नमस्ते! आज मैं हबर के पाठकों को बताऊंगा कि कैसे हमने टेक्स्ट रिकग्निशन तकनीक बनाई जो 45 भाषाओं में काम करती है और यैंडेक्स के लिए सुलभ है। उपयोगकर्ताओं के लिए, हम कौन से कार्य निर्धारित करते हैं और उन्हें कैसे हल करते हैं। यह उपयोगी होगा यदि आप इसी तरह की परियोजनाओं पर काम कर रहे हैं या यह पता लगाना चाहते हैं कि यह कैसे हुआ कि आज आपको बस तुर्की स्टोर के साइन की तस्वीर चाहिए ताकि ऐलिस इसे रूसी में अनुवाद कर सके।

ऑप्टिकल कैरेक्टर रिकग्निशन (OCR) तकनीक दुनिया में दशकों से विकसित हो रही है। हम अपनी सेवाओं को बेहतर बनाने और उपयोगकर्ताओं को अधिक विकल्प देने के लिए यैंडेक्स में अपनी खुद की ओसीआर तकनीक विकसित करने लगे। चित्र इंटरनेट का एक बड़ा हिस्सा हैं, और उन्हें समझने की क्षमता के बिना, इंटरनेट पर खोज करना अधूरा होगा।
छवि विश्लेषण समाधान तेजी से लोकप्रिय हो रहे हैं। यह उच्च गुणवत्ता वाले सेंसर के साथ कृत्रिम तंत्रिका नेटवर्क और उपकरणों के प्रसार के कारण है। यह स्पष्ट है कि पहली जगह में हम स्मार्टफ़ोन के बारे में बात कर रहे हैं, लेकिन न केवल उनके बारे में।
पाठ मान्यता के क्षेत्र में कार्यों की जटिलता लगातार बढ़ रही है - यह सब स्कैन किए गए दस्तावेजों की मान्यता के साथ शुरू हुआ। फिर इंटरनेट से टेक्स्ट के साथ बॉर्न-डिजिटल-इमेज
की मान्यता जोड़ी गई। फिर, मोबाइल कैमरों की बढ़ती लोकप्रियता के साथ, अच्छे कैमरा शॉट्स (
फोकस्ड सीन टेक्स्ट ) की मान्यता। और दूर, अधिक जटिल पैरामीटर: पाठ फ़र्ज़ी (
आकस्मिक दृश्य पाठ ) हो सकता है, किसी भी मोड़ के साथ या विभिन्न श्रेणियों में, सर्पिल में
लिखा जा सकता है -
अलमारियों और साइनबोर्डों को संग्रहीत करने के लिए प्राप्तियों की
तस्वीरों से ।
हम किस रास्ते पर गए
पाठ मान्यता कंप्यूटर विज़न कार्यों का एक अलग वर्ग है। कई कंप्यूटर दृष्टि एल्गोरिदम की तरह, तंत्रिका नेटवर्क की लोकप्रियता से पहले, यह काफी हद तक मैनुअल सुविधाओं और हेयुरेटिक्स पर आधारित था। हालांकि, हाल ही में, तंत्रिका नेटवर्क दृष्टिकोण के लिए संक्रमण के साथ, प्रौद्योगिकी की गुणवत्ता में काफी वृद्धि हुई है। फोटो में उदाहरण देखें। यह कैसे हुआ, मैं आगे बताऊंगा।
2018 की शुरुआत में परिणामों के साथ आज के मान्यता परिणामों की तुलना करें:
पहले हमें किन कठिनाइयों का सामना करना पड़ा?
अपनी यात्रा की शुरुआत में, हमने रूसी और अंग्रेजी के लिए मान्यता प्रौद्योगिकी बनाई, और मुख्य उपयोग के मामलों में इंटरनेट से पाठ और चित्रों के पृष्ठ देखे गए। लेकिन काम के दौरान, हमने महसूस किया कि यह पर्याप्त नहीं है: छवियों पर पाठ किसी भी भाषा में, किसी भी सतह पर पाया गया था, और कभी-कभी चित्र बहुत अलग गुणवत्ता के थे। इसका मतलब है कि मान्यता किसी भी स्थिति में और सभी प्रकार के आने वाले डेटा पर काम करना चाहिए।
और यहाँ हम कई कठिनाइयों का सामना कर रहे हैं। यहाँ कुछ ही हैं:
- विवरण। एक ऐसे व्यक्ति के लिए जिसका उपयोग पाठ से जानकारी प्राप्त करने के लिए किया जाता है, छवि में पाठ पैराग्राफ, लाइनें, शब्द और अक्षर हैं, लेकिन एक तंत्रिका नेटवर्क के लिए सब कुछ अलग दिखता है। पाठ की जटिल प्रकृति के कारण, नेटवर्क को दोनों को एक पूरे के रूप में देखने के लिए मजबूर किया जाता है (उदाहरण के लिए, यदि लोग हाथ मिलाते हैं और एक शिलालेख का निर्माण करते हैं), और सबसे छोटे विवरण (वियतनामी भाषा में, समान प्रतीकों of और words शब्दों के अर्थ बदल जाते हैं)। अलग-अलग चुनौतियां मनमाना पाठ और गैर-मानक फोंट को पहचान रही हैं।
- बहुभाषावाद । हमने जितनी अधिक भाषाओं को जोड़ा, उतना ही हमें उनकी बारीकियों का सामना करना पड़ा: सिरिलिक और लैटिन शब्दों में अलग-अलग अक्षरों से बना है, अरबी में वे एक साथ लिखे गए हैं, जापानी में कोई अलग शब्द प्रतिष्ठित नहीं हैं। कुछ भाषाएं बाएं से दाएं वर्तनी का उपयोग करती हैं, कुछ दाएं से बाएं। कुछ शब्द क्षैतिज रूप से लिखे जाते हैं, कुछ लंबवत। एक सार्वभौमिक उपकरण को इन सभी विशेषताओं को ध्यान में रखना चाहिए।
- पाठ की संरचना । विशिष्ट छवियों, जैसे चेक या जटिल दस्तावेजों को पहचानने के लिए, एक संरचना जो पैराग्राफ, तालिकाओं और अन्य तत्वों के लेआउट को ध्यान में रखती है, महत्वपूर्ण है।
- प्रदर्शन । तकनीक का उपयोग ऑफ़लाइन सहित विभिन्न प्रकार के उपकरणों पर किया जाता है, इसलिए हमें कठोर प्रदर्शन आवश्यकताओं को ध्यान में रखना चाहिए।
डिटेक्शन मॉडल का चयन
पाठ को पहचानने का पहला चरण अपनी स्थिति (पहचान) निर्धारित करना है।
टेक्स्ट डिटेक्शन को ऑब्जेक्ट रिकग्निशन टास्क माना जा सकता है, जहाँ व्यक्तिगत
अक्षर ,
शब्द या
लाइन ऑब्जेक्ट के रूप में कार्य कर सकते हैं।
यह हमारे लिए महत्वपूर्ण था कि मॉडल बाद में अन्य भाषाओं (अब हम 45 भाषाओं का समर्थन करते हैं) को बढ़ाया गया।
पाठ का पता लगाने पर कई शोध लेख उन मॉडलों का उपयोग करते हैं जो व्यक्तिगत
शब्दों की स्थिति का अनुमान लगाते हैं। लेकिन एक
सार्वभौमिक मॉडल के मामले में
, इस दृष्टिकोण की कई सीमाएं हैं - उदाहरण के लिए, चीनी भाषा के लिए एक शब्द की अवधारणा, मूल रूप से एक शब्द की अवधारणा से अलग है, उदाहरण के लिए, अंग्रेजी में। चीनी भाषा में अलग-अलग शब्द एक स्थान से अलग नहीं होते हैं। थाई में, केवल एक वाक्य को एक स्थान के साथ छोड़ दिया जाता है।
रूसी, चीनी और थाई में एक ही पाठ के उदाहरण इस प्रकार हैं:
. .
今天天气很好 这是一个美丽的一天散步。
สภาพอากาศสมบูรณ์แบบในวันนี้ มันเป็นวันที่สวยงามสำหรับเดินเล่นกันหน่อยแล้วबदले में,
लाइनें पहलू अनुपात के मामले में बहुत परिवर्तनशील हैं। इस वजह से, लाइन पूर्वानुमान के लिए इस तरह के सामान्य पहचान मॉडल (उदाहरण के लिए, एसएसडी या आरसीएनएन-आधारित) की संभावनाएं सीमित हैं, क्योंकि ये मॉडल कई पूर्वनिर्धारित पहलू अनुपात वाले उम्मीदवार क्षेत्रों / लंगर बक्से पर आधारित हैं। इसके अलावा, लाइनों में एक मनमाना आकार हो सकता है, उदाहरण के लिए, घुमावदार, इसलिए लाइनों के गुणात्मक विवरण के लिए यह विशेष रूप से चतुर्भुज का वर्णन करने के लिए पर्याप्त नहीं है, यहां तक कि एक रोटेशन कोण के साथ भी।
इस तथ्य के बावजूद कि व्यक्तिगत
पात्रों की स्थितियां स्थानीय और वर्णित हैं, उनका दोष यह है कि एक अलग पोस्ट-प्रोसेसिंग कदम की आवश्यकता है - आपको शब्दों और लाइनों में वर्णों को चमकाने के लिए उत्तराधिकार का चयन करने की आवश्यकता है।
इसलिए, हमने
SegLink मॉडल को
पहचानने के लिए आधार के रूप में लिया, जिसका मुख्य विचार लाइनों / शब्दों को दो और स्थानीय संस्थाओं: खंडों और उनके बीच संबंधों को विघटित करना है।
डिटेक्टर वास्तुकला
मॉडल की वास्तुकला एसएसडी पर आधारित है, जो सुविधाओं के कई पैमानों पर वस्तुओं की स्थिति की भविष्यवाणी करती है। केवल व्यक्तिगत "खंडों" के निर्देशांक की भविष्यवाणी करने के अलावा, आसन्न खंडों के बीच "कनेक्शन" की भी भविष्यवाणी की जाती है, अर्थात दो खंड एक ही पंक्ति के हैं। "कनेक्शंस" की भविष्यवाणी दोनों पड़ोसी क्षेत्रों में संकेतों के समान पैमाने पर की जाती है, और पड़ोसी पैमानों पर आस-पास के क्षेत्रों में स्थित क्षेत्रों के लिए (संकेतों के विभिन्न पैमानों वाले सेगमेंट आकार में थोड़ा भिन्न हो सकते हैं और एक ही लाइन से संबंधित होते हैं)।
प्रत्येक स्केल के लिए, प्रत्येक फीचर सेल संबंधित "खंड" से जुड़ा होता है। प्रत्येक खंड के लिए
(x, y, l) बिंदु पर (x, y) स्केल l पर, निम्नलिखित को प्रशिक्षित किया गया है:
- पी
एस क्या दिए गए खंड पाठ है;
- x
s , y
s , w
s , h
s , -
s - बेस निर्देशांक की ऑफसेट और खंड के झुकाव का कोण;
- {s
(x ', y', l) } / s
(x, y, l) , जहां x से l- वें पैमाने (L
w s, s ' , s से संबंधित खंडों के साथ "कनेक्शन" की उपस्थिति के लिए 8 स्कोर -1 - x '' x + 1, y - 1 ≤ y '1 y + 1);
- एल -1 स्केल (L
c s, s ' , s' से {s
(x ', y', l-1) } से सटे हुए खंडों के साथ "कनेक्शन" की उपस्थिति के लिए 4 अंक, जहां 2x 'x' + 2x1 1 , 2y 2 y 'y 2y + 1) (जो इस तथ्य के कारण सच है कि पड़ोसी तराजू पर सुविधाओं का आयाम 2 बार भिन्न होता है)।
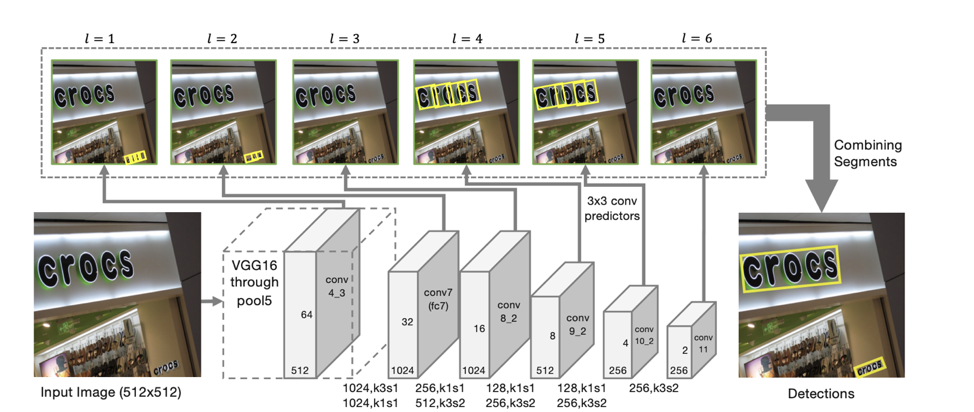
इस तरह की भविष्यवाणियों के अनुसार, यदि हम सभी खंडों के रूप में लेते हैं, जिसके लिए वे पाठ की संभावना थ्रेशोल्ड α से अधिक है, और किनारों के रूप में सभी बांड जिनकी संभावना थ्रेशोल्ड से अधिक है,, तो सेगमेंट जुड़े घटकों का निर्माण करते हैं, जिनमें से प्रत्येक पाठ की एक पंक्ति का वर्णन करता है। ।
परिणामी मॉडल में एक
उच्च सामान्यीकरण क्षमता है : यहां तक कि रूसी और अंग्रेजी डेटा पर पहले दृष्टिकोणों में प्रशिक्षित किया गया है, यह गुणात्मक रूप से चीनी और अरबी पाठ पाया गया है।
दस लिपियाँ
यदि पता लगाने के लिए हम एक ऐसा मॉडल बनाने में सक्षम थे जो सभी भाषाओं के लिए तुरंत काम करता है, तो पाया गया लाइनों की मान्यता के लिए ऐसा मॉडल प्राप्त करना अधिक कठिन है। इसलिए, हमने
प्रत्येक स्क्रिप्ट (सिरिलिक, लैटिन, अरबी, हिब्रू, ग्रीक, आर्मीनियाई, जॉर्जियाई, कोरियाई, थाई) के
लिए एक
अलग मॉडल का उपयोग करने का निर्णय लिया। चित्रलिपि में बड़े चौराहे के कारण चीनी और जापानी के लिए एक अलग सामान्य मॉडल का उपयोग किया जाता है।
संपूर्ण स्क्रिप्ट के लिए सामान्य मॉडल प्रत्येक भाषा के लिए अलग-अलग मॉडल से 1 p.p. से कम दूरी पर भिन्न होता है। गुणवत्ता। इसी समय, एक मॉडल का निर्माण और कार्यान्वयन की तुलना में सरल है, उदाहरण के लिए, 25 मॉडल (लैटिन मॉडल द्वारा समर्थित लैटिन भाषाओं की संख्या)। लेकिन सभी भाषाओं में अंग्रेजी की लगातार उपस्थिति के कारण, हमारे सभी मॉडल मुख्य स्क्रिप्ट, लैटिन वर्णों के अलावा, भविष्यवाणी करने में सक्षम हैं।
यह समझने के लिए कि मान्यता के लिए किस मॉडल का उपयोग किया जाना चाहिए, हम पहले यह निर्धारित करते हैं कि प्राप्त लाइनें मान्यता के लिए उपलब्ध 10 लिपियों में से एक से संबंधित हैं या नहीं।
यह अलग से ध्यान दिया जाना चाहिए कि लाइन के साथ इसकी स्क्रिप्ट को विशिष्ट रूप से निर्धारित करना हमेशा संभव नहीं होता है। उदाहरण के लिए, संख्याएँ या एकल लैटिन वर्ण कई लिपियों में समाहित हैं, इसलिए मॉडल के आउटपुट वर्गों में से एक "अपरिभाषित" स्क्रिप्ट है।
स्क्रिप्ट की परिभाषा
स्क्रिप्ट को परिभाषित करने के लिए हमने एक अलग क्लासिफायर बनाया। एक स्क्रिप्ट को परिभाषित करने का कार्य मान्यता के कार्य की तुलना में बहुत सरल है, और तंत्रिका नेटवर्क को सिंथेटिक डेटा पर आसानी से पुनर्प्राप्त किया जाता है। इसलिए, हमारे प्रयोगों में,
स्ट्रिंग मान्यता समस्या पर पूर्व-प्रशिक्षण द्वारा मॉडल की गुणवत्ता में एक महत्वपूर्ण सुधार दिया गया था। ऐसा करने के लिए, हमने पहले सभी उपलब्ध भाषाओं के लिए मान्यता समस्या के लिए नेटवर्क को प्रशिक्षित किया। उसके बाद, परिणामस्वरूप रीढ़ की हड्डी का उपयोग मॉडल को स्क्रिप्ट वर्गीकरण कार्य के लिए आरंभ करने के लिए किया गया था।
जबकि एक व्यक्तिगत लाइन पर एक स्क्रिप्ट अक्सर काफी शोर होता है, एक पूरे के रूप में चित्र में अक्सर एक भाषा में पाठ होता है, या तो अंग्रेजी के साथ मुख्य इंटरसेप्टर के अलावा (या हमारे रूसी उपयोगकर्ताओं के मामले में)। इसलिए, स्थिरता
बढ़ाने के लिए, हम छवि से अधिक स्थिर पूर्वानुमान प्राप्त करने के लिए छवि से लाइनों की भविष्यवाणियों को एकत्र करते हैं। एकत्रीकरण में "अनिश्चित" के पूर्वानुमानित वर्ग वाली रेखाओं पर ध्यान नहीं दिया जाता है।
रेखा की मान्यता
अगला चरण, जब हमने पहले से ही प्रत्येक पंक्ति और उसकी स्क्रिप्ट की स्थिति निर्धारित की है, तो हमें
वर्णों के अनुक्रम की भविष्यवाणी करने के लिए पिक्सेल के अनुक्रम से
दिए गए स्क्रिप्ट से वर्णों के अनुक्रम को
पहचानने की आवश्यकता है। कई प्रयोगों के बाद, हम निम्नलिखित क्रम 2 ध्यान पर आधारित मॉडल पर आए:

एनकोडर में CNN + BiLSTM का उपयोग करने से आप ऐसे संकेत प्राप्त कर सकते हैं जो स्थानीय और वैश्विक दोनों संदर्भों को कैप्चर करते हैं। पाठ के लिए, यह महत्वपूर्ण है - अक्सर इसे एक फ़ॉन्ट में लिखा जाता है (फ़ॉन्ट जानकारी के साथ समान अक्षरों को भेद करना बहुत आसान है)। और लगातार अंतरिक्ष से लिखे गए दो अक्षरों को अलग करने के लिए, लाइन के लिए वैश्विक आंकड़ों की भी आवश्यकता होती है।
एक दिलचस्प अवलोकन : परिणामस्वरूप मॉडल में, एक विशेष प्रतीक के लिए ध्यान मुखौटा के आउटपुट का उपयोग छवि में इसकी स्थिति का अनुमान लगाने के लिए किया जा सकता है।
इसने हमें
मॉडल के ध्यान को
स्पष्ट रूप से "फोकस" करने की कोशिश करने के लिए प्रेरित
किया । इस तरह के विचारों को लेखों में भी पाया गया था - उदाहरण के लिए, लेख में
ध्यान केंद्रित करना: प्राकृतिक छवियों में सटीक पाठ मान्यता की ओर ।
चूंकि ध्यान तंत्र सुविधा स्थान पर एक संभाव्यता वितरण देता है, यदि हम अतिरिक्त नुकसान के रूप में इस कदम पर भविष्यवाणी की गई पत्र के अनुरूप मास्क के अंदर आउटपुट का योग लेते हैं, तो हमें उस "ध्यान" का हिस्सा मिलता है जो सीधे उस पर केंद्रित होता है।
हानि
-लॉग (
, i, j tM t α
i, j ) शुरू करने से, जहां M
t छठे अक्षर का मुखौटा है, α ध्यान का आउटपुट है, हम दिए गए प्रतीक पर ध्यान केंद्रित करने के लिए "ध्यान" को प्रोत्साहित करेंगे और इस प्रकार मदद करेंगे तंत्रिका नेटवर्क बेहतर सीखते हैं।
उन प्रशिक्षण उदाहरणों के लिए जिनके लिए व्यक्तिगत वर्णों का स्थान अज्ञात है या गलत है (सभी प्रशिक्षण डेटा में व्यक्तिगत वर्णों के स्तर पर अंकन है, शब्द नहीं), इस शब्द को अंतिम नुकसान में ध्यान में नहीं रखा गया था।
एक और अच्छी विशेषता: यह वास्तुकला आपको अतिरिक्त परिवर्तनों के बिना
दाएं-से-बाएं लाइनों की
मान्यता की भविष्यवाणी करने की अनुमति देता है (जो कि महत्वपूर्ण है, उदाहरण के लिए, अरबी, हिब्रू जैसी भाषाओं के लिए)। मॉडल खुद ही दाएं से बाएं पहचान को जारी करना शुरू कर देता है।
तेज और धीमी मॉडल
इस प्रक्रिया में, हमें एक समस्या का सामना करना पड़ा:
"लम्बे" फोंट के लिए , अर्थात, फोंट लम्बवत, मॉडल खराब तरीके से काम करता है। यह इस तथ्य के कारण था कि ध्यान के स्तर पर संकेतों का आयाम मूल छवि के आयाम की तुलना में 8 गुना छोटा है, जो नेटवर्क के दृढ़ भाग के आर्किटेक्चर में स्ट्राइड्स और पुलिंग के कारण होता है। और स्रोत छवि में कई पड़ोसी पात्रों के स्थान समान फीचर वेक्टर के स्थान के अनुरूप हो सकते हैं, जिससे ऐसे उदाहरणों में त्रुटियां हो सकती हैं। सुविधाओं के आयाम के एक छोटे से संकीर्णता के साथ वास्तुकला के उपयोग से गुणवत्ता में वृद्धि हुई, लेकिन प्रसंस्करण समय में वृद्धि भी हुई।
इस समस्या को हल करने और
प्रसंस्करण समय बढ़ाने से बचने के लिए , हमने मॉडल के लिए निम्नलिखित परिशोधन किए:
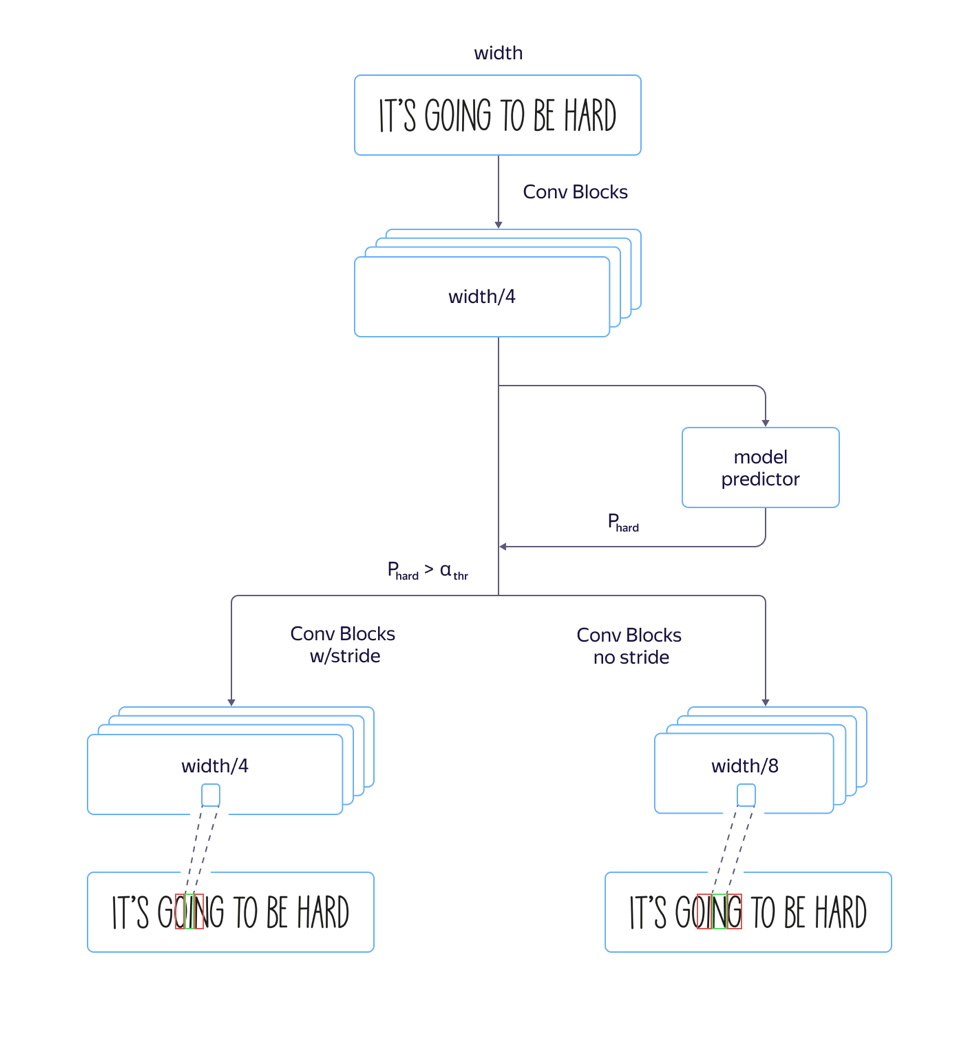
हमने बहुत तेज स्ट्राइड के साथ एक फास्ट मॉडल और कम के साथ धीमी गति से दोनों को प्रशिक्षित किया। उस परत पर जहां मॉडल के पैरामीटर अलग-अलग होने लगे, हमने एक अलग नेटवर्क आउटपुट जोड़ा, जिसने भविष्यवाणी की कि किस मॉडल में कम मान्यता त्रुटि होगी। मॉडल का कुल नुकसान एल
छोटा + एल
बड़ा + एल
गुणवत्ता से बना था । इस प्रकार, मध्यवर्ती परत पर, मॉडल ने इस उदाहरण की "जटिलता" निर्धारित करना सीखा। इसके अलावा, आवेदन के चरण में, सामान्य भाग और उदाहरण की "जटिलता" की भविष्यवाणी को सभी लाइनों के लिए माना जाता था, और इसके आउटपुट के आधार पर, भविष्य में थ्रेशोल्ड मान के अनुसार या तो एक तेज़ या धीमी मॉडल का उपयोग किया गया था। इसने हमें एक ऐसी गुणवत्ता प्राप्त करने की अनुमति दी, जो एक लंबे मॉडल की गुणवत्ता से लगभग अलग नहीं है, जबकि गति अनुमानित 30% के बजाय केवल 5% बढ़ी है।
प्रशिक्षण डेटा
उच्च-गुणवत्ता वाला मॉडल बनाने में एक महत्वपूर्ण चरण एक बड़े और विविध प्रशिक्षण नमूने की तैयारी है। पाठ की "सिंथेटिक" प्रकृति से बड़ी मात्रा में उदाहरण उत्पन्न करना और वास्तविक डेटा पर अच्छे परिणाम प्राप्त करना संभव हो जाता है।
सिंथेटिक डेटा की पीढ़ी के लिए पहले दृष्टिकोण के बाद, हमने ध्यान से प्राप्त मॉडल के परिणामों को देखा और पाया कि प्रशिक्षण सेट बनाने के लिए उपयोग किए जाने वाले ग्रंथों में पूर्वाग्रह के कारण मॉडल एकल अक्षरों 'आई' को अच्छी तरह से नहीं पहचानता है। इसलिए, हमने स्पष्ट रूप
से "समस्याग्रस्त" उदाहरणों का एक
सेट उत्पन्न किया, और जब हमने इसे मॉडल के प्रारंभिक डेटा में जोड़ा, तो गुणवत्ता में काफी वृद्धि हुई। हमने इस प्रक्रिया को कई बार दोहराया, अधिक से अधिक जटिल स्लाइस को जोड़ा, जिस पर हम मान्यता की गुणवत्ता में सुधार करना चाहते थे।
महत्वपूर्ण बिंदु यह है कि उत्पन्न
डेटा विविध और वास्तविक लोगों के समान होना चाहिए । और अगर आप चाहते हैं कि मॉडल कागज की चादरों पर पाठ की तस्वीरों पर काम करे, और पूरे सिंथेटिक डेटासेट में भूदृश्य के ऊपर लिखा गया पाठ हो, तो यह काम नहीं कर सकता है।
एक और महत्वपूर्ण कदम उन उदाहरणों के प्रशिक्षण के लिए उपयोग करना है जिन पर वर्तमान मान्यता गलत है। यदि बड़ी संख्या में ऐसे चित्र हैं जिनके लिए कोई मार्कअप नहीं है, तो आप वर्तमान मान्यता प्रणाली के उन आउटपुट को ले सकते हैं जिसमें वह सुनिश्चित नहीं है, और केवल उन्हें चिह्नित करें, जिससे मार्कअप की लागत कम हो जाएगी।
जटिल उदाहरणों के लिए, हमने Yandex.Tolok के उपयोगकर्ताओं से फ़ोटो के शुल्क के लिए सेवा मांगी और हमें
एक निश्चित "जटिल" समूह के चित्र भेजे - उदाहरण के लिए, सामानों के पैकेज की तस्वीरें:


"जटिल" डेटा पर काम की गुणवत्ता
हम अपने उपयोगकर्ताओं को किसी भी जटिलता की तस्वीरों के साथ काम करने का अवसर देना चाहते हैं, क्योंकि यह न केवल पुस्तक पृष्ठ या स्कैन किए गए दस्तावेज़ पर पाठ को पहचानने या अनुवाद करने के लिए आवश्यक हो सकता है, बल्कि सड़क पर हस्ताक्षर, घोषणा या उत्पाद पैकेजिंग पर भी हो सकता है। इसलिए, पुस्तकों और दस्तावेजों के प्रवाह पर काम की उच्च गुणवत्ता बनाए रखते हुए (हम इस विषय पर एक अलग कहानी समर्पित करेंगे), हम "छवियों के जटिल सेट" पर विशेष ध्यान देते हैं।
ऊपर वर्णित तरीके से, हमने जंगली में पाठ युक्त चित्रों का एक सेट संकलित किया है, जो हमारे उपयोगकर्ताओं के लिए उपयोगी हो सकता है: साइनबोर्ड, घोषणाओं, प्लेटों, बुक कवर, घरेलू उपकरणों, कपड़े और वस्तुओं पर ग्रंथों की तस्वीरें। इस डेटा सेट पर (जिसका लिंक नीचे है), हमने अपने एल्गोरिथ्म की गुणवत्ता का मूल्यांकन किया।
तुलना के लिए एक मीट्रिक के रूप में, हमने डेटासेट में सटीकता और शब्द पहचान की पूर्णता के मानक मीट्रिक का उपयोग किया, साथ ही साथ एफ-माप भी। एक मान्यता प्राप्त शब्द को सही ढंग से पाया जाता है, यदि इसके निर्देशांक चिह्नित-अप शब्द (IoU> 0.3) के निर्देशांक के अनुरूप हैं और मान्यता बिल्कुल मामले के रूप में चिह्नित है। परिणामी डेटासेट पर आंकड़े:
परिणाम पुन: प्रस्तुत करने के लिए डेटासेट, मैट्रिक्स और स्क्रिप्ट
यहां उपलब्ध
हैं ।
Upd। दोस्तों, एब्बी के समान समाधान के साथ हमारी तकनीक की तुलना करने से बहुत विवाद हुआ। हम समुदाय और उद्योग के साथियों की राय का सम्मान करते हैं। लेकिन एक ही समय में हम अपने परिणामों में आश्वस्त हैं, इसलिए हमने इस तरह से फैसला किया: हम अन्य उत्पादों के परिणामों को तुलना से हटा देंगे, उनके साथ परीक्षण पद्धति पर फिर से चर्चा करेंगे और उन परिणामों पर वापस लौटेंगे जिनमें हम एक सामान्य समझौते पर आते हैं।
अगले चरण
अलग-अलग चरणों के जंक्शन पर, जैसे कि पहचान और मान्यता, समस्याएं हमेशा उत्पन्न होती हैं: पहचान मॉडल में थोड़े से बदलाव मान्यता मॉडल को बदलने की आवश्यकता को पूरा करते हैं, इसलिए हम एंड-टू-एंड समाधान बनाने के लिए सक्रिय रूप से प्रयोग कर रहे हैं।
तकनीक में सुधार करने के लिए पहले से ही वर्णित तरीकों के अलावा, हम दस्तावेज़ की संरचना का विश्लेषण करने के लिए एक दिशा विकसित करेंगे, जो जानकारी निकालने के दौरान मौलिक रूप से महत्वपूर्ण है और उपयोगकर्ताओं के बीच मांग में है।
निष्कर्ष
उपयोगकर्ता पहले से ही सुविधाजनक तकनीकों के आदी हैं और बिना किसी हिचकिचाहट के कैमरे को चालू करते हैं, स्टोर के संकेत, रेस्तरां में मेनू या विदेशी भाषा में पुस्तक में पृष्ठ और जल्दी से एक अनुवाद प्राप्त करते हैं। हम सिद्ध सटीकता के साथ 45 भाषाओं में पाठ पहचानते हैं, और अवसरों का केवल विस्तार होगा। Yandex.Cloud के अंदर औजारों का एक सेट जो भी लंबे समय से Yandex खुद के लिए कर रहा है सबसे अच्छा अभ्यासों का उपयोग करना चाहता है।
आज आप केवल तैयार तकनीक ले सकते हैं, इसे अपने स्वयं के अनुप्रयोग में एकीकृत कर सकते हैं और नए उत्पादों को बनाने और अपनी प्रक्रियाओं को स्वचालित करने के लिए इसका उपयोग कर सकते हैं। हमारे ओसीआर के लिए प्रलेखन
यहां उपलब्ध
है ।
क्या पढ़ें:
- डी। करेजा, एसआर मेस्ट्रे, जे। मास, एफ। नूरबख्श, और पीपी रॉय, "आईसीडीएआर 2011 की मजबूत पठन प्रतियोगिता-चुनौती 1: डॉक्यूमेंट एनालिसिस एंड रिकिशन (आईसीडीएआर) में जन्मे-डिजिटल इमेज (वेब और ईमेल) में टेक्स्ट पढ़ना। ), 2011 अंतर्राष्ट्रीय सम्मेलन। IEEE, 2011, पीपी। 1485-1490।
- कारजेटास डी। एट अल। आईसीडीएआर 2015 मजबूत रीडिंग पर 2015 प्रतियोगिता। दस्तावेज़ विश्लेषण और मान्यता (आईसीडीएआर) पर 13 वें अंतर्राष्ट्रीय सम्मेलन। - IEEE, 2015 ।-- एस। 1156-1160।
- ची-खेंग चंग एट। अल। ICDAR2019 रॉबस्ट रीडिंग चैलेंज ऑन आर्बिटवर्स-शेप्ड टेक्स्ट (RRC-ArT) [ arxiv: 1909.07145v1 ]
- ICDAR 2019 स्कैन पठन रसीद OCR और सूचना निष्कर्षण पर चुनौती rrc.cvc.uab.es/?f=13
- ShopSign: सड़क दृश्य में चीनी दुकान के संकेत के एक विविध दृश्य पाठ डेटासेट [ arxiv: 190380480 ]
- बाओगुआंग शि, जियांग बाई, सर्ज बेलॉन्गी डिटेक्टिंग ओरिएंटेड टेक्स्ट इन नैचुरल इमेजेज इन लिंकिंग सेगमेंट [ arxiv: 1703.06520 ]।
- झांझन चेंग, फैन बाई, यूंगलू जू, गैंग झेंग, शिलियांग पु, शुइगेंग झोउ फोकसिंग ध्यान: प्राकृतिक छवियों में सटीक पाठ की पहचान [ arxiv: 1709.02054 ]।