यह और निम्नलिखित गाइड आपको डिस्कवरी.जेएस परियोजना के आधार पर एक समाधान बनाने की प्रक्रिया के माध्यम से मार्गदर्शन करेंगे। हमारा लक्ष्य NPM निर्भरता के लिए एक इंस्पेक्टर बनाना है, अर्थात, node_modules की संरचना की जांच करने के लिए एक इंटरफ़ेस है।
नोट: Discovery.js विकास के प्रारंभिक चरण में है, इसलिए समय के साथ, कुछ सरल हो जाएगा और अधिक उपयोगी हो जाएगा। यदि आपके पास कुछ सुधार करने के बारे में विचार हैं, तो हमें लिखें ।
अमूर्त
नीचे आपको Discovery.js की प्रमुख अवधारणाओं का अवलोकन मिलेगा। आप GitHub पर रिपॉजिटरी में संपूर्ण मैनुअल कोड सीख सकते हैं, या आप यह कोशिश कर सकते हैं कि यह ऑनलाइन कैसे काम करता है ।
प्रारंभिक शर्तें
सबसे पहले, हमें विश्लेषण के लिए एक परियोजना चुनने की आवश्यकता है। यह एक हौसले से बनाई गई परियोजना या मौजूदा एक हो सकती है, मुख्य बात यह है कि इसमें node_modules (हमारे विश्लेषण की वस्तु) शामिल है।
सबसे पहले, discoveryjs कोर पैकेज और उसके कंसोल टूल्स को स्थापित करें:
npm install @discoveryjs/discovery @discoveryjs/cli
इसके बाद, Discovery.js सर्वर लॉन्च करें:
> npx discovery No config is used Models are not defined (model free mode is enabled) Init common routes ... OK Server listen on http://localhost:8123
यदि आप ब्राउज़र में http://localhost:8123 खोलते हैं, तो आप निम्नलिखित देख सकते हैं:

यह एक मॉडल के बिना एक मोड है, अर्थात्, एक मोड जब कुछ भी कॉन्फ़िगर नहीं किया जाता है। लेकिन अब, "लोड डेटा" बटन का उपयोग करके, आप किसी भी JSON फ़ाइल का चयन कर सकते हैं, या बस इसे पृष्ठ पर खींच सकते हैं और विश्लेषण शुरू कर सकते हैं।
हालाँकि, हमें कुछ विशिष्ट चाहिए। विशेष रूप से, हमें node_modules संरचना का एक दृश्य प्राप्त करने की आवश्यकता है। ऐसा करने के लिए, कॉन्फ़िगरेशन जोड़ें।
कॉन्फ़िगरेशन जोड़ें
जैसा कि आपने देखा होगा, सर्वर शुरू होने पर संदेश No config is used । आइए निम्नलिखित सामग्रियों के साथ .discoveryrc.js कॉन्फ़िगरेशन फ़ाइल बनाएँ:
module.exports = { name: 'Node modules structure', data() { return { hello: 'world' }; } };
नोट: यदि आप वर्तमान वर्किंग डायरेक्टरी (प्रोजेक्ट के रूट में) में एक फाइल बनाते हैं, तो और कुछ नहीं चाहिए। अन्यथा, आपको --config विकल्प का उपयोग करके कॉन्फ़िगरेशन फ़ाइल में पथ पास करना होगा या package.json में पथ सेट करना होगा। package.json :
{ ... "discovery": "path/to/discovery/config.js", ... }
सर्वर को पुनरारंभ करें ताकि कॉन्फ़िगरेशन लागू हो:
> npx discovery Load config from .discoveryrc.js Init single model default Define default routes ... OK Cache: DISABLED Init common routes ... OK Server listen on http://localhost:8123
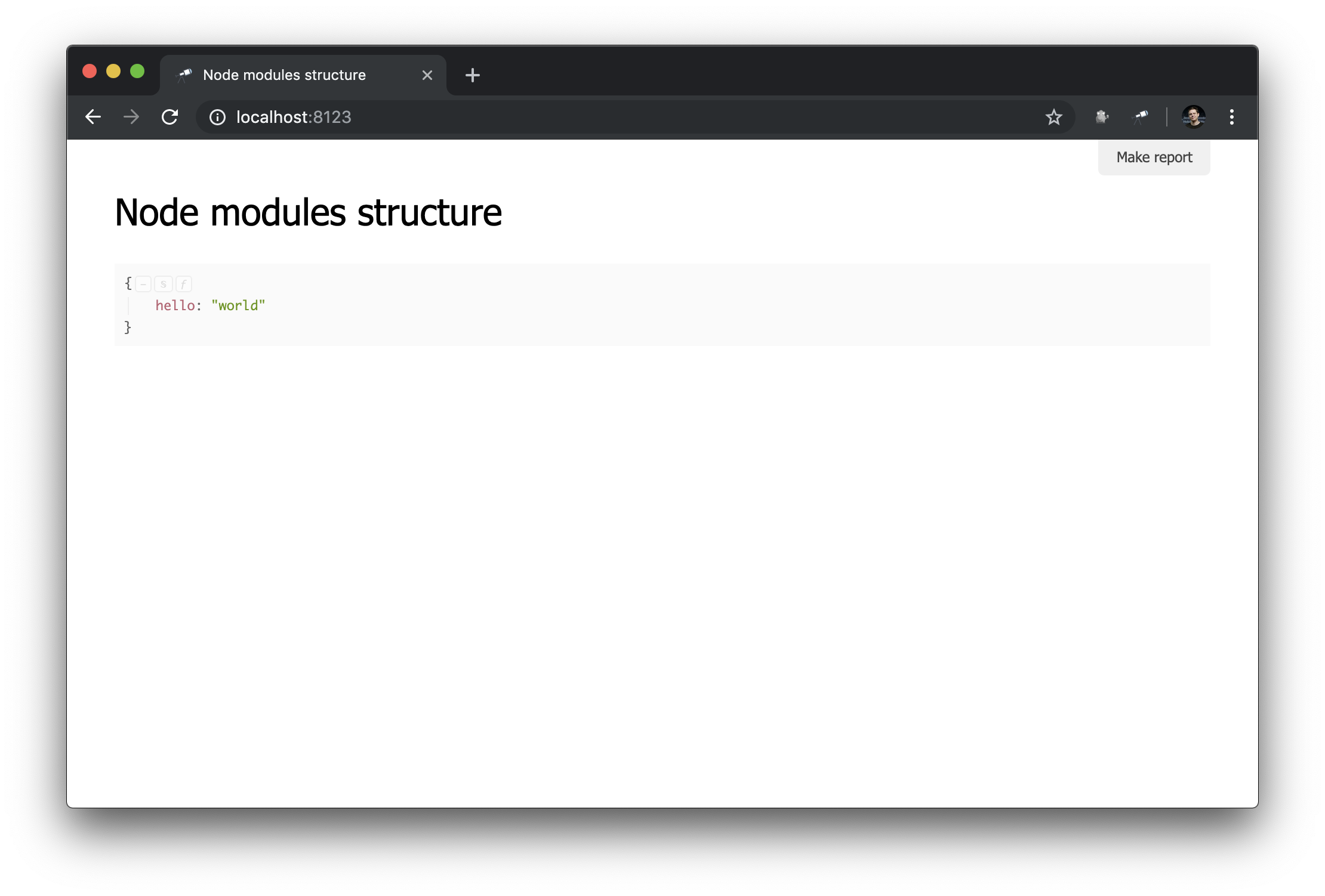
जैसा कि आप देख सकते हैं, अब हमारे द्वारा बनाई गई फ़ाइल का उपयोग किया जाता है। और हमारे द्वारा वर्णित डिफ़ॉल्ट मॉडल लागू किया गया है (डिस्कवरी कई मॉडलों के मोड में काम कर सकती है, हम निम्नलिखित मैनुअल में इस सुविधा के बारे में बात करेंगे)। आइए देखें कि ब्राउज़र में क्या बदल गया है:
यहाँ क्या देखा जा सकता है:
name उपयोग पृष्ठ शीर्षक के रूप में किया जाता है;data पद्धति को कॉल करने का परिणाम पृष्ठ की मुख्य सामग्री के रूप में प्रदर्शित होता है।
नोट: data विधि को डेटा या वादा वापस करना चाहिए, जो डेटा को हल करता है।
मूल सेटिंग्स बनाई गई हैं, आप आगे बढ़ सकते हैं।
प्रसंग
आइए देखें कस्टम रिपोर्ट पेज ( Make report क्लिक Make report ):
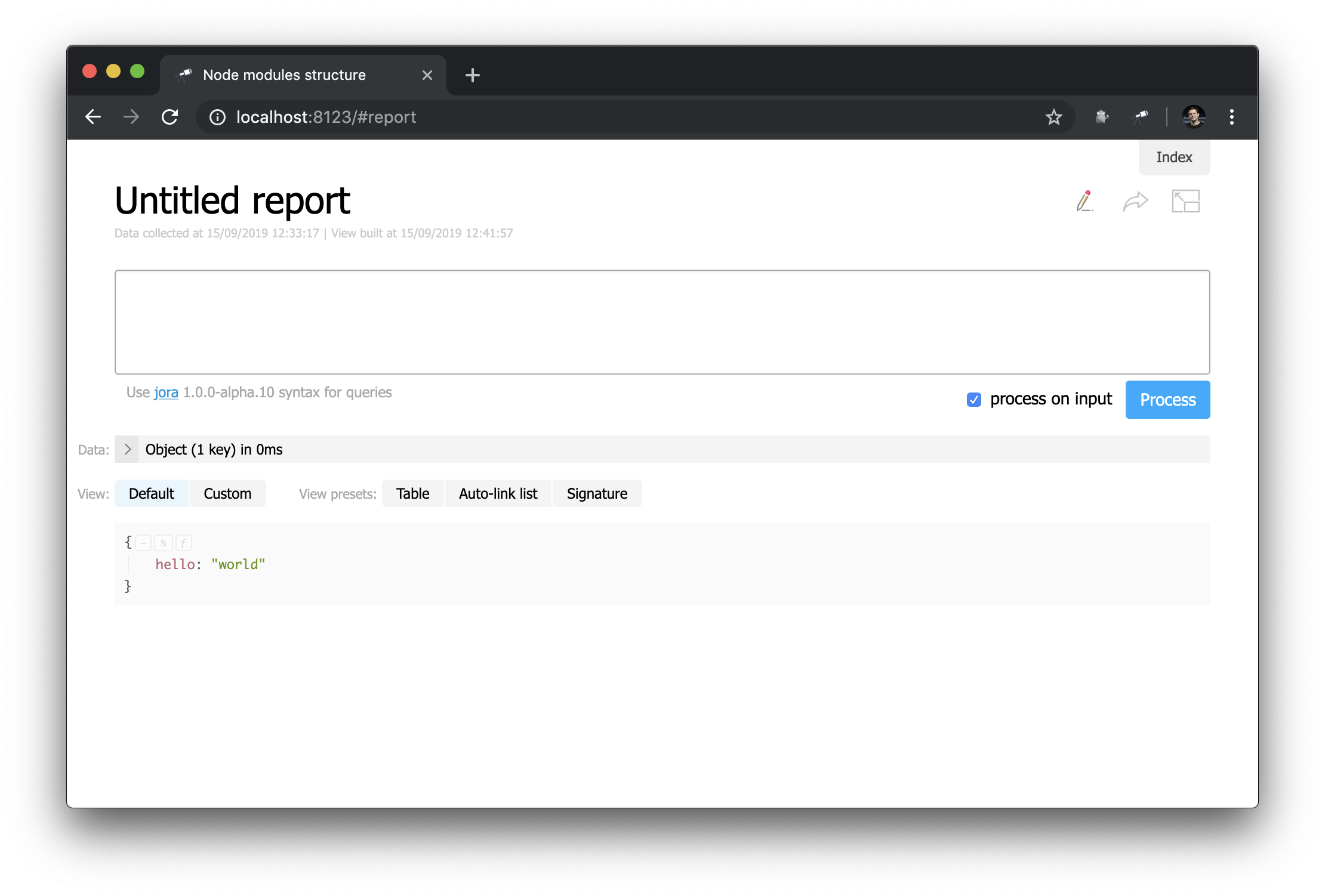
पहली नज़र में, यह प्रारंभ पृष्ठ से बहुत अलग नहीं है ... लेकिन यहां आप सब कुछ बदल सकते हैं! उदाहरण के लिए, हम प्रारंभ पृष्ठ की उपस्थिति को आसानी से बना सकते हैं:
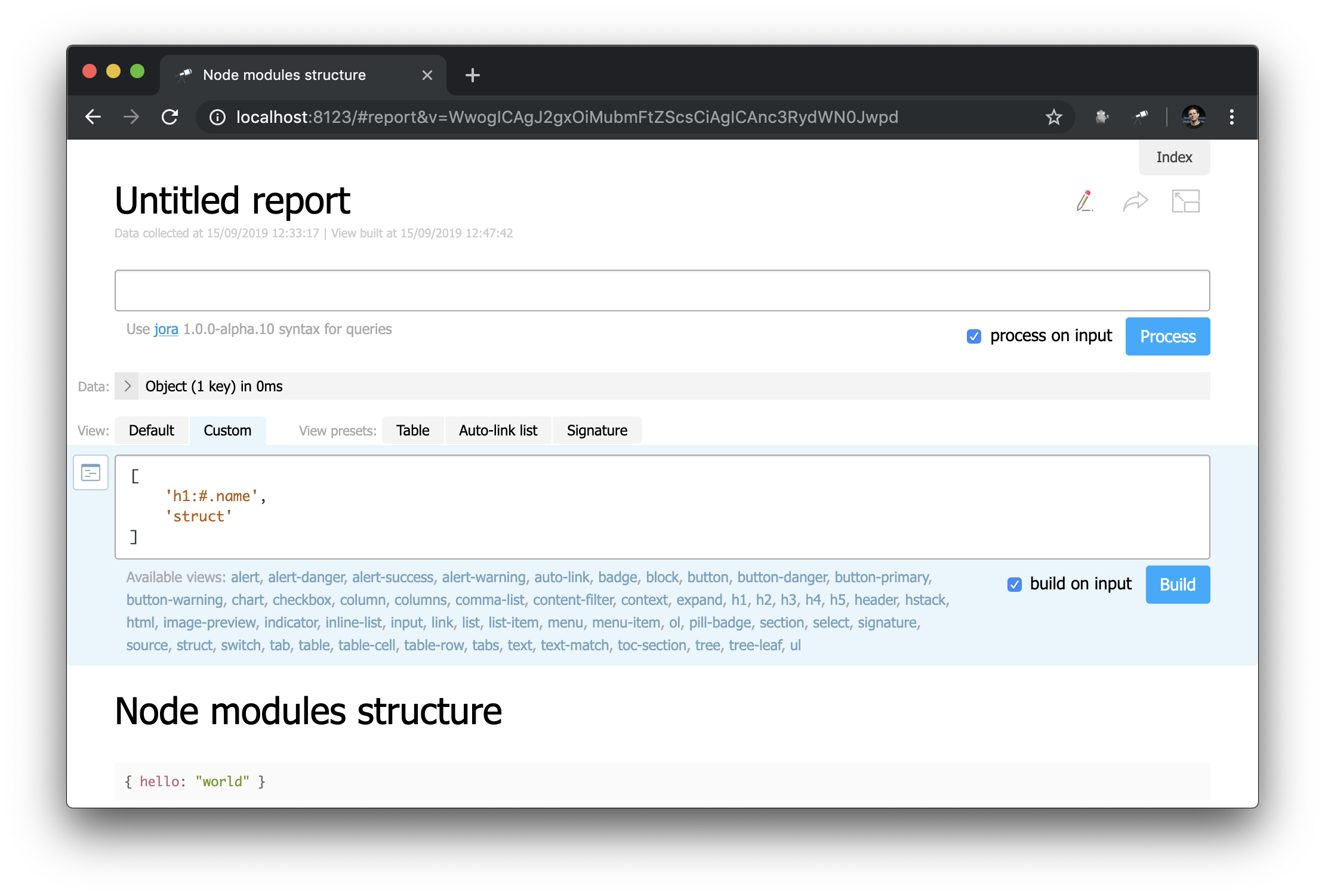
ध्यान दें कि हेडर कैसे परिभाषित किया गया है: "h1:#.name" । यह #.name की सामग्री के साथ प्रथम स्तर का शीर्ष लेख है, जो कि एक जोरा अनुरोध है। # अनुरोध संदर्भ को संदर्भित करता है। इसकी सामग्री देखने के लिए, क्वेरी संपादक में बस # दर्ज करें और डिफ़ॉल्ट प्रदर्शन का उपयोग करें:
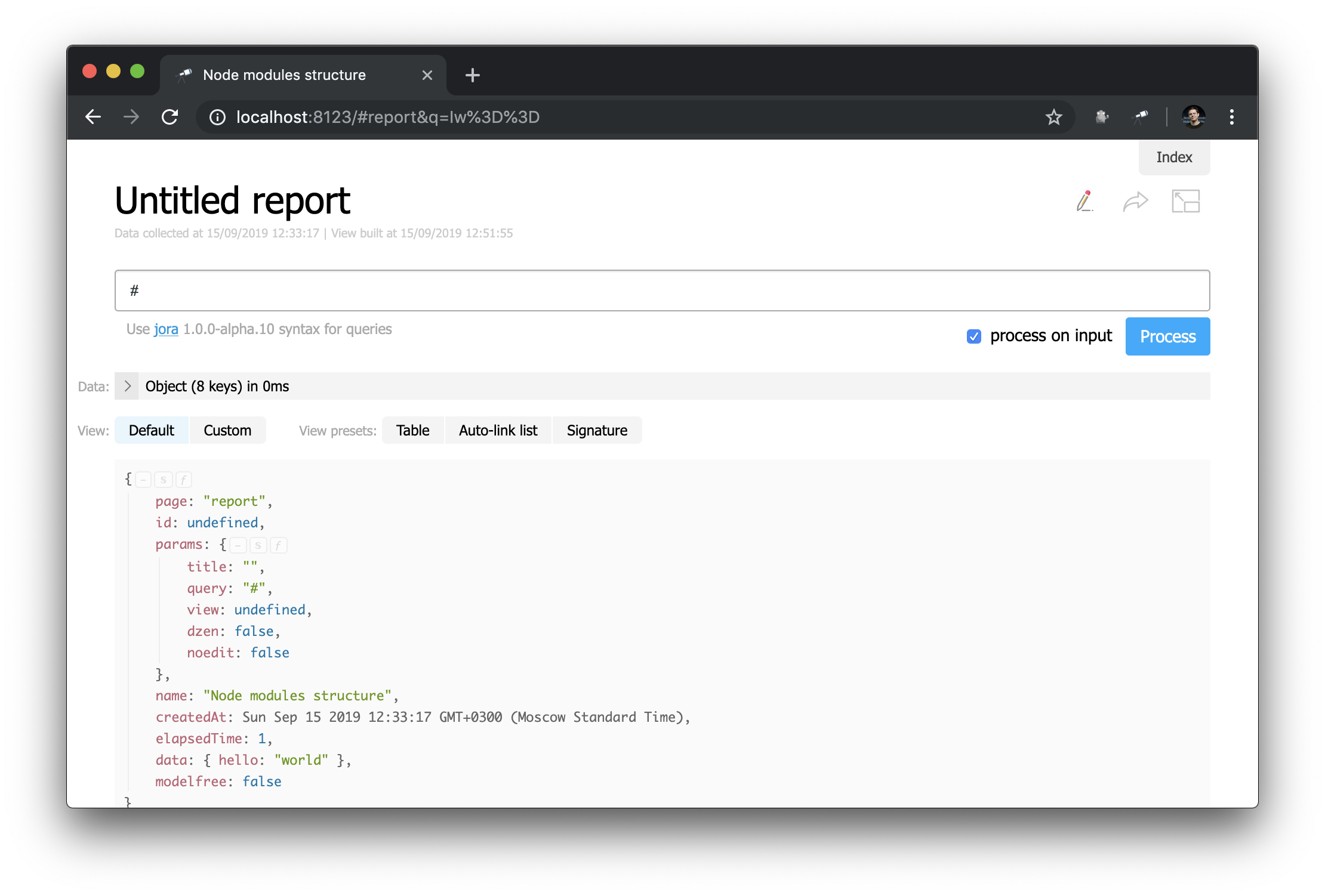
अब आप जानते हैं कि वर्तमान पृष्ठ की आईडी, इसके मापदंडों और अन्य उपयोगी मूल्यों को कैसे प्राप्त किया जाए।
डेटा संग्रह
अब हम वास्तविक डेटा के बजाय प्रोजेक्ट में एक स्टब का उपयोग करते हैं, लेकिन हमें वास्तविक डेटा की आवश्यकता होती है। ऐसा करने के लिए, एक मॉड्यूल बनाएं और कॉन्फ़िगरेशन में data मान को बदलें (वैसे, इन परिवर्तनों के बाद सर्वर को पुनरारंभ करना आवश्यक नहीं है:
module.exports = { name: 'Node modules structure', data: require('./collect-node-modules-data') };
collect-node-modules-data.js :
const path = require('path'); const scanFs = require('@discoveryjs/scan-fs'); module.exports = function() { const packages = []; return scanFs({ include: ['node_modules'], rules: [{ test: /\/package.json$/, extract: (file, content) => { const pkg = JSON.parse(content); if (pkg.name && pkg.version) { packages.push({ name: pkg.name, version: pkg.version, path: path.dirname(file.filename), dependencies: pkg.dependencies }); } } }] }).then(() => packages); };
मैंने @discoveryjs/scan-fs पैकेज का इस्तेमाल किया, जो फाइल सिस्टम स्कैनिंग को सरल बनाता है। पैकेज का उपयोग करने का एक उदाहरण इसकी रीडमी में वर्णित है, मैंने इस उदाहरण को आधार के रूप में लिया और आवश्यकतानुसार अंतिम रूप दिया। अब हमारे पास node_modules की सामग्री के बारे में कुछ जानकारी है:
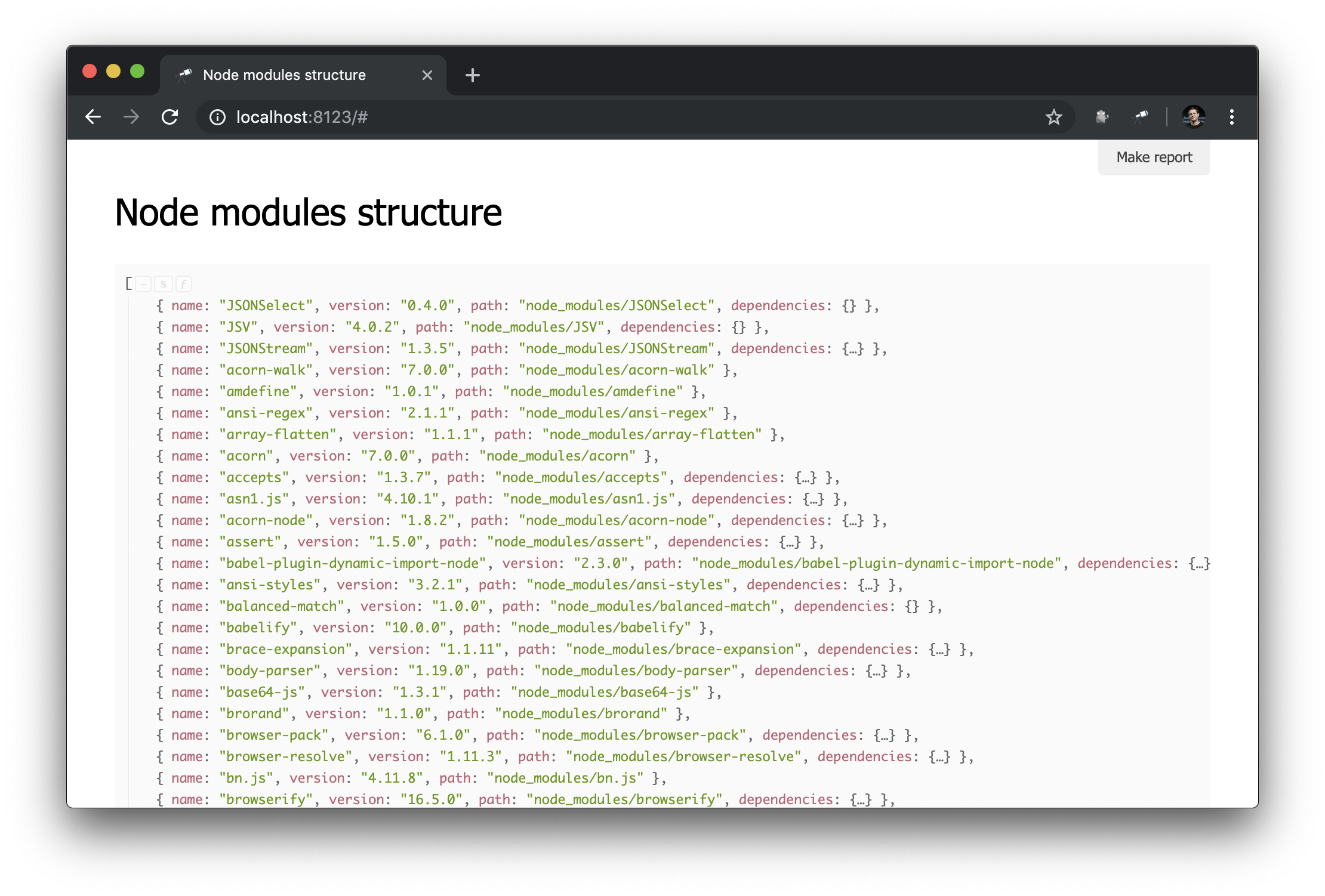
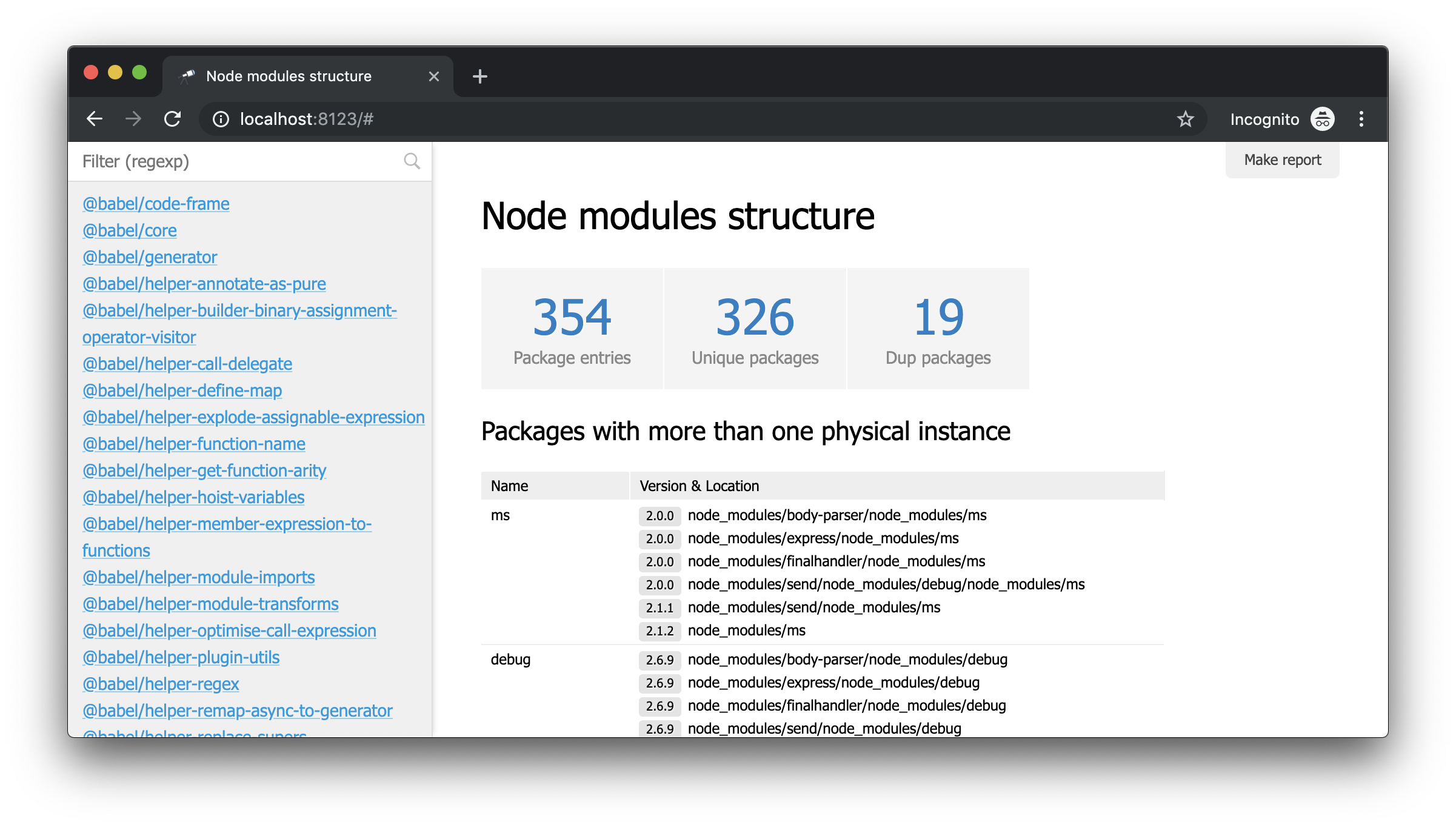
आपको क्या चाहिए! और इस तथ्य के बावजूद कि यह सामान्य JSON है, हम पहले से ही इसका विश्लेषण कर सकते हैं और कुछ निष्कर्ष निकाल सकते हैं। उदाहरण के लिए, डेटा संरचना के पॉपअप का उपयोग करके, आप पैकेटों की संख्या का पता लगा सकते हैं और पता लगा सकते हैं कि उनमें से कितने में एक से अधिक भौतिक उदाहरण हैं (संस्करणों में अंतर या उनके कटौती के साथ समस्याएं)।
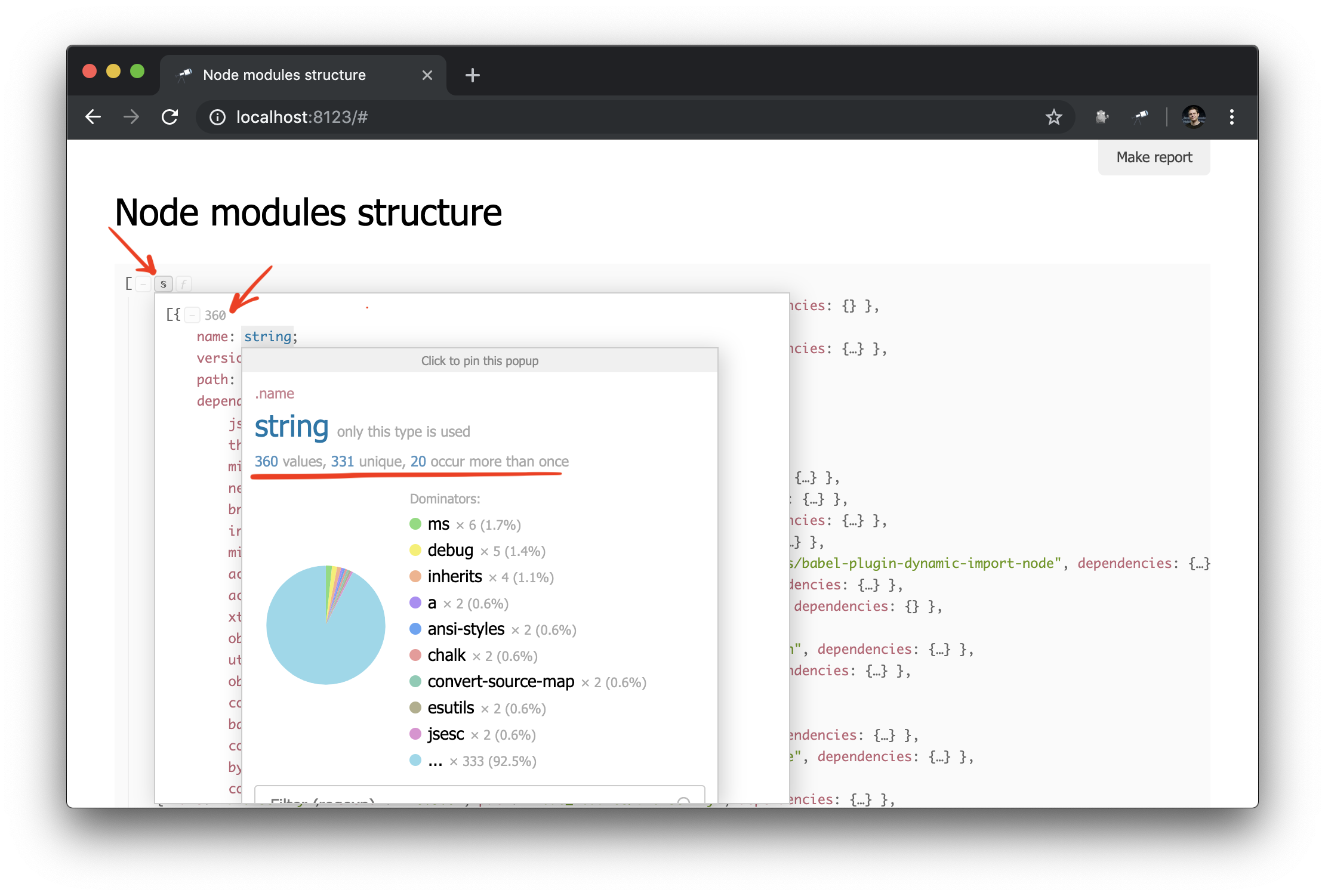
इस तथ्य के बावजूद कि हमारे पास पहले से ही कुछ डेटा है, हमें अधिक विवरण की आवश्यकता है। उदाहरण के लिए, यह जानना अच्छा होगा कि कौन सा भौतिक उदाहरण किसी विशेष मॉड्यूल की घोषित निर्भरता में से प्रत्येक को हल करता है। हालांकि, डेटा निष्कर्षण में सुधार पर काम इस गाइड के दायरे से परे है। इसलिए, हम डेटा को पुनः प्राप्त करने और पैकेज के बारे में आवश्यक विवरण प्राप्त करने के लिए इसे @discoveryjs/node-modules पैकेज (जो @discoveryjs/scan-fs पर भी आधारित है) से बदल देंगे। परिणामस्वरूप, collect-node-modules-data.js बहुत सरल किया जाता है:
const fetchNodeModules = require('@discoveryjs/node-modules'); module.exports = function() { return fetchNodeModules(); };
अब node_modules बारे में जानकारी इस प्रकार है:
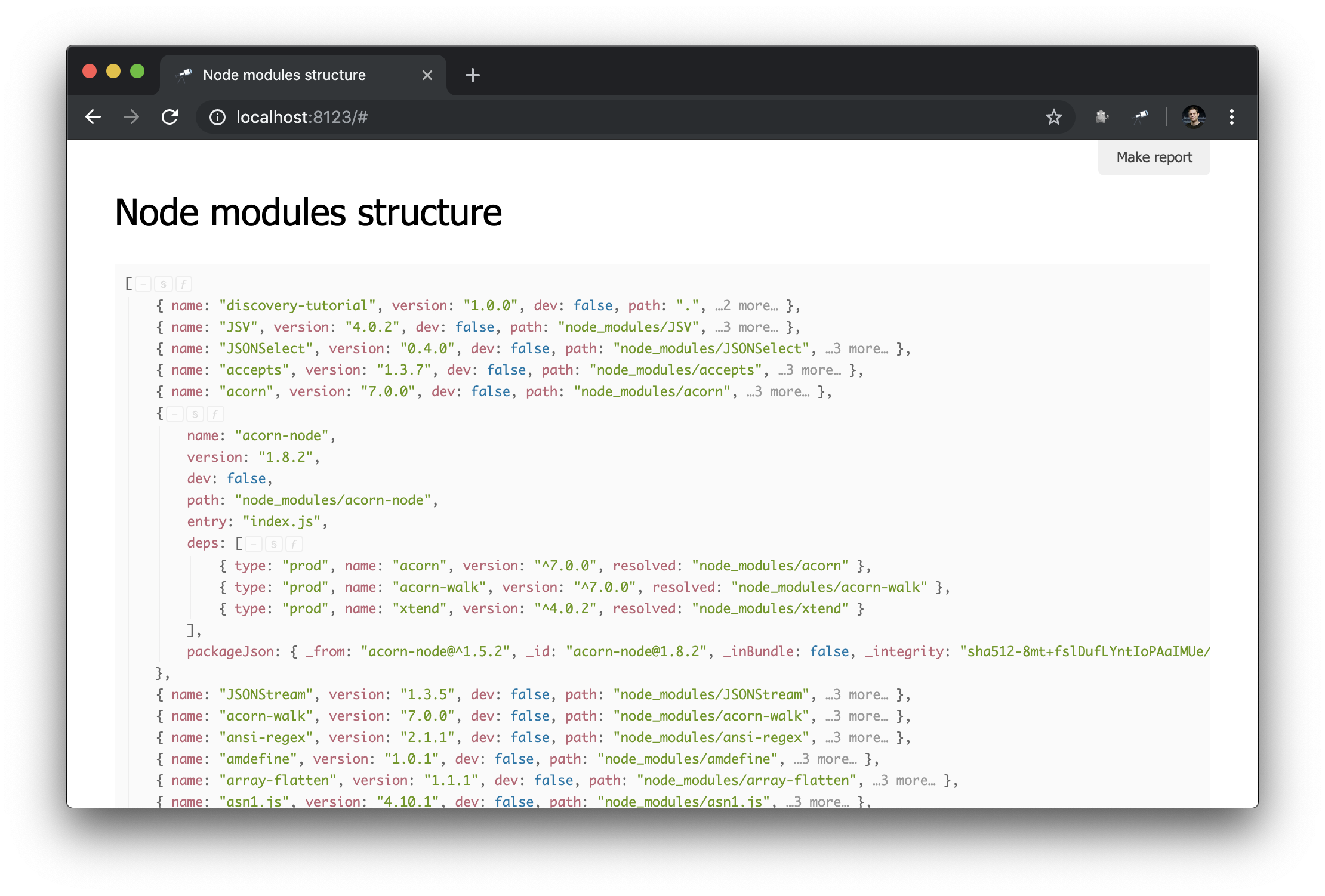
स्क्रिप्ट तैयार करना
जैसा कि आपने देखा होगा, पैकेजों का वर्णन करने वाली कुछ वस्तुओं में deps होते हैं - निर्भरता की सूची। प्रत्येक निर्भरता में एक resolved क्षेत्र होता है जिसका मूल्य पैकेज के भौतिक उदाहरण का संदर्भ होता है। इस तरह के लिंक में से एक पैकेज का path मूल्य है, यह अद्वितीय है। पैकेज के लिंक को हल करने के लिए, आपको अतिरिक्त कोड (उदाहरण के लिए, #.data.pick(<path=resolved>) का उपयोग करने की आवश्यकता है। और निश्चित रूप से, यह बहुत सुविधाजनक होगा यदि इस तरह के लिंक पहले से ही वस्तु संदर्भों में हल किए गए थे।
दुर्भाग्य से, डेटा संग्रह के चरण में, हम लिंक को हल नहीं कर सकते हैं, क्योंकि यह परिपत्र कनेक्शन को जन्म देगा, जो JSON के रूप में इस तरह के डेटा को स्थानांतरित करने की समस्या पैदा करेगा। हालांकि, एक समाधान है: यह एक विशेष prepare स्क्रिप्ट है। इसे कॉन्फ़िगरेशन में परिभाषित किया गया है और हर बार एक नया डेटा डिस्कवरी उदाहरण को सौंपा जाता है। चलो विन्यास के साथ शुरू करते हैं:
module.exports = { ... prepare: __dirname + '/prepare.js',
prepare.js परिभाषित करें।
discovery.setPrepare(function(data) {
इस मॉड्यूल में, हमने डिस्कवरी उदाहरण के लिए prepare फ़ंक्शन को परिभाषित किया। डिस्कवरी उदाहरण में डेटा लगाने से पहले हर बार इस फ़ंक्शन को कहा जाता है। वस्तु संदर्भों में मूल्यों को अनुमति देने के लिए यह एक अच्छी जगह है:
discovery.setPrepare(function(data) { const packageIndex = data.reduce((map, pkg) => map.set(pkg.path, pkg), new Map()); data.forEach(pkg => pkg.deps.forEach(dep => dep.resolved = packageIndex.get(dep.resolved) ) ); });
यहां हमने एक पैकेज इंडेक्स बनाया है जिसमें कुंजी पैकेज path मूल्य (अद्वितीय) है। फिर हम सभी पैकेज और उनकी निर्भरता से गुजरते हैं, और निर्भरता में हम पैकेज ऑब्जेक्ट के संदर्भ में resolved मूल्य को प्रतिस्थापित करते हैं। परिणाम:
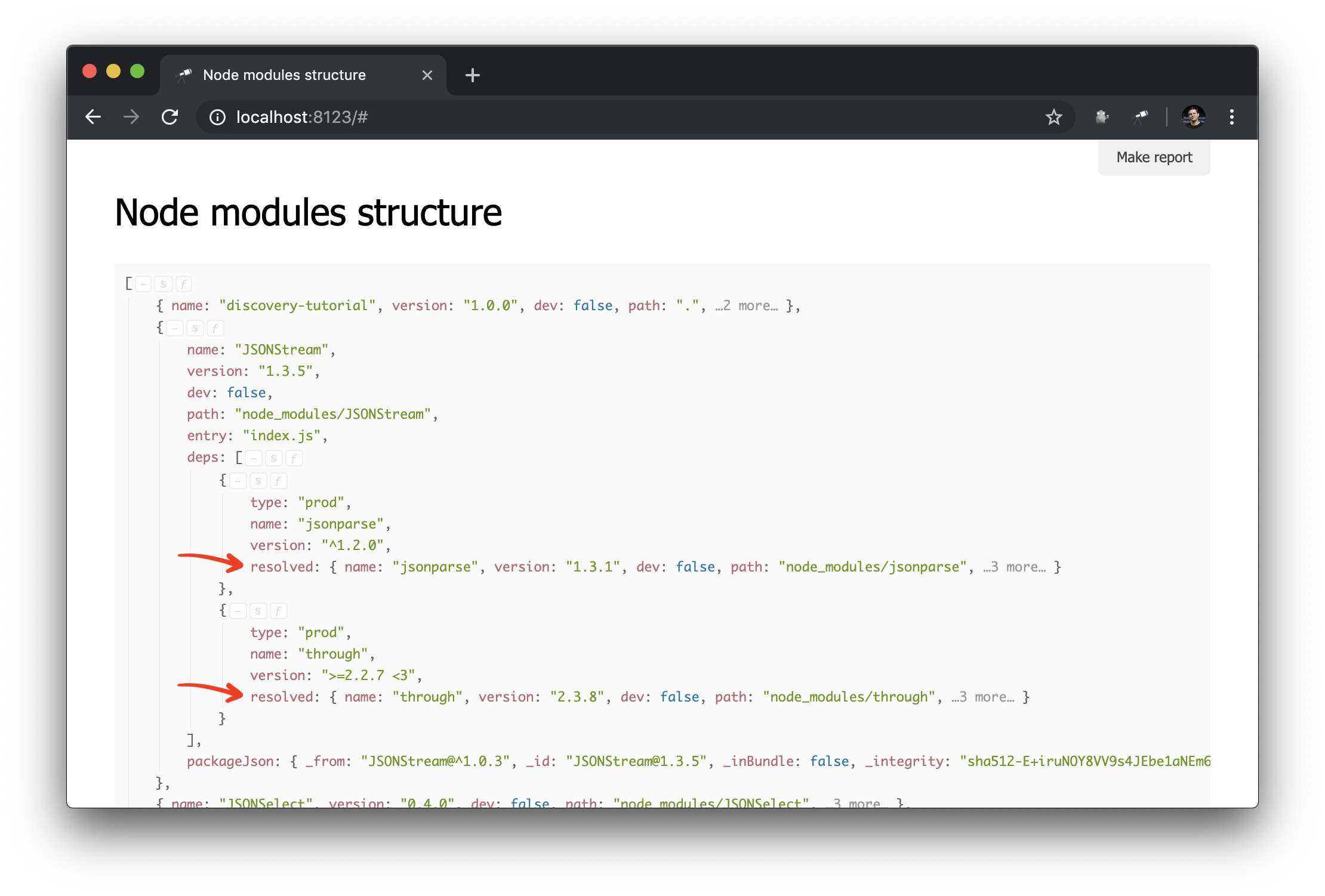
अब निर्भरता ग्राफ प्रश्नों को बनाना बहुत आसान है। यह है कि आप एक विशिष्ट पैकेज के लिए निर्भरता (यानी निर्भरता, निर्भरता निर्भरता, आदि) का एक समूह कैसे प्राप्त कर सकते हैं:
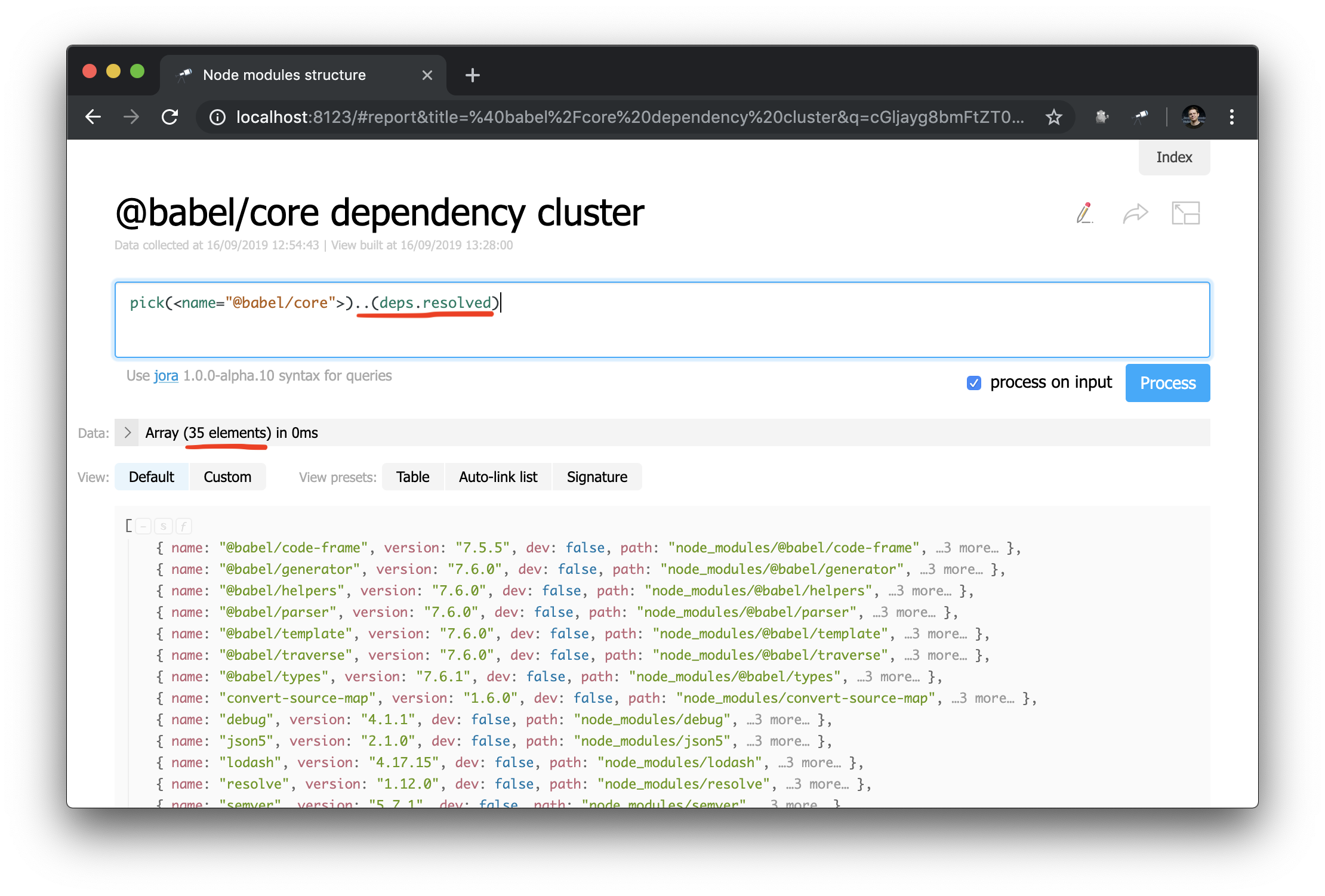
एक अप्रत्याशित सफलता की कहानी: मैनुअल लिखने के दौरान डेटा का अध्ययन करते समय, मैंने @discoveryjs/cli .[deps.[not resolved]] @discoveryjs/cli (क्वेरी का उपयोग करके एक समस्या की @discoveryjs/cli .[deps.[not resolved]] ), जिसकी सहकर्मी निर्भरता में एक टाइपो था। समस्या तुरंत ठीक हो गई थी । मामला इस बात का एक अच्छा उदाहरण है कि ऐसे उपकरण कैसे मदद करते हैं।
शायद प्रारंभ पृष्ठ पर कई नंबरों और पैकेजों के साथ दिखाने का समय आ गया है।
प्रारंभ पृष्ठ को अनुकूलित करें
सबसे पहले, हमें एक पेज मॉड्यूल बनाने की जरूरत है, उदाहरण के लिए, pages/default.js । हम default उपयोग करते हैं, क्योंकि यह प्रारंभ पृष्ठ के लिए पहचानकर्ता है, जिसे हम (Discovery.js में, आप बहुत अधिक ओवरराइड कर सकते हैं) ओवरराइड कर सकते हैं। आइए कुछ सरल से शुरू करें, उदाहरण के लिए:
discovery.page.define('default', [ 'h1:#.name', 'text:"Hello world!"' ]);
अब कॉन्फ़िगरेशन में आपको पृष्ठ मॉड्यूल कनेक्ट करने की आवश्यकता है:
module.exports = { name: 'Node modules structure', data: require('./collect-node-modules-data'), view: { assets: [ 'pages/default.js'
ब्राउज़र में जांचें:
यह काम करता है!
चलिए अब कुछ काउंटर मिलते हैं। ऐसा करने के लिए, pages/default.js परिवर्तन करें:
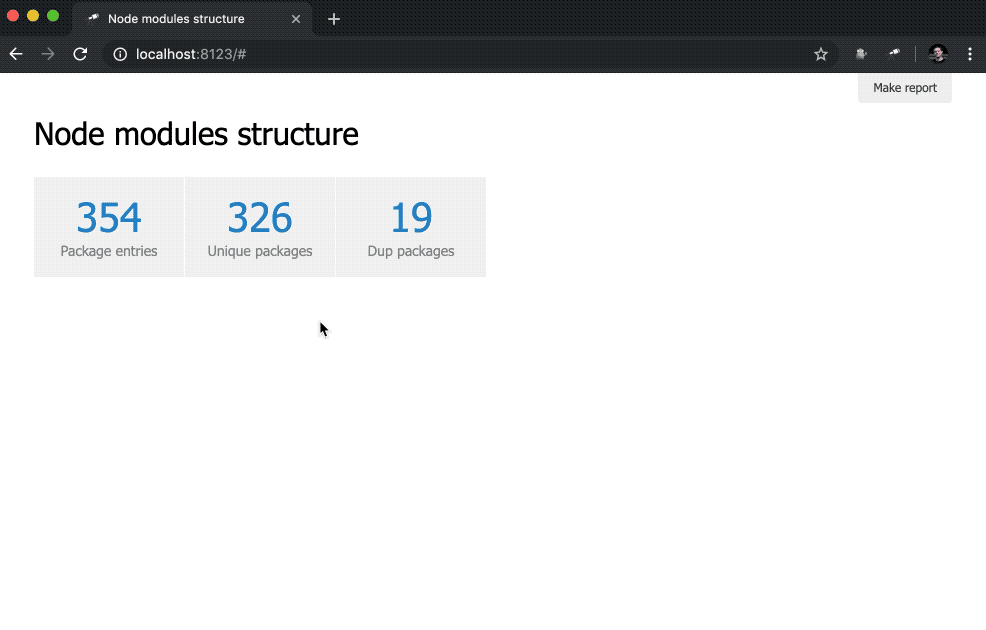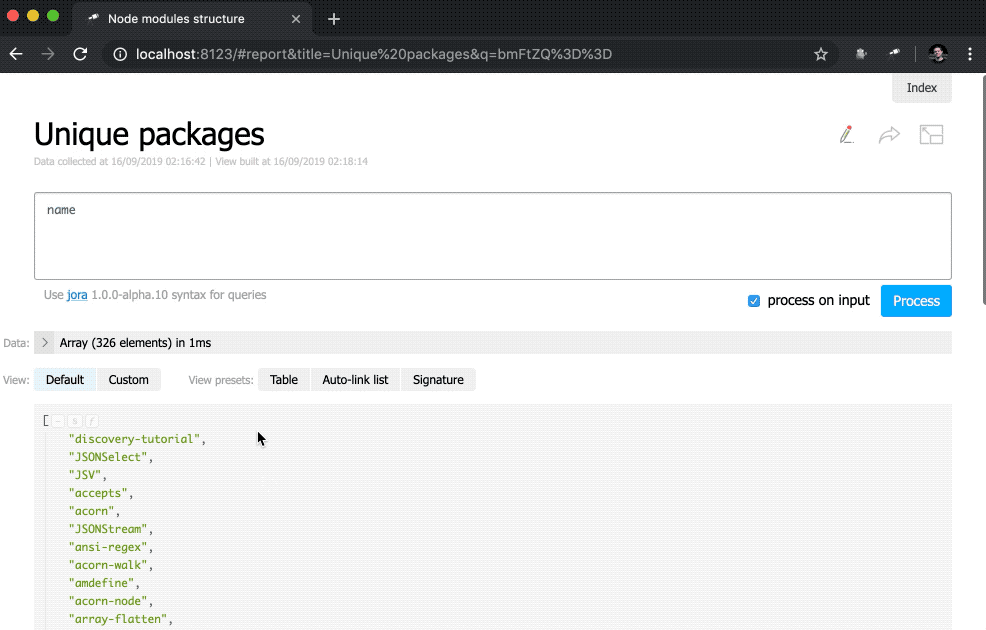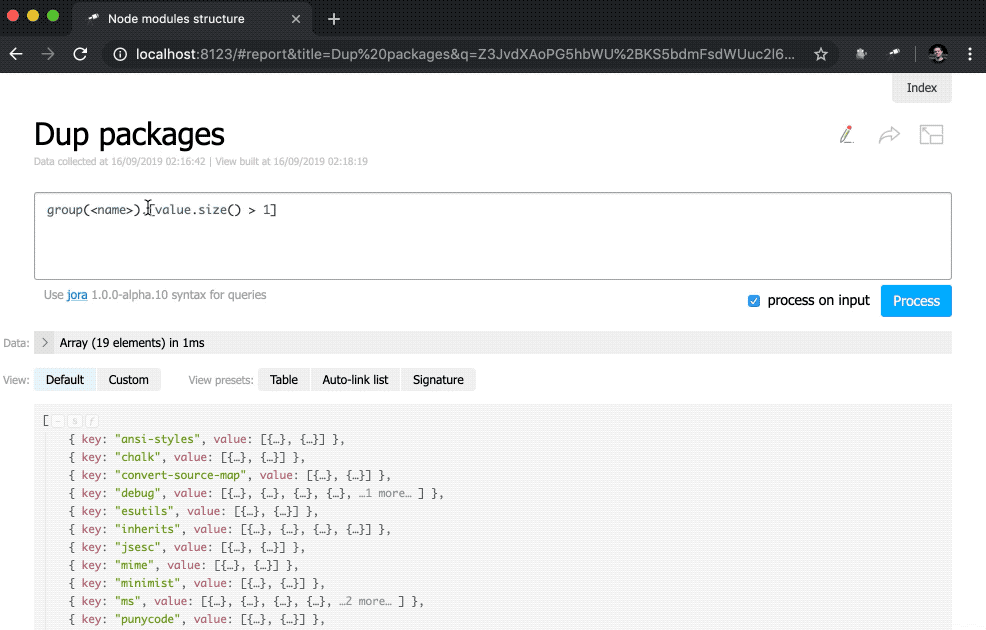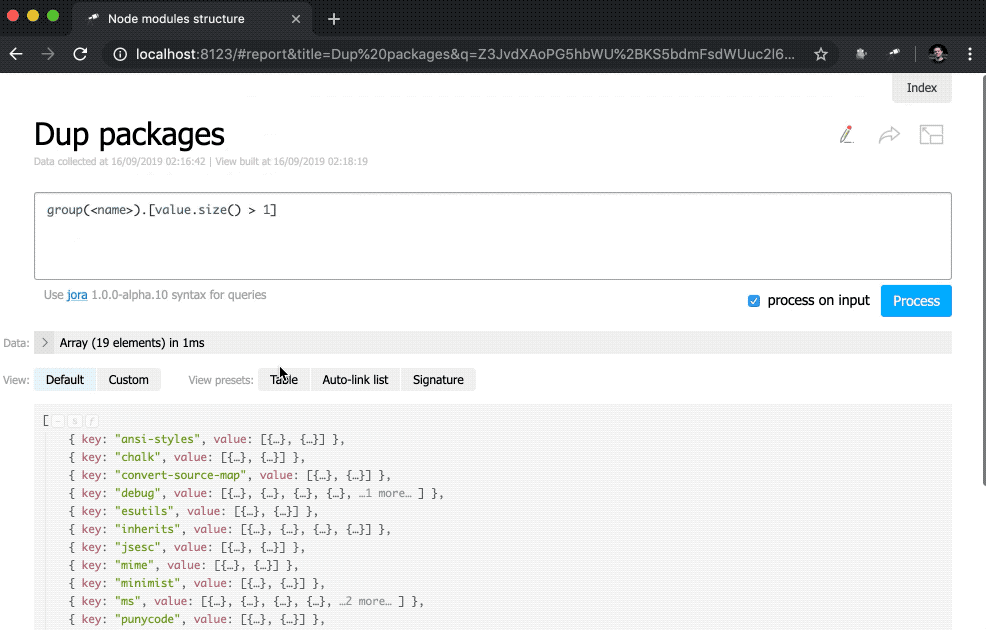
discovery.page.define('default', [ 'h1:#.name', { view: 'inline-list', item: 'indicator', data: `[ { label: 'Package entries', value: size() }, { label: 'Unique packages', value: name.size() }, { label: 'Dup packages', value: group(<name>).[value.size() > 1].size() } ]` } ]);
यहां हम संकेतकों की एक इनलाइन सूची को परिभाषित करते हैं। data मान एक जोरा क्वेरी है जो रिकॉर्ड की एक सरणी बनाता है। संकुल की सूची (डेटा रूट) का उपयोग प्रश्नों के आधार के रूप में किया जाता है, इसलिए हमें सूची की लंबाई ( size() ), अद्वितीय पैकेज नामों की संख्या ( name.size() ) और डुप्लिकेट वाले पैकेज नामों की संख्या ( group(<name>).[value.size() > 1].size() name.size() ) name.size() group(<name>).[value.size() > 1].size() )।
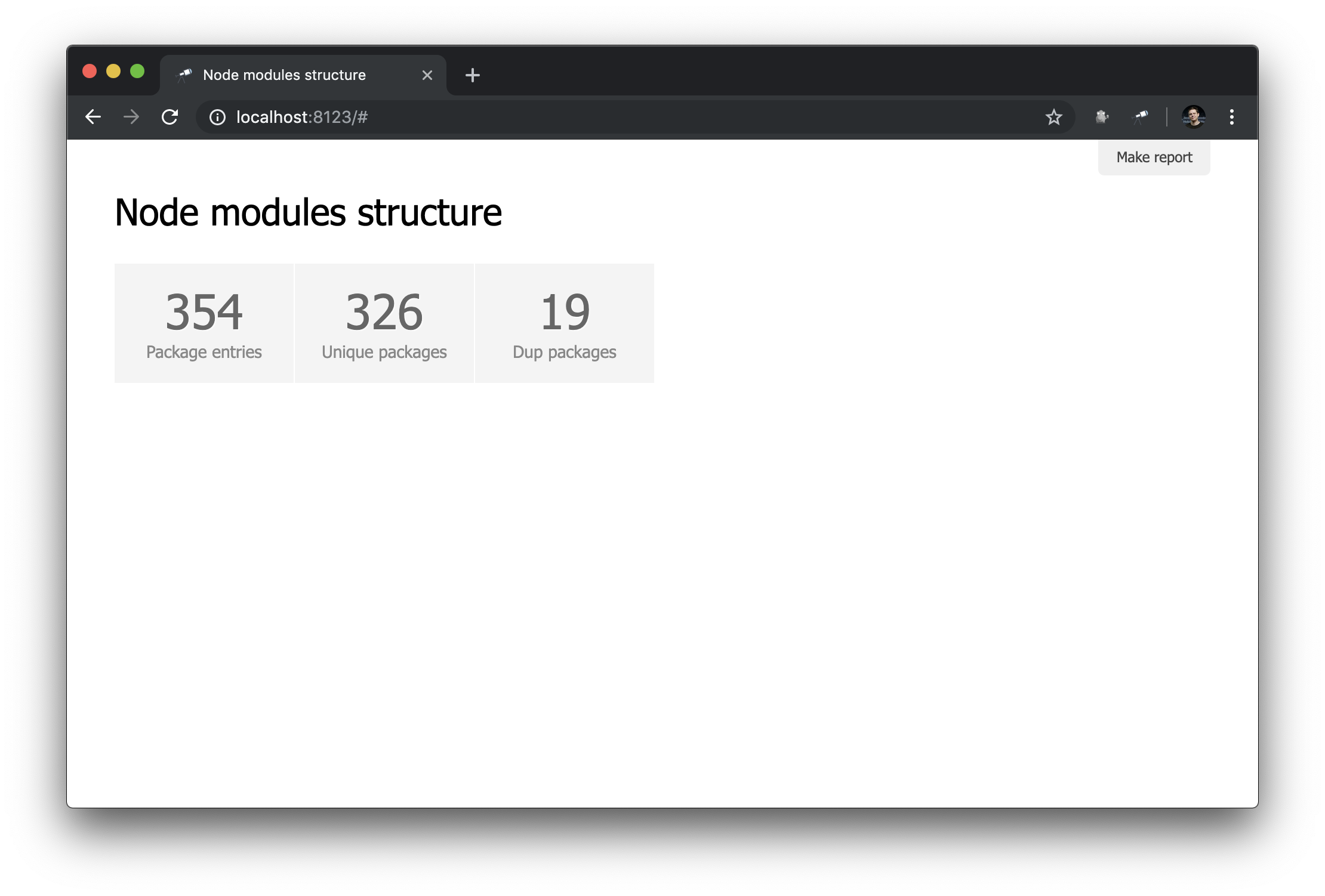
बुरा नहीं है। फिर भी, संख्याओं के अलावा, संबंधित नमूनों से लिंक होना बेहतर होगा:
discovery.page.define('default', [ 'h1:#.name', { view: 'inline-list', data: [ { label: 'Package entries', value: '' }, { label: 'Unique packages', value: 'name' }, { label: 'Dup packages', value: 'group(<name>).[value.size() > 1]' } ], item: `indicator:{ label, value: value.query(#.data, #).size(), href: pageLink('report', { query: value, title: label }) }` } ]);
सबसे पहले, हमने data के मूल्य को बदल दिया, अब यह कुछ वस्तुओं के साथ एक नियमित सरणी है। साथ ही, size() पद्धति को मूल्य अनुरोधों से हटा दिया गया है।
इसके अलावा, indicator दृश्य में एक उप-वर्ग जोड़ा गया है। इस प्रकार के प्रश्न प्रत्येक तत्व के लिए एक नई वस्तु बनाते हैं जिसमें value और href की गणना की जाती है। value , query() विधि का उपयोग करके एक क्वेरी निष्पादित की जाती है, जिसमें डेटा को संदर्भ से स्थानांतरित किया जाता है, और फिर क्वेरी परिणाम पर size() पद्धति लागू की जाती है। pageLink() लिए, pageLink() विधि का उपयोग किया जाता है, जो एक विशिष्ट अनुरोध और हेडर के साथ रिपोर्ट पेज का लिंक उत्पन्न करता है। इन सभी परिवर्तनों के बाद, संकेतक क्लिक करने योग्य हो गए (ध्यान दें कि उनके मूल्य नीले हो गए हैं) और अधिक कार्यात्मक।
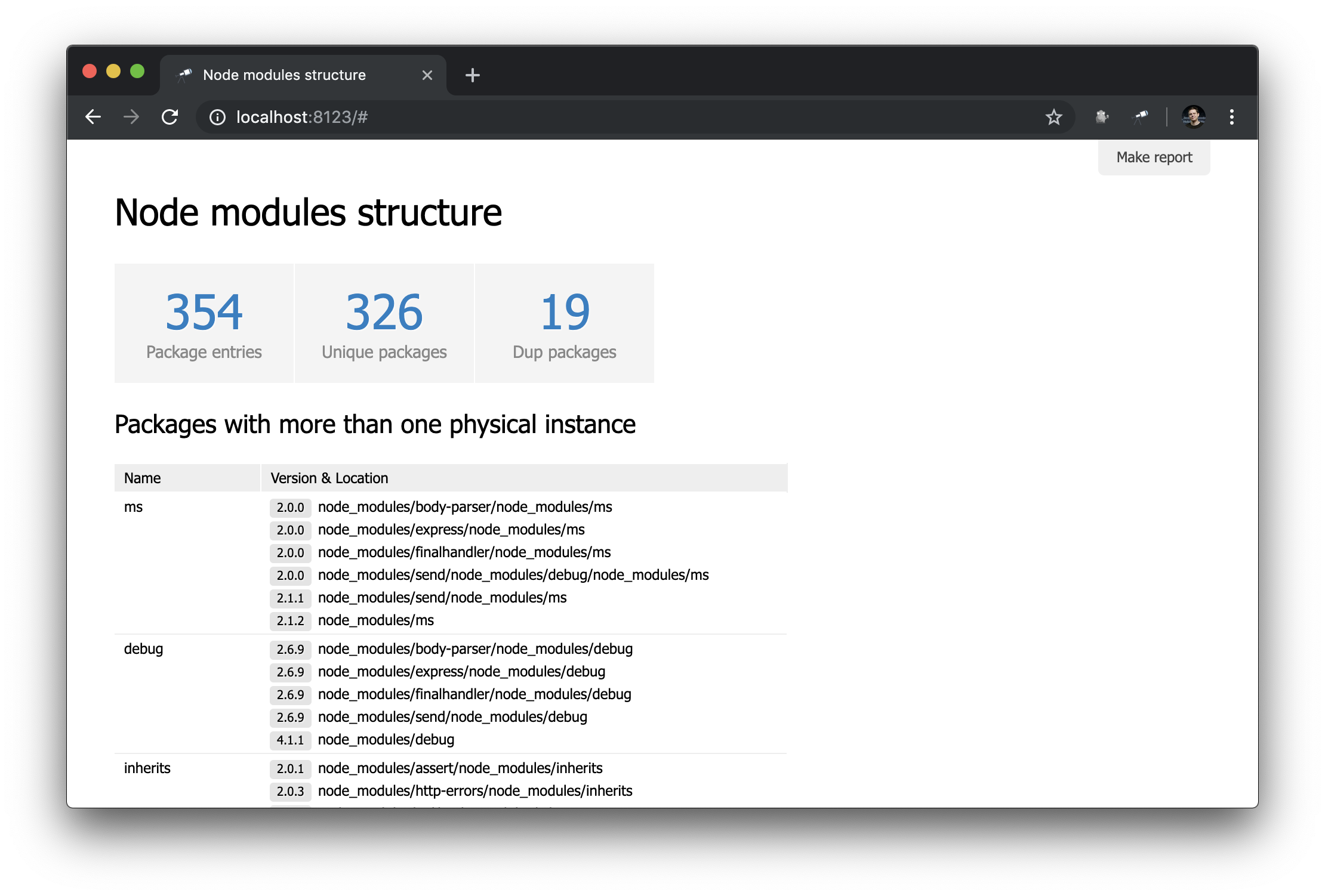
प्रारंभ पृष्ठ को अधिक उपयोगी बनाने के लिए, डुप्लिकेट वाले पैकेजों के साथ एक तालिका जोड़ें।
discovery.page.define('default', [
तालिका उसी डेटा का उपयोग करती है जैसे कि Dup packages इंडिकेटर। संकुल की सूची को समूह आकार द्वारा उल्टे क्रम में क्रमबद्ध किया गया था। शेष सेटअप कॉलम से संबंधित है (वैसे, आमतौर पर उन्हें ट्यून करने की आवश्यकता नहीं होती है)। Version & Location कॉलम के लिए, हमने एक नेस्टेड सूची (संस्करण द्वारा क्रमबद्ध) को परिभाषित किया है, जिसमें प्रत्येक तत्व संस्करण संख्या और उदाहरण के लिए पथ की एक जोड़ी है।
पैकेज पृष्ठ
अब हमारे पास संकुल का केवल एक सामान्य अवलोकन है। लेकिन किसी विशेष पैकेज के बारे में विवरण के साथ एक पृष्ठ होना उपयोगी होगा। ऐसा करने के लिए, एक नया मॉड्यूल pages/package.js बनाएँ pages/package.js और एक नया पृष्ठ परिभाषित करें:
discovery.page.define('package', { view: 'context', data: `{ name: #.id, instances: .[name = #.id] }`, content: [ 'h1:name', 'table:instances' ] });
इस मॉड्यूल में, हमने पहचानकर्ता package साथ पृष्ठ को परिभाषित किया। प्रारंभिक घटक के रूप में context घटक का उपयोग किया गया था। यह एक गैर-दृश्य घटक है जो आपको नेस्टेड मैपिंग के लिए डेटा को परिभाषित करने में मदद करता है। ध्यान दें कि हमने पैकेज का नाम पाने के लिए #.id का उपयोग किया था, जिसे इस http://localhost:8123/#package:{id} जैसे URL से पुनर्प्राप्त किया जाता है।
कॉन्फ़िगरेशन में नया मॉड्यूल शामिल करना न भूलें:
module.exports = { ... view: { assets: [ 'pages/default.js', 'pages/package.js'
ब्राउज़र में परिणाम:
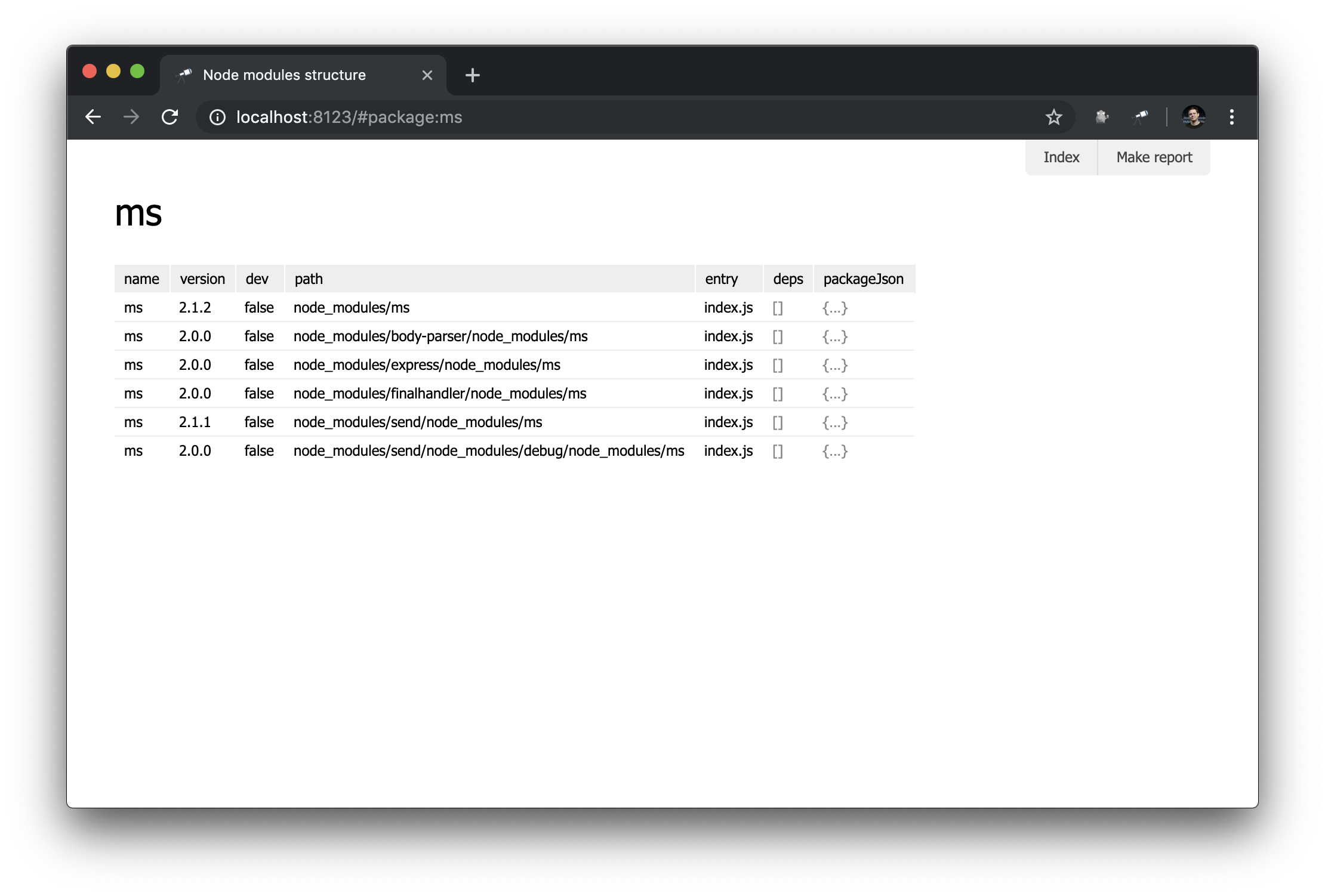
बहुत प्रभावशाली नहीं है, लेकिन अभी के लिए। हम बाद के मैनुअल में अधिक जटिल मैपिंग बनाएंगे।
साइड पैनल
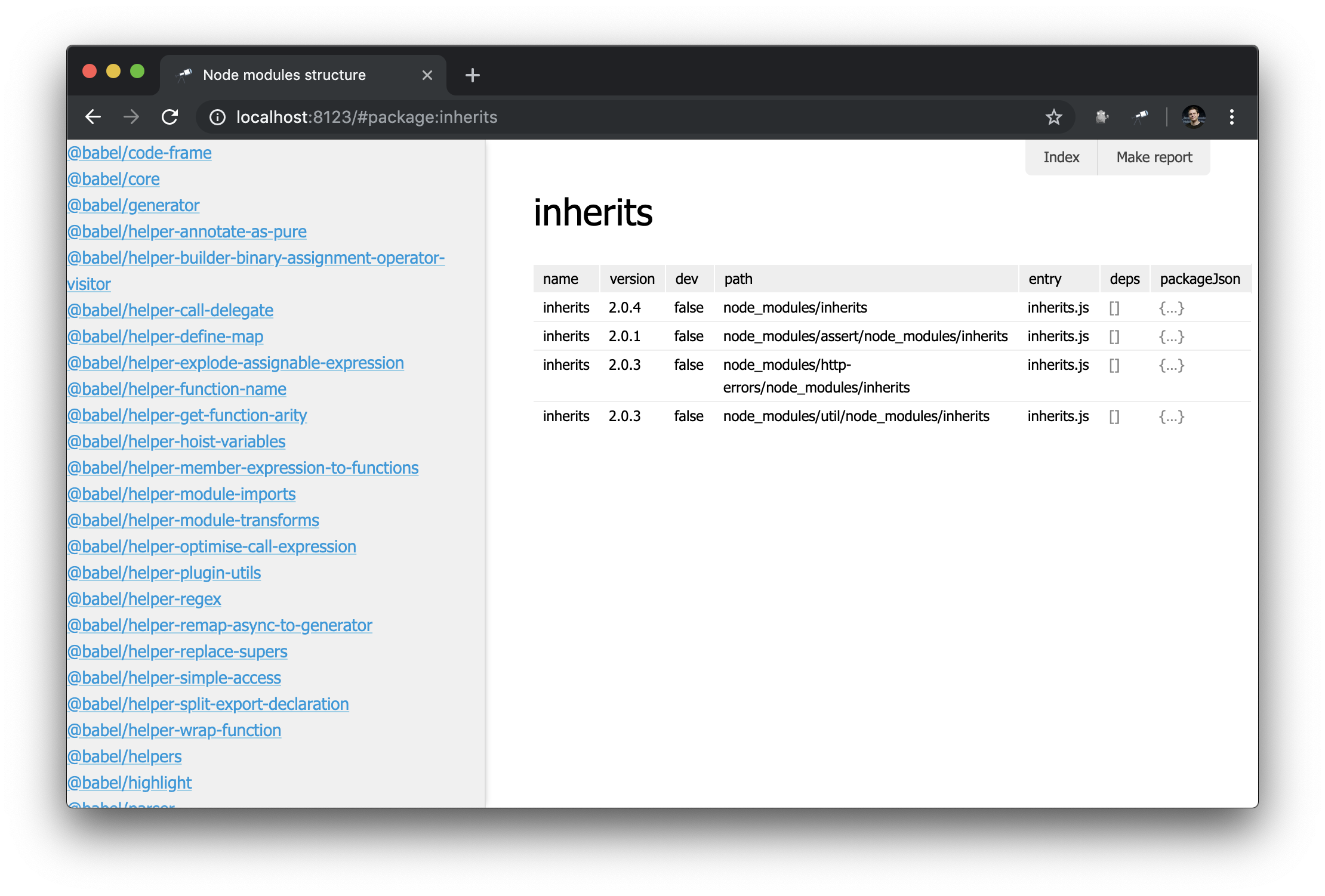
चूंकि हमारे पास पहले से ही एक पैकेज पृष्ठ है, इसलिए सभी पैकेजों की एक सूची रखना अच्छा होगा। ऐसा करने के लिए, आप एक विशेष दृश्य - sidebar को परिभाषित कर सकते हैं, जिसे प्रदर्शित किया जाता है यदि इसे परिभाषित किया गया है (डिफ़ॉल्ट रूप से परिभाषित नहीं किया गया है)। एक नया मॉड्यूल views/sidebar.js बनाएं। views/sidebar.js :
discovery.view.define('sidebar', { view: 'list', data: 'name.sort()', item: 'link:{ text: $, href: pageLink("package") }' });
अब हमारे पास सभी पैकेजों की एक सूची है:
यह अच्छा लग रहा है। लेकिन एक फिल्टर के साथ यह और भी बेहतर होगा। हम sidebar की परिभाषा का विस्तार करते हैं:
discovery.view.define('sidebar', { view: 'content-filter', content: { view: 'list', data: 'name.[no #.filter or $~=#.filter].sort()', item: { view: 'link', data: '{ text: $, href: pageLink("package"), match: #.filter }', content: 'text-match' } } });
यहां हमने सूची को एक content-filter घटक में लपेटा है जो इनपुट फ़ील्ड को नियमित अभिव्यक्तियों में इनपुट मान को परिवर्तित करता है (या यदि फ़ील्ड खाली है) तो इसे संदर्भ में filter मान के रूप में सहेजता है ( name विकल्प के साथ name बदला जा सकता है)। इसके अलावा, सूची के लिए डेटा को फ़िल्टर करने के लिए, हमने #.filter उपयोग किया। अंत में, हमने text-match साथ मिलान वाले हिस्सों को उजागर करने के लिए लिंक मैपिंग लागू किया। परिणाम:

यदि आपको डिफ़ॉल्ट डिज़ाइन पसंद नहीं है, तो आप अपनी इच्छानुसार शैलियों को अनुकूलित कर सकते हैं। मान लीजिए कि आप साइडबार की चौड़ाई बदलना चाहते हैं, इसके लिए आपको एक स्टाइल फाइल बनाने की आवश्यकता है (जैसे, views/sidebar.css ):
.discovery-sidebar { width: 300px; }
और कॉन्फ़िगरेशन में इस फ़ाइल के लिए एक लिंक जोड़ें, साथ ही जावास्क्रिप्ट मॉड्यूल:
module.exports = { ... view: { assets: [ ... 'views/sidebar.css',
स्वत: लिंक
इस गाइड का अंतिम अध्याय लिंक्स के लिए समर्पित है। इससे पहले, pageLink() विधि का उपयोग करते हुए, हमने पैकेज पेज के लिए एक लिंक बनाया। लेकिन लिंक के अलावा, आपको लिंक टेक्स्ट भी सेट करना होगा। लेकिन हम इसे कैसे आसान बनाएंगे?
लिंक के काम को सरल बनाने के लिए, हमें लिंक बनाने के लिए एक नियम को परिभाषित करने की आवश्यकता है। यह prepare स्क्रिप्ट में सबसे अच्छा किया जाता है:
discovery.setPrepare(function(data) { ... const packageIndex = data.reduce( (map, item) => map .set(item, item)
हमने पैकेजों का एक नया नक्शा (इंडेक्स) जोड़ा और इसे इकाई रिज़ॉल्वर के लिए उपयोग किया। इकाई रिज़ॉल्वर, यदि संभव हो, तो इसके लिए दिए गए मान को एक इकाई विवरणक में परिवर्तित करने की कोशिश करता है। वर्णनकर्ता में शामिल हैं:
type - इकाई प्रकारid - एक id रूप में लिंक में उपयोग की जाने वाली इकाई उदाहरण के लिए एक अद्वितीय संदर्भname - लिंक पाठ के रूप में उपयोग किया जाता है
अंत में, आपको इस प्रकार को एक विशिष्ट पृष्ठ पर निर्दिष्ट करने की आवश्यकता है (लिंक को कहीं और ले जाना चाहिए, सही?)।
discovery.page.define('package', { ... }, { resolveLink: 'package'
इन परिवर्तनों का पहला परिणाम यह है कि struct दृश्य में कुछ मान अब पैकेज पृष्ठ के लिंक के साथ चिह्नित हैं:
और अब आप auto-link घटक को किसी ऑब्जेक्ट या पैकेज के नाम पर भी लागू कर सकते हैं:
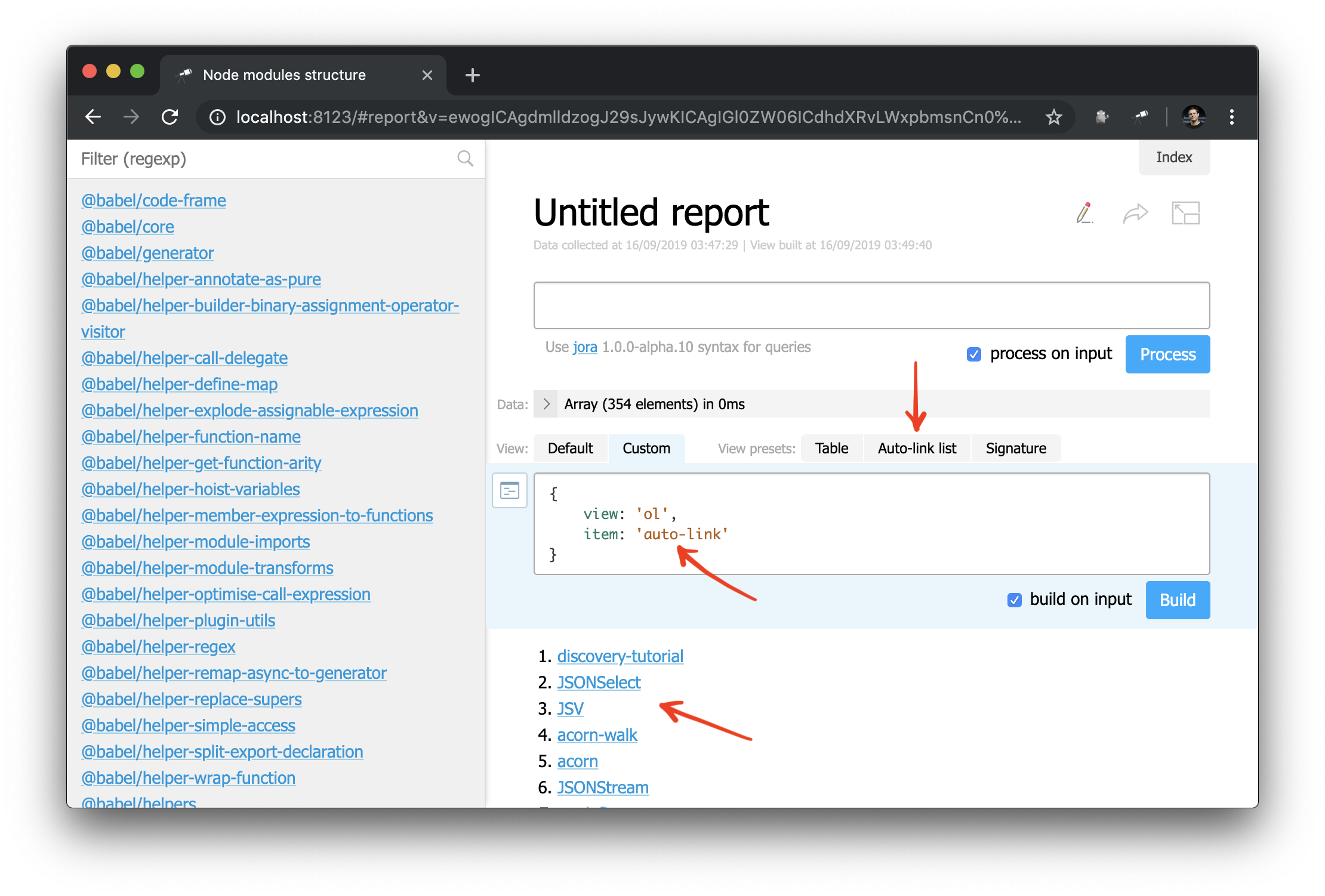
और, एक उदाहरण के रूप में, आप साइडबार को फिर से काम कर सकते हैं:
निष्कर्ष
अब आपको Discovery.js की प्रमुख अवधारणाओं की एक बुनियादी समझ है। निम्नलिखित गाइड में हम शामिल विषयों पर एक करीब से नज़र डालेंगे।
आप गाइड के संपूर्ण स्रोत कोड को GitHub पर रिपॉजिटरी में देख सकते हैं या कोशिश कर सकते हैं कि यह ऑनलाइन कैसे काम करता है ।
ताजा खबरों से बचने के लिए ट्विटर पर @js_discovery को फॉलो करें !