Generasi musik klasik menggunakan jaringan saraf berulang
Saat ini, jaringan saraf terlatih melakukan hal-hal luar biasa, tetapi percobaan di bidang ini terus menemukan sesuatu yang baru. Misalnya, programmer Daniel Johnson menerbitkan hasil eksperimennya tentang penggunaan jaringan saraf untuk menghasilkan musik klasik.Sayangnya, Anda tidak dapat menanamkan file audio pada GT, jadi Anda harus memberikan tautan langsung untuk mendengarkan salah satu hasilnya: http://hexahedria.com/files/nnet_music_2.mp3 .Bagaimana dia melakukannya?Daniel Johnson mengatakan bahwa dia fokus pada properti invarian. Sebagian besar jaringan saraf yang ada untuk generasi musik adalah time-invariant, tetapi tidak not-invarian. Oleh karena itu, pengubahan posisi hanya satu langkah akan menghasilkan hasil yang sama sekali berbeda. Untuk sebagian besar aplikasi lain, pendekatan ini berfungsi dengan baik, tetapi tidak dalam musik. Di sini saya ingin mencapai harmoni harmoni.Daniel hanya menemukan satu jenis jaringan saraf populer di mana ada invarian di beberapa arah: ini adalah jaringan saraf convolutional untuk pengenalan gambar.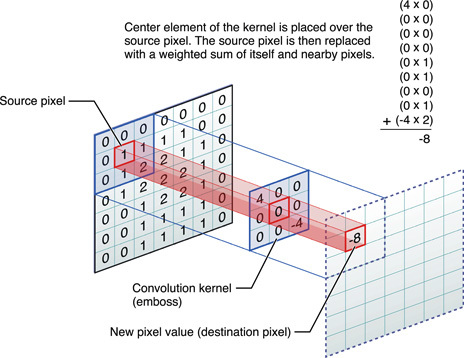 Penulis mengadaptasi model konvolusional, menambahkan jaringan saraf berulang untuk setiap piksel dengan ingatannya sendiri, dan mengganti piksel dengan catatan. Dengan demikian, ia menerima sistem yang tidak berubah baik dalam waktu maupun dalam catatan.
Penulis mengadaptasi model konvolusional, menambahkan jaringan saraf berulang untuk setiap piksel dengan ingatannya sendiri, dan mengganti piksel dengan catatan. Dengan demikian, ia menerima sistem yang tidak berubah baik dalam waktu maupun dalam catatan.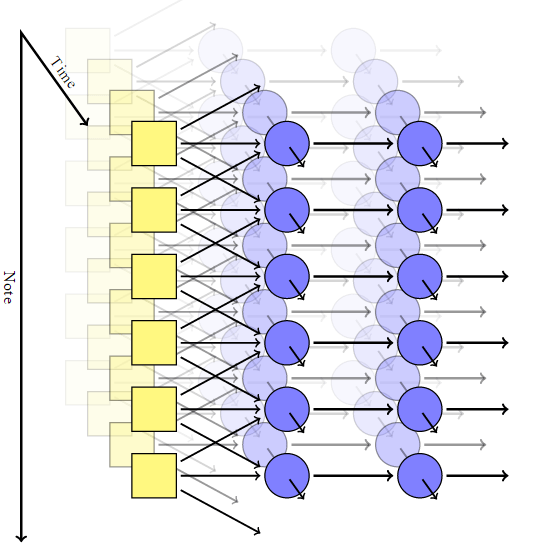 Tetapi dalam jaringan seperti itu tidak ada mekanisme untuk mendapatkan akord yang harmonis: pada output, setiap not sepenuhnya independen dari yang lain.Untuk mencapai kombinasi not, Johnson menggunakan model seperti RNN-RBM, di mana satu bagian dari jaringan saraf bertanggung jawab atas waktu, dan bagian lainnya untuk akord konsonan. Untuk menghindari keterbatasan RBM, ia datang dengan memperkenalkan dua sumbu: untuk waktu dan untuk catatan (dan sumbu pseudo untuk arah perhitungan).
Tetapi dalam jaringan seperti itu tidak ada mekanisme untuk mendapatkan akord yang harmonis: pada output, setiap not sepenuhnya independen dari yang lain.Untuk mencapai kombinasi not, Johnson menggunakan model seperti RNN-RBM, di mana satu bagian dari jaringan saraf bertanggung jawab atas waktu, dan bagian lainnya untuk akord konsonan. Untuk menghindari keterbatasan RBM, ia datang dengan memperkenalkan dua sumbu: untuk waktu dan untuk catatan (dan sumbu pseudo untuk arah perhitungan).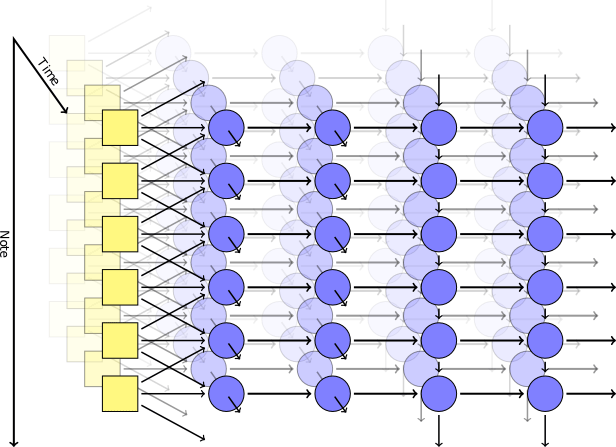 Menggunakan Perpustakaan Theanopenulis menghasilkan jaringan saraf sesuai dengan modelnya. Lapisan pertama dengan sumbu waktu mengambil parameter berikut pada input: posisi, nada, nilai catatan sekitarnya, konteks sebelumnya, ritme. Kemudian, blok yang menghasilkan sendiri berdasarkan memori jangka pendek (LSTM) dipicu: di satu, koneksi berulang diarahkan di sepanjang sumbu waktu, di yang lain di sepanjang sumbu catatan. Setelah blok LSTM terakhir, ada lapisan sederhana yang tidak berulang untuk mengeluarkan hasil akhir, ia memiliki dua nilai output: probabilitas bermain untuk not tertentu dan probabilitas artikulasi (yaitu, probabilitas bahwa not akan bergabung dengan yang lain).Selama pelatihan, kami menggunakan seperangkat fragmen musik pendek yang dipilih secara acak dari koleksi MIDI Piano Klasik Halaman. Kemudian kami bermain sedikit dengan logaritma sehingga parameter cross-entropy dalam output akan setidaknya tidak terlalu rendah. Untuk menjamin spesialisasi lapisan, kami menggunakan teknik seperti putus , ketika pada setiap langkah pelatihan setengah dari node tersembunyi tidak sengaja dikecualikan.Model praktis terdiri dari dua lapisan tersembunyi dalam waktu, masing-masing 300 node, dan dua lapisan sepanjang sumbu catatan, masing-masing untuk 100 dan 50 node. Pelatihan dilakukan di mesin virtual g2.2xlarge di cloud Amazon Web Services.
Menggunakan Perpustakaan Theanopenulis menghasilkan jaringan saraf sesuai dengan modelnya. Lapisan pertama dengan sumbu waktu mengambil parameter berikut pada input: posisi, nada, nilai catatan sekitarnya, konteks sebelumnya, ritme. Kemudian, blok yang menghasilkan sendiri berdasarkan memori jangka pendek (LSTM) dipicu: di satu, koneksi berulang diarahkan di sepanjang sumbu waktu, di yang lain di sepanjang sumbu catatan. Setelah blok LSTM terakhir, ada lapisan sederhana yang tidak berulang untuk mengeluarkan hasil akhir, ia memiliki dua nilai output: probabilitas bermain untuk not tertentu dan probabilitas artikulasi (yaitu, probabilitas bahwa not akan bergabung dengan yang lain).Selama pelatihan, kami menggunakan seperangkat fragmen musik pendek yang dipilih secara acak dari koleksi MIDI Piano Klasik Halaman. Kemudian kami bermain sedikit dengan logaritma sehingga parameter cross-entropy dalam output akan setidaknya tidak terlalu rendah. Untuk menjamin spesialisasi lapisan, kami menggunakan teknik seperti putus , ketika pada setiap langkah pelatihan setengah dari node tersembunyi tidak sengaja dikecualikan.Model praktis terdiri dari dua lapisan tersembunyi dalam waktu, masing-masing 300 node, dan dua lapisan sepanjang sumbu catatan, masing-masing untuk 100 dan 50 node. Pelatihan dilakukan di mesin virtual g2.2xlarge di cloud Amazon Web Services.hasil
Kode sumber untuk program ini diterbitkan di Github . Source: https://habr.com/ru/post/id382711/
All Articles