Algoritma neuroevolutionary belajar bermain Mario
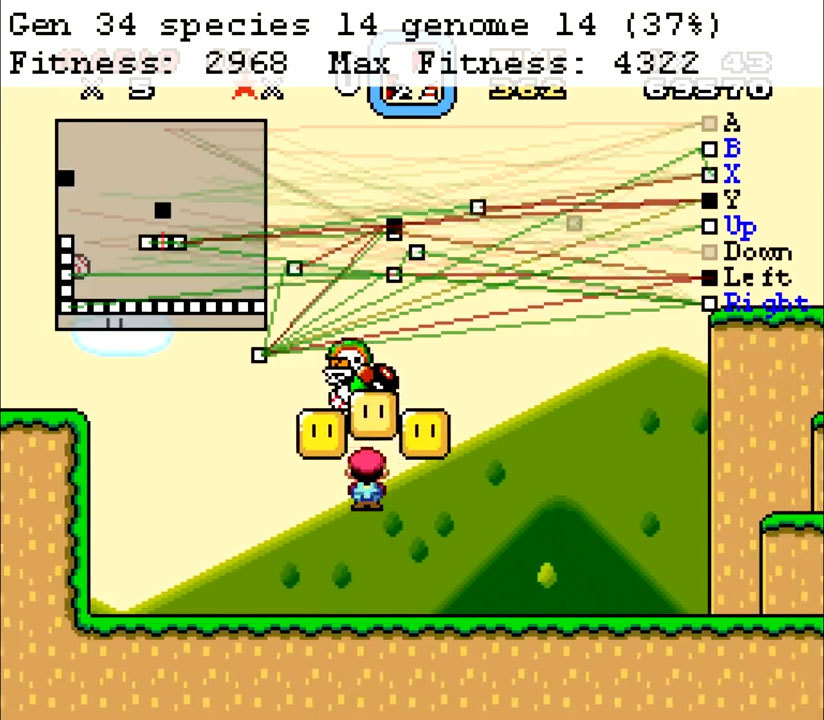 SethBling dikenal dengan salurannya yang memuat berbagai kiat dan penemuan untuk dunia Minecraft. Seringkali muncul konten lain. Misalnya, Mario ada di daftar minat vlogger. Itu SethBling yang pertama kali melewati Super Mario World di konsol menggunakan bug dengan mengedit memori dengan memindahkan item dalam permainan. Video dan streaming terbarunya masih memiliki gim yang sama. Tapi itu bukan orang yang bermain, tetapi algoritma neuroevolutionary, yang ditulis sendiri oleh SethBling.Implementasinya disebut MarI / O. Representasi grafis dari jaringan saraf dibuat di bagian atas layar. Di sebelah kiri diperlihatkan bagaimana algoritma melihat tingkat - ia memahami lingkungan dan posisi pemain. Kotak putih adalah blok tempat pemain dapat berdiri, yang hitam adalah objek bergerak. Di sebelah kanan adalah tombol-tombol yang bisa diklik oleh sebuah jaringan saraf. Koneksi neuron terletak di tengah, hanya sebagian saja yang digunakan pada waktu tertentu.Strukturnya kompleks, tetapi SethBling tidak membuat jaringan saraf. Ini dilakukan oleh penerapan algoritma neuroevolutionary. Program mencoba melakukan tindakan, kemudian keefektifannya dinilai berdasarkan jarak yang ditempuh. Pelatihan itu berlangsung sehari. Generasi nol sangat bodoh, beberapa individu hanya diam. Jika pemain berdiri terlalu lama, simulasi berakhir. Beberapa telah belajar untuk bergerak maju, mengabaikan kehadiran rintangan dan musuh. Ini mengarah pada pertemuan dengan musuh dan peluru, tetapi setidaknya ada beberapa kemajuan. Salah satu individu generasi nol. Garis hijau adalah koneksi positif. Jika sebuah blok masuk ke dalamnya, maka warna yang sama akan dikirim ke output. Neuron ini memaksa pemain untuk bergerak maju sementara ada platform di depannya. Garis merah negatif, dan output adalah kebalikan dari warna yang diperoleh.
SethBling dikenal dengan salurannya yang memuat berbagai kiat dan penemuan untuk dunia Minecraft. Seringkali muncul konten lain. Misalnya, Mario ada di daftar minat vlogger. Itu SethBling yang pertama kali melewati Super Mario World di konsol menggunakan bug dengan mengedit memori dengan memindahkan item dalam permainan. Video dan streaming terbarunya masih memiliki gim yang sama. Tapi itu bukan orang yang bermain, tetapi algoritma neuroevolutionary, yang ditulis sendiri oleh SethBling.Implementasinya disebut MarI / O. Representasi grafis dari jaringan saraf dibuat di bagian atas layar. Di sebelah kiri diperlihatkan bagaimana algoritma melihat tingkat - ia memahami lingkungan dan posisi pemain. Kotak putih adalah blok tempat pemain dapat berdiri, yang hitam adalah objek bergerak. Di sebelah kanan adalah tombol-tombol yang bisa diklik oleh sebuah jaringan saraf. Koneksi neuron terletak di tengah, hanya sebagian saja yang digunakan pada waktu tertentu.Strukturnya kompleks, tetapi SethBling tidak membuat jaringan saraf. Ini dilakukan oleh penerapan algoritma neuroevolutionary. Program mencoba melakukan tindakan, kemudian keefektifannya dinilai berdasarkan jarak yang ditempuh. Pelatihan itu berlangsung sehari. Generasi nol sangat bodoh, beberapa individu hanya diam. Jika pemain berdiri terlalu lama, simulasi berakhir. Beberapa telah belajar untuk bergerak maju, mengabaikan kehadiran rintangan dan musuh. Ini mengarah pada pertemuan dengan musuh dan peluru, tetapi setidaknya ada beberapa kemajuan. Salah satu individu generasi nol. Garis hijau adalah koneksi positif. Jika sebuah blok masuk ke dalamnya, maka warna yang sama akan dikirim ke output. Neuron ini memaksa pemain untuk bergerak maju sementara ada platform di depannya. Garis merah negatif, dan output adalah kebalikan dari warna yang diperoleh.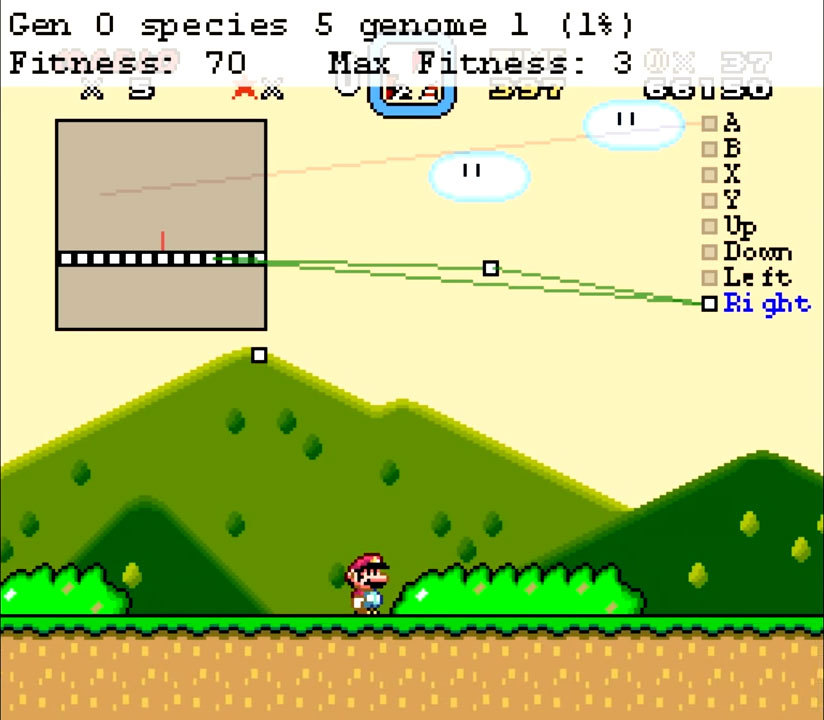
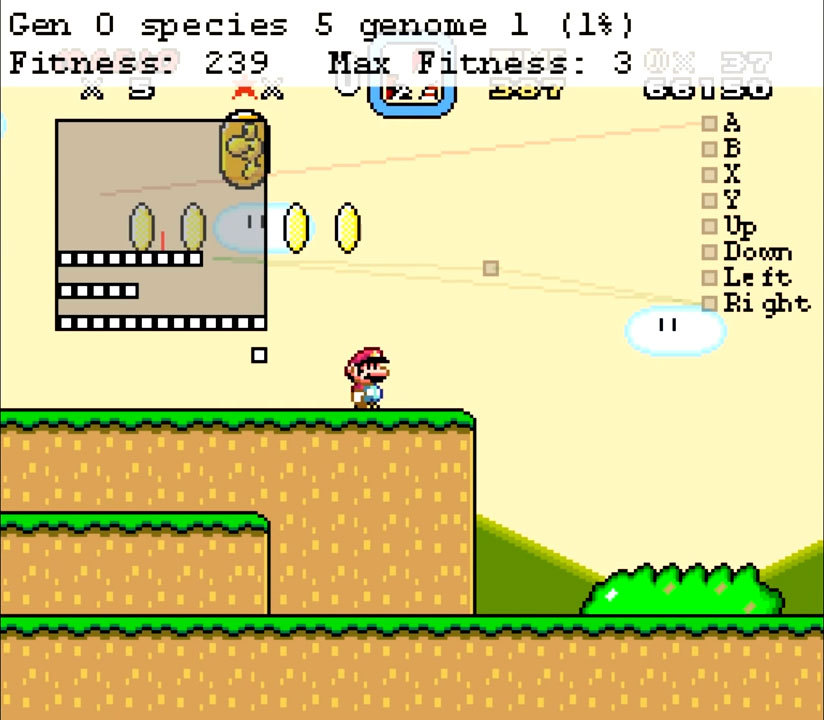 Setelah bertemu beberapa musuh di atas kepalanya, pemain melompat beberapa kali dan menemukan dirinya di platform yang berakhir di tebing. Karena tidak ada lagi blok di tempat yang tepat, orang ini berhenti di sini. Individu yang lebih kompleks dan mungkin lebih sukses memiliki lebih banyak neuron, tetapi prinsip operasi tetap sama.Untuk membuat jaringan saraf belajar, seleksi diterapkan. Kinerja setiap individu diperkirakan berdasarkan jarak yang ditempuh dan kecepatan. Hanya individu yang paling efektif yang dilewati pada generasi berikutnya, maka mutasi terjadi. Proses ini diulangi sebanyak yang diperlukan. Butuh 35 generasi untuk menyelesaikan satu level. Individu yang paling sempurna menerima nilai kebugaran dari urutan 4000.
Setelah bertemu beberapa musuh di atas kepalanya, pemain melompat beberapa kali dan menemukan dirinya di platform yang berakhir di tebing. Karena tidak ada lagi blok di tempat yang tepat, orang ini berhenti di sini. Individu yang lebih kompleks dan mungkin lebih sukses memiliki lebih banyak neuron, tetapi prinsip operasi tetap sama.Untuk membuat jaringan saraf belajar, seleksi diterapkan. Kinerja setiap individu diperkirakan berdasarkan jarak yang ditempuh dan kecepatan. Hanya individu yang paling efektif yang dilewati pada generasi berikutnya, maka mutasi terjadi. Proses ini diulangi sebanyak yang diperlukan. Butuh 35 generasi untuk menyelesaikan satu level. Individu yang paling sempurna menerima nilai kebugaran dari urutan 4000.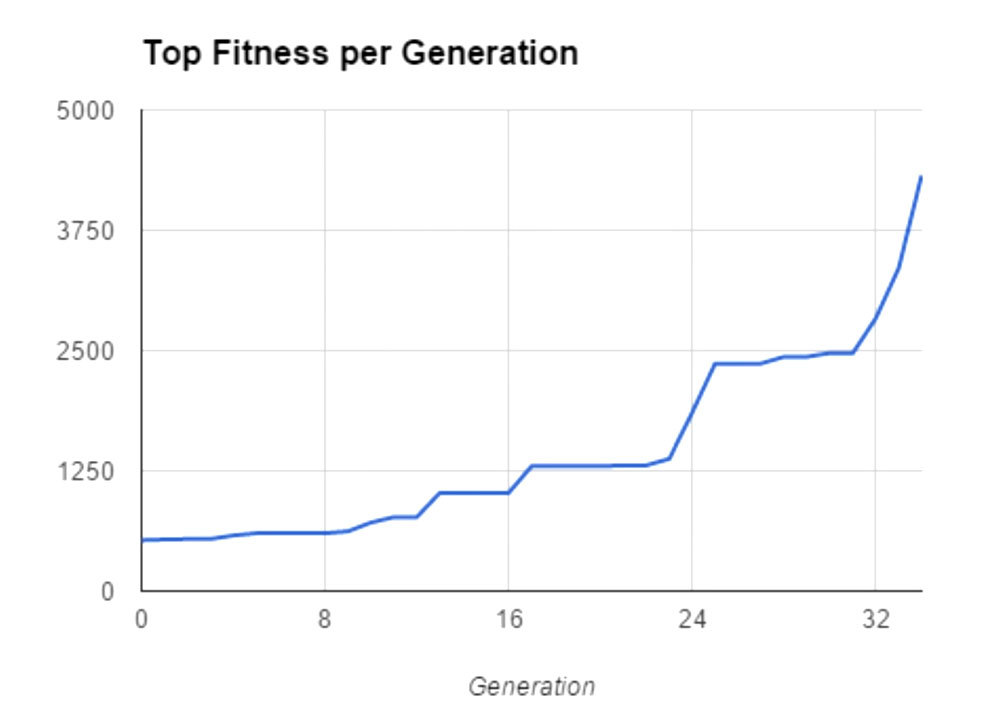 SethBling tidak datang dengan prinsip kerja dari awal. Ketika membuatnya, ia menggunakan karya ilmiah yang sudah ada tentang NEAT (NeuroEvolution of Augmenting Topologies), neuroevolution dari topologi yang sedang tumbuh. Ini juga menjelaskan bagaimana generasi dapat dibagi menjadi spesies, yang tidak semua algoritma genetika coba lakukan. MarI / O ditulis dalam Lua menggunakan emulator BizHawk . SethBling tidak berhenti di situ. Dia memaksa algoritma untuk melewati platformer lain, menyiarkan proses pembelajaran di akun Twitch-nya. Di antara permainan itu adalah Super Mario Brothers klasik. MarI / O mampu melewati level pertama, tetapi terhenti di level kedua. Sekalipun mengalami kegagalan, algoritme itu secara tidak sengaja menemukan bug kecil yang berpotensi berguna bagi speedraner.
SethBling tidak datang dengan prinsip kerja dari awal. Ketika membuatnya, ia menggunakan karya ilmiah yang sudah ada tentang NEAT (NeuroEvolution of Augmenting Topologies), neuroevolution dari topologi yang sedang tumbuh. Ini juga menjelaskan bagaimana generasi dapat dibagi menjadi spesies, yang tidak semua algoritma genetika coba lakukan. MarI / O ditulis dalam Lua menggunakan emulator BizHawk . SethBling tidak berhenti di situ. Dia memaksa algoritma untuk melewati platformer lain, menyiarkan proses pembelajaran di akun Twitch-nya. Di antara permainan itu adalah Super Mario Brothers klasik. MarI / O mampu melewati level pertama, tetapi terhenti di level kedua. Sekalipun mengalami kegagalan, algoritme itu secara tidak sengaja menemukan bug kecil yang berpotensi berguna bagi speedraner.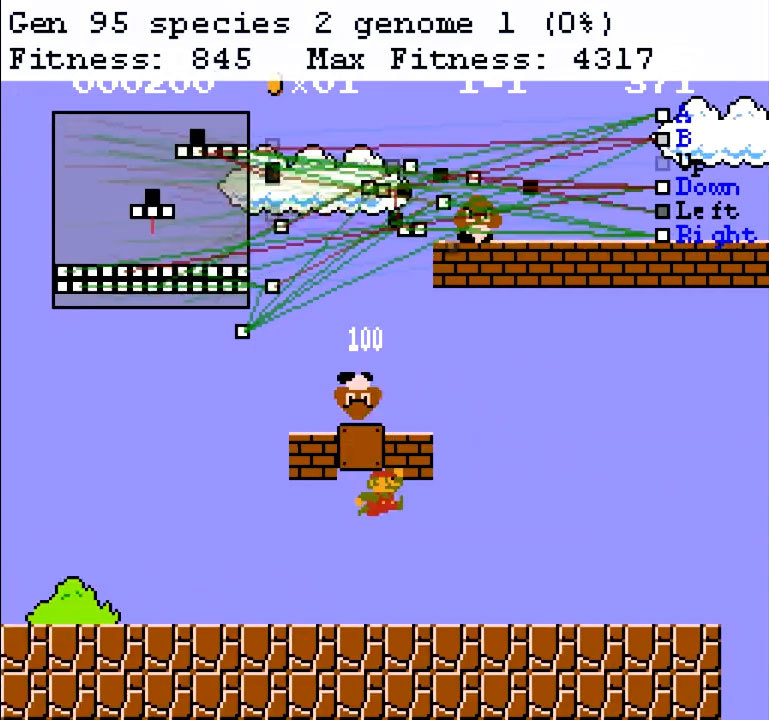 Beberapa orang terjebak di salah satu dinding di tingkat Donat Plains 4 di Super Mario World. Butuh beberapa waktu untuk memahami bahwa Anda harus berlari ke dinding, Anda tidak perlu melompat ke sana. Generasi berikutnya sudah dapat berlari ke dinding, tetapi pada rintangan berikutnya, individu-individu berhenti - mereka lupa bagaimana cara melompat di depan rintangan. Setelah beberapa generasi, algoritma menyadari di mana harus menekan tombol ke kiri, dan ke mana harus melompat. MarI / O tidak pernah bisa menyelesaikan level itu. Salah satu pipa terlalu tinggi untuk dilompati. Sebaliknya, gunakan platform dari salah satu Hammer Brothers. SethBling mengganggu proses belajar, percaya bahwa algoritma tidak akan pernah mempelajari ini.
Beberapa orang terjebak di salah satu dinding di tingkat Donat Plains 4 di Super Mario World. Butuh beberapa waktu untuk memahami bahwa Anda harus berlari ke dinding, Anda tidak perlu melompat ke sana. Generasi berikutnya sudah dapat berlari ke dinding, tetapi pada rintangan berikutnya, individu-individu berhenti - mereka lupa bagaimana cara melompat di depan rintangan. Setelah beberapa generasi, algoritma menyadari di mana harus menekan tombol ke kiri, dan ke mana harus melompat. MarI / O tidak pernah bisa menyelesaikan level itu. Salah satu pipa terlalu tinggi untuk dilompati. Sebaliknya, gunakan platform dari salah satu Hammer Brothers. SethBling mengganggu proses belajar, percaya bahwa algoritma tidak akan pernah mempelajari ini.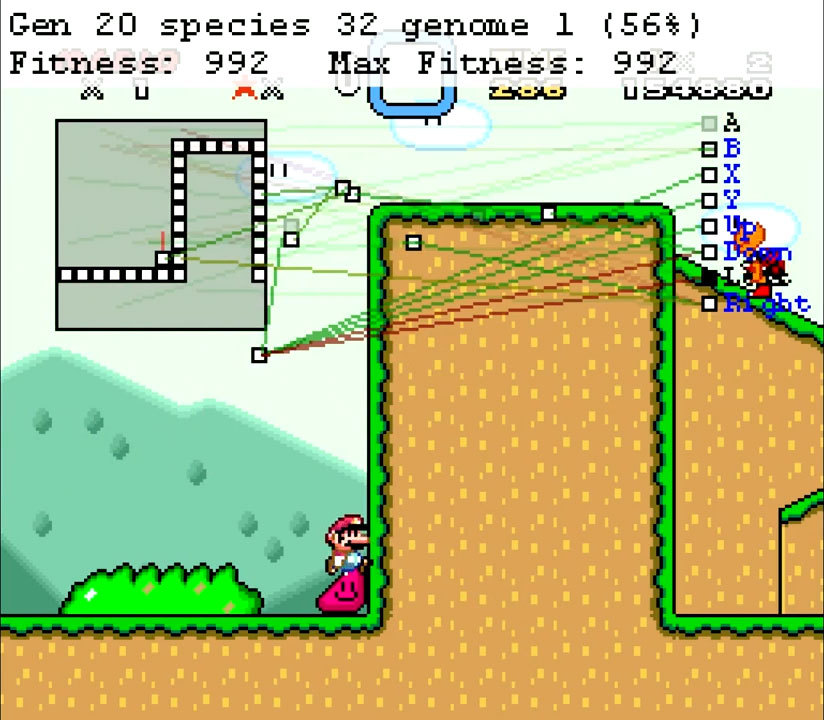
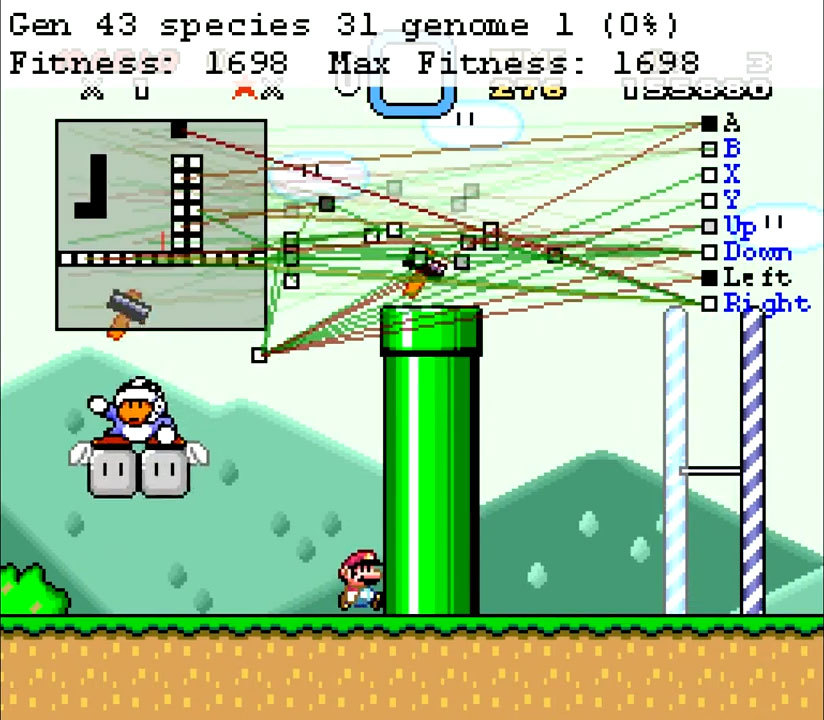 Dalam video ketiga, MarI / O memainkan Super Mario Kart dalam mode Time Trial tanpa musuh. Winterbunny membantu memodifikasi skrip agar berfungsi dalam game ini. Meskipun Super Mario Kart berbeda dari platformer, proses pembelajarannya sama. Pada awalnya, algoritma ini bodoh dan tidak bisa melakukan apa-apa. Individu hanya mencoba mengklik tombol tertentu. Tetapi bahkan pada generasi nol pun ada individu yang belajar mengendarai dengan cukup baik.Sudah di generasi ketujuh, seorang individu ditemukan yang melaju 5 lap dalam 2,5 menit. Angka ini buruk, rekor dunia sekitar satu menit. Seorang individu terus-menerus mengalami hambatan dan terkadang melingkari lingkaran. Seorang individu dari generasi kesembilan menunjukkan hasil yang baik dari 1,5 menit, ia bahkan mencoba untuk tetap berada di jalan tanpa pergi ke sela-sela.Pastebin MarI / O kode sumberSaluran Twitch lain di mana MarI / O belajar memainkan berbagai permainan
Dalam video ketiga, MarI / O memainkan Super Mario Kart dalam mode Time Trial tanpa musuh. Winterbunny membantu memodifikasi skrip agar berfungsi dalam game ini. Meskipun Super Mario Kart berbeda dari platformer, proses pembelajarannya sama. Pada awalnya, algoritma ini bodoh dan tidak bisa melakukan apa-apa. Individu hanya mencoba mengklik tombol tertentu. Tetapi bahkan pada generasi nol pun ada individu yang belajar mengendarai dengan cukup baik.Sudah di generasi ketujuh, seorang individu ditemukan yang melaju 5 lap dalam 2,5 menit. Angka ini buruk, rekor dunia sekitar satu menit. Seorang individu terus-menerus mengalami hambatan dan terkadang melingkari lingkaran. Seorang individu dari generasi kesembilan menunjukkan hasil yang baik dari 1,5 menit, ia bahkan mencoba untuk tetap berada di jalan tanpa pergi ke sela-sela.Pastebin MarI / O kode sumberSaluran Twitch lain di mana MarI / O belajar memainkan berbagai permainanSource: https://habr.com/ru/post/id381315/
All Articles