो इनपुट के वर्तमान मूल्य को प्राप्त करता है। और आउटपुट पर हम फिर से, ऐसे वर्तमान मूल्य है
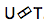
।
तंत्रिका ट्रांसड्यूसर । यह क्लासिक seq-2seq दृष्टिकोण की एक जटिलता है। इनपुट ध्वनिक अनुक्रम को एन्कोडर द्वारा प्रत्येक समय चरण में छिपे हुए राज्य वैक्टर बनाने के लिए संसाधित किया जाता है। यह सब हमेशा की तरह लगता है। लेकिन एक अतिरिक्त ट्रांसड्यूसर तत्व है जो प्रत्येक चरण पर एक इनपुट ब्लॉक प्राप्त करता है और इस इनपुट के ऊपर seq-2seq- आधारित मॉडल का उपयोग करके एम-आउटपुट टोकन तक उत्पन्न करता है। ट्रांसड्यूसर पिछले समय के चरणों के साथ आवधिक कनेक्शन का उपयोग करके ब्लॉकों में अपनी स्थिति बनाए रखता है।
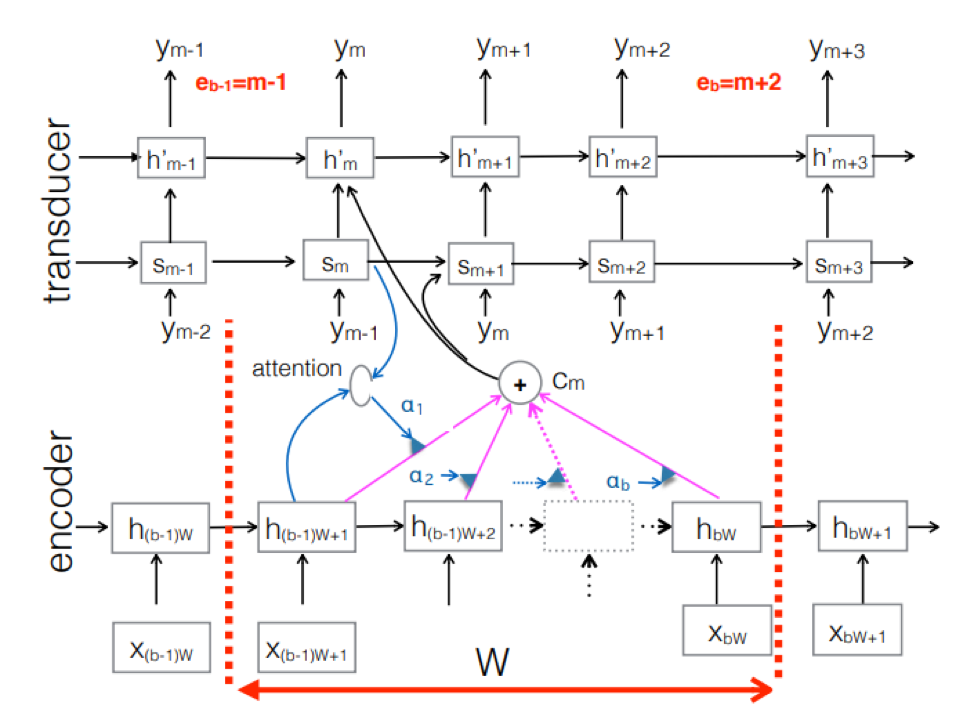 यह आंकड़ा ट्रांसड्यूसर को दिखाता है, इसी Ym के ब्लॉक में प्रयुक्त अनुक्रम के लिए ब्लॉक के लिए टोकन का उत्पादन करता है।
यह आंकड़ा ट्रांसड्यूसर को दिखाता है, इसी Ym के ब्लॉक में प्रयुक्त अनुक्रम के लिए ब्लॉक के लिए टोकन का उत्पादन करता है।इसलिए, हमने End2End दृष्टिकोण के आधार पर भाषण मान्यता की वर्तमान स्थिति की जांच की। यह कहने योग्य है कि, दुर्भाग्य से, आज इन दृष्टिकोणों को बड़ी मात्रा में डेटा की आवश्यकता होती है। और वास्तविक परिणाम जो शास्त्रीय दृष्टिकोण द्वारा प्राप्त किए जाते हैं, एंडडाईंड के आधार पर एक अच्छे मॉडल के प्रशिक्षण के लिए 200 से 500 घंटे की ध्वनि रिकॉर्डिंग की आवश्यकता होती है, कई, या शायद दसियों बार अधिक डेटा की आवश्यकता होगी। अब इन दृष्टिकोणों के साथ यह सबसे बड़ी समस्या है। लेकिन शायद जल्द ही सब कुछ बदल जाएगा।
एआई एमटीएस केंद्र के प्रमुख डेवलपर निकिता सेमेनोव।