
डिजाइनिंग स्ट्रीमिंग एनालिटिक्स और स्ट्रीमिंग डेटा प्रोसेसिंग सिस्टम की अपनी बारीकियां हैं, अपनी समस्याएं हैं, और अपने स्वयं के तकनीकी स्टैक हैं। हमने इस बारे में अगले
खुले पाठ में बात की, जो
डेटा इंजीनियर पाठ्यक्रम के शुभारंभ की पूर्व संध्या पर आयोजित किया गया था।
वेबिनार पर चर्चा की:
- जब स्ट्रीमिंग प्रसंस्करण की आवश्यकता होती है;
- SPOD में कौन से तत्व हैं, इन तत्वों को लागू करने के लिए हम किन उपकरणों का उपयोग कर सकते हैं;
- कैसे अपने स्वयं के क्लिकस्ट्रीम विश्लेषण प्रणाली का निर्माण करने के लिए।
लेक्चरर -
येगोर मातेशुक ,
मैक्सिमाटेलकॉम के वरिष्ठ डेटा इंजीनियर।
कब ज़रूरी है स्ट्रीमिंग? स्ट्रीम बनाम बैच
सबसे पहले, हमें यह पता लगाने की आवश्यकता है कि कब हमें स्ट्रीमिंग की आवश्यकता है, और कब बैच प्रसंस्करण की आवश्यकता है। आइए हम इन तरीकों की ताकत और कमजोरियों के बारे में बताएं।
तो, बैच प्रसंस्करण के नुकसान:- देरी से डेटा दिया जाता है। चूंकि हमारे पास गणनाओं की एक निश्चित अवधि है, तो इस अवधि के लिए हम हमेशा वास्तविक समय से पीछे रह जाते हैं। और अधिक पुनरावृति, हम जितना पीछे रह जाते हैं। इस प्रकार, हमें एक समय की देरी हो जाती है, जो कुछ मामलों में महत्वपूर्ण है;
- लोहे पर पीक लोड बनाया जाता है। यदि हम बैच मोड में बहुत अधिक गणना करते हैं, तो अवधि (दिन, सप्ताह, महीने) के अंत में हमारे पास एक पीक लोड होता है, क्योंकि आपको बहुत सी चीजों की गणना करने की आवश्यकता होती है। इससे क्या होता है? सबसे पहले, हम सीमा के खिलाफ आराम करना शुरू करते हैं, जो, जैसा कि आप जानते हैं, अनंत नहीं हैं। नतीजतन, सिस्टम समय-समय पर सीमा तक चलता है, जिसके परिणामस्वरूप अक्सर विफलताएं होती हैं। दूसरे, चूंकि ये सभी नौकरियां एक ही समय में शुरू होती हैं, इसलिए वे प्रतिस्पर्धा करते हैं और काफी धीरे-धीरे गणना की जाती हैं, यानी आप एक त्वरित परिणाम पर भरोसा नहीं कर सकते।
लेकिन बैच प्रोसेसिंग के अपने फायदे हैं:- उच्च दक्षता। हम गहराई तक नहीं जाएंगे, क्योंकि दक्षता संपीड़न के साथ जुड़ी हुई है, चौखटे के साथ, और स्तंभ प्रारूपों के उपयोग के साथ, आदि तथ्य यह है कि बैच प्रसंस्करण, यदि आप प्रति यूनिट समय में संसाधित रिकॉर्ड की संख्या लेते हैं, तो अधिक कुशल होगा;
- विकास और समर्थन में आसानी। आप आवश्यक रूप से परीक्षण और पुनरावर्तन द्वारा डेटा के किसी भी भाग को संसाधित कर सकते हैं।
डेटा प्रोसेसिंग (स्ट्रीमिंग) स्ट्रीमिंग के लाभ:- वास्तविक समय में परिणाम। हम किसी भी अवधि के अंत की प्रतीक्षा नहीं करते हैं: जैसे ही डेटा (यहां तक कि बहुत कम राशि) हमारे पास आती है, हम तुरंत इसे संसाधित कर सकते हैं और इसे पास कर सकते हैं। यही है, परिणाम, परिभाषा के अनुसार, वास्तविक समय के लिए प्रयास कर रहा है;
- लोहे पर समान भार। यह स्पष्ट है कि दैनिक चक्र हैं, आदि, हालांकि, लोड अभी भी पूरे दिन वितरित किया जाता है और यह अधिक समान और अनुमानित है।
स्ट्रीमिंग प्रसंस्करण का मुख्य नुकसान:- विकास और समर्थन की जटिलता। बैच की तुलना में पहले, परीक्षण, प्रबंधन, और डेटा पुनर्प्राप्त करना थोड़ा कठिन है। दूसरी कठिनाई (वास्तव में, यह सबसे बुनियादी समस्या है) रोलबैक से जुड़ी है। यदि नौकरियों में काम नहीं किया गया था, और एक विफलता थी, तो उस क्षण पर कब्जा करना बहुत मुश्किल है जहां सब कुछ टूट गया। और समस्या को हल करने के लिए आपको बैच प्रसंस्करण की तुलना में अधिक प्रयास और संसाधनों की आवश्यकता होगी।
इसलिए, यदि आप इस बारे में सोच रहे हैं
कि क्या आपको धाराओं की आवश्यकता है , तो अपने लिए निम्नलिखित प्रश्नों के उत्तर दें:
- क्या आपको वास्तव में वास्तविक समय की आवश्यकता है?
- क्या कई स्ट्रीमिंग स्रोत हैं?
- क्या एक रिकॉर्ड को खोना महत्वपूर्ण है?
आइए
दो उदाहरण देखें :
उदाहरण 1. खुदरा के लिए शेयर विश्लेषण:- माल का प्रदर्शन वास्तविक समय में नहीं बदलता है;
- डेटा को अक्सर बैच मोड में दिया जाता है;
- सूचना का नुकसान महत्वपूर्ण है।
इस उदाहरण में, बैच का उपयोग करना बेहतर है।
उदाहरण 2. वेब पोर्टल के लिए विश्लेषिकी:- विश्लेषण की गति एक समस्या के लिए प्रतिक्रिया समय निर्धारित करती है;
- डेटा वास्तविक समय में आता है;
- उपयोगकर्ता गतिविधि जानकारी की एक छोटी राशि के नुकसान स्वीकार्य हैं।
कल्पना कीजिए कि एनालिटिक्स यह दर्शाता है कि किसी वेब पोर्टल के विज़िटर आपके उत्पाद का उपयोग करके कैसा महसूस करते हैं। उदाहरण के लिए, आपने एक नई रिलीज़ शुरू की और आपको 10-30 मिनट के भीतर समझने की ज़रूरत है कि क्या सब कुछ क्रम में है, अगर कोई कस्टम सुविधाएँ टूट गई हैं। मान लें कि "ऑर्डर" बटन से पाठ चला गया है - एनालिटिक्स आपको आदेशों की संख्या में तेज गिरावट का जवाब देने की अनुमति देगा, और आप तुरंत समझ जाएंगे कि आपको वापस रोल करने की आवश्यकता है।
इस प्रकार, दूसरे उदाहरण में, धाराओं का उपयोग करना बेहतर है।
SPOD तत्व
डेटा प्रोसेसिंग इंजीनियर इस बहुत डेटा (हाँ, डेटा भंडारण भी एक सक्रिय प्रक्रिया है!) को कैप्चर करते हैं, स्थानांतरित करते हैं, वितरित करते हैं और स्टोर करते हैं।
इसलिए, स्ट्रीमिंग डेटा प्रोसेसिंग सिस्टम (SPOD) बनाने के लिए, हमें निम्नलिखित तत्वों की आवश्यकता होगी:
- डेटा लोडर (भंडारण के लिए डेटा डिलीवरी का मतलब);
- डेटा विनिमय बस (यह हमेशा आवश्यक नहीं है, लेकिन इसके बिना धाराओं में कोई रास्ता नहीं है, क्योंकि आपको एक प्रणाली की आवश्यकता है जिसके माध्यम से आप वास्तविक समय में डेटा का आदान-प्रदान करेंगे);
- डेटा भंडारण (इसके बिना);
- ईटीएल इंजन (विभिन्न फ़िल्टरिंग, सॉर्टिंग और अन्य संचालन करने के लिए आवश्यक);
- BI (परिणाम प्रदर्शित करने के लिए);
- ऑर्केस्ट्रेटर (पूरी प्रक्रिया को एक साथ जोड़ता है, मल्टी-स्टेज डेटा प्रोसेसिंग का आयोजन करता है)।
हमारे मामले में, हम सबसे सरल स्थिति पर विचार करेंगे और केवल पहले तीन तत्वों पर ध्यान केंद्रित करेंगे।
डेटा स्ट्रीम प्रोसेसिंग टूल
हमारे पास
डेटा लोडर की भूमिका के लिए कई "उम्मीदवार" हैं:
- अपाचे झाड़
- अपाचे निफी
- StreamSets
अपाचे झाड़
पहले हम जिस बारे में बात करेंगे, वह
अपाचे फ्लूम है , जो विभिन्न स्रोतों और रिपॉजिटरी के बीच डेटा परिवहन के लिए एक उपकरण है।

पेशेवरों:
- लगभग हर जगह है
- लंबे समय तक इस्तेमाल किया
- लचीला और पर्याप्त पर्याप्त
विपक्ष:
- असुविधाजनक विन्यास
- निगरानी करना मुश्किल है
इसके विन्यास के लिए, यह कुछ इस तरह दिखता है:

ऊपर, हम एक सरल चैनल बनाते हैं जो पोर्ट पर बैठता है, वहां से डेटा लेता है और बस इसे लॉग करता है। सिद्धांत रूप में, एक प्रक्रिया का वर्णन करने के लिए, यह अभी भी सामान्य है, लेकिन जब आपके पास ऐसी दर्जनों प्रक्रियाएं होती हैं, तो कॉन्फ़िगरेशन फ़ाइल नरक में बदल जाती है। कोई व्यक्ति कुछ दृश्य विन्यासकर्ता जोड़ता है, लेकिन अगर बॉक्स से बाहर करने वाले उपकरण हैं तो परेशान क्यों? उदाहरण के लिए, वही NiFi और स्ट्रीमसेट।
अपाचे निफी
वास्तव में, यह फ्लूम के रूप में एक ही भूमिका करता है, लेकिन एक दृश्य इंटरफ़ेस के साथ, जो एक बड़ा प्लस है, खासकर जब बहुत सारी प्रक्रियाएं होती हैं।
NiFi के बारे में कुछ तथ्य
- मूल रूप से एनएसए में विकसित;
- हॉर्टोनवर्क्स अब समर्थित और विकसित है;
- हॉर्टनवर्क्स से एचडीएफ का हिस्सा;
- उपकरणों से डेटा एकत्र करने के लिए MiNiFi का एक विशेष संस्करण है।
सिस्टम कुछ इस तरह दिखता है:
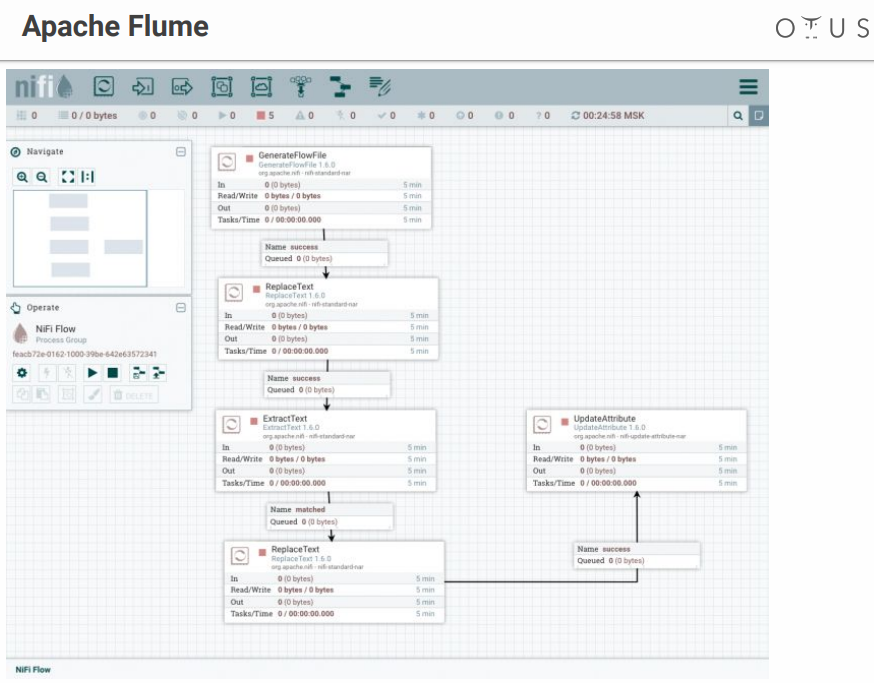
हमारे पास रचनात्मकता और डेटा प्रोसेसिंग के चरणों के लिए एक क्षेत्र है जिसे हम वहां फेंकते हैं। सभी संभव प्रणालियों आदि के लिए कई कनेक्टर हैं।
StreamSets
यह एक विज़ुअल इंटरफ़ेस के साथ डेटा फ्लो कंट्रोल सिस्टम भी है। यह क्लाउडरा के लोगों द्वारा विकसित किया गया था, इसे आसानी से सीडीएच पर पार्सल के रूप में स्थापित किया गया है, इसमें उपकरणों से डेटा एकत्र करने के लिए एसडीसी एज का एक विशेष संस्करण है।
दो घटकों से मिलकर बनता है:
- एसडीसी - एक प्रणाली जो प्रत्यक्ष डेटा प्रसंस्करण (मुक्त) करती है;
- स्ट्रीमसेट्स कंट्रोल हब - कई एसडीसी के लिए एक नियंत्रण केंद्र है जिसमें पेलाइन (भुगतान) के विकास के लिए अतिरिक्त सुविधाएं हैं।
यह कुछ इस तरह दिखता है:

अप्रिय क्षण - स्ट्रीमसेट में स्वतंत्र और सशुल्क दोनों भाग होते हैं।
डेटा बस
अब यह पता लगाते हैं कि हम यह डेटा कहां अपलोड करेंगे। आवेदकों:
अपाचे काफ्का सबसे अच्छा विकल्प है, लेकिन अगर आपकी कंपनी में RabbitMQ या NATS है, और आपको थोड़ा सा एनालिटिक्स जोड़ने की जरूरत है, तो खरोंच से काफ्का को तैनात करना बहुत लाभदायक नहीं होगा।
अन्य सभी मामलों में, काफ्का एक बढ़िया विकल्प है। वास्तव में, यह क्षैतिज स्केलिंग और विशाल बैंडविड्थ के साथ एक संदेश दलाल है। यह पूरी तरह से डेटा के साथ काम करने के लिए उपकरणों के पूरे पारिस्थितिकी तंत्र में एकीकृत है और भारी भार का सामना कर सकता है। इसका एक सार्वभौमिक इंटरफ़ेस है और हमारे डेटा प्रोसेसिंग का संचार तंत्र है।
अंदर, काफ्का को टॉपिक में विभाजित किया गया है - एक ही योजना वाले संदेशों से एक अलग डेटा स्ट्रीम या, कम से कम, एक ही उद्देश्य के साथ।
अगली बारीकियों पर चर्चा करने के लिए, आपको यह याद रखना चाहिए कि डेटा स्रोत थोड़े भिन्न हो सकते हैं। डेटा प्रारूप बहुत महत्वपूर्ण है:

अपाचे एवरो डेटा क्रमांकन प्रारूप विशेष उल्लेख के योग्य है। सिस्टम JSON का उपयोग डेटा संरचना (स्कीमा) को निर्धारित करने के लिए करता है जो एक
कॉम्पैक्ट बाइनरी प्रारूप में क्रमबद्ध होता है। इसलिए, हम डेटा की एक बड़ी राशि बचाते हैं, और क्रमांकन / डीसर्लाइज़ेशन सस्ता होता है।
सब कुछ ठीक लग रहा है, लेकिन सर्किट के साथ अलग-अलग फ़ाइलों की उपस्थिति एक समस्या बन गई है, क्योंकि हमें विभिन्न प्रणालियों के बीच फ़ाइलों का आदान-प्रदान करने की आवश्यकता है। ऐसा लगता है कि यह सरल है, लेकिन जब आप विभिन्न विभागों में काम करते हैं, तो दूसरे छोर के लोग कुछ बदल सकते हैं और शांत हो सकते हैं, और सब कुछ आपके लिए टूट जाएगा।
इन सभी फ़ाइलों को फ्लैश ड्राइव, फ्लॉपी डिस्क और गुफा चित्रों में स्थानांतरित नहीं करने के लिए, एक विशेष सेवा है - स्कीमा रजिस्ट्री। यह कफ़्का से लिखने और पढ़ने वाली सेवाओं के बीच एवरो-योजनाओं को सिंक्रनाइज़ करने के लिए एक सेवा है।

काफ्का के संदर्भ में, निर्माता वह है जो लिखता है, उपभोक्ता वह है जो डेटा का उपभोग करता है (पढ़ता है)।
डेटा वेयरहाउस
चैलेंजर्स (वास्तव में, कई और विकल्प हैं, लेकिन केवल कुछ ही लें):
- HDFS + हाइव
- कुडु + इम्पाला
- ClickHouse
रिपॉजिटरी चुनने से पहले, याद रखें कि क्या
बेवकूफी है । विकिपीडिया कहता है कि idempotency (लैटिन इडेम - वही + पोटेन्स - सक्षम) - ऑब्जेक्ट को फिर से ऑब्जेक्ट पर लागू करते समय किसी ऑब्जेक्ट या ऑपरेशन की संपत्ति, पहले जैसा ही परिणाम देती है। हमारे मामले में, स्ट्रीमिंग प्रसंस्करण की प्रक्रिया का निर्माण किया जाना चाहिए ताकि स्रोत डेटा को फिर से भरने पर परिणाम सही रहे।
स्ट्रीमिंग सिस्टम में
इसे कैसे प्राप्त करें :
- एक विशिष्ट आईडी की पहचान करें (समग्र हो सकती है)
- डेटा को कम करने के लिए इस आईडी का उपयोग करें
HDFS + हाइव भंडारण स्ट्रीमिंग "बॉक्स से बाहर" के लिए सुविधा
प्रदान नहीं करता है , इसलिए हमारे पास है:
कुडू विश्लेषणात्मक प्रश्नों के लिए एक रिपॉजिटरी है, लेकिन एक प्राथमिक कुंजी के साथ, समर्पण के लिए।
इम्पाला इस रिपॉजिटरी (और कई अन्य) के लिए SQL इंटरफ़ेस है।
ClickHouse के लिए, यह यांडेक्स का एक विश्लेषणात्मक डेटाबेस है। इसका मुख्य उद्देश्य कच्चे डेटा की एक बड़ी धारा से भरी तालिका पर विश्लेषण है। फायदों में से - मुख्य डडुप्लीकेशन के लिए एक रीप्लेसिंगमेजरट्री इंजन है (कटौती को अंतरिक्ष को बचाने के लिए डिज़ाइन किया गया है और कुछ मामलों में डुप्लिकेट को छोड़ सकता है, आपको
बारीकियों को ध्यान में रखना होगा)।
यह
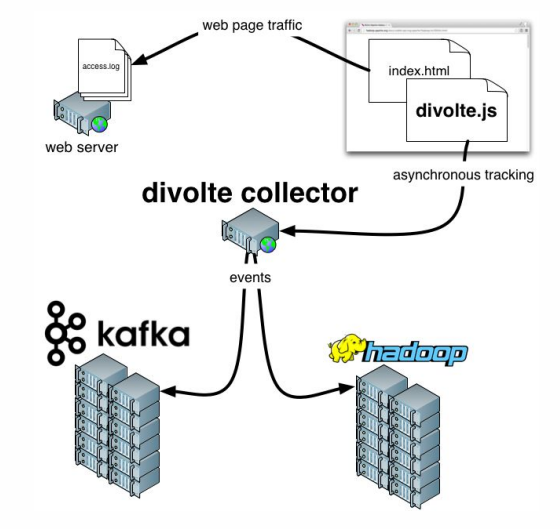
Divolte के बारे में कुछ शब्द जोड़ना
बाकी है । यदि आपको याद है, तो हमने इस तथ्य के बारे में बात की कि कुछ डेटा को कैप्चर करने की आवश्यकता है। यदि आपको किसी पोर्टल के लिए एनालिटिक्स को जल्दी और आसानी से व्यवस्थित करने की आवश्यकता है, तो जावास्क्रिप्ट के माध्यम से वेब पेज पर उपयोगकर्ता की घटनाओं को कैप्चर करने के लिए Divolte एक उत्कृष्ट सेवा है।
व्यावहारिक उदाहरण
हम क्या करने की कोशिश कर रहे हैं?
आइए वास्तविक समय में क्लिकस्ट्रीम डेटा एकत्र
करने के लिए एक पाइपलाइन
बनाने की कोशिश करें ।
क्लिकस्ट्रीम एक आभासी पदचिह्न है जो एक उपयोगकर्ता आपकी साइट पर छोड़ देता है। हम Divolte का उपयोग करके डेटा कैप्चर करेंगे, और उन्हें काफ्का में लिखेंगे।

आपको काम करने के लिए डॉकर की आवश्यकता है, साथ ही आपको
निम्न भंडार को क्लोन करने की आवश्यकता
है । जो कुछ भी होता है उसे कंटेनरों में लॉन्च किया जाएगा। एक साथ कई कंटेनरों को लगातार चलाने के लिए,
docker-compose.yml का उपयोग किया जाएगा। इसके अलावा, कुछ निर्भरता के साथ हमारे
स्ट्रीमसेट को संकलित करने के लिए एक
डॉकफाइल है ।
तीन फ़ोल्डर भी हैं:
- क्लिकहाउस डेटा को क्लिकहाउस-डेटा लिखा जाएगा
- बिल्कुल वही डैडी ( sdc-data ) हमारे पास स्ट्रीमसेट्स के लिए होगा, जहाँ सिस्टम कॉन्फ़िगरेशन स्टोर कर सकता है
- तीसरे फ़ोल्डर ( उदाहरण ) में स्ट्रीमसेट के लिए एक अनुरोध फ़ाइल और एक पाइप कॉन्फ़िगरेशन फ़ाइल शामिल है

शुरू करने के लिए, निम्नलिखित कमांड दर्ज करें:
docker-compose up
और हम आनंद लेते हैं कि धीरे-धीरे लेकिन निश्चित रूप से कंटेनर कैसे शुरू होते हैं। शुरू करने के बाद, हम पते पर जा सकते हैं
http: // localhost: 18630 / और तुरंत Divolte को स्पर्श करें:

इसलिए, हमारे पास दिवोल्टे हैं, जो पहले से ही कुछ घटनाओं को प्राप्त कर चुके हैं और उन्हें काफ्का में दर्ज किया है। चलिए इन्हें
स्ट्रीमसेट्स :
http: // localhost: 18630 / (पासवर्ड / लॉगिन - एडमिन / एडमिन) का उपयोग करके गणना करने का प्रयास करें।

पीड़ित न होने के लिए,
पाइपलाइन को
आयात करना बेहतर है, इसका नामकरण, उदाहरण के लिए,
clickstream_pipeline । और उदाहरण फोल्डर से हम
क्लिकस्ट्रीम.जसन आयात करते हैं। यदि सब कुछ ठीक है,
तो हम निम्नलिखित चित्र देखेंगे :

तो, हमने काफ्का के लिए एक कनेक्शन बनाया, जिसे कफ्का की आवश्यकता है, जो कि हमें किस विषय में रुचि रखता है, को पंजीकृत किया, फिर उन क्षेत्रों का चयन किया जो हमें रुचि रखते हैं, फिर काफ्का में एक नाली डालें, जो कि काफ्का और किस विषय को पंजीकृत करता है। अंतर यह है कि एक मामले में, डेटा प्रारूप एवरो है, और दूसरे में यह सिर्फ JSON है।
चलो आगे बढ़ते हैं। उदाहरण के लिए, हम
एक पूर्वावलोकन कर सकते हैं जो कफ़्का से वास्तविक समय में कुछ रिकॉर्ड प्राप्त करता है। फिर हम सब कुछ लिखते हैं।
लॉन्च करने के बाद, हम देखेंगे कि काफ्का के लिए घटनाओं की एक धारा उड़ती है, और यह वास्तविक समय में होता है:

अब आप ClickHouse में इस डेटा के लिए एक रिपॉजिटरी बना सकते हैं। ClickHouse के साथ काम करने के लिए, आप निम्न कमांड चलाकर एक साधारण देशी ग्राहक का उपयोग कर सकते हैं:
docker run -it --rm --network divolte-ss-ch_default yandex/clickhouse-client --host clickhouse
कृपया ध्यान दें कि यह रेखा उस नेटवर्क को इंगित करती है जिससे आप कनेक्ट करना चाहते हैं। और आप रिपॉजिटरी के साथ फ़ोल्डर का नाम कैसे देते हैं, इसके आधार पर, आपका नेटवर्क नाम भिन्न हो सकता है। सामान्य तौर पर, कमांड निम्नानुसार होगी:
docker run -it --rm --network {your_network_name} yandex/clickhouse-client --host clickhouse
नेटवर्क की सूची कमांड के साथ देखी जा सकती है:
docker network ls
खैर, कुछ बचा नहीं है:
1.
सबसे पहले, "क्लिक" हमारे क्लिकहाउस को काफ्का , "उसे समझाते हुए" हमें उस प्रारूप का क्या स्वरूप चाहिए जो हमें चाहिए:
CREATE TABLE IF NOT EXISTS clickstream_topic ( firstInSession UInt8, timestamp UInt64, location String, partyId String, sessionId String, pageViewId String, eventType String, userAgentString String ) ENGINE = Kafka SETTINGS kafka_broker_list = 'kafka:9092', kafka_topic_list = 'clickstream', kafka_group_name = 'clickhouse', kafka_format = 'JSONEachRow';
2.
अब हम एक वास्तविक तालिका बनाएँगे जहाँ हम अंतिम डेटा डालेंगे:
CREATE TABLE clickstream ( firstInSession UInt8, timestamp UInt64, location String, partyId String, sessionId String, pageViewId String, eventType String, userAgentString String ) ENGINE = ReplacingMergeTree() ORDER BY (timestamp, pageViewId);
3.
और फिर हम इन दो तालिकाओं के बीच एक संबंध प्रदान करेंगे :
CREATE MATERIALIZED VIEW clickstream_consumer TO clickstream AS SELECT * FROM clickstream_topic;
4.
और अब हम आवश्यक क्षेत्रों का चयन करेंगे :
SELECT * FROM clickstream;
परिणामस्वरूप, लक्ष्य तालिका से चुनने पर हमें वह परिणाम मिलेगा जिसकी हमें आवश्यकता है।
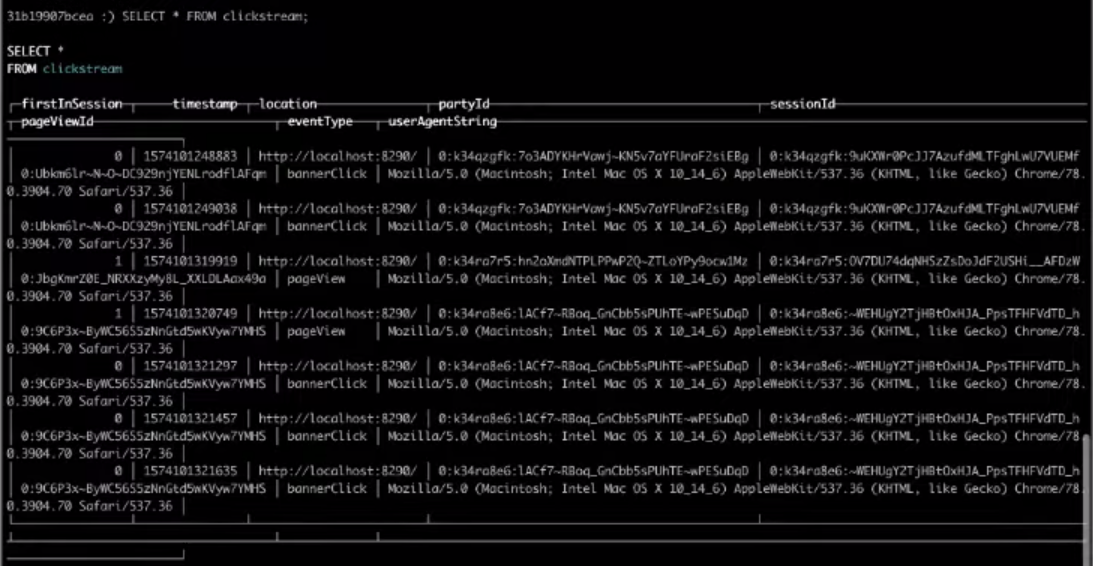
बस इतना ही, यह सबसे सरल क्लिकस्ट्रीम था जिसे आप बना सकते हैं। यदि आप उपरोक्त चरणों को स्वयं पूरा करना चाहते हैं,
तो पूरा
वीडियो देखें ।