क्वेरी भाषा Cypher मूल रूप से चित्रमय DBMS Neo4j के लिए विशेष रूप से विकसित किया गया था। साइफर का लक्ष्य ग्राफ डेटाबेस के लिए मानव-पठनीय SQL डेटाबेस क्वेरी भाषा प्रदान करना है। आज, साइफर को कई ग्राफ डीबीएमएस द्वारा समर्थित किया गया है। OpenCypher को Cypher को मानकीकृत करने के लिए बनाया गया था।
Neo4j DBMS के साथ काम करने की मूल बातें एक ब्राउज़र में Neo4j के साथ काम करने की मूल बातें लेख में वर्णित हैं।
साइरोफ़र से परिचित होने के लिए, मैं एक परिवार के पेड़ के एक उदाहरण पर विचार करता हूं, जिसे मैं ब्रेटको द्वारा क्लासिक प्रोलॉग पाठ्यपुस्तक से उधार लिया गया था। यह उदाहरण दिखाएगा कि ग्राफ़ में नोड्स और लिंक कैसे जोड़े जाएं, उन्हें लेबल और विशेषताओं को कैसे असाइन किया जाए, और प्रश्न कैसे पूछे जाएं।
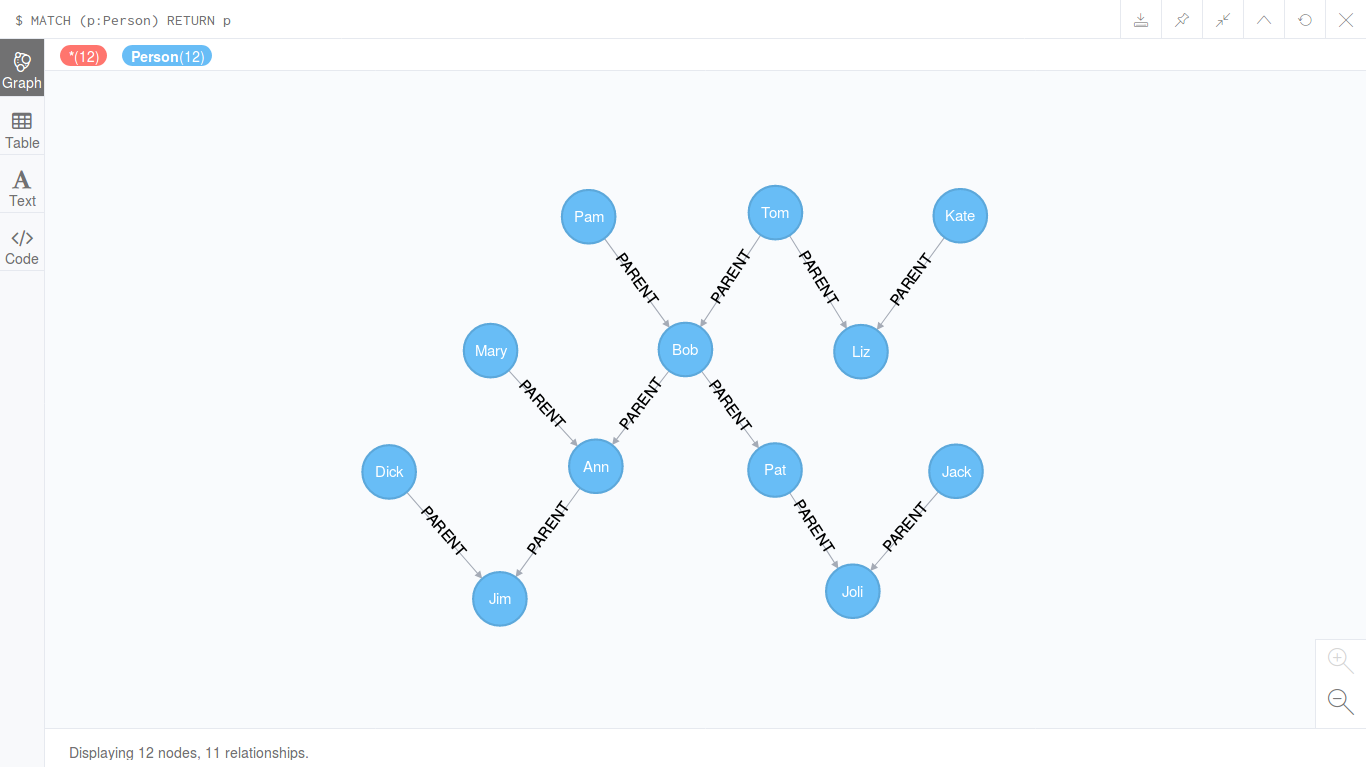
तो, आइए हम नीचे दिए गए चित्र में एक पारिवारिक पेड़ दिखाए गए हैं।
आइए देखते हैं कि साइफ्रे में संबंधित ग्राफ कैसे बनता है:
CREATE (pam:Person {name: "Pam"}), (tom:Person {name: "Tom"}), (kate:Person {name: "Kate"}), (mary:Person {name: "Mary"}), (bob:Person {name: "Bob"}), (liz:Person {name: "Liz"}), (dick:Person {name: "Dick"}), (ann:Person {name: "Ann"}), (pat:Person {name: "Pat"}), (jack:Person {name: "Jack"}), (jim:Person {name: "Jim"}), (joli:Person {name: "Joli"}), (pam)-[:PARENT]->(bob), (tom)-[:PARENT]->(bob), (tom)-[:PARENT]->(liz), (kate)-[:PARENT]->(liz), (mary)-[:PARENT]->(ann), (bob)-[:PARENT]->(ann), (bob)-[:PARENT]->(pat), (dick)-[:PARENT]->(jim), (ann)-[:PARENT]->(jim), (pat)-[:PARENT]->(joli), (jack)-[:PARENT]->(joli)
एक चित्रमय DBMS में डेटा जोड़ने के लिए एक अनुरोध में दो भाग होते हैं: नोड्स जोड़ना और उनके बीच लिंक जोड़ना। जोड़े जाने वाले प्रत्येक नोड को इस अनुरोध के ढांचे के भीतर एक नाम सौंपा गया है, जिसका उपयोग लिंक बनाने के लिए किया जाता है। नोड्स और संचार दस्तावेजों को स्टोर कर सकते हैं। हमारे मामले में, नोड्स में नाम फ़ील्ड के साथ दस्तावेज़ होते हैं, और दस्तावेज़ लिंक में नहीं होते हैं। इसके अलावा नोड्स और लिंक को लेबल किया जा सकता है। हमारे मामले में, नोड्स को लेबल व्यक्ति को सौंपा गया है, और लिंक PARENT हैं। अनुरोधों में लेबल को उसके नाम से पहले एक बृहदान्त्र द्वारा हाइलाइट किया गया है।
तो, Neo4j ने हमें बताया कि: Added 12 labels, created 12 nodes, set 12 properties, created 11 relationships, completed after 9 ms.
आइए देखें कि हमें क्या मिला:
MATCH (p:Person) RETURN p
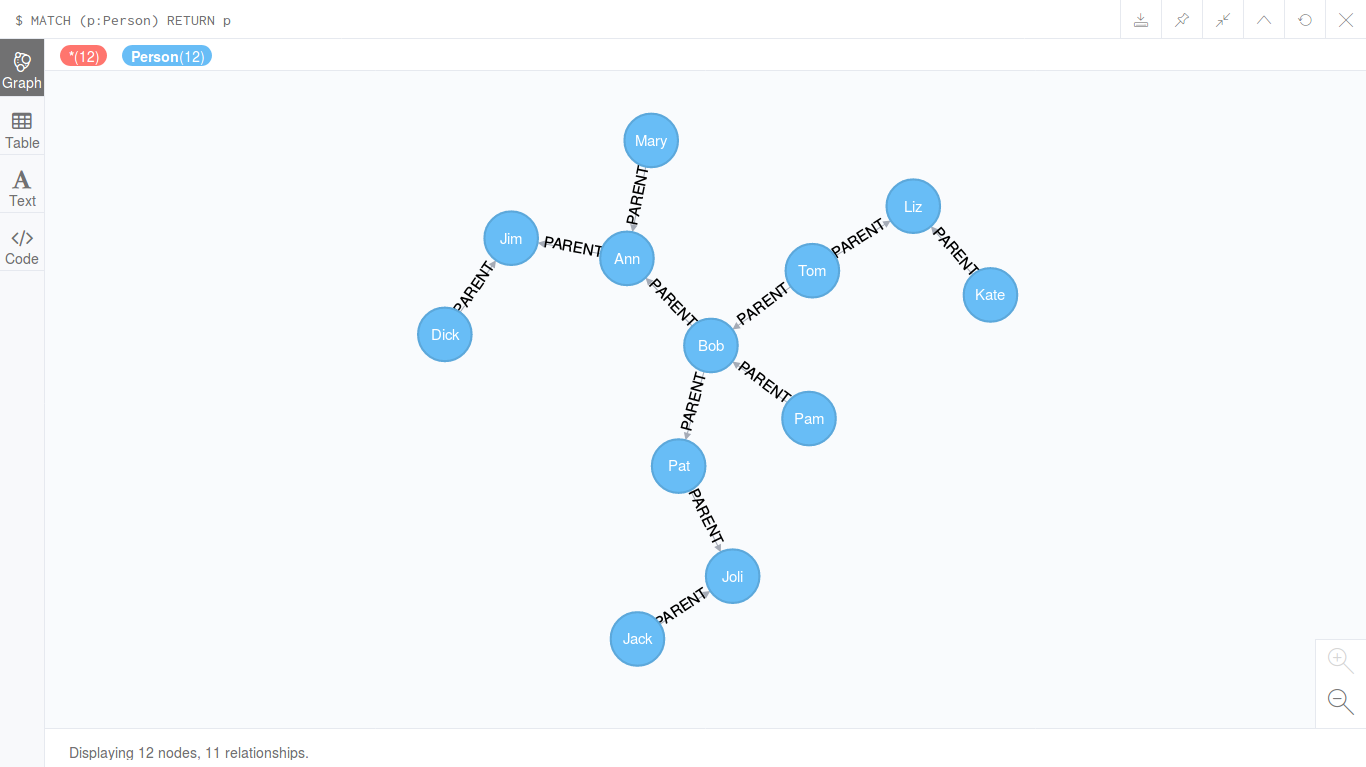
परिणामी ग्राफ की उपस्थिति को संपादित करने के लिए हमें कोई भी मना नहीं करता है:
इससे क्या हो सकता है? आप यह सत्यापित कर सकते हैं, उदाहरण के लिए, पाम है
बॉब के माता-पिता:
MATCH ans = (:Person {name: "Pam"})-[:PARENT]->(:Person {name: "Bob"}) RETURN ans
हमें इसी उपसमूह मिलता है:

हालांकि, यह बिल्कुल वैसा नहीं है, जिसकी हमें जरूरत है। अनुरोध बदलें:
MATCH ans = (:Person {name: "Pam"})-[:PARENT]->(:Person {name: "Bob"}) RETURN ans IS NOT NULL
अब जवाब में हम true । और अगर हम पूछें:
MATCH ans = (:Person {name: "Pam"})-[:PARENT]->(:Person {name: "Liz"}) RETURN ans IS NOT NULL
हमें कुछ भी नहीं मिला ... यहाँ आपको OPTIONAL शब्द जोड़ना होगा, फिर यदि
परिणाम खाली होगा, फिर false लौटाया जाएगा:
OPTIONAL MATCH ans = (:Person {name: "Pam"})-[:PARENT]->(:Person {name: "Liz"}) RETURN ans IS NOT NULL
अब हमें अपेक्षित उत्तर false ।
अगला, आप देख सकते हैं कि माता-पिता कौन है:
MATCH (p1:Person)-[:PARENT]->(p2:Person) RETURN p1, p2
Text साथ परिणाम टैब खोलें और दो कॉलम वाली एक तालिका देखें:
╒═══════════════╤═══════════════╕ │"p1" │"p2" │ ╞═══════════════╪═══════════════╡ │{"name":"Pam"} │{"name":"Bob"} │ ├───────────────┼───────────────┤ │{"name":"Tom"} │{"name":"Bob"} │ ├───────────────┼───────────────┤ │{"name":"Tom"} │{"name":"Liz"} │ ├───────────────┼───────────────┤ │{"name":"Kate"}│{"name":"Liz"} │ ├───────────────┼───────────────┤ │{"name":"Mary"}│{"name":"Ann"} │ ├───────────────┼───────────────┤ │{"name":"Bob"} │{"name":"Ann"} │ ├───────────────┼───────────────┤ │{"name":"Bob"} │{"name":"Pat"} │ ├───────────────┼───────────────┤ │{"name":"Dick"}│{"name":"Jim"} │ ├───────────────┼───────────────┤ │{"name":"Ann"} │{"name":"Jim"} │ ├───────────────┼───────────────┤ │{"name":"Pat"} │{"name":"Joli"}│ ├───────────────┼───────────────┤ │{"name":"Jack"}│{"name":"Joli"}│ └───────────────┴───────────────┘
हम और क्या सीख सकते हैं? उदाहरण के लिए, जीन के एक विशिष्ट सदस्य के माता-पिता कौन हैं, उदाहरण के लिए, बॉब के लिए:
MATCH (parent:Person)-[:PARENT]->(:Person {name: "Bob"}) RETURN parent.name
╒═════════════╕ │"parent.name"│ ╞═════════════╡ │"Tom" │ ├─────────────┤ │"Pam" │ └─────────────┘
यहां, एक उत्तर के रूप में, हम पूरे नोड का अनुरोध नहीं करते हैं, लेकिन केवल इसकी विशिष्ट विशेषता है।
हम यह भी पता लगा सकते हैं कि बॉब के बच्चे कौन हैं:
MATCH (:Person {name: "Bob"})-[:PARENT]->(child:Person) RETURN child.name
╒════════════╕ │"child.name"│ ╞════════════╡ │"Ann" │ ├────────────┤ │"Pat" │ └────────────┘
हम यह भी पूछ सकते हैं कि किसके बच्चे हैं:
MATCH (parent:Person)-[:PARENT]->(:Person) RETURN parent.name
╒═════════════╕ │"parent.name"│ ╞═════════════╡ │"Pam" │ ├─────────────┤ │"Tom" │ ├─────────────┤ │"Tom" │ ├─────────────┤ │"Kate" │ ├─────────────┤ │"Mary" │ ├─────────────┤ │"Bob" │ ├─────────────┤ │"Bob" │ ├─────────────┤ │"Dick" │ ├─────────────┤ │"Ann" │ ├─────────────┤ │"Pat" │ ├─────────────┤ │"Jack" │ └─────────────┘
हम्म, टॉम और बॉब एक दूसरे से दो बार मिले, इसे ठीक करें:
MATCH (parent:Person)-[:PARENT]->(:Person) RETURN DISTINCT parent.name
हमने क्वेरी के रिटर्न परिणाम में DISTINCT शब्द जोड़ा है, जिसका अर्थ है
SQL में ऐसा ही है।
╒═════════════╕ │"parent.name"│ ╞═════════════╡ │"Pam" │ ├─────────────┤ │"Tom" │ ├─────────────┤ │"Kate" │ ├─────────────┤ │"Mary" │ ├─────────────┤ │"Bob" │ ├─────────────┤ │"Dick" │ ├─────────────┤ │"Ann" │ ├─────────────┤ │"Pat" │ ├─────────────┤ │"Jack" │ └─────────────┘
आप यह भी देख सकते हैं कि Neo4j क्रिएट अनुरोध में दर्ज किए गए क्रम में माता-पिता को हमारे पास लौटाता है।
आइए अब पूछते हैं कि दादा या दादी कौन हैं:
MATCH (grandparent:Person)-[:PARENT]->()-[:PARENT]->(:Person) RETURN DISTINCT grandparent.name
महान, यह बात है:
╒══════════════════╕ │"grandparent.name"│ ╞══════════════════╡ │"Tom" │ ├──────────────────┤ │"Pam" │ ├──────────────────┤ │"Bob" │ ├──────────────────┤ │"Mary" │ └──────────────────┘
क्वेरी टेम्प्लेट में, हमने मध्यवर्ती मध्यवर्ती नोड () और प्रकार के दो संबंधों का उपयोग किया।
हमें अब पता चला कि पिता कौन है। पिता वह व्यक्ति होता है जिसके पास एक बच्चा होता है। इस प्रकार, हमारे पास डेटा की कमी है कि आदमी कौन है। तदनुसार, यह निर्धारित करने के लिए कि मां कौन है, आपको यह जानना होगा कि एक महिला कौन है। प्रासंगिक जानकारी को हमारे डेटाबेस में जोड़ें। ऐसा करने के लिए, हम Male और Female को मौजूदा नोड में लेबल असाइन करेंगे।
MATCH (p:Person) WHERE p.name IN ["Tom", "Dick", "Bob", "Jim", "Jack"] SET p:Male
MATCH (p:Person) WHERE p.name IN ["Pam", "Kate", "Mary", "Liz", "Ann", "Pat", "Joli"] SET p:Female
आइए बताते हैं कि हमने यहाँ क्या किया: हमने सभी नोड्स का चयन किया, जिन्हें Person ने लेबल किया था, उनकी जाँच की
वर्ग कोष्ठक में निर्दिष्ट दी गई सूची के अनुसार name संपत्ति, और क्रमशः लेबल Male या Female निर्दिष्ट नोड्स सौंपा।
की जाँच करें:
MATCH (p:Person) WHERE p:Male RETURN p.name
╒════════╕ │"p.name"│ ╞════════╡ │"Tom" │ ├────────┤ │"Bob" │ ├────────┤ │"Dick" │ ├────────┤ │"Jack" │ ├────────┤ │"Jim" │ └────────┘
MATCH (p:Person) WHERE p:Female RETURN p.name
╒════════╕ │"p.name"│ ╞════════╡ │"Pam" │ ├────────┤ │"Kate" │ ├────────┤ │"Mary" │ ├────────┤ │"Liz" │ ├────────┤ │"Ann" │ ├────────┤ │"Pat" │ ├────────┤ │"Joli" │ └────────┘
हमने व्यक्तिगत रूप से लेबल किए गए सभी नोड्स का अनुरोध किया, जिसमें क्रमशः Male या Female का लेबल भी है। लेकिन हम अपने अनुरोधों को थोड़ा अलग कर सकते हैं:
MATCH (p:Person:Male) RETURN p.name MATCH (p:Person:Female) RETURN p.name
आइए एक बार फिर हमारे ग्राफ पर नज़र डालें:
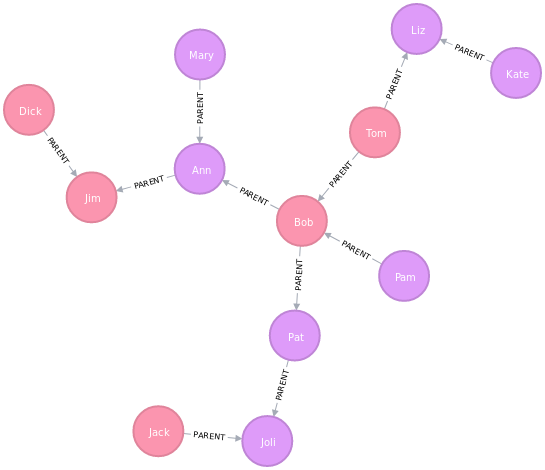
Neo4j Browser ने माले और के निशान के अनुसार नोड्स को दो अलग-अलग रंगों में चित्रित किया
महिला।
ठीक है, अब हम डेटाबेस से सभी पिताओं को क्वेरी कर सकते हैं:
MATCH (p:Person:Male)-[:PARENT]->(:Person) RETURN DISTINCT p.name
╒════════╕ │"p.name"│ ╞════════╡ │"Tom" │ ├────────┤ │"Bob" │ ├────────┤ │"Dick" │ ├────────┤ │"Jack" │ └────────┘
और माता:
MATCH (p:Person:Female)-[:PARENT]->(:Person) RETURN DISTINCT p.name
╒════════╕ │"p.name"│ ╞════════╡ │"Pam" │ ├────────┤ │"Kate" │ ├────────┤ │"Mary" │ ├────────┤ │"Ann" │ ├────────┤ │"Pat" │ └────────┘
आइए अब एक भाई और बहन के रिश्ते को बनाते हैं। X, Y का भाई है
अगर वह एक आदमी है, और एक्स और वाई के लिए कम से कम एक सामान्य माता-पिता हैं। इसी तरह के लिए
रिश्ते की बहन
साइप्रोफ़ पर भाई का रवैया:
MATCH (brother:Person:Male)<-[:PARENT]-()-[:PARENT]->(p:Person) RETURN brother.name, p.name
╒══════════════╤════════╕ │"brother.name"│"p.name"│ ╞══════════════╪════════╡ │"Bob" │"Liz" │ └──────────────┴────────┘
साइफर पर बहन का रवैया:
MATCH (sister:Person:Female)<-[:PARENT]-()-[:PARENT]->(p:Person) RETURN sister.name, p.name
╒═════════════╤════════╕ │"sister.name"│"p.name"│ ╞═════════════╪════════╡ │"Liz" │"Bob" │ ├─────────────┼────────┤ │"Ann" │"Pat" │ ├─────────────┼────────┤ │"Pat" │"Ann" │ └─────────────┴────────┘
तो, हम यह पता लगा सकते हैं कि किसके माता-पिता कौन हैं, और यह भी कि किसके दादा या दादी हैं। लेकिन अधिक दूर पूर्वजों के बारे में क्या? दादा-दादी के साथ, महान-परदादा या इतने पर? हम ऐसे प्रत्येक मामले के लिए एक समान नियम नहीं लिखेंगे, और यह हर बार अधिक समस्याग्रस्त होगा। वास्तव में, सब कुछ सरल है: X, Y के लिए पूर्वज है यदि यह एक माता-पिता के लिए पूर्वज है। Cypher एक पैटर्न प्रदान करता है * जो आपको किसी भी लम्बाई के संबंधों के अनुक्रम की आवश्यकता देता है:
MATCH (p:Person)-[*]->(s:Person) RETURN DISTINCT p.name, s.name
इसमें वास्तव में एक समस्या है: यह कोई भी कनेक्शन होगा। PARENT लिंक का संदर्भ जोड़ें:
MATCH (p:Person)-[:PARENT*]->(s:Person) RETURN DISTINCT p.name, s.name
लेख की लंबाई नहीं बढ़ाने के लिए, हम Joli सभी पूर्वजों को Joli :
MATCH (p:Person)-[:PARENT*]->(:Person {name: "Joli"}) RETURN DISTINCT p.name
╒════════╕ │"p.name"│ ╞════════╡ │"Jack" │ ├────────┤ │"Pat" │ ├────────┤ │"Bob" │ ├────────┤ │"Pam" │ ├────────┤ │"Tom" │ └────────┘
यह पता लगाने के लिए अधिक जटिल नियम पर विचार करें कि कौन किससे संबंधित है।
सबसे पहले, रिश्तेदार पूर्वज और वंशज हैं, उदाहरण के लिए, एक बेटा और मां, दादी और पोता। दूसरे, रिश्तेदार चचेरे भाई, दूसरे चचेरे भाई, और इतने पर सहित भाई हैं, जो पूर्वजों के संदर्भ में इसका मतलब है कि उनका एक सामान्य पूर्वज है। और तीसरा, वे रिश्तेदार जिनके पास सामान्य वंशज हैं, उदाहरण के लिए, पति और पत्नी, रिश्तेदार माने जाते हैं।
साइफर पर, आपको कई पैटर्न के लिए UNION का उपयोग करने की आवश्यकता है:
MATCH (r1:Person)-[:PARENT*]-(r2:Person) RETURN DISTINCT r1.name, r2.name UNION MATCH (r1:Person)<-[:PARENT*]-(:Person)-[:PARENT*]->(r2:Person) RETURN DISTINCT r1.name, r2.name UNION MATCH (r1:Person)-[:PARENT*]->(:Person)<-[:PARENT*]-(r2:Person) RETURN DISTINCT r1.name, r2.name
यहां, पहले नियम में, कनेक्शन का उपयोग किया जाता है, जिसकी दिशा हमारे लिए कोई मायने नहीं रखती है। इस तरह के कनेक्शन को एक तीर के बिना इंगित किया जाता है, बस एक डैश - । दूसरा और तीसरा नियम स्पष्ट, परिचित तरीके से लिखा गया है।
हम यहां कुल क्वेरी का परिणाम नहीं देंगे, हम केवल यह कहेंगे कि पाए गए रिश्तेदारों के जोड़े 132 हैं, जो कि गणना मूल्य के अनुरूप है। 12 से ऑर्डर किए गए जोड़े की संख्या 12. हम इस क्वेरी को चर r1 या r2 की घटना को प्रतिस्थापित करके भी निर्दिष्ट कर सकते हैं (:Person {name: "Liz"}) उदाहरण के लिए, हालांकि, हमारे मामले में यह बहुत मायने नहीं रखता है, क्योंकि हमारे डेटाबेस में सभी व्यक्ति स्पष्ट रूप से रिश्तेदार हैं।
यह हमारे डेटाबेस में व्यक्तियों के बीच संबंधों की पहचान करने की हमारी चर्चा को समाप्त करता है।
अंत में, विचार करें कि नोड्स और लिंक कैसे हटाएं।
हमारे सभी व्यक्तियों को हटाने के लिए, आप अनुरोध को निष्पादित कर सकते हैं:
MATCH (p:Person) DELETE p
हालाँकि, Neo4j हमें बताएगा कि आप लिंक वाले नोड्स को हटा नहीं सकते हैं।
इसलिए, हम पहले लिंक को हटाते हैं और फिर नोड्स को हटाने को दोहराते हैं:
MATCH (p1:Person)-[r]->(p2:Person) DELETE r
अब हमने क्या किया है: दो व्यक्तियों की तुलना जिनके बीच संबंध है, इस संबंध को r नाम दिया और फिर इसे हटा दिया।
निष्कर्ष
लेख दिखाता है कि सामाजिक ग्राफ के सरल उदाहरण का उपयोग करते हुए साइफेयर क्वेरी भाषा की क्षमताओं का उपयोग कैसे किया जाए। विशेष रूप से, हमने जांच की कि नोड्स और लिंक को एक क्वेरी के साथ कैसे जोड़ा जाए, संबंधित डेटा की खोज कैसे करें, अप्रत्यक्ष लिंक सहित, और नोड्स को लेबल कैसे असाइन करें। साइरफ के बारे में अधिक जानकारी नीचे दिए गए लिंक पर पाई जा सकती है। एक अच्छा प्रारंभिक बिंदु "Neo4j Cypher Refcard" है।
Neo4j एकमात्र ग्राफ DBMS से दूर है। अन्य सबसे लोकप्रिय में से एक हैं केली , ग्राफ़िकल क्वेरी भाषा के साथ डग्राफ, मल्टी-मॉडल अरेंजबीडीबी और ओरिएंटबीडी । RDF और SPARQL के समर्थन से विशेष रुचि ब्लेज़ग्राफ हो सकती है।
संदर्भ
ग्रन्थसूची
- रॉबिन्सन जान, वेबर जिम, इफ्रेम एमिल। ग्राफ़ डेटाबेस। नई सुविधाएँ
संबंधित डेटा / प्रति के साथ काम करने के लिए। अंग्रेजी से - दूसरा एड। - एम।: डीएमके-प्रेस,
2016 - 256 एस। - Bratko I. कृत्रिम बुद्धि के लिए प्रोलॉग भाषा में प्रोग्रामिंग:
प्रति। अंग्रेजी से - एम ।: मीर, 1990 ।-- 560 पी।: बीमार।
अंतभाषण
लेख के लेखक केवल दो कंपनियों (सेंट पीटर्सबर्ग से दोनों) को जानते हैं जो अपने उत्पादों के लिए ग्राफ डीबीएमएस का उपयोग करते हैं। लेकिन मैं यह जानना चाहूंगा कि इस लेख के पाठकों की कितनी कंपनियां उनके विकास में उपयोग करती हैं। इसलिए, मैं सर्वेक्षण में भाग लेने का प्रस्ताव करता हूं। टिप्पणियों में अपने अनुभव के बारे में भी लिखें, यह जानना बहुत दिलचस्प होगा।