नमस्कार, हेब्र! सॉफ्टपॉइंट से हमारे दोस्तों ने माइक्रोसॉफ्ट एसक्यूएल सर्वर के बारे में एक दिलचस्प लेख तैयार किया है। यह पूर्ण-पाठ खोज का उपयोग करने के दो व्यावहारिक उदाहरण प्रस्तुत करता है:
- LIKE के माध्यम से एक नियमित खोज के विपरीत "अनंत" लाइनों (जैसे टिप्पणियाँ) में खोजें;
- उपसर्गों के साथ दस्तावेज़ संख्याओं द्वारा खोजें। जहां आमतौर पर पूर्ण-पाठ खोज का उपयोग नहीं किया जा सकता है: निरंतर उपसर्ग इसके साथ हस्तक्षेप करते हैं। 2 दृष्टिकोणों का विश्लेषण किया जाता है: दस्तावेज़ संख्या को प्रीप्रोसेस करना और अपना स्वयं का लाइब्रेरी-शब्द ब्रेकर जोड़ना।
अब सम्मिलित हों!
 मैं लेखक को मंजिल देता हूं
मैं लेखक को मंजिल देता हूंसंचित डेटा के गीगाबाइट में एक प्रभावी खोज लेखांकन प्रणालियों के "पवित्र ग्रिल" का एक प्रकार है। हर कोई उसे खोजना चाहता है और अमरता प्राप्त करना चाहता है, लेकिन बार-बार खोज करने की प्रक्रिया में यह पता चलता है कि कोई भी चमत्कारी उपाय नहीं है।
स्थिति इस तथ्य से जटिल है कि उपयोगकर्ता आमतौर पर एक विकल्प के लिए खोज करना चाहते हैं - कहीं न कहीं यह पता चलता है कि टिप्पणी के बीच में वांछित अनुबंध संख्या "दफन" है; कहीं न कहीं, ऑपरेटर को ग्राहक का नाम ठीक से याद नहीं है, लेकिन उसे याद आया कि उसका नाम "एलेक्सी एवरग्राफोविच" था; कहीं न कहीं, आपको बस BYUBL के स्वामित्व के आवर्ती रूप को छोड़ना होगा और संगठन के नाम से तुरंत खोजना होगा। क्लासिक रिलेशनल डीबीएमएस के लिए, इस तरह की खोज बहुत बुरी खबर है। सबसे अधिक बार, इस तरह के एक विकल्प की खोज तालिका की प्रत्येक पंक्ति के व्यवस्थित स्क्रॉलिंग तक कम हो जाती है। सबसे प्रभावी रणनीति नहीं, खासकर अगर तालिका का आकार कई टन गीगाबाइट तक बढ़ता है।
एक विकल्प की तलाश में, मैं अक्सर "पूर्ण-पाठ खोज" को याद करता हूं। एक समाधान खोजने की खुशी आमतौर पर मौजूदा अभ्यास की सरसरी समीक्षा के बाद जल्दी से गुजरती है। यह जल्दी से पता चला है कि, लोकप्रिय राय के अनुसार, पूर्ण पाठ खोज:
- कॉन्फ़िगर करना मुश्किल है
- धीरे-धीरे अपडेट किया गया
- अपडेट करते समय सिस्टम हैंग हो जाता है
- किसी प्रकार का
बेवकूफ असामान्य वाक्यविन्यास है - वे क्या पूछते हैं नहीं मिल रहा है
मिथकों के सेट को लंबे समय तक जारी रखा जा सकता है, लेकिन यहां तक कि प्लेटो ने हमें संदेह करना सिखाया और विश्वास पर किसी और की राय को आँख बंद करके स्वीकार नहीं किया। आइए देखें कि क्या शैतान इतना भयानक है कि वह चित्रित है?
और, जबकि हम अध्ययन में गहराई से डूबे नहीं हैं, हम
तुरंत एक महत्वपूर्ण शर्त पर सहमत होंगे । पूर्ण-पाठ खोज इंजन एक नियमित स्ट्रिंग खोज की तुलना में बहुत अधिक कर सकता है। उदाहरण के लिए, आप पर्यायवाची शब्द को परिभाषित कर सकते हैं और "फोन" खोजने के लिए "संपर्क" शब्द का उपयोग कर सकते हैं। या फार्म और एंडिंग के संबंध के बिना शब्दों की खोज करें। ये विकल्प उपयोगकर्ताओं के लिए बहुत उपयोगी हो सकते हैं, लेकिन इस लेख में हम पूर्ण-पाठ खोज को केवल क्लासिक लाइन खोज के विकल्प के रूप में मानते हैं। यही है,
हम केवल उन विकल्पों की खोज करेंगे जो खोज बार में निर्दिष्ट होंगे , बिना शब्दों के समानार्थी शब्द को ध्यान में रखते हुए, "सामान्य" रूप और अन्य जादू के लिए।
MS SQL Full Text Search कैसे काम करता है
MS SQL में पूर्ण-पाठ खोज कार्यक्षमता को मुख्य DBMS सेवा से आंशिक रूप से हटा दिया गया है (लेख के अंत में हम देखेंगे कि यह अत्यंत उपयोगी क्यों हो सकता है)। खोज के लिए, सामान्य संतुलित पेड़ों के विपरीत, इसकी संरचना के साथ एक विशेष सूचकांक बनाया जाता है।
यह महत्वपूर्ण है कि एक पूर्ण-पाठ खोज सूचकांक बनाने के लिए, यह आवश्यक है कि कुंजी तालिका में एक अद्वितीय सूचकांक मौजूद हो, जिसमें केवल एक स्तंभ शामिल हो - यह इसकी पूर्ण-पाठ खोज है जिसका उपयोग तालिका पंक्तियों की पहचान करने के लिए किया जाएगा। अक्सर मेज पर पहले से ही प्राथमिक कुंजी पर ऐसा सूचकांक होता है, लेकिन कभी-कभी इसे अतिरिक्त रूप से बनाना होगा।
पूर्ण-पाठ खोज सूचकांक अतुल्यकालिक रूप से और लेनदेन से बाहर आबादी है। तालिका पंक्ति को बदलने के बाद, इसे प्रसंस्करण के लिए पंक्तिबद्ध किया जाता है। इंडेक्स को अपडेट करने की प्रक्रिया सभी स्ट्रिंग मानों को टेबल रो (पंक्ति) से प्राप्त करती है, जो इंडेक्स को "सब्स्क्राइब्ड" करती है, और उन्हें अलग-अलग शब्दों में तोड़ती है। इसके बाद, शब्दों को एक निश्चित "मानक" रूप में (उदाहरण के लिए, बिना समाप्ति के) कम किया जा सकता है, ताकि शब्द रूपों द्वारा खोज करना आसान हो। "स्टॉप वर्ड्स" को फेंक दिया जाता है (प्रस्ताव, लेख और अन्य शब्द जो अर्थ नहीं ले जाते हैं)। शेष वर्ड-टू-स्ट्रिंग लिंक मैच पूर्ण-पाठ खोज सूचकांक में लिखे गए हैं।
यह पता चला है कि सूचकांक में शामिल तालिका का प्रत्येक स्तंभ इस तरह की पाइपलाइन से गुजरता है:
लंबी लाइन -> वर्डब्रेकर -> भागों का सेट (शब्द) -> स्टेमर -> सामान्यीकृत शब्द -> [वैकल्पिक] शब्द अपवाद को रोकें -> इंडेक्स को लिखें
जैसा कि उल्लेख किया गया है, सूचकांक अद्यतन प्रक्रिया अतुल्यकालिक है। यह इस प्रकार है:
- अद्यतन उपयोगकर्ता कार्यों को ब्लॉक नहीं करता है
- अद्यतन पंक्ति परिवर्तन लेन-देन के पूरा होने की प्रतीक्षा करता है और परिवर्तनों को पहले की तुलना में लागू करने के लिए शुरू होता है
- पूर्ण-पाठ सूचकांक में परिवर्तन मुख्य लेनदेन के सापेक्ष कुछ देरी के साथ लागू होते हैं। यही है, एक पंक्ति को जोड़ने और उस क्षण के बीच जब इसे पाया जा सकता है, सूचकांक अद्यतन कतार की लंबाई के आधार पर देरी होगी
- सूचकांक में शामिल तत्वों की संख्या की निगरानी क्वेरी द्वारा की जा सकती है:
SELECT cat.name, FULLTEXTCATALOGPROPERTY(cat.name,'ItemCount') AS [ItemCount] FROM sys.fulltext_catalogs AS cat
व्यावहारिक परीक्षण। भौतिक के लिए खोजें नाम से व्यक्ति
डेटा के साथ तालिका भरना
प्रयोगों के लिए, हम एक तालिका के साथ एक नया खाली आधार बनाएंगे जहाँ "प्रतिपक्ष" संग्रहीत किया जाएगा। "विवरण" फ़ील्ड के अंदर अनुबंध के नाम के साथ एक पंक्ति होगी, जहां प्रतिपक्ष के नाम का उल्लेख किया जाएगा। कुछ इस तरह:
"बोरोविक डमीसन एमिलानोविच के साथ अनुबंध"
या तो:
"डॉग। बोरोविक-रोमानोव अनातोली एवडीविच के साथ "
हां, मैं खुद को इस तरह के "आर्किटेक्चर" से तुरंत दूर करना चाहता हूं, लेकिन, दुर्भाग्य से, "टिप्पणियों" या "विवरण" का ऐसा अनुप्रयोग अक्सर व्यावसायिक उपयोगकर्ताओं के बीच होता है।
इसके अतिरिक्त, हम "वजन के लिए" कुछ फ़ील्ड जोड़ते हैं: यदि तालिका में केवल 2 कॉलम हैं, तो एक साधारण स्कैन इसे क्षणों में पढ़ेगा। हमें टेबल को "फुला" करने की आवश्यकता है ताकि स्कैन लंबा हो। यह हमें वास्तविक व्यावसायिक मामलों के करीब लाता है: हम न केवल तालिका में "विवरण" को संग्रहीत करते हैं, बल्कि कई अन्य [शैतान] उपयोगी जानकारी भी संग्रहीत करते हैं।
create table partners (id bigint identity (1,1) not null, [description] nvarchar(max), [address] nvarchar(256) not null default N'107240, , ., 168', [phone] nvarchar(256) not null default N'+7 (495) 111-222-33', [contact_name] nvarchar(256) not null default N'', [bio] nvarchar(2048) not null default N' . , , . , . , . , , , , . . , , . , , . , , , . , , . . .') -- , ..
अगला सवाल यह है कि इतने अनूठे अंतिम नाम, पहले नाम और संरक्षक कैसे प्राप्त करें? मैं, एक पुरानी आदत के अनुसार, एक सामान्य रूसी छात्र के रूप में कार्य करता था, अर्थात्। विकिपीडिया पर गया:
- पृष्ठ से लिए गए नाम श्रेणी: रूसी पुरुष नाम
- नामों के बीच से मध्य नामों को मैन्युअल रूप से फिर से लिखना, अंत बदलना
- उपनामों के साथ यह थोड़ा और जटिल हो गया। अंत में, "नाम" श्रेणी मिली। पायथन के साथ और एक अलग तालिका में थोड़ा शर्मिंदगी 46.5 हजार नामों से पता चला। (उपनाम डाउनलोड करने के लिए एक स्क्रिप्ट यहाँ उपलब्ध है)
बेशक, उपनामों में अजीब भिन्नताएं थीं, लेकिन अध्ययन के प्रयोजनों के लिए यह काफी स्वीकार्य था।
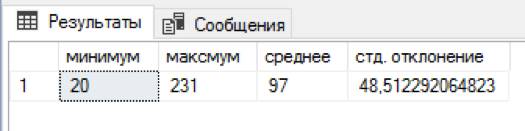
मैंने एक एसक्यूएल स्क्रिप्ट लिखी है जो प्रत्येक अंतिम नाम के लिए यादृच्छिक संख्या में नाम और संरक्षक की भूमिका निभाती है। 5 मिनट की प्रतीक्षा और एक अलग तालिका में पहले से ही 4.5 मिलियन संयोजन थे। बुरा नहीं है! प्रत्येक उपनाम के लिए नाम + मध्य नाम के 20 से 231 संयोजन थे, औसतन 97 संयोजन प्राप्त हुए थे। नाम और पेट्रोनामिक द्वारा वितरण "बाईं ओर" थोड़ा पक्षपाती हो गया, लेकिन यह अधिक संतुलित एल्गोरिदम के साथ आने के लिए बेमानी लग रहा था।
डेटा तैयार है, हम अपने प्रयोग शुरू कर सकते हैं।
पूर्ण पाठ खोज सेटअप
MS SQL लेवल पर एक फुल-टेक्स्ट इंडेक्स बनाएं। पहले हमें इस सूचकांक के लिए एक रिपॉजिटरी बनाने की आवश्यकता है - एक पूर्ण-पाठ कैटलॉग।
USE [like_vs_fulltext] GO CREATE FULLTEXT CATALOG [basic_ftc] WITH ACCENT_SENSITIVITY = OFF AS DEFAULT AUTHORIZATION [dbo] GO
एक कैटलॉग है, हम अपनी तालिका के लिए एक पूर्ण-पाठ इंडेक्स जोड़ने की कोशिश कर रहे हैं ... और कुछ भी काम नहीं करता है।
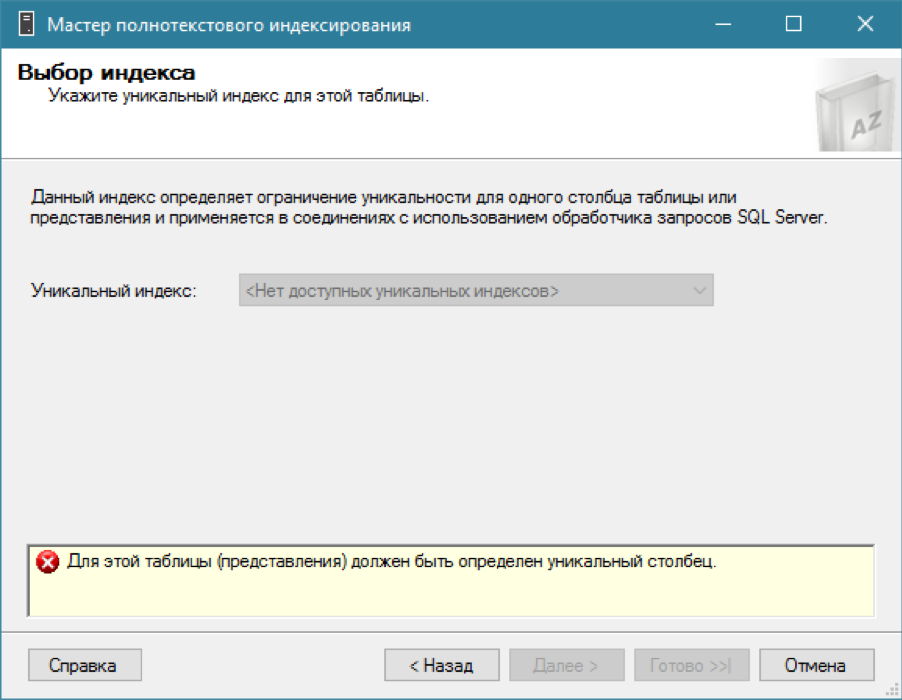
जैसा कि मैंने कहा, पूर्ण-पाठ सूचकांक के लिए आपको एक अद्वितीय कॉलम के साथ एक नियमित सूचकांक की आवश्यकता होती है। हमें याद है कि हमारे पास पहले से ही आवश्यक फ़ील्ड है - एक विशिष्ट पहचानकर्ता आईडी। आइए इस पर एक अद्वितीय क्लस्टर इंडेक्स बनाएं (हालांकि एक गैर-सूचीबद्ध एक ही पर्याप्त होगा):
create unique clustered index ndx1 on partners (id)
एक नया सूचकांक बनाने के बाद, हम अंत में पूर्ण-पाठ खोज सूचकांक जोड़ सकते हैं। जब तक सूचकांक पूरा नहीं हो जाता है, तब तक प्रतीक्षा करें (याद रखें कि इसे अतुल्यकालिक रूप से अपडेट किया गया है!)। आप परीक्षणों के लिए आगे बढ़ सकते हैं।
परीक्षण
आइए सबसे सरल परिदृश्य से शुरू करें, खोज के वास्तविक अनुप्रयोग के करीब। हम एक "सूची दृश्य" का अनुकरण करते हैं - खोज मास्क द्वारा चयन के साथ 45 लाइनों का एक विंडो चयन। हम एक नए पूर्ण-पाठ सूचकांक के साथ अनुरोध को निष्पादित करते हैं, हम समय - 0 सेकंड - उत्कृष्ट पर ध्यान देते हैं!
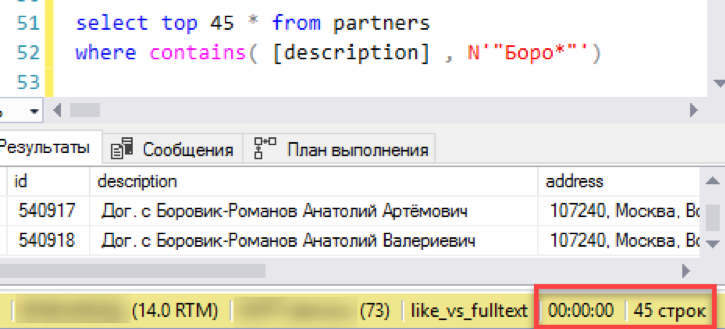
अब एक पुरानी, सिद्ध खोज के माध्यम से "जैसे।" परिणाम तैयार करने में 3 सेकंड का समय लगा। इतना बुरा नहीं, कुल हार से काम नहीं चला। शायद तब यह पूर्ण-पाठ खोज स्थापित करने के लिए कोई मतलब नहीं है - क्या सब कुछ ठीक काम करता है?
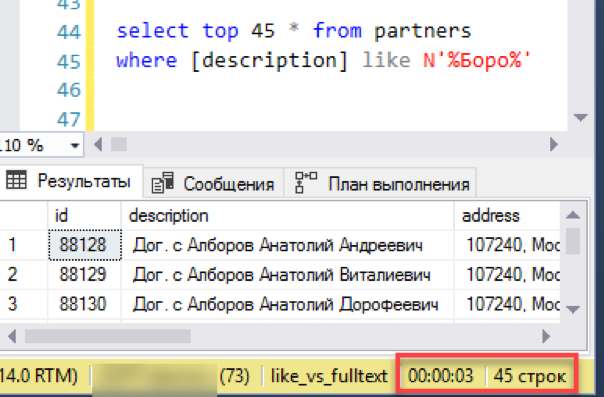
वास्तव में, हमने एक महत्वपूर्ण विवरण को याद किया: अनुरोध को बिना छांटे निष्पादित किया गया था। सबसे पहले, इस तरह के एक क्वेरी "पहले एन रिकॉर्ड का चयन" के साथ जोड़ा जाता है एक अनुचित परिणाम देता है। प्रत्येक शुरुआत यादृच्छिक एन रिकॉर्ड वापस कर सकती है और इस बात की कोई गारंटी नहीं है कि लगातार दो शुरुआत एक ही डेटा सेट देगी। दूसरे, अगर हम "स्लाइडिंग विंडो के साथ सूची देखने" के बारे में बात कर रहे हैं - आमतौर पर यह बहुत ही "विंडो" किसी भी कॉलम द्वारा सॉर्ट किया जाता है, उदाहरण के लिए, नाम से। आखिरकार, ऑपरेटर को यह जानना होगा कि जब वह अगले "खिड़की" पर जाएगा तो उसे क्या मिलेगा।
प्रयोग को ठीक करें। फ़ोन नंबर द्वारा सॉर्ट करना, कहना:
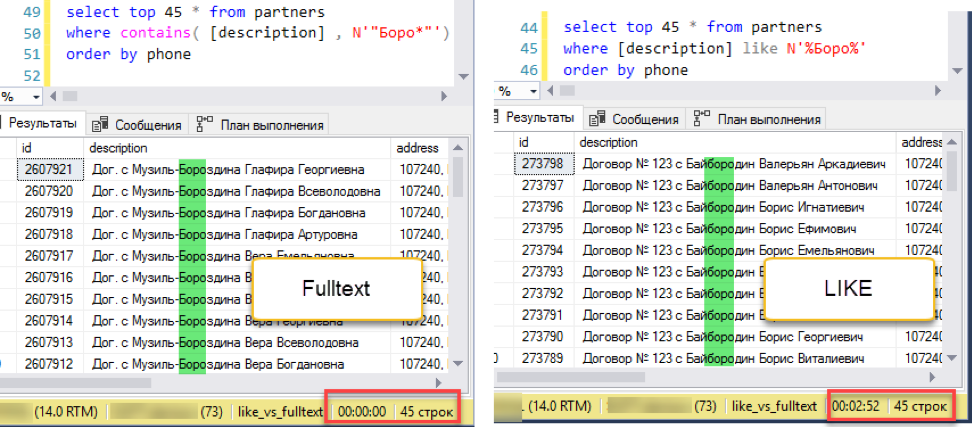 पूर्ण पाठ खोज एक बहरा स्कोर के साथ जीतता है: 0 सेकंड बनाम 172 सेकंड!
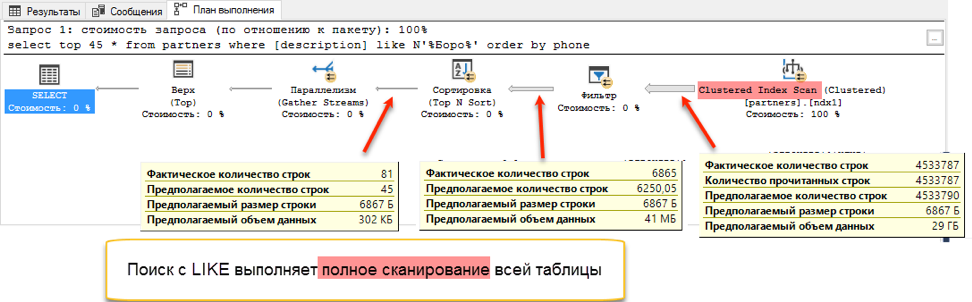
पूर्ण पाठ खोज एक बहरा स्कोर के साथ जीतता है: 0 सेकंड बनाम 172 सेकंड!यदि आप क्वेरी योजनाओं को देखते हैं, तो यह स्पष्ट हो जाता है कि ऐसा क्यों है। क्वेरी टेक्स्ट को ऑर्डर करने के अलावा निष्पादन के दौरान एक प्रकार का ऑपरेशन दिखाई दिया। यह तथाकथित "ब्लॉकिंग" ऑपरेशन है, जो तब तक अनुरोध को पूरा नहीं कर सकता है जब तक कि यह सॉर्टिंग के लिए पूरी मात्रा में डेटा प्राप्त नहीं करता है। हमारे पास पहले 45 रिकॉर्ड नहीं हैं, हमें पूरे डेटा सेट को सॉर्ट करना होगा।
और छँटाई के लिए डेटा प्राप्त करने के चरण में, एक नाटकीय अंतर होता है। "जैसे" के साथ एक खोज को संपूर्ण उपलब्ध तालिका के माध्यम से ब्राउज़ करना होगा। इसमें 172 सेकंड का समय लगता है। लेकिन पूर्ण-पाठ खोज की अपनी अनुकूलित संरचना है, जो तुरंत सभी आवश्यक प्रविष्टियों के लिंक लौटा देती है।
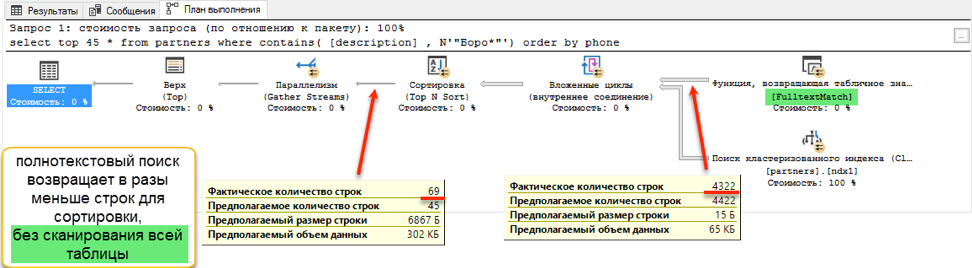
लेकिन क्या मरहम में एक मक्खी होना चाहिए? एक है। जैसा कि शुरुआत में कहा गया है, एक पूर्ण-पाठ खोज केवल एक शब्द की शुरुआत से खोज कर सकती है। और अगर हम "* ओक *" के विकल्प द्वारा "इवान पोड्डुबनी" खोजना चाहते हैं, तो एक पूर्ण-पाठ खोज कुछ भी उपयोगी नहीं दिखाएगी।
सौभाग्य से, नाम से खोज करने के लिए, यह सबसे लोकप्रिय परिदृश्य नहीं है।
किसी दस्तावेज़ को संख्या द्वारा खोजें
चलो कुछ और अधिक जटिल प्रयास करें। खोज के लिए दूसरा लोकप्रिय उपयोग मामला इसकी संख्या के हिस्से के द्वारा एक दस्तावेज ढूंढना है। इसके अलावा, अक्सर दस्तावेज़ संख्या में दो भाग होते हैं: अक्षर उपसर्ग और वास्तविक संख्या जिसमें प्रमुख शून्य होते हैं।
इन भागों के बीच कोई स्थान या सेवा वर्ण नहीं हैं। इसी समय, पूर्ण संख्या द्वारा खोज करना राक्षसी रूप से असुविधाजनक है - आपको यह याद रखना होगा कि उपसर्ग के बाद कितने अग्रणी शून्य महत्वपूर्ण भाग की शुरुआत से पहले होने चाहिए। यह पता चलता है कि पूर्ण-पाठ खोज "बॉक्स से बाहर" बस ऐसे परिदृश्य में बेकार है। चलो इसे ठीक करने की कोशिश करते हैं।
परीक्षण के लिए, मैंने दस्तावेज़ नामक एक नई तालिका बनाई, जिसमें मैंने "ओआरजी" प्रकार की अनूठी संख्या के साथ 13.5 मिलियन रिकॉर्ड जोड़े। क्रमांकन क्रम में चला गया, सभी संख्याएं "ओआरजी" से शुरू हुईं। आप शुरू कर सकते हैं।
एक नंबर को पूर्व-विभाजित करना
पूर्ण-पाठ खोज कुशलता से शब्दों की खोज कर सकती है। ठीक है, चलो उसकी मदद करें और अग्रिम रूप से "असुविधाजनक" संख्या को सुविधाजनक शब्दों में तोड़ दें। कार्य योजना इस प्रकार है:
- स्रोत तालिका में एक अतिरिक्त कॉलम जोड़ें जहां विशेष रूप से परिवर्तित संख्या संग्रहीत की जाएगी
- एक ट्रिगर जोड़ें, जो संख्या बदलने पर इसे कई छोटे भागों में तोड़ देगा, एक स्थान द्वारा अलग किया जाएगा
- पूर्ण-पाठ खोज पहले से ही जानती है कि रिक्त स्थान द्वारा स्ट्रिंग को भागों में कैसे विभाजित किया जाए, ताकि यह बिना किसी समस्या के हमारे संशोधित संख्या को अनुक्रमित करे
आइए देखें कि यह कैसे काम करेगा।
तालिका में एक अतिरिक्त कॉलम जोड़ें।
alter table document add number_parts nvarchar(128) not null default ''
एक नया कॉलम भरने वाले ट्रिगर को "माथे" लिखा जा सकता है, संभव डुप्लिकेट को अनदेखा करते हुए (कितने दोहराए जाने वाले ट्रिपल्स "0000012" हैं?) और आप कुछ XML जादू जोड़ सकते हैं और केवल अद्वितीय भागों को रिकॉर्ड कर सकते हैं। पहला कार्यान्वयन तेजी से होगा, दूसरा अधिक कॉम्पैक्ट परिणाम देगा। वास्तव में, चुनाव लिखने की गति और पढ़ने की गति के बीच है, यह चुनें कि आपकी स्थिति में क्या अधिक महत्वपूर्ण है। अब बस एक
स्क्रिप्ट के माध्यम से जाना जो मौजूदा संख्याओं को संसाधित करता है।
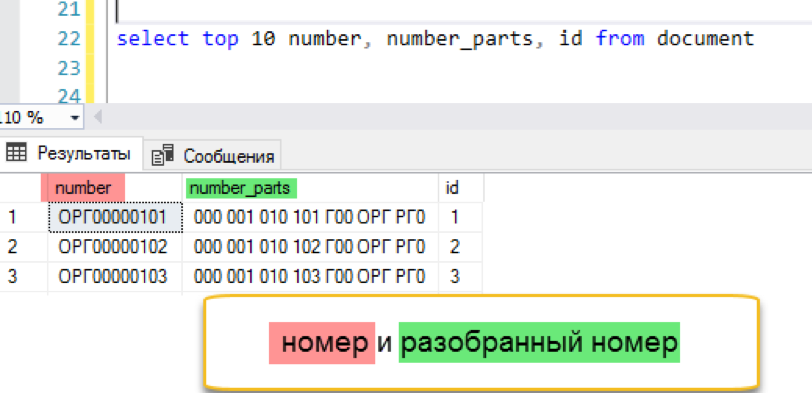
पूर्ण-पाठ अनुक्रमणिका जोड़ें
create fulltext index on document (number_parts) key index ndx1 with change_tracking = Auto
और परिणाम की जांच करें। प्रयोग समान है - दस्तावेजों की एक सूची से एक "विंडो" चयन मॉडलिंग। हम पिछली त्रुटियों को नहीं दोहराते हैं और तुरंत इस मामले में तिथि के अनुसार छँटाई के साथ अनुरोध को निष्पादित करते हैं।
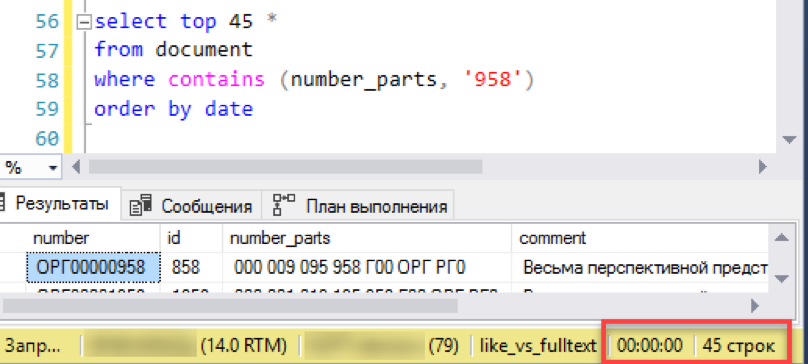
यह काम करता है! अब अधिक प्रामाणिक संख्या आज़माते हैं:
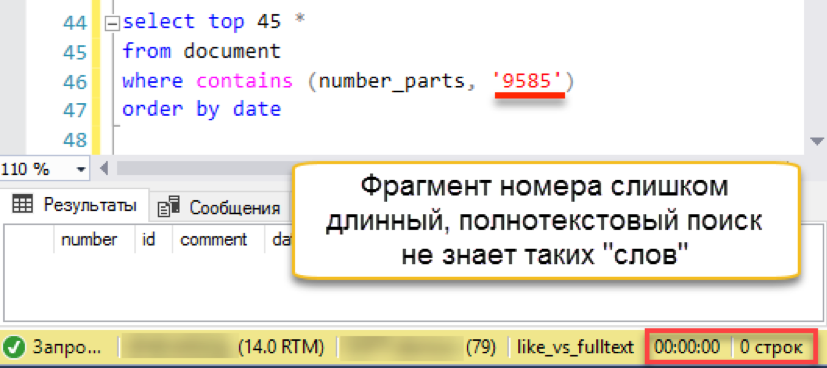
और फिर एक मिसफायर होता है। खोज स्ट्रिंग की लंबाई संग्रहीत "शब्दों" की लंबाई से अधिक लंबी है। वास्तव में, खोज डेटाबेस में केवल 4 वर्णों की एक पंक्ति नहीं होती है, इसलिए यह ईमानदारी से एक खाली परिणाम देता है। हमें खोज स्ट्रिंग को भागों में हरा देना होगा:
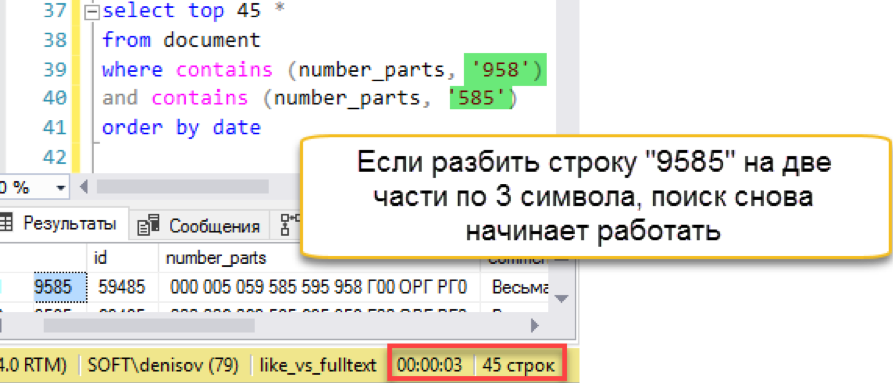
एक और बात! हमें फिर से एक त्वरित खोज करनी है। हां, वह अपने ओवरहेड को रखरखाव पर लगाता है, लेकिन परिणाम क्लासिक खोज की तुलना में सैकड़ों गुना तेज है। हम गिनाए गए प्रयास को ध्यान में रखते हैं, लेकिन किसी भी तरह रखरखाव को सरल बनाने की कोशिश करते हैं - अगले भाग में।
हम इसे अपने तरीके से शब्दों में तोड़ देंगे!
वास्तव में, किसने कहा कि शब्दों को रिक्त स्थान द्वारा अलग किया जाना चाहिए? शायद मुझे शब्दों के बीच शून्य चाहिए! (और, यदि संभव हो तो, उपसर्ग ताकि यह भी किसी तरह से नजरअंदाज कर दिया जाए और अंडरफुट में हस्तक्षेप न करें)। सामान्य तौर पर, इसमें कुछ भी असंभव नहीं है। लेख की शुरुआत से पूर्ण-पाठ खोज ऑपरेशन योजना को याद करें - एक अलग घटक, वर्डब्रेकर, शब्दों में तोड़ने के लिए जिम्मेदार है, और, सौभाग्य से, Microsoft आपको अपने स्वयं के "शब्द ब्रेकर" को लागू करने की अनुमति देता है।
और यहाँ दिलचस्प शुरू होता है। वर्डब्रेकर एक अलग डीएल है जो फुल-टेक्स्ट सर्च इंजन से जुड़ता है।
आधिकारिक प्रलेखन कहता है कि इस पुस्तकालय को बनाना बहुत सरल है - बस IWordBreaker इंटरफ़ेस को लागू करें। और यहाँ C ++ में लघु आरंभीकरण लिस्टिंग के एक जोड़े हैं। बहुत सफलतापूर्वक, मुझे अभी एक उपयुक्त ट्यूटोरियल मिला है!

(
स्रोत )
गंभीरता से, इंटरनेट पर अपना स्वयं का वर्कर बनाने के लिए दस्तावेज गायब है। और भी कम उदाहरण और टेम्पलेट। लेकिन मुझे अभी भी
एक तरह का व्यक्ति
प्रोजेक्ट मिला,
जिसमें C ++ इंप्लीमेंटेशन लिखा गया है जो विभाजकों द्वारा नहीं बल्कि शब्दों को तोड़ता है (केवल पिछले भाग की तरह!) खोज इंजन से कनेक्ट करें।
बस में प्लग इन करना ... वास्तव में बहुत आसान नहीं है। चलो चरणों के माध्यम से चलते हैं:
आपको SQL सर्वर के साथ लाइब्रेरी को फ़ोल्डर में कॉपी करने की आवश्यकता है:

पूर्ण-पाठ खोज में एक नई "भाषा" पंजीकृत करें
exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWARE\Microsoft\MSSQLSERVER\MSSearch\CLSID\{d225281a-7ca9-4a46-ae7d-c63a9d4815d4}', 'DefaultData', 'REG_SZ', 'sqlngram.dll' exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWARE\Microsoft\MSSQLSERVER\MSSearch\CLSID\{0a275611-aa4d-4b39-8290-4baf77703f55}', 'DefaultData', 'REG_SZ', 'sqlngram.dll' exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWARE\Microsoft\MSSQLSERVER\MSSearch\Language\ngram', 'Locale', 'REG_DWORD', 1 exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWARE\Microsoft\MSSQLSERVER\MSSearch\Language\ngram', 'WBreakerClass', 'REG_SZ', '{d225281a-7ca9-4a46-ae7d-c63a9d4815d4}' exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWARE\Microsoft\MSSQLSERVER\MSSearch\Language\ngram', 'StemmerClass', 'REG_SZ', '{0a275611-aa4d-4b39-8290-4baf77703f55}' exec sp_fulltext_service 'verify_signature' , 0; exec sp_fulltext_service 'update_languages'; exec sp_fulltext_service 'restart_all_fdhosts'; exec sp_help_fulltext_system_components 'wordbreaker';
रजिस्ट्री में मैन्युअल रूप से कई चाबियाँ संपादित करें (लेखक प्रक्रिया को स्वचालित करने जा रहा था, लेकिन 2016 के बाद से कोई खबर नहीं है। हालांकि, यह मूल रूप से एक "कार्यान्वयन उदाहरण" था, इसके लिए भी धन्यवाद)
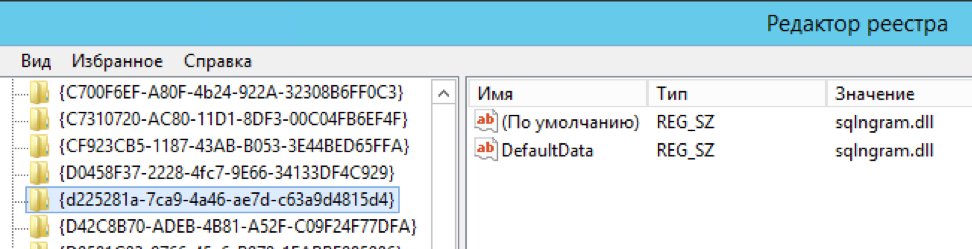
कदम परियोजना पृष्ठ पर विस्तार से वर्णित हैं।
हो गया। पुराने फुल-टेक्स्ट इंडेक्स को डिलीट कर दें, क्योंकि एक टेबल के लिए दो फुल-टेक्स्ट इंडेक्स नहीं हो सकते हैं। एक नया बनाएं और हमारे दस्तावेज़ संख्याओं को अनुक्रमित करें। मुख्य स्तंभ के रूप में, हम संख्याओं को स्वयं इंगित करते हैं, किसी भी अधिक सरोगेट पूर्व-टूटे हुए स्तंभों की आवश्यकता नहीं होती है। हौसले से स्थापित वर्डब्रेकर का उपयोग करने के लिए "भाषा नंबर 1" निर्दिष्ट करना सुनिश्चित करें।
drop fulltext index on document go create fulltext index on document (number Language 1) key index ndx1 with change_tracking = Auto
चेक?
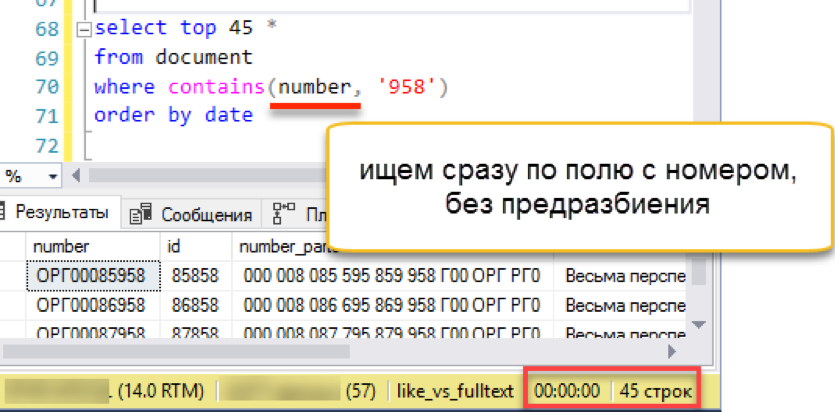
यह काम करता है! यह उपर्युक्त सभी उदाहरणों के रूप में तेजी से काम करता है।
चलो उस लंबी लाइन की जांच करते हैं जिस पर पिछला विकल्प ठोकर खाई थी:
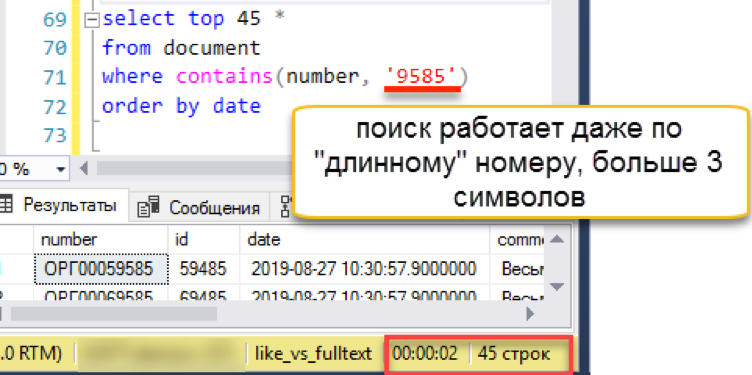
उपयोगकर्ता और प्रोग्रामर के लिए खोज पारदर्शी रूप से काम करती है। वर्डब्रेकर स्वतंत्र रूप से खोज स्ट्रिंग को टुकड़ों में तोड़ता है और वांछित परिणाम पाता है।
यह पता चला है कि अब हमें अतिरिक्त कॉलम और ट्रिगर्स की आवश्यकता नहीं है, अर्थात, समाधान पिछले प्रयास की तुलना में सरल (पढ़ें: अधिक विश्वसनीय) है। खैर, समर्थन के संदर्भ में, ऐसा कार्यान्वयन सरल और अधिक पारदर्शी है, त्रुटियों की संभावना कम है।
तो, बंद करो, मैंने कहा "अधिक विश्वसनीय"? हमने अपने DBMS में कुछ तृतीय-पक्ष लाइब्रेरी को जोड़ा है! और अगर वह गिर गई तो क्या होगा? यहां तक कि अनजाने में पूरी डेटाबेस सेवा को समाप्त कर देता है!
यहां आपको यह याद रखने की आवश्यकता है कि मैंने लेख की शुरुआत में मुख्य डीबीएमएस प्रक्रिया से अलग पूर्ण-पाठ खोज सेवा का उल्लेख कैसे किया। यह यहां है कि यह स्पष्ट हो जाता है कि यह क्यों महत्वपूर्ण है। पुस्तकालय पूर्ण-पाठ अनुक्रमण सेवा से जुड़ता है, जो कम अधिकारों के साथ काम कर सकता है। और, इससे भी महत्वपूर्ण बात, अगर तीसरे पक्ष के घटक गिरते हैं, तो केवल अनुक्रमण सेवा गिर जाएगी। खोज थोड़ी देर के लिए रुक जाएगी (लेकिन यह पहले से ही अतुल्यकालिक है), और डेटाबेस इंजन काम करना जारी रखेगा जैसे कि कुछ भी नहीं हुआ था।
संक्षेप में देना। अपने खुद के वर्डब्रेकर को जोड़ना काफी चुनौती भरा हो सकता है। लेकिन "लंबे समय में" खेलते समय, ये प्रयास अधिक लचीलापन और रखरखाव में आसानी के साथ भुगतान करते हैं। पसंद, हमेशा की तरह, आपकी है।
यह सब क्यों जरूरी है?
एक जिज्ञासु पाठक शायद एक से अधिक बार आश्चर्यचकित हुआ: "यह सब बहुत अच्छा है, लेकिन अगर मैं अपने आवेदन से खोज प्रश्नों को नहीं बदल सकता तो मैं इन सुविधाओं का उपयोग कैसे कर सकता हूं?" वाजिब सवाल। पूर्ण-पाठ एमएस एसक्यूएल खोज को शामिल करने के लिए प्रश्नों के वाक्यविन्यास को बदलने की आवश्यकता होती है, और अक्सर यह मौजूदा वास्तुकला में बस संभव नहीं होता है।
आप एप्लिकेशन को नियमित रूप से टेबल के बजाय उसी नाम के टेबल-वैल्यू फ़ंक्शन को "स्लिप" करके ट्रिक करने की कोशिश कर सकते हैं, जो पहले से ही खोज को जिस तरह से हम चाहते हैं, प्रदर्शन करेंगे। आप खोज को बाहरी डेटा स्रोत के रूप में बाँधने का प्रयास कर सकते हैं। एक और समाधान है - सॉफ्टपॉइंट डेटा क्लस्टर - एक विशेष सेवा जो स्रोत एप्लिकेशन और SQL सर्वर सेवा के बीच "अग्रेषण" स्थापित करती है, ट्रैफ़िक के लिए सुनती है और विशेष नियमों के अनुसार "फ्लाई पर" अनुरोधों को बदल सकती है। इन नियमों का उपयोग करके, हम LIKE के साथ नियमित प्रश्नों को पा सकते हैं और उन्हें पूर्ण-पाठ खोज के साथ CONTAINS में परिवर्तित कर सकते हैं।
ऐसी मुश्किलें क्यों? फिर भी, खोज की गति मनोरम है। एक अत्यधिक भरी हुई प्रणाली में, जहां ऑपरेटर अक्सर लाखों तालिकाओं में रिकॉर्ड की तलाश करते हैं, प्रतिक्रिया की गति महत्वपूर्ण होती है। सबसे अधिक लगातार संचालन पर समय की बचत के परिणामस्वरूप दर्जनों अतिरिक्त संसाधित अनुप्रयोग होते हैं, और यह वास्तविक धन है, जिसे कोई भी व्यवसाय खुश है। अंत में, प्रौद्योगिकी के अध्ययन और कार्यान्वयन के लिए कुछ दिन या सप्ताह भी बढ़े हुए संचालक दक्षता के साथ भुगतान करेंगे।
लेख में उल्लिखित सभी लिपियाँ
github.com/frrrost/mssql_fulltext रिपॉजिटरी में उपलब्ध हैं
लेखक के बारे में
 अलेक्जेंडर डेनिसोव
अलेक्जेंडर डेनिसोव - एमएस SQL सर्वर डेटाबेस प्रदर्शन विश्लेषक। पिछले 6 वर्षों में, सॉफ्टपॉइंट टीम के हिस्से के रूप में, मैं अन्य लोगों के अनुरोधों में बाधाओं को खोजने और ग्राहकों के डेटाबेस से सबसे अधिक निचोड़ने में मदद कर रहा हूं।