मुझे स्कूल ऑफ डेटा कंपनी के ब्लॉग पर
एक लेख आया और यह जांचने का फैसला किया कि Fast.ai लाइब्रेरी उसी डेटासेट पर सक्षम है जो लेख में उल्लिखित है। यहां आपको इस बारे में तर्क नहीं मिलेंगे कि निमोनिया का समय पर और सही निदान करना कितना महत्वपूर्ण है, क्या रेडियोलॉजिस्ट को तकनीकी विकास की स्थितियों में आवश्यकता होगी, क्या तंत्रिका नेटवर्क की भविष्यवाणी को चिकित्सा निदान माना जा सकता है, आदि। मुख्य लक्ष्य यह दिखाना है कि आधुनिक पुस्तकालयों में मशीन सीखना काफी सरल हो सकता है (शाब्दिक रूप से कोड की कुछ पंक्तियों की आवश्यकता होती है) और उत्कृष्ट परिणाम देता है। हमें लेख से परिणाम याद रखें (सटीक = 0.84, याद = 0.96) और देखें कि हमारे साथ क्या होता है।
हम
यहां से प्रशिक्षण के लिए डेटा लेते
हैं । डेटा 5856 एक्स-रे दो वर्गों में वितरित किया जाता है - निमोनिया के संकेतों के साथ या बिना। तंत्रिका नेटवर्क का कार्य हमें निमोनिया के संकेतों को निर्धारित करने के लिए एक उच्च गुणवत्ता वाला बाइनरी एक्स-रे क्लासिफायर देना है।
हम पुस्तकालयों और कुछ मानक सेटिंग्स को आयात करके शुरू करते हैं:
%reload_ext autoreload %autoreload 2 %matplotlib inline from fastai.vision import * from fastai.metrics import error_rate import os
अगला, बैच आकार निर्धारित करें। जीपीयू पर सीखते समय, इसे इस तरह से चुनना महत्वपूर्ण है कि आपकी मेमोरी पूर्ण न हो। यदि आवश्यक हो, तो इसे आधा किया जा सकता है।
bs = 64
महत्वपूर्ण अपडेट:जैसा कि नीचे दिए गए टिप्पणियों में सही उल्लेख किया गया है, यह स्पष्ट रूप से उस डेटा की निगरानी करना महत्वपूर्ण है जिस पर मॉडल को प्रशिक्षित किया जाएगा और जिस पर हम इसकी प्रभावशीलता का परीक्षण करेंगे। हम ट्रेन और वैल फ़ोल्डरों में चित्रों में मॉडल को प्रशिक्षित करेंगे, और परीक्षण फ़ोल्डर में छवियों को मान्य करेंगे, जो
यहां किया गया था।
हम अपने डेटा के लिए पथ निर्धारित करते हैं
path = Path('storage/chest_xray') path.ls()
और जांच लें कि सभी फ़ोल्डर जगह में हैं (वैल फ़ोल्डर को ट्रेन में ले जाया गया है):
Out: [PosixPath('storage/chest_xray/train'), PosixPath('storage/chest_xray/test')]
हम तंत्रिका नेटवर्क में "लोडिंग" के लिए अपना डेटा तैयार कर रहे हैं। यह ध्यान रखना महत्वपूर्ण है कि Fast.ai में छवि लेबल के मिलान के कई तरीके हैं। From_folder विधि हमें बताती है कि लेबल उस फ़ोल्डर के नाम से लिया जाना चाहिए जिसमें छवि स्थित है।
आकार पैरामीटर का मतलब है कि हम सभी छवियों को 299x299 के आकार का आकार देते हैं (हमारे एल्गोरिदम वर्ग छवियों के साथ काम करते हैं)। Get_transforms फ़ंक्शन हमें प्रशिक्षण डेटा की मात्रा बढ़ाने के लिए छवि वृद्धि देता है (हम यहां डिफ़ॉल्ट सेटिंग्स छोड़ते हैं)।
np.random.seed(5) data = ImageDataBunch.from_folder(path, train = 'train', valid = 'test', size=299, bs=bs, ds_tfms=get_transforms()).normalize(imagenet_stats)
आइए डेटा को देखें:
data.show_batch(rows=3, figsize=(6,6))
जाँच करने के लिए, हम देखते हैं कि हमें कौन सी कक्षाएं मिलीं और ट्रेन और सत्यापन के बीच छवियों का मात्रात्मक वितरण क्या है:
data.classes, data.c, len(data.train_ds), len(data.valid_ds)
Out: (['NORMAL', 'PNEUMONIA'], 2, 5232, 624)
हम Resnet50 वास्तुकला पर आधारित एक प्रशिक्षण मॉडल को परिभाषित करते हैं:
learn = cnn_learner(data, models.resnet50, metrics=error_rate)
और
एक साइकिल नीति के आधार पर 8 युगों में सीखना शुरू करें:
learn.fit_one_cycle(8)
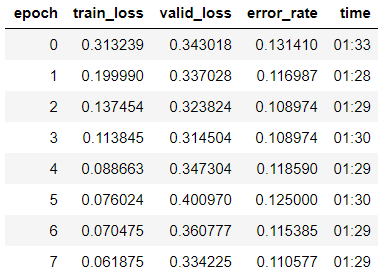
हम देखते हैं कि हमने पहले ही सत्यापन नमूने पर 89% की सटीकता प्राप्त कर ली है। हम अभी के लिए अपने मॉडल के वजन को लिखेंगे और परिणाम को बेहतर बनाने का प्रयास करेंगे।
learn.save('step-1-50')
पूरे मॉडल को "डीफ्रॉस्ट" करें, क्योंकि इससे पहले, हमने केवल परतों के अंतिम समूह पर मॉडल को प्रशिक्षित किया था, और बाकी के वजन को मॉडल से पहले से ले लिया गया था, जो कि इमेनेजेट और "जमे हुए" पर पूर्व-प्रशिक्षित थे:
learn.unfreeze()
हम सीखने के लिए इष्टतम सीखने की दर की तलाश कर रहे हैं:
learn.lr_find() learn.recorder.plot()
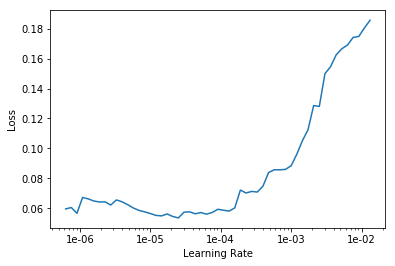
हम परतों के प्रत्येक समूह के लिए अलग-अलग सीखने की दरों के साथ 10 युगों के लिए प्रशिक्षण शुरू करते हैं।
learn.fit_one_cycle(10, max_lr=slice(1e-6, 1e-4))
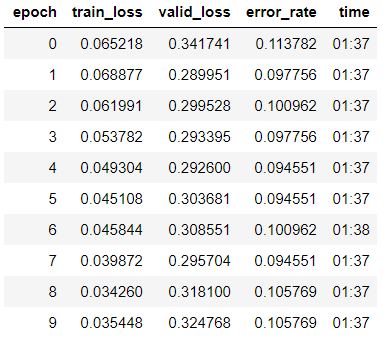
हम देखते हैं कि सत्यापन नमूने में हमारे मॉडल की सटीकता 89.4% तक बढ़ गई है।
हम वज़न लिखते हैं।
learn.save('step-2-50')
निर्माण भ्रम मैट्रिक्स:
interp = ClassificationInterpretation.from_learner(learn) interp.plot_confusion_matrix()
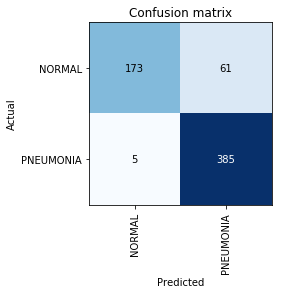
इस बिंदु पर, हम याद करते हैं कि अकेले सटीकता पैरामीटर अपर्याप्त है, खासकर असंतुलित वर्गों के लिए। उदाहरण के लिए, यदि वास्तविक जीवन में निमोनिया केवल 0.1% लोगों में होता है, जो एक्स-रे परीक्षा से गुजरते हैं, तो सिस्टम सभी मामलों में निमोनिया की अनुपस्थिति को आसानी से दे सकता है और इसकी सटीकता बिल्कुल शून्य उपयोगिता के साथ 99.9% के स्तर पर होगी।
यह वह जगह है जहाँ प्रेसिजन और रिकॉल मेट्रिक्स खेल में आते हैं:
- टीपी - सच्ची सकारात्मक भविष्यवाणी;
- टीएन - सच्ची नकारात्मक भविष्यवाणी;
- एफपी - झूठी सकारात्मक भविष्यवाणी;
- एफएन - झूठी नकारात्मक भविष्यवाणी।
हम देखते हैं कि हमने जो परिणाम प्राप्त किया है वह लेख में उल्लिखित की तुलना में थोड़ा अधिक है। कार्य पर आगे के काम में, यह याद रखने योग्य है कि रिकॉल चिकित्सा समस्याओं में एक अत्यंत महत्वपूर्ण पैरामीटर है, क्योंकि निदान के दृष्टिकोण से गलत नकारात्मक त्रुटियां सबसे खतरनाक हैं (जिसका अर्थ है कि हम बस एक खतरनाक निदान को "अनदेखा" कर सकते हैं)।