कई बार, यह C ++ प्रोग्राम में प्रोग्राम के प्रदर्शन या मेमोरी की खपत को प्रोफाइल करने के लिए आवश्यक हो सकता है। दुर्भाग्य से, अक्सर यह उतना आसान नहीं होता है जितना यह लग सकता है।
यहाँ हम प्रोफाइलर प्रोग्राम की विशेषताओं पर विचार करेंगे
जिसमें वेलग्रिंड और
गूगल पेर्फटूल टूल्स का उपयोग किया जाएगा। यह सामग्री बहुत अधिक संरचित नहीं हुई, यह "व्यक्तिगत उद्देश्यों के लिए" एक ज्ञान आधार को इकट्ठा करने का एक प्रयास है, ताकि भविष्य में आपको यह याद रखने की आवश्यकता नहीं है कि "यह काम क्यों नहीं करता है" या "इसे कैसे करें"। सबसे अधिक संभावना है, सभी अस्पष्ट मामले यहां प्रभावित नहीं होंगे, अगर आपको कुछ जोड़ना है, तो कृपया टिप्पणियों में लिखें।
सभी उदाहरण लिनक्स सिस्टम पर चलेंगे।
रनटाइम प्रोफाइलिंग
ट्रेनिंग
प्रोफाइलिंग की विशेषताओं का विश्लेषण करने के लिए, मैं छोटे प्रोग्राम चलाऊंगा, जिसमें आमतौर पर एक main.cpp फ़ाइल और एक func.cpp फ़ाइल शामिल होती है।
मैं उन्हें
जी ++ 8.3.0 संकलक के साथ संकलित करूंगा।
चूँकि ग़ैर-अनुकूलित प्रोग्रामों की रूपरेखा बनाना एक अजीब काम है, इसलिए हम
-Oxt विकल्प का संकलन करेंगे, और आउटपुट में डिबग वर्ण प्राप्त करने के लिए, हम
-g विकल्प जोड़ना नहीं
भूलेंगे । हालांकि, कभी-कभी सामान्य फ़ंक्शन नामों के बजाय, आप केवल अप्राप्य कॉल पते देख सकते हैं। इसका मतलब है कि "पता स्थान आवंटन का यादृच्छिककरण" हुआ है। यह बाइनरी पर
एनएम कमांड को कॉल करके निर्धारित किया जा सकता है। यदि अधिकांश पते इस 00000000000030e0 (शुरुआत में बड़ी संख्या में शून्य) जैसे दिखते हैं, तो सबसे अधिक संभावना यही है। एक सामान्य कार्यक्रम में, पते 0000000000402fa0 की तरह दिखते हैं। इसलिए, आपको
-no-pie विकल्प जोड़ने की आवश्यकता है। परिणामस्वरूप, विकल्पों का पूरा सेट इस तरह दिखेगा:
-अगस्त -ग -नो-पाईपरिणामों को देखने के लिए, हम
KCachegrind प्रोग्राम का उपयोग करेंगे, जो
कॉलग्रिंड रिपोर्ट
प्रारूप के साथ काम कर सकता है
Callgrind
आज हम जिस पहली उपयोगिता को देखेंगे वह
कॉलग्रिंड है । यह उपयोगिता वेलग्रिंड टूल का हिस्सा है। यह कार्यक्रम के प्रत्येक निष्पादन योग्य निर्देश का अनुकरण करता है और, प्रत्येक निर्देश की "लागत" के बारे में आंतरिक मैट्रिक्स के आधार पर, निष्कर्ष की आवश्यकता को जारी करता है। इस दृष्टिकोण के कारण, ऐसा कभी-कभी होता है कि कॉलग्रिंड अगले निर्देश को नहीं पहचान सकता है और एक त्रुटि के साथ बाहर आता है
पते पर अपरिचित निर्देशइस स्थिति से बाहर निकलने का एकमात्र तरीका सभी संकलन विकल्पों पर पुनर्विचार करना और हस्तक्षेप करने का प्रयास करना है
आइए इस टूल के परीक्षण के लिए एक प्रोग्राम बनाएं, जिसमें एक साझा लाइब्रेरी और एक स्टैटिक लाइब्रेरी है (बाद में अन्य टेस्ट में हम लाइब्रेरी को छोड़ देंगे)। प्रत्येक पुस्तकालय, साथ ही कार्यक्रम स्वयं, एक सरल कम्प्यूटेशनल फ़ंक्शन प्रदान करेगा, उदाहरण के लिए, फाइबोनैचि अनुक्रम की गणना।
हम इस कार्यक्रम को संकलित करते हैं, और निम्नानुसार वेलग्रिंड चलाते हैं:
valgrind --tool=callgrind ./test_profiler 100000000
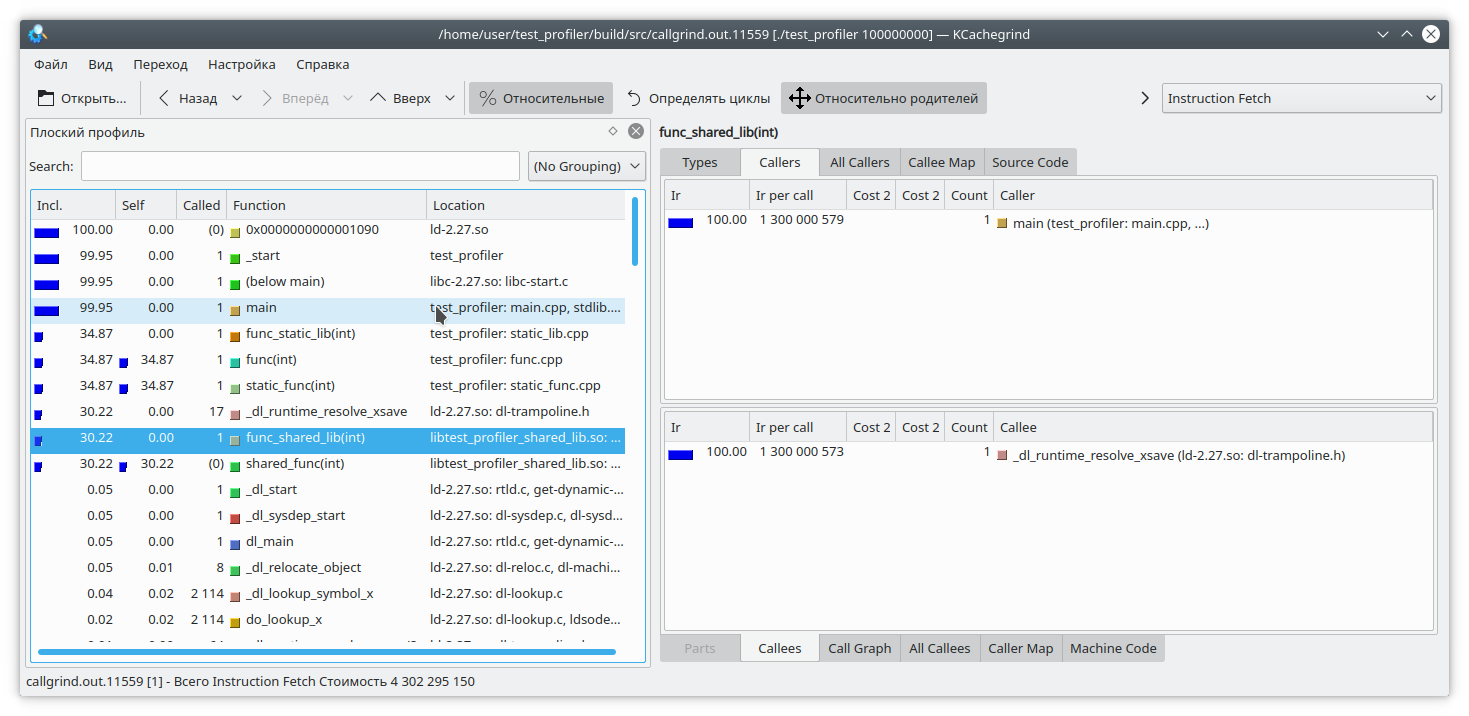
हम देखते हैं कि एक स्थिर पुस्तकालय और एक नियमित कार्य के लिए, परिणाम अपेक्षित के समान है। लेकिन गतिशील पुस्तकालय में, कॉलग्रिंड फ़ंक्शन को पूरी तरह से हल नहीं कर सका।
इसे ठीक करने के लिए, प्रोग्राम शुरू करते समय, आपको
LD_BIND_NOW चर को 1 पर सेट करना
होगा , इस तरह:
LD_BIND_NOW=1 valgrind --tool=callgrind ./test_profiler 100000000
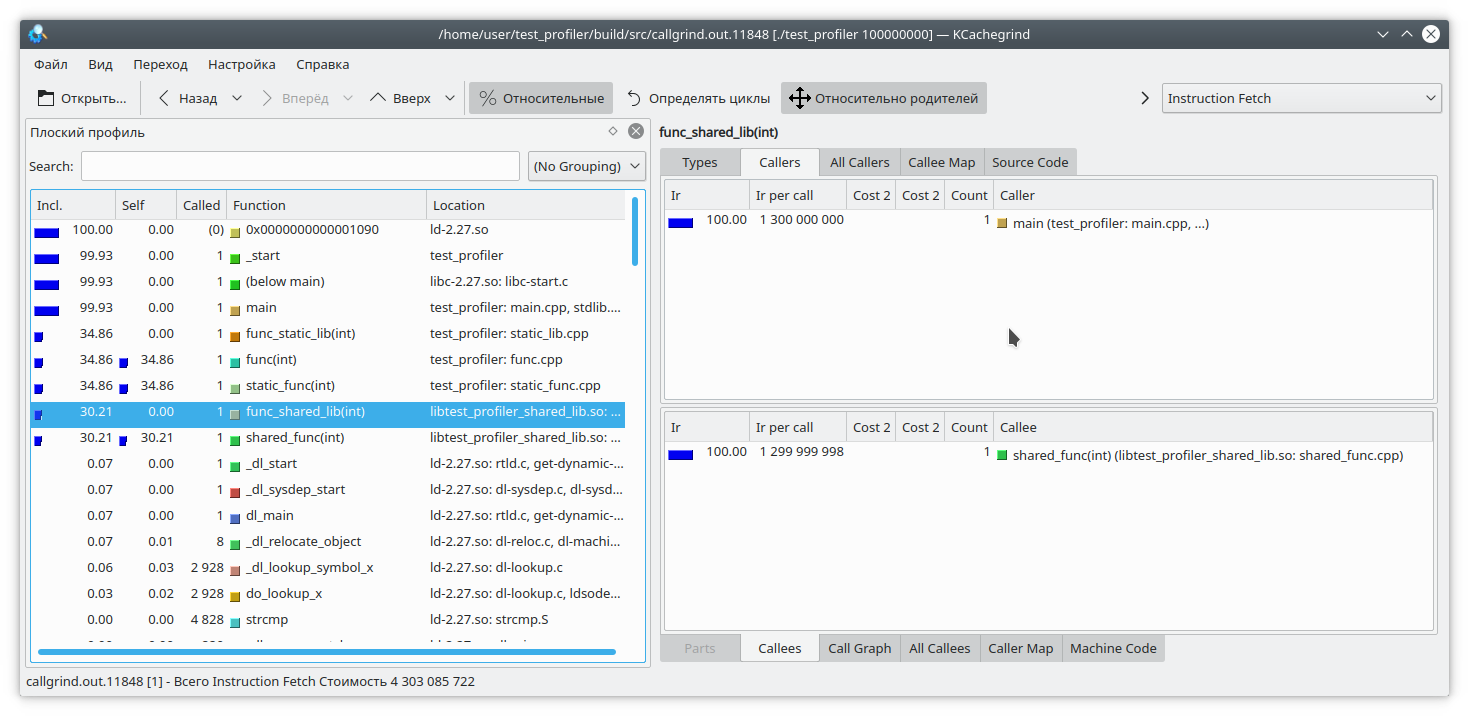
और अब, जैसा कि आप देख सकते हैं, सब कुछ ठीक है
निर्देश का अनुकरण करके प्रोफाइलिंग से उत्पन्न होने वाली अगली कॉलग्रिंड समस्या यह है कि प्रोग्राम निष्पादन बहुत धीमा हो जाता है। यह कोड के विभिन्न भागों के निष्पादन समय का गलत सापेक्ष अनुमान लगा सकता है।
आइए इस कोड को देखें:
int func(int arg) { int fst = 1; int snd = 1; std::ofstream file("tmp.txt"); for (int i = 0; i < arg; i++) { int res = (fst + snd + 1) % 19845689; std::string r = std::to_string(res); file << res; file.flush(); fst = snd; snd = res + r.size(); } return fst; }
यहां, मैंने लूप के प्रत्येक पुनरावृत्ति के लिए एक फ़ाइल में एक छोटी मात्रा में डेटा जोड़ा। चूँकि फ़ाइल लिखना एक लंबा ऑपरेशन है, एक काउंटरवेट के रूप में, मैंने एक संख्या से लूप के प्रत्येक पुनरावृत्ति में एक लाइन पीढ़ी को जोड़ा। जाहिर है, इस मामले में, फ़ाइल का लेखन संचालन फ़ंक्शन के बाकी तर्क की तुलना में अधिक समय लेता है। लेकिन कॉलगर्ल अलग तरह से सोचती है:
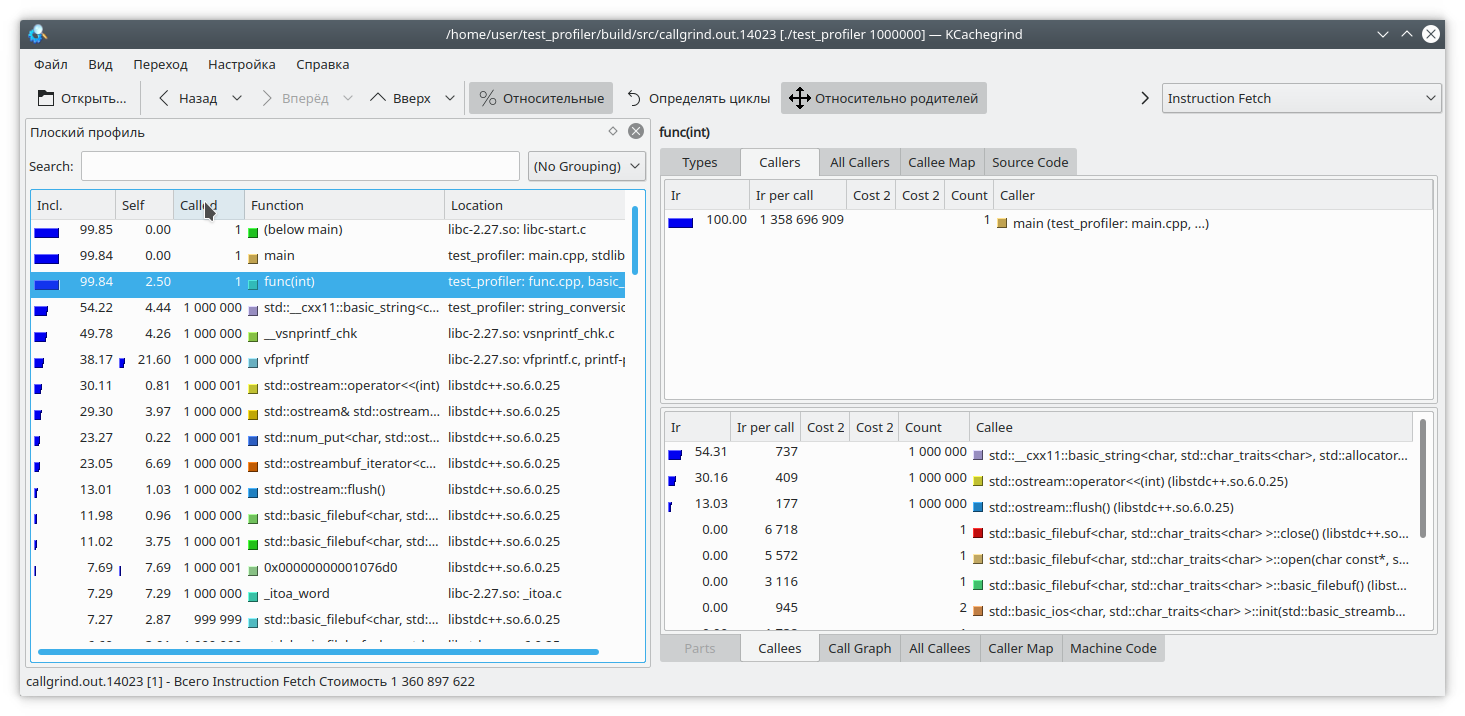
यह भी विचार करने योग्य है कि कॉलग्रिंड केवल एक फ़ंक्शन की लागत को माप सकता है जब यह काम करता है। फ़ंक्शन काम नहीं करता है - इसलिए, लागत में वृद्धि नहीं होती है। यह उन प्रोग्रामों के डिबगिंग को जटिल बनाता है जो समय-समय पर लॉक में प्रवेश करते हैं या अवरुद्ध फाइल सिस्टम / नेटवर्क के साथ काम करते हैं। आइए देखें:
#include "func.h" #include <mutex> static std::mutex mutex; int funcImpl(int arg) { std::lock_guard<std::mutex> lock(mutex); int fst = 1; int snd = 1; for (int i = 0; i < arg; i++) { int res = (fst + snd + 1) % 19845689; fst = snd; snd = res; } return fst; } int func2(int arg){ return funcImpl(arg); } int func(int arg) { return funcImpl(arg); } int main(int argc, char **argv) { if (argc != 2) { std::cout << "Incorrect args"; return -1; } const int arg = std::atoi(argv[1]); auto future = std::async(std::launch::async, &func2, arg); std::cout << "result: " << func(arg) << std::endl; std::cout << "second result " << future.get() << std::endl; return 0; }
यहां हमने म्यूटेक्स के लॉक में पूरे फ़ंक्शन निष्पादन को संलग्न किया है, और इस फ़ंक्शन को दो अलग-अलग थ्रेड्स से बुलाया है। कॉलग्रिंड का परिणाम काफी अनुमानित है - उसे म्यूटेक्स कैप्चर करने में कोई समस्या नहीं दिखती है:
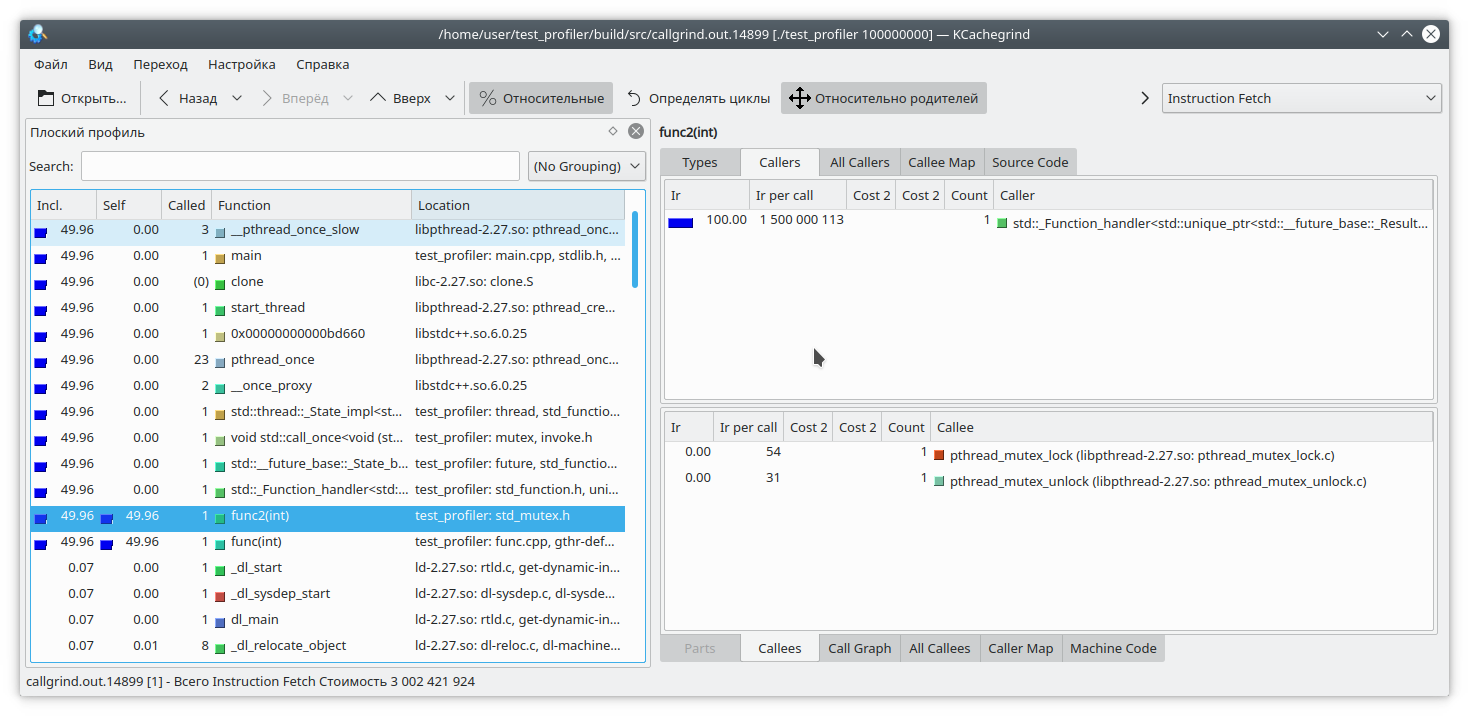
इसलिए, हमने कॉलग्रिंड प्रोफाइलर के उपयोग की कुछ समस्याओं की जांच की। चलिए अगले परीक्षण विषय पर चलते हैं - google perftools profiler
गूगल perftools
कॉलग्रिंड के विपरीत, Google प्रोफाइलर एक अलग सिद्धांत पर काम करता है।
निष्पादन योग्य कार्यक्रम के प्रत्येक निर्देश का विश्लेषण करने के बजाय, यह नियमित अंतराल पर कार्यक्रम को रोक देता है और यह निर्धारित करने की कोशिश करता है कि यह वर्तमान में किस फ़ंक्शन में है। नतीजतन, यह लगभग रनिंग एप्लिकेशन के प्रदर्शन को प्रभावित नहीं करता है। लेकिन इस दृष्टिकोण की अपनी कमजोरियां भी हैं।
चलो दो पुस्तकालयों के साथ पहले कार्यक्रम की रूपरेखा तैयार करते हैं।
एक नियम के रूप में, इस उपयोगिता के साथ प्रोफाइलिंग शुरू करने के लिए, आपको libprofiler.so लाइब्रेरी को प्रीलोड करना होगा, सैंपलिंग फ़्रीक्वेंसी सेट करना होगा और डंप को बचाने के लिए फ़ाइल निर्दिष्ट करना होगा। दुर्भाग्य से, प्रोफाइलर को कार्यक्रम को "अपने दम पर" समाप्त करने की आवश्यकता होती है। कार्यक्रम की जबरन समाप्ति के कारण रिपोर्ट को केवल डंप नहीं किया जाएगा। यह असुविधाजनक है जब लंबे समय तक रहने वाले कार्यक्रमों की रूपरेखा तैयार की जाती है जो खुद को रोक नहींते हैं, जैसे डेमॉन। इस बाधा को दूर करने के लिए, मैंने यह स्क्रिप्ट बनाई:
gprof.sh rnd=$RANDOM if [ $# -eq 0 ] then echo "./gprof.sh command args" echo "Run with variable N_STOP=true if hand stop required" exit fi libprofiler=$( dirname "${BASH_SOURCE[0]}" ) arg=$1 nostop=$N_STOP profileName=callgrind.out.$rnd.g gperftoolProfile=./gperftool."$rnd".txt touch $profileName echo "Profile name $profileName" if [[ $nostop = "true" ]] then echo "without stop" trap 'echo trap && kill -12 $PID && sleep 1 && kill -TERM $PID' TERM INT else trap 'echo trap && kill -TERM $PID' TERM INT fi if [[ $nostop = "true" ]] then CPUPROFILESIGNAL=12 CPUPROFILE_FREQUENCY=1000000 CPUPROFILE=$gperftoolProfile LD_PRELOAD=${libprofiler}/libprofiler.so "${@:1}" & else CPUPROFILE_FREQUENCY=1000000 CPUPROFILE=$gperftoolProfile LD_PRELOAD=${libprofiler}/libprofiler.so "${@:1}" & fi PID=$! if [[ $nostop = "true" ]] then sleep 1 kill -12 $PID fi wait $PID trap - TERM INT wait $PID EXIT_STATUS=$? echo $PWD ${libprofiler}/pprof --callgrind $arg $gperftoolProfile* > $profileName echo "Profile name $profileName" rm -f $gperftoolProfile*
इस उपयोगिता को चलाने की जरूरत है, निष्पादन योग्य फ़ाइल के नाम और इसके मापदंडों की सूची के रूप में गुजरती है। इसके अलावा, यह माना जाता है कि स्क्रिप्ट के बगल में वह फाइलें हैं जिनकी उसे libprofiler.so और pprof की आवश्यकता है। यदि प्रोग्राम लंबे समय तक जीवित रहता है और निष्पादन को बाधित करके रुक जाता है, तो आपको N_STOP चर को सही पर सेट करना होगा, उदाहरण के लिए, जैसे:
N_STOP=true ./gprof.sh ./test_profiler 10000000000
काम के अंत में, स्क्रिप्ट मेरे पसंदीदा कॉलग्रिंड प्रारूप में एक रिपोर्ट उत्पन्न करेगी।
तो, चलिए इस प्रोफाइलर के तहत अपना प्रोग्राम चलाते हैं।
./gprof.sh ./test_profiler 1000000000

सिद्धांत रूप में, सब कुछ बहुत स्पष्ट है।
जैसा कि मैंने कहा, Google प्रोफाइलर प्रोग्राम के निष्पादन को रोककर और वर्तमान फ़ंक्शन की गणना करके काम करता है। वह ऐसा कैसे करता है? वह स्टैक को कताई करके ऐसा करता है। लेकिन क्या होगा अगर, स्टैक प्रमोशन के समय, प्रोग्राम खुद स्टैक को अनचेक कर दे? खैर, जाहिर है, कुछ भी अच्छा नहीं होगा। आइए इसे देखें। आइए लिखते हैं ऐसे समारोह:
int runExcept(int res) { if (res % 13 == 0) { throw std::string("Exception"); } return res; } int func(int arg) { int fst = 1; int snd = 1; for (int i = 0; i < arg; i++) { int res = (fst + snd + 1) % 19845689; try { res = runExcept(res); } catch (const std::string &e) { res = res - 1; } fst = snd; snd = res; } return fst; }
और प्रोफाइलिंग चलाएं। कार्यक्रम बहुत जल्दी जमा देता है।
प्रोफाइलर ऑपरेशन की ख़ासियत से जुड़ी एक और समस्या है। मान लीजिए कि हम स्टैक को खोलना चाहते हैं, और अब हमें प्रोग्राम के विशिष्ट कार्यों के साथ पतों का मिलान करना होगा। यह बहुत अच्छा हो सकता है, क्योंकि C ++ में काफी बड़ी संख्या में फ़ंक्शन इनलाइन हैं। आइए इस तरह एक उदाहरण देखें:
#include "func.h" static int func1(int arg) { std::cout << 1 << std::endl; return func(arg); } static int func2(int arg) { std::cout << 2 << std::endl; return func(arg); } static int func3(int arg) { std::cout << 3 << std::endl; if (arg % 2 == 0) { return func2(arg); } else { return func1(arg); } } int main(int argc, char **argv) { if (argc != 2) { std::cout << "Incorrect args"; return -1; } const int arg = std::atoi(argv[1]); int arg2 = func3(arg); int arg3 = func(arg); std::cout << "result: " << arg2 + arg3; return 0; }
जाहिर है, यदि आप इस तरह से उदाहरण के लिए कार्यक्रम चलाते हैं:
./gprof.sh ./test_profiler 1000000000
तब फ़ंक्शन func1 को कभी नहीं बुलाया जाएगा। लेकिन प्रोफाइलर अलग सोचता है:
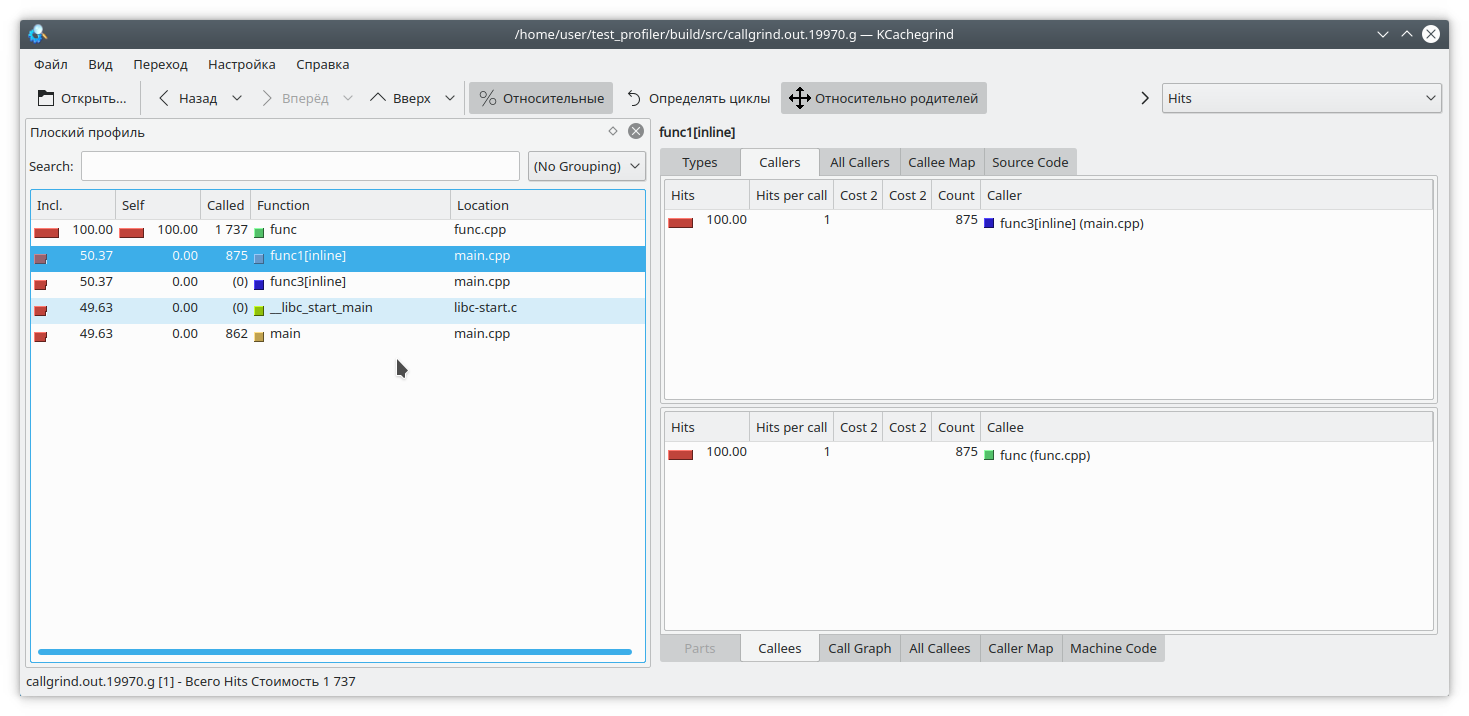
(वैसे, वैलग्राइंड ने चुपचाप चुप रहने का फैसला किया और यह निर्दिष्ट नहीं किया कि कॉल किस विशिष्ट कार्य से आया है)।
मेमोरी प्रोफाइलिंग
अक्सर ऐसी स्थितियां होती हैं जब एप्लिकेशन से मेमोरी कहीं "फ्लो" हो जाती है। यदि यह संसाधन सफाई की कमी के कारण है, तो मेमचेक को समस्या की पहचान करने में मदद करनी चाहिए। लेकिन आधुनिक सी ++ में मैनुअल संसाधन प्रबंधन के बिना ऐसा करना इतना मुश्किल नहीं है। unique_ptr, shared_ptr, वेक्टर, मैप नंगे-बिंदु हेरफेर को व्यर्थ बनाते हैं।
फिर भी, ऐसे अनुप्रयोगों में, मेमोरी लीक हो जाती है। यह कैसा चल रहा है? काफी बस, एक नियम के रूप में, यह कुछ ऐसा है जैसे "मूल्य को लंबे समय तक रहने वाले नक्शे में डाल दिया, लेकिन इसे हटाना भूल गया"। आइए इस स्थिति को ट्रैक करने का प्रयास करें।
ऐसा करने के लिए, हम अपने परीक्षण फ़ंक्शन को इस तरह से फिर से लिखते हैं
#include "func.h" #include <deque> #include <string> #include <map> static std::deque<std::string> deque; static std::map<int, std::string> map; int func(int arg) { int fst = 1; int snd = 1; for (int i = 0; i < arg; i++) { int res = (fst + snd + 1) % 19845689; fst = snd; snd = res; deque.emplace_back(std::to_string(res) + " integer"); map[i] = "integer " + std::to_string(res); deque.pop_front(); if (res % 200 != 0) { map.erase(i - 1); } } return fst; }
यहां, प्रत्येक पुनरावृत्ति पर, हम मानचित्र में कुछ तत्व जोड़ते हैं, और दुर्घटना से (सच, सच) हम कभी-कभी उन्हें वहां से हटाना भूल जाते हैं। इसके अलावा, हमारी आँखों को रोकने के लिए, हम std :: deque को थोड़ा टार्चर करते हैं।
हम दो उपकरणों के साथ मेमोरी लीक
पकड़ेंगे -
वैलेजिंड मासिफ और
गूगल हीपम्प ।
पुंजक
इस कमांड के साथ प्रोग्राम को रन करें
valgrind --tool=massif ./test_profiler 1000000
और हम कुछ इस तरह देखते हैं
पुंजक time=1277949333 mem_heap_B=313518 mem_heap_extra_B=58266 mem_stacks_B=0 heap_tree=detailed n4: 313518 (heap allocation functions) malloc/new/new[], --alloc-fns, etc. n1: 195696 0x109A69: func(int) (new_allocator.h:111) n0: 195696 0x10947A: main (main.cpp:18) n1: 72704 0x52BA414: ??? (in /usr/lib/x86_64-linux-gnu/libstdc++.so.6.0.25) n1: 72704 0x4010731: _dl_init (dl-init.c:72) n1: 72704 0x40010C8: ??? (in /lib/x86_64-linux-gnu/ld-2.27.so) n1: 72704 0x0: ??? n1: 72704 0x1FFF0000D1: ??? n0: 72704 0x1FFF0000E1: ??? n2: 42966 0x10A7EC: std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >::_M_mutate(unsigned long, unsigned long, char const*, unsigned long) (new_allocator.h:111) n1: 42966 0x10AAD9: std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >::_M_replace(unsigned long, unsigned long, char const*, unsigned long) (basic_string.tcc:466) n1: 42966 0x1099D4: func(int) (basic_string.h:1932) n0: 42966 0x10947A: main (main.cpp:18) n0: 0 in 2 places, all below massif's threshold (1.00%) n0: 2152 in 10 places, all below massif's threshold (1.00%)
यह देखा जा सकता है कि मासिफ समारोह में एक रिसाव का पता लगाने में सक्षम था, लेकिन अभी तक यह स्पष्ट नहीं है कि कहां है। चलो
-fno- इनलाइन ध्वज के साथ कार्यक्रम का पुनर्निर्माण करते हैं और फिर से विश्लेषण चलाते हैं
पुंजक time=3160199549 mem_heap_B=345142 mem_heap_extra_B=65986 mem_stacks_B=0 heap_tree=detailed n4: 345142 (heap allocation functions) malloc/new/new[], --alloc-fns, etc. n1: 221616 0x10CDBC: std::_Rb_tree_node<std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > >* std::_Rb_tree<int, std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::_Select1st<std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > >, std::less<int>, std::allocator<std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > > >::_M_create_node<std::piecewise_construct_t const&, std::tuple<int const&>, std::tuple<> >(std::piecewise_construct_t const&, std::tuple<int const&>&&, std::tuple<>&&) [clone .isra.81] (stl_tree.h:653) n1: 221616 0x10CE0C: std::_Rb_tree_iterator<std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > > std::_Rb_tree<int, std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::_Select1st<std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > >, std::less<int>, std::allocator<std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > > >::_M_emplace_hint_unique<std::piecewise_construct_t const&, std::tuple<int const&>, std::tuple<> >(std::_Rb_tree_const_iterator<std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > >, std::piecewise_construct_t const&, std::tuple<int const&>&&, std::tuple<>&&) [clone .constprop.87] (stl_tree.h:2414) n1: 221616 0x10CF2B: std::map<int, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, std::less<int>, std::allocator<std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > > >::operator[](int const&) (stl_map.h:499) n1: 221616 0x10A7F5: func(int) (func.cpp:20) n0: 221616 0x109F8E: main (main.cpp:18) n1: 72704 0x52BA414: ??? (in /usr/lib/x86_64-linux-gnu/libstdc++.so.6.0.25) n1: 72704 0x4010731: _dl_init (dl-init.c:72) n1: 72704 0x40010C8: ??? (in /lib/x86_64-linux-gnu/ld-2.27.so) n1: 72704 0x0: ??? n1: 72704 0x1FFF0000D1: ??? n0: 72704 0x1FFF0000E1: ??? n2: 48670 0x10B866: std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >::_M_mutate(unsigned long, unsigned long, char const*, unsigned long) (basic_string.tcc:317) n1: 48639 0x10BB2C: std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >::_M_replace(unsigned long, unsigned long, char const*, unsigned long) (basic_string.tcc:466) n1: 48639 0x10A643: std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > std::operator+<char, std::char_traits<char>, std::allocator<char> >(char const*, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >&&) [clone .constprop.86] (basic_string.h:6018) n1: 48639 0x10A7E5: func(int) (func.cpp:20) n0: 48639 0x109F8E: main (main.cpp:18) n0: 31 in 1 place, below massif's threshold (1.00%) n0: 2152 in 10 places, all below massif's threshold (1.00%)
अब यह स्पष्ट है कि मानचित्र तत्व को जोड़ने में रिसाव कहां है। मासिफ अल्पकालिक वस्तुओं का पता लगा सकता है, इसलिए इस डंप में std :: deque के साथ जोड़-तोड़ अदृश्य हैं।
Heapdump
Google heapdump को काम करने के लिए, आपको
tcmalloc लाइब्रेरी को लिंक या प्रीलोड करना
होगा । यह लाइब्रेरी मेमोरी एलोकेशन, फ्री, ... के मानक कार्यों की जगह लेती है। इसके अलावा, यह इन कार्यों के उपयोग के बारे में जानकारी एकत्र कर सकता है, जिनका उपयोग हम कार्यक्रम का विश्लेषण करते समय करेंगे।
चूंकि यह विधि बहुत धीमी गति से काम करती है (यहां तक कि द्रव्यमान की तुलना में भी), मैं अनुशंसा करता हूं कि आप संकलन करते समय
-fno-inline विकल्प के साथ कार्यों के संकलन को तुरंत अक्षम कर
दें । इसलिए, हम अपने आवेदन का पुनर्निर्माण करते हैं और टीम के साथ चलते हैं
HEAPPROFILESIGNAL=23 HEAPPROFILE=./heap ./test_profiler 100000000
यहाँ यह माना जाता है कि tcmalloc पुस्तकालय हमारे आवेदन से जुड़ा हुआ है।
अब, हम ध्यान देने योग्य रिसाव के गठन के लिए कुछ समय के लिए आवश्यक प्रतीक्षा करते हैं, और हमारी प्रक्रिया को एक संकेत 23 भेजते हैं
kill -23 <pid>
नतीजतन, heap.0001.heap नामक एक फ़ाइल दिखाई देती है, जिसे हम कमांड के साथ कॉलग्रिंड प्रारूप में परिवर्तित करते हैं
pprof ./test_profiler "./heap.0001.heap" --inuse_space --callgrind > callgrind.out.4
साथ ही pitable ऑप्शन पर भी ध्यान दें। आप
inuse_space ,
inuse_objects ,
आवंटन_ space ,
आवंटन_ objects के विकल्पों में से चुन सकते हैं, जो उपयोग में आने वाले स्थान या ऑब्जेक्ट्स को दिखाते हैं, या क्रमशः कार्यक्रम की पूरी अवधि के लिए आवंटित स्थान और ऑब्जेक्ट्स। हम inuse_space विकल्प में रुचि रखते हैं, जो वर्तमान में उपयोग की गई मेमोरी स्पेस दिखाता है।
हमारे पसंदीदा kCacheGrind खोलें और देखें
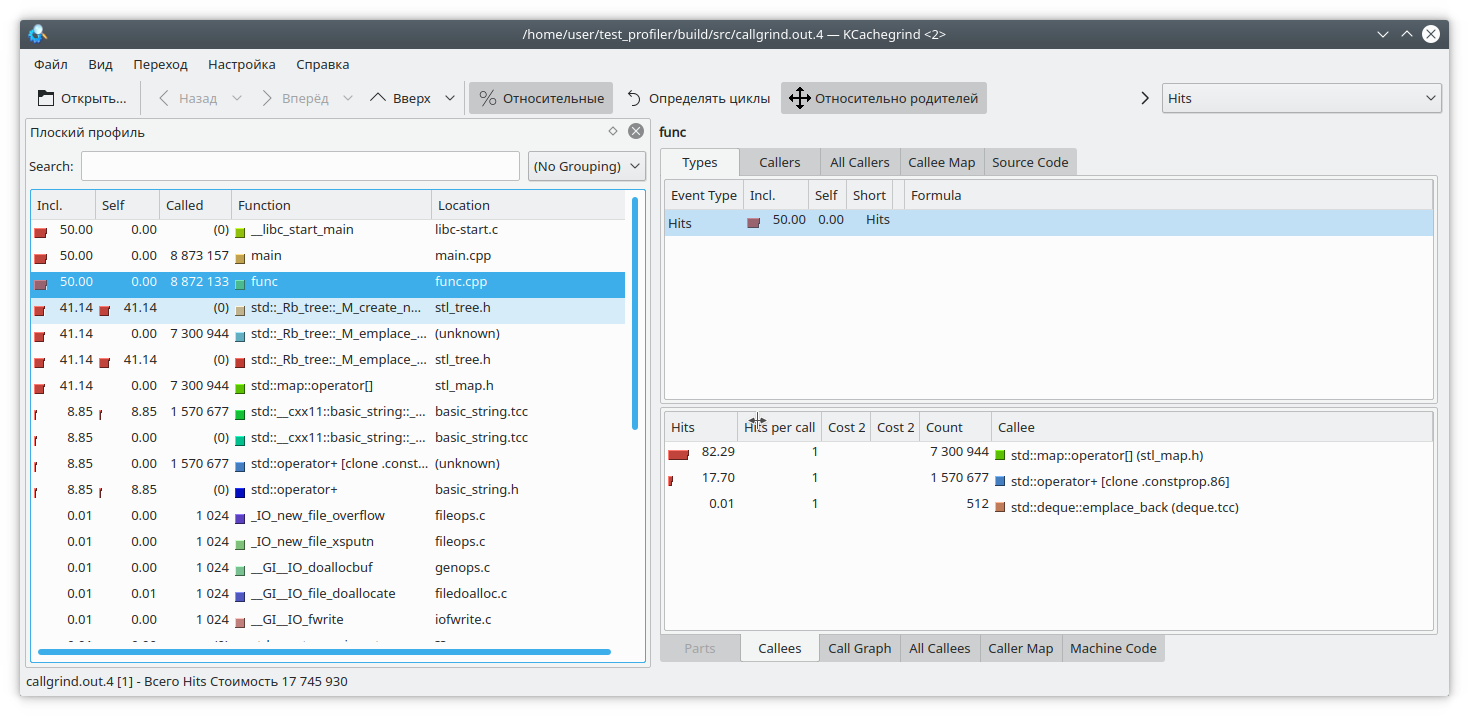
std :: मैप ने बहुत अधिक मेमोरी खा ली है। शायद इसमें एक रिसाव।
निष्कर्ष
C ++ में प्रोफाइलिंग करना बहुत मुश्किल काम है। यहां हमें इनलाइनिंग कार्य, असमर्थित निर्देश, गलत परिणाम आदि से निपटना होगा। प्रोफाइलर के परिणामों पर भरोसा करना हमेशा संभव नहीं होता है।
ऊपर प्रस्तावित कार्यों के अलावा, प्रोफाइलिंग के लिए डिज़ाइन किए गए अन्य उपकरण हैं - perf, Intel VTune और अन्य। लेकिन वे इनमें से कुछ कमियों को भी दिखाते हैं। इसलिए, फ़ंक्शन के निष्पादन समय को मापने और लॉग में प्रदर्शित करके "दादा" की रूपरेखा के बारे में मत भूलना।
इसके अलावा, यदि आपके पास अपने कोड की रूपरेखा बनाने की दिलचस्प तकनीक है, तो कृपया उन्हें टिप्पणियों में पोस्ट करें