नमस्ते!
क्या आप अक्सर सोशल नेटवर्क पर विषाक्त टिप्पणियां देखते हैं? यह संभवतः उस सामग्री पर निर्भर करता है जिसे आप देख रहे हैं। मैं इस विषय पर थोड़ा प्रयोग करने का प्रस्ताव करता हूं और तंत्रिका नेटवर्क को नफरत की टिप्पणियों को निर्धारित करने के लिए सिखाता हूं।
इसलिए, हमारा वैश्विक लक्ष्य यह निर्धारित करना है कि क्या कोई टिप्पणी आक्रामक है, अर्थात हम द्विआधारी वर्गीकरण से निपट रहे हैं। हम एक सरल तंत्रिका नेटवर्क लिखेंगे, इसे विभिन्न सामाजिक नेटवर्क से टिप्पणियों के डेटासेट पर प्रशिक्षित करेंगे, और फिर हम विज़ुअलाइज़ेशन के साथ एक सरल विश्लेषण करेंगे।
काम के लिए मैं Google Colab का उपयोग करूंगा। यह सेवा आपको ज्यूपिटर नोटबुक चलाने की अनुमति देती है, और मुफ्त में GPU (NVidia Tesla K80) तक पहुंच सकती है, जिससे सीखने की गति बढ़ेगी। मैं TendorFlow बैकएंड की आवश्यकता होगी, कोलाब में डिफ़ॉल्ट संस्करण 1.15.0, इसलिए सिर्फ 2.0.0 में अपग्रेड करें।
हम मॉड्यूल और अपडेट आयात करते हैं।
from __future__ import absolute_import, division, print_function, unicode_literals import tensorflow as tf !tf_upgrade_v2 -h
आप वर्तमान संस्करण को इस तरह देख सकते हैं।
print(tf.__version__)
प्रारंभिक कार्य किया जाता है, हम सभी आवश्यक मॉड्यूल आयात करते हैं।
import os import numpy as np
प्रयुक्त पुस्तकालयों का विवरण
- ओएस - फाइल सिस्टम के साथ काम करने के लिए
- सुन्न - सरणियों के साथ काम करने के लिए
- पांडा - सारणीबद्ध डेटा के विश्लेषण के लिए एक पुस्तकालय
- केरस - एक मॉडल बनाने के लिए
- keras.preprocessing.Text - पाठ प्रसंस्करण के लिए, एक तंत्रिका नेटवर्क के प्रशिक्षण के लिए संख्यात्मक रूप में प्रस्तुत करने के लिए
- sklearn.train_test_split - प्रशिक्षण से परीक्षण डेटा को अलग करने के लिए
- matplotlib - सीखने की प्रक्रिया की कल्पना करने के लिए
- sklearn.normalize - परीक्षण और प्रशिक्षण डेटा को सामान्य करने के लिए
कागल के साथ डेटा पार्स करना
मैं सीधे कोलाब लैपटॉप में ही डेटा लोड करता हूं। इसके अलावा, किसी भी समस्या के बिना, मैं पहले से ही उन्हें निकाल रहा हूं।
path = 'labeled.csv' df = pd.read_csv(path) df.head()
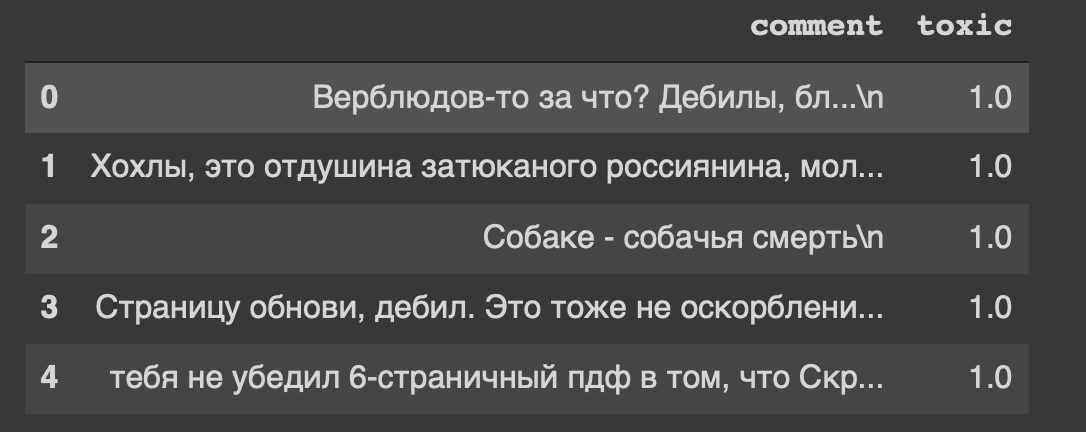
और यह हमारे डेटासेट की हेडिंग है ... मैं भी किसी तरह "रिफ्रेश पेज, मोरन" से असहज महसूस करता हूं।
इसलिए, हमारा डेटा तालिका में है, हम इसे दो भागों में विभाजित करेंगे: प्रशिक्षण के लिए डेटा और परीक्षण मॉडल के लिए। लेकिन यह सब पाठ है, कुछ करने की जरूरत है।
डाटा प्रोसेसिंग
टेक्स्ट से न्यूलाइन वर्ण निकालें।
def delete_new_line_symbols(text): text = text.replace('\n', ' ') return text
df['comment'] = df['comment'].apply(delete_new_line_symbols) df.head()
टिप्पणियों में एक वास्तविक डेटा प्रकार होता है, हमें उन्हें पूर्णांक में अनुवाद करने की आवश्यकता होती है। अगला, इसे एक अलग चर में सहेजें।
target = np.array(df['toxic'].astype('uint8')) target[:5]
अब हम टोकनर क्लास का उपयोग करके टेक्स्ट को थोड़ा प्रोसेस करेंगे। इसकी एक प्रति लिखते हैं।
tokenizer = Tokenizer(num_words=30000, filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n', lower=True, split=' ', char_level=False)
जल्दी मापदंडों के बारे में- num_words - निश्चित शब्दों की संख्या (सबसे सामान्य)
- फ़िल्टर - हटाए जाने वाले वर्णों का एक क्रम
- निचला - एक बूलियन पैरामीटर जो नियंत्रित करता है कि क्या पाठ लोअरकेस होगा
- स्प्लिट - स्प्लिट ऑफर का मुख्य प्रतीक
- char_level - इंगित करता है कि क्या किसी एकल वर्ण को एक शब्द माना जाएगा
और अब हम कक्षा का उपयोग करके पाठ को संसाधित करेंगे।
tokenizer.fit_on_texts(df['comment']) matrix = tokenizer.texts_to_matrix(df['comment'], mode='count') matrix.shape
हमें 14k नमूना पंक्तियाँ और 30k फ़ीचर कॉलम मिले।

मैं दो परतों से एक मॉडल का निर्माण कर रहा हूं: घने और ड्रॉपआउट।
def get_model(): model = Sequential() model.add(Dense(32, activation='relu')) model.add(Dropout(0.3)) model.add(Dense(16, activation='relu')) model.add(Dropout(0.3)) model.add(Dense(16, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(optimizer=RMSprop(lr=0.0001), loss='binary_crossentropy', metrics=['accuracy']) return model
हम मैट्रिक्स को सामान्य करते हैं और डेटा को दो भागों में विभाजित करते हैं, जैसा कि सहमति (प्रशिक्षण और परीक्षण)।
X = normalize(matrix) y = target X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) X_train.shape, y_train.shape
मॉडल प्रशिक्षण
model = get_model() history = model.fit(X_train, y_train, epochs=150, batch_size=500, validation_data=(X_test, y_test)) history
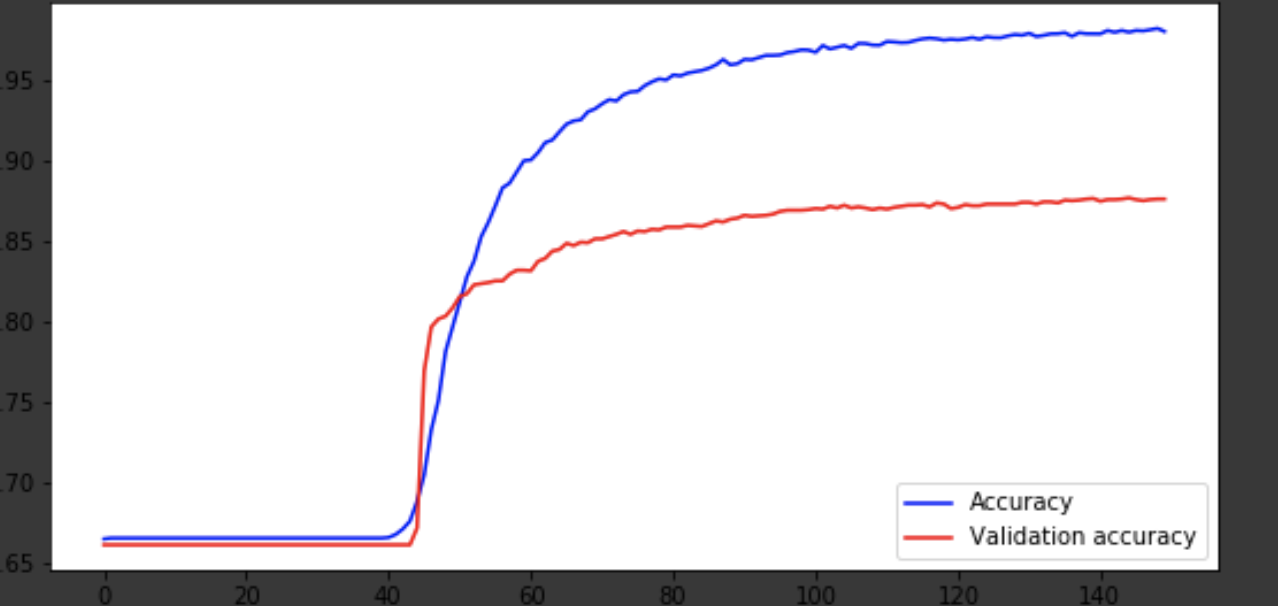
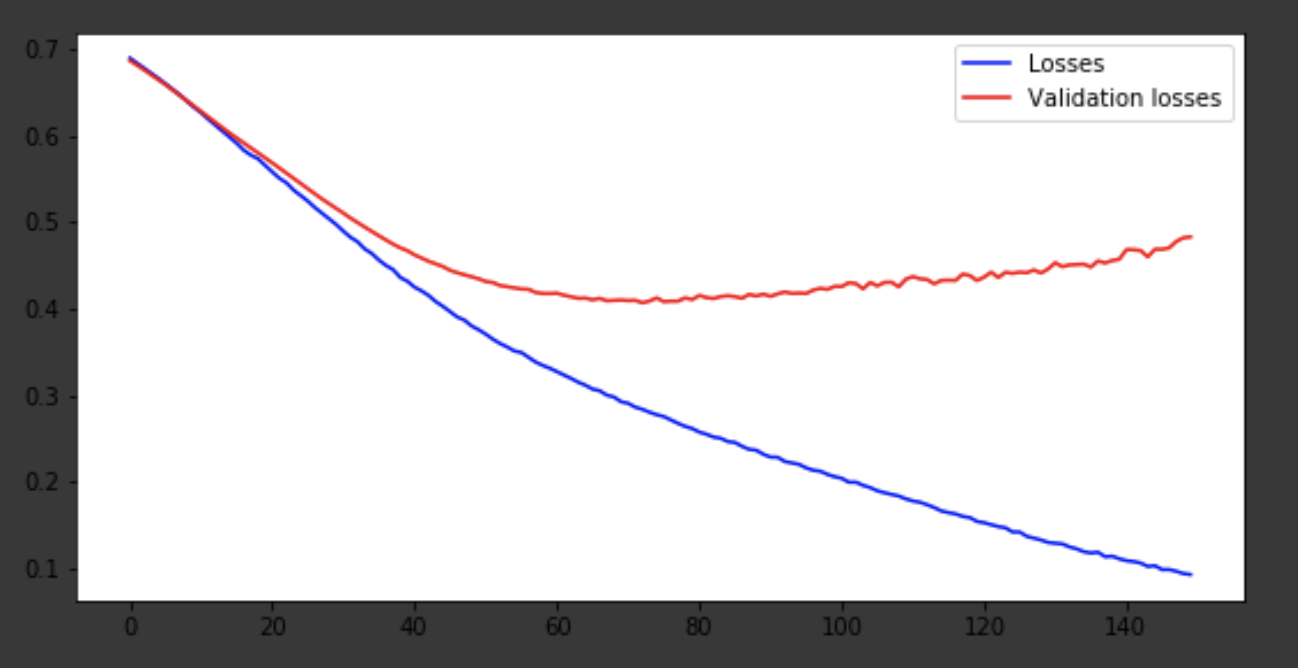
मैं अंतिम पुनरावृत्तियों में सीखने की प्रक्रिया दिखाऊंगा।

सीखने की प्रक्रिया का दृश्य
history = history.history fig = plt.figure(figsize=(20, 10)) ax1 = fig.add_subplot(221) ax2 = fig.add_subplot(223) x = range(150) ax1.plot(x, history['acc'], 'b-', label='Accuracy') ax1.plot(x, history['val_acc'], 'r-', label='Validation accuracy') ax1.legend(loc='lower right') ax2.plot(x, history['loss'], 'b-', label='Losses') ax2.plot(x, history['val_loss'], 'r-', label='Validation losses') ax2.legend(loc='upper right')
निष्कर्ष
मॉडल 75 वें युग के आसपास आया था, और फिर यह बुरी तरह से व्यवहार करता है। 0.85 की सटीकता परेशान नहीं करती है। आप परतों की संख्या, हाइपरपरमेटर्स के साथ मज़े कर सकते हैं और परिणाम को बेहतर बनाने का प्रयास कर सकते हैं। यह हमेशा दिलचस्प होता है और नौकरी का हिस्सा होता है। अपने विचारों के बारे में टिप्पणियों में लिखें, हम देखेंगे कि इस लेख से कितनी टोपियाँ मिलेंगी।