नमस्कार, हेब्र! इस लेख में मैं यह बताने की कोशिश करूंगा कि कार्यक्रमों / अनुप्रयोगों में मेमोरी प्रबंधन एक एप्लिकेशन प्रोग्रामर के दृष्टिकोण से क्या है। यह एक संपूर्ण मार्गदर्शक या मैनुअल नहीं है, बल्कि मौजूदा समस्याओं का एक सिंहावलोकन और उन्हें हल करने के लिए कुछ दृष्टिकोण हैं।
यह क्यों आवश्यक है? एक प्रोग्राम डेटा प्रोसेसिंग निर्देशों का एक क्रम है (सबसे सामान्य स्थिति में)। इस डेटा को किसी तरह से संग्रहीत , लोड , स्थानांतरित , आदि करने की आवश्यकता है। ये सभी ऑपरेशन तुरंत नहीं होते हैं, इसलिए, वे सीधे आपके अंतिम आवेदन की गति को प्रभावित करते हैं। कार्य की प्रक्रिया में डेटा को बेहतर ढंग से प्रबंधित करने की क्षमता आपको बहुत गैर-तुच्छ और बहुत संसाधन-मांग वाले कार्यक्रम बनाने की अनुमति देगा।
नोट: सामग्री का थोक खेल / खेल इंजन (उदाहरण के लिए यह विषय मेरे लिए व्यक्तिगत रूप से अधिक दिलचस्प है) से उदाहरण के साथ प्रस्तुत किया गया है, हालांकि, अधिकांश सामग्री लेखन सर्वर, उपयोगकर्ता अनुप्रयोगों, ग्राफिक्स पैकेज, आदि के लिए लागू की जा सकती है।

हर चीज को ध्यान में रखना असंभव है। लेकिन अगर आपने इसे लोड करने का प्रबंधन नहीं किया है, तो आपको साबुन मिलेगा
बल्ले से ही सही
यह उद्योग में ऐसा हुआ कि बड़े एएए गेम प्रोजेक्ट मुख्य रूप से C ++ का उपयोग करने वाले इंजनों पर विकसित किए गए हैं। इस भाषा की विशेषताओं में से एक मैनुअल मेमोरी प्रबंधन की आवश्यकता है। जावा / सी # आदि। वे कचरा संग्रह (कचरा कचरा / जीसी) का दावा करते हैं - वस्तुओं को बनाने की क्षमता और अभी भी हाथ से उपयोग की गई स्मृति को मुक्त नहीं करते हैं। यह प्रक्रिया विकास को सरल और गति प्रदान करती है, लेकिन यह कुछ समस्याएं भी पैदा कर सकती है: समय-समय पर ट्रिगर किया गया कचरा कलेक्टर सभी नरम-वास्तविक समय को मार सकता है और खेल में अप्रिय फ्रीज जोड़ सकता है।
हां, "Minecraft" जैसी परियोजनाओं में GC ध्यान देने योग्य नहीं हो सकता है, जैसा कि वे आम तौर पर कंप्यूटर के संसाधनों पर मांग नहीं कर रहे हैं, लेकिन सिस्टम प्रदर्शन के चरम पर "रेड डेड रिडेम्पशन 2", "गॉड ऑफ वॉर", "लास्ट ऑफ अस" काम "लगभग" जैसे खेल हैं और इसलिए न केवल बड़े की जरूरत है संसाधनों की मात्रा, लेकिन उनके सक्षम वितरण में भी।
इसके अलावा, स्वचालित मेमोरी आवंटन और कचरा संग्रह के साथ एक वातावरण में काम करना, आप संसाधन प्रबंधन में लचीलेपन की कमी का सामना कर सकते हैं। यह कोई रहस्य नहीं है कि जावा अपने काम के सभी कार्यान्वयन विवरण और पहलुओं को हुड के नीचे छिपाता है, इसलिए आउटपुट पर आपके पास सिस्टम संसाधनों के साथ बातचीत करने के लिए केवल स्थापित इंटरफ़ेस है, लेकिन यह कुछ समस्याओं को हल करने के लिए पर्याप्त नहीं हो सकता है। उदाहरण के लिए, प्रत्येक फ्रेम में गैर-निरंतर संख्या में मेमोरी आवंटन के साथ एक एल्गोरिथ्म शुरू करना (यह एआई के लिए रास्तों की खोज हो सकती है, दृश्यता, एनीमेशन, आदि की जांच कर सकता है) अनिवार्य रूप से प्रदर्शन में एक भयावह गिरावट की ओर जाता है।
कोड में आवंटन कैसे दिखते हैं
चर्चा जारी रखने से पहले, मैं यह दिखाना चाहूंगा कि सी / सी ++ में मेमोरी के साथ काम सीधे उदाहरण के एक जोड़े के साथ कैसे होता है। सामान्य तौर पर, प्रक्रिया मेमोरी आवंटित करने के लिए मानक और सरलतम इंटरफ़ेस निम्नलिखित कार्यों द्वारा दर्शाया जाता है:
// size void* malloc(size_t size); // p void free(void* p);
यहां आप अतिरिक्त कार्यों के बारे में जोड़ सकते हैं जो आपको स्मृति के एक गठबंधन को आवंटित करने की अनुमति देते हैं:
// C11 - , * alignment void* aligned_alloc(size_t size, size_t alignment); // Posix - // address (*address = allocated_mem_p) int posix_memalign(void** address, size_t alignment, size_t size);
कृपया ध्यान दें कि विभिन्न प्लेटफ़ॉर्म विभिन्न फ़ंक्शन मानकों का समर्थन कर सकते हैं, उदाहरण के लिए macOS पर उपलब्ध है और जीतने पर उपलब्ध नहीं है।
आगे देखते हुए, प्रोसेसर के कैश लाइन को हिट करने और रजिस्टरों के एक विस्तारित सेट ( एसएसई , एमएमएक्स , एवीएक्स , आदि) का उपयोग करके गणना के लिए मेमोरी के विशेष रूप से संरेखित क्षेत्र आपके लिए आवश्यक हो सकते हैं।
एक खिलौना कार्यक्रम का एक उदाहरण जो स्मृति को आवंटित करता है और बफर मूल्यों को प्रिंट करता है, उन्हें हस्ताक्षरित पूर्णांक के रूप में व्याख्या करता है:
/* main.cpp */ #include <cstdio> #include <cstdlib> int main(int argc, char** argv) { const int N = 10; int* buffer = (int*) malloc(sizeof(int) * N); for(int i = 0; i < N; i++) { printf("%i ", buffer[i]); } free(buffer); return 0; }
MacOS 10.14 पर, इस प्रोग्राम को कमांड के निम्नलिखित सेट के साथ बनाया और चलाया जा सकता है:
$ clang++ main.cpp -o main $ ./main
नोट: इसके बाद मैं वास्तव में C ++ ऑपरेशंस जैसे कि नए / डिलीट को कवर नहीं करना चाहता हूं, क्योंकि वे ऑब्जेक्ट्स को सीधे बनाने / नष्ट करने के लिए उपयोग किए जाने की अधिक संभावना रखते हैं, लेकिन वे मेमोरी के साथ सामान्य संचालन का उपयोग करते हैं जैसे कि मॉलॉक / फ्री।
याददाश्त की समस्या
कंप्यूटर की रैम के साथ काम करते समय कई समस्याएं आती हैं। वे सभी, एक तरह से या किसी अन्य, न केवल ओएस और सॉफ़्टवेयर की सुविधाओं के कारण होते हैं, बल्कि लोहे की वास्तुकला से भी होते हैं, जिस पर यह सब काम करता है।
1. स्मृति की मात्रा
दुर्भाग्य से, स्मृति शारीरिक रूप से सीमित है। PlayStation 4 पर, यह 8 GiB GDDR5, 3.5 GiB है जिसमें से ऑपरेटिंग सिस्टम इसकी जरूरतों के लिए आरक्षित है । वर्चुअल मेमोरी और पेज स्वैपिंग ज्यादा मदद नहीं करेगी, क्योंकि पेज को डिस्क पर स्वैप करना एक बहुत ही धीमा ऑपरेशन है (अगर हम गेम के बारे में बात करें तो प्रति सेकंड निश्चित एन फ्रेम के भीतर)।
यह सीमित " बजट " पर ध्यान देने योग्य भी है - कई प्लेटफार्मों पर एप्लिकेशन को चलाने के लिए उपयोग की गई मेमोरी की मात्रा पर कुछ कृत्रिम सीमा। यदि आप एक मोबाइल प्लेटफ़ॉर्म के लिए एक गेम बना रहे हैं और न केवल एक, बल्कि उपकरणों की एक पूरी लाइन का समर्थन करना चाहते हैं, तो आपको एक व्यापक बिक्री बाजार प्रदान करने के लिए अपने भूखों को सीमित करना होगा। यह केवल रैम की खपत को सीमित करके, और इस प्रतिबंध को कॉन्फ़िगर करने की क्षमता के आधार पर प्राप्त किया जा सकता है जिस पर गैजेट वास्तव में शुरू होता है।
2. विखंडन
एक अप्रिय प्रभाव जो विभिन्न आकारों की स्मृति के टुकड़ों के कई आवंटन की प्रक्रिया के दौरान प्रकट होता है। नतीजतन, आपको कई अलग-अलग हिस्सों में खंडित एक पता जगह मिलती है। इन भागों को एक बड़े आकार के एकल खंडों में संयोजित करने से काम नहीं चलेगा, क्योंकि स्मृति के हिस्से पर कब्जा है, और हम इसे स्वतंत्र रूप से स्थानांतरित नहीं कर सकते हैं।
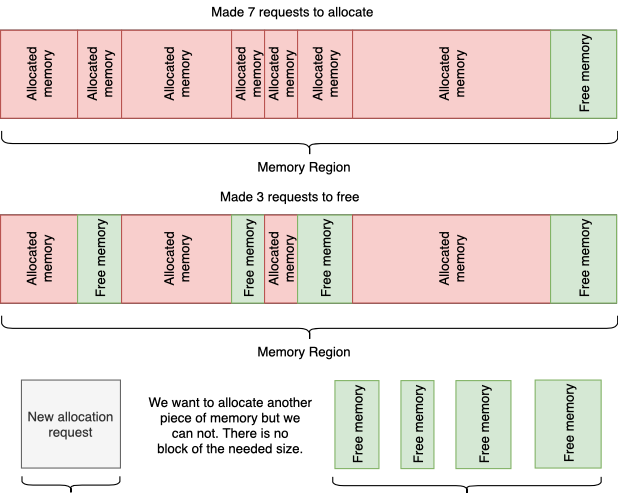
अनुक्रमिक आवंटन और मेमोरी ब्लॉकों के रिलीज के उदाहरण द्वारा विखंडन
परिणामस्वरूप: हमारे पास पर्याप्त मात्रा में मुक्त मेमोरी हो सकती है, लेकिन गुणात्मक रूप से नहीं। और अगला अनुरोध, कहते हैं, "ऑडियो ट्रैक के लिए स्थान आवंटित करें", आवंटनकर्ता को संतुष्ट करने में सक्षम नहीं होगा, क्योंकि इस आकार की स्मृति का बस एक टुकड़ा नहीं है।
3. सीपीयू कैश

कंप्यूटर मेमोरी पदानुक्रम
एक आधुनिक प्रोसेसर का कैश एक मध्यवर्ती लिंक है जो मुख्य मेमोरी (रैम) को जोड़ता है और प्रोसेसर सीधे रजिस्टर करता है। ऐसा हुआ है कि मेमोरी में एक्सेस पढ़ना / लिखना एक बहुत धीमा ऑपरेशन है (यदि हम निष्पादित करने के लिए आवश्यक सीपीयू घड़ी चक्रों की संख्या के बारे में बात करते हैं)। इसलिए, कुछ कैश पदानुक्रम (L1, L2, L3, आदि) है, जो अनुमति देता है, जैसा कि रैम से डेटा लोड करने के लिए "कुछ भविष्यवाणी के अनुसार" था, या धीरे-धीरे इसे धीमी मेमोरी में धकेल दें।
स्मृति में एक ही प्रकार की वस्तुओं को रखने से आप उन्हें प्रसंस्करण की प्रक्रिया को "महत्वपूर्ण रूप से" गति दे सकते हैं (यदि प्रसंस्करण क्रमिक रूप से होता है), क्योंकि इस मामले में यह अनुमान लगाना आसान है कि आगे क्या डेटा की आवश्यकता होगी। और "महत्वपूर्ण" से तात्पर्य कई बार उत्पादकता लाभ से है। एकता इंजन के डेवलपर्स ने जीडीसी में अपनी रिपोर्ट में बार-बार इस बारे में बात की है।
4. मल्टी-थ्रेडिंग
बहु-थ्रेडेड वातावरण में साझा मेमोरी तक सुरक्षित पहुंच सुनिश्चित करना मुख्य समस्याओं में से एक है जिसे आपको अपना गेम इंजन / गेम / कोई अन्य एप्लिकेशन बनाते समय हल करना होगा जो अधिक प्रदर्शन प्राप्त करने के लिए कई थ्रेड का उपयोग करता है। आधुनिक कंप्यूटरों को बहुत ही गैर-तुच्छ तरीके से व्यवस्थित किया जाता है। हमारे पास एक जटिल कैश संरचना और कई कैलकुलेटर कोर हैं। यह सब, अगर अनुचित तरीके से उपयोग किया जाता है, तो उन स्थितियों को जन्म दे सकता है जब आपकी प्रक्रिया का साझा डेटा कई थ्रेड्स के परिणामस्वरूप क्षतिग्रस्त हो जाएगा (यदि वे एक साथ एक्सेस कंट्रोल के बिना इस डेटा के साथ काम करने की कोशिश करते हैं)। सबसे सरल मामले में, यह इस तरह दिखेगा:
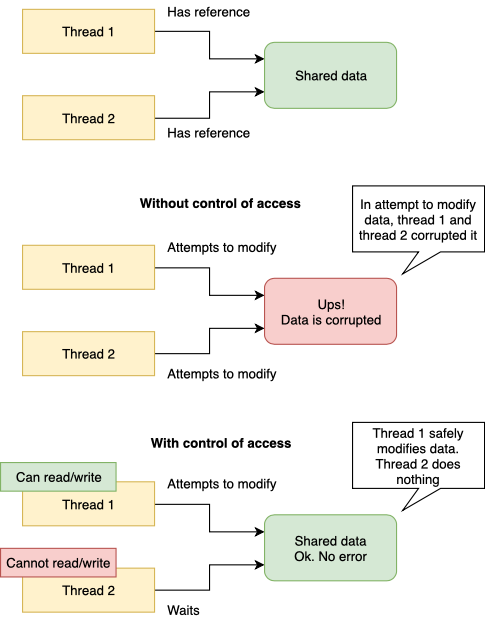
मैं बहु-थ्रेडेड प्रोग्रामिंग के विषय में तल्लीन नहीं करना चाहता, क्योंकि इसके कई पहलू लेख या पूरी किताब के दायरे से बहुत दूर जाते हैं।
5. मलोक / मुक्त
आवंटन / रिलीज संचालन तुरंत नहीं होते हैं। आधुनिक ऑपरेटिंग सिस्टम पर, अगर हम विंडोज / लिनक्स / मैकओएस के बारे में बात कर रहे हैं, तो वे अच्छी तरह से लागू होते हैं और अधिकांश स्थितियों में जल्दी से काम करते हैं। लेकिन संभावित रूप से यह बहुत समय लेने वाला ऑपरेशन है। न केवल यह एक प्रणाली कॉल है, लेकिन कार्यान्वयन के आधार पर, उपयुक्त मेमोरी (फर्स्ट फिट, बेस्ट फिट, आदि) को खोजने या मुक्त क्षेत्र को सम्मिलित करने और / या विलय करने के लिए जगह खोजने में कुछ समय लग सकता है।
इसके अलावा, ताजा आवंटित मेमोरी वास्तव में वास्तविक भौतिक पृष्ठों पर मैप नहीं की जा सकती है, जिसमें पहली बार उपयोग करने में कुछ समय भी लग सकता है।
ये कार्यान्वयन विवरण हैं, लेकिन प्रयोज्यता के बारे में क्या? Malloc / नए का कोई पता नहीं है कि आपने कहां, कैसे या क्यों उन्हें बुलाया है। वे 1 KiB और 100 MiB की मेमोरी (सबसे खराब स्थिति में) समान रूप से ... समान रूप से खराब आवंटित करते हैं। सीधे तौर पर, उपयोग की रणनीति को या तो प्रोग्रामर या आपके प्रोग्राम के रनटाइम को लागू करने वाले के लिए छोड़ दिया जाता है।
6. स्मृति भ्रष्टाचार
जैसा कि विकी कहते हैं , यह सबसे अप्रत्याशित त्रुटियों में से एक है जो केवल कार्यक्रम के दौरान दिखाई देता है, और इस कार्यक्रम के लेखन में त्रुटियों के कारण अक्सर होता है। लेकिन यह समस्या क्या है? सौभाग्य से (या दुर्भाग्य से), यह आपके कंप्यूटर के भ्रष्टाचार से संबंधित नहीं है। इसके बजाय, यह एक ऐसी स्थिति को प्रदर्शित करता है, जिसमें आप उस मेमोरी के साथ काम करने की कोशिश कर रहे हैं जो आपकी नहीं है । अब मैं समझाऊंगा:
- यह असंबद्ध स्मृति के एक हिस्से को पढ़ने / लिखने का प्रयास हो सकता है।
- आपको प्रदान की गई मेमोरी ब्लॉक की सीमाओं से परे जाकर। यह समस्या एक प्रकार की विशेष समस्या (1) है, लेकिन यह बदतर है क्योंकि सिस्टम आपको बताएगा कि आप केवल सीमाओं से परे गए हैं जब आप आपके लिए प्रदर्शित पृष्ठ छोड़ देते हैं। यही है, संभावित रूप से, यह समस्या पकड़ना बहुत मुश्किल है, क्योंकि ओएस केवल तब ही जवाब देने में सक्षम है जब आप अपने द्वारा प्रदर्शित आभासी पृष्ठों की सीमा को छोड़ देते हैं। आप प्रक्रिया मेमोरी को खराब कर सकते हैं और उस स्थान से बहुत अजीब त्रुटि प्राप्त कर सकते हैं जहां से यह बिल्कुल भी अपेक्षित नहीं था।
- पहले से मुक्त (अजीब लगता है) जारी करना या अभी तक आवंटित स्मृति नहीं है
- आदि
C / C ++ में, जहां सूचक अंकगणित है, आप एक या दो बार इस पार आ जाएंगे। हालांकि, जावा रनटाइम में, आपको इस तरह की त्रुटि को प्राप्त करने के लिए बहुत कठिन पसीना बहाना पड़ता है (मैंने खुद इसे आज़माया नहीं है, लेकिन मुझे लगता है कि यह संभव है, अन्यथा जीवन बहुत सरल होगा)।
7. मेमोरी लीक
यह अधिक सामान्य समस्या का एक विशेष मामला है जो कई प्रोग्रामिंग भाषाओं में होता है। मानक C / C ++ लाइब्रेरी OS संसाधनों तक पहुँच प्रदान करता है। यह फाइलें, सॉकेट, मेमोरी आदि हो सकती हैं। उपयोग के बाद, संसाधन सही ढंग से बंद होना चाहिए और
उसके द्वारा कब्जा की गई स्मृति को मुक्त किया जाना चाहिए। और अगर हम विशेष रूप से मेमोरी को मुक्त करने के बारे में बात करते हैं - प्रोग्राम के परिणामस्वरूप संचित लीक एक "मेमोरी से बाहर" त्रुटि का कारण बन सकता है जब ओएस आवंटन के लिए अगले अनुरोध को पूरा करने में सक्षम नहीं होगा। अक्सर, डेवलपर केवल एक कारण या किसी अन्य के लिए उपयोग की गई मेमोरी को मुक्त करना भूल जाता है।
यहां GPU पर संसाधनों के सही समापन और रिलीज के बारे में जोड़ना उचित है, क्योंकि पिछले सत्र सही तरीके से पूरा नहीं होने पर शुरुआती ड्राइवरों ने वीडियो कार्ड के साथ काम करना फिर से शुरू करने की अनुमति नहीं दी थी। केवल सिस्टम को रिबूट करने से इस समस्या का समाधान हो सकता है, जो बहुत ही संदिग्ध है - उपयोगकर्ता को आपके एप्लिकेशन को चलाने के बाद सिस्टम को रिबूट करने के लिए मजबूर करना।
8. डेंजरिंग पॉइंटर
डैंगलिंग पॉइंटर कुछ शब्दजाल है जो ऐसी स्थिति का वर्णन करता है जहां एक पॉइंटर एक अमान्य मान को संदर्भित करता है। सी / सी ++ प्रोग्राम में क्लासिक सी-स्टाइल पॉइंटर्स का उपयोग करते समय एक समान स्थिति आसानी से उत्पन्न हो सकती है। मान लीजिए कि आपने मेमोरी आवंटित की है, पी पॉइंटर में उसका पता सेव किया और फिर मेमोरी को मुक्त कर दिया (कोड उदाहरण देखें):
// void* p = malloc(size); // ... - // free(p); // p? // *p == ?
सूचक कुछ मान संग्रहीत करता है, जिसे हम मेमोरी ब्लॉक के पते के रूप में व्याख्या कर सकते हैं। ऐसा हुआ कि हम यह नहीं कह सकते कि यह मेमोरी ब्लॉक वैध है या नहीं। केवल एक प्रोग्रामर, कुछ समझौतों के आधार पर, एक सूचक के साथ काम कर सकता है। C ++ 11 से शुरू करके, कई अतिरिक्त "स्मार्ट पॉइंटर्स" पॉइंटर्स को मानक पुस्तकालय में पेश किया गया था, जो प्रोग्रामर द्वारा स्वयं के अंदर अतिरिक्त मेटा-जानकारी का उपयोग करके संसाधन नियंत्रण को कमजोर करने की अनुमति देते हैं (इस पर बाद में अधिक)।
आंशिक समाधान के रूप में, आप सूचक के विशेष मूल्य का उपयोग कर सकते हैं, जो हमें संकेत देगा कि इस पते पर कुछ भी नहीं है। C में, NULL मैक्रो का उपयोग इस मान के मान के रूप में किया जाता है, और C ++ में, nullptr भाषा कीवर्ड का उपयोग किया जाता है। समाधान आंशिक है, क्योंकि:
- पॉइंटर मान को मैन्युअल रूप से सेट किया जाना चाहिए, इसलिए प्रोग्रामर इसे करना भूल सकता है।
- nullptr या सिर्फ 0x0 पॉइंटर द्वारा स्वीकार किए गए मूल्यों के सेट में शामिल है, जो तब अच्छा नहीं होता जब किसी वस्तु की विशेष अवस्था को उसके सामान्य अवस्था के माध्यम से व्यक्त किया जाता है। यह किसी प्रकार की विरासत है, और समझौते से, ओएस आपको स्मृति का एक टुकड़ा आवंटित नहीं करेगा, जिसका पता 0x0 से शुरू होता है।
नल के साथ नमूना कोड:
// - p free(p); p = nullptr; // p == nullptr ,
आप इस प्रक्रिया को कुछ हद तक स्वचालित कर सकते हैं:
void _free(void* &p) { free(p); p = nullptr; } // - p _free(p); // p == nullptr, //
9. स्मृति का प्रकार
RAM एक सामान्य सामान्य-उद्देश्य रैंडम एक्सेस मेमोरी है, जिसकी पहुंच केंद्रीय बस के माध्यम से आपके प्रोसेसर और परिधीय उपकरणों के सभी कोर तक है। इसकी मात्रा भिन्न होती है, लेकिन अक्सर हम एन गीगाबाइट्स के बारे में बात कर रहे हैं, जहां एन 1,2,4,8,16 और इतने पर है। कंप्यूटर की रैम में आप जो मेमोरी चाहते हैं, उसके ब्लॉक को रखने के लिए मॉलॉक / फ्री की तलाश करें।
वीआरएएम (वीडियो मेमोरी) - वीडियो मेमोरी, जो आपके पीसी के वीडियो कार्ड / वीडियो त्वरक के साथ आपूर्ति की जाती है। यह, एक नियम के रूप में, रैम (लगभग 1.2.4 GiB) से छोटा है, लेकिन इसकी उच्च गति है। इस प्रकार की मेमोरी का वितरण वीडियो कार्ड ड्राइवर द्वारा संभाला जाता है, और अक्सर आपके पास इसका सीधा उपयोग नहीं होता है।
PlayStation 4 पर ऐसा कोई पृथक्करण नहीं है, और सभी RAM को GDDR5 पर एक एकल 8 गीगाबाइट द्वारा दर्शाया गया है। इसलिए, प्रोसेसर और वीडियो त्वरक दोनों के लिए सभी डेटा पास हैं।
गेम इंजन में अच्छे संसाधन प्रबंधन में मुख्य RAM और VRAM दोनों में सक्षम मेमोरी आवंटन शामिल हैं। जब आप एक ही डेटा वहाँ और वहाँ, या RAM से VRAM और इसके विपरीत डेटा के अत्यधिक हस्तांतरण के साथ यहाँ दोहराव का सामना कर सकते हैं।
आवाज उठाई गई सभी समस्याओं के दृष्टांत के रूप में : आप डिवाइस कंप्यूटर के पहलुओं को PlayStation (आर्किटेक्चर) (Fig।) के उदाहरण पर देख सकते हैं। यहां केंद्रीय प्रोसेसर, 8 कोर, एल 1 और एल 2 स्तर के कैश, डेटा बसें, रैम, ग्राफिक्स त्वरक, आदि हैं। पूर्ण और विस्तृत विवरण के लिए, जेसन ग्रेगरी के "गेम इंजन आर्किटेक्चर" को देखें ।
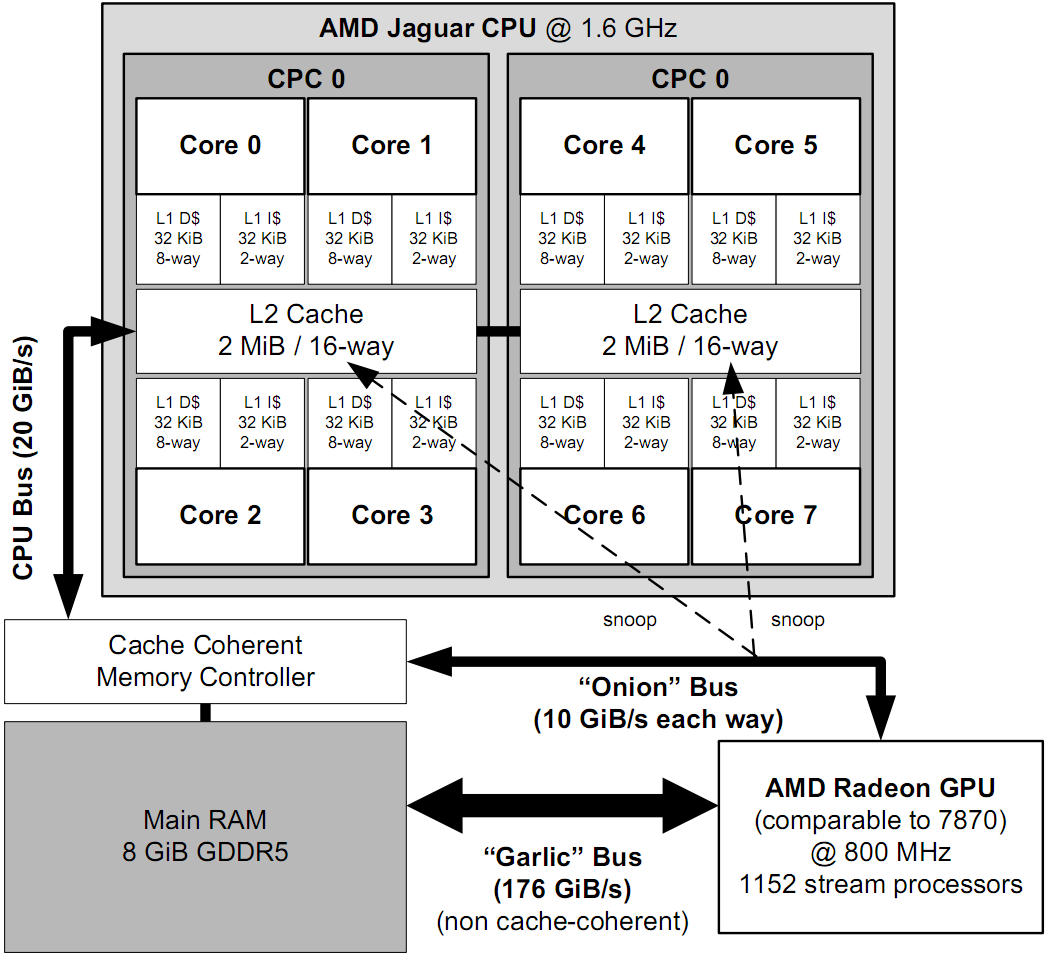
प्लेस्टेशन 4 आर्किटेक्चर
सामान्य दृष्टिकोण
कोई सार्वभौमिक समाधान नहीं है। लेकिन कुछ बिंदुओं का एक सेट है जिस पर आपको ध्यान देना चाहिए यदि आप अपने आवेदन में मैन्युअल आवंटन और स्मृति प्रबंधन को लागू करने जा रहे हैं। इसमें कंटेनर और विशेष आवंटनकर्ता, मेमोरी आवंटन रणनीति, सिस्टम / गेम डिज़ाइन, संसाधन प्रबंधक, और बहुत कुछ शामिल हैं।
आवंटनकर्ताओं के प्रकार
विशेष मेमोरी एलोकेटर्स का उपयोग निम्नलिखित विचार पर आधारित है: आप जानते हैं कि किस आकार में, किस क्षण काम करते हैं और किस स्थान पर आपको मेमोरी के टुकड़ों की आवश्यकता होगी। इसलिए, आप आवश्यक मेमोरी को आवंटित कर सकते हैं, किसी तरह इसे संरचना और उपयोग / पुन: उपयोग कर सकते हैं। यह विशेष आवंटनकर्ताओं का उपयोग करने का सामान्य विचार / अवधारणा है। वे (निश्चित रूप से, सभी नहीं) आगे देखे जा सकते हैं:
रैखिक आवंटनकर्ता
एक सन्निहित पते अंतरिक्ष बफर का प्रतिनिधित्व करता है। काम के दौरान, यह आपको मनमाने आकार की स्मृति के वर्गों को आवंटित करने की अनुमति देता है (जैसे कि वे एक बफर में फिट होते हैं)। लेकिन आप सभी आवंटित मेमोरी को केवल 1 बार मुक्त कर सकते हैं। यह है कि स्मृति के एक मनमाने टुकड़े को मुक्त नहीं किया जा सकता है - यह तब तक रहेगा जब तक पूरे बफर को स्वच्छ के रूप में चिह्नित नहीं किया जाता। यह डिज़ाइन O (1) का आवंटन और रिलीज़ प्रदान करता है, जो किसी भी परिस्थिति में गति की गारंटी देता है।
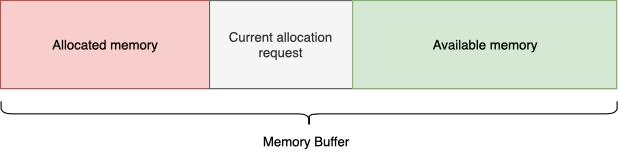
विशिष्ट उपयोग-मामला: प्रक्रिया की स्थिति को अपडेट करने की प्रक्रिया में (गेम में हर फ्रेम) आप किसी तकनीकी जरूरतों के लिए tmp बफ़र्स आवंटित करने के लिए LinearAllocator का उपयोग कर सकते हैं: इनपुट प्रोसेसिंग, स्ट्रिंग्स के साथ काम करना, डिबग मोड में कॉनसर्फमैन कमांड को पार्स करना आदि।
ढेर का आवंटन करनेवाला
एक रैखिक आवंटनकर्ता का संशोधन। आपको आवंटन के रिवर्स ऑर्डर में मेमोरी को मुक्त करने की अनुमति देता है, दूसरे शब्दों में, एलआईएफओ सिद्धांत के अनुसार एक नियमित स्टैक की तरह व्यवहार करता है। यह लोडिंग गणितीय गणनाओं (परिवर्तनों का पदानुक्रम) को पूरा करने के लिए बहुत उपयोगी हो सकता है, स्क्रिप्टिंग सबसिस्टम के काम को लागू करने के लिए, किसी भी गणना के लिए जहां मेमोरी को मुक्त करने के लिए संकेतित प्रक्रिया को पहले से जाना जाता है।
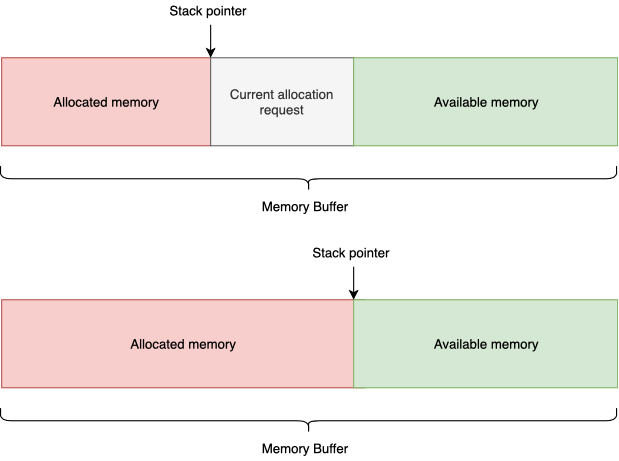
डिजाइन की सादगी O (1) मेमोरी आवंटन और फ्रीजिंग गति प्रदान करती है।
पूल का आवंटन करने वाला
आपको समान आकार के मेमोरी ब्लॉक आवंटित करने की अनुमति देता है। इसे एक पूर्व निर्धारित आकार के ब्लॉकों में विभाजित निरंतर पता स्थान के बफर के रूप में लागू किया जा सकता है। ये ब्लॉक एक लिंक की गई सूची बना सकते हैं। और हम हमेशा जानते हैं कि अगले आवंटन में कौन सा ब्लॉक देना है। इस मेटा जानकारी को स्वयं ब्लॉकों में संग्रहीत किया जा सकता है, जो न्यूनतम ब्लॉक आकार (आकार) (शून्य *) पर प्रतिबंध लगाता है। वास्तव में, यह महत्वपूर्ण नहीं है।
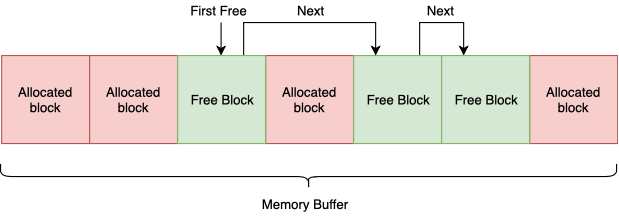
चूंकि सभी ब्लॉक समान आकार के हैं, इसलिए हमारे लिए यह महत्वपूर्ण नहीं है कि कौन सा ब्लॉक लौटाया जाए, और इसलिए, सभी आवंटन / डीलआउट संचालन ओ (1) में किए जा सकते हैं।
फ्रेम आबंटक
रैखिक आवंटनकर्ता लेकिन केवल वर्तमान फ्रेम के संदर्भ में - आपको tmp मेमोरी आवंटन करने की अनुमति मिलती है और फिर फ्रेम बदलते समय स्वचालित रूप से सबकुछ छोड़ देते हैं। इसे अलग से एकल किया जाना चाहिए, क्योंकि यह रनटाइम गेम के ढांचे के भीतर कुछ वैश्विक और अनोखी इकाई है, और इसलिए इसे बहुत प्रभावशाली आकार का बनाया जा सकता है, एक दर्जन MiB के एक जोड़े का कहना है, जो संसाधनों को लोड करने और उन्हें संसाधित करते समय बहुत उपयोगी होगा।
डबल फ्रेम आवंटन
यह एक डबल फ्रेम एलोकेटर है, लेकिन कुछ विशेषताओं के साथ। यह आपको वर्तमान फ्रेम में मेमोरी आवंटित करने की अनुमति देता है, और इसे वर्तमान और अगले फ्रेम दोनों में उपयोग करता है। यही है, मेमोरी जिसे आपने फ्रेम एन में आवंटित किया है, एन + 1 फ्रेम के बाद ही मुक्त किया जाएगा। यह प्रत्येक फ़्रेम के अंत में हाइलाइट करने के लिए सक्रिय फ़्रेम को स्विच करके महसूस किया जाता है।
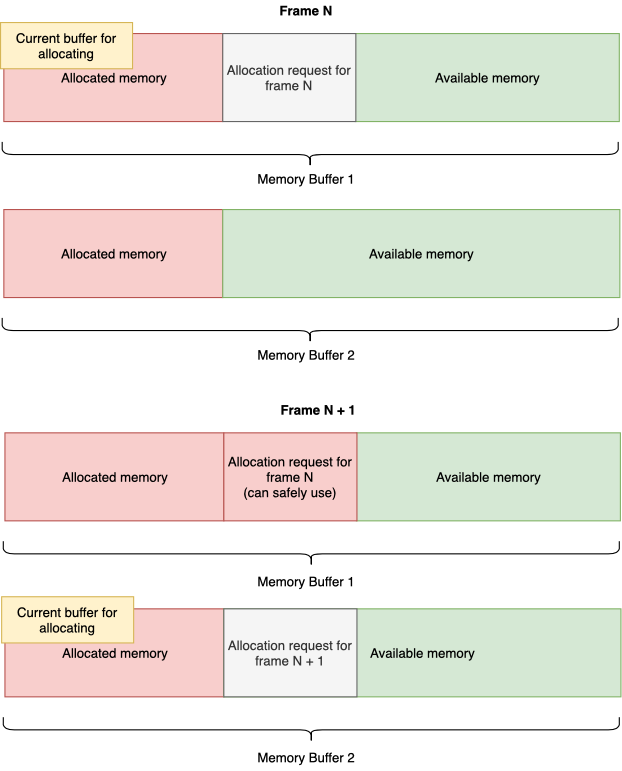
लेकिन इस प्रकार के आवंटनकर्ता, पिछले वाले की तरह, इसे आवंटित की गई मेमोरी में बनाई गई वस्तुओं के जीवनकाल पर कई प्रतिबंध लगाते हैं। इसलिए, आपको पता होना चाहिए कि फ्रेम के अंत में, डेटा बस अमान्य हो जाता है, और उनके लिए बार-बार पहुंच गंभीर समस्याएं पैदा कर सकती है।
स्थैतिक आवंटनकर्ता
इस प्रकार के आवंटनकर्ता प्राप्त मेमोरी को एक बफर से आवंटित करता है, उदाहरण के लिए, प्रोग्राम लॉन्च चरण में, या फ़ंक्शन फ़्रेम में स्टैक पर कब्जा कर लिया गया। प्रकार से, यह बिल्कुल किसी भी आवंटनकर्ता हो सकता है: रैखिक, पूल, स्टैक। इसे स्थैतिक क्यों कहा जाता है? कैप्चर किए गए मेमोरी बफ़र का आकार कार्यक्रम के संकलन के चरण में जाना जाना चाहिए। यह एक महत्वपूर्ण सीमा लगाता है: इस आवंटन के लिए उपलब्ध मेमोरी की मात्रा को ऑपरेशन के दौरान नहीं बदला जा सकता है। लेकिन इसके क्या फायदे हैं? उपयोग किए गए बफर को स्वचालित रूप से कैप्चर किया जाएगा और फिर मुक्त किया जाएगा (या तो काम पूरा होने पर या फ़ंक्शन से बाहर निकलने पर)। यह ढेर को लोड नहीं करता है, आपको विखंडन से बचाता है, आपको जगह में स्मृति को जल्दी से आवंटित करने की अनुमति देता है।
आप इस एलोकेटर का उपयोग करके कोड का उदाहरण देख सकते हैं, यदि आपको स्ट्रिंग को सब्सट्रिंग में तोड़ने और उनके साथ कुछ करने की आवश्यकता है:

यह भी ध्यान दिया जा सकता है कि सिद्धांत में स्टैक से मेमोरी का उपयोग अधिक कुशल है, क्योंकि एक उच्च संभावना के साथ वर्तमान फ़ंक्शन के फ्रेम को स्टैक करें पहले से ही प्रोसेसर कैश में होगा।
ये सभी आबंटक किसी न किसी तरह से विखंडन के साथ समस्याओं को हल करते हैं, स्मृति की कमी के साथ, आवश्यक आकार के ब्लॉक प्राप्त करने और जारी करने की गति के साथ, वस्तुओं के जीवनकाल और वे जिस स्मृति पर कब्जा करते हैं।
यह भी ध्यान दिया जाना चाहिए कि इंटरफ़ेस डिज़ाइन का सही तरीका आपको आवंटनकर्ताओं की एक प्रकार की पदानुक्रम बनाने की अनुमति देगा, उदाहरण के लिए: पूल फ्रेम आवंटन से मेमोरी आवंटित करता है, और बदले में आवंटित किया गया फ्रेम रैखिक आवंटन से मेमोरी आवंटित करता है। इसी तरह की संरचना को आगे भी जारी रखा जा सकता है, अपने कार्यों और जरूरतों के अनुरूप।
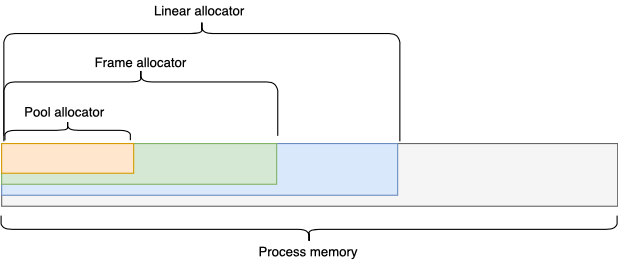
मैं इस प्रकार के पदानुक्रम बनाने के लिए एक समान इंटरफ़ेस देखता हूं:
class IAllocator { public: virtual void* alloc(size_t size) = 0; virtual void* alloc(size_t size, size_t alignment) = 0; virtual void free (void* &p) = 0; }
malloc/free , . , , . / , .
Smart pointer — C++ ++11 ( boost, ). -, , - , . .
? :
- (/)
:
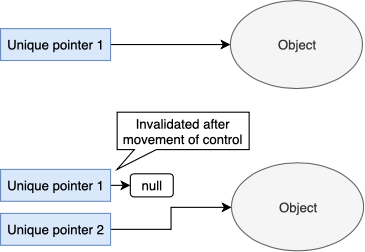
Unique pointer
1 ( ).
unique pointer , . , .. 1 / .
uniquePtr1 uniquePtr2, uniquePtr1 , . 1 .
Shared pointer
(reference counting). , , . , , , .
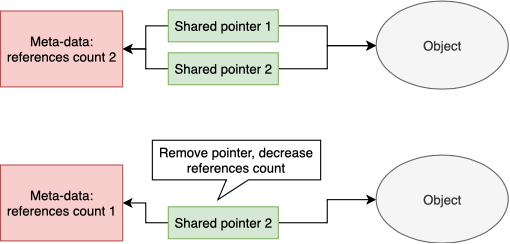
. -, , . . -, - .
Weak pointer
. , . इसका क्या मतलब है? shared pointer. , shared pointer , . , shared pointer weak pointer. , (shared) , weak pointer shared pointer. — weak pointer , , , .

shared, weak pointer meta-data . - , .. , O(N) overhead , N — - . , . , . .
: . , shared pointer, , ( ) - - - . . meta-info , , . एक उदाहरण:
/* */ /* , shared pointer */ Array<TSharedPtr<Object>> objects; objects.add(newShared<Object>(...)); ... objects.add(newShared<Object>(...));
/* ( meta-info ) */ Array<Object> objects; objects.emplace(...); ... objects.emplace(...);
. . इसके बारे में आगे।
Unique id
, . (id/identificator), , , -. :
, id. , , , id.
, ( , )
id , , id.
. , id, .
: id, , id, .
id , (Vulkan, OpenGL), (Godot, CryEngine). EntityID CryEngine .
, id : . , ( ), , .
/* */ class ID { uint32 index; uint32 generation; }
/* - / */ class ObjectManager { public: ID create(...); void destroy(ID); void update(ID id, ...); private: Array<uint32> generations; Array<Objects> objects; }
ID , ID . :
generation = generations[id.index]; if (generation == id.generation) then /* */ else /* , */
id generation 1 id ids.
C++ , . std, , . :
- Linked list —
- Array — /
- Queue —
- Stack —
- Map —
- Set —
? memory corruption. / , , , , .
, , . , , / .
, , . , ( ) . , malloc/free , , .
? , (/ ), , , . , , , .
ryEngine Sandbox:
, Unreal, Unity, CryEngine ., , . , , , — , .
Pre-allocating
, / .
: malloc/free . , "run out of memory", . . , (, , .).
. . , - . , malloc/free, : , , .
. : , , , .. .
: , , , . open-source , , . , , — malloc/free.
GDC CD Project Red , , "The Witcher: Blood and Wine" () . , , , , .

Naughty Dog , "Uncharted 4: A Thief's End" , (, ) .

निष्कर्ष
, , , . , . / , , - .. , (, ).