Pitable Go में मुख्य प्रोफाइलिंग टूल है। प्रोफाइलर को गो मानक पुस्तकालय में शामिल किया गया है और वर्षों में इसके बारे में बहुत कुछ लिखा गया है। किसी मौजूदा एप्लिकेशन के लिए आपको एक कोड में एक लाइन जोड़ने की जरूरत है।
import _ “net/http/pprof”
डिफ़ॉल्ट HTTP सर्वर में - net/http.DefaultServeMux - प्रोफाइलर्स जो प्रोफाइलिंग परिणाम भेजते हैं, उन्हें पथ /debug/pprof/ साथ पंजीकृत किया जाएगा।
curl -o cpu-profile.pb.gz http://<server-addr>/debug/pprof/profile
(अधिक जानकारी के लिए https://godoc.org/net/http/pprof देखें )
लेकिन अनुभव से, यह हमेशा इतना सरल नहीं होता है और अभ्यास में लड़ाई में पवित्रता का उपयोग करते हुए नुकसान होते हैं।
शुरुआत करने के लिए, हम नहीं चाहते हैं कि प्रोफाइलर इंटरनेट पर चिपके रहें। ओवरहेड के संदर्भ में प्रोफाइलिंग सस्ता है, लेकिन मुफ्त नहीं है, और प्रोफ़ाइल में ही आवेदन की आंतरिक संरचना के बारे में जानकारी है, जो अक्सर बाहरी लोगों के लिए खोलने की सलाह नहीं दी जाती है। आपको यह सुनिश्चित करना होगा कि /debug पथ अनधिकृत उपयोगकर्ताओं के लिए सुलभ नहीं है। एक्सेस को प्रॉक्सी सर्वर साइड पर सीमित किया जा सकता है या Pprof सर्वर को एक अलग पोर्ट में ले जाया जा सकता है, जिस तक पहुंच केवल विशेषाधिकार प्राप्त होस्ट के माध्यम से खुली होगी।
लेकिन क्या होगा अगर आवेदन में HTTP एक्सेस शामिल नहीं है - उदाहरण के लिए, क्या यह एक ऑफ़लाइन कतार प्रोसेसर है?
कंपनी में बुनियादी ढांचे की स्थिति के आधार पर, आवेदन प्रक्रिया के अंदर एक "अचानक" HTTP सर्वर परिचालन विभाग से सवाल उठा सकता है;) सर्वर अतिरिक्त रूप से क्षैतिज स्केलिंग क्षमताओं को सीमित करता है, जैसा कि यह एक ही मेजबान पर आवेदन के कई उदाहरणों को चलाने के लिए काम नहीं करेगा - प्रक्रियाएं संघर्ष करेंगी, समान सर्वर के लिए समान टीसीपी पोर्ट खोलने की कोशिश कर रही है।
यह कंटेनर में प्रत्येक आवेदन प्रक्रिया को अलग करने (या एक अद्वितीय पोर्ट, या UNIX सॉकेट पर pitable सर्वर चलाने) द्वारा हल करने के लिए "सरल" है। आप कई डेटा केंद्रों में "स्प्रेड आउट" सैकड़ों उदाहरणों में क्षैतिज रूप से स्केल की गई सेवा के साथ अब किसी को आश्चर्यचकित नहीं करेंगे। एक बहुत ही गतिशील बुनियादी ढांचे में, आवेदन के साथ कंटेनर समय-समय पर प्रकट हो सकते हैं और गायब हो सकते हैं। और हमें अभी भी किसी तरह प्रोफाइलर से संपर्क करने की आवश्यकता है। और इसका मतलब यह है कि चयनित स्केलिंग विधि की परवाह किए बिना, एक विशिष्ट एप्लिकेशन इंस्टेंस के लिए खोज तंत्र और संबंधित pitable सर्वर पोर्ट की आवश्यकता है।
कंपनी की विशेषताओं के आधार पर, कुछ का उपयोग करने की क्षमता का बहुत ही अस्तित्व जो सेवा की मुख्य उत्पादन गतिविधि से संबंधित नहीं है, सुरक्षा विभाग से सवाल उठा सकता है;) मैंने एक कंपनी में काम किया है, जहां उद्देश्य कारणों से, किसी भी चीज की पहुंच पक्ष में है; उत्पादन विशेष रूप से परिचालन विभाग में था। एक रनिंग एप्लिकेशन पर प्रोफाइलर को चलाने का एकमात्र तरीका ऑपरेशन बग ट्रैकर में एक कार्य को खोलना था, जिसमें कर्ल कमांड, जिसमें डीसी, किस सर्वर पर आप चलाना चाहते हैं, किस परिणाम की उम्मीद करते हैं और इसके साथ क्या करना है।
या एक स्थिति की कल्पना करें: एक कामकाजी सुबह। आपने स्लैक खोला और पता चला कि शाम में, उत्पादन सेवा प्रक्रियाओं में से एक में "कुछ गलत हो गया", "कहीं, कुछ" बंद "," स्मृति प्रवाह शुरू हुई "," सीपीयू ग्राफिक्स क्रॉल हुआ "या" एप्लिकेशन को बस घबराहट शुरू कर दिया। ड्यूटी ऑपरेटिंग टीम (या ओओएम किलर) ने गहरी खुदाई नहीं की और बस आवेदन को फिर से शुरू किया या पिछले दिन की नवीनतम रिलीज को वापस ले लिया।
तथ्य के बाद, ऐसी स्थितियों को समझना आसान नहीं है। यह बहुत अच्छा है अगर समस्या का परीक्षण वातावरण में (या उत्पादन के एक अलग हिस्से में किया जा सकता है, जिसकी पहुंच आपके पास है)। आप उन सभी उपकरणों के साथ आवश्यक डेटा एकत्र कर सकते हैं जो हाथ में हैं, और फिर यह पता लगाना है कि समस्या किस घटक की है।
लेकिन अगर समस्या को पुन: उत्पन्न करने का कोई स्पष्ट तरीका नहीं है, तो क्या हम केवल कल के लॉग और मैट्रिक्स के साथ बचे हैं? ऐसी स्थितियों में, यह हमेशा शर्म की बात है कि आप उस समय को वापस नहीं ला सकते जब समस्या उत्पादन में दिखाई देती थी और जल्दी से सभी आवश्यक प्रोफाइल एकत्र करते थे, ताकि बाद में, एक शांत मोड में, विश्लेषण करें।
लेकिन अगर प्राइफाइड अपेक्षाकृत सस्ता है, तो प्रोफाइलिंग डेटा को स्वचालित रूप से, कुछ अंतराल पर क्यों नहीं इकट्ठा किया जाता है, और उन्हें उत्पादन से अलग कहीं स्टोर किया जाता है, जहाँ आप उन सभी को दिलचस्पी दे सकते हैं?
2010 में, Google ने डेटा सेंटर दस्तावेज़ के लिए Google- वाइड प्रोफाइलिंग: ए कंटीन्यूअस प्रोफाइलिंग इन्फ्रास्ट्रक्चर प्रकाशित किया, जो कंपनी सिस्टम की निरंतर रूपरेखा के लिए एक दृष्टिकोण का वर्णन करता है। और कुछ वर्षों के बाद, कंपनी ने एक निरंतर रूपरेखा सेवा - स्टैकड्राइवर प्रोफाइलर लॉन्च की - जो सभी के लिए उपलब्ध है।
ऑपरेशन का सिद्धांत सरल है: एक pprof सर्वर के बजाय, एक स्टैडड्राइवर एजेंट अनुप्रयोग से जुड़ा होता है, जो सीधे runtime/pprof एपीआई का उपयोग करते हुए, समय-समय पर आवेदन से विभिन्न प्रकार की रूपरेखा एकत्र करता है और प्रोफाइल को क्लाउड पर भेजता है। Stackdriver नियंत्रण कक्ष का उपयोग करते हुए, डेवलपर को सभी की जरूरत है, वांछित AZ में वांछित एप्लिकेशन इंस्टेंस का चयन करें और आप इस तथ्य के बाद, अतीत में किसी भी समय एप्लिकेशन का विश्लेषण कर सकते हैं।
अन्य सास प्रदाता समान कार्यक्षमता प्रदान करते हैं। लेकिन, आपकी कंपनी के सुरक्षा नियम अपने स्वयं के बुनियादी ढांचे से परे डेटा निर्यात करने पर रोक लगा सकते हैं। और सेवाएं जो आपको अपने स्वयं के सर्वर पर एक निरंतर प्रोफाइलिंग सिस्टम को तैनात करने की अनुमति देती हैं, मैंने नहीं देखा है।
ऊपर वर्णित सभी कठिनाइयाँ और विचार न केवल गो के लिए नए और विशिष्ट हैं। उनके साथ, एक रूप या किसी अन्य में, डेवलपर्स का सामना लगभग सभी कंपनियों में किया जाता है जहां मैंने काम किया था।
कुछ बिंदु पर, मैं मनमाने ढंग से गो-सेवा के लिए स्टैकड्राइवर प्रोफाइलर का एक एनालॉग बनाने की कोशिश करने के लिए उत्सुक था जो वर्णित समस्याओं को हल कर सकता था। एक शौक परियोजना के रूप में, अपने खाली समय में, मैं प्रोफिफ ( https://github.com/profefe/profefe ) पर काम करता हूं - निरंतर प्रोफाइलिंग की एक खुली सेवा। परियोजना अभी भी प्रयोगों और आवधिक चर्चाओं के चरण में है, लेकिन पहले से ही परीक्षण के लिए उपयुक्त है।
परियोजना के लिए मेरे द्वारा निर्धारित कार्य:
- सेवा को कंपनी के आंतरिक बुनियादी ढांचे पर तैनात किया जाएगा।
- सेवा का उपयोग कंपनी के आंतरिक उपकरण के रूप में किया जाएगा। आप डेटा के आपूर्तिकर्ताओं और उपभोक्ताओं पर भरोसा कर सकते हैं: शुरुआती चरणों में, आप लिखने / पढ़ने के अनुरोध के प्राधिकरण को छोड़ सकते हैं और अग्रिम में अपने आप को दुर्भावनापूर्ण उपयोग से बचाने की कोशिश नहीं कर सकते।
- सेवा को कंपनी के बुनियादी ढांचे से कोई विशेष उम्मीद नहीं होनी चाहिए: सब कुछ बादल में या अपने स्वयं के डीसी में रह सकता है; प्रोफाइल किए गए अनुप्रयोगों को कंटेनरों के अंदर चलाया जा सकता है ("सब कुछ कुबेरनेट द्वारा नियंत्रित किया जाता है") या नंगे धातु पर चल सकता है।
- सेवा को संचालित करना आसान होना चाहिए (यह एक निश्चित सीमा तक लगता है, प्रोमेथियस एक अच्छा उदाहरण है)।
- यह समझा जाना चाहिए कि चयनित वास्तुकला उन स्थितियों को संतुष्ट नहीं कर सकता है जिनमें सेवा का उपयोग किया जाएगा। सबसे अधिक संभावना है, आपको सिस्टम घटकों को "मौके पर" पैमाने पर फैलाने / बदलने की क्षमता की आवश्यकता होगी।
- (4) के अनुसार, हमें आवश्यक बाहरी निर्भरता को कम करने की कोशिश करनी चाहिए। उदाहरण के लिए, किसी सेवा को किसी तरह के प्रोफाइल के उदाहरणों के लिए देखना चाहिए, लेकिन, कम से कम शुरुआती चरणों में, मैं एक स्पष्ट सेवा खोज के बिना करना चाहता हूं।
- सेवा गो-अनुप्रयोगों के प्रोफाइल को स्टोर और कैटलॉग करेगी। हम उम्मीद करते हैं कि एक pprof फ़ाइल 100KB - 2MB पर कब्जा करती है ( ढेर प्रोफाइल आमतौर पर सीपीयू प्रोफाइल से बहुत बड़ी होती है )। एक प्रोफाइल से, यह प्रति मिनट एन प्रोफाइल से अधिक भेजने के लिए कोई मतलब नहीं है (एक स्टैकड्राइवर एजेंट भेजता है, औसतन, प्रति मिनट 2 प्रोफाइल)। यह तुरंत गणना के लायक है कि एक एकल आवेदन में कई से कई सौ उदाहरण हो सकते हैं।
- सेवा के माध्यम से, उपयोगकर्ता आवेदन के विभिन्न प्रकार के प्रोफाइल (सीपीयू, हीप, म्यूटेक्स, आदि) या एक निश्चित अवधि के लिए आवेदन के एक विशिष्ट उदाहरण की खोज करेंगे।
- सेवा से, उपयोगकर्ता खोज परिणामों से एक अलग pprof प्रोफ़ाइल का अनुरोध करेगा।
अब प्रोफिफ में दो घटक होते हैं:
प्रोफे-कलेक्टर एक साधारण रेस्टफुल एपीआई के साथ एक सेवा कलेक्टर है।
कलेक्टर का कार्य है कि वह प्रिटि-फाइल और कुछ मेटा-डेटा प्राप्त करे और उन्हें स्थायी स्टोरेज में सेव करे। एपीआई ग्राहकों को एक निश्चित समय खिड़की में मेटा-डेटा द्वारा प्रोफाइल खोजने या स्टोर से एक विशिष्ट प्रोफ़ाइल (या उसी प्रकार के प्रोफाइल का एक समूह) पढ़ने की अनुमति देता है।
एजेंट - एक वैकल्पिक पुस्तकालय जो कि pprof सर्वर के बजाय एप्लिकेशन से जुड़ा होना चाहिए। एप्लिकेशन के अंदर, एक अलग गोरोइन में, एजेंट समय-समय पर प्रोफाइलिंग प्रक्रिया ( runtime/pprof का उपयोग करके) शुरू करता है, और कलेक्टर को मेटा डेटा के साथ-साथ प्राप्त की गई प्रोफिट प्रोफाइल को भेजता है।
मेटा डेटा एक मनमाना कुंजी-मूल्य सेट है जो किसी एप्लिकेशन या उसके व्यक्तिगत उदाहरण का वर्णन करता है। उदाहरण के लिए: सेवा का नाम, संस्करण, डेटा केंद्र और होस्ट जहां एप्लिकेशन चल रहा है।

प्रोफ़ाइल घटक बातचीत आरेख
मैंने ऊपर उल्लेख किया है कि एजेंट एक वैकल्पिक घटक है। यदि इसे किसी मौजूदा एप्लिकेशन से कनेक्ट करना संभव नहीं है, लेकिन net/http/pprof सर्वर पहले से ही एप्लिकेशन में जुड़ा हुआ है, तो प्रोफाइल को किसी भी बाहरी टूल का उपयोग करके हटाया जा सकता है और HTTP API के माध्यम से कलेक्टर को pprof फाइल भेज सकता है।
उदाहरण के लिए, मेजबानों पर, आप एक क्रॉन कार्य को कॉन्फ़िगर कर सकते हैं जो समय-समय पर चलने वाले उदाहरणों से प्रोफाइल एकत्र करेगा और उन्हें भंडारण के लिए प्रोफाईल भेज देगा;)
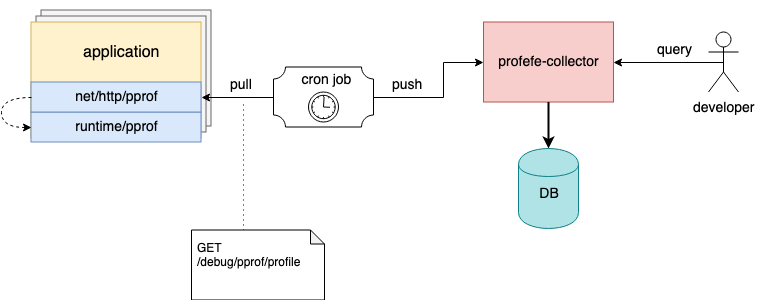
क्रोन कार्य एकत्र करता है और प्रोफाईल कलेक्टर को आवेदन प्रोफाइल भेजता है
आप GitHub पर प्रलेखन में प्रोफाईफ एपीआई के बारे में अधिक पढ़ सकते हैं।
योजनाओं
अब तक, प्रोफाईल कलेक्टर के साथ बातचीत करने का एकमात्र तरीका HTTP API है। भविष्य के लिए कार्यों में से एक अलग यूआई सेवा को इकट्ठा करना है जिसके माध्यम से संग्रहीत डेटा को नेत्रहीन रूप से दिखाना संभव होगा: खोज परिणाम, क्लस्टर प्रदर्शन का एक सामान्य अवलोकन, आदि।
प्रोफाइलिंग डेटा एकत्र करना और संग्रहीत करना बुरा नहीं है, लेकिन "एप्लिकेशन के बिना, डेटा बेकार है।" टीम, जहां मैं काम करता हूं, के पास सेवा से कई लाभकारी प्रोफाइल के लिए बुनियादी आंकड़े एकत्र करने के लिए प्रयोगात्मक उपकरण का एक सेट है। यह आवेदन की प्रमुख निर्भरता को अपडेट करने के परिणामों या एक बड़े रीफैक्टरिंग के परिणामों का विश्लेषण करने में बहुत मदद करता है ( दुर्भाग्य से, उत्पादन में प्रदर्शन हमेशा अलग-अलग बेंचमार्क के प्रक्षेपण और एक परीक्षण वातावरण में रूपरेखा के आधार पर अपेक्षाओं को पूरा नहीं करता है )। मैं प्रोफाईफ एपीआई में संग्रहीत प्रोफाइल की तुलना और विश्लेषण करने के लिए समान कार्यक्षमता जोड़ना चाहता हूं।
इस तथ्य के बावजूद कि प्रोफिफ का मुख्य फोकस गो सेवाओं की निरंतर रूपरेखा है, प्रोफिट प्रोफ़ाइल प्रारूप गो के लिए बंधा हुआ नहीं है। जावा, जावास्क्रिप्ट, पायथन आदि के लिए, पुस्तकालय हैं जो आपको इस प्रारूप में प्रोफाइलिंग डेटा प्राप्त करने की अनुमति देते हैं। शायद अन्य भाषाओं में लिखे गए अनुप्रयोगों के लिए प्रोफिफ एक उपयोगी सेवा बन सकती है।
अन्य बातों के अलावा, रिपॉजिटरी में गीथहब पर प्रोजेक्ट ट्रैकर में वर्णित कई खुले प्रश्न हैं।
निष्कर्ष
पिछले कुछ वर्षों में, लोकप्रिय विचार डेवलपर्स के बीच उलझ गया है कि एक सेवा के " अवलोकन " को प्राप्त करने के लिए तीन घटकों की आवश्यकता होती है: मैट्रिक्स, लॉग और ट्रेसिंग (" अवलोकन के तीन स्तंभ ")। यह मुझे लगता है कि दृश्यता प्रणाली और उसके घटकों के स्वास्थ्य के बारे में प्रभावी ढंग से जवाब देने की क्षमता है। मेट्रिक्स और ट्रेसिंग सिस्टम को समग्र रूप से समझना संभव बनाते हैं। लॉग सिस्टम के जानबूझकर वर्णित भागों को कवर करते हैं। दृश्यता प्राप्त करने के लिए प्रोफाइलिंग एक और संकेत है, जिससे आप माइक्रो लेवल पर सिस्टम को समझ सकते हैं। समय की अवधि में लगातार रूपरेखा यह समझने में भी मदद करती है कि व्यक्तिगत घटकों और पर्यावरण ने पूरे सिस्टम की संचालन क्षमता और उत्पादकता को कैसे प्रभावित और प्रभावित किया है।