नमस्कार, हेब्र! मेरा नाम डेनिस कोपरिन है, और आज मैं इस बारे में बात करना चाहता हूं कि हमने मैकओएस पर मांग पर बैकअप की समस्या को कैसे हल किया। वास्तव में, संस्थान में मुझे मिला एक दिलचस्प काम अंततः फाइल सिस्टम के साथ काम करने पर एक बड़ी शोध परियोजना में बदल गया। सभी विवरण कट के नीचे हैं।

मैं दूर से शुरू नहीं करूंगा, मैं केवल यह कह सकता हूं कि यह सब मास्को इंस्टीट्यूट ऑफ फिजिक्स एंड टेक्नोलॉजी में एक परियोजना के साथ शुरू हुआ था, जिसे मैंने Acronis बेस विभाग में अपने पर्यवेक्षक के साथ विकसित किया था। हमें रिमोट फाइल स्टोरेज को व्यवस्थित करने या उनके बैकअप की वर्तमान स्थिति को बनाए रखने के कार्य का सामना करना पड़ा।
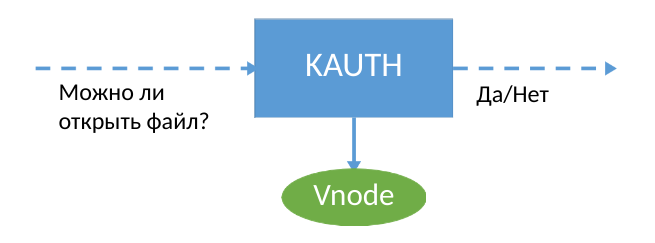
डेटा सुरक्षा सुनिश्चित करने के लिए, हम macOS कर्नेल एक्सटेंशन का उपयोग करते हैं, जो सिस्टम में घटनाओं के बारे में जानकारी एकत्र करता है। डेवलपर्स के लिए KPI में KAUTH API है, जो आपको फ़ाइल खोलने और बंद करने के बारे में सूचनाएं प्राप्त करने की अनुमति देता है - यही सब कुछ है। यदि आप KAUTH का उपयोग करते हैं, तो आपको इसे लिखने के लिए खोलते समय फ़ाइल को पूरी तरह से सहेजना होगा, क्योंकि फ़ाइल को लिखने की घटनाएं डेवलपर्स के लिए उपलब्ध नहीं हैं। इस तरह की जानकारी हमारे कार्यों के लिए पर्याप्त नहीं थी। वास्तव में, डेटा की बैकअप प्रतिलिपि को स्थायी रूप से पूरक करने के लिए, आपको ठीक से समझने की आवश्यकता है कि उपयोगकर्ता (या मैलवेयर :) ने फ़ाइल को नया डेटा कहां लिखा है।
लेकिन ओएस प्रतिबंधों से कौन से डेवलपर्स डर गए थे? यदि कर्नेल एपीआई आपको लिखने के संचालन के बारे में जानकारी प्राप्त करने की अनुमति नहीं देता है, तो आपको अन्य कर्नेल टूल के माध्यम से अवरोधन करने के लिए अपने तरीके से आने की आवश्यकता है।
पहले, हम कोर और इसकी संरचनाओं को पैच नहीं करना चाहते थे। इसके बजाय, उन्होंने एक पूरी आभासी मात्रा बनाने की कोशिश की, जो हमें इसके माध्यम से गुजरने वाले सभी पढ़ने और लिखने के लिए अवरोधन करने की अनुमति देगा। लेकिन यह macOS की एक अप्रिय विशेषता निकला: ऑपरेटिंग सिस्टम का मानना है कि इसमें 1 नहीं है, लेकिन 2 यूएसबी फ्लैश ड्राइव, दो डिस्क, और इसी तरह। और इस तथ्य से कि पहले के साथ काम करते समय दूसरा वॉल्यूम बदलता है, मैकओएस ड्राइव के साथ गलत तरीके से काम करना शुरू कर देता है। इस पद्धति से इतनी समस्याएं थीं कि मुझे इसे छोड़ना पड़ा।
दूसरे उपाय की तलाश करें
KAUTH की सीमाओं के बावजूद, यह KPI आपको सभी कार्यों से पहले रिकॉर्डिंग के लिए फ़ाइल के उपयोग के बारे में सूचित करने की अनुमति देता है। डेवलपर्स को कर्नेल - vnode में बीएसडी फ़ाइल अमूर्त तक पहुंच दी जाती है। ताज्जुब है, यह पता चला है कि पैच फ़िल्टरिंग वॉल्यूम फ़िल्टरिंग की तुलना में आसान है। Vnode संरचना में फ़ंक्शंस की एक तालिका होती है जो वास्तविक फ़ाइलों के साथ काम प्रदान करती है। इसलिए, हमारे पास इस तालिका को बदलने का विचार था।
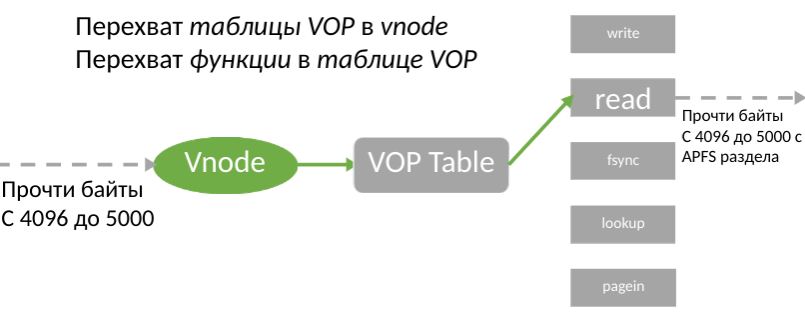
इस विचार को तुरंत एक अच्छा विचार माना गया था, लेकिन इसके कार्यान्वयन के लिए vnode संरचना में ही तालिका को खोजना आवश्यक था, क्योंकि Apple कहीं भी अपने स्थान का दस्तावेज़ नहीं देता है। ऐसा करने के लिए, कर्नेल मशीन कोड का अध्ययन करना आवश्यक था, और यह भी पता लगाना था कि क्या इस पते पर लिखना संभव है ताकि सिस्टम उसके बाद मर न जाए।
यदि तालिका मिल जाती है, तो हम बस इसे मेमोरी में कॉपी करते हैं, पॉइंटर को प्रतिस्थापित करते हैं और लिंक को नई टेबल पर मौजूदा vnode में पेस्ट करते हैं। इसके लिए धन्यवाद, फ़ाइलों के साथ सभी ऑपरेशन हमारे ड्राइवर के माध्यम से जाएंगे, और हम सभी उपयोगकर्ता अनुरोधों को पंजीकृत करने में सक्षम होंगे, जिसमें पढ़ना और लिखना शामिल है। इसलिए, क़ीमती तालिका की खोज हमारा मुख्य लक्ष्य बन गया है।
यह देखते हुए कि Apple वास्तव में यह नहीं चाहता है, समस्या को हल करने के लिए आपको फ़ील्ड के सापेक्ष स्थान के लिए अनुमानों का उपयोग करके तालिका के स्थान को "अनुमान" करने की कोशिश करनी होगी, या पहले से ही ज्ञात फ़ंक्शन को लेना, इसे अलग करना और इस जानकारी से ऑफसेट की तलाश करना चाहिए।
कैसे एक ऑफसेट के लिए देखने के लिए: एक आसान तरीका हैVnode में टेबल ऑफ़सेट खोजने का सबसे सरल तरीका एक संरचना में फ़ील्ड के स्थान के आधार पर एक अनुमानी है (
गिथूब से लिंक )।
struct vnode { ... int (**v_op)(void *); mount_t v_mount; ... }
हम इस धारणा का उपयोग करेंगे कि जिस v_op क्षेत्र की हमें आवश्यकता है, वह v_mount से ठीक 8 बाइट्स निकाला गया है। बाद के मूल्य को सार्वजनिक KPI (
Github से लिंक ) का उपयोग करके प्राप्त किया जा सकता है:
mount_t vnode_mount(vnode_t vp);
V_mount के मूल्य को जानने के बाद, हम "हैस्टैक में सुई" की तलाश करने लगेंगे - हम पॉइंटर के मान को 'vpode' को uintptr_t *, vintode_mount (vp) के मान को uintptr_t के रूप में देखेंगे। इसके बाद पुनरावृत्तियों के बाद मुझे "उचित" मान दिया जाता है, जब तक कि शर्त 'हैस्टैक [i] == सुई' पूरी नहीं हो जाती। और यदि खेतों के स्थान के बारे में धारणा सही है, तो ऑफसेट v_op i-1 है।
void* getVOPPtr(vnode_t vp) { auto haystack = (uintptr_t*) vp; auto needle = (uintptr_t) vnode_mount(vp); for (int i = 0; i < ATTEMPTCOUNT; i++) { if (haystack[i] == needle) { return haystack + (i - 1); } } return nullptr; }
कैसे एक ऑफसेट के लिए देखने के लिए: disassemblingइसकी सादगी के बावजूद, पहली विधि में एक महत्वपूर्ण कमी है। यदि Apple vnode संरचना में फ़ील्ड के क्रम को बदलता है, तो सरल विधि टूट जाएगी। एक अधिक सार्वभौमिक, लेकिन कम तुच्छ विधि कर्नेल को गतिशील रूप से अलग करना है।
उदाहरण के लिए, मैकओएस 10.14.6 पर असंतुष्ट कर्नेल फ़ंक्शन VNOP_CREATE (
Github से लिंक ) पर विचार करें। हमारे लिए दिलचस्प निर्देश एक तीर के साथ चिह्नित हैं ->।
_VNOP_CREATE:
1 push rbp
2 mov rbp, rsp
3 push r15
4 push r14
5 push r13
6 push r12
7 push rbx
8 sub rsp, 0x48
9 mov r15, r8
10 mov r12, rdx
11 mov r13, rsi
-> 12 mov rbx, rdi
13 lea rax, qword [___stack_chk_guard]
14 mov rax, qword [rax]
15 mov qword [rbp+-48], rax
-> 16 lea rax, qword [_vnop_create_desc] ; _vnop_create_desc
17 mov qword [rbp+-112], rax
18 mov qword [rbp+-104], rdi
19 mov qword [rbp+-96], rsi
20 mov qword [rbp+-88], rdx
21 mov qword [rbp+-80], rcx
22 mov qword [rbp+-72], r8
-> 23 mov rax, qword [rdi+0xd0]
-> 24 movsxd rcx, dword [_vnop_create_desc]
25 lea rdi, qword [rbp+-112]
-> 26 call qword [rax+rcx*8]
27 mov r14d, eax
28 test eax, eax
…. errno_t VNOP_CREATE(vnode_t dvp, vnode_t * vpp, struct componentname * cnp, struct vnode_attr * vap, vfs_context_t ctx) { int _err; struct vnop_create_args a; a.a_desc = &vnop;_create_desc; a.a_dvp = dvp; a.a_vpp = vpp; a.a_cnp = cnp; a.a_vap = vap; a.a_context = ctx; _err = (*dvp->v_op[vnop_create_desc.vdesc_offset])(&a;); …
हम कोडांतरक निर्देशों को स्कैन करेंगे vnode dvp में बदलाव खोजने के लिए। कोडांतरक कोड का "उद्देश्य" v_op तालिका से एक फ़ंक्शन को कॉल करना है। ऐसा करने के लिए, प्रोसेसर को इन चरणों का पालन करना चाहिए:
- रजिस्टर करने के लिए DVp अपलोड करें
- इसे प्राप्त करने के लिए v_op (पंक्ति 23)
- Vnop_create_desc.vdesc_offset (पंक्ति 24) प्राप्त करें
- एक फ़ंक्शन को कॉल करें (पंक्ति 26)
यदि चरण 2-4 के साथ सब कुछ स्पष्ट है, तो पहले चरण के साथ कठिनाइयां पैदा होती हैं। कैसे समझें कि किस रजिस्टर में डीवीपी लोड किया गया था? ऐसा करने के लिए, हमने एक फ़ंक्शन का अनुकरण करने की एक विधि का उपयोग किया जो वांछित पॉइंटर के आंदोलनों की निगरानी करता है। सिस्टम V x86_64 कॉलिंग कन्वेंशन के अनुसार, पहला तर्क आरडीआई रजिस्टर में पारित किया गया है। इसलिए, हमने उन सभी रजिस्टरों पर नज़र रखने का फैसला किया जिनमें रडी शामिल हैं। मेरे उदाहरण में, ये आरबीएक्स और रेडी रजिस्टर हैं। इसके अलावा, रजिस्टर की एक प्रति को स्टैक पर सहेजा जा सकता है, जो कर्नेल के डिबग संस्करण में पाया जाता है।
यह जानते हुए कि आरबीएक्स और रेडी रजिस्टर्स डीवीपी को स्टोर करते हैं, हम पता लगाते हैं कि लाइन 23 को v_op प्राप्त करने के लिए vnferenced vnode है। तो हमें यह धारणा मिलती है कि संरचना में विस्थापन 0xd0 है। सही निर्णय की पुष्टि करने के लिए, हम स्कैन करते हैं और सुनिश्चित करते हैं कि फ़ंक्शन सही ढंग से कहा जाता है (लाइनें 24 और 26)।
यह विधि सुरक्षित है, लेकिन, दुर्भाग्य से, इसके नुकसान भी हैं। हमें इस तथ्य पर भरोसा करना होगा कि फ़ंक्शन का पैटर्न (अर्थात 4 चरण जिनके बारे में हमने ऊपर बात की थी) समान होंगे। हालांकि, फ़ंक्शन के पैटर्न को बदलने की संभावना खेतों के क्रम को बदलने की संभावना से कम परिमाण का एक आदेश है। इसलिए हमने दूसरी विधि पर रोक लगाने का फैसला किया।
पॉइंटर्स को तालिका में बदलें
V_op खोजने के बाद, सवाल उठता है कि इस पॉइंटर का उपयोग कैसे करें? दो अलग-अलग तरीके हैं - तालिका में फ़ंक्शन को ओवरराइट करें (चित्र में तीसरा तीर) या vnode में तालिका को ओवरराइट करें (चित्र में दूसरा तीर)।
पहले तो ऐसा लगता है कि पहला विकल्प अधिक लाभदायक है, क्योंकि हमें केवल एक पॉइंटर को बदलने की आवश्यकता है। हालांकि, इस दृष्टिकोण में 2 महत्वपूर्ण कमियां हैं। सबसे पहले, v_op तालिका किसी दिए गए फ़ाइल सिस्टम के सभी vnode के लिए समान है (HFS के लिए v_op, APFS के लिए v_op, ...), इसलिए vnode द्वारा फ़िल्टर करना आवश्यक है, जो बहुत महंगा हो सकता है - आपको प्रत्येक लेखन कार्रवाई पर अतिरिक्त vnode को फ़िल्टर करना होगा। दूसरे, तालिका केवल पढ़ने के लिए पृष्ठ पर लिखी गई है। यदि आप IOMappedWrite64 के माध्यम से रिकॉर्डिंग का उपयोग करते हैं, तो सिस्टम की जाँच को दरकिनार कर इस सीमा को कम किया जा सकता है। इसके अलावा, अगर फ़ाइल सिस्टम ड्राइवर के साथ kext भेज दिया जाता है, तो यह पता लगाना मुश्किल होगा कि पैच को कैसे हटाया जाए।
दूसरा विकल्प अधिक लक्षित और सुरक्षित है - इंटरसेप्टर को केवल आवश्यक vnode के लिए कहा जाएगा, और vnode मेमोरी शुरू में रीड-राइट ऑपरेशन की अनुमति देती है। चूंकि पूरी तालिका को प्रतिस्थापित किया जा रहा है, इसलिए थोड़ी अधिक मेमोरी (एक के बजाय 80 फ़ंक्शन) आवंटित करना आवश्यक है। और चूंकि तालिकाओं की संख्या आमतौर पर फ़ाइल सिस्टम की संख्या के बराबर होती है, इसलिए मेमोरी की सीमा पूरी तरह से नगण्य है।
यही कारण है कि kext दूसरी विधि का उपयोग करता है, हालांकि, मैं दोहराता हूं, पहली नज़र में ऐसा लगता है कि यह विकल्प बदतर है।
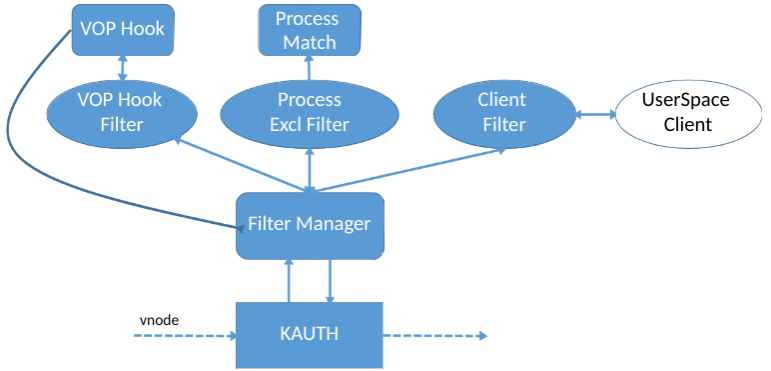
परिणामस्वरूप, हमारा ड्राइवर निम्नानुसार काम करता है:
- KAUTH API vnode प्रदान करता है
- हम vnode तालिका की जगह ले रहे हैं। यदि आवश्यक हो, तो हम केवल "दिलचस्प" vnode के लिए संचालन को रोकते हैं, उदाहरण के लिए, उपयोगकर्ता दस्तावेज़
- इंटरसेप्ट करते समय, हम जांचते हैं कि कौन सी प्रक्रिया रिकॉर्ड कर रही है, हम "हमारा" फ़िल्टर करते हैं
- हम ग्राहक को एक समकालिक यूजरस्पेस अनुरोध भेजते हैं, जो तय करता है कि वास्तव में क्या सहेजना है।
क्या हुआ?
आज हमारे पास एक प्रायोगिक मॉड्यूल है, जो macOS कर्नेल का विस्तार है और फाइल सिस्टम में किसी भी बदलाव को ध्यान में रखता है। यह ध्यान देने योग्य है कि macOS 10.15 में Apple ने फाइल सिस्टम में बदलाव की सूचनाएँ प्राप्त करने के
लिए एक नया ढाँचा (
EndpointSecurity के लिए ) पेश किया, जिसे एक्टिव प्रोटेक्शन में उपयोग करने की योजना है, इसलिए लेख में वर्णित समाधान को पदावनत घोषित किया गया था।