रेडैश ने हाल ही में एक कार्य निष्पादन प्रणाली से दूसरे में बदलना शुरू कर दिया है। अर्थात्, उन्होंने अजवाइन से आरक्यू तक संक्रमण शुरू किया। पहले चरण में, केवल वे कार्य जो सीधे अनुरोध नहीं करते हैं उन्हें नए प्लेटफ़ॉर्म पर स्थानांतरित कर दिया गया था। इन कार्यों में ईमेल भेजना, यह पता लगाना है कि किन अनुरोधों को अद्यतन किया जाना चाहिए, उपयोगकर्ता घटनाओं की रिकॉर्डिंग, और अन्य सहायक कार्य।

यह सब तैनात करने के बाद, यह देखा गया कि आरक्यू कार्यकर्ताओं को सेलरी को हल करने के लिए उपयोग किए जाने वाले कार्यों की समान मात्रा को हल करने के लिए बहुत अधिक कंप्यूटिंग संसाधनों की आवश्यकता होती है।
सामग्री, जिसका अनुवाद आज हम प्रकाशित करते हैं, यह कहानी इस बात के लिए समर्पित है कि कैसे रेडैश ने समस्या के कारण का पता लगाया और उसका मुकाबला किया।
सेलेरी और आरक्यू के बीच अंतर के बारे में कुछ शब्द
अजवाइन और आरक्यू में प्रक्रिया श्रमिकों की अवधारणा है। कांटों के निर्माण का उपयोग करते हुए कार्यों के समानांतर निष्पादन के संगठन के लिए वहां और वहां दोनों। जब सेलेरी कार्यकर्ता शुरू होता है, तो कई कांटा प्रक्रियाएं बनाई जाती हैं, जिनमें से प्रत्येक स्वायत्त रूप से कार्य करता है। आरक्यू के मामले में, कार्यकर्ता के उदाहरण में केवल एक उपप्रकार ("वर्कहॉर्स" के रूप में जाना जाता है) शामिल है, जो एक कार्य करता है, और फिर नष्ट हो जाता है। जब कार्यकर्ता कतार से अगला कार्य डाउनलोड करता है, तो वह एक नया "वर्कहॉर्स" बनाता है।
RQ के साथ काम करते समय, आप समानांतरता के समान स्तर को प्राप्त कर सकते हैं जब सेलेरी के साथ काम कर रहे हैं, बस अधिक कार्यकर्ता प्रक्रियाएं चलाकर। हालांकि, सेलेरी और आरक्यू के बीच एक सूक्ष्म अंतर है। सेलेरी में, एक कार्यकर्ता स्टार्टअप पर उपप्रकारों के कई उदाहरण बनाता है, और फिर कई कार्यों को पूरा करने के लिए उन्हें बार-बार उपयोग करता है। और आरक्यू के मामले में, प्रत्येक काम के लिए आपको एक नया कांटा बनाने की आवश्यकता है। दोनों दृष्टिकोणों में उनके पक्ष और विपक्ष हैं, लेकिन यहां हम इस बारे में बात नहीं करेंगे।
प्रदर्शन माप
इससे पहले कि मैं प्रोफाइलिंग शुरू करूं, मैंने यह पता लगाने के लिए सिस्टम प्रदर्शन को मापने का फैसला किया कि श्रमिक कंटेनर को 1000 नौकरियों की प्रक्रिया में कितने समय की जरूरत है। मैंने
record_event कार्य पर ध्यान केंद्रित करने का निर्णय लिया, क्योंकि यह एक सामान्य हल्का ऑपरेशन है। प्रदर्शन को मापने के लिए, मैंने
time कमांड का उपयोग किया। इसके लिए प्रोजेक्ट कोड में कुछ बदलाव आवश्यक थे:
- 1000 कार्यों के प्रदर्शन को मापने के लिए, मैंने आरक्यू बैच मोड का उपयोग करने का निर्णय लिया, जिसमें, कार्यों को संसाधित करने के बाद, प्रक्रिया से बाहर निकल जाता है।
- मैं अपने माप को अन्य कार्यों के साथ प्रभावित करने से बचना चाहता था जो शायद उस समय के लिए निर्धारित किए गए थे जब मैं सिस्टम प्रदर्शन को माप रहा था। इसलिए मैंने
@job('default') जगह @job('benchmark') जगह benchmark नामक एक अलग कतार में record_event स्थानांतरित record_event दिया। यह tasks/general.py में record_event से ठीक पहले किया गया था।
अब माप शुरू करना संभव था। शुरुआत के लिए, मैं जानना चाहता था कि लोड के बिना किसी कार्यकर्ता को शुरू करने और रोकने में कितना समय लगता है। इस समय को बाद में प्राप्त अंतिम परिणामों से घटाया जा सकता है।
$ docker-compose exec worker bash -c "time ./manage.py rq workers 4 benchmark" real 0m14.728s user 0m6.810s sys 0m2.750s
मेरे कंप्यूटर पर कार्यकर्ता को आरंभ करने में 14.7 सेकंड का समय लगा। मुझे वह याद है।
फिर मैंने
benchmark कतार में 1000
record_event परीक्षण
record_event को रखा:
$ docker-compose run --rm server manage shell <<< "from redash.tasks.general import record_event; [record_event.delay({ 'action': 'create', 'timestamp': 0, 'org_id': 1, 'user_id': 1, 'object_id': 0, 'object_type': 'dummy' }) for i in range(1000)]"
उसके बाद, मैंने सिस्टम को उसी तरह से शुरू किया जैसा मैंने पहले किया था, और पता चला कि 1000 नौकरियों को संसाधित करने में कितना समय लगता है।
$ docker-compose exec worker bash -c "time ./manage.py rq workers 4 benchmark" real 1m57.332s user 1m11.320s sys 0m27.540s
जो हुआ उससे 14.7 सेकंड घटाना, मुझे पता चला कि 4 कार्यकर्ता 102 सेकंड में 1000 कार्यों की प्रक्रिया करते हैं। अब यह जानने की कोशिश करते हैं कि ऐसा क्यों है। ऐसा करने के लिए, हम, जबकि श्रमिक व्यस्त हैं, वे
py-spy का उपयोग करके शोध करेंगे।
रूपरेखा
हम कतार में एक और 1,000 कार्य जोड़ते हैं (यह इस तथ्य के कारण किया जाना चाहिए कि पिछले मापों के दौरान सभी कार्यों को संसाधित किया गया था), श्रमिकों को चलाएं और उन पर जासूसी करें।
$ docker-compose run --rm server manage shell <<< "from redash.tasks.general import record_event; [record_event.delay({ 'action': 'create', 'timestamp': 0, 'org_id': 1, 'user_id': 1, 'object_id': 0, 'object_type': 'dummy' }) for i in range(1000)]" $ docker-compose exec worker bash -c 'nohup ./manage.py rq workers 4 benchmark & sleep 15 && pip install py-spy && rq info -u "redis://redis:6379/0" | grep busy | awk "{print $3}" | grep -o -P "\s\d+" | head -n 1 | xargs py-spy record -d 10 --subprocesses -o profile.svg -p' $ open -a "Google Chrome" profile.svg
मुझे पता है कि पिछली टीम बहुत लंबी थी। आदर्श रूप से, इसकी पठनीयता में सुधार करने के लिए, इसे अलग-अलग टुकड़ों में तोड़ने के लायक होगा, इसे उन जगहों पर विभाजित करना होगा जहां
&& वर्णों के अनुक्रम पाए जाते हैं। लेकिन कमांड को क्रमिक रूप से एक ही
docker-compose exec worker bash सेशन के भीतर निष्पादित किया जाना चाहिए, इसलिए सब कुछ वैसा ही दिखता है। यहाँ इस आदेश का क्या वर्णन है:
- पृष्ठभूमि में 4 बैच के श्रमिकों को लॉन्च करता है।
- यह 15 सेकंड प्रतीक्षा करता है (लगभग इतना ही कि उनके डाउनलोड को पूरा करने के लिए आवश्यक है)।
py-spy स्थापित करता है।rq-info चलाता है और श्रमिकों में से एक के पीआईडी का पता लगाता है।- 10 सेकंड के लिए पहले प्राप्त पीआईडी के साथ कार्यकर्ता के काम के बारे में जानकारी रिकॉर्ड करता है और
profile.svg में डेटा बचाता है। profile.svg फ़ाइल
नतीजतन, निम्नलिखित "उग्र अनुसूची" प्राप्त की गई थी।
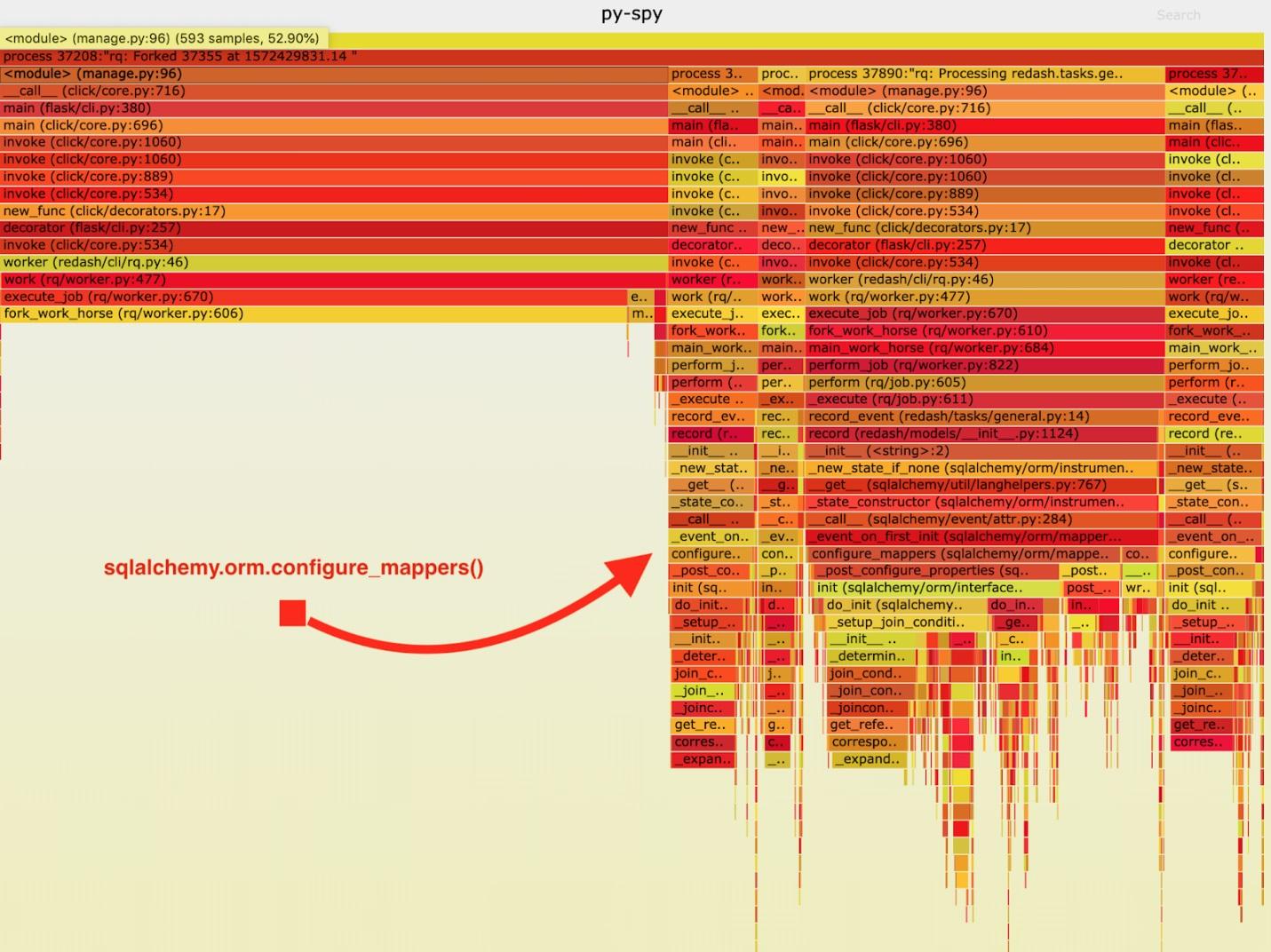 Py-spy द्वारा एकत्र आंकड़ों का विज़ुअलाइज़ेशन
Py-spy द्वारा एकत्र आंकड़ों का विज़ुअलाइज़ेशनइस डेटा का विश्लेषण करने के बाद, मैंने देखा कि
record_event कार्य
sqlalchemy.orm.configure_mappers में इसे चलाने में एक लंबा समय बिताता है। यह प्रत्येक कार्य के दौरान होता है। प्रलेखन से मुझे पता चला कि उस समय जो मुझे रुचता है, पहले से निर्मित सभी मैपर के संबंध आरम्भिक हैं।
इस तरह की चीजें हर कांटे के साथ होना जरूरी नहीं है। हम मूल कार्यकर्ता में एक बार संबंध शुरू कर सकते हैं और "वर्कहॉर्स" में इस कार्य को दोहराने से बच सकते हैं।
परिणामस्वरूप, मैंने "वर्कहॉर्स" शुरू करने से पहले
sqlalchemy.org.configure_mappers() कोड में एक कॉल जोड़ा और फिर से माप लिया।
$ docker-compose run --rm server manage shell <<< "from redash.tasks.general import record_event; [record_event.delay({ 'action': 'create', 'timestamp': 0, 'org_id': 1, 'user_id': 1, 'object_id': 0, 'object_type': 'dummy' }) for i in range(1000)] $ docker-compose exec worker bash -c "time ./manage.py rq workers 4 benchmark" real 0m39.348s user 0m15.190s sys 0m10.330s
यदि आप इन परिणामों में से 14.7 सेकंड घटाते हैं, तो यह पता चलता है कि हमने 102 सेकंड से 24.6 सेकंड तक 1000 कर्मचारियों को संसाधित करने के लिए 4 श्रमिकों के लिए आवश्यक समय में सुधार किया है। यह चार गुना बेहतर प्रदर्शन है! इस फिक्स के लिए धन्यवाद, हम आरक्यू उत्पादन संसाधनों को चौगुनी करने और एक ही सिस्टम बैंडविड्थ को बनाए रखने में सक्षम थे।
परिणाम
इस सब से, मैंने निम्नलिखित निष्कर्ष निकाला: यह याद रखने योग्य है कि यदि यह एकमात्र प्रक्रिया है, और यदि यह कांटे की बात आती है, तो आवेदन अलग तरीके से व्यवहार करता है। यदि प्रत्येक कार्य के दौरान कुछ कठिन आधिकारिक कार्यों को हल करना आवश्यक है, तो उन्हें पहले से हल करना बेहतर होता है, कांटा पूरा होने से पहले एक बार ऐसा करना। परीक्षण और विकास के दौरान ऐसी चीजों का पता नहीं लगाया जाता है, इसलिए, यह महसूस करते हुए कि परियोजना में कुछ गड़बड़ है, इसकी गति को मापें और अपने प्रदर्शन के साथ समस्याओं के कारणों की खोज करते हुए अंत तक पहुंचें।
प्रिय पाठकों! क्या आपने पायथन परियोजनाओं में प्रदर्शन समस्याओं का सामना किया है जिन्हें आप एक कार्य प्रणाली का सावधानीपूर्वक विश्लेषण करके हल कर सकते हैं?
