हम लंबे समय से क्लाउड सेवाओं का उपयोग कर रहे हैं: मेल, भंडारण, सामाजिक नेटवर्क, त्वरित संदेशवाहक। वे सभी दूर से काम करते हैं - हम संदेश और फाइलें भेजते हैं, और उन्हें दूरस्थ सर्वर पर संग्रहीत और संसाधित किया जाता है। क्लाउड गेमिंग भी काम करता है: उपयोगकर्ता सेवा से जुड़ता है, खेल का चयन करता है और लॉन्च करता है। यह खिलाड़ी के लिए सुविधाजनक है, क्योंकि खेल लगभग तुरंत शुरू होते हैं, मेमोरी नहीं लेते हैं, और एक शक्तिशाली गेमिंग कंप्यूटर की आवश्यकता नहीं है।

क्लाउड सेवा के लिए, सब कुछ अलग है - इसमें डेटा संग्रहण समस्याएं हैं। प्रत्येक खेल में दसियों या सैकड़ों गीगाबाइट का वजन हो सकता है, उदाहरण के लिए, "द विचर 3" में 50 जीबी लगता है, और "कॉल ऑफ ड्यूटी: ब्लैक ऑप्स III" - 113। एक ही समय में, खिलाड़ी 2-3 गेम के साथ सेवा का उपयोग नहीं करेंगे, कम से कम दर्जनों की आवश्यकता होती है। । सैकड़ों गेमों को संग्रहीत करने के अलावा, सेवा को यह तय करने की आवश्यकता है कि प्रति खिलाड़ी को कितना भंडारण करना है, और जब उनमें से हजारों होते हैं, तो पैमाने।
क्या यह सब उनके सर्वर पर संग्रहीत किया जाना चाहिए: उन्हें कितने डेटा की जरूरत है, जहां डेटा केंद्रों को रखा जाए, मक्खी पर कई डेटा केंद्रों के बीच डेटा को "सिंक्रनाइज़" कैसे किया जाए? "बादल" खरीदें? आभासी मशीनों का उपयोग करें? क्या 5 बार संपीड़न के साथ उपयोगकर्ता डेटा संग्रहीत करना और उन्हें वास्तविक समय में प्रदान करना संभव है? एक ही वर्चुअल मशीन के लगातार उपयोग के दौरान एक दूसरे पर उपयोगकर्ताओं के किसी भी प्रभाव को कैसे बाहर रखा जाए?
क्लाउड-आधारित गेमिंग प्लेटफ़ॉर्म - Playkey.net में इन सभी कार्यों को सफलतापूर्वक हल किया गया था।
व्लादिमीर रयाबोव (
ग्रेमेंसामा ) - सिस्टम एडमिनिस्ट्रेशन विभाग के प्रमुख - फ्रीबीएसडी के लिए जेडएफएस तकनीक के बारे में विस्तार से बात करेंगे, जिसने इसमें मदद की, और जेडओएल (लिनक्स पर जेडएफएस) का ताजा कांटा।
कंपनी के एक हजार सर्वर मॉस्को, लंदन और फ्रैंकफर्ट में दूरस्थ डेटा केंद्रों में स्थित हैं। सेवा में 250 से अधिक खेल हैं, जो एक महीने में 100 हजार खिलाड़ियों द्वारा खेले जाते हैं।
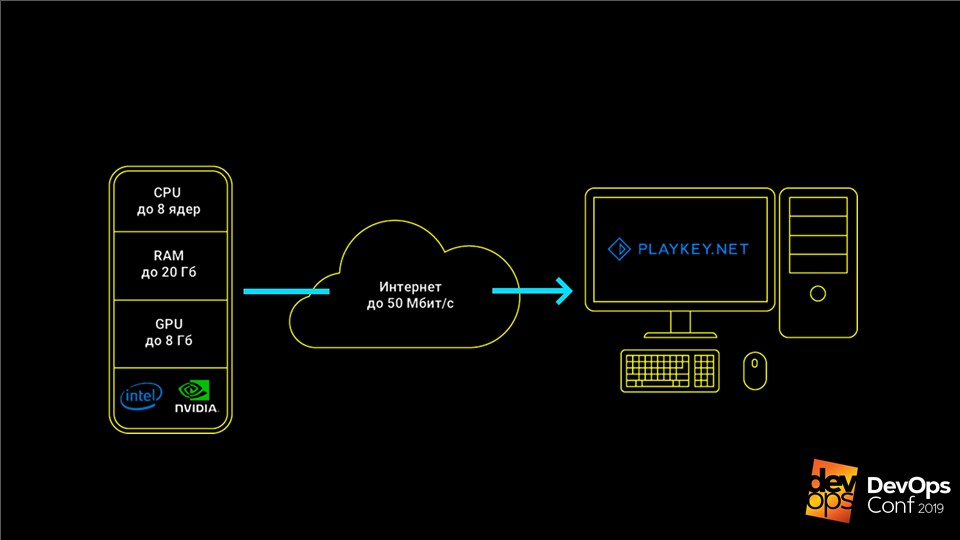
यह सेवा इस तरह काम करती है: गेम कंपनी के सर्वर पर चलता है, उपयोगकर्ता कीबोर्ड, माउस या गेमपैड से नियंत्रण की एक धारा प्राप्त करता है, और प्रतिक्रिया में एक वीडियो स्ट्रीम भेजा जाता है। यह आपको कमजोर हार्डवेयर वाले कंप्यूटर, एकीकृत वीडियो वाले लैपटॉप, या मैक पर आधुनिक टॉप-एंड गेम खेलने की अनुमति देता है, जिसके लिए ये गेम बिल्कुल भी रिलीज़ नहीं होते हैं।
खेलों को संग्रहीत और अद्यतन किया जाना चाहिए
क्लाउड गेमिंग सेवा के लिए मुख्य डेटा गेम वितरण है, जो सैकड़ों जीबी से अधिक हो सकता है, और उपयोगकर्ता बचा सकता है।
जब हम छोटे थे, हमारे पास केवल एक दर्जन सर्वर और 50 खेलों का एक मामूली कैटलॉग था। हमने सर्वर पर स्थानीय रूप से सभी डेटा संग्रहीत किया, मैन्युअल रूप से अपडेट किया, सब कुछ ठीक था। लेकिन समय बढ़ने लगा है और हमने
AWS बादलों के लिए बंद कर दिया
है ।
AWS के साथ, हमें कई सौ सर्वर मिले, लेकिन आर्किटेक्चर नहीं बदला। वे सर्वर भी थे, लेकिन अब वर्चुअल, स्थानीय डिस्क के साथ, जिस पर गेम वितरण होता है। हालाँकि, सौ सर्वर पर मैन्युअल रूप से अपडेट करना विफल हो जाएगा।
हम इसका हल ढूंढने लगे। सबसे पहले हमने
rsync के माध्यम से अपडेट करने का प्रयास किया। लेकिन यह पता चला कि यह बेहद धीमा है, और मुख्य नोड पर लोड बहुत अधिक है। लेकिन यह भी सबसे खराब नहीं है: जब हमारे पास ऑनलाइन कम था, तो हमने कुछ आभासी मशीनों को बंद कर दिया ताकि उनके लिए भुगतान न हो, और जब अपडेट करते हैं, तो डेटा को बंद सर्वर पर नहीं डाला गया था। वे सभी अपडेट के बिना छोड़ दिए गए थे।
समाधान
टॉरेंट था -
BTSync प्रोग्राम। यह आपको केंद्रीय नोड को स्पष्ट रूप से निर्दिष्ट किए बिना बड़ी संख्या में नोड पर एक फ़ोल्डर को सिंक्रनाइज़ करने की अनुमति देता है।
विकास की समस्याएं
कुछ समय के लिए, यह सब आश्चर्यजनक रूप से काम किया। लेकिन सेवा विकसित हो रही थी, अधिक गेम और सर्वर थे। स्थानीय भंडारण की संख्या भी बढ़ गई, हमें अधिक से अधिक भुगतान करना पड़ा। बादलों में यह महंगा है, खासकर एसएसडी के लिए। एक बिंदु पर, अपने सिंक्रनाइज़ेशन को शुरू करने के लिए एक फ़ोल्डर का सामान्य अनुक्रमण भी एक घंटे से अधिक समय लेने लगा, और सभी सर्वरों को कई दिनों तक अद्यतन किया जा सकता है।
BTSync ने अत्यधिक नेटवर्क ट्रैफ़िक के साथ एक और समस्या पैदा की है। उस समय, अमेज़ॅन में इसे आंतरिक वर्चुअल के बीच भी भुगतान किया गया था। यदि क्लासिक गेम लांचर बड़ी फ़ाइलों में छोटे बदलाव करता है, तो BTSync तुरंत मानता है कि पूरी फ़ाइल बदल गई है, और इसे पूरी तरह से सभी नोड्स में स्थानांतरित करना शुरू कर देता है। नतीजतन, यहां तक कि 15 एमबी का अपग्रेड भी दसियों जीबी का सिंक्रोनाइज़ेशन ट्रैफिक उत्पन्न कर सकता है।
स्थिति तब गंभीर हो गई जब भंडारण 1 टीबी तक बढ़ गया। बस युद्धपोतों का एक नया गेम वर्ल्ड जारी किया। उसके वितरण में कई सौ छोटी फाइलें थीं। BTSync इसे पचा नहीं सका और इसे अन्य सभी सर्वरों में वितरित कर दिया - इससे अन्य खेलों का वितरण धीमा हो गया।
इन सभी कारकों ने दो समस्याएं पैदा कीं:
- स्थानीय भंडारण महंगा, असुविधाजनक और अद्यतन करने में मुश्किल है;
- बादल बहुत महंगे थे।
हमने अपने भौतिक सर्वर की अवधारणा पर वापस जाने का फैसला किया।
खुद की भंडारण प्रणाली
भौतिक सर्वर पर जाने से पहले, हमें स्थानीय भंडारण से छुटकारा पाने की आवश्यकता है। इसके लिए अपनी
भंडारण प्रणाली - भंडारण की आवश्यकता होती है। यह एक प्रणाली है जो सभी वितरणों को संग्रहीत करती है और उन्हें सभी सर्वरों के लिए केंद्रीय रूप से वितरित करती है।
ऐसा लगता है कि कार्य सरल है - यह पहले से ही बार-बार हल हो गया है। लेकिन खेलों के साथ बारीकियां हैं। उदाहरण के लिए, अधिकांश गेम केवल काम करने से इनकार करते हैं यदि उन्हें केवल-पढ़ने के लिए एक्सेस दिया जाता है। यहां तक कि सामान्य नियमित स्टार्ट-अप के साथ, वे अपनी फ़ाइलों के लिए कुछ लिखना पसंद करते हैं, और इसके बिना वे काम करने से इनकार करते हैं। इसके विपरीत, यदि बड़ी संख्या में उपयोगकर्ताओं को वितरण के एक सेट तक पहुंच दी जाती है, तो वे प्रतिस्पर्धी पहुंच के साथ एक-दूसरे की फ़ाइलों को पीटना शुरू कर देते हैं।
हमने इस समस्या के बारे में सोचा, कई संभावित समाधानों की जाँच की, और
FreeFSD पर
ZFS - Zettabyte File System आया।
FreeBSD पर ZFS
यह एक साधारण फाइल सिस्टम नहीं है। शास्त्रीय प्रणालियों को शुरू में एक डिवाइस पर स्थापित किया जाता है, और कई डिस्क के साथ काम करने के लिए पहले से ही वॉल्यूम प्रबंधक की आवश्यकता होती है।
ZFS मूल रूप से वर्चुअल पूल पर बनाया गया था।
उन्हें
zpool कहा जाता है और डिस्क समूह या RAID सरणियों से मिलकर बनता है। इन डिस्क की पूरी मात्रा किसी भी फाइल सिस्टम के लिए ज़ूल के भीतर उपलब्ध है। ऐसा इसलिए है क्योंकि जेडएफएस मूल रूप से एक प्रणाली के रूप में विकसित किया गया था जो बड़ी मात्रा में डेटा के साथ काम करेगा।
कैसे ZFS ने हमारी समस्याओं को हल करने में मदद की
इस प्रणाली में
स्नैपशॉट और क्लोन बनाने के लिए एक अद्भुत
तंत्र है । वे
तुरन्त बनाए
जाते हैं , और केवल कुछ KB का वजन करते हैं। जब हम किसी एक क्लोन में परिवर्तन करते हैं, तो यह इन परिवर्तनों की मात्रा से बढ़ जाता है। इसी समय, शेष क्लोनों में डेटा नहीं बदलता है और अद्वितीय रहता है। यह आपको केवल कुछ KB खर्च करते हुए, अंतिम उपयोगकर्ता के लिए अनन्य पहुँच के साथ
10 टीबी डिस्क वितरित करने की अनुमति देता है।
यदि किसी खेल सत्र में परिवर्तन करने की प्रक्रिया में क्लोन बढ़ते हैं, तो क्या वे सभी खेलों के लिए उतनी जगह नहीं लेंगे? नहीं, हमने पाया कि काफी लंबे खेल सत्रों में भी, परिवर्तन का सेट शायद ही कभी 100-200 एमबी से अधिक हो - यह महत्वपूर्ण नहीं है। इसलिए, हम एक ही समय में कई सौ उपयोगकर्ताओं के लिए एक पूर्ण उच्च क्षमता वाले हार्ड ड्राइव तक पूर्ण पहुंच दे सकते हैं, केवल एक पूंछ के साथ 10 टीबी खर्च कर सकते हैं।
कैसे काम करता है ZFS
विवरण जटिल लगता है, लेकिन ZFS काफी सरलता से काम करता है। आइए एक सरल उदाहरण के साथ इसके काम का विश्लेषण करें - उपलब्ध
zpool create data /dev/da /dev/db /dev/dc डिस्क से
zpool create data /dev/da /dev/db /dev/dc ।
नोट। उत्पादन के लिए यह आवश्यक नहीं है, क्योंकि यदि कम से कम एक डिस्क मर जाती है, तो पूरा पूल इसके साथ विस्मरण में चला जाएगा। RAID समूहों का बेहतर उपयोग करें।हम
zfs create data/games फाइल सिस्टम
zfs create data/games , और इसमें 10 टीबी के
data/games/disk के नाम के साथ एक ब्लॉक डिवाइस होता है। डिवाइस एक नियमित डिस्क के रूप में
/dev/zvol/data/games/disk पर उपलब्ध है - आप इसके साथ एक ही जोड़ तोड़ कर सकते हैं।
फिर मस्ती शुरू होती है। हम इस डिस्क को
iSCSI के माध्यम
से अपने अपडेट विजार्ड को देते हैं - विंडोज चलाने वाली एक नियमित वर्चुअल मशीन। हम डिस्क कनेक्ट करते हैं, और नियमित रूप से घर के कंप्यूटर पर स्टीम से गेम को उस पर डालते हैं।
गेम के साथ डिस्क भरें। अब यह अंत उपयोगकर्ताओं के लिए
200 सर्वरों को इस डेटा को वितरित करने के लिए बना हुआ है।
- इस डिस्क का स्नैपशॉट बनाएं और इसे पहला संस्करण कहें -
zfs snapshot data/games/disk@ver1 । इसके क्लोन zfs clone data/games/disk@ver1 data/games/disk-vm1 , जो पहली वर्चुअल मशीन पर जाएगा। - हम iSCSI के माध्यम से क्लोन देते हैं और KVM इस डिस्क के साथ एक वर्चुअल मशीन लॉन्च करता है । यह लोड होता है, उपयोगकर्ताओं के लिए सुलभ सर्वरों के एक पूल में जाता है, और एक खिलाड़ी की उम्मीद करता है।
- जब उपयोगकर्ता सत्र पूरा हो जाता है, तो हम सभी उपयोगकर्ता को इस वर्चुअल मशीन से सहेजते हैं और उन्हें एक अलग सर्वर पर डालते हैं । हम वर्चुअल मशीन को बंद कर देते हैं और क्लोन को नष्ट कर देते हैं -
zfs destroy data/games/disk-vm1 । - हम पहले चरण पर लौटते हैं, फिर से एक क्लोन बनाते हैं और वर्चुअल मशीन शुरू करते हैं।
यह हमें प्रत्येक अगले उपयोगकर्ता को
हमेशा एक
स्वच्छ मशीन प्रदान करने की अनुमति देता है, जिस पर पिछले खिलाड़ी से कोई बदलाव नहीं होता है। प्रत्येक उपयोगकर्ता सत्र के बाद डिस्क को हटा दिया जाता है, और भंडारण प्रणाली पर कब्जा कर लिया गया स्थान मुक्त हो जाता है। हम सिस्टम डिस्क के साथ और हमारे सभी आभासी मशीनों के साथ समान संचालन करते हैं।
हाल ही में, मैं YouTube पर एक वीडियो भर आया, जहाँ गेम सत्र के दौरान एक संतुष्ट उपयोगकर्ता ने सर्वर पर हमारी हार्ड ड्राइव को स्वरूपित किया, और बहुत खुशी हुई कि उसने सब कुछ तोड़ दिया है। हाँ, कृपया, बस भुगतान करने के लिए - वह खेल सकता है और लिप्त हो सकता है। किसी भी मामले में, अगले उपयोगकर्ता को हमेशा एक स्वच्छ, कार्यात्मक आभासी मशीन मिलेगी, इससे कोई फर्क नहीं पड़ता कि पिछले एक क्या करता है।
इस योजना के अनुसार, खेल केवल 200 सर्वरों को वितरित किए जाते हैं। हमने 200 नंबर की प्रायोगिक रूप से गणना की: यह उन सर्वरों की संख्या है, जिन पर स्टोरेज ड्राइव पर क्रिटिकल लोड नहीं होता है। इसका कारण यह है कि
खेलों में एक विशिष्ट लोड प्रोफ़ाइल होती है : वे लॉन्च चरण या स्तर लोडिंग चरण में बहुत कुछ पढ़ते हैं, और खेल के दौरान, इसके विपरीत, व्यावहारिक रूप से डिस्क का उपयोग नहीं करते हैं। यदि आपकी लोड प्रोफ़ाइल अलग है, तो आंकड़ा अलग होगा।
पुरानी योजना में, 200 उपयोगकर्ताओं की एक साथ सर्विसिंग के लिए, हमें 2,000 टीबी के स्थानीय भंडारण की आवश्यकता होगी। अब हम मुख्य डेटा सेट के लिए 10 से अधिक टीबी खर्च कर सकते हैं, और उपयोगकर्ता परिवर्तनों के लिए स्टॉक में अभी भी 0.5 टीबी है। हालाँकि ZFS को पसंद है जब उसके पूल में कम से कम 15% खाली जगह होती है, तो मुझे लगता है कि हमने काफी बचत की है।
यदि हमारे पास कई डेटा केंद्र हैं तो क्या होगा?
यह तंत्र केवल एक डेटा सेंटर के अंदर काम करेगा, जहां स्टोरेज सिस्टम वाले सर्वर कम से कम 10 गीगाबिट इंटरफेस से जुड़े होते हैं। यदि कई डीसी हैं तो क्या करें? उनके बीच गेम (डेटासेट) के साथ मुख्य डिस्क को कैसे अपडेट करें?
इसके लिए, ZFS का अपना समाधान है -
भेजें / प्राप्त तंत्र । निष्पादन कमांड बहुत सरल है:
zfs send -v data/games/disk@ver1 | ssh myzfsuser@myserverip zfs receive data/games/disk
तंत्र आपको एक भंडारण प्रणाली से दूसरे स्नैपशॉट को मुख्य प्रणाली से स्थानांतरित करने की अनुमति देता है। पहली बार, आपको खाली स्टोरेज सिस्टम में सभी 10 टीबी डेटा भेजना होगा जो मास्टर नोड पर दर्ज है। लेकिन अगले अपडेट के साथ, हम केवल उसी पल से बदलाव भेजेंगे जब हमने पिछले स्नैपशॉट बनाया था।
नतीजतन, हम प्राप्त करते हैं:
- सभी परिवर्तन एक भंडारण प्रणाली पर केन्द्रित किए जाते हैं । फिर वे किसी भी मात्रा में अन्य सभी डेटा केंद्रों को फैलाते हैं, और सभी नोड्स पर डेटा हमेशा समान होता है।
- भेजें / प्राप्त तंत्र एक वियोग से डरता नहीं है । डेटा मुख्य डेटासेट पर तब तक लागू नहीं किया जाता है जब तक कि यह पूरी तरह से दास नोड को प्रेषित न हो। यदि कनेक्शन खो गया है, तो डेटा को नुकसान पहुंचाना असंभव है, और बस भेजने की प्रक्रिया को दोहराएं।
- कोई भी नोड आसानी से कुछ ही मिनटों में एक दुर्घटना के दौरान मास्टर नोड बन सकता है , क्योंकि सभी नोड्स पर डेटा हमेशा समान होता है।
Deduplication और बैकअप
ZFS की एक और उपयोगी विशेषता है -
समर्पण । यह फ़ंक्शन
दो समान डेटा ब्लॉक को संग्रहीत नहीं करने में मदद करता है। इसके बजाय, केवल पहला ब्लॉक संग्रहीत किया जाता है, और दूसरे के स्थान पर, पहले के लिए एक लिंक संग्रहीत किया जाता है। दो समान फाइलें एक के रूप में जगह ले लेंगी, और यदि वे 90% से मेल खाते हैं, तो वे मूल मात्रा का 110% भरेंगे।
उपयोगकर्ता को सहेजने में फ़ंक्शन ने हमें बहुत मदद की। एक गेम में, विभिन्न उपयोगकर्ताओं के समान बचत होती है, कई फाइलें समान होती हैं। डिडुप्लीकेशन के उपयोग के माध्यम से हम पांच गुना ज्यादा डाटा स्टोर कर सकते हैं। हमारा कटौती अनुपात 5.22 है। शारीरिक रूप से, हमारे पास 4.43 टेराबाइट हैं, हम एक कारक से गुणा करते हैं, और हमें वास्तविक डेटा के लगभग 23 टेराबाइट मिलते हैं। यह डुप्लिकेट स्टोरेज से बचकर स्पेस बचाता है।
स्नैपशॉट बैकअप के लिए अच्छे हैं । हम इस तकनीक का उपयोग अपने फाइल स्टोरेज पर करते हैं। उदाहरण के लिए, यदि आप एक महीने के लिए हर दिन एक तस्वीर बचाते हैं, तो आप उस महीने के किसी भी दिन किसी भी समय एक क्लोन को तैनात कर सकते हैं और खोई या क्षतिग्रस्त फ़ाइलों को बाहर निकाल सकते हैं। यह पूरे भंडारण को वापस रोल करने या इसकी एक पूरी प्रति तैनात करने की आवश्यकता को समाप्त करता है।
हम अपने डेवलपर्स की सहायता के लिए क्लोन का उपयोग करते हैं । उदाहरण के लिए, वे लड़ाकू बेस पर संभावित खतरनाक प्रवास का अनुभव करना चाहते हैं। यह 1 टीबी के पास आने वाले डेटाबेस का क्लासिक बैकअप तैनात करने के लिए तेज़ नहीं है। इसलिए, हम बस आधार डिस्क से क्लोन को हटाते हैं और इसे तुरंत नए उदाहरण में जोड़ते हैं। अब डेवलपर्स सुरक्षित रूप से वहां सब कुछ परीक्षण कर सकते हैं।
ZFS एपीआई
बेशक, यह सब स्वचालित होना चाहिए। सर्वर पर क्यों चढ़ें, अपने हाथों से काम करें, स्क्रिप्ट लिखें, अगर यह प्रोग्रामर को दिया जा सकता है? इसलिए, हमने अपना सरल
वेब एपीआई लिखा।
हमने इसमें सभी मानक ZFS फ़ंक्शन लपेटे हैं, उन तक पहुंच को काट दिया जो संभावित खतरनाक हैं और पूरे स्टोरेज सिस्टम को तोड़ सकते हैं, और प्रोग्रामरों को यह सब दिया। अब
सभी डिस्क परिचालनों को कड़ाई से केंद्रीकृत और कोड द्वारा निष्पादित किया जाता है, और हम
हमेशा प्रत्येक डिस्क की स्थिति जानते हैं । सब कुछ बढ़िया काम करता है।
ZoL - लिनक्स पर ZFS
हमने सिस्टम को केंद्रीकृत किया और सोचा, क्या यह इतना अच्छा है? दरअसल, अब किसी भी विस्तार के लिए, हमें तुरंत कई सर्वर रैक खरीदने की आवश्यकता है: वे भंडारण प्रणालियों से बंधे हैं, और यह सिस्टम को विभाजित करने के लिए तर्कहीन है। जब हम दूसरे देशों में भागीदारों को प्रौद्योगिकी दिखाने के लिए एक छोटे डेमो स्टैंड को तैनात करने का निर्णय लेते हैं तो क्या करें?
सोचकर, हम पुराने विचार पर आए -
स्थानीय ड्राइव का
उपयोग करने के
लिए , लेकिन केवल उस सभी अनुभव और ज्ञान के साथ जो हमें प्राप्त हुआ था। यदि आप विश्व स्तर पर विचार का विस्तार करते हैं, तो हमारे उपयोगकर्ताओं को न केवल हमारे सर्वर का उपयोग करने का अवसर दें, बल्कि अपने कंप्यूटर को किराए पर भी दें?
लिनक्स पर ZFS का अपेक्षाकृत हालिया कांटा
- ZoL ने इसमें हमारी बहुत मदद की।
अब प्रत्येक सर्वर का अपना भंडारण है।
केवल यह 10 टेराबाइट्स डेटा को संग्रहीत नहीं करता है, जैसा कि एक केंद्रीकृत स्थापना के मामले में है, लेकिन जो गेम खेलता है उसके केवल 1-2 वितरण। एक एसएसडी इसके लिए पर्याप्त है। यह सब ठीक काम करता है: हर अगले उपयोगकर्ता को हमेशा एक साफ वर्चुअल मशीन मिलती है, साथ ही एक कॉम्बैट इंस्टॉलेशन भी।
हालाँकि, यहाँ हमें दो समस्याओं का सामना करना पड़ा।
कैसे अपडेट करें?
SSH के माध्यम से केंद्रीय रूप से अपडेट करें, जैसा कि हम डेटा केंद्रों में करते हैं, काम नहीं करेगा । उपयोगकर्ताओं को स्टोरेज सिस्टम के विपरीत, स्थानीय नेटवर्क से जोड़ा जा सकता है या बस बंद किया जा सकता है, और आप इतने सारे एसएसएच कनेक्शन नहीं उठाना चाहते।
हमें rsync का उपयोग करते समय समान समस्याओं का सामना करना पड़ा। हालाँकि, ZFS के शीर्ष पर मौजूद धार अब प्राप्त नहीं की जा सकती हैं। हम ध्यान से इस बारे में सोचते हैं कि कैसे भेजें तंत्र काम करता है: यह सभी परिवर्तित डेटा ब्लॉकों को अंतिम भंडारण में भेजता है, जहां प्राप्तकर्ता उन्हें वर्तमान डेटासेट पर लागू करता है। अंत उपयोगकर्ता को भेजने के बजाय, किसी फ़ाइल को डेटा क्यों नहीं लिखा जाता है?
परिणाम यह है कि जिसे हम कहते हैं वह
भिन्न है । यह एक फाइल है जिसमें पिछले दो स्नैपशॉट के बीच सभी परिवर्तित ब्लॉक क्रमिक रूप से लिखे गए हैं। हमने इस अंतर को एक सीडीएन पर डाल दिया, और इसे अपने सभी उपयोगकर्ताओं को HTTP के माध्यम से भेजें: यह मशीन को चालू कर दिया, यह देखा कि रिसीव का उपयोग करके अद्यतन, अपस्फीति और स्थानीय डेटासेट में इसे लागू किया गया था।
ड्राइवरों के साथ क्या करना है?
केंद्रीकृत सर्वर में समान कॉन्फ़िगरेशन होता है, और
अंतिम उपयोगकर्ताओं के पास हमेशा अलग-अलग कंप्यूटर और वीडियो कार्ड होते हैं । यहां तक कि अगर हम यथासंभव सभी संभव ड्राइवरों के साथ ओएस वितरण को भरते हैं, तो पहली बार शुरू होने पर, यह अभी भी इन ड्राइवरों को स्थापित करना चाहेगा, फिर इसे फिर से शुरू करेगा, और फिर, संभवतः, फिर से। चूंकि हर बार हम एक साफ क्लोन प्रदान करते हैं, तो यह सभी हिंडोला प्रत्येक उपयोगकर्ता सत्र के बाद होगा - यह खराब है।
हम कुछ इनिशियलाइज़ेशन रन करना चाहते थे: विंडोज बूट होने तक प्रतीक्षा करें, सभी ड्राइवरों को इंस्टॉल करें, वह सब कुछ करें जो वह चाहता है, और उसके बाद ही इस ड्राइव पर काम करें। लेकिन समस्या यह है कि यदि आप मुख्य डेटासेट में परिवर्तन करते हैं, तो अपडेट टूट जाएंगे, क्योंकि स्रोत और रिसीवर पर डेटा अलग-अलग होंगे, और अलग-अलग बस लागू नहीं होंगे।
हालांकि, ZFS एक लचीली प्रणाली है और हमें एक छोटी बैसाखी बनाने की अनुमति देता है।
- हमेशा की तरह, एक स्नैपशॉट बनाएँ:
zfs snapshot data/games/os@init । - इसके क्लोन -
zfs clone data/games/os@init data/games/os-init बनाएँ - और इसे आरंभिक मोड में चलाएं। - हम सभी ड्राइवरों को स्थापित करने के लिए इंतजार कर रहे हैं और सब कुछ रिबूट होगा।
- वर्चुअल मशीन को बंद करें और फिर से स्नैपशॉट लें। लेकिन इस बार, मूल डेटासेट से नहीं, बल्कि इनिशियलाइज़ेशन क्लोन से:
zfs snapshot data/games/os-init@ver1 । - हम सभी स्थापित ड्राइवरों के साथ स्नैपशॉट का एक क्लोन बनाते हैं। यह अब रिबूट नहीं होगा:
zfs clone data/games/os-init@ver1 data/games/os-vm1 । - फिर हम क्लासिक गुच्छा पर काम करते हैं।
अब यह सिस्टम अल्फा टेस्टिंग स्टेज पर है। हम लिनक्स के ज्ञान के बिना वास्तविक उपयोगकर्ताओं पर इसका परीक्षण करते हैं, लेकिन वे इसे पूरे घर में तैनात करने का प्रबंधन करते हैं। हमारा अंतिम लक्ष्य किसी भी उपयोगकर्ता के लिए बस एक बूट करने योग्य USB फ्लैश ड्राइव को अपने कंप्यूटर में प्लग करना है, एक अतिरिक्त SSD ड्राइव कनेक्ट करना और इसे हमारे क्लाउड प्लेटफ़ॉर्म पर किराए पर देना है।
हमने ZFS कार्यक्षमता के केवल एक छोटे भाग पर चर्चा की। यह प्रणाली बहुत अधिक रोचक और विभिन्न चीजें कर सकती है, लेकिन ZFS के बारे में बहुत कम लोग जानते हैं - उपयोगकर्ता इसके बारे में बात नहीं करना चाहते हैं। मुझे उम्मीद है कि इस लेख के बाद नए उपयोगकर्ता ZFS- समुदाय में दिखाई देंगे।
DevOpsConf सम्मेलन से नए लेखों और वीडियो के बारे में जानने के लिए टेलीग्राम चैनल या न्यूज़लेटर की सदस्यता लें। समाचार पत्र के अलावा, हम आगामी सम्मेलनों से समाचार एकत्र करते हैं और बताते हैं, उदाहरण के लिए, सेंट हाईलाड ++ पर DevOps प्रशंसकों के लिए क्या दिलचस्प होगा।