पिछले हफ्ते, मैंने
इस बारे में बात की कि Yandex.Stations ध्वनि के माध्यम से कैसे सक्रिय होते हैं। यह पता चला कि वाईफाई पासवर्ड स्पष्ट पाठ में प्रेषित है। मैंने सोचा कि क्यों इस तरह से सक्रियता करना आवश्यक था, और कुछ डिबगेड तरीके से नहीं।
नतीजतन, मैं इस निष्कर्ष पर पहुंचा कि इस प्रक्रिया में शो महत्वपूर्ण है। लेकिन, क्या होगा यदि हम एक डेटा ट्रांसफर प्रोटोकॉल बनाते हैं जो पूरी तरह से उपयोगकर्ता के अनुभव पर केंद्रित है? इस तरह से ऑक्टेव परियोजना का जन्म हुआ - मेलोडिक डेटा ट्रांसफर के लिए।

कट के तहत, मैं आपको बताऊंगा कि प्रोटोटाइप कैसे बनाया गया था, और डेमो के लिए एक लिंक दें। आप सुन सकते हैं कि कोई भी संदेश कैसा लगता है :)
पिछले लेख का सारांश
मैंने उस ध्वनि को रिकॉर्ड किया जिसके साथ स्टेशन सक्रिय है, चल रहे फूरियर ट्रांसफॉर्म के विज़ुअलाइज़ेशन को देखा और महसूस किया कि सिग्नल की व्यवस्था कैसे की जाती है और वाईफाई पासवर्ड स्पष्ट में निहित है।
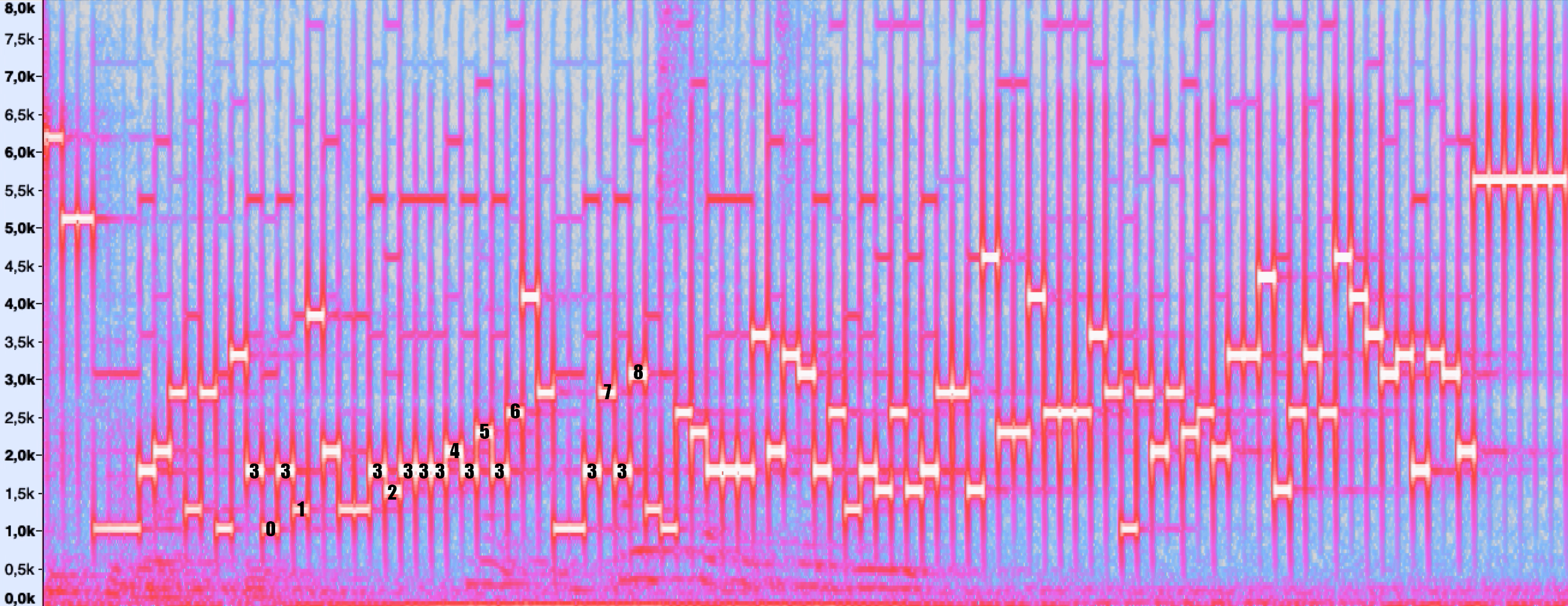
एक हेक्स स्ट्रिंग प्रेषित होती है, जहां प्रत्येक वर्ण 0 - F के लिए 240 kz के एक चरण के साथ 1 kHz - 4.6 kHz की आवृत्ति होती है। मैंने सोचा कि इस तरह से सक्रियण करना क्यों आवश्यक था, और ब्लूटूथ के माध्यम से नहीं, उदाहरण के लिए चीनी रोबोट वैक्यूम क्लीनर के साथ, और इस निष्कर्ष पर पहुंचा कि इस मामले में दक्षता सुरक्षा या गति से अधिक महत्वपूर्ण है।
प्रेरणा
सच में! आखिरकार, संचार प्रोटोकॉल हमेशा सीमा, गति और विश्वसनीयता के बीच एक समझौता है। लेकिन क्या होगा अगर ये सभी विशेषताएं पृष्ठभूमि में फीका हो जाती हैं, और निर्णायक कारक उपयोगकर्ता के लिए छाप कारक है?
मुझे यैंडेक्स डेवलपर्स के एक हथौड़ा की तरह, सरल विचार पसंद आया - 16 आवृत्तियों को चुनने के लिए: प्रत्येक हेक्स-प्रतीक के लिए। और मेरे पास पिछले अध्ययन से एक सिग्नल रिसीवर भी था, इसलिए मैंने इस विचार को विकसित करने का फैसला किया, और खरोंच से सब कुछ नहीं आया।
दो सुधार
चरण विराम निकालें
सबसे पहले, जब मैंने स्टेशन के सक्रियण संकेत का विश्लेषण किया, तो मैं प्रतीक स्विच करने के समय सभी आवृत्तियों पर शोर से भ्रमित था। ये स्पेक्ट्रोग्राम में खड़ी पट्टियाँ हैं:
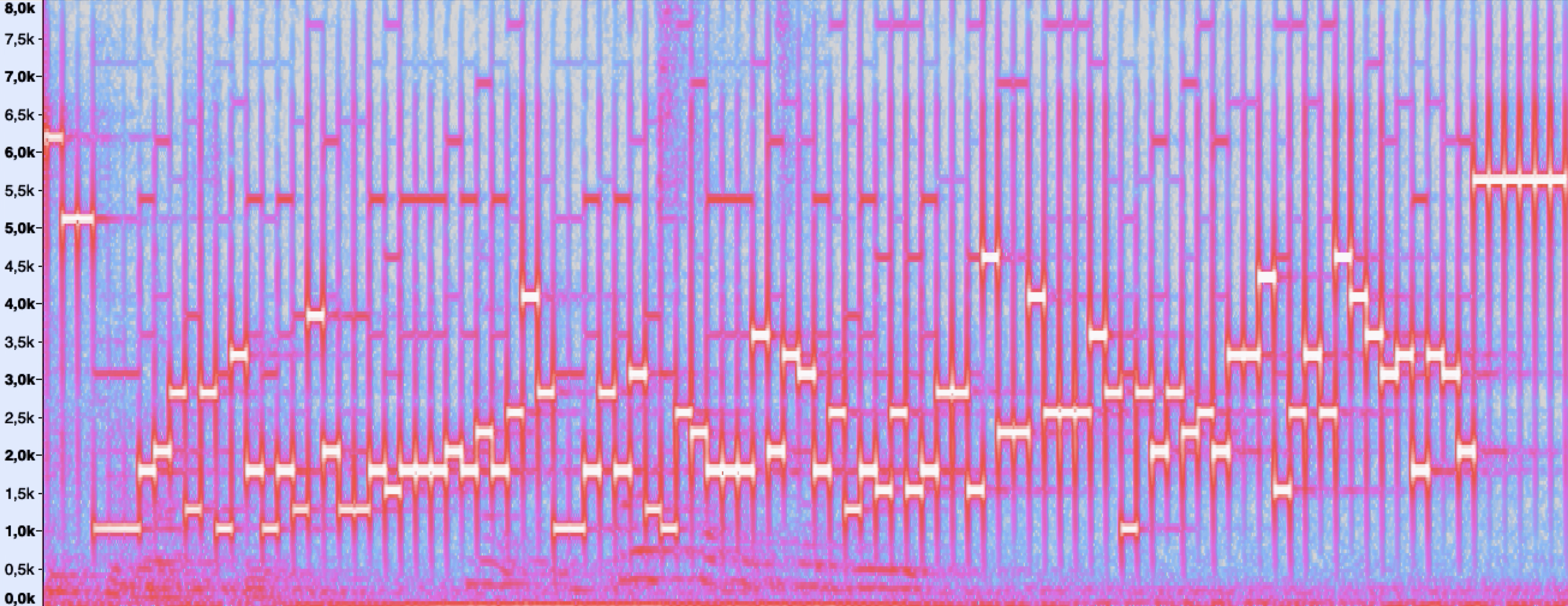
इन क्षणों में, क्लिक सुनाई पड़ते हैं। इस आशय का कारण पात्रों के बीच एक चरण अंतराल है। तथ्य यह है कि एक प्रतीक की लंबाई ध्वनि कंपन की अवधि के पूर्णांक संख्या में फिट नहीं होती है। इसलिए, आवृत्ति स्विच करने के समय, संकेत आयाम नाटकीय रूप से बदलता है। कुछ इस तरह:
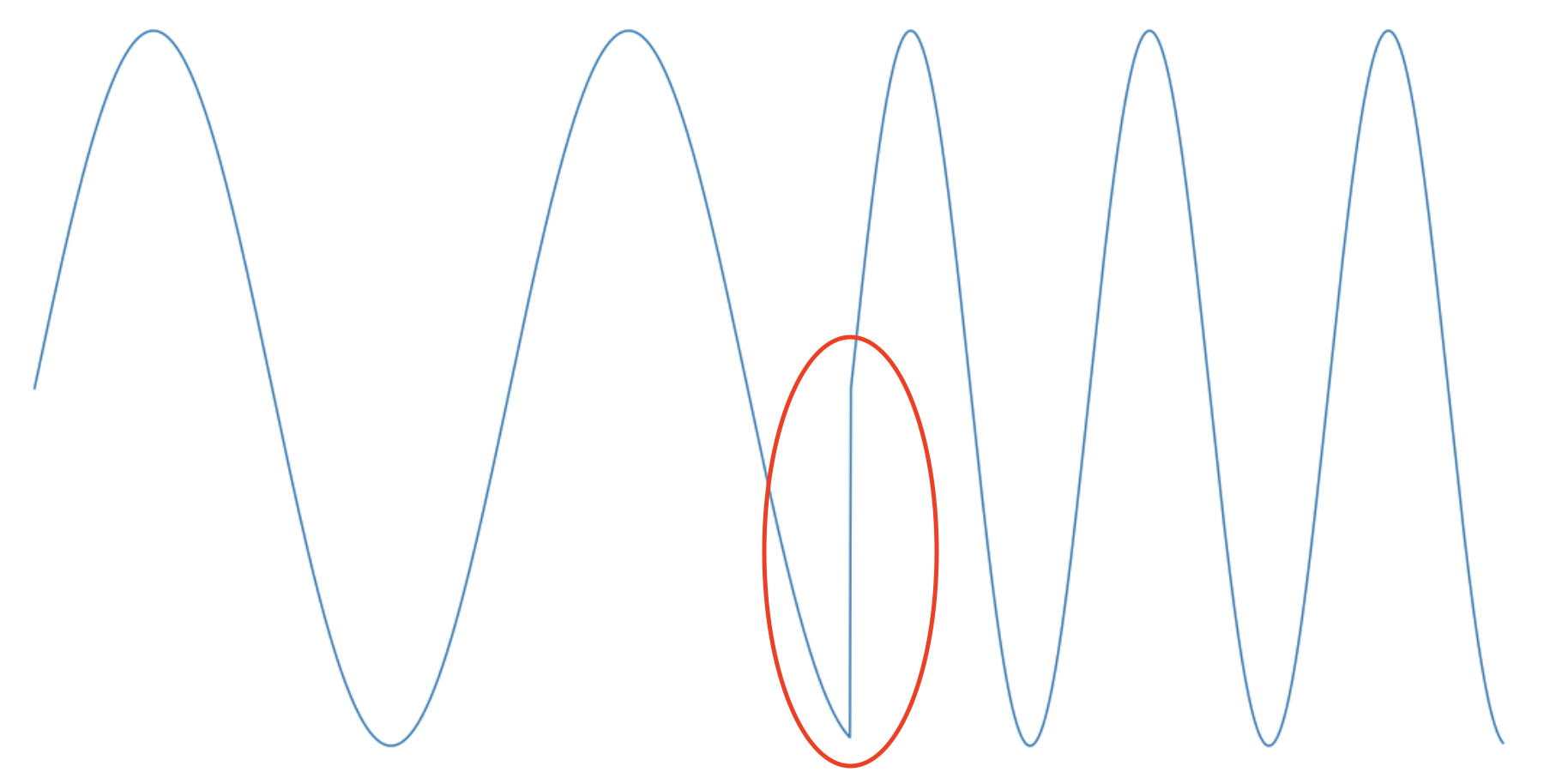
इस प्रभाव से बचने के लिए रेडियो में विभिन्न विधियाँ हैं। मैंने आवृत्ति को स्विच करने के समय सिग्नल के आयाम को आसानी से कम करने का फैसला किया, और फिर सुचारू रूप से निर्माण किया - यह नरम लगता है। यह इस तरह दिखता है:

शायद क्लिक्स बग नहीं थे, लेकिन सुविधाएँ और अधिक "भविष्यवादी" ध्वनि देती थीं, लेकिन मुझे यह उनके बिना बेहतर लगता है :)
संगीत जोड़ें
हम ध्वनि के माध्यम से डेटा संचारित करते हैं। इसके लिए नोट आवृत्तियों का उपयोग क्यों नहीं किया जाता है? मैंने विभिन्न विकल्पों की कोशिश की, अंत में मैंने पहले ऑक्टेव से पहले शुरू होने वाले 16 नोटों को चुना।

उच्च नोट्स का उपयोग करने से आपके कान कम आरामदायक होंगे। और वक्ताओं और माइक्रोफोनों की आवृत्ति प्रतिक्रिया की विशेषताओं के कारण निचले नोट्स बदतर रूप से प्रसारित होते हैं। इसके अलावा, कम नोटों की आवृत्तियों एक-दूसरे के करीब हैं, जो रिसेप्शन को प्रभावित करती हैं।
यह एक प्रकार का संगीत-आवृत्ति मॉड्यूलेशन निकला। चलो इसे "क्रुप-मॉड्यूलेशन" कहते हैं :)
हम लॉन्च करते हैं
वह आवाज कैसी है? ताकि आप ब्राउज़र में सही कोशिश कर सकें, मैंने अजगर से जेएस तक क्रुप-संग्राहक ट्रांसमीटर को फिर से लिखा और एक सरल इंटरफ़ेस बनाया।
मैं यह कहने का अवसर लेता हूँ:
मैं utf-8 का उपयोग करता हूं, जिसका अर्थ है कि सिरिलिक वर्ण और यहां तक कि इमोजी भी प्रसारित किए जा सकते हैं। उनके साथ पार्सल लंबे होते हैं, क्योंकि प्रत्येक ऐसे चरित्र में 1 से अधिक बाइट होती हैं।
यह लैटिन की तुलना में थोड़ा कम सुखद लगता है, क्योंकि प्रत्येक सिरिलिक चरित्र में एक ही पता बाइट होता है। लेकिन फिर भी दिलचस्प :)
आप
यहां किसी भी वाक्यांश की कोशिश कर सकते
हैं । (लेख के अंत में डुप्लिकेट)
लेकिन रिसीवर के बारे में क्या?
बेशक, पाठ के आधार पर यादृच्छिक ध्वनियों को सुनने का मज़ा है, लेकिन डेटा ट्रांसमिशन को केवल तभी कहा जा सकता है जब सिग्नल प्राप्त होता है, ध्वस्त और डिकोड किया जाता है।
मैंने अवधारणा के प्रमाण के रूप में एक अजगर रिसीवर का प्रोटोटाइप बनाया। यहां बताया गया है कि यह कैसे काम करता है:
आप देखते हैं, डेटा ट्रांसफर नोटों द्वारा होता है! बेशक, अभी किसी उत्पादन का सवाल नहीं है। कोई सिंक्रनाइज़ेशन, त्रुटि-सुधार कोडिंग और अखंडता नियंत्रण नहीं है। लेकिन अगर समुदाय रुचि दिखाता है और व्यावहारिक उपयोग के लिए कुछ विकल्पों को फेंकता है, तो मैं उपरोक्त कार्यक्षमता को लागू कर सकता हूं और इसे सामान्य पुस्तकालय में लपेट सकता हूं :)
संक्षेप में देना
यह एक शानदार परिणाम के साथ शाम के एक जोड़े के लिए एक दिलचस्प परियोजना थी। इस तरह के डेटा ट्रांसफर का उपयोग किया जा सकता है, उदाहरण के लिए, "ध्वनि क्यूआर-कोड" के रूप में - एक फोन से एक वेबसाइट पर एक खाता साझा करने के लिए, आदि।
वैकल्पिक रूप से, आप इसका उपयोग ब्रांडों के लिए रिंगटोन बनाने के लिए कर सकते हैं। यहाँ, उदाहरण के लिए,
हब्र की तरह लगता है ।
सभी वर्तमान विकास
गिथब पर उपलब्ध हैं - आप स्वयं प्रोजेक्ट विकसित करने का प्रयास कर सकते हैं।
ब्राउज़र में चल रहे डेमो के
लिंक को डुप्लिकेट करें
।पढ़ने के लिए धन्यवाद! मुझे आशा है कि आप रुचि रखते थे।
अ छा!