लेख रूसी में पाठ संदेशों के टन की वर्गीकरण पर चर्चा करेगा (और अनिवार्य रूप से उसी तकनीक का उपयोग करके ग्रंथों के किसी भी वर्गीकरण)। हम
इस लेख को एक आधार के रूप में लेंगे, जिसमें Word2vec मॉडल का उपयोग करके CNN आर्किटेक्चर पर आज की रात के वर्गीकरण पर विचार किया गया था। हमारे उदाहरण में, हम
ULMFit मॉडल का उपयोग करके एक ही डेटासेट पर सकारात्मक और नकारात्मक में ट्वीट्स को अलग करने की एक ही समस्या को हल करेंगे। लेख से परिणाम (औसत एफ 1-स्कोर = 0.78142) को आधार रेखा के रूप में स्वीकार किया जाएगा।
परिचय
ULMFIT मॉडल को 2018 में fast.ai Developers (जेरेमी हॉवर्ड, सेबेस्टियन रुडर) द्वारा पेश किया गया था। दृष्टिकोण का सार एनएलपी कार्यों में ट्रांसफर लर्निंग का उपयोग करना है जब आप पूर्व-प्रशिक्षित मॉडल का उपयोग करते हैं, अपने मॉडल के प्रशिक्षण के लिए समय कम करते हैं और लेबल किए गए परीक्षण नमूने के आकार के लिए आवश्यकताओं को कम करते हैं।
हमारे मामले में प्रशिक्षण योजना इस प्रकार होगी:

भाषा मॉडल का अर्थ अनुक्रम में अगले शब्द की भविष्यवाणी करने में सक्षम होना है। इस तरह से लंबे समय तक जुड़े हुए ग्रंथों को प्राप्त करना समस्याग्रस्त है, लेकिन फिर भी, भाषा मॉडल भाषा के गुणों को पकड़ने में सक्षम हैं, शब्दों के उपयोग के संदर्भ को समझते हैं, इसलिए यह भाषा मॉडल है (और नहीं, उदाहरण के लिए, शब्दों का वेक्टर प्रदर्शन) जो कि प्रौद्योगिकी का आधार है। भाषा के मॉडलिंग के कार्य के लिए, ULMFit
AWD-LSTM आर्किटेक्चर का उपयोग करता है, जिसमें जहां भी संभव हो, ड्रॉपआउट का सक्रिय उपयोग शामिल है और समझ में आता है। भाषा मॉडल प्रशिक्षण के प्रकार को कभी-कभी अर्ध-पर्यवेक्षणीय शिक्षा कहा जाता है, क्योंकि यहां लेबल अगले शब्द है और कुछ भी आपके हाथों से चिह्नित करने की आवश्यकता नहीं है।
पूर्व-प्रशिक्षित भाषा मॉडल के रूप में, हम लगभग एकमात्र
उपलब्ध सार्वजनिक रूप से उपयोग करेंगे।
आइए शुरू से ही सीखने के एल्गोरिथ्म के माध्यम से चलते हैं।
हम पुस्तकालयों को लोड करते हैं (हम किसी भी असंगतता के मामले में Fast.ai के संस्करण की जांच करते हैं):
%load_ext autoreload %autoreload 2 import pandas as pd import numpy as np import re import statistics import fastai print('fast.ai version is:', fastai.__version__) from fastai import * from fastai.text import * from sklearn.model_selection import train_test_split path = ''
Out: fast.ai version is: 1.0.58
हम प्रशिक्षण के लिए डेटा तैयार करते हैं
सादृश्य से, हम
यूलिया रुबतसोवा द्वारा लघु ग्रंथ RuTweetCorp के
शरीर पर प्रशिक्षण का आयोजन करेंगे, जो ट्विटर से रूसी-भाषा के संदेशों के आधार पर बनाया गया है। शरीर में 114,991 सकारात्मक ट्वीट और CSV प्रारूप में 111,923 नकारात्मक ट्वीट हैं। इसके अलावा, SQL प्रारूप में 17 639 674 रिकॉर्ड की मात्रा के साथ असंबद्ध ट्वीट्स का एक डेटाबेस है। हमारे वर्गीकरण का कार्य यह निर्धारित करना होगा कि ट्वीट सकारात्मक है या नकारात्मक।
चूँकि
17 मिलियन ट्वीट्स पर भाषा मॉडल को फिर से लिखना था और ट्रांसफर लर्निंग को दिखाने के लिए कार्य करना था, इसलिए हम प्रशिक्षण डेटासेट से पाठ के एक टुकड़े पर भाषा मॉडल को फिर से लिखना चाहते हैं, पूरी तरह से असंबद्ध ट्वीट के आधार को अनदेखा कर रहे हैं। संभवतः, भाषा मॉडल को "तेज" करने के लिए इस आधार का उपयोग करके, आप समग्र परिणाम में सुधार कर सकते हैं।
हम प्रारंभिक शब्द प्रसंस्करण के साथ प्रशिक्षण और परीक्षण के लिए डेटासेट बनाते हैं। हम
मूल लेख से कोड लेते हैं:
def preprocess_text(text): text = text.lower().replace("", "") text = re.sub('((www\.[^\s]+)|(https?://[^\s]+))', 'URL', text) text = re.sub('@[^\s]+', 'USER', text) text = re.sub('[^a-zA-Z--1-9]+', ' ', text) text = re.sub(' +', ' ', text) return text.strip() data = [preprocess_text(t) for t in raw_data]
df_train=pd.DataFrame(columns=['Text', 'Label']) df_test=pd.DataFrame(columns=['Text', 'Label']) df_train['Text'], df_test['Text'], df_train['Label'], df_test['Label'] = train_test_split(data, labels, test_size=0.2, random_state=1)
df_val=pd.DataFrame(columns=['Text', 'Label']) df_train, df_val = train_test_split(df_train, test_size=0.2, random_state=1)
हम देखते हैं कि क्या हुआ:
df_train.groupby('Label').count()
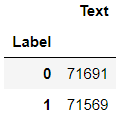
df_val.groupby('Label').count()
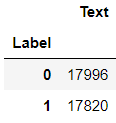
df_test.groupby('Label').count()

एक भाषा मॉडल सीखना
डेटा लोड हो रहा है:
tokenizer=Tokenizer(lang='xx') data_lm = TextLMDataBunch.from_df(path, tokenizer=tokenizer, bs=16, train_df=df_train, valid_df=df_val, text_cols=0)
हम सामग्री को देखते हैं:
data_lm.show_batch()

हम
पूर्व प्रशिक्षित मॉडल और एक शब्दकोश के संग्रहीत भार को लिंक प्रदान करते हैं:
weights_pretrained = 'ULMFit/lm_5_ep_lr2-3_5_stlr' itos_pretrained = 'ULMFit/itos' pretained_data = (weights_pretrained, itos_pretrained)
हम शिक्षार्थी बनाते हैं, लेकिन उससे पहले - उपवास के लिए एक बैसाखी। पूर्व-प्रशिक्षित मॉडल पुस्तकालय के एक पुराने संस्करण पर प्रशिक्षित किया गया था, इसलिए आपको तंत्रिका नेटवर्क की छिपी हुई परत में नोड्स की संख्या को समायोजित करने की आवश्यकता है।
config = awd_lstm_lm_config.copy() config['n_hid'] = 1150 learn_lm = language_model_learner(data_lm, AWD_LSTM, config=config, pretrained_fnames=pretained_data, drop_mult=0.3) learn_lm.freeze()
हम इष्टतम सीखने की दर की तलाश कर रहे हैं:
learn_lm.lr_find() learn_lm.recorder.plot()

हम तीसरे युग के मॉडल को प्रशिक्षित करते हैं (मॉडल में, केवल परतों का अंतिम समूह अपरिवर्तनीय है)।
learn_lm.fit_one_cycle(3, 1e-2, moms=(0.8, 0.7))
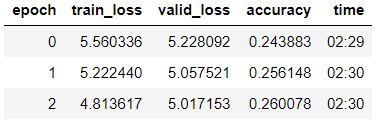
मॉडल को परिभाषित करना, कम सीखने की दर के साथ 5 और युगों को पढ़ाना:
learn_lm.unfreeze() learn_lm.fit_one_cycle(5, 1e-3, moms=(0.8, 0.7))

learn_lm.save('lm_ft')
हम एक प्रशिक्षित मॉडल पर पाठ उत्पन्न करने का प्रयास करते हैं।
learn_lm.predict(" ", n_words=5)
Out: ' '
learn_lm.predict(", ", n_words=4)
Out: ', '
हम देखते हैं - कुछ ऐसा जो मॉडल करता है। लेकिन हमारा मुख्य कार्य वर्गीकरण है, और इसके समाधान के लिए हम मॉडल से एक एनकोडर लेंगे।
learn_lm.save_encoder('ft_enc')
हम क्लासिफायर ट्रेन करते हैं
प्रशिक्षण के लिए डेटा डाउनलोड करें
data_clas = TextClasDataBunch.from_df(path, vocab=data_lm.train_ds.vocab, bs=32, train_df=df_train, valid_df=df_val, text_cols=0, label_cols=1, tokenizer=tokenizer)
आइए डेटा को देखें, हम देखते हैं कि लेबल सफलतापूर्वक गिने गए थे (0 का मतलब नकारात्मक है, और 1 का मतलब सकारात्मक टिप्पणी है):
data_clas.show_batch()

एक समान बैसाखी के साथ एक शिक्षार्थी बनाएँ:
config = awd_lstm_clas_config.copy() config['n_hid'] = 1150 learn = text_classifier_learner(data_clas, AWD_LSTM, config=config, drop_mult=0.5)
हम पिछले चरण में प्रशिक्षित एनकोडर को लोड करते हैं और मॉडल को भार के अंतिम समूह को छोड़कर फ्रीज करते हैं:
learn.load_encoder('ft_enc') learn.freeze()
हम इष्टतम सीखने की दर की तलाश कर रहे हैं:
learn.lr_find() learn.recorder.plot(skip_start=0)

हम परतों के क्रमिक विगलन के साथ मॉडल को प्रशिक्षित करते हैं।
learn.fit_one_cycle(2, 2e-2, moms=(0.8,0.7))
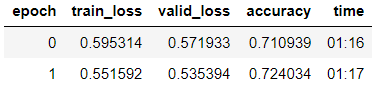
learn.freeze_to(-2) learn.fit_one_cycle(3, slice(1e-2/(2.6**4),1e-2), moms=(0.8,0.7))

learn.freeze_to(-3) learn.fit_one_cycle(2, slice(5e-3/(2.6**4),5e-3), moms=(0.8,0.7))

learn.unfreeze() learn.fit_one_cycle(2, slice(1e-3/(2.6**4),1e-3), moms=(0.8,0.7))

learn.save('tweet-0801')
हम देखते हैं कि सत्यापन के नमूने पर उन्होंने सटीकता = 80.1% हासिल की।
हम अपने पिछले लेख पर
ज़्लोडीबल टिप्पणी पर मॉडल का
परीक्षण करेंगे :
learn.predict(' — ?')
Out: (Category 0, tensor(0), tensor([0.6283, 0.3717]))
हम देखते हैं कि मॉडल ने इस टिप्पणी को नकारात्मक :-) के लिए जिम्मेदार ठहराया है
परीक्षण नमूने पर मॉडल की जाँच करना
इस स्तर पर मुख्य कार्य सामान्यीकरण क्षमता के लिए मॉडल का परीक्षण करना है। ऐसा करने के लिए, हम DataFrame df_test में संग्रहीत डेटासेट पर मॉडल को मान्य करते हैं, जो तब तक भाषा मॉडल या क्लासिफायरियर के लिए उपलब्ध नहीं था।
data_test_clas = TextClasDataBunch.from_df(path, vocab=data_lm.train_ds.vocab, bs=32, train_df=df_train, valid_df=df_test, text_cols=0, label_cols=1, tokenizer=tokenizer)
config = awd_lstm_clas_config.copy() config['n_hid'] = 1150 learn_test = text_classifier_learner(data_test_clas, AWD_LSTM, config=config, drop_mult=0.5)
learn_test.load_encoder('ft_enc') learn_test.load('tweet-0801')
learn_test.validate()
Out: [0.4391682, tensor(0.7973)]
हम देखते हैं कि परीक्षण नमूने पर सटीकता 79.7% थी।
भ्रम मैट्रिक्स पर एक नज़र डालें:
interp = ClassificationInterpretation.from_learner(learn) interp.plot_confusion_matrix()
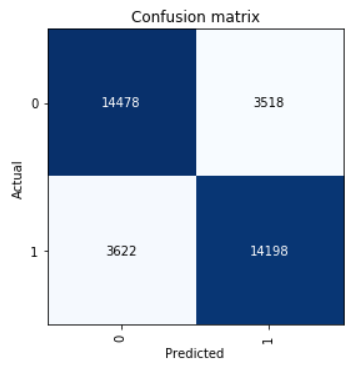
हम सटीक, रिकॉल और एफ 1 स्कोर मापदंडों की गणना करते हैं।
neg_precision = interp.confusion_matrix()[0][0] / (interp.confusion_matrix()[0][0] + interp.confusion_matrix()[1][0]) neg_recall = interp.confusion_matrix()[0][0] / (interp.confusion_matrix()[0][0] + interp.confusion_matrix()[0][1]) pos_precision = interp.confusion_matrix()[1][1] / (interp.confusion_matrix()[1][1] + interp.confusion_matrix()[0][1]) pos_recall = interp.confusion_matrix()[1][1] / (interp.confusion_matrix()[1][1] + interp.confusion_matrix()[1][0]) neg_f1score = 2 * (neg_precision * neg_recall) / (neg_precision + neg_recall) pos_f1score = 2 * (pos_precision * pos_recall) / (pos_precision + pos_recall)
print(' F1-score') print(' Negative {0:1.5f} {1:1.5f} {2:1.5f}'.format(neg_precision, neg_recall, neg_f1score)) print(' Positive {0:1.5f} {1:1.5f} {2:1.5f}'.format(pos_precision, pos_recall, pos_f1score)) print(' Average {0:1.5f} {1:1.5f} {2:1.5f}'.format(statistics.mean([neg_precision, pos_precision]), statistics.mean([neg_recall, pos_recall]), statistics.mean([neg_f1score, pos_f1score])))
Out: F1-score Negative 0.79989 0.80451 0.80219 Positive 0.80142 0.79675 0.79908 Average 0.80066 0.80063 0.80064
परीक्षण नमूना औसत F1-स्कोर = 0.80064 में दिखाया गया परिणाम।
सहेजे गए मॉडल वजन को
यहां ले जाया जा सकता
है ।