संभवतः, बेलारूस के हर शहर में जहां ट्रॉलीबस हैं, वहां टेलीग्राम पर वीके समूह या चैट हैं जिसमें लोग नियंत्रकों के स्थान को ट्रैक करते हैं। यह मुख्य रूप से ऐसा किया जाता है ताकि यात्रा और मुफ्त यात्रा के लिए भुगतान न किया जा सके, हालांकि समूहों के विवरण में लगभग "यात्रा के लिए भुगतान" पोस्टस्क्रिप्ट शामिल हैं।
वीसी में, यह आमतौर पर इस तरह दिखता है:
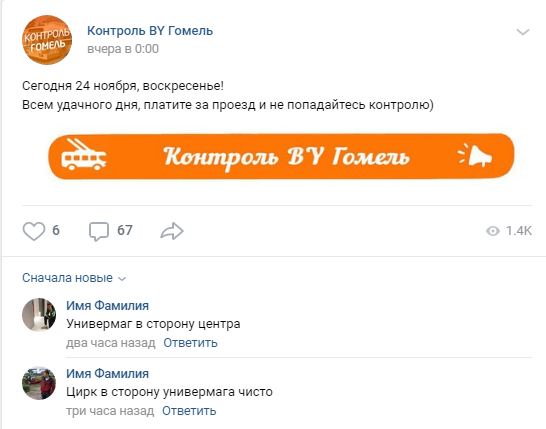
एक सामान्य टिप्पणी इस तरह दिखती है:
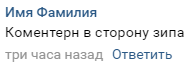
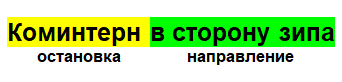
संरचना अत्यंत सरल है। कमेंटरी में उन स्टॉप्स के नाम दिए गए हैं, जहां वर्तमान में नियंत्रकों का ध्यान था, वे जिस दिशा में खड़े हैं, वह भी है:
परिणाम के रूप में टिप्पणी, एक स्टॉप, समय और दिनांक के साथ एक वस्तु है, साथ ही एक अद्वितीय आईडी जिसके द्वारा हम इसे पहचान सकते हैं। इसके साथ, आप सबसे अधिक संभावित स्थान की गणना कर सकते हैं जहां नियंत्रक अब हैं।
ट्रेनिंग
पहले आपको लक्ष्य को सार्वजनिक करने की आवश्यकता है, जिसमें से हम डेटा को पार्स करेंगे। समूह में टिप्पणियों में बहुत अधिक गतिविधि होनी चाहिए, अन्यथा हम बहुत कम डेटा प्राप्त करने का जोखिम उठाते हैं
मेरे मामले में, यह "कंट्रोल गोमेल" समूह है।
हम पायथन के लिए आधिकारिक VKontakte API का उपयोग करके टिप्पणियों को पार्स करेंगे
हम उपयोगकर्ता की पहुंच कुंजी के साथ प्रमाणित करते हैं, क्योंकि कुछ समूह बंद हो सकते हैं, और उनकी टिप्पणियों तक पहुंच केवल तभी प्राप्त की जा सकती है जब आपको समूह में स्वीकार किया गया हो।
उसके बाद, आप टिप्पणियां निकालना शुरू कर सकते हैं:
टिप्पणियाँ प्राप्त करें
आरंभ करने के लिए, हमें vk.wall.getComments के माध्यम से टिप्पणियां निकालने के लिए समूह में अंतिम उपलब्ध पोस्ट मिलती है, और DataFrame को इनिशियलाइज़ करता है, जिसमें हम डेटा को सेव करेंगे।
प्रत्येक टिप्पणी पोस्ट में शिलालेख है "एक अच्छा दिन है, किराया का भुगतान करें और नियंत्रण में न आएं", इसलिए टिप्पणियों को डाउनलोड करें, पोस्ट की सामग्री की जांच करें और उन टिप्पणियों की एक सरणी प्राप्त करें जिनसे आप डेटा ले सकते हैं।
मैंने पिछले 3 महीनों में पोस्ट से टिप्पणियां लीं, यह देखते हुए कि 1 पोस्ट हर दिन पोस्ट की जाती है (अब नवंबर के अंत में, स्कूल वर्ष सितंबर में शुरू होता है, और पर्यवेक्षकों को सबसे अधिक संभावना है कि इसे ध्यान में रखा जाए और उनके सामान्य स्थानों को बदल दिया जाए)। सिद्धांत रूप में, अन्य संकेतों को ध्यान में रखा जा सकता है, जैसे, उदाहरण के लिए, वर्ष का समय।
कुछ टिप्पणियों को संदेशों से भरा हुआ है जैसे "क्या बैरीकिन पर कोई है?" यदि आप ऐसी (अनावश्यक) टिप्पणियों को देखते हैं, तो आप कुछ संकेतों को उजागर कर सकते हैं:
- पाठ में "स्वच्छ", "बाएं", "कोई नहीं" और जैसे शब्द शामिल हैं
- शब्द "मुझे बताओ", "कौन", "क्या", "कैसे"
- उदाहरण के लिए प्रतीक, जैसे इमोटिकॉन्स
उसके बाद, हम टिप्पणियों की एक सरणी के माध्यम से जाते हैं और उनसे सप्ताह की एक अद्वितीय आईडी, पाठ, समय, तिथि और दिन निकालते हैं, जिसे हमने पहले से ही बनाए गए डेटाफ़्रेम में डाल दिया है।
टिप्पणियाँ प्राप्त करेंimport re import time import pandas as pd import lp import vk_api import check_correctness def auth(): vk_session = vk_api.VkApi(lp.login, lp.password) vk_session.auth() vk = vk_session.get_api() return vk def getDataFromComments(vk, groupID):
इस प्रकार, हमें टिप्पणियों के पाठ के साथ एक डेटाफ़्रेम प्राप्त हुआ, उनकी आईडी, सप्ताह का दिन, घंटे और मिनट जिसमें टिप्पणी लिखी गई थी। हमें केवल सप्ताह का दिन, लेखन का समय और पाठ की आवश्यकता है। यह कुछ इस तरह दिखता है:
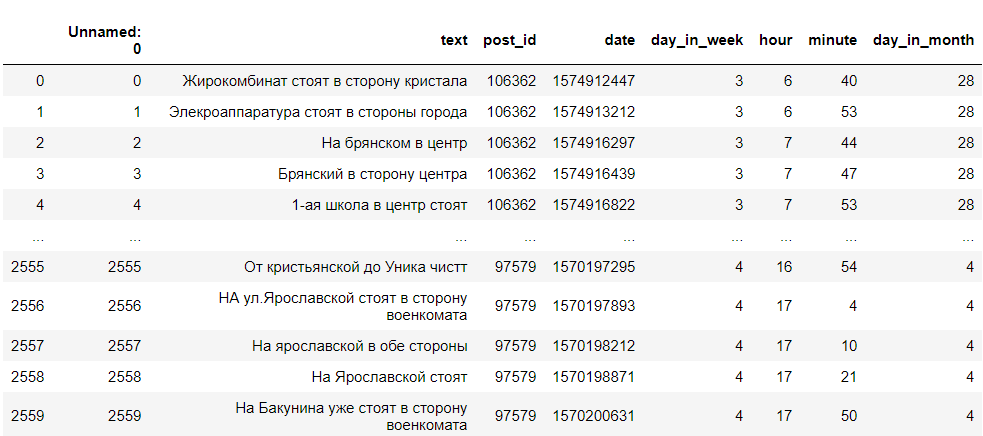
डेटा की सफाई
अब हमें डेटा साफ़ करने की आवश्यकता है। लेवेंसहेटिन दूरी की खोज करते समय कम गलतियां करने के लिए टिप्पणी से दिशा को हटाने के लिए आवश्यक है। हमें भाव "ओर", "जाने", "कैसे", "निकट" मिलते हैं, जैसा कि वे आम तौर पर दूसरे पड़ाव के नाम से होते हैं, और हम उन्हें उनके साथ आने वाली चीज़ों के साथ हटा देते हैं, साथ ही कुछ जार्गान के नामों को सामान्य के साथ रोकते हैं। ।
डेटा साफ़ करें from fuzzywuzzy import process def clear_commentary(text): """ - """ index = 0 splitted = text.split(" ") for i, s in enumerate(splitted): if len(splitted) == 1: return np.NaN if ((("" in s) or ("" in s) or ( "" in s) or ( "" in s)) and s is not ""): index = i if index is not 0 and index < len(splitted) - 2: for i in range(1, 4): splitted.remove(splitted[index]) string = " ".join(splitted) text = (string.lower()) elif index is not 0: splitted = splitted[:index] string = " ".join(splitted) text = string.lower() else: text = " ".join(splitted).lower() return text def clean_data(data): data.dropna(inplace=True) data["text"] = data["text"].map(lambda s: clear_commentary(s)) data.dropna(inplace=True) print("cleaned") return data
लेवेंसहाइट दूरी का उपयोग करते हुए परिवर्तित करना
हम सीधे लेवेन्शेन दूरी के लिए आगे बढ़ते हैं। एक छोटी सी मदद: लेवेंसहाइट दूरी - एक वर्ण को सम्मिलित करने के लिए संचालन की न्यूनतम संख्या, एक वर्ण को हटाएं और एक वर्ण को दूसरे के साथ बदलने के लिए, एक पंक्ति को दूसरी में बदलने के लिए आवश्यक है।
हम इसे
फजीविज्जी लाइब्रेरी का उपयोग कर
पाएंगे । यह आपको लेवेंशेटिन दूरी की जल्दी और आसानी से गणना करने में मदद करता है। कार्य को गति देने के लिए, पुस्तकालय के लेखक भी अजगर-लेवेंसटेइन पुस्तकालय स्थापित करने की सलाह देते हैं।
टिप्पणियों से स्टॉप पाने के लिए, हमें स्टॉप की सूची चाहिए। यह कृपया मुझे GoTrans एप्लिकेशन के डेवलपर अलेक्जेंडर कोज़लोव द्वारा प्रदान किया गया था।
सूची का विस्तार करना था, वहां कुछ स्टॉप्स जोड़ना जो वहां नहीं थे, और नामों का हिस्सा बदलना ताकि वे बेहतर स्थित थे।
बंद हो जाता हैस्टॉप्स = ['सुपरमार्केट', 'मीडो', 'रेमीबख्तनिका', 'लेनिनग्राद', 'यारोस्लाव', 'पोलेस्काया',
'यारोस्लाव', 'टाइमफिनको', '8 मार्च',
'रेकिट्स्की ट्रेडिंग हाउस', 'रेकिट्स्की एवेन्यू', 'सर्कस', 'डिपार्टमेंटल स्टोर', 'चोंगर्सकाया',
'चोंगाका', 'गुग', 'स्कोरीना', 'विश्वविद्यालय', 'उपकरण', '1000 छोटी चीजें', 'माया', 'स्टेशन',
'ग्रेजुएट पार्क', 'ट्रेड एंड इकोनॉमिक', 'एनिवर्सरी', 'माइक्रोडिसिस्ट 18', 'एयरपोर्ट', 'इनकमिंग',
'गोमेलजोडेसेन्ट्र', 'क्रिस्टल', 'लेक लिबेंसकोय', 'डैविडोव्स्की मार्केट', 'डैविडोव्का',
'नदी सोझ', 'गोमेल्ड्रेव',
'सेवरुकी', 'गमू नंबर 1', 'आदि रिच्त्स्की', 'पोशाक', 'संक्रामक रोग अस्पताल', 'गल शिविर',
वोल्तोवा, कोरल, गोमेल्टॉर्गमाश, गोमेलप्रोक्ट, वनेशगोमेलस्ट्रॉय, न्यूजपेपर,
'कालेनिकोवा', 'एरेमिनो', 'डिस्टिलरी', 'स्पेशल इंडस्ट्रियल ऑटोमेशन', 'सेकंड स्कूल', 'बेरीकिना',
'मशीन यूनिट्स', 'यूथ', 'कास्टिंग बॉडी', 'केमिस्ट्स', 'गोलोवैट्सकी', 'बेनी',
'स्पू67', '35 वां ',' गागरिन ', '50 साल से गोमेलमश प्लांट', 'हिल', 'रेडियो फैक्ट्री'
'दादी', 'कांच के बने पदार्थ', 'शाहबलूत', 'शुरुआती इंजन', 'अंतरिक्ष यात्री',
'आरटीएसआरएम प्रारंभिक ’, k ब्यखोव्स्काया’, initial आपातकालीन स्थितियों के मंत्रालय का संस्थान ’, m डीके गोमेल्माश’,' स्टोर ’, ch रेकिट्स्की’
'सेव्रक्स', 'ओसोवेत्सी', 'टूरिस्ट', 'मीट फैक्ट्री', 'होली ट्रिनिटी', 'मेडिकल टाउन', 'अक्टूबर'
'तेल डिपो', 'गोमेलोब्लावतोट्रान्स', 'मिल्कविता', 'बेकुनिन', 'जिप', 'ओमा', 'रेजिन'
'कंस्ट्रक्शन मार्केट ksk', 'रोड बिल्डर', 'फ़ील्ड', 'kamenetskaya', 'bolshevik', 'jakubovka',
'बोरोडिना', 'हिप्पो हाइपरमार्केट', 'भूमिगत नायक', '9 मई', 'चेस्टनट', 'प्रोस्थेटिस्ट',
'आईपुत स्टेशन', 'कम्युनिस्ट इंटरनेशनल', 'म्यूज़िक पेडागॉजिकल कॉलेज', 'एग्रीकल्चरल फ़र्म', 'बाईपास रोड', 'जीत',
'वेस्टर्न', 'पर्ल', 'व्लादिमीर', 'ड्राई', 'डिस्पेंसरी', 'इवानोवा',
'मशीन-बिल्डिंग', 'बिर्च', '60 साल ',' पावर इंजीनियर ',' सेंट्रोलाइट ',
'ऑन्कोलॉजिकल क्लिनिक ’, range शूटिंग रेंज’, ints गोलोवेन्सी ’, ological कोरल’, spring साउथर्न ’, ic स्प्रिंग’,
एफ़्रेमोवा, बॉर्डर, बेलगुट, गोमेलस्ट्रॉय, बोरिसेंको, एथलेटिक्स पैलेस,
'मिचुरिन्स्की', 'सोलर', 'गैस्टेलो', 'मिलिट्री', 'ऑटो सेंटर', 'प्लंबिंग', 'उजा',
'मेडिकल कॉलेज', 'किंडरगार्टन 11', 'बोल्शेविक', 'पिल्लों', 'डेविडोव्स्की', 'महासागर', 'प्रगति'
'दोब्रुस्काया', 'श्वेत', 'जीएसके', 'द्विदलोवका', 'विद्युत उपकरण', 'मैत्री',
'70 साल ',' कार की मरम्मत ',' सनी पहाड़ी ',' सर्किट ',' वाटर कैनाल ',' मशीन गोमेल ',
वोल्तोवा, पायनियर, आरसीएम, खिम्तोर्ग, दूसरा मीडो लेन, बोचकिना, स्नान,
'ऑन्कोलॉजिकल क्लिनिक', 'स्क्वायर', 'लेनिन', '1 स्कूल', 'साउथ स्टोर',
rans गोमेलैग्रोट्रान्स ’, ers मिलर्स’, ens लियूबेंस्की ’, el मिलिट्री एनॉलिस्टमेंट ऑफिस’, हॉस्पिटल ’, hospital उजा’, r आरटीएसएम ’,
'lysyukovyh', 'shop iput', 'raton', 'gas station', 'randovsky', 'फार्महाउस', 'चेस्टनट', 'ropovsky',
'रोमानोविची', 'इलिच', 'रोइंग', 'कंस्ट्रक्शन एंटरप्राइज', 'संक्रामक'
'फैट फैक्ट्री', 'कार सर्विस', 'एग्रोस सर्विस', 'स्टिकी', 'निकोलसकाया',
'स्व-चालित हार्वेस्टर', 'राजमिस्त्री', 'निर्माण सामग्री', 'मरम्मत मशीनरी', 'प्रशासन',
'अक्टूबर', 'वन परी कथा', 'तातियाना', 'बोरिस त्सारीकोव', 'झरकोवस्की', 'जैतसेवा',
'रिलोकेशन', 'करपोविच', 'हाउस-बिल्डिंग प्लांट', 'सिटी इलेक्ट्रिक ट्रांसपोर्ट', 'ज़्लिन'
'स्टेडियम गोमेलमश', 'एपी 6', 'हाइड्रोलिक ड्राइव', 'लोकोमोटिव डिपो', 'कार बाजार ऑसोव्त्सी',
'नया जीवन', 'झोकोवा', 'मिलिट्री यूनिट', 'थ्री स्कूल', 'वन', 'रेड लाइटहाउस',
yd क्षेत्रीय ’, ovsk डेविडॉस्काया’, he करबिश्वा ’,, दुनिया का उपग्रह’, st युवा ’, 'स्टेडियम लोकोमोटिव’,
'सोलर', 'लाड्स सर्विस', 'μR 21', 'एरेसा', 'इंटरनेशनलिस्ट', 'कोसरेवा',
'बोगदानोवा', 'गोमेल आयरन-कंक्रीट', 'μr 20a', 'μr Rechitsky', 'चिकित्सा उपकरण', 'Juraeva',
'कॉलेज ऑफ आर्ट क्राफ्ट्स', 'आइस', 'डीके फेस्टिवल', 'शॉपिंग सेंटर',
'कुइबिशेवस्की', 'फेस्टिवल', 'गैराज कोप 27', 'भूकंपीय इंजीनियरिंग', 'मिल्खा', 'ट्यूब हॉस्पिटल',
'ptu179', 'रासायनिक उत्पाद', 'अग्निशमन विभाग', 'अस्पताल', 'बस डिपो',
'अखबार परिसर', 'जीत', 'केलकोवस्की', 'हीरा', 'इंजन की मरम्मत', 'एमकेआर 19']
.Map और fuzzywuzzy.process.extractOne का उपयोग करते हुए, हम सूची में न्यूनतम Levenshtein दूरी के साथ रोक पाते हैं, जिसके बाद हम टिप्पणी पाठ को स्टॉप के नाम से बदल देते हैं, जो हमें स्टॉप के नाम के साथ एक डेटासेट प्राप्त करने की अनुमति देता है।
परिणामी डेटासेट कुछ इस तरह दिखता है:
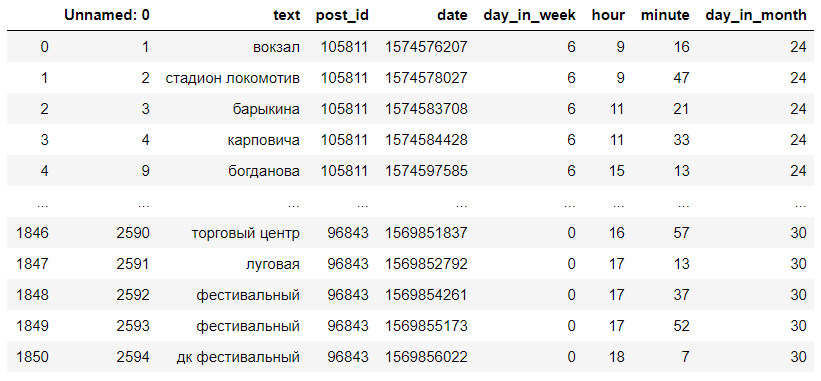
टिप्पणियाँ स्टॉप में बदल जाती हैं def get_category_from_comment(text): """ """ dict = process.extractOne(text.lower(), stops) if dict[1] > 75: text = dict[0] else: text = np.nan print("wait") return text def get_category_dataset(data): """ """ print("remap started. wait") data.text = data.text.map(lambda comment: get_category_from_comment(str(comment))) print("remap ends") data.dropna(inplace=True) data["text"] = data.text.map(lambda s: "" if s=="" else s) data["text"] = data.text.map(lambda s: "" if s=="" else s) data["text"] = data.text.map(lambda s: " " if s=="" else s) data["text"] = data.text.map(lambda s: " " if s=="" else s) return data
डेटा आउटपुट
अब हम मान सकते हैं कि नियत समय पर नियंत्रक की संभावना सबसे अधिक होगी।
हम सप्ताह के एक विशिष्ट घंटे और दिन के लिए परिणामी डेटा रिकॉर्ड देख रहे हैं। उदाहरण के लिए, मंगलवार को सुबह 9 बजे:
<code>data[(data["day_in_week"] == day) & (data["hour"] == hour)]</code>
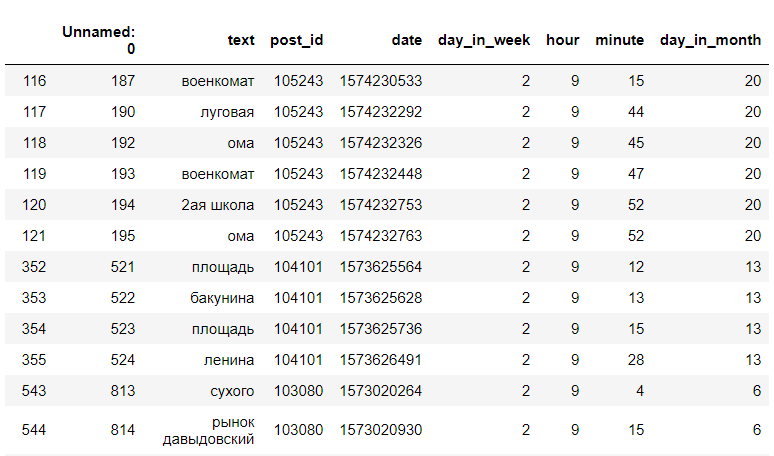 (यह सब डेटा नहीं है)
(यह सब डेटा नहीं है)उसके बाद, हम अद्वितीय स्टॉप की संख्या पाते हैं, और केवल स्टॉप को प्रदर्शित करते हैं, और उनकी संख्या:
df[(df["day_in_week"] == 2) & (df["hour"] == 9)]["text"].value_counts()

अब हम कह सकते हैं कि मंगलवार सुबह 9 बजे, मीट प्रोसेसिंग प्लांट, उल के स्टॉप पर नियंत्रकों की सबसे अधिक संभावना होगी। लुगोवया, बेलगुट, टीडी "ओमा"।
इस पद्धति का मुख्य दोष डेटा की कमी है। सभी दिनों और घंटों के लिए नहीं, भीड़ के समय में दी गई टिप्पणियों में प्रविष्टियां होती हैं, जब लोग कम लोकप्रिय घंटों में डेटा से अधिक सार्वजनिक परिवहन का उपयोग करते हैं, लेकिन यदि आप डेटा जोड़ते हैं, उदाहरण के लिए, न केवल एक समूह की टिप्पणियों से, बल्कि वैकल्पिक समूहों या टेलीग्राम चैट से, प्रविष्टियों की संख्या के साथ, सब कुछ आसान हो जाएगा।
वीके लॉन्गपॉल एपीआई के साथ बॉट
नियंत्रकों के स्थान पर डेटा प्राप्त करने का अवसर देने के लिए, समय के आधार पर, और कंप्यूटर से जुड़े हुए बिना, मैंने VKontakte पर एक समूह के लिए एक बॉट बनाया जो रिकॉर्ड के स्टॉप की संख्या भेजकर किसी भी संदेश का जवाब देता है, जिसे वर्तमान घंटे और सप्ताह का दिन बताया गया है।
बॉट कोड from random import randint import vk_api from requests import * from get_stops_from_data import get_stops_by_time def start_bot(data, token): vk_session = vk_api.VkApi(token=token) vk = vk_session.get_api() print("bot started") longPoll = vk.groups.getLongPollServer(group_id=183524419) server, key, ts = longPoll['server'], longPoll['key'], longPoll['ts'] while True:
निष्कर्ष
इस तरह की परिकल्पनाओं की गुणवत्ता का मेरे द्वारा एक बार से अधिक अभ्यास में परीक्षण किया गया है, और सब कुछ ठीक है। यह पता चला कि नियंत्रक, मूल रूप से, एक ही स्टॉप पर हैं, हालांकि बिल्कुल सही पूर्वानुमान नहीं दिए जा सकते हैं, और सफलता की संभावना 100% नहीं है। एक शब्द में त्रुटियों को सही करने से लेकर जीन, गुणसूत्र और प्रोटीन की तुलना करने के लिए लेवेन्सहाइट दूरी के दर्जनों अलग-अलग अनुप्रयोग हैं, लेकिन इस तरह की लागू समस्याओं में इसकी क्षमता भी है।
आपका दिन शुभ हो, और किराया चुकाएं।
सभी बॉट कोड और डेटा जोड़तोड़ यहां प्रकाशित किए गए
हैं ।