कोड लिखे बिना विचारों, वास्तुकला और एल्गोरिदम का परीक्षण कैसे करें? उनकी संपत्तियों को कैसे तैयार और सत्यापित किया जाए? मॉडल-चेकर और मॉडल-खोजक क्या हैं? जब परीक्षण क्षमता पर्याप्त न हो तो क्या करें
नमस्कार। मेरा नाम वासिल डियाडोव है, अब मैं Yandex.Mail में एक प्रोग्रामर के रूप में काम करता हूं। इससे पहले मैंने इंटेल में काम किया था, मैंने पहले ASIC / FADA के लिए वेरिलोग / VHDL पर RTL- कोड (रजिस्टर ट्रांसफर लेवल) विकसित किया था। मैं लंबे समय से सॉफ्टवेयर और हार्डवेयर विश्वसनीयता, गणित, उपकरण और विधियों के शौकीन रहा हूं जो गारंटी और पूर्वनिर्धारित गुणों के साथ सॉफ्टवेयर और तर्क विकसित करने के लिए उपयोग किया जाता है।
यह एक श्रृंखला का दूसरा लेख है ( यहां पहला लेख), जिसे सॉफ्टवेयर विकास के लिए इंजीनियरिंग दृष्टिकोण के लिए डेवलपर्स और प्रबंधकों का ध्यान आकर्षित करने के लिए डिज़ाइन किया गया है। हाल ही में, उनके दृष्टिकोण और समर्थन साधनों में क्रांतिकारी बदलाव के बावजूद, उन्हें अवांछनीय रूप से अनदेखा किया गया है।
पहला लेख कुछ पाठकों को बहुत सारगर्भित लगा। कई लोग वास्तविकता के करीब स्थितियों में इंजीनियरिंग दृष्टिकोण और औपचारिक विनिर्देशों का उपयोग करने का एक उदाहरण देखना चाहते हैं।
इस लेख में, हम एक व्यावहारिक समस्या को हल करने के लिए TLA + के वास्तविक अनुप्रयोग का एक उदाहरण देखेंगे।
मैं सॉफ्टवेयर विकास से संबंधित मुद्दों पर चर्चा करने के लिए हमेशा खुला हूं, और मुझे पाठकों के साथ बातचीत करने में खुशी होगी (संचार के लिए निर्देशांक मेरी प्रोफाइल में हैं)।
TLA + क्या है?
शुरुआत करने के लिए, मैं टीएलए + और टीएलसी के बारे में कुछ शब्द कहना चाहता हूं।
TLA + (क्रियाओं का लौकिक तर्क + डेटा) एक औपचारिकता है जो एक प्रकार के लौकिक तर्क पर आधारित है। लेस्ली लामपोर्ट द्वारा डिज़ाइन किया गया।
इस औपचारिकता के ढांचे के भीतर, कोई भी सिस्टम व्यवहार वेरिएंट के स्थान और इन व्यवहारों के गुणों का वर्णन कर सकता है।
सादगी के लिए, हम यह मान सकते हैं कि सिस्टम के व्यवहार को उसके राज्यों के अनुक्रम (जैसे कि एक स्ट्रिंग पर अनंत मोती, गेंदें) द्वारा दर्शाया गया है, और TLA + सूत्र श्रृंखला के एक वर्ग को परिभाषित करता है जो सिस्टम के व्यवहार के सभी संभावित वेरिएंट्स (बड़ी संख्या में मोतियों) का वर्णन करता है।
टीएलए + गैर-नियतात्मक परिमित राज्य मशीनों (उदाहरण के लिए, एक सिस्टम में सेवाओं की बातचीत) का वर्णन करने के लिए अच्छी तरह से अनुकूल है, हालांकि इसकी स्पष्टता कई अन्य चीजों (जो पहले क्रम के तर्क में व्यक्त की जा सकती है) का वर्णन करने के लिए पर्याप्त है।
और टीएलसी एक स्पष्ट-राज्य मॉडल-चेकर है: एक प्रोग्राम जो किसी दिए गए टीएलए + सिस्टम विवरण और संपत्ति के सूत्रों के अनुसार, सिस्टम राज्यों पर पुनरावृत्त करता है और निर्धारित करता है कि सिस्टम निर्दिष्ट गुणों को संतुष्ट करता है या नहीं।
आमतौर पर, TLA + / TLC के साथ काम करना इस तरह से बनाया गया है: हम TLA + में सिस्टम का वर्णन करते हैं, TLA + में दिलचस्प गुणों को औपचारिक रूप देते हैं, सत्यापन के लिए TLC चलाते हैं।
चूंकि टीएलए + में अधिक या कम जटिल प्रणाली का सीधे वर्णन करना आसान नहीं है, इसलिए एक उच्च-स्तरीय भाषा का आविष्कार किया गया था - प्लसकाल, जो टीएलए + में अनुवाद करता है। PlusCal दो तरह से मौजूद है: पास्कल और C- जैसे सिंटैक्स के साथ। लेख में मैंने पास्कल-जैसे वाक्यविन्यास का उपयोग किया है, यह मुझे बेहतर पढ़ा जाता है। प्लस टीएलए + के संबंध में प्लसस लगभग उसी तरह है जैसे सी कोडांतरक के संबंध में।
यहां हम सिद्धांत में गहरे नहीं जाएंगे। लेख के अंत में टीएलए + / प्लसकाल / टीएलसी में विसर्जन के लिए साहित्य प्रदान किया गया है।
मेरा मुख्य कार्य टीएलए + / टीएलसी के आवेदन को एक सरल और समझने योग्य वास्तविक जीवन उदाहरण में दिखाना है।
पिछले लेख की कुछ टिप्पणियों में, मुझे फटकार लगाई गई थी कि मैंने उपकरणों की सैद्धांतिक नींव को चित्रित नहीं किया है, लेकिन लेखों की इस श्रृंखला का उद्देश्य सॉफ्टवेयर विकास में इंजीनियरिंग दृष्टिकोण के लिए उपकरणों के व्यावहारिक अनुप्रयोग को दिखाना था।
मुझे लगता है कि सिद्धांत में एक गहरी तल्लीनता किसी के लिए बहुत कम रुचि है, लेकिन अगर आप रुचि रखते हैं, तो आप हमेशा लिंक और स्पष्टीकरण के लिए पीएम तक जा सकते हैं, और जहां तक मुझे पर्याप्त ज्ञान है (आखिरकार, मैं एक सैद्धांतिक गणितज्ञ नहीं हूं, लेकिन एक सॉफ्टवेयर इंजीनियर हूं), मैं जवाब देने की कोशिश करूंगा ।
समस्या का बयान
पहले, मैं उस कार्य के बारे में थोड़ी बात करूंगा जिसके लिए TLA + का उपयोग किया गया था।
कार्य घटनाओं के प्रवाह को संसाधित करने से संबंधित है। अर्थात्, घटनाओं को संग्रहीत करने और इन घटनाओं के बारे में सूचनाएं भेजने के लिए एक कतार बनाने के लिए।
डेटा वेयरहाउस भौतिक रूप से PostgreSQL DBMS के आधार पर व्यवस्थित होता है।
मुख्य बात जिसे आप जानना चाहते हैं:
- घटनाओं के स्रोत हैं। हमारे उद्देश्यों के लिए, हम खुद को इस तथ्य तक सीमित कर सकते हैं कि प्रत्येक घटना उस समय तक विशेषता होती है जिसमें उसके प्रसंस्करण की योजना बनाई जाती है। ये स्रोत डेटाबेस को ईवेंट लिखते हैं। आमतौर पर, डेटाबेस को लिखने का समय और नियोजित प्रसंस्करण का समय किसी भी तरह से संबंधित नहीं है।
- समन्वय प्रक्रियाएं हैं जो डेटाबेस से घटनाओं को पढ़ती हैं और आगामी घटनाओं की सूचना सिस्टम के उन घटकों को भेजती हैं जिन्हें इन सूचनाओं का जवाब देना चाहिए।
- मौलिक आवश्यकता: हमें घटनाओं को नहीं खोना चाहिए। चरम मामलों में घटना की सूचना को दोहराया जा सकता है, अर्थात कम से कम एक बार गारंटी होनी चाहिए। वितरित प्रणालियों में, केवल एक बार गारंटी को लागू करना बेहद मुश्किल है (यह असंभव भी हो सकता है, लेकिन इसे साबित करने की आवश्यकता है) आम सहमति तंत्र के बिना, और वे (कम से कम सभी मुझे पता है) देरी और थ्रूपुट के संदर्भ में सिस्टम पर बहुत मजबूत प्रभाव डालते हैं।
अब कुछ विवरण:
- कई स्रोत प्रक्रियाएं हैं, वे एक संकीर्ण समय अंतराल में गिरने वाली घटनाओं के लाखों (सबसे खराब स्थिति में) उत्पन्न कर सकते हैं।
- घटनाओं को भविष्य के लिए और पिछले समय के लिए उत्पन्न किया जा सकता है (उदाहरण के लिए, यदि स्रोत प्रक्रिया धीमी हो गई है और एक पल के लिए एक घटना दर्ज की गई है जो पहले ही बीत चुका है)।
- ईवेंट प्रोसेसिंग की प्राथमिकता समय पर होती है, यानी हमें सबसे पहले ईवेंट को प्रोसेस करना चाहिए।
- प्रत्येक घटना के लिए, स्रोत प्रक्रिया एक यादृच्छिक संख्या कार्यकर्ता_आईडी उत्पन्न करती है , जिसके कारण घटनाओं को समन्वयकों के बीच वितरित किया जाता है।
- कई समन्वय प्रक्रियाएं हैं (सिस्टम लोड के आधार पर जरूरतों के अनुसार तराजू)।
- प्रत्येक समन्वयक प्रक्रिया अपने स्वयं के सेट कार्यकर्ता_आईडी के लिए घटनाओं की प्रक्रिया करता है, अर्थात, कार्यकर्ता_एड के कारण , हम समन्वयकों और ताले की आवश्यकता के बीच प्रतिस्पर्धा से बचते हैं।
जैसा कि विवरण से देखा जा सकता है, हम केवल एक समन्वय प्रक्रिया पर विचार कर सकते हैं और अपने कार्य में कार्यकर्ता_द को ध्यान में नहीं रखते हैं।
यही कारण है कि, सादगी के लिए, हम मानते हैं कि:
- कई स्रोत प्रक्रियाएं हैं।
- समन्वय प्रक्रिया एक है।
मैं इस समस्या को चरणों में हल करने के विचार के विकास का वर्णन करूंगा, ताकि यह अधिक समझ में आए कि कैसे एक सरल कार्यान्वयन से एक अनुकूलित एक तक विचार विकसित हुआ।
माथे का फैसला
हम उन घटनाओं के लिए एक प्लेट बनाएंगे जहां हम घटनाओं को सिर्फ टाइमस्टैम्प के रूप में संग्रहीत करेंगे (हम इस कार्य में अन्य मापदंडों में रुचि नहीं रखते हैं)। आइए टाइमस्टैम्प क्षेत्र पर एक इंडेक्स बनाएं ।
यह पूरी तरह से सामान्य समाधान लगता है।
केवल स्केलेबिलिटी के साथ एक समस्या है: अधिक घटनाएँ, डेटाबेस संचालन धीमा।
घटनाएँ पिछले समय के लिए आ सकती हैं, इसलिए समन्वयक को लगातार पूरे समयरेखा की समीक्षा करनी होगी।
समय-समय पर डेटाबेस को शार्क द्वारा तोड़कर समस्या को बड़े पैमाने पर हल किया जा सकता है, लेकिन यह एक संसाधन-गहन तरीका है।
नतीजतन, समन्वयकों का काम धीमा हो जाएगा, क्योंकि आपको कई डेटाबेस से डेटा पढ़ना और संयोजित करना होगा।
समन्वयक में ईवेंट कैशिंग को लागू करना मुश्किल है, ताकि प्रत्येक घटना को संसाधित करने के लिए आधारों पर न जाएं।
अधिक डेटाबेस - अधिक दोष सहिष्णुता मुद्दे।
और इसी तरह।
हम इस ललाट समाधान पर विस्तार से ध्यान नहीं देंगे, क्योंकि यह तुच्छ और अविरल है।
पहला अनुकूलन
आइए देखें कि ललाट समाधान को कैसे बेहतर बनाया जाए।
डेटाबेस तक पहुंच को अनुकूलित करने के लिए, आप सूचकांक को थोड़ा जटिल कर सकते हैं, डेटाबेस में लेनदेन करते समय उत्पन्न होने वाली घटनाओं के लिए एक नीरस बढ़ती पहचानकर्ता जोड़ सकते हैं। यही है, अब इस घटना को जोड़ी {समय, आईडी} की विशेषता है , जहां वह समय है जिस पर कार्यक्रम निर्धारित है, आईडी एक नीरस रूप से बढ़ते काउंटर है। प्रत्येक घटना के लिए आईडी की विशिष्टता की गारंटी है, लेकिन इस बात की कोई गारंटी नहीं है कि आईडी मान बिना छेद के चलते हैं (अर्थात, ऐसा कोई अनुक्रम हो सकता है: 1 , 2 , 7 , 15 )।
ऐसा लगता है कि अब हम समन्वयक प्रक्रिया में अंतिम रीड इवेंट के पहचानकर्ता को संग्रहीत कर सकते हैं और, लाते समय, अंतिम संसाधित इवेंट की तुलना में पहचानकर्ताओं के साथ घटनाओं का चयन कर सकते हैं।
लेकिन यहां समस्या तुरंत पॉप हो जाती है: स्रोत प्रक्रियाएं भविष्य में एक टाइमस्टैम्प के साथ एक घटना रिकॉर्ड कर सकती हैं। तब हमें लगातार समन्वय प्रक्रिया में छोटे पहचानकर्ताओं के साथ घटनाओं के सेट को ध्यान में रखना होगा, जिसके प्रसंस्करण समय अभी तक नहीं आया है।
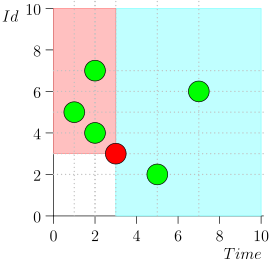
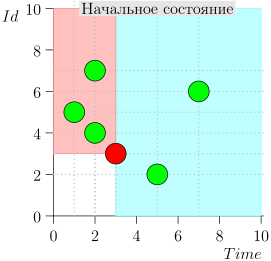
आप देख सकते हैं कि वर्तमान समय के सापेक्ष घटनाओं को दो वर्गों में विभाजित किया गया है:
- टाइमस्टैम्प घटनाओं अतीत में, लेकिन एक बड़े पहचानकर्ता के साथ। वे डेटाबेस के लिए हाल ही में लिखे गए थे, जब हमने उस समय अंतराल को संसाधित किया। ये उच्च प्राथमिकता वाली घटनाएँ हैं, और उन्हें पहले संसाधित करने की आवश्यकता है ताकि अधिसूचना - जो पहले से ही देर हो चुकी है - देर नहीं हुई है।
- वर्तमान समय के करीब समय टिकटों के साथ एक बार दर्ज की गई घटनाएँ। इस तरह के आयोजनों की पहचान कम होगी।
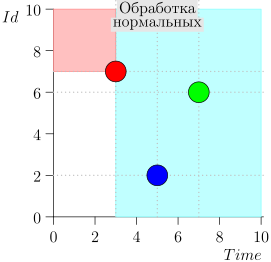
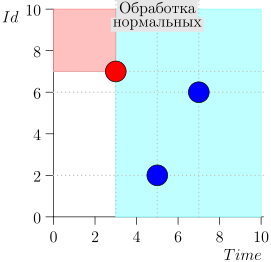
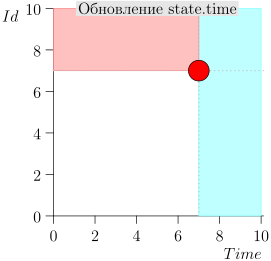
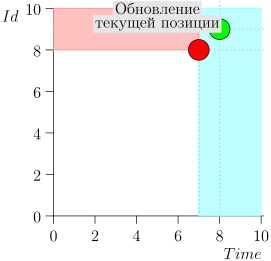
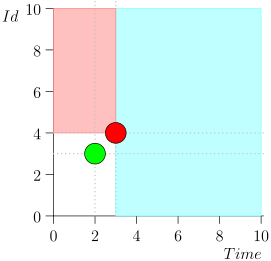
तदनुसार, समन्वयक प्रक्रिया की वर्तमान स्थिति को जोड़ी {state.time, state.id} की विशेषता है।
यह पता चलता है कि उच्च-प्राथमिकता वाली घटनाएं इस बिंदु (गुलाबी क्षेत्र) के बाईं और ऊपर हैं, और सामान्य घटनाएं दाईं ओर (हल्की नीली) हैं:
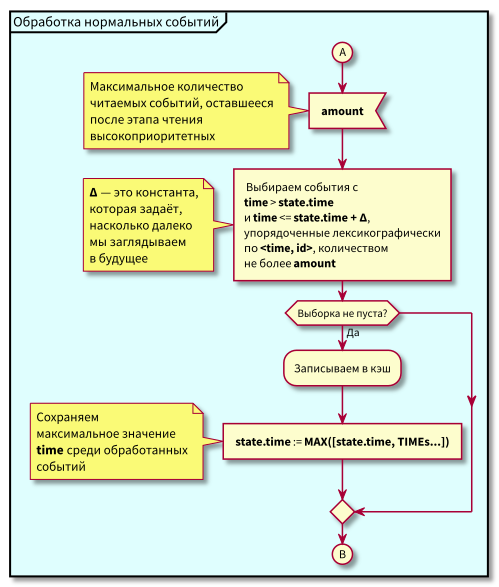
फ्लो चार्ट
समन्वयक कार्य एल्गोरिथ्म इस प्रकार है:
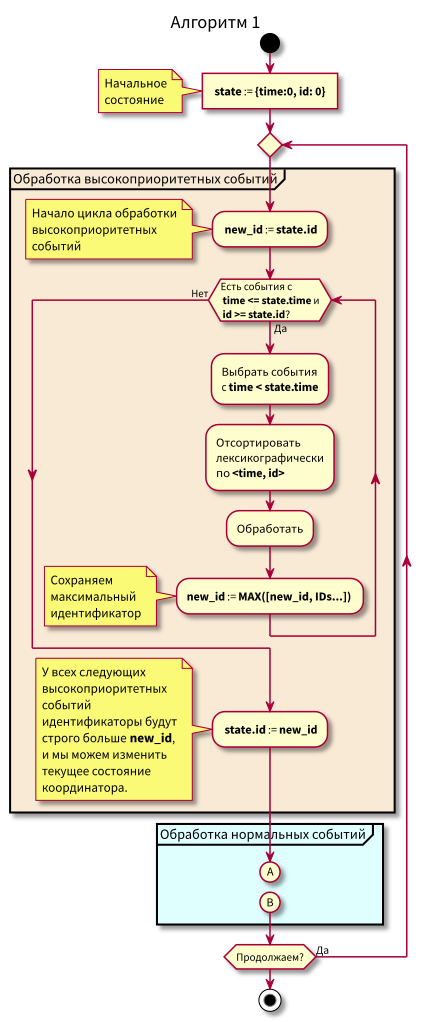
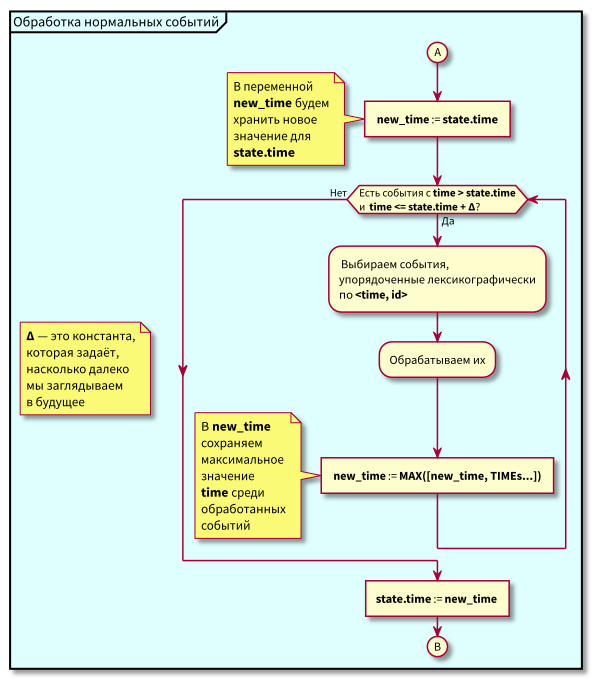
एल्गोरिथ्म का अध्ययन करते समय, प्रश्न उत्पन्न हो सकते हैं:
- क्या होगा अगर सामान्य घटनाओं का प्रसंस्करण शुरू होता है और उस समय अतीत में नई घटनाएं आती हैं (गुलाबी क्षेत्र में), तो क्या वे खो नहीं जाएंगे? उत्तर: उन्हें उच्च-प्राथमिकता वाली घटनाओं के प्रसंस्करण के अगले चक्र में संसाधित किया जाएगा। वे खो नहीं सकते हैं, क्योंकि उनकी आईडी राज्य से अधिक होने की गारंटी है।
- क्या होगा अगर सभी सामान्य घटनाओं को संसाधित करने के बाद - उच्च-प्राथमिकता वाली घटनाओं को संसाधित करने के लिए स्विचिंग के समय - अंतराल से समय टिकटों के साथ नई घटनाएं [राज्य। समय, राज्य.समय + डेल्टा] पहुंचें, तो क्या हम उन्हें खो देते हैं? उत्तर: वे गुलाबी क्षेत्र में गिरेंगे, क्योंकि उनके पास समय होगा <state.time और id > state.id: वे हाल ही में पहुंचे, और आईडी नीरस रूप से बढ़ रही है।
एल्गोरिथम ऑपरेशन उदाहरण
आइए एल्गोरिथ्म के कुछ चरणों को देखें:
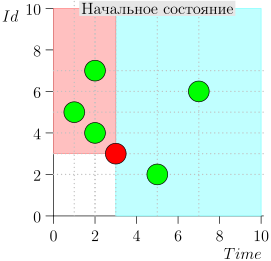
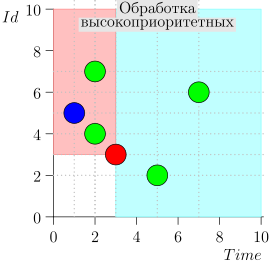
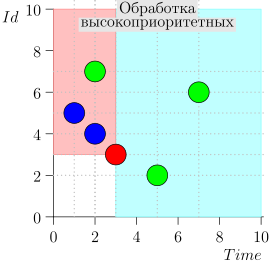
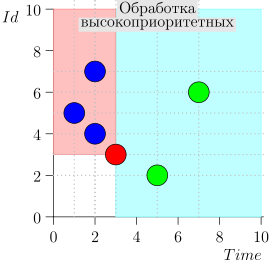
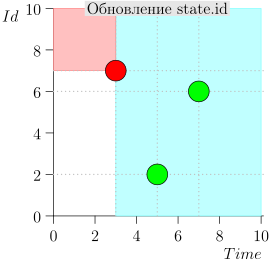
आदर्श
हम यह सुनिश्चित करेंगे कि एल्गोरिथ्म घटनाओं को याद नहीं करता है और सभी सूचनाएं भेजी जाएंगी: हम एक सरल मॉडल की रचना करेंगे और इसे सत्यापित करेंगे।
मॉडल के लिए हम TLA + का उपयोग करते हैं, अधिक सटीक रूप से PlusCal, जो TLA + में अनुवाद करता है।
---------------- MODULE events ---------------- EXTENDS Naturals, FiniteSets, Sequences, TLC (* --algorithm Events \* \* (by Daniel Jackson) \* small-scope hypothesis, \* , ́ \* \* \* : \* Events - - , \* [time, id], \* \* \* \* Event_Id - \* id \* MAX_TIME - , \* \* TIME_DELTA - Delta, \* \* variables Events = {}, Event_Id = 0, MAX_TIME = 5, TIME_DELTA \in 1..3 define \* \* ZERO_EVT == [time |-> 0, id |-> 0] MAX(S) == CHOOSE x \in S: \A y \in S: y <= x MIN(S) == CHOOSE x \in S: \A y \in S: y >= x \* fold_left/fold_right RECURSIVE SetReduce(_, _, _) SetReduce(Op(_, _), S, value) == IF S = {} THEN value ELSE LET s == CHOOSE s \in S : TRUE IN SetReduce(Op, S \ {s}, Op(s, value)) (* ( ) *) ToSeq(S) == LET op(e, val) == Append(val, e) IN SetReduce(op, S, << >>) (* : *) ToSet(S) == {S[i] : i \in DOMAIN(S)} (* map *) MapSet(Op(_), S) == {Op(x) : x \in S} (* *) \* id GetIds(Evts) == MapSet(LAMBDA x: x.id, Evts) \* time GetTimes(Evts) == MapSet(LAMBDA x: x.time, Evts) (* SQL *) \* \* ORDER BY EventsOrderByTime(e1, e2) == e1.time < e2.time EventsOrderById(e1, e2) == e1.id < e2.id EventsOrder(e1, e2) == \* time, id \/ EventsOrderByTime(e1, e2) \/ /\ e1.time = e2.time /\ EventsOrderById(e1, e2) \* SELECT * FROM events \* WHERE time <= curr_time AND id >= max_id \* ORDER BY time, id SELECT_HIGH_PRIO(state) == LET \* \* time <= curr_time \* AND id >= maxt_id selected == {e \in Events : /\ e.time <= state.time /\ e.id >= state.id } IN selected \* SELECT * FROM events \* WHERE time > current_time AND time - Time <= delta_time \* ORDER BY time, id SELECT_NORMAL(state, delta_time) == LET selected == {e \in Events : /\ e.time <= state.time + delta_time /\ e.time > state.time } IN selected \* Safety predicate \* ALL_EVENTS_PROCESSED(state) == \A e \in Events: \/ e.time >= state.time \/ e.id >= state.id end define; \* - fair process inserter = "Sources" variable n, t; begin forever: while TRUE do \* get_time: \* \* , , \* with evt_time \in 0..MAX_TIME do t := evt_time; end with; \* ; \* : \* 1. . \* 2. , \* Event_Id - , \* commit: \* either - either Events := Events \cup {[time |-> t, id |-> Event_Id]} || Event_Id := Event_Id + 1; or Event_Id := Event_Id + 1; end either; end while; end process fair process coordinator = "Coordinator" variable state = ZERO_EVT, events = {}; begin forever: while TRUE do \* high_prio: events := SELECT_HIGH_PRIO(state); \* process_high_prio: \* , \* Events, \* state.id := MAX({state.id} \union GetIds(events)) || \* , \* Events := Events \ events || \* events , \* events := {}; \* - normal: events := SELECT_NORMAL(state, TIME_DELTA); process_normal: state.time := MAX({state.time} \union GetTimes(events)) || Events := Events \ events || events := {}; end while; end process end algorithm; *) \* BEGIN TRANSLATION \* TLA+, PlusCal \* END TRANSLATION ================================
जैसा कि आप देख सकते हैं, विवरण अपेक्षाकृत छोटा है, परिभाषाओं के अधिक स्पष्ट खंड (परिभाषित) के बावजूद, जिसे एक अलग मॉड्यूल में निकाला जा सकता है, और फिर पुन: उपयोग किया जा सकता है।
टिप्पणियों में मैंने यह समझाने की कोशिश की कि मॉडल में क्या हो रहा है। यह आशा है
मैं कामयाब रहा और मॉडल को और अधिक विस्तार से चित्रित करने की आवश्यकता नहीं है।
मैं केवल राज्यों और मॉडलिंग सुविधाओं के बीच संक्रमण की परमाणुता के बारे में एक बिंदु स्पष्ट करना चाहूंगा।
प्रक्रियाओं के परमाणु चरणों का प्रदर्शन करके मॉडलिंग की जाती है। एक संक्रमण में, एक प्रक्रिया का एक परमाणु चरण किया जाता है जिसमें यह चरण किया जा सकता है। कदम और प्रक्रिया का विकल्प गैर-निर्धारक है: मॉडलिंग के दौरान, सभी प्रक्रियाओं के परमाणु चरणों की सभी संभावित श्रृंखलाओं को क्रमबद्ध किया जाता है।
सवाल उठ सकता है: मॉडलिंग के बारे में क्या सच है, जब हम एक साथ विभिन्न प्रक्रियाओं में कई परमाणु कदम उठाते हैं?
इस सवाल का लेस्ली लामपोर्ट लंबे समय से पुस्तक निर्दिष्ट सिस्टम और अन्य कार्यों में उत्तर दिया गया है।
मैं उत्तर को पूरी तरह से उद्धृत नहीं करूंगा, संक्षेप में सार यह है: यदि कोई सटीक समय पैमाना नहीं है जहां प्रत्येक घटना एक विशिष्ट क्षण से बंधी है, तो समानांतर घटनाओं को मॉडलिंग में कोई अंतर नहीं है क्योंकि गैर-नियतात्मक घटने वाले अनुक्रमिक होते हैं, क्योंकि हम हमेशा मान सकते हैं कि एक घटना दूसरे से पहले हुई थी infinitesimal value।
लेकिन जो वास्तव में महत्वपूर्ण है वह है परमाणु कदमों का सक्षम आवंटन। यदि उनमें से बहुत सारे हैं, तो राज्य अंतरिक्ष का एक दहनशील विस्फोट होगा। यदि आप आवश्यक से कम कदम उठाते हैं, या गलत तरीके से उनका चयन करते हैं - अर्थात, अमान्य स्थिति / परिवर्तन (यानी, हम मॉडल पर त्रुटियों को याद करेंगे) की संभावना गायब है।
परमाणु चरणों में प्रक्रियाओं को सही ढंग से तोड़ने के लिए, आपको यह विचार करने की आवश्यकता है कि डेटा और सिंक्रनाइज़ेशन तंत्र पर प्रक्रियाओं की निर्भरता के संदर्भ में सिस्टम कैसे काम करता है।
एक नियम के रूप में, परमाणु चरणों में प्रक्रियाओं को विभाजित करने से बड़ी समस्याएं नहीं होती हैं। और अगर ऐसा होता है, तो यह समस्या की समझ की कमी को दर्शाता है, न कि मॉडल को संकलित करने और टीएलई + विनिर्देश लिखने के साथ समस्याओं के बारे में। यह औपचारिक विनिर्देशों की एक और बहुत उपयोगी विशेषता है: उन्हें गहन अध्ययन और विश्लेषण की आवश्यकता होती है।
एक समस्या। एक नियम के रूप में, यदि कार्य सार्थक और अच्छी तरह से समझा जाता है, तो इसकी औपचारिकता के साथ कोई समस्या नहीं है।
मॉडल की जाँच
मॉडलिंग के लिए मैं टीएलए-टूलबॉक्स का उपयोग करूंगा। आप बेशक, कमांड लाइन से सब कुछ चला सकते हैं, लेकिन आईडीई अभी भी अधिक सुविधाजनक है, खासकर टीएलए + का उपयोग करके मॉडलिंग के बारे में सीखना शुरू करना।
परियोजना के निर्माण को मैनुअल, लेख और पुस्तकों में अच्छी तरह से वर्णित किया गया है, जिनके लिंक मैंने लेख के अंत में उद्धृत किए थे, इसलिए मैं खुद को नहीं दोहराऊंगा। केवल एक चीज जो मैं आपका ध्यान आकर्षित करूंगा वह है सिमुलेशन सेटिंग्स।
टीएलसी एक मॉडल चेकर है जिसमें स्पष्ट राज्य की जाँच है। यह स्पष्ट है कि राज्य का स्थान उचित सीमा तक सीमित होना चाहिए। एक तरफ, यह उन संपत्तियों को सत्यापित करने में काफी बड़ा होना चाहिए जो हमारे लिए रुचि रखते हैं, और दूसरी ओर, सिमुलेशन के लिए पर्याप्त छोटे हैं जो स्वीकार्य संसाधनों का उपयोग करके एक स्वीकार्य समय में पूरा किया जा सकता है।
यह एक बहुत ही नाजुक बिंदु है, यहां आपको सिस्टम और मॉडल के गुणों को समझने की आवश्यकता है। लेकिन यह जल्दी से अनुभव के साथ आता है। शुरुआत के लिए, आप बस अधिकतम संभव सीमाएं निर्धारित कर सकते हैं जो अभी भी सिमुलेशन समय और उपभोग किए गए संसाधनों के संदर्भ में स्वीकार्य हैं।
पूरे राज्य के स्थान की नहीं, बल्कि एक निश्चित गहराई तक चयनात्मक श्रृंखलाओं की जाँच करने की भी एक विधा है। यह कभी-कभी संभव और उपयोग करने के लिए आवश्यक भी है।
हम सिमुलेशन सेटिंग्स पर लौटते हैं।
सबसे पहले, हम सिस्टम के राज्य स्थान पर प्रतिबंध को परिभाषित करते हैं। सीमाएं उन्नत विकल्प / राज्य बाधा सिमुलेशन सेटिंग अनुभाग में सेट की गई हैं।
वहाँ मैंने एक TLA + अभिव्यक्ति का संकेत दिया: Cardinality(Events) <= 5 /\ Event_Id <= 5 ,
जहां Event_Id ईवेंट आइडेंटिफ़ायर के मान पर ऊपरी सीमा है, कार्डिनैलिटी Cardinality(Events) इवेंट रिकॉर्ड्स के सेट का आकार (सीमित मॉडल सीमित करता है)
एक प्लेट में पांच रिकॉर्ड द्वारा डेटा)।
सिमुलेशन में, टीएलसी केवल उन राज्यों को देखेगा जिनमें यह सूत्र सत्य है।
आप अभी भी मान्य राज्य परिवर्तन ( उन्नत विकल्प / कार्रवाई बाधा ) की अनुमति दे सकते हैं,
लेकिन हमें इसकी आवश्यकता नहीं है।
इसके बाद, हम TLA + सूत्र को इंगित करते हैं जो हमारी प्रणाली का वर्णन करता है: मॉडल अवलोकन / टेम्पोरल फॉर्मूला = Spec , जहां प्लस प्लसल द्वारा निर्दिष्ट TLA + सूत्र का नाम ऑटोगेनलेट है (ऊपर दिए गए मॉडल कोड में यह नहीं है: अंतरिक्ष को बचाने के लिए, मैंने प्लससीएल को टीएलए + में अनुवाद करने का परिणाम नहीं बताया है) ।
ध्यान देने योग्य अगली सेटिंग गतिरोध जांच है।
( मॉडल अवलोकन / डेडलॉक में चेकमार्क)। जब यह ध्वज सक्षम हो जाता है, तो TLC "हैंगिंग" राज्यों के लिए मॉडल की जाँच करेगा, यानी उनमें से कोई भी आउटगोइंग ट्रांज़िशन नहीं होगा। यदि राज्य स्थान में ऐसे राज्य हैं, तो इसका मतलब मॉडल में स्पष्ट त्रुटि है। या टीएलसी में, जो किसी अन्य गैर-तुच्छ कार्यक्रम की तरह, त्रुटियों से प्रतिरक्षा नहीं है :) मेरे (इतने बड़े) अभ्यास में, मैंने अभी तक गतिरोध का सामना नहीं किया है।
और अंत में, जिसके लिए यह सब परीक्षण शुरू किया गया था, मॉडल ओवरव्यू / ALL_EVENTS_PROCESSED(state) = ALL_EVENTS_PROCESSED(state) में सुरक्षा सूत्र।
टीएलसी प्रत्येक राज्य में सूत्र की वैधता को सत्यापित करेगा, और यदि यह गलत हो जाता है,
एक त्रुटि संदेश प्रदर्शित करेगा और उन राज्यों के अनुक्रम को दिखाएगा जो त्रुटि का कारण बने।
टीएलसी शुरू करने के बाद, लगभग 8 मिनट तक काम करने के बाद, इसने "नो एरर्स" की सूचना दी। इसका मतलब है कि मॉडल का परीक्षण किया गया है और निर्दिष्ट गुणों को पूरा करता है।
टीएलसी भी कई दिलचस्प आंकड़े प्रदर्शित करता है। उदाहरण के लिए, इस मॉडल के लिए, 7 677 824 अद्वितीय राज्य प्राप्त हुए थे, कुल मिलाकर, टीएलसी ने 27 109 029 राज्यों को देखा, राज्य स्थान का व्यास 47 है (पुनरावृत्ति से पहले यह राज्य श्रृंखला की अधिकतम लंबाई है,)
राज्य और संक्रमण ग्राफ में गैर-दोहराए जाने वाले राज्यों से अधिकतम चक्र की लंबाई)।
यदि हम 27 मिलियन राज्यों को 8 मिनट में विभाजित करते हैं, तो हमें प्रति सेकंड लगभग 56 हजार राज्य मिलते हैं, जो बहुत तेज़ नहीं लग सकते हैं। लेकिन ध्यान रखें कि मैंने एक लैपटॉप पर सिमुलेशन चलाया था जो ऊर्जा-बचत मोड में काम करता था (मैंने कोर आवृत्ति को 800 मेगाहर्ट्ज के लिए मजबूर किया, क्योंकि मैं उस पल में एक इलेक्ट्रिक ट्रेन में यात्रा कर रहा था), और सिमुलेशन गति के लिए मॉडल का बिल्कुल भी अनुकूलन नहीं किया।
सिमुलेशन को गति देने के कई तरीके हैं: TLA + मॉडल कोड के हिस्से को जावा में पोर्ट करने और फ्लाई पर TLC से कनेक्ट करने के लिए (यह उपयोगी है कि सभी प्रकार के सहायक कार्यों को गति देने के लिए) बादलों में और TLC को चलाने के लिए (Amazon और Azure क्लाउड समर्थन TLC में ही बनाया गया है)।
दूसरा अनुकूलन
पिछले एल्गोरिथ्म में, कुछ समस्याओं को छोड़कर, सब कुछ ठीक है:
- जब तक हम अंतराल
[state.time, state.time + Delta] में ब्लू ज़ोन से सभी घटनाओं को संसाधित नहीं करते हैं, तब तक हम उच्च-प्राथमिकता वाले इवेंट पर नहीं जा सकते। यानी देर से होने वाली घटनाएं और भी देर से होंगी। और आमतौर पर देरी अप्रत्याशित होती है। इस वजह से, state.time वर्तमान समय से काफी पिछड़ सकती है, और यह अगली समस्या का कारण है। - सामान्य घटनाओं के क्षेत्र में आने वाली घटनाएं देर से हो सकती हैं ( आईडी > स्टेट.ड)। वे पहले से ही उच्च प्राथमिकता वाले हैं और गुलाबी क्षेत्र से घटनाओं पर विचार किया जाना चाहिए, और हम अभी भी उन्हें सामान्य मानते हैं और उन्हें सामान्य मानते हैं।
- ईवेंट कैशिंग और कैश पुनःपूर्ति (डेटाबेस से पढ़ना) को व्यवस्थित करना मुश्किल है।
यदि पहले दो अंक स्पष्ट हैं, तो तीसरा संभवत: सबसे अधिक प्रश्न उठाएगा। आइए हम इस पर अधिक विस्तार से ध्यान दें।
मान लीजिए कि हम पहले निश्चित संख्या में घटनाओं को स्मृति में पढ़ना चाहते हैं और फिर उन्हें संसाधित करते हैं।
प्रसंस्करण के बाद, हम संसाधित किए गए ब्लॉक प्रश्नों के साथ डेटाबेस में घटनाओं को चिह्नित करना चाहते हैं, क्योंकि यदि आप ब्लॉक के साथ नहीं, बल्कि एकल घटनाओं के साथ काम करते हैं, तो कैशिंग से कोई बड़ा लाभ नहीं होगा।
मान लीजिए कि हमने ब्लॉकों का हिस्सा संसाधित कर दिया है और कैश को पूरक करना चाहते हैं। फिर, यदि देर से उच्च प्राथमिकता वाली घटनाएं प्रसंस्करण के दौरान आती हैं, तो हम उन्हें जल्दी संसाधित कर सकते हैं।
यही है, देर से लोगों को जल्दी से जल्दी संसाधित करने के लिए छोटे ब्लॉकों में घटनाओं को पढ़ने में सक्षम होना बहुत ही वांछनीय है, लेकिन एक बार में बड़े ब्लॉकों के साथ डेटाबेस में प्रसंस्करण विशेषता को अपडेट करने के लिए - दक्षता के लिए।
इस मामले में क्या करना है?
एक नीले और गुलाबी क्षेत्र के साथ छोटे ब्लॉकों में डेटाबेस के साथ काम करने का प्रयास करें और छोटे चरणों में राज्य बिंदु को स्थानांतरित करें।
इस प्रकार, कैश को डेटा के डेटाबेस टुकड़ों से पेश किया गया था और उसमें पढ़ा गया था, प्रत्येक पढ़ने के बाद, राज्य बिंदु को स्थानांतरित कर दिया गया था ताकि पहले से पढ़ी गई घटनाओं को फिर से पढ़ने के लिए न हो।
अब एल्गोरिथ्म थोड़ा और जटिल हो गया है, हमने सीमित भागों में पढ़ना शुरू किया।
फ्लो चार्ट
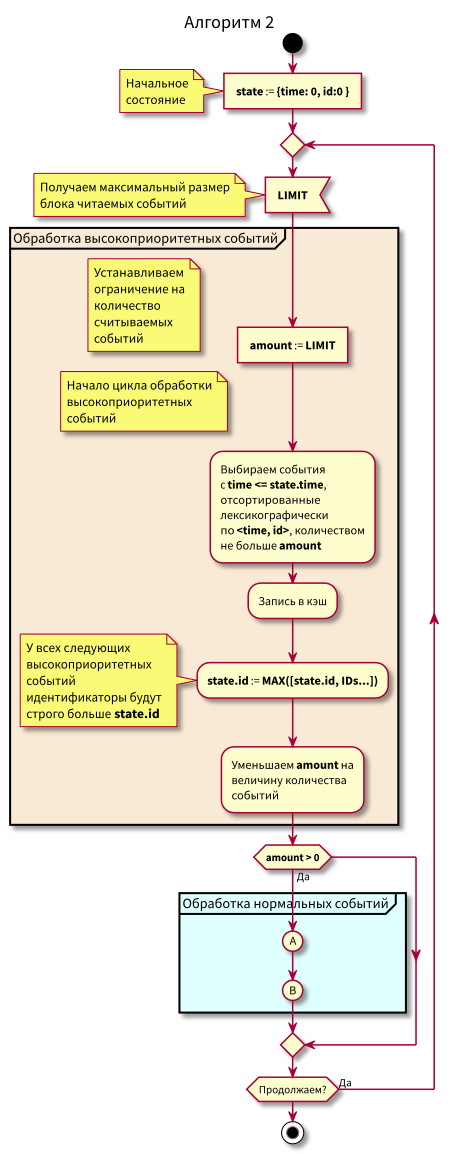
इस एल्गोरिथ्म में, यह देखा जा सकता है कि पठनीय घटनाओं के ब्लॉक पर प्रतिबंध के कारण, कम प्राथमिकता वाले प्रसंस्करण से उच्च प्राथमिकता वाले प्रसंस्करण में संक्रमण में अधिकतम देरी ब्लॉक के अधिकतम प्रसंस्करण समय के बराबर होगी।
यही है, अब हम दोनों घटनाओं को छोटे खंडों में कैश में पढ़ सकते हैं, और पढ़ने के लिए अधिकतम ब्लॉक आकार को नियंत्रित करने के माध्यम से उच्च-प्राथमिकता वाली घटनाओं को संसाधित करने के लिए संक्रमण में अधिकतम देरी को नियंत्रित कर सकते हैं।
एल्गोरिथम ऑपरेशन उदाहरण
आइए एल्गोरिदम को काम में देखें, चरणों में। सुविधा के लिए, LIMIT = 2 ।
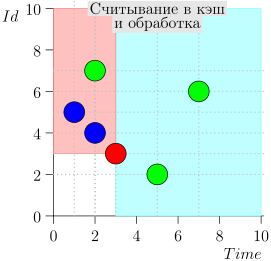
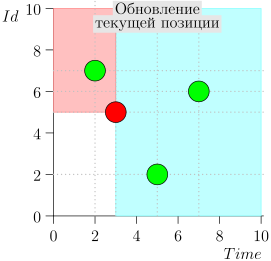
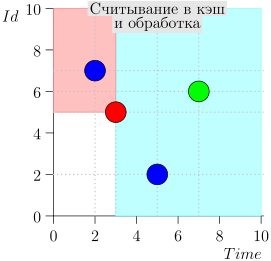
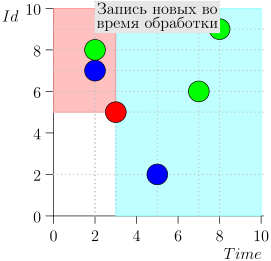
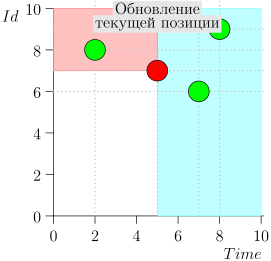
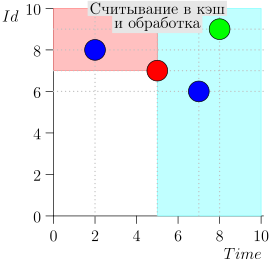
यह पता चला समस्या हल हो गई है? लेकिन नहीं। (यह स्पष्ट है कि यदि इस स्तर पर समस्या पूरी तरह से हल हो गई थी, तो
यह लेख नहीं होगा :))
त्रुटि?
इस रूप में, एल्गोरिथ्म ने लंबे समय तक काम किया। टेस्ट सब ठीक चला। उत्पादन में भी कोई समस्या नहीं थी।
लेकिन एल्गोरिथ्म के डेवलपर और इसके कार्यान्वयन (मेरे सहयोगी पीटर रेजनिकोव) बहुत अनुभवी हैं, और उन्होंने सहजता से महसूस किया कि यहां कुछ गलत था। इसलिए, मुख्य कोड के बगल में एक चेकर बनाया गया था, जो टाइमर पर एक बार चेक करता था कि क्या कोई मिस्ड इवेंट था और
यदि कोई हो, मैंने उन्हें संसाधित किया।
इस रूप में, सिस्टम ने सफलतापूर्वक काम किया। सच है, किसी ने भी चेकर द्वारा चयनित घटनाओं की संख्या पर आंकड़े नहीं रखे। इसलिए, दुर्भाग्य से, हम नहीं जानते कि असामयिक घटना प्रसंस्करण के साथ कितनी विफलताएं जुड़ी थीं।
मैंने समयबद्ध वस्तुओं की एक समान कतार को लागू किया। पीटर रेजनिकोव के साथ एल्गोरिदम के कार्यान्वयन और अनुकूलन पर चर्चा करते हुए, हमने घटनाओं के साथ काम करने के लिए इस एल्गोरिदम के बारे में बात की। उन्होंने संदेह किया कि एल्गोरिथ्म सही है। हमने संदेह की पुष्टि करने या उन्हें दूर करने के लिए एक छोटा मॉडल बनाने का फैसला किया। नतीजतन, हमें एक गलती मिली।
आदर्श
त्रुटि के साथ ट्रेस को हटाने से पहले, मैं उस मॉडल का स्रोत कोड दूंगा जिस पर त्रुटि का पता चला था।
पिछले मॉडल से अंतर बहुत छोटा है, रीड ब्लॉक के आकार पर केवल एक सीमा है: सीमा ऑपरेटर को जोड़ा जाता है और, तदनुसार, ईवेंट चयन ऑपरेटरों को बदल दिया जाता है।
अंतरिक्ष को बचाने के लिए, मैंने केवल मॉडल के परिवर्तित भागों पर टिप्पणियां छोड़ दीं।
---------------- MODULE events ---------------- EXTENDS Naturals, FiniteSets, Sequences, TLC (* --algorithm Events \* LIMIT, \* \* \* variables Events = {}, Event_Id = 0, MAX_TIME = 5, LIMIT \in 1..3, TIME_DELTA \in 1..2 define ZERO_EVT == [time |-> 0, id |-> 0] MAX(S) == CHOOSE x \in S: \A y \in S: y <= x MIN(S) == CHOOSE x \in S: \A y \in S: y >= x RECURSIVE SetReduce(_, _, _) SetReduce(Op(_, _), S, value) == IF S = {} THEN value ELSE LET s == CHOOSE s \in S : TRUE IN SetReduce(Op, S \ {s}, Op(s, value)) ToSeq(S) == LET op(e, val) == Append(val, e) IN SetReduce(op, S, << >>) ToSet(S) == {S[i] : i \in DOMAIN(S)} MapSet(Op(_), S) == {Op(x) : x \in S} GetIds(Evts) == MapSet(LAMBDA x: x.id, Evts) GetTimes(Evts) == MapSet(LAMBDA x: x.time, Evts) EventsOrderByTime(e1, e2) == e1.time < e2.time EventsOrderById(e1, e2) == e1.id < e2.id EventsOrder(e1, e2) == \/ EventsOrderByTime(e1, e2) \/ /\ e1.time = e2.time /\ EventsOrderById(e1, e2) Limit(S, limit) == LET amount == MIN({limit, Len(S)}) result == IF amount > 0 THEN SubSeq(S, 1, amount) ELSE << >> IN result \* SELECT * FROM events \* WHERE time <= curr_time AND id > max_id \* ORDER BY id \* LIMIT limit SELECT_HIGH_PRIO(state, limit) == LET selected == {e \in Events : /\ e.time <= state.time /\ e.id >= state.id } \* Id sorted == SortSeq(ToSeq(selected), EventsOrderById) \* limited == Limit(sorted, limit) IN ToSet(limited) \* SELECT * FROM events \* WHERE time > current_time \* AND time - Time <= delta_time \* ORDER BY time, id \* LIMIT limit SELECT_NORMAL(state, delta_time, limit) == LET selected == {e \in Events: /\ e.time <= state.time + delta_time /\ e.time > state.time } \* sorted == SortSeq(ToSeq(selected), EventsOrder) \* limited == Limit(sorted, limit) IN ToSet(limited) ALL_EVENTS_PROCESSED(state) == \A e \in Events: \/ e.time >= state.time \/ e.id >= state.id end define; fair process inserter = "Sources" variable t; begin forever: while TRUE do get_time: with evt_time \in 0..MAX_TIME do t := evt_time; end with; commit: either Events := Events \union {[time |-> t, id |-> Event_Id]} || Event_Id := Event_Id + 1; or Event_Id := Event_Id + 1; end either; end while; end process fair process event_processor = "Event_processor" variable state = ZERO_EVT, events = {}; begin forever: while TRUE do select: events := LET evts_high_prio == SELECT_HIGH_PRIO(state, LIMIT) new_limit == LIMIT - Cardinality(evts_high_prio) evts_normal == SELECT_NORMAL(state, TIME_DELTA, new_limit) IN evts_high_prio \union evts_normal; proc_evts: Events := Events \ events || state := [ time |-> MAX({state.time} \union GetTimes(events)), id |-> MAX({state.id} \union GetIds(events))] || events := {}; end while; end process end algorithm; *) \* BEGIN TRANSLATION \* TLA+, PlusCal \* END TRANSLATION ===================================================
एक चौकस पाठक यह नोटिस कर सकता है कि, लिमिट को शुरू करने के अलावा, घटना_प्रोसेसर में लेबल भी बदल दिए गए हैं। लक्ष्य वास्तविक कोड का अनुकरण करने के लिए थोड़ा बेहतर है कि एक लेनदेन में दो चयन निष्पादित होते हैं, अर्थात, घटनाओं का चयन परमाणु प्रदर्शन किया जा सकता है।
ठीक है, और अगर हमें बड़े परमाणु संचालन वाले मॉडल में कोई त्रुटि मिलती है, तो यह व्यावहारिक रूप से गारंटी देता है कि एक ही मॉडल में एक ही त्रुटि होती है, लेकिन छोटे परमाणु चरणों के साथ (बल्कि एक मजबूत बयान, लेकिन मुझे लगता है कि यह सहज है; हालांकि यह अच्छा होना चाहिए अगर साबित नहीं किया जाता है, तो मॉडल के एक विस्तृत चयन पर जांच की जाती है)।
मॉडल की जाँच
हम सिमुलेशन को पहले अवतार के रूप में उसी मापदंडों के साथ शुरू करते हैं।
और हमें चौड़ाई में खोज करने पर सिमुलेशन के 19 वें चरण पर ALL_EVENTS_PROCESSED संपत्ति का उल्लंघन मिलता है।
दिए गए प्रारंभिक आंकड़ों के लिए (यह एक बहुत छोटा राज्य स्थान है), 19 वें चरण में त्रुटि इंगित करती है कि त्रुटि बहुत दुर्लभ है और यह पता लगाना मुश्किल है, क्योंकि इससे पहले 19 से कम की लंबाई वाले सभी राज्य श्रृंखलाओं की जांच की गई थी।
इसलिए, यह त्रुटि परीक्षणों में पकड़ना कठिन है। केवल तभी यदि आप जानते हैं कि कहाँ देखना है, और विशेष रूप से परीक्षण और अस्थायी झोपड़ियों का चयन करें।
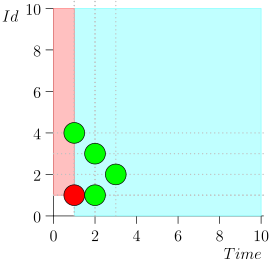
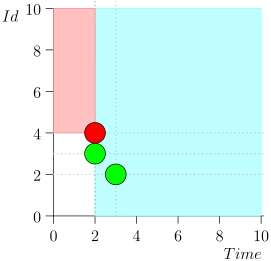
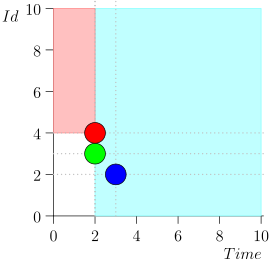
मैं स्थान और समय की बचत के लिए संपूर्ण मार्ग नहीं ला सका। यहां कई राज्यों से त्रुटि के साथ एक खंड है:

विश्लेषण और सुधार
क्या हुआ था?
जैसा कि आप देख सकते हैं, त्रुटि इस तथ्य में ही प्रकट हुई कि हम घटना {2, 3} से चूक गए, इस तथ्य के कारण कि घटना {2, 1} पर सीमा समाप्त हो गई, और उसके बाद हमने समन्वयक की स्थिति बदल दी। यह तभी हो सकता है जब एक समय में कई घटनाएँ हों।
यही कारण है कि त्रुटि परीक्षण में मायावी थी। इसकी अभिव्यक्ति के लिए, यह आवश्यक है कि काफी दुर्लभ चीजें मेल खाती हैं:
- कई घटनाओं ने समय में एक ही बिंदु मारा।
- घटनाओं के चयन की सीमा इन सभी घटनाओं को पढ़ने के क्षण से पहले समाप्त हो गई।
यदि समन्वयक की स्थिति को थोड़ा विस्तारित किया जाता है, तो त्रुटि को आसानी से ठीक किया जा सकता है: सामान्य ईवेंट क्षेत्र से अंतिम रीड इवेंट के समय और पहचानकर्ता को अधिकतम आईडी के साथ जोड़ें यदि इस इवेंट का समय अगले स्टेट.टाइम मान से मेल खाता है।
यदि ऐसी कोई घटना नहीं है, तो हम अतिरिक्त राज्य (extra_state) को अमान्य स्थिति (UNDEF_EVT) पर सेट करते हैं और काम करते समय इसे ध्यान में नहीं रखते हैं।
सामान्य क्षेत्र से उन घटनाओं को समन्वयक के पिछले चरण में संसाधित नहीं किया गया था, हम पहले से ही उच्च प्राथमिकता पर विचार करेंगे और तदनुसार उच्च प्राथमिकता और सुरक्षा विधेय के चयन को सही करेंगे।
उच्च प्राथमिकता और सामान्य के बीच एक और क्षेत्र मध्यवर्ती शुरू करना और एल्गोरिथ्म को बदलना संभव होगा। सबसे पहले, यह उच्च प्राथमिकता वाले लोगों को संसाधित करेगा, फिर मध्यवर्ती लोगों को, और उसके बाद राज्य के बाद के बदलाव के साथ सामान्य लोगों के लिए आगे बढ़ेगा।
लेकिन इस तरह के बदलावों से स्पष्ट लाभ के साथ रिफ्लेक्टिंग की अधिक मात्रा हो जाएगी (एल्गोरिथ्म थोड़ा स्पष्ट हो जाएगा; अन्य लाभ अभी दिखाई नहीं दे रहे हैं)।
इसलिए, हमने केवल वर्तमान स्थिति और डेटाबेस से घटनाओं के चयन को थोड़ा समायोजित करने का फैसला किया।
समायोजित मॉडल
यहाँ सही मॉडल है।
------------------- MODULE events ------------------- EXTENDS Naturals, FiniteSets, Sequences, TLC \* CONSTANTS MAX_TIME, LIMIT, TIME_DELTA (* --algorithm Events variables Events = {}, Limit \in LIMIT, Delta \in TIME_DELTA, Event_Id = 0 define \* \* , extra_state UNDEF_EVT == [time |-> MAX_TIME + 1, id |-> 0] ZERO_EVT == [time |-> 0, id |-> 0] MAX(S) == CHOOSE x \in S: \A y \in S: y <= x MIN(S) == CHOOSE x \in S: \A y \in S: y >= x RECURSIVE SetReduce(_, _, _) SetReduce(Op(_, _), S, value) == IF S = {} THEN value ELSE LET s == CHOOSE s \in S : TRUE IN SetReduce(Op, S \ {s}, Op(s, value)) ToSeq(S) == LET op(e, val) == Append(val, e) IN SetReduce(op, S, << >>) ToSet(S) == {S[i] : i \in DOMAIN(S)} MapSet(Op(_), S) == {Op(x) : x \in S} GetIds(Evts) == MapSet(LAMBDA x: x.id, Evts) GetTimes(Evts) == MapSet(LAMBDA x: x.time, Evts) EventsOrderByTime(e1, e2) == e1.time < e2.time EventsOrderById(e1, e2) == e1.id < e2.id EventsOrder(e1, e2) == \/ EventsOrderByTime(e1, e2) \/ /\ e1.time = e2.time /\ EventsOrderById(e1, e2) TakeN(S, limit) == LET amount == MIN({limit, Len(S)}) result == IF amount > 0 THEN SubSeq(S, 1, amount) ELSE << >> IN result (* SELECT * FROM events WHERE time <= curr_time AND id > max_id ORDER BY id Limit limit *) SELECT_HIGH_PRIO(state, limit, extra_state) == LET \* \* time <= curr_time \* AND id > maxt_id selected == {e \in Events : \/ /\ e.time <= state.time /\ e.id >= state.id \/ /\ e.time = extra_state.time /\ e.id > extra_state.id} sorted == \* SortSeq(ToSeq(selected), EventsOrderById) limited == TakeN(sorted, limit) IN ToSet(limited) SELECT_NORMAL(state, delta_time, limit) == LET selected == {e \in Events : /\ e.time <= state.time + delta_time /\ e.time > state.time } sorted == SortSeq(ToSeq(selected), EventsOrder) limited == TakeN(sorted, limit) IN ToSet(limited) \* extra_state UpdateExtraState(events, state, extra_state) == LET exact == {evt \in events : evt.time = state.time} IN IF exact # {} THEN CHOOSE evt \in exact : \A e \in exact: e.id <= evt.id ELSE UNDEF_EVT \* extra_state ALL_EVENTS_PROCESSED(state, extra_state) == \A e \in Events: \/ e.time >= state.time \/ e.id > state.id \/ /\ e.time = extra_state.time /\ e.id > extra_state.id end define; fair process inserter = "Sources" variable t; begin forever: while TRUE do get_time: with evt_time \in 0..MAX_TIME do t := evt_time; end with; commit: either Events := Events \union {[time |-> t, id |-> Event_Id]} || Event_Id := Event_Id + 1; or Event_Id := Event_Id + 1; end either; end while; end process fair process event_processor = "Event_processor" variable events = {}, state = ZERO_EVT, extra_state = UNDEF_EVT; begin forever: while TRUE do select: events := LET evts_high_prio == SELECT_HIGH_PRIO(state, Limit, extra_state) new_limit == Limit - Cardinality(evts_high_prio) evts_normal == SELECT_NORMAL(state, Delta, new_limit) IN evts_high_prio \union evts_normal; proc_evts: Events := Events \ events || state := [ time |-> MAX({state.time} \union GetTimes(events)), id |-> MAX({state.id} \union GetIds(events)) ]; extra_state := UpdateExtraState(events, state, extra_state) || events := {}; end while; end process end algorithm; *) \* BEGIN TRANSLATION \* TLA+, PlusCal \* END TRANSLATION ===================================================
जैसा कि आप देख सकते हैं, परिवर्तन बहुत छोटे हैं:
- अतिरिक्त डेटा को extra_state स्थिति में जोड़ा गया।
- उच्च प्राथमिकता वाली घटनाओं के चयन को बदल दिया।
- UpdateExtraState extra_state.
- safety - .
, . , (, , , ).
, , TLA+/TLC . :)
निष्कर्ष
, , ( , , , ).
, , TLA+/TLC, . , .
TLA+/TLC , , ( , ) .
, , , TLA+/TLC .
किताबें
, , , . .
Michael Jackson Problem Frames: Analysing & Structuring Software Development Problems
( !), . , . , .
Hillel Wayne Practical TLA+: Planning Driven Development
TLA+/PlusCal . , . . : .
MODEL CHECKING.
. , , . , .
Leslie Lamport Specifying Systems: The TLA+ Language and Tools for Hardware and Software Engineers
TLA+. , . : , . , TLA+ , .
Formal Development of a Network-Centric RTOS
TLA+ ( RTOS ) TLC.
, . , TLA+ , , RTOS — Virtuoso. , .
, (, , , , ).
w Amazon Web Services Uses Formal Methods
TLA+ AWS. : http://lamport.azurewebsites.net/tla/amazon-excerpt.html
Hillel Wayne ( "Practical TLA+")
. , . , - .
Ron Pressler
. . , TLA+. TLA+, computer science .
Leslie Lamport
TLA+ computer science . TLA+ .
. . , . . , . . .
, , .
TLA+,
, TLA+. , TLA+.
Hillel Wayne
Hillel Wayne . .
Ron Pressler
, Hillel Wayne, . , . Ron Pressler . ́ , , .
TLA toolbox + TLAPS : TLA+
. Alloy Analyzer .