
शुभ दोपहर, मैं आपके साथ Windows कंटेनरों के लिए AWS EKS (Elastic Kubernetes Service) सेवा को कॉन्फ़िगर करने और उपयोग करने में अपना अनुभव साझा करना चाहता हूं, या इसका उपयोग करने की असंभवता के बारे में, और AWS सिस्टम कंटेनर में पाया जाने वाला बग, उन लोगों के लिए जो Windows कंटेनरों के लिए इस सेवा में रुचि रखते हैं, कृपया बिल्ली के नीचे।
मुझे पता है कि विंडोज़ कंटेनर एक लोकप्रिय विषय नहीं है, और बहुत कम लोग उनका उपयोग करते हैं, लेकिन फिर भी इस लेख को लिखने का फैसला किया है, क्योंकि हब्रे पर कुबेरनेट और खिड़कियों पर कुछ लेख थे और अभी भी ऐसे लोग हैं।
शुरुआत
यह सब इस तथ्य के साथ शुरू हुआ कि हमारी कंपनी में सेवाएं, इसे कुबेरनेट्स में स्थानांतरित करने का निर्णय लिया गया था, यह 70% खिड़कियां और 30% लिनक्स है। इसके लिए, AWS EKS क्लाउड सेवा को संभावित विकल्पों में से एक माना गया था। 8 अक्टूबर, 2019 तक एडब्ल्यूएस ईकेएस विंडोज सार्वजनिक पूर्वावलोकन में था, मैंने इसके साथ शुरू किया था, कुबेरनेट्स संस्करण का उपयोग वहाँ पुराना 1.11 था, लेकिन मैंने इसे वैसे भी जांचने और यह देखने का फैसला किया कि यह क्लाउड सेवा किस चरण में काम कर रही है, अगर यह बिल्कुल भी काम कर रहा है, तो यह नहीं है। चूल्हों को हटाने के साथ एक बग, जबकि पुराने लोगों ने आंतरिक कार्यकर्ता के माध्यम से विंडोज कार्यकर्ता नोड के रूप में एक ही सबनेट से जवाब देना बंद कर दिया।
इसलिए, एक ही EC2 पर कुबेरनेट्स पर अपने स्वयं के क्लस्टर के पक्ष में AWS EKS के उपयोग को छोड़ने का फैसला किया गया था, केवल CloudFormation के माध्यम से सभी संतुलन और हा को स्वयं द्वारा वर्णित किया जाना होगा।
अमेज़न ईकेएस विंडोज कंटेनर समर्थन अब आम तौर पर उपलब्ध है
by मार्टिन बीबी | 08 OCT 2019 कोमेरे पास अपने स्वयं के क्लस्टर के लिए CloudFormation में एक टेम्पलेट जोड़ने का समय नहीं है, क्योंकि मैंने इस समाचार को देखा था
Amazon EKS Windows कंटेनर समर्थन अब आम तौर पर उपलब्ध हैबेशक, मैंने अपने सभी घटनाक्रमों को स्थगित कर दिया, और यह अध्ययन करना शुरू कर दिया कि उन्होंने जीए के लिए क्या किया और सार्वजनिक पूर्वावलोकन से सब कुछ कैसे बदल गया। हाँ एडब्ल्यूएस फेलो ने विंडोज़ वर्कर नोड के लिए छवियों को संस्करण 1.14 के साथ-साथ अब ईकेएस में क्लस्टर संस्करण 1.14 में विंडोज़ नोड्स के समर्थन के साथ अपडेट किया है। उन्होंने
गिटहब पर सार्वजनिक पूर्वावलोकन परियोजना को बंद कर दिया और कहा कि अब यहां आधिकारिक दस्तावेज का उपयोग करें:
ईकेएस विंडोज सपोर्टवर्तमान VPC और सबनेट में EKS क्लस्टर का एकीकरण
सभी स्रोतों में, घोषणा के ऊपर की कड़ी में और दस्तावेज में भी, यह मालिकाना उपयोगिता के माध्यम से क्लस्टर को तैनात करने का प्रस्ताव था या बाद में CloudFormation + kubectl के माध्यम से, केवल अमेज़ॅन में सार्वजनिक सबनेट का उपयोग करने के साथ-साथ एक नए क्लस्टर के लिए एक अलग VPC का निर्माण करना।
यह विकल्प कई लोगों के लिए उपयुक्त नहीं है, सबसे पहले, एक अलग VPC अपने वर्तमान VPC के लिए इसकी लागत + सहकर्मी यातायात की अतिरिक्त लागत है। उन लोगों के लिए क्या करें जिनके पास पहले से ही AWS में अपने कई AWS खातों, VPC, सबनेट्स, रूट टेबल, ट्रांजिट गेटवे और के साथ एक तैयार बुनियादी ढांचा है? बेशक, मैं इसे तोड़ना या इसे फिर से प्राप्त नहीं करना चाहता हूं, और मुझे मौजूदा वीपीसी का उपयोग करके मौजूदा नेटवर्क बुनियादी ढांचे में नए ईकेएस क्लस्टर को एकीकृत करने और अधिकतम विभाजित करने के लिए, क्लस्टर के लिए नए सबनेट बनाने की आवश्यकता है।
मेरे मामले में, इस पथ को चुना गया था, मैंने मौजूदा VPC का उपयोग किया, एक नए क्लस्टर के लिए केवल 2 सार्वजनिक सबनेट और 2 निजी सबनेट जोड़े, बेशक, सभी नियमों को दस्तावेज के अनुसार ध्यान में रखा गया था
अपने अमेज़ॅन ईकेएस क्लस्टर वीपीसी बनाएं ।
EIP का उपयोग करते हुए सार्वजनिक सबनेट में कोई भी कार्यकर्ता नोड के लिए एक शर्त नहीं थी।Eksctl बनाम CloudFormation
मैं तुरंत एक आरक्षण कर दूंगा कि मैंने क्लस्टर परिनियोजन के दोनों तरीकों की कोशिश की, दोनों ही मामलों में तस्वीर समान थी।
मैं केवल कोड के छोटे होने के बाद से eksctl के उपयोग के साथ एक उदाहरण दिखाऊंगा। 3 चरणों में तैनात एक्सेलक्ट क्लस्टर का उपयोग करना:
1. क्लस्टर स्वयं + लिनक्स वर्कर नोड को बनाएं, जिस पर बाद में सिस्टम कंटेनर और बहुत ही अशुभ वीपीसी-नियंत्रक स्थित होंगे।
eksctl create cluster \ --name yyy \ --region www \ --version 1.14 \ --vpc-private-subnets=subnet-xxxxx,subnet-xxxxx \ --vpc-public-subnets=subnet-xxxxx,subnet-xxxxx \ --asg-access \ --nodegroup-name linux-workers \ --node-type t3.small \ --node-volume-size 20 \ --ssh-public-key wwwwwwww \ --nodes 1 \ --nodes-min 1 \ --nodes-max 2 \ --node-ami auto \ --node-private-networking
मौजूदा VPC में तैनात करने के लिए, बस अपने सबनेट की आईडी निर्दिष्ट करें, और ectctl VPC को ही निर्धारित करेगा।
अपने कार्यकर्ता नोड को केवल निजी सबनेट पर तैनात करने के लिए, आपको नोडग्रुप के लिए --node-Private-नेटवर्किंग को निर्दिष्ट करने की आवश्यकता है।
2. हमारे क्लस्टर में vpc- नियंत्रक स्थापित करें, जो तब मुफ्त आईपी पते की संख्या, साथ ही उदाहरण के लिए, ईएनआई की संख्या को गिनकर और उन्हें हटाकर हमारे कार्यकर्ता नोड्स को संसाधित करेगा।
eksctl utils install-vpc-controllers --name yyy --approve
3. अपने सिस्टम कंटेनरों को सफलतापूर्वक vpc- नियंत्रक सहित अपने linux कार्यकर्ता नोड पर शुरू कर दिया है, यह केवल विंडोज श्रमिकों के लिए एक और नोडग्रुप बनाने के लिए बनी हुई है।
eksctl create nodegroup \ --region www \ --cluster yyy \ --version 1.14 \ --name windows-workers \ --node-type t3.small \ --ssh-public-key wwwwwwwwww \ --nodes 1 \ --nodes-min 1 \ --nodes-max 2 \ --node-ami-family WindowsServer2019CoreContainer \ --node-ami ami-0573336fc96252d05 \ --node-private-networking
आपके नोड के सफलतापूर्वक आपके क्लस्टर में आ जाने के बाद और सब कुछ ठीक लग रहा है, यह रेडी स्थिति में है, लेकिन नहीं।
Vpc- नियंत्रक में त्रुटि
यदि हम विंडोज़ वर्कर नोड पर पॉड्स चलाने की कोशिश करते हैं, तो हमें एक त्रुटि मिलती है:
NetworkPlugin cni failed to teardown pod "windows-server-iis-7dcfc7c79b-4z4v7_default" network: failed to parse Kubernetes args: pod does not have label vpc.amazonaws.com/PrivateIPv4Address]
गहराई से देखने पर, हम देखते हैं कि हमारा AWS उदाहरण इस तरह दिखता है:

और यह इस तरह होना चाहिए:

इससे यह स्पष्ट है कि vpc- नियंत्रक ने किसी कारण से अपने हिस्से को काम नहीं किया और उदाहरण के लिए नए आईपी-पते नहीं जोड़ सके ताकि पॉड्स उनका उपयोग कर सकें।
हम vpc- नियंत्रक पॉड लॉग को देखने के लिए चढ़ते हैं और यही हम देखते हैं:
kubectl लॉग <vpc-नियंत्रक-परिनियोजन> -n kube-system I1011 06:32:03.910140 1 watcher.go:178] Node watcher processing node ip-10-xxx.ap-xxx.compute.internal. I1011 06:32:03.910162 1 manager.go:109] Node manager adding node ip-10-xxx.ap-xxx.compute.internal with instanceID i-088xxxxx. I1011 06:32:03.915238 1 watcher.go:238] Node watcher processing update on node ip-10-xxx.ap-xxx.compute.internal. E1011 06:32:08.200423 1 manager.go:126] Node manager failed to get resource vpc.amazonaws.com/CIDRBlock pool on node ip-10-xxx.ap-xxx.compute.internal: failed to find the route table for subnet subnet-0xxxx E1011 06:32:08.201211 1 watcher.go:183] Node watcher failed to add node ip-10-xxx.ap-xxx.compute.internal: failed to find the route table for subnet subnet-0xxx I1011 06:32:08.201229 1 watcher.go:259] Node watcher adding key ip-10-xxx.ap-xxx.compute.internal (0): failed to find the route table for subnet subnet-0xxxx I1011 06:32:08.201302 1 manager.go:173] Node manager updating node ip-10-xxx.ap-xxx.compute.internal. E1011 06:32:08.201313 1 watcher.go:242] Node watcher failed to update node ip-10-xxx.ap-xxx.compute.internal: node manager: failed to find node ip-10-xxx.ap-xxx.compute.internal.
Google खोजों से कुछ भी नहीं हुआ, क्योंकि स्पष्ट रूप से किसी ने भी इस तरह के बग को अभी तक नहीं पकड़ा था, अच्छी तरह से, या इस पर एक मुद्दा पोस्ट किया, मुझे सभी विकल्पों में से पहले खुद को सोचना पड़ा। पहली बात जो दिमाग में आई, वह यह है कि शायद vpc- नियंत्रक IP-10-xxx.ap-xxx.compute.internal को सोख नहीं सकता है और इसके माध्यम से मिलता है और इसलिए त्रुटियां गिरती हैं।
हां, वास्तव में, हम VPC में कस्टम डीएनएस सर्वर का उपयोग करते हैं और हम सिद्धांत रूप में अमेज़ॅन सर्वर का उपयोग नहीं करते हैं, इसलिए यहां तक कि अग्रेषण इस डोमेन ap-xxx.compute.internal पर कॉन्फ़िगर नहीं किया गया था। मैंने इस विकल्प की जाँच की, और यह कोई परिणाम नहीं लाया, शायद परीक्षण साफ नहीं था, और इसलिए, तकनीकी सहायता के साथ संचार करते समय, मैंने उनके विचार के आगे घुटने टेक दिए।
चूंकि कोई विचार नहीं था, इसलिए सभी सुरक्षा समूह ectctl द्वारा बनाए गए थे, इसलिए इसमें कोई संदेह नहीं था कि वे काम कर रहे थे, रूट टेबल भी सही थे, nat, dns, वर्कर नोड्स के साथ इंटरनेट एक्सेस भी था।
उसी समय, यदि आप कार्यकर्ता नोड को - सब-प्राइवेट-नेटवर्किंग का उपयोग किए बिना सार्वजनिक सबनेट पर तैनात करते हैं, तो इस नोड को तुरंत vpc- नियंत्रक द्वारा अद्यतन किया गया था और सब कुछ एक घड़ी की तरह काम करता था।
दो विकल्प थे:
- हैमर और प्रतीक्षा करें जब तक कि कोई व्यक्ति एडब्ल्यूएस में इस बग का वर्णन नहीं करता है और वे इसे ठीक कर देते हैं और फिर आप एडब्ल्यूएस ईकेएस विंडोज का सुरक्षित रूप से उपयोग कर सकते हैं, क्योंकि वे सिर्फ जीए में पाए गए (लेखन के समय 8 दिन लगे), सबसे अधिक संभावना है कि मेरे जैसे ही ।
- AWS समर्थन को लिखें और उन्हें हर जगह से लॉग के पूरे गुच्छा के साथ समस्या का सार समझाएं और उन्हें साबित करें कि उनके VPC और सबनेट का उपयोग करते समय उनकी सेवा काम नहीं करती है, यह व्यर्थ नहीं था कि हमारे पास व्यावसायिक समर्थन था, हमें इसे कम से कम एक बार करना होगा :-)
AWS इंजीनियर्स के साथ संचार
पोर्टल पर एक टिकट बनाने के बाद, मैंने गलती से मुझे वेब - ईमेल या सहायता केंद्र के माध्यम से उत्तर देने के लिए चुना, इस विकल्प के माध्यम से वे कुछ दिनों के बाद आपको जवाब दे सकते हैं, इस तथ्य के बावजूद कि मेरे टिकट में गंभीरता थी - सिस्टम बिगड़ा हुआ था, जिसने <12 के भीतर प्रतिक्रिया व्यक्त की थी घंटे, और जब से बिजनेस सपोर्ट प्लान को 24/7 समर्थन मिला है, मैं सबसे अच्छे की उम्मीद कर रहा था, लेकिन यह हमेशा की तरह बदल गया।
मेरा टिकट शुक्रवार से सोम तक अनसाइनड में उतरा, फिर मैंने इसे फिर से लिखने का फैसला किया और चैट उत्तर विकल्प को चुना। थोड़े इंतजार के बाद, हर्षद माधव मुझे नियुक्त किया गया, और फिर शुरू हुआ ...
हमने पंक्ति में 3 घंटे ऑनलाइन उसके साथ बहस की, लॉग्स ट्रांसफर किया, समस्या का अनुकरण करने के लिए AWS प्रयोगशाला में एक ही क्लस्टर को तैनात किया, मेरे हिस्से पर क्लस्टर को फिर से बनाया और इसी तरह, केवल एक चीज जो हम आए थे कि लॉग्स ने दिखाया कि रिज़ॉल्यूशन काम नहीं कर रहा था जैसा कि मैंने ऊपर लिखा था AWS आंतरिक डोमेन नाम, और हर्षद माधव ने मुझे अग्रेषण बनाने के लिए कहा, माना जाता है कि हम कस्टम डीएनएस का उपयोग करते हैं और यह एक समस्या हो सकती है।
अग्रेषण
ap-xxx.compute.internal -> 10.xx2 (VPC CIDRBlock) amazonaws.com -> 10.xx2 (VPC CIDRBlock)
क्या किया गया था, दिन खत्म हो गया था। हर्षद माधव ने चेक को अनसब्सक्राइब कर दिया और उसे काम करना चाहिए, लेकिन नहीं, संकल्प ने मदद नहीं की।
फिर 2 और इंजीनियरों के साथ एक बातचीत हुई, एक तो बस चैट से गिर गया, जाहिरा तौर पर एक मुश्किल मामले से डर गया, दूसरे ने एक बार फिर एक पूर्ण डिबग चक्र पर अपना दिन बिताया, लॉग भेजना, दोनों तरफ गुच्छों का निर्माण करना, अंत में उसने बस इतना ही कहा, यह मेरे लिए काम करता है, मैं यहां हूं। आधिकारिक दस्तावेज़ीकरण मैं सब कुछ चरण दर चरण करता हूं और आप सफल होंगे।
जिस पर मैंने विनम्रता से उसे छोड़ने के लिए कहा, और यदि आप नहीं जानते कि समस्या की तलाश के लिए मेरे टिकट पर कोई और असाइन करें।
अन्त
तीसरे दिन, एक नया इंजीनियर अरुण बी मुझे नियुक्त किया गया था, और उनके साथ संचार की शुरुआत से ही यह तुरंत स्पष्ट हो गया था कि ये 3 पिछले इंजीनियर नहीं थे। उन्होंने पूरे इतिहास को पढ़ा और तुरंत ps1 पर अपनी स्क्रिप्ट के साथ लॉग इकट्ठा करने के लिए कहा जो उनके गीथूब पर पड़ा था। फिर क्लस्टर बनाने, टीमों के परिणामों का आउटपुट देने, लॉग को फिर से इकट्ठा करने के सभी पुनरावृत्तियां हुईं, लेकिन अरुण बी मुझसे पूछे गए प्रश्नों को देखते हुए सही दिशा में आगे बढ़ रहे थे।
जब हम -sderrthreshold = डीबग को उनके vpc- नियंत्रक में शामिल करने के लिए मिला, और आगे क्या हुआ? यह निश्चित रूप से काम नहीं करता है) फली बस इस विकल्प के साथ शुरू नहीं होती है, केवल -stderrthreshold = जानकारी काम करती है।
यह वह जगह है जहां हम समाप्त हो गए और अरुण बी ने कहा कि वह उसी त्रुटि को प्राप्त करने के लिए मेरे कदमों को पुन: उत्पन्न करने का प्रयास करेंगे। अगले दिन मुझे अरुण बी से एक प्रतिक्रिया मिली। उन्होंने इस मामले को नहीं छोड़ा, लेकिन उनके vpc- नियंत्रक के समीक्षा कोड को ले लिया और उसी जगह पाया जहां यह करता है और काम क्यों नहीं करता है:
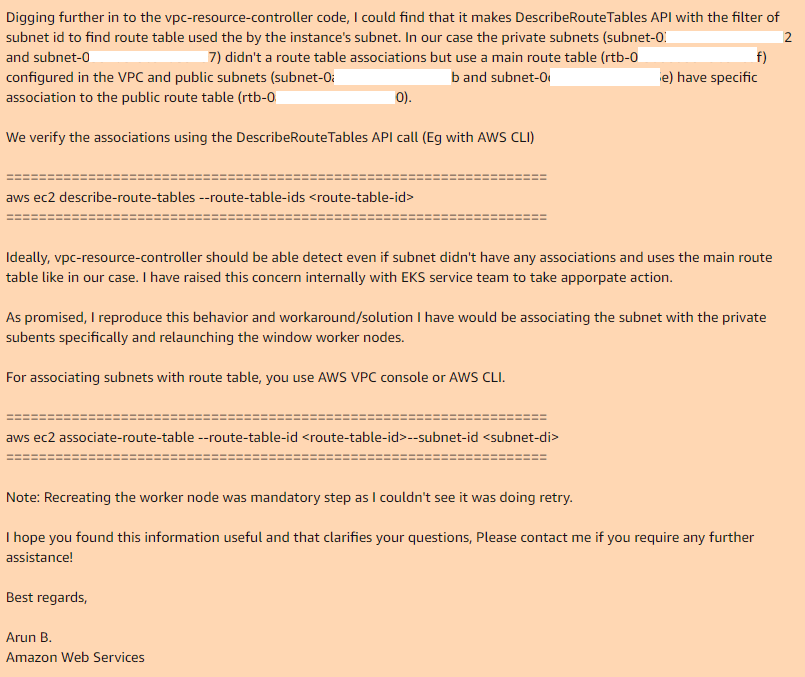
इस प्रकार, यदि आप अपने वीपीसी में मुख्य मार्ग तालिका का उपयोग करते हैं, तो डिफ़ॉल्ट रूप से इसमें आवश्यक सबनेट के साथ जुड़ाव नहीं होता है, इसलिए आवश्यक सब-पीसी-नियंत्रक, सार्वजनिक सबनेट के मामले में, इसमें एक कस्टम मार्ग तालिका होती है जिसमें एक संघ होता है।
वांछित सबनेट के साथ मुख्य मार्ग तालिका के लिए मैन्युअल रूप से संघों को जोड़कर और नोडग्रुप को फिर से बनाते हुए, सब कुछ पूरी तरह से काम करता है।
मुझे उम्मीद है कि अरुण बी वास्तव में इस बग को ईकेएस डेवलपर्स को रिपोर्ट करेंगे और हम vpc- नियंत्रक का एक नया संस्करण देखेंगे, और जहां सब कुछ बॉक्स से बाहर काम करेगा। वर्तमान में नवीनतम संस्करण: 602401143452.dkr.ecr.ap-southeast-1.amazonaws.com/eks/vpc-resource-controllerPoint.2.1
यह समस्या है।
उन सभी के लिए धन्यवाद, जो अंत तक पढ़ते हैं, उन सभी चीजों का परीक्षण करते हैं जिन्हें आप कार्यान्वयन से पहले उत्पादन में उपयोग करने जा रहे हैं।
अपडेट: नई बग # 2
पहली समस्या का हल खोजने के बाद, हमने अपनी आवश्यकताओं के लिए इस सेवा को तैयार करना जारी रखा, और अब अंतिम चरण में, हमने जीवन के साथ एक और बग को असंगत पाया।
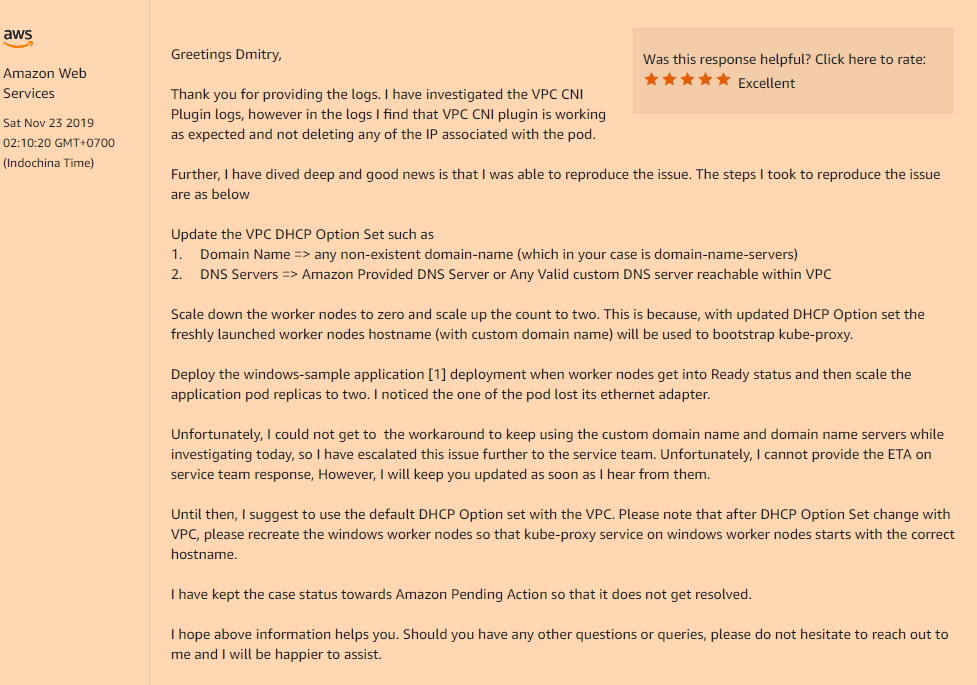
समस्या:कुबेरनेट्स में एप्लिकेशन को तैनात करें, अपनी तैनाती, प्रतिकृतियां> 1 सेट करें और निम्न चित्र देखें। नई पॉड सामान्य रूप से शुरू होती है और काम करती है, जबकि पुरानी पॉड अपना नेटवर्क इंटरफेस खो देती है। हां, हां, पूरी तरह से एक नेटवर्क के बिना पुरानी फली, हालांकि यह रनिंग स्थिति में लटका रहता है। प्रतिकृतियों को कम या बढ़ाएं, फली को हटाएं ताकि आप हमेशा केवल उस फली को न करें जो पिछले एक ने रनिंग स्थिति में प्रवेश किया है, काम करेगा, बाकी सभी नहीं करेंगे। भले ही, फली या अलग-अलग एक ही नोड पर शुरू हो।
समाधान:हां, समस्या फिर से हमारे VPC के कस्टम कॉन्फ़िगरेशन में बदल गई, अर्थात् यदि आप अपने डीएचसीपी विकल्प सेट का उपयोग करते हैं जो डोमेन-नाम फ़ील्ड के कस्टम मूल्य को इंगित करता है, या पूरी तरह से खाली है (जैसा कि मेरे मामले में, मैंने केवल डोमेन-नाम-सर्वर बदल दिया है मुझे बाकी चीजों की आवश्यकता नहीं है) लॉन्च के बाद आपके पॉड्स के अंदर नेटवर्क इंटरफेस के गायब होने से आपको इस तरह की असंगत समस्या होगी।
आपको इसे अपने डीएचसीपी विकल्प सेट में पंजीकृत करना होगा:
domain-name = <aws-region-name>.compute.internal;
और इसके बाद अपने सभी कार्यकर्ता नोड्स को फिर से स्थापित करना है ताकि बूटस्ट्रैप के दौरान सभी घटक सही सेटिंग्स को पंजीकृत करें।
नीचे यह विवरण दिया गया है कि यह डोमेन-नाम विकल्प आपके कार्यकर्ता नोड्स को कैसे प्रभावित करता है:
इस बार, मैंने उन्हें Windows के लिए AWS EKS में कम से कम प्रलेखन जोड़ने के लिए कहा, ये उनकी सेवा की "विशेषताएं" हैं।